
基于深度强化学习的自适应交通信号控制研究
2022-09-01 07:25:42徐建闽周湘鹏首艳芳
重庆交通大学学报(自然科学版) 2022年8期
徐建闽,周湘鹏,首艳芳
(1. 华南理工大学 土木与交通学院,广东 广州 510640; 2. 华南理工大学 广州现代产业技术研究院, 广东 广州 510640)
0 引 言
交通信号控制分为定时控制,感应控制和自适应控制,而定时控制和感应控制效率较低,灵活性不强。随着车联网和人工智能技术的发展,自适应交通控制逐渐成为了研究热点。
传统的自适应交通信号控制方法主要有基于交通流预测的控制方法和基于数学模型的控制方法。郭海锋等[1]依据历史交通流量制定了交通状态-信号周期模板,以预测的交通量为依据调整信号周期和绿信比;徐建闽等[2]先使用K近邻算法预测短时交通量,然后建立模型求解信号周期,再根据各相位交通状态、最大绿灯时间确定是否延长相位进行自适应控制。基于交通预测的自适应交通控制算法的控制效果依赖于预测算法的精度且采用的交通信息较为单一,效果有限。目前有多种基于数学模型的自适应控制方法。LI Lubing等[3]使用两阶段法以延误为优化目标建立优化模型实现随机需求下的自适应信号控制;Y.LI等[4]采用多目标优化的方法实时优化延误时间,排队长度,污染排放。基于数学模型的自适应控制方法结合多种因素对道路信号配时进行分析,但只考虑了当前状态下的最优控制动作。
强化学习交通控制方法通过探索试错使信号控制机能作出最大化奖励值的相位动作以期实现交叉口的最优控制,控制效果往往优于非学习型自适应控制方法。卢守峰等[5]分别对定周期和不定周期模式下的强化学习控制方法进行了研究,并与定时控制方法进行了对比;F.RASHEED等[6]、S.TOUHBI等[7]以排队长度和当前信号状态为输入,并分析了多种自适应控制策略,结果表明,基于深度强化学习的自适应控制方法能取得更低的延误和排队长度;A.G.ROAN等[8]使用了一种基于时间差分的强化学习方法,并使用了连续时间马尔可夫过程进行多路交叉口的信号控制;赖建辉[9]、孙浩等[10]采用高维离散化模型作为输入,并对强化学习算法进行了改进以研究其收敛性和控制效果。
为了进一步提高交叉口通行效率,并考虑到动作空间的影响,提出了一种改进的D3QN自适应信号控制方法,使用不定步长动作控制模式同时输出相位和绿灯时间,分析了在稳定流和随机流场景下的收敛性和控制效果,有效地降低了交叉口延误时间和排队长度。
1 系统模型与算法设计
1.1 强化学习交通控制
强化学习交通控制机以ε-greedy规则探索动作(信号机以概率1-ε使用最大Q值对应的相位动作,以概率ε随机选择相位),在不断的探索与试错中最大化期望奖励值为:
(1)
式中:rt为时刻t执行相位动作后得到的奖励值;信号控制机时刻t得到的奖励值在时刻τ衰减为γτ-trt,其中γ∈[0,1]为衰减系数,由于城市道路交通的高时间关联性,γ取值为0.95。
控制机通过策略π选择相位动作,采用相位动作效用函数表示某一时刻交通状态s下采取动作a获得的效用值为:
Qπ(s,a)=Ea~π(s)[r+γVπ(s′)]
(2)
式中:s′为状态s后可能的状态;Ea~π(s)为策略π下的累计期望;r为状态s下采取动作a获得的奖励值;Vπ(s′)表示交通控制策略π在交通状态s′下的价值。
而交通状态s下的估计价值Vπ(s)可根据式(3)求得:
Vπ(s)=Rs+γ∑Pss′Vπ(s′)
(3)
式中:Pss′为从交通状态s转移到交通状态s′的概率;Rs为状态s下获得的即时奖励,通过Bellman方程不断迭代以优化信号控制策略π。
1.2 改进的D3QN控制方法
由于在线学习的方法会导致严重的交通拥堵,通过离线学习训练得到的模型进行交通控制。首先生成一个随机初始化交通控制策略π,将检测到的交叉口状态输入到信号控制策略π,策略π输出下一相位动作,信号灯执行此相位动作后反馈给智能体一个奖励值以更新策略π,经过多次迭代最终收敛,获得最优策略π*。一般情况下信号控制策略可由Q表表示,当交叉口交通状态很复杂时,使用Q表作出相位动作决策会出现维度爆炸的问题,使用神经网络拟合相位动作效用函数如DQN(深度Q神经网络)可解决此问题。神经网络参数为θ,信号控制机在交通状态s下使用相位动作a的实际价值为y*,Q(s′,a′;θ)为神经网络θ在交通状态s下采取相位动作a的估计值,则有:
(4)
式中:a′为状态s′下采用的动作。
以最小化时序差分误差δ优化神经网络参数θ:
δ=y*-Qπ(s,a)
(5)
Li(θ)=Ea~π(s)(δ2)
(6)
为避免Q值过高的估计,将相位动作选择和相位动作价值的估计解耦,在Double DQN中估计Q值的计算公式为:
(7)
