
砂壤潮土有机质含量可见-近红外光谱预测
2022-09-05 03:27:04钟翔君张东兴和贤桃杜兆辉
光谱学与光谱分析 2022年9期
钟翔君, 杨 丽*, 张东兴, 崔 涛, 和贤桃, 杜兆辉
1. 中国农业大学工学院, 北京 100083 2. 农业农村部土壤-机器-植物系统技术重点实验室, 北京 100083
引 言
土壤有机质(soil organic matter, SOM)是影响播量的土壤关键参数, 对作物的生长发育起至关重要的作用[1-2]。 根据田间SOM信息对播量进行实时调控, 可以充分挖掘土壤潜力、 节约良种用量, 对作物的提质增效具有重要意义[3-6]。 传统SOM信息的获取多以实验室化学分析为主[7], 虽然应用较广, 但分析过程繁琐、 时效性差、 成本高且采样的密度难以满足大面积检测需求。 近年来可见-近红外光谱分析因其具有操作方便、 采样速率快等优势, 还可提供高分辨率和丰富的土壤光谱信息, 成为SOM快速获取的热门途径。
国内外许多学者对SOM含量的光谱预测已开展了大量研究[8-12], 其中, 光谱特征筛选方法[13]有效解决光谱信息量大、 数据冗杂等造成预测模型效率低的问题, 是光谱分析过程的重要环节。 Vohland等[14]对德国不同类型的土样进行光谱分析, 通过竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)结合偏最小二乘回归(partial least squares regression, PLSR)建立了SOM含量预测模型。 Viscarra Rossel等[15]对澳大利亚不同类型土壤有机碳的组成进行研究, 基于决策树算法推导传递函数并构建预测模型来预测土壤总有机碳组分。 Shi等[16]对不同省份的土类数据进行可见-近红外光谱分析, 通过空间约束局部-偏最小二乘方法建立了SOM预测模型。 张智涛等[17]基于分数阶微分结合支持向量机分类-随机森林构建荒漠土SOM含量预测模型。 张娟娟等[18]分析了5种砂姜黑土样本的光谱特征, 通过遗传算法筛选特征波长并结合支持向量机建立了预测模型。 于雷等[19]采用不同变量筛选方法对汉江平原土样进行特征提取, 并构建了SOM含量预测模型。 Hong等[20]通过分数阶微分结合不同的变量筛选方法, 分析了华中地区土样的光谱特征并构建了SOM含量预测模型。 综上可以看出, 利用特征变量筛选方法可以有效优化模型, 但是不同类型土壤差异较大, 构建的模型大多仅针对某种特定类型的土壤, 对不同土壤类型的估测精度和适用性难以估测[21]。
华北平原是全国重要的粮食和经济作物区, 同时是我国玉米主产区之一, 通过研究该区域SOM信息指导播种、 施肥及其他土壤改良作业, 可有效降低生产投入、 提高肥料利用率。 基于此, 以该区域北部的砂壤潮土为研究对象, 以高灵敏度微型可见-近红外光谱仪采集并分析300~2 500 nm波长范围的光谱反射率, 以多种波长选择方法筛选出特征波长, 在对不同特征波长进行建模分析的基础上, 找出反演SOM的优选方法, 为该区域SOM的快速获取设备的设计方法和模型选择提供参考。
1 实验部分
1.1 土样采集与处理
