
面向时序的相似重复数据清洗算法优化
2022-09-07 12:52:34毛海涛胡文林
计算机时代 2022年9期
沈 沛,毛海涛,胡文林,芮 波
(1.中国人民解放军92728部队,上海 200436;2.杭州幂链科技有限公司)
0 引言
随着智能设备和传感器技术的大量应用,在大数据处理中出现了一类典型特征的数据——时序数据。时序数据在商业、气象、农业、航天、生物科学等各个领域都有着广泛而重要的应用,其特点是数据随时间生成,且数据量巨大、对实时分析处理要求高。但由于各种因素,如设备异常、网络波动、重复输入、多源合并等等,使得在时序数据记录中统一实体容易在相同时间单位产生相似重复数据。针对时序数据体量大这一特点,更高效的相似重复数据检测和清洗算法就显得十分重要了。
1 相关工作
目前,在相似重复数据检测和清洗方面已经有不少研究。如很多研究者提出了分区处理的思想,其本质是将大块数据分成更小的子集,这样可以在清洗过程中使单条数据记录仅与本分区中的其余记录比对识别,而不需要比对全数据集,从而大大提高了算法效率。在分区思想中,最常用的方法是分块和窗口技术。分块技术,先将数据集切分成适合处理的独立子集,再在独立子集内采用聚类算法来进行进一步的处理;窗口技术则是通过滑动窗口,选取固定大小的数据量依次比对。
其中,基于窗口技术的算法已有较多的研究和应用,在重复数据检测方面也有了一些成果。例如基于“排序合并”的算法先将数据按关键特征排序,然后通过比对邻近记录特征是否相等或相似来识别相似重复记录。在“排序合并”思想的基础上,又有研究者提出了SNM(Sorted Neighborhood Method)及其改进算 法、排序分块算法 SBM(SortedBlocks Method)、多趟近邻排序算法MPN(Multi-Pass Sorted Neighborhood)等等。其中SNM 算法主要思想是先通过关键属性对数据记录进行排序,将相似重复记录聚在一起;然后移动一个固定大小为w 的窗口,每个新进入窗口的数据记录都会与前w-1 条记录进行比对,当比对完成后,窗口会继续往下移动一格。该算法的不足主要有两点。①固定窗口的大小w选择困难。太小的窗口容易遗漏重复记录,太大则增加时间复杂度;②窗口单格滑动,效率低,每次窗口内的数据比对完成后,窗口都只向前滑动一格,在重复数据率低的数据段,效率非常低。MPN 则进一步将相似数据集中后,再进行识别。但该算法不仅要多次使用SNM 还需要多次选择不同特征进行排序,计算时间复杂度远高于SNM。
因此,以上算法都不适合重复度低的时序数据,本文以窗口技术为基础,针对低重复度时序数据的特征,提出一种相似重复数据检测算法DS-SNM(Dynamic Sliding-Sorted Neighborhood Method),该算法减少非重复数据的比对次数,提高了算法的效率。
2 DS-SNM算法
