
基于Albert模型的民族医药知识图谱构建*
2022-09-07 12:52:18唐东昕
计算机时代 2022年9期
李 晴,唐东昕,贺 松
(贵州大学医学院,贵州 贵阳 550025)
0 引言
中华文化博大精深,源远流长。在医疗救治的发展过程中,五十六个民族形成了各具民族特色的防病治病的医疗方剂和用药经验。具有鲜明的地域性和民族性的中国少数民族医药是经过古人不断切身实践和数千次的经验凝聚而成,是中华文化的瑰宝之一。然而有关民族医药的信息化资源非常稀少,只有古籍医书记载,不便于学习和整理。将民族医药进行实体抽取,构建民族医药知识图谱,可以方便查询方剂的治疗功效以及清楚地了解其中的关联,便于医护人员和研究人员高效地学习,对其进行规范性整理和保护,彰显其民族特色,有助于推动民族医药的发展和传承。
1 研究现状
在人工智能领域中,对于医学知识图谱的构建始终是国内外的研究热点。高效地将知识图谱应用于医学领域将给人类的医疗卫生带来革命性的变化。张雨琪等人详细地介绍了现有的中医药知识图谱,并以知识图谱的构建过程为主线,阐述了构建技术如何根据领域特点应用于中医药知识图谱,以及其应用进展。北京大学计算语言学研究所发布的中文医学知识图谱CMeKG(Chinese Medical Knowledge Graph),其规模庞大,涉及医学文本范围广泛。然而对于民族医药知识图谱构建却寥寥无几,因此为保护民族医药的传承和推进其不断发展,构建民族医药知识图谱有非常重要的意义。
知识图谱是谷歌于2012 年正式提出,主要目的是为了提升谷歌的搜索质量和搜索性能。知识图谱的定义:“A knowledge graph consists of a set of interconnected typed entities and their attributes.”即知识图谱是由一组相互连接的类型化实体及其属性组成。知识图谱(Knowledge Graph,KG)作为一种用图模型描述知识和建模世界万物之间关联关系的方法,通过一系列形如<头实体,关系,尾实体〉的三元组对知识进行结构化表示。通过构建知识图谱的方式,可以综合分析民族医药方剂的治疗过程,对于理解民族医药方剂理论,提供了高效的学习途径。
2 方法与结果
2.1 民族医药数据处理
由于民族医药记载于古医药典中,因此需要将非结构化数据转化为结构化数据,有关数据是选取于贾敏如、李星炜的《中国民族药志要》,这本书主要涉及到44 个用药民族,记载的药物总共达5500 余种,民族医药的地域性非常明显,其记载主要是按照如下顺序:①使用的民族;②该族用的药名或者药物别名;③明确的药用部位;④药物具有正确的生物学名称;⑤该药物在本民族中的使用功能和主治效果。这种记载方式为后序提取文字节省精力,也便利了后序数据的整理和标注。
数据提取后整理成文本格式,删除无效重复的数据,修改错误的数据,补充缺失的数据,对于中英文符号进行正确的转换,清理文本中的停用词以及无效字段,总共设置了如下的实体字段,具体说明见表1。

表1 民族医药数据字段说明
基于上述的操作,使用doccano 开源的文本标注工具进行标注。doccano主要可以进行文本分类,序列标注,以及序列到序列标注等比较常用的标注功能。民族医药数据集属于文本命名实体标注范畴,对民族医药语料逐一进行标注。民族医药语料标注完成后,将数据集按照70%,20%,10%的比例随机划分为训练集,测试集和验证集,导出的数据使用相关代码转换为BIO三元标注方式。
2.2 基于Albert-BiLSTM-CRF模型实体识别过程
2.2.1 Albert-BiLSTM-CRF模型架构
Albert-BiLSTM-CRF 模型是进行民族医药专业术语的实体提取,主要包含:数据输入层,Albert 预训练语言模型,BiLSTM 层,CRF 层,最终是输出层。如图1所示。