研究区位于河北省廊坊市(39°19′N, 116°17′E)中部平原地带, 地处华北平原北部, 是我国玉米生产主区之一。 地势平坦, 土壤类型以砂壤质为主, 占土壤总面积90%以上, 光照充足, 温差较大, 这些独特的土壤及气候条件, 使得该地区以种植玉米、 花生、 甘薯等作物为主。
在常年耕作的地块上以五点采样法采集0~20 cm耕作层的土壤样本, 采集时去除地表残茬及砾石, 并将采集的土样密封带回实验室进行处理。 共采集了60份土样, 每份大约3 kg。 为不破坏其内部成分, 将取回的土样分别置于恒温干燥箱(DHG-9123A型, 上海)并在40 ℃下烘干24 h至恒重, 然后将烘干后的土壤研磨并过1 mm筛网后备用, 分别供实验室分析及光谱测试用。
1.2 土样实验室检测
样品的SOM含量采用TOC元素分析仪(Elementar vario TOC cube, 德国)进行测定。 首先分别用万分之一电子天平(FA324型, 上海)称取研磨后的土样15~20 mg, 并置于准备好的直径4 mm、 高6 mm开口银囊中, 随后在每个银囊滴入1 mol·L-1HCl将土样完全浸润, 静置30 min后转移至恒温干燥箱中干燥至恒重。 将烘干后的银囊封口并用锡纸包裹、 压实, 随后依次投放于TOC元素分析仪中测量其SOM含量。 为保证数据的有效性, 每个样本准备5个重复并求均值, 得到SOM含量统计结果如表1所示。

表1 SOM含量统计
1.3 光谱数据采集
土壤样品的光谱数据用美国海洋光学公司的QE Pro高性能光谱仪及NIR Quest系列近红外光谱仪同步采集。 其中, NIR Quest512-2.5近红外光谱仪采用稳定性高的滨松铟镓砷化物(InGaAs)阵列探测器, 可测量900~2 500 nm波长范围的光谱数据, 光学分辨率为9.0 nm。 QE Pro高性能光纤光谱仪采用低噪音的电子部分与18位A/D转换器, 同时配备高容量的板存缓冲区, 具有高灵敏度与宽动态范围特性, 可大大提高光谱检测的准确度, 同时具有很高的信噪比(大于1 000∶1)和稳定性, 可测量185~1 100 nm可见-近红外波长范围的光谱数据, 满足高速及宽浓度范围的快速高精度的光谱测量, 光学分辨率为1.7 nm。
图1为光谱采集装置实物图, 其中, 光源为5W HL-2000-FHSA型卤钨灯光源(Ocean Optics, Inc., 美国), 其内部集成风扇冷却、 快门和手动衰减器功能, 可以保证持续稳定的光源输出; 光源配合实验试级QR200-12-MIXED型全光谱一分三光纤(Ocean Optics, Inc., 美国)进行试验, 该光纤主要包括1个入射光纤、 2个反射光纤(UV-Vis和Vis-NIR)和光纤探头组成; 光纤探头固定在Stage-RTL-T型多功能检测台(Ocean Optics, Inc., 美国)光具座上, 装有土样的培养皿置于检测台下方的样品支座上; 通过笔记本电脑的Ocean View软件采集样本的反射光谱。

图1 光谱采集装置图
为降低环境及仪器噪声的影响, 获取高精度的光谱反射率数据, 样品测量前用美国海洋光学公司99%漫反射标准白板进行校正, 分别获取开启光源及关闭光源后得到的亮、 暗光谱数据后, 根据式(1)运算得到校正后的反射率数据。
