
基于k-means算法的岩性分类研究
2022-09-01 02:29高雅田范雄
微型电脑应用 2022年8期
高雅田, 范雄
(东北石油大学,计算机与信息技术学院,黑龙江,大庆 163318)
0 引言
岩性识别是储层评价、油藏描述以及实时钻井监控等方面的重要内容[1]。传统岩性识别方法主要包括岩心岩屑和薄片识别法、交会图法、对应分析法等。这些方法需要较高专业知识,受人为因素影响较大,无法满足大量数据进行处理和分析的需求。目前,随着计算机技术的发展,机器学习在实践应用中取得巨大突破。文献[2]引入BP神经网络进行复杂岩性识别,文献[3]应用支持向量机(SVM)对六种岩性进行分类,文献[4]提出K-NN模型实现对复杂碳酸盐岩岩性分类。上述研究中的岩性分类方法大都采用了有监督的机器学习算法,虽然这类型算法很多且识别精度较高,但是基于机器学习的分类算法需要提前训练大量数据集,且训练消耗时间过长、算力较大。在对大量岩性数据进行预测时,这些分类方法并不是最高效的。
本文提出使用无监督的k-means算法实现岩性识别,该方法对大量数据的岩性分类有更高的性价比和更有可行性。目前国内外对以聚类算法实现岩性分类的研究较少,并且聚类算法有分类算法所不能比拟的优势,即不需提前训练便可完成岩性预测工作。
1 k-means算法的岩性分类模型介绍
1.1 k-means聚类算法原理
k-means算法属于无监督学习,同时也是基于划分的聚类算法[5],k-means聚类算法一般采用欧式距离作为度量样本之间相似度的指标,相似度与样本间的距离成反比,相似度越大,距离越小[6]。根据k-means聚类算法的原理,要实现最终的聚类效果:首先,需要给定初始聚类数目K值;然后,根据相似度计算原理不断迭代更新聚类中心,直到聚类中心稳定生成最终结果。相较于其他的聚类算法,k-means算法以效果较好、思想简单的优点在聚类算法中得到了广泛的应用,包括市场研究、模式识别、数据分析和图像处理。
k-means算法的核心思想是:给定m个n维数据集以及k值作为输入参数,随机选取k个聚类中心Ci(1≤i≤k),利用欧式距离计算得到剩余数据到每个聚类中心Ci的值,找出数据集中与每个聚类中心距离最小的数据对象,将数据对象匹配到聚类中心Ci所对应的集群中。然后,求出每个集群中数据的均值从而生成新的聚类中心,重复迭代这个过程,最终得到稳定的聚类中心或者达到达到迭代次数。
计算数据与聚类中心欧式距离的公式为
其中,m为数据集,Ci表示第i个聚类中心,n表示数据维度,mj、Cij表示m和Ci的第j个属性值。
1.2 k-means算法流程
k-means算法的流程图如图1所示。

图1 k-means算法流程图
k-means算法可以对大规模的数据集进行分类,其算法复杂度为O(mnkT)。其中,m表示数据集数量,n表示数据集的维度,k表示聚类数目,T表示总循环次数。
1.3 岩性分类模型