图1 Albert-BiLSTM-CRF模型
第一层:将预处理好的民族医药数据转换为BIO格式数据输入到模型中。
第二层:数据通过Albert预训练语言模型,将文本转化为动态向量,实现字符向量化。
第三层:BiLSTM 层通过获取前后向相关的语义信息进行更深一步的语义编码,提取文本特征,经过深层神经网络的训练,给出文本中各对应标签的权重。
第四层:CRF 层根据BiLSTM 层输出的每个实体类别标签的概率来自动学习句子的约束条件,通过考虑文本标签间的相关性输出概率最大的的实体标签序列,获得全局最优的标签实体。
第五层:通过CRF 层输出的概率最大的实体标注序列来提取出民族医药文本中对应的实体。
2.2.2 ALBERT模型
BERT模型是谷歌于2018年提出,推动了自然语言处理领域的发展。BERT 是基于Transformer的双向编码表示的深度学习框架模型,Transformer 模型使用的是编码器和解码器的架构,编码器是由多个网络层叠加形成,其中主要包含多头自注意力机制层和前反馈网络层,这两层又分别添加了Add&Norm 残差模块,将这一层的输入信息加上输出信息进行数据的归一化处理和网络子层的连接。BERT 模型使用Attention 机制能有效捕捉语句之间的双向关系,由于BERT 模型的参数量庞大,模型训练时间周期长,因此谷歌又推出了相较于BERT,参数量大幅度削减,轻量级的Albert模型。
Albert 模型主要是通过以下两种方法降低模型的参数量,同时对其性能没有造成明显的影响。第一种方法是参数因式分解,BERT模型中的Embedding size和Hidden size是相等的,即Transformer中的输入和输出维度,而Albert模型中,对于词嵌入参数进行了因式分解,将E 和H 分开设定,把原本的V*H 的大矩阵分解成了两个小矩阵,将词映射到低维Embedding空间E,再投影到高维隐藏空间H,则词嵌入参数量从O(V*H)降低为O(V*E+E*H),当H 远远大于E 时,参数量削减非常明显。第二种方法是跨层参数共享,BERT 模型中Transformer 每一层的参数都是独立的,而Albert模型中,采用的是共享所有层的所有参数,再次大量缩减参数量,同时有效地提高了模型的稳定性。
Albert 模型还更改了BERT 模型中的一个子任务Next Sentence Prediction,即预测下一句损失,但由于下一句预测把主题预测和连贯性预测结合到文本任务中,而模型会倾向于关注主题来预测,并且主题预测更简单,因此Albert 模型换成了Sentence Order Prediction,即句间连贯性预测,避免预测主题,只关注句子之间的连贯性,SOP 获取的正负样本均取自同一文本,正样本是两个连贯的语句,负样本是交换正样本中的两个连贯语句的顺序,SOP 只专注于预测句子之间的连贯性,使得模型能够学习到更细粒度的区分,Albert 模型显著地提升了下游多句子编码任务的性能。
2.2.3 BiLSTM-CRF模型
BiLSTM-CRF 模型是由前后向LSTM 和CRF 两个模型组合而形成的,其模型结构如图2所示。

图2 BiLSTM-CRF模型

2.3 ALBBC模型实验配置参数
2.3.1 实验环境
实验所采用的环境如表2所示。

表2 实验环境
2.3.2 Albert-BiLSTM-CRF模型参数
Albert-BiLSTM-CRF模型的实验参数如表3所示。

表3 模型参数
2.3.3 实验结果分析
基于模型的参数配置,图3展示的是模型的epoch为30 时,loss 和accuracy 的变化曲线,其中训练集和验证集的loss基本同步下降,趋于平稳,准确率也同步提升,训练集略微高于验证集,说明数据在训练集和测试集中是同分布的,在训练集中学习到的目标特征适用于测试集,通过loss变化曲线不断优化模型超参数,最终得到适用于数据集对应的最优参数。