(1)
式(1)中:WS为开启光源得到的校正亮光谱,DS为关闭光源的得到的校正暗光谱,RS为样品初始反射率光谱,Rf为校正后的样品反射率光谱。
经白板校准后, 将不同SOM含量的土壤样本置于直径3.5 mm的培养皿中, 通过调节检测台滑轨使光纤探头位于样品上表面, 试验时每采集5个样本, 用标准白板校正1次。 其中, 试验时光纤探头距标准白板及样品的上表面高度均为3 mm。 采用五点法选取样本5个位置采集光谱, 每个位置连续采集5次的均值作为该位置的反射光谱, 每个土壤样本准备3个重复, 试验共得到900条光谱数据。
1.4 光谱数据处理
由于低于380 nm和高于2 400 nm波长的数据噪声较大, 因此将上述波段从每组光谱数据中去除, 只保留380~2 400 nm范围的光谱数据用于后续分析。 为降低因仪器噪声、 测量环境及土样表面粗糙度等因素对采样的影响, 采用蒙特卡洛交叉验证法(Monte Carlo cross validation, MCCV)筛选异常数据并剔除。 对剔除异常样本后的光谱数据采用Savitzky-Golay(SG)平滑法进行预处理, 并用作后续分析。
1.5 SOM含量特征筛选方法
1.5.1 CARS算法
CARS方法首先抽取部分样本作为校正集, 利用MCCV方法及PLSR构建模型, 以模型中回归系数绝对值权重作为基准, 保留模型中权重值大的特征波长并建立新的模型, 经过多次计算, 结合交叉验证确定交叉验证均方根误差(root mean square error of cross validation, RMSECV)小的波长集合为最优特征组合[19]。 该方法可以降低冗余数据的干扰, 从而选出优化后的变量组合, 提高模型的稳定性及预测效果。
1.5.2 连续投影算法
连续投影算法(successive projections algorithm, SPA)首先将校正集波长矩阵投影到其他波长上, 计算出每个波长点对应的投影值, 以投影值为基准, 筛选并保留最大投影值所在的波长, 通过不断计算筛选出最优的波长组合。 通过SPA方法选择的是冗余信息低及共线性少的变量组合, 可以在一定程度上避免光谱信息重叠, 有利于简化模型结构、 提高运算效率。
1.5.3 其他特征提取算法
无信息变量消除(uninformative variables elimination, UVE)方法通过噪声信息加入到光谱数据中, 通过交叉验证剔除无效信息变量并建立PLSR模型, 通过对比系数矩阵的绝对值大小, 确定出特征变量组合。 变量组合集群分析法(variable combination population analysis, VCPA)采用二进制矩阵采样策略, 利用指数衰减函数筛选无效变量, 并依据交叉验证均方根误差最终选择出特征变量组合。
1.6 模型构建及检验