众所周知,在实际的应用中,相似重复数据通常分布并不均匀,比如在某装备信息管理系统数据中,部分区域相似重复记录特别集中,部分区域十分稀疏,而更多部分则完全没有重复记录。这样的数据分布特点,就要求算法窗口能根据实际数据分布情况动态调节大小,以实现最高效率。具体需要当相似重复记录密集时,缩小窗口,而当重复记录稀疏时,则增大窗口。通过窗口大小的自动伸缩能力来适配相似重复记录的分布,从而提高数据清洗的效率。
另一方面,对于时序数据,时间属性是排序和比较的关键特征。时序数据产生相似重复的主要原因是在相同抽样时间点产生了多条数据记录。以某装备信息管理系统数据为例,其数据来源主要来自某装备在服役期间各时间点的采样上报,样本特征属性包含完好率、故障率、剩余寿命等几十项指标,这些数据为后续对装备质量的评估、预测和预警打下了基础。但是由于系统数据以人工录入为主,且单个业务流程中人工干预的步骤较多,导致数据质量不高,易产生相似重复记录。如多单位重复上报、漏报、错报,存在主观性指标等。该场景下数据量较大,且要求在同一时间单位内单台装备只能有一条有效数据。
航空质控数据如表1 所示,其中,第3 和第4 条为相似记录,第3和第5条记录为重复记录。
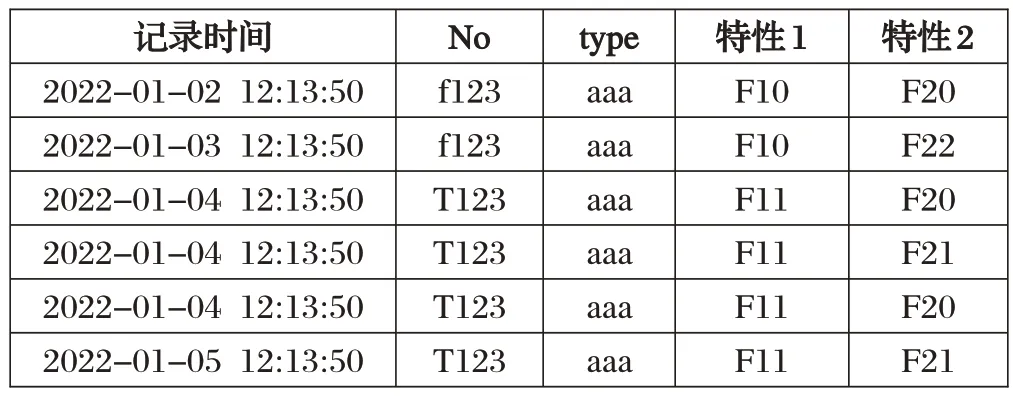
表1 重复数据的示例
基于上述数据特征,本文在SNM 算法的基础上,不降低查全率的前提下,针对时序数据提出了DSSNM算法,目的是为了改善SNM 算法中窗口大小选择难、单格窗口移动效率低的问题。
2.1 算法描述
DS-SNM主要引入以下思想:
⑴ 利用时序特性,减少比对的次数。在原始SNM 算法窗口中数据记录进行比对的过程中,假设窗口大小为,则需要每次将滑动窗口中的最后一条记录与窗口内前-1 条数据做-1 次比对。而时序性数据有着天然的时序特点,理论上,对于同一个实体,每个采样时间点t有且仅有一条数据。假设某个时间块中有个采样点,那应该有且仅有n 条数据。据此,我们对窗口中的数据比对次数进行优化。假设,在窗口中实体A 有条时序数据,第一条数据为D,其时间戳为,最后一条数据记录为D ,其时间戳为,数据记录的采样频率为,当(-)*+1=时,则表示该窗口中没有重复数据,不需要再对窗口中的数据做额外的比对。因此,当连续无相似重复记录时,一个窗口中只需要做一次比对,该策略在相似重复记录稀疏的数据段的效果最明显,能极大降低比对的次数。
⑵采用跳跃滑动窗口,提高窗口移动效率。在SNM 算法中,每次处理完本窗口的比对后,会自动向下移动一条记录的位移,对于包含n 条数据的数据集,一共要移动n-w+1 次窗口。本文对窗口滑动的方式做了优化,根据不同的情况给出了不同的滑动策略。假设,当前窗口中有n 条时序数据为<…,D>,如果窗口时段内的理论采样次数亦等于,且窗内第一条记录和最后一条记录实体类型相同,则表示该窗口中没有重复记录,我们直接将窗口移动至窗口的末端,即D为下一窗口的第一条记录;当本窗口中对应的n条记录经过首尾比对,发现窗口中不止一个实体,我们先通过二分搜索法找到最早发生实体变化的位置,窗口则滑动到该变化位置处。
