
基于购买次数的用户群体聚类分析*
2022-09-07 12:52:38顾强
计算机时代 2022年9期
顾 强
(中国移动通信集团江苏有限公司,江苏 南京 210000)
0 引言
随着移动通信技术的发展和移动终端的普及,越来越多的人选择线上购买商品。一些大型线上购物平台不断涌现,如淘宝、京东、苏宁易购等,电子商务模式也多种多样。这些平台不仅给人们提供了舒适便捷的购物体验,促进了线上消费模式等周边行业的发展,更是对计算机和互联网技术的发展起到了推动作用。在2020 年初新冠肺炎疫情爆发的一段时间,线上购物成为很多人购买商品的必须途径。
线上购物平台中的客户关系管理已经成为了电商平台极为重视的业务。良好的客户关系管理可以指导电商平台及时调整营销策略,根据不同用户精准的推送商品,显著提高消费者的消费体验,增加客户粘连性。为了实现良好的客户关系管理,很多专家和学者对如何将客户精准细分进行了研究。
1 需求分析和相关研究
在商城管理系统中,对客户细分常用的特征数据有:消费间隔、消费次数、消费金额、加购次数和收藏次数等。常用的分析技术是:聚类算法和分类算法。
聚类算法是一种“无监督”的数据挖掘算法,用类标号创建对象的标记,可以发现数据集中的潜在规律,算法执行开始时所有的数据是没有标记的。分类算法则是一种“监督”算法,是用类标记已知的对象标记训练而成的模型,并对新的无标记数据赋予标记。
由于在商城管理系统中,营业数据的分析是至关重要的。用户对于商品的购买信息都记录在数据库中,在这些大量的订单数据中就有很多值得挖掘的信息,因此用聚类分析非常适合。聚类分析在商城管理系统的运用场景主要是用户群体划分,通过对用户的购买行为进行聚类,划分出多个用户群体,一个用户群体中的用户往往具有相似的购买偏好,利于在后续环节根据用户的购买偏好为用户精准推送商品信息,也可以调整商城的商品结构,使之适合用户的需求,实现利益最大化。