利用光谱-理化值共生距离法(sample set partitioning based on joint x-y distance, SPXY)将样本集按7∶3划分为建模集和预测集。 分别以全波长及CARS, SPA, UVE, VCPA及CARS-SPA等不同方法筛选的特征波长为自变量, SOM含量为因变量, 基于PLSR结合交叉验证构建SOM含量预测模型。 分别以决定系数(R2)、 校正均方根误差(root mean square error of calibration, RMSEC)、 预测均方根误差(root mean square error of prediction, RMSEP)及剩余预测偏差(residual prediction deviation, RPD)等作为模型的评价指标[16]。 其中, RPD越大、R2越接近1、 RMSEC与RMSEP越小表明模型效果越好。
2 结果与讨论
2.1 预处理结果分析
采用MCCV方法分别对不同样本的反射率数据进行异常筛选, 其中每个样本的光谱数据作为一个独立的数据点, 分别以样本的标准偏差作为y轴, 平均预测误差为x轴, 对所有样本光谱数据(数据点)进行筛选, 不同样本的数据集分布结果如图2所示。 从图中可以看出, 不同土样光谱的数据集离散程度不一样, 但大部分数据点在某范围内呈现集中分布。 将远离大部分数据集分布的数据点(即平均误差和标准偏差越大)视为异常样本并予以剔除, 留下的样本数据作为有效数据, 用于后续分析与运算。 经过异常值的筛选剔除, 最终共保留了809个有效数据。

图2 MCCV异常值筛选结果
对剔除异常数据后的光谱进行SG平滑, 得到平滑后的光谱曲线如图3所示。 从图中可以看出, 不同SOM含量的光谱反射率曲线总体变化趋势类似, 随着波长的增加, 光谱反射率呈现先增加后减小的趋势。 同时, 所有光谱曲线均在1 410, 1 910和2 200 nm附近出现明显的水分吸收谷, 这与Laamrani等[13]得到的光谱曲线特征结论类似。 另外, 由于两台光谱仪在Ocean View软件中进行拼接, 所以在970 nm附近的反射率出现明显波动。
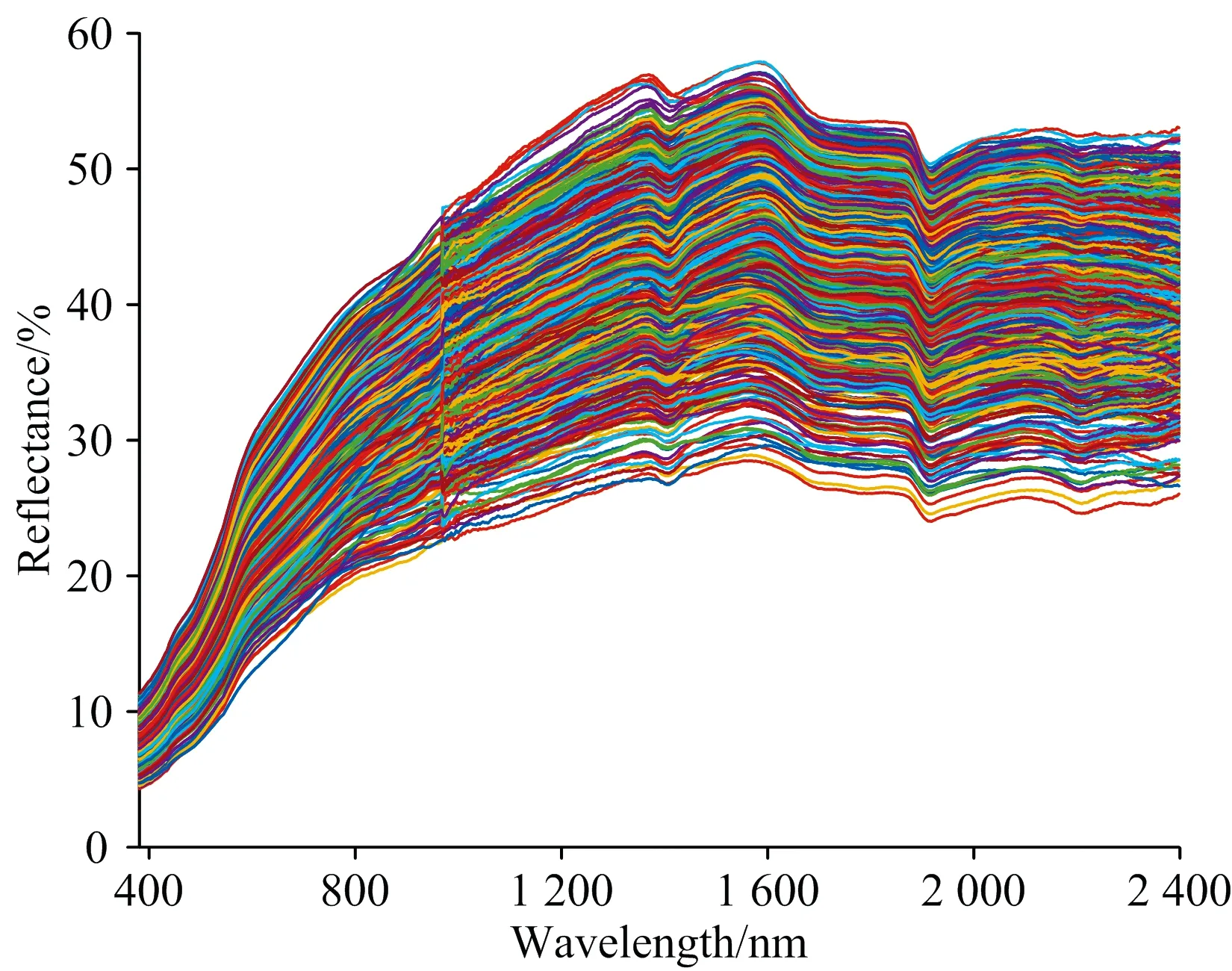
图3 光谱反射率曲线
2.2 SOM含量特征变量筛选
经过CARS, SPA, CARS-SPA, UVE及VCPA方法筛选变量结果如图4所示, 从图中可以看出, 不同筛选方法筛选出的波长数目及波长所在位置存在显著差异。 从图4(a)中可以看出, CARS算法在采样次数增加至200次的过程中, 特征变量的个数逐渐减少, 其趋势由快速下降逐渐变为平缓, 而RMSECV的值呈现先减小后增加的趋势, 这与Hong等[20]对汉江平原土样进行光谱数据处理得到的结论类似。 如图4(a)中黑色竖直线标注, 当采样次数为46次时RMSECV取得最小值, 该采样次数对应筛选出的特征波长个数为288个, 使得波段数目压缩至全波段数目的23.4%, 波长的分布如图4(b)所示。 将基于SPXY方法划分好的建模集和预测集数据通过SPA算法进行计算, 结合图4(c)可以看出, 随着变量个数的增加, RMSECV的值大致呈现快速减小然后趋于稳定的趋势, 而当变量个数为138个时, 其值达到最小, 筛选出的特征变量分布如图4(d)所示, 波段数目压缩至全波段的11.2%。 相较于CARS方法, SPA法筛选的变量共线性达到最小, 极大地减少了建模所需的波长个数, 而经过CARS方法筛选的变量个数虽然相较于全波长有所降低, 但是波长数量仍然较多, 在全波长范围内均有分布, 所以采用SPA算法对CARS筛选后的变量进行二次筛选, 进一步优化变量的结构, 结果如图4(e)和(f)所示, 共筛选出了185组特征波长, 波段数目压缩至全波段的15.0%。 