⑶窗口大小自适应。SNM 算法采用固定大小的窗口,而窗口大小的选择除了对相似重复记录清除的效率有很大影响外,同时也影响识别准确性。对此,本文引入窗口自适应策略,当前窗口大小由上一窗口重复率决定。
2.2 算法实现
基于以上思想,DS-SNM算法的具体步骤如下:
设窗口大小为,初始值为2,最大值为w,数据采样频率为,窗口内记录为<D,D,D…,D >,每条记录至少包含时间戳、实体唯一标识和用于对比相似重复性的特征集三个属性。第一条数据D,对应的时间戳为T,最后一条数据D ,对应的时间戳为T ,那么,对于同一个实体而言,从T到T 之间的理论记录条数应为:
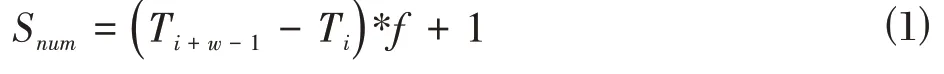
设窗口内相似重复记录数为d,则窗口内记录的相似重复率为:

算法描述如下:
⑴先按时间戳排序,时间戳相同的记录按属性排序,当时间戳和属性均相同时,则按特征集排序,得到排序数据集,并初始化相关窗口参数。
⑵ 比较窗口中第一条记录D和最后一条记录D 的实体标识属性。如果两条记录的属性相同,转向⑶,否则转向⑺。
⑶ 计算窗口中第一条记录D和最后一条记录D 的理论记录数S,将S和窗口大小比较。
⑷如果S=,则表示该窗口内均为非重复记录,则不需要对窗口中的数据再进行比对,窗口大小调整至当前窗口的两倍,如果窗口大小已经大于w,则= w,且窗口直接滑动至D 处,本轮结束。
⑸如果T= T ,则表示该窗口内均为相似重复的记录,则同样窗口大小调整至当前窗口的两倍,如果窗口大小大于w,则= w,且窗口直接滑动至D 处,本轮结束。
⑹ 否则,表示该窗口中有重复记录,或者缺失记录,转向⑺。
⑺窗口内第一条记录D开始在D到D 之间二分折半搜索寻找,即先对比D与 不满足条件则比对D与 以此类推。如果遇到属性与D不相同的记录D,则转向⑻,如果直到D处依然未转向⑻,则最后转向⑼。
⑻窗口直接滑动至D处,窗口大小不变,重新回到⑵。
⑼对窗口内的记录采用SNM 比对,清洗相似重复记录并计算出当前窗口内的重复率,清洗完成后将窗口滑动到下一条待处理记录,并调整窗口大小=(×(1-))+2。重新回到⑵。
3 实验结果与分析
本文将DS-SNM 应用于某装备信息管理系统数据,选取其中50万条连续记录用于实验。数据采样率为每日一条记录,每条记录包含单位、时间、装备型号、出厂号码、状态等多个属性,以装备型号和出厂号码唯一确定单台装备实体,且理论上,该记录表应该每天每台装备有且仅有一条记录。但实际中,因一天中会有多个单位同时对单台装备进行记录,或人工失误多次输入相似记录的情况,因此存在不少重复数据。
本文采用SNM 与DS-SNM 算法在不同窗口大小(其中DS-SNM 为最大窗口大小)以及不同数据集规模的实际效果进行了对比。窗口大小选择了4、16、32和64四个等级,数据集则选择了从5万到50万的不同规模做对比。实验中,我们以算法名加窗口大小表示一个带具体配置的算法,例如SNM4 表示窗口大小为4 的SNM 算法,DS-SNM32 则表示最大窗口为32 的DS-SNM算法,以此类推,结果如图1、图2、图3所示。