因此,本文提出一种基于购买次数的用户群体聚类分析算法,该算法可以对用户的购买行为进行分析,指导商家及时调整营销策略,以适应消费者的多种需求。
2 基于购买次数的用户群体聚类分析算法
2.1 总体设计
本文的聚类分析算法主要基于订单数据表存储的信息,通过数据导入、数据标准化、算法求解和结果呈现四个模块实现。如图1所示。
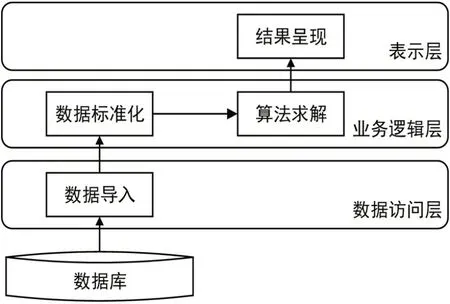
图1 基于购买次数的用户群体的聚类分析总体设计图
⑴数据导入模块:利用多表查询导入每个用户购买各种类商品的次数,以一个三元组表存储,字段分别是用户编号、商品类别编号和购买次数。如果用户没有购买过任何商品,那么该信息不会被查询,这避免了空数据对聚类结果的干扰。
⑵数据标准化模块:随着系统业务量的增长,用户对于各种商品都产生了购买行为,数据存储操作比较频繁,二维数组比三元组表更有优势,因此在数据标准化中,将查询结果转化为二维数组形式,以简化后续的计算。
⑶算法求解模块:本文采用基于购买次数的用户群体聚类分析算法,其中聚类中心的选择,是个亟待解决的问题。本文首先通过优化的K-means++算法完成聚类中心的选取,然后再进行具体的聚类分析,从而极大地提高效率和准确度。
⑷结果呈现模块:根据计算结果生成数据源并通过数据绑定的方式,呈现每个用户被分配的群体和每个群体的中心。通过对聚类结果分析,商家可以直观看到地每个群体中用户的具体购买偏好,有针对性地调整营销策略,实现利益最大化。
在数据访问中,将数据库中的每张表(例如此处的订单数据表)涉及的操作封装成一个对应的类,每个类中提供了数据库连接的开闭以及对数据表的存取操作,数据访问层直接与数据库进行交互并对上层屏蔽底层细节,对于业务逻辑层来说,只要调用相关类中的方法即可对数据库进行操作,而无需了解底层细节,有利于保证整个系统的数据安全。