其中θ和θ-分别为原神经网络和目标神经网络。
为保证信号控制算法快速收敛,将状态-价值对作为两部分输出。DQN的输出是相位动作效用函数的值,输出层的前一层是全联接层,而Dueling DQN把全联接层分成两股,分别估算交通状态价值Vπ(s)和当前交通状态下各相位动作优势值Aπ(s,a),所以相位动作效用函数为:
Qπ(s,a)=Vπ(s)+Aπ(s,a)
(8)
其中满足:
(9)
为了解决样本间的相关性过大的问题,D3QN训练样本从经验池中直接抽取产生,每个样本被选择的概率是相等的。但这种采样方式无法区分样本的重要性,导致一些重要的信息得不到充分利用,可以通过改进抽样方法加快算法的训练效率,采用和树的方法进行样本抽取。将时序差分误差的绝对值|δ|作为优先级值存储于和树的叶子节点,然后根据优先级的和与抽样数获取抽样区间数,并在每个区间随机抽取一个数,从根节点向下搜索对应叶子节点,如此从样本池抽取到的个体即为训练样本。
此外,算法根据ε-greedy策略选择的动作为策略输出,信号灯执行完输出的动作便返回一个奖励值继续下一步迭代。为了平衡算法探索与利用之间的关系,笔者采用了一种基于奖励值序列的自适应探索因子,算法的探索因子依据最近一段连续动作序列获得的平均奖励值确定。探索因子ε取值为:
(10)
(11)

2 强化学习自适应控制策略
为使模型输入准确地表达交通状态,输入状态向量由两部分组成。第1部分表示交叉口当前信号灯状态,为1组one-hot向量。第2部分通过对交叉口各车道进行分段处理以获得各车道状态[11]。对于车道x,其长度为l,将其分成k小段,每小段长度为l/k,其中,记车道x第y小段车辆数为ux,y,车道x第y小段的平均车速为vx,y,所以交叉口各车道状态为(u1,1,v1,1,…,ux,y,vx,y,…,ue,k,ve,k),其中e为交叉口车道数。因此,文中方法状态向量长度为2ek+|P|,|P|为交叉口相位数。
2.1 强化学习自适应信号控制模式
2.1.1 定周期自适应控制
定周期自适应控制是强化学习自适应控制中的一种模式。该模式计算出最佳周期时间,给定统一的最小绿灯时间和最大绿灯时间,输入交叉口交通状态,输出下一周期的相位方案。定周期控制每隔最佳周期采集一次交通状态,输出信号配时方案,但是该模式下动作空间随着相位的增加而指数级扩大,只适合两相位的小型交叉口。
2.1.2 固定步长动作控制
给定最小绿灯时间gmin,智能体每隔时间步长Δt对交通状态进行一次采集作为深度Q神经网络的输入,输出n个动作(对应n个相位)的Q值,选择最大Q值对应的相位,当选择的相位与当前运行相位一致时,在当前相位运行时间步长Δt,当选择的相位与当前运行相位不一致时,运行黄灯时间b秒后在新相位上运行Δt-b秒。然后再次采集环境的状态值,输入神经网络,确定下一时间步长Δt的相位动作。信号机每隔固定时间步长Δt对相位进行一次决策。固定步长动作控制模式中,交通状态采集间隔受最小绿灯时间gmin约束,Δt满足约束为:
Δt≥gmin+b
(12)
2.1.3 不定步长动作控制
给定最小绿灯时间gmin,首先根据实用信号周期公式计算最小周期时间为:
(13)
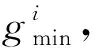
(14)
智能体根据当前输入的状态向量输出下一相位动作at,所以下一相位pt为:
(15)
绿灯时间gpt为:
(16)
在相位pt运行一个绿灯持续时间gpt后,环境将状态反馈给智能体,获取下一个相位pt′及绿灯持续时间gpt′。
2.2 奖励函数
排队长度是评价交叉口运行效率的一个重要指标,不同于定时控制,在强化学习自适应交通控制中,信号控制机频繁地切换相位也能降低交叉口的排队长度,所以在以排队长度作为奖励函数时往往需要考虑相位的切换。以各相位对应车道的最大空间占有率之和为优化目标可以解决此问题,降低交叉口各相位的空间占有率等价于路网流量输入一定的前提下,使交叉口各相位滞留的车辆最少。基于空间占有率的奖励函数在t时刻得到的奖励值Rt为:
(17)
其中:
(18)
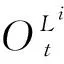
2.3 训练迭代过程
研究的城市交叉口有4个相位且流量较大,不适合采用定周期自适应控制模式。不定步长动作控制和固定步长动作控制分别对应不同的训练迭代流程。固定步长动作的训练迭代流程为:
Step 1总迭代次数为T,初始化当前迭代次数t=0,神经网络训练间隔ttrain,目标神经网络更新间隔ttarget,训练选取样本数为batch_size。
Step 2获取当前交通状态st,神经网络输出各相位对应的Q值,选择最大Q值对应的相位at。

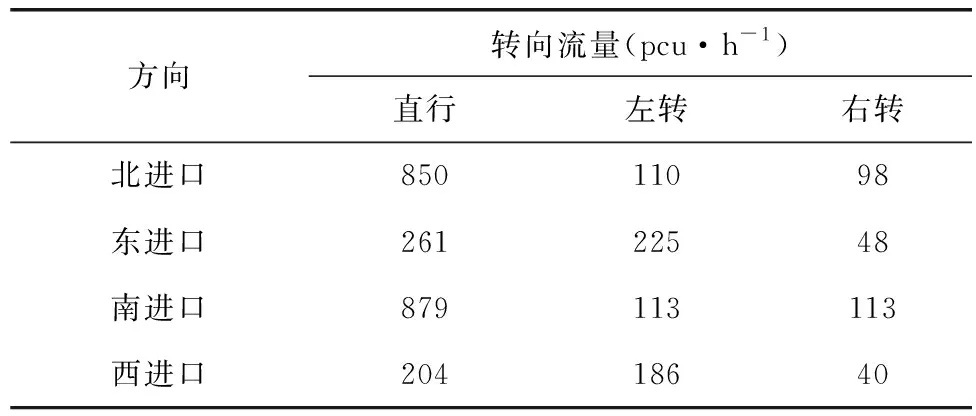