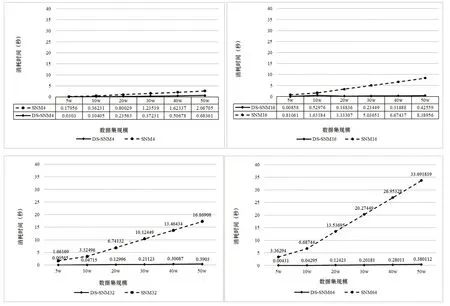
图1 DS-SNM与SNM在不同窗口大小和不同数据集大小下的耗时对比
从图1 和图2 可以看出在选择不同窗口大小及不同规模数据集下,DS-SNM 算法在时序数据的清洗上所产生的比对次数和耗时都显著优于传统的SNM。而从图3 可以看出,SNM 算法随窗口变大,比对次数线性增加,而DS-SNM 算法在最大窗口变大的情况下反而比对次数会小幅度下降。在准确率方面。效率提升的同时,相似重复数据的清洗准确率几乎无变化,DS-SNM 与SNM 在该数据集上均达到95.6%以上的清洗率。在该数据集的不同规模子集下的准确率略有波动,均不超过1%。
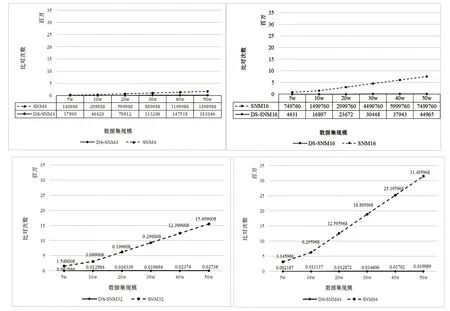
图2 DS-SNM与SNM在不同窗口大小和不同数据集大小下的比对次数对比
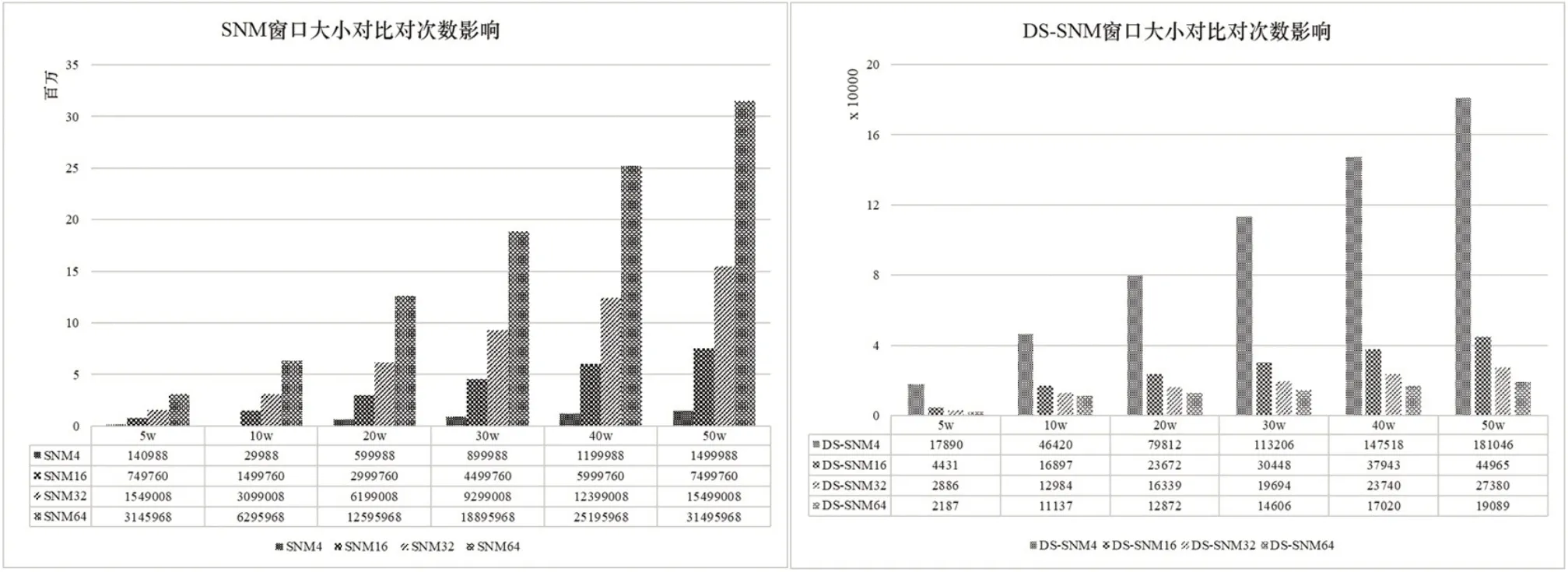
图3 窗口大小对比对次数产生的影响
从实验结果中我们可以看到,改进算法DS-SNM在不同规模的数据集下都比原SNM 算法大幅提高了效率,且数据集规模越大效率提升越明显。该结果也印证了算法理论,由于DS-SNM 专门针对相似重复较稀疏的数据集而设计,在稀疏数据段做了跳跃优化策略,在密集相似重复的数据段则依然使用SNM,所以能在保证准确率的前提下提高算法效率。同时可以发现,原始的SNM 算法比对次数会随着窗口变大而成倍增大,从而导致耗时大幅增加,而DS-SNM 中最大窗口变大所带来的对比次数反而减少,因此该算法在窗口大小变化上也更具鲁棒性。
4 结束语
时序数据随时间产生,数据量大,时效性要求高,因此提高检测算法的效率非常必要。本文针对时序相似重复数据清洗,对传统SNM 算法进行改进提高,提出DS-SNM 算法。该算法引入多种有效机制,大大减少了数据比对次数,减少了时间的消耗。该算法特别适合大规模的时序数据处理,实验结果也表明,该算法显著提高了相似重复数据的检测效率。
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
中国农业信息(2021年3期)2021-11-22 06:44:48
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
制造技术与机床(2018年11期)2018-11-23 01:08:02
意林(绘英语)(2018年1期)2018-04-28 01:21:42
儿童绘本(2018年5期)2018-04-12 16:45:32
电子制作(2016年15期)2017-01-15 13:39:08
城市轨道交通研究(2015年11期)2015-02-27 11:02:50