2.2 聚类中心的选择
在基于购买次数的用户群体聚类分析算法中,算法的输入参数有:=[x]和。是聚类的用户数据矩阵,其中x表示聚类数据中第个用户对第类商品的购买次数,是实际参与聚类的用户数量,是商品类别的数量,是聚类生成用户群体的个数。算法的输出参数有:=(idx)和=[c]。是簇索引,idx表示第个用户被分配到的用户群体的编号,是群体中心位置,c表示编号为的用户群体对第类商品的购买次数的平均数。
由于聚类算法对初始选择的群体中心较为敏感,本文使用优化的K-means++算法对于初始群体中心的选择进行改进。K-means++算法通过启发式方法找到K-means 算法的初始群体中心,可以改进K-means算法的运行时间和最终解的质量。具体实现步骤如下:
从中随机均匀选择一个用户数据,作为第一个群体中心,记为。
计算所有用户数据到各群体中心的距离平方,并将其分配给最近的群体中心。
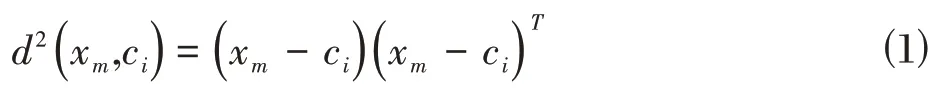
这里的距离使用欧氏距离。
对于=1,2,…和=1,2,…-1,通过轮盘赌的方法,在中选择一个用户数据作为第个群体中心,每个用户数据被选中的概率为:

其中,C表示第个用户群体,x∈C,也就是说选中概率和用户数据到当前分配的群体中心的距离平方成正比。
根据分配结果计算每个群体中的数据平均值,并以此更新群体中心位置。
重复Step2 至Step4,直至群体分配不变或达到了最大迭代次数,此时选中了个初始群体中心。在这个算法中,第一次执行Step2时,由于只存在第一个群体中心,所有的用户数据会被分配至第一个群体,在执行Step3 时,由于已被选为群体中心的用户数据必然被分配在自己所在的群体中且至群体中心的距离为0,所以在Step3 中不会出现重复选择群体中心的现象。