针对现阶段录井岩性识别算法的缺陷,本文结合聚类算法的特点构建岩性识别模型。与传统以机器学习算法构建的岩性分类模型相比,本模型可实现在不影响精度的前提下对大规模数据的快速分类。在本模型中,首先需要对初始测井曲线数据集进行预处理,筛选出完整的共计7种属性的特征值作为模型输入,然后采用k-means算法构建分类模型对实验数据进行聚类,将模型输出结果进行标注,生成带有岩性标签的结果,实现岩性的分类。用岩性剖面数据来验证模型的精度。岩性分类模型的系统流程图如图2所示:
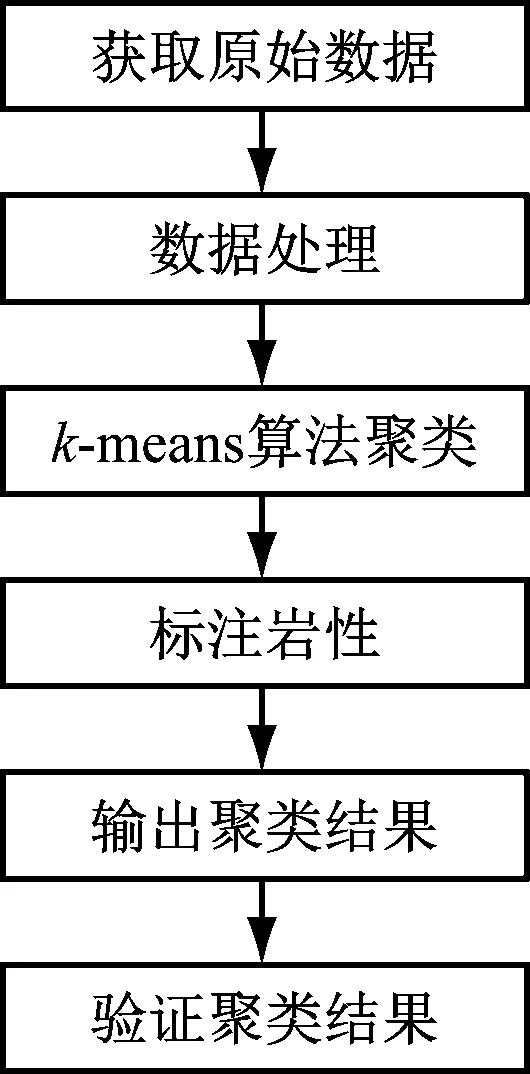
图2 系统流程图
2 数据探索分析与预处理
本实验所采用的数据集来源于松辽盆地构造区某井的测井数据。根据岩性解释结果分析,该区地层的岩石类型主要包括泥岩、粉砂岩和油页岩三种岩性。
2.1 数据清洗
原始的测井数据采集过程中可能会受到人为因素的干扰,在生成的后现数据集中可能出现重复、不完整、不相关或者变异的数据,严重影响模型分类结果。因此,在进行分析之前需要进行数据清洗。原始数据中主要存在缺失值、无关数据、重复数据和异常数据。(1)无关数据和重复数据,根据现场调研,删除同类信息和无关信息数据;(2)异常数据,原始数据中存在大量属性值为”-999.25”的数据,这类数据影响占比不大,对岩性分类干扰较大,选择删除异常值对应的元组;(3)缺失值在数据中占比很少,采用拉格朗日插值法,确保数据的完整性。数据处理后得到一组具有七个属性的测井数据,分别是自然伽玛(GR)、自然电位(SP)、深侧向(RD)、浅侧向(RS)、声波时差(DT24)、井径(CAL)、井深(DETT)。
拉格朗日插值法公式为
2.2 数据标准化
数据标准化处理的目的是降低不用特征值的量纲和取值范围差异造成的影响,本文采用零——均值规范化方法将特征值映射到[-1,1]:
其中,x*为归一化后的值,xmean为数据集中特征值的均值,xstd为数据集中特征值的标准差。
3 实验及结果分析
3.1 实验数据
本实验选取的数据包括:(1)测井曲线数据从284 m到1 185 m,间隔为1 m,共902组测井曲线作为实验数据集。(2)录井岩性剖面解释数据,数据主要有顶部深度、底部深度和岩性。
操作系统为Windows 10,软件环境为Python 3,Jupyter Notebook。
读取处理后的数据,作为训练数据。用k-means聚类算法训练数据。对k-means算法的参数进行初始化设置,如表所示。
3.2 评价标准
本文用录井岩性剖面解释对聚类效果进行验证。录井岩性剖面解释结果是人工校正的岩性剖面结果。基于k-means算法的岩性分类模型可实现对岩性的训练、分类、评价等功能。本文借助purity评价法、召回率和准确率、F-Measure值评价法三种方法评价模型分类结果。

表1 k-means参数初始化
(1)purity评价法
purity评价法,即计算正确聚类数占总数的比例。purity评价公式如下:
其中,x={x1,x2,…,xi}表示类簇的集合,xi表示第i个聚类的集合;y={y1,y2,…,yk}表示需要被聚类的集合,yi表示第i个聚类对象;n表示被聚类对象集合的总数。
(2)召回率和准确率
召回率的定义为r=R/(R+M),准确率的定义为p=R/(R+D)。其中R指真实岩性类别与聚类类别一致;M指真实岩性类别本不属于该类,但模型预测属于该类;D指真实岩性类别本不属于该类,但模型预测属于该类。