通过比较UVE方法运算得到的系数矩阵, 筛选出248组特征波长, 波段数目压缩至全波段的20.1%, 如图4(g)所示, 该方法筛选出的波段较为集中。 经过对比RMSECV的值, 基于VCPA方法最终筛选出100组特征波长, 波段数目压缩至全波段的8.1%, 波长分布如图4(h)所示。
2.3 模型建立与检验
分别基于全波长及不同变量筛选方法得到的特征波长为自变量, SOM含量为因变量, 采用SPXY法将光谱数据按7∶3分为建模集和预测集, 结合留一法交叉验证, 构建PLSR预测模型, 得到不同模型的预测效果如图5所示。
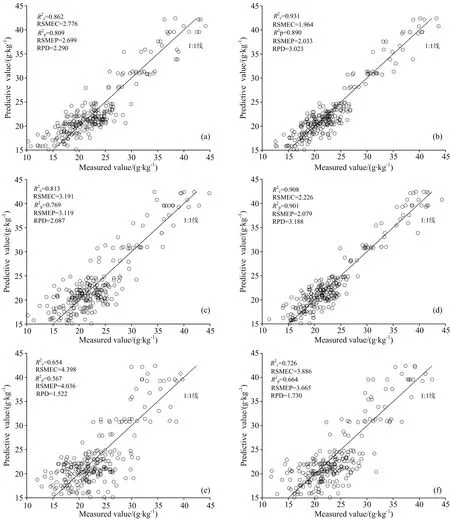
图5 不同波长PLSR建模结果
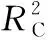
利用光谱可以实现SOM的预测, 但是光谱波段多、 数据信息冗杂, 且土壤光谱反射率易受土壤质地、 颜色及外部工作环境等多种因素的影响, 均为SOM的快速预测及仪器设计增加了难度。 本研究针对玉米主产区之一华北平原地带的砂壤潮土进行一致的处理以后, 对比不同的波长筛选方法提取有效变量, 降低了无效信息对预测效果的干扰, 实现SOM含量预测。 在后续研究中, 需要考虑其他影响因素如光照、 温度、 土壤类型等对预测效果的影响, 优化数据处理及建模方法, 以进一步提高SOM的预测精度, 实现田间SOM快速高精度检测。
3 结 论
以玉米主产区之一华北平原为研究区域, 对该区域砂壤潮土进行可见-近红外光谱采集, 通过不同的波长筛选方法提取有效变量并进行SOM含量预测, 得到主要结论如下:
(1)不同方法筛选的波长数目及波长位置存在显著差异, CARS和SPA算法选择的光谱特征在整个光谱范围都有分布, UVE和VCPA筛选的波段较为集中, 且基于CARS-SPA方法可以进一步优选特征变量, 其特征波长仅为全波长数量的15%。
(2)通过对比不同模型的建模及预测效果, 除UVE和VCPA算法外, 其余算法构建的模型均能实现SOM含量的有效预测, 其RPD值均大于2.0。
猜你喜欢
河南水利与南水北调(2023年7期)2023-08-29 02:19:54
特产研究(2022年6期)2023-01-17 05:06:16
环境保护与循环经济(2022年7期)2023-01-03 09:31:55
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
治淮(2018年6期)2018-01-30 11:42:44
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
中国照明(2016年4期)2016-05-17 06:16:15
中国光学(2015年5期)2015-12-09 09:00:28
物理实验(2015年9期)2015-02-28 17:36:46
食品工业科技(2014年23期)2014-03-11 18:18:54