2.3 基于购买次数的用户群体聚类算法
通过优化的K-means++算法选择个初始群体中心后,就可以进行聚类了。在聚类算法的执行过程中,由于数据的分布,可能会出现空群体的现象,即某一次迭代后用户群体的数量不足个。一种可行的解决办法是不断选择当前群体中用户数据量最多的群体,用其中距离群体中心最远的用户数据作为一个新群体,直至当前群体数量为。同时,为了避免算法陷入局部最优解,可以多执行几次算法,通过比较所有用户数据到被分配的群体中心距离平方和,得出最好质量的解。基于购买次数的用户群体聚类算法的流程如图2所示。
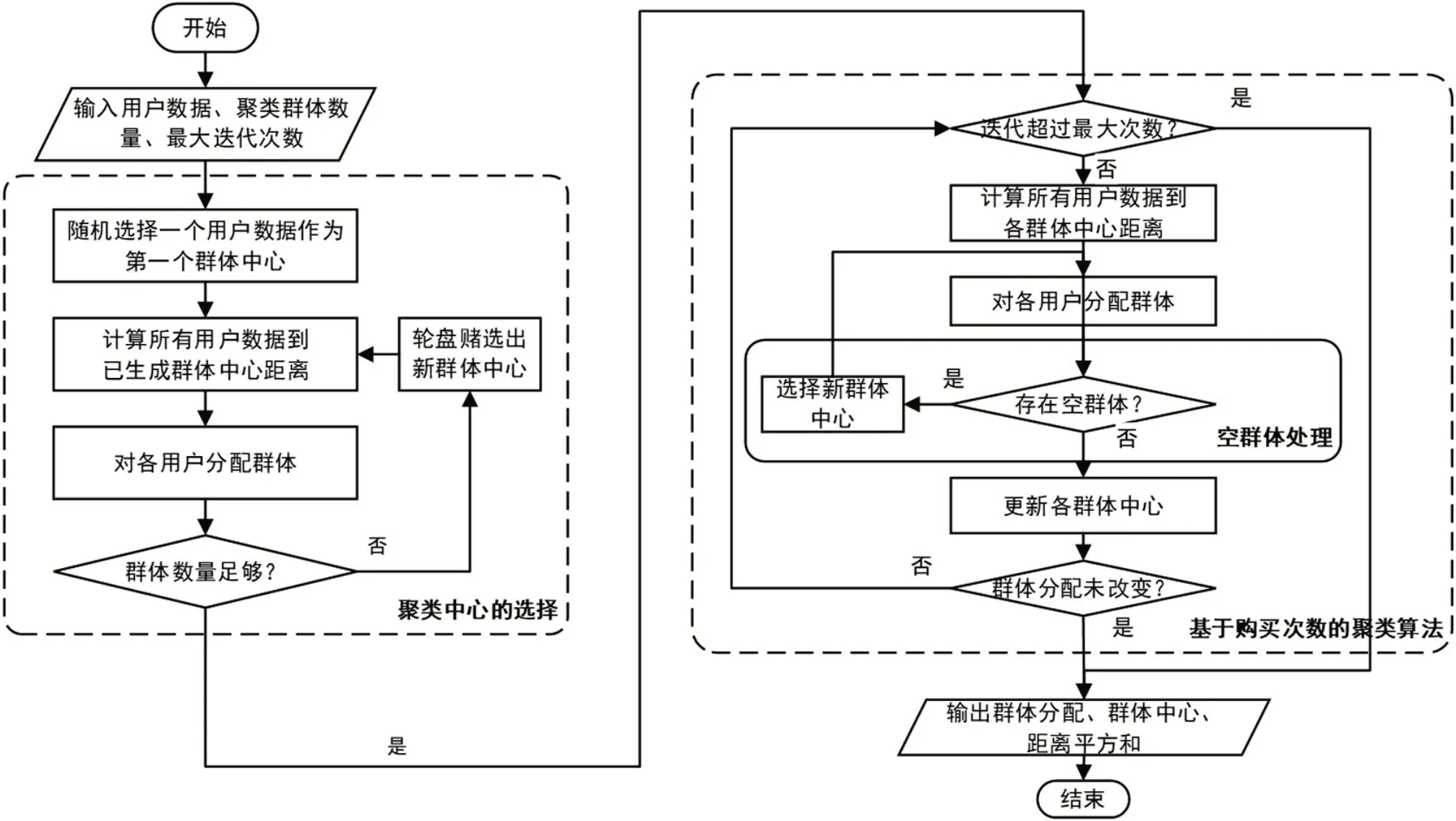
图2 基于购买次数的用户群体聚类算法
算法求解结束后,根据计算结果生成数据源,并通过数据绑定的方式,可以呈现出每个用户被分配的群体和每个群体的中心。通过聚类分析,商家可以直接观察每个群体中用户的具体购买偏好,有针对性地调整营销策略,实现利益最大化。
3 仿真实验
⑴有效性验证
本文在基于购买次数的用户群体聚类分析中,对传统K-means 算法中出现空群体的情况进行了处理。为了验证算法的有效性,本文进行了仿真实验,实验的数据集如表1 所示。其中,群体的数量为3 个,最大迭代次数设置为500次。
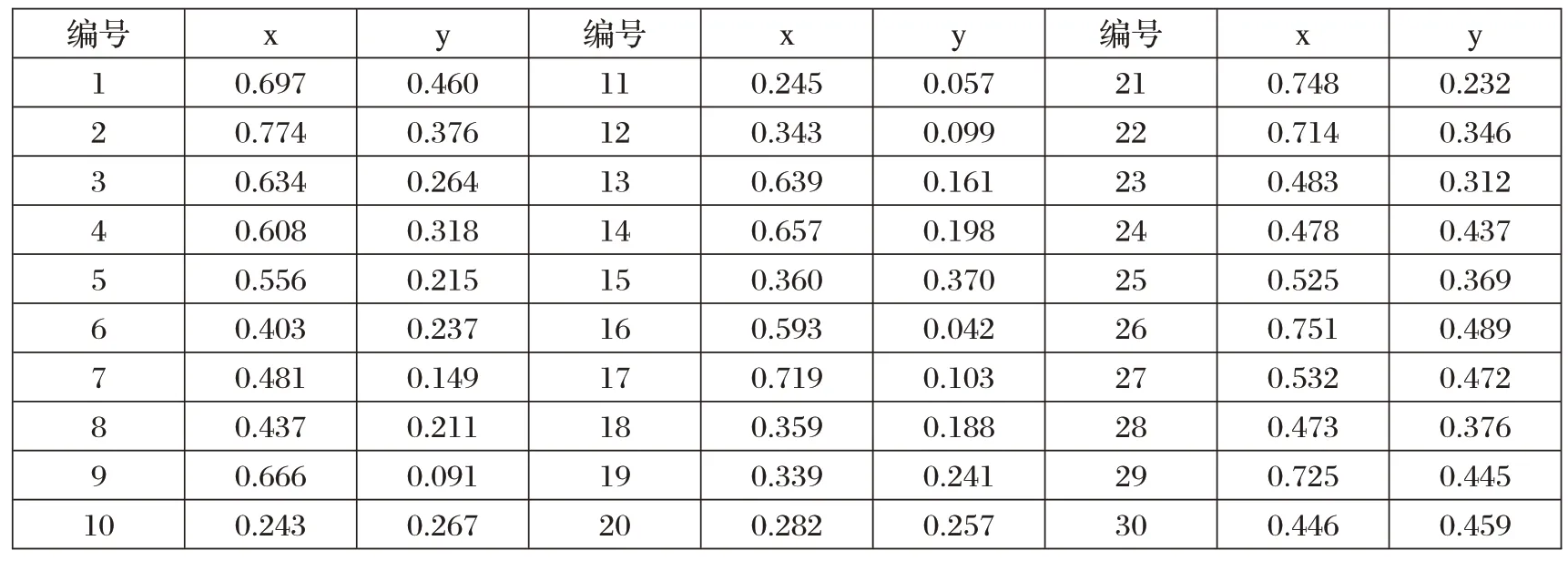
表1 仿真实验测试数据
使用上述聚类算法对实验数据集进行20次聚类,共产生三种分类,其聚类结果如图3所示。
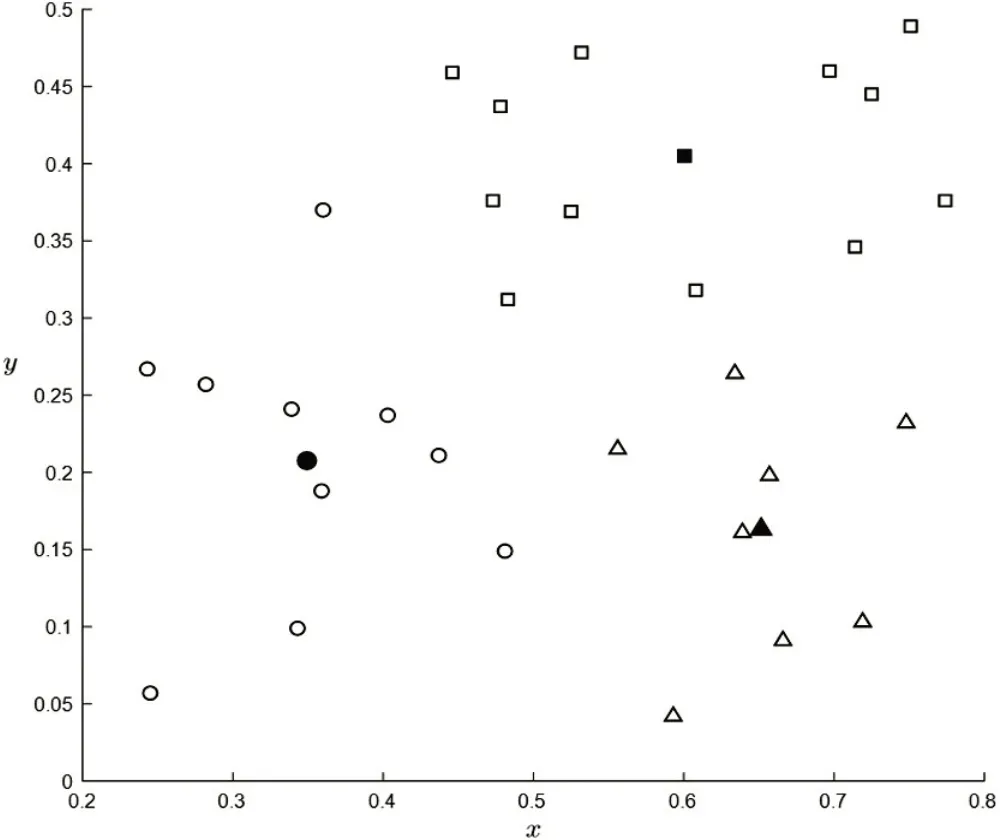
图3 基于购买次数的用户群体聚类算法实验结果图
根据可视化的结果,算法的聚类结果是正确的,每个观测值都分配到了最近中心所属的群体。同时,仿真实验汇总20 次算法执行结果都是3 类,没有出现空群体的情况,这表明对空群体情况的处理是有效的,而且结果的距离平方和标准差较小,算法的求解性能较好。