图3 ALBBC模型loss和accuracy变化曲线
实验采用评价指标分别是精确率(Precision),召回率(Recall)和F1 值(F1-Score)来评判民族医药实体的识别效果,不同实体识别的效果如表4所示。
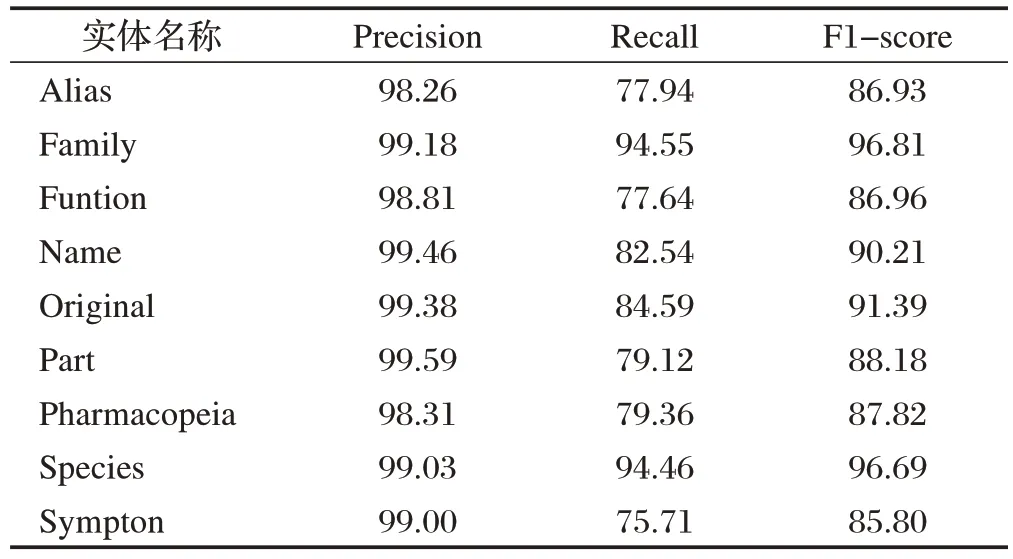
表4 实体抽取结果(单位:%)
同时为了对比本模型的有效性,选取了以下模型进行对比,取值均是经过多次实验,取其平均值而得,如表5所示。

表5 不同模型的结果对比(单位:%)
表5 中展现了CRF,双向LSTM,BiLSTM-CRF 模型,Albert-BiLSTM 模型和Albert-BiLSTM-CRF 模型的P、R、F1 值。由模型实验对比结果可以得出,机器学习方法结果最低,BiLSTM-CRF 模型从上下文信息中高效地提取文本特征,加入Albert模型,识别效果有进一步提升,最终Albert-BiLSTM-CRF模型可以高效实现命名实体识别。
2.4 民族医药知识图谱存储及可视化
2.4.1 Neo4j图数据库
Neo4j是高性能的NoSQL 数据库,同时也是目前主流数据库中使用率较高的图数据库之一。Neo4j图数据库具备对事物的支持特性,能够对数据的存储进行横向扩展,查询语言使用Cypher并且具备强大的图形搜索能力。Neo4j图数据库主要存储数据的节点和“关系”,节点可以附带零个或多个属性值和“关系”,“关系”是用户自定义实体之间的关系。
2.4.2 民族医药知识图谱展示
将模型抽取的实体存储为CSV 格式,利用Python中py2neo 模块,将其导入Neo4j 中,通过Cypher LOAD CSV 读取数据,在Neo4j 中直观地展示民族医知识图谱,如图4 所示。在Neo4j 中使用Cypher 查询语句:

图4 部分民族医药图谱展示

其中,n1,n2 是节点,rel 是节点之间的关系,where 是过滤条件,根据自己需要查询的信息进行筛选,return是返回需要的信息。
3 结束语
本文围绕民族医药知识图谱的构建展开,主要基于Albert-BiLSTM-CRF 模型对数据集进行命名实体识别,实体表示知识图谱的节点,并自定义节点之间的关系,最终,通过Neo4j 实现民族医药知识图谱可视化。由于Albert 模型需要大量的数据来进行训练,而民族医药的数据是非结构化的,数据集有限,因此准确率还有待提高,本实验还存在不足之处,例如还可利用知识图谱构建民族医药的智能问答系统,在此领域上延伸民族医药的学习,挖掘更多的专业问题,更好地为学习民族医药提供更加高效的渠道,同时有助于积极推进民族医药现代化传承与创新研究。
猜你喜欢
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
遵义(2017年24期)2017-12-22 06:10:49
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
中国卫生(2016年12期)2016-11-23 01:10:10
领导科学论坛(2016年9期)2016-06-05 14:59:58
中国当代医药(2015年9期)2015-03-01 02:02:22