(3)F-Measure值评价法
F-Measure值评价法结合召回率r和准确率p对模型预测结果作出评价。公式如下:
本文采用最常用的F1评价法,即选取α的值为1。
3.3 标注实验结果
聚类算法的结果只能说明相同标签的数据属于同一类,并不代表对数据的最终预测。因此本实验需要对聚类结果添加标签属性。通过对标签的转换,才能将聚类结果与岩性剖面数据中的岩性进行类别匹配。
3.4 实验结果分析
表2统计了最终聚类中心和每个类的数目,通过对聚类结果进行标签转换可知,类型0为泥岩,该井段中泥岩共有659项,占总比的73%。类型1为粉砂岩,共有236项,占总比26%;类型2为油页岩,共有7项,占总比不到1%。泥岩在深侧向(RD)、浅侧向(RS)属性上的值最小,在声波时差(DT24)、自然电位(SP)和井径(CAL)属性上的值最大;粉砂岩在自然伽玛(GR)、自然电位(SP)属性上的值最小;油页岩在声波时差(DT24)属性上的值最小,在自然伽玛(GR)、深侧向(RD)和浅侧向(RS)属性上的值最大。由上述图表分析可知,每种岩性都有不同的属性特征值。
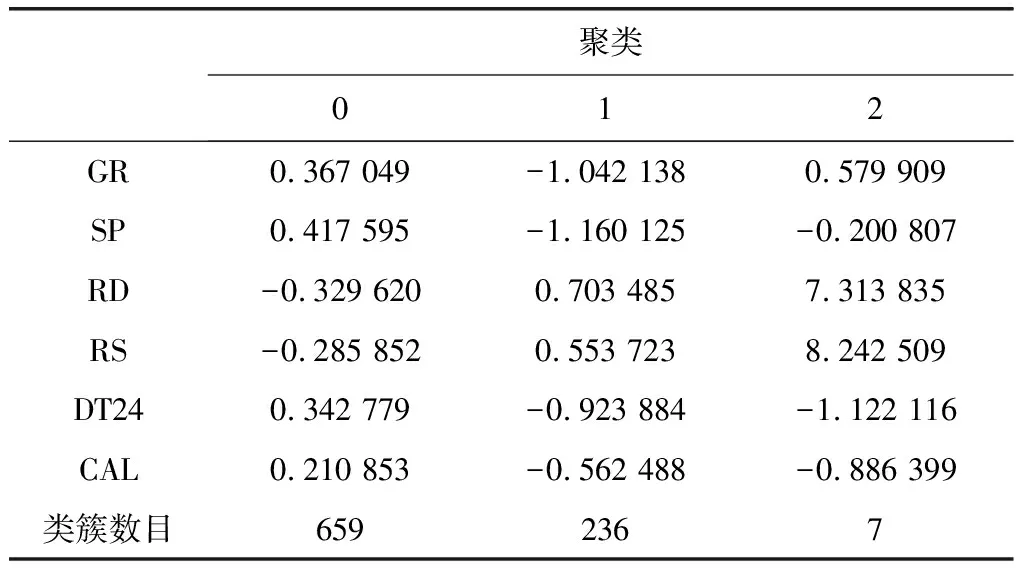
表2 聚类中心及聚类数目
表3为k-means聚类算法的岩性识别效果表。表3中YXDH表示岩性、recall表示召回率、accuracy_rate表示准确率、YX_counts表示样品数量,该井段共有三类数据,n00为泥岩共718项数据,s05为粉砂岩共170项数据,y01为油页岩共14项数据。由表3可以看出,k-means算法对泥岩(n00)识别率达到96.22%,召回率为0.883,F-measure值为0.921;对粉砂岩(s05)的识别率达到63.56%,召回率为0.882 3,F-measure值为0.738 9;对油页岩的识别率达到57.14%,召回率为0.285 7,F-measure值为0.380 9以及purity评价法的准确率为87.3%。结合三种评价方法可知,k-means算法岩性分类模型对泥岩和粉砂岩的识别效果较好,对油页岩的识别效果较差。以上结果表明,本文采用基于k-means算法的分类模型可取得较好的效果。
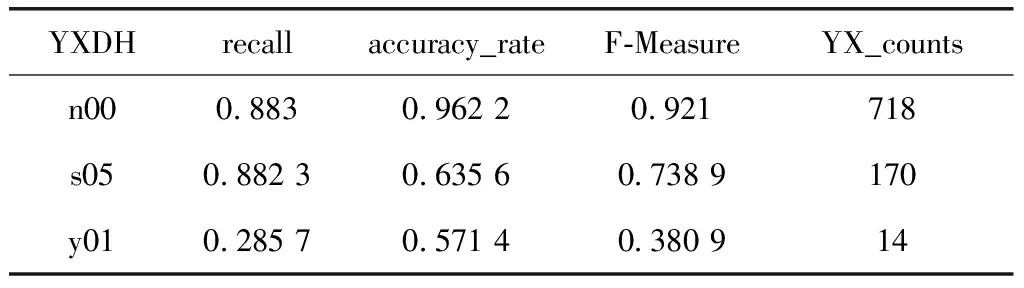
表3 k-means聚类模型识别效果
4 总结
本文提出采用k-means聚类算法进行岩性分类,识别平均准确率达到87.3%,对个别岩性的识别效果达到96.22%,分类结果与录井剖面解释结果基本吻合。证明了该方法在松辽盆地岩性性识别方面的可行性与有效性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
复杂油气藏(2021年1期)2021-05-27
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
健康体检与管理(2021年10期)2021-01-03
湖北农业科学(2017年16期)2017-09-14
中国水运(2017年1期)2017-02-27