⑵性能比较
将本文将基于购买次数的用户群体聚类算法与传统Keams算法进行了性能比较。本文对3组不同数据进行了聚类处理,并根据评价指标进行对比,其结果如表2所示。
从表2 中数据可以看出,本文基于购买次数的用户群体聚类算法在处理商城客户购买商品数据时,在准确度ACC 和标准互信息NMI 方面都优于传统的Keams算法。

表2 算法性能比较
以上结果表明,聚类分析算法的有效性和性能都得到验证,可以应用于商城管理系统的用户群体聚类分析中。
4 总结
本文提出了一种基于购买次数的用户群体聚类分析方法。通过数据库查询,得到每个用户对各个类别商品的购买次数,对查询结果进行聚类分析,可显示每个用户的群体划分以及不同群体用户的购买偏好。这项技术可以让后台管理员直接看到商城的客户细分,便于及时调整营销策略以保持良好的客户关系。
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06 02:30:46
商用汽车(2021年4期)2021-10-13 07:16:02
数学物理学报(2020年6期)2021-01-14 01:00:14
铁道通信信号(2020年9期)2020-02-06 09:15:22
数学大王·趣味逻辑(2019年5期)2019-06-13 20:27:43
小学科学(学生版)(2019年5期)2019-05-21 01:00:18
经济技术协作信息(2018年30期)2018-11-22 06:20:24
电子测试(2017年15期)2017-12-18 07:19:27
中学生数理化·中考版(2017年12期)2017-04-18 12:55:03
智能系统学报(2015年4期)2015-12-27 09:38:39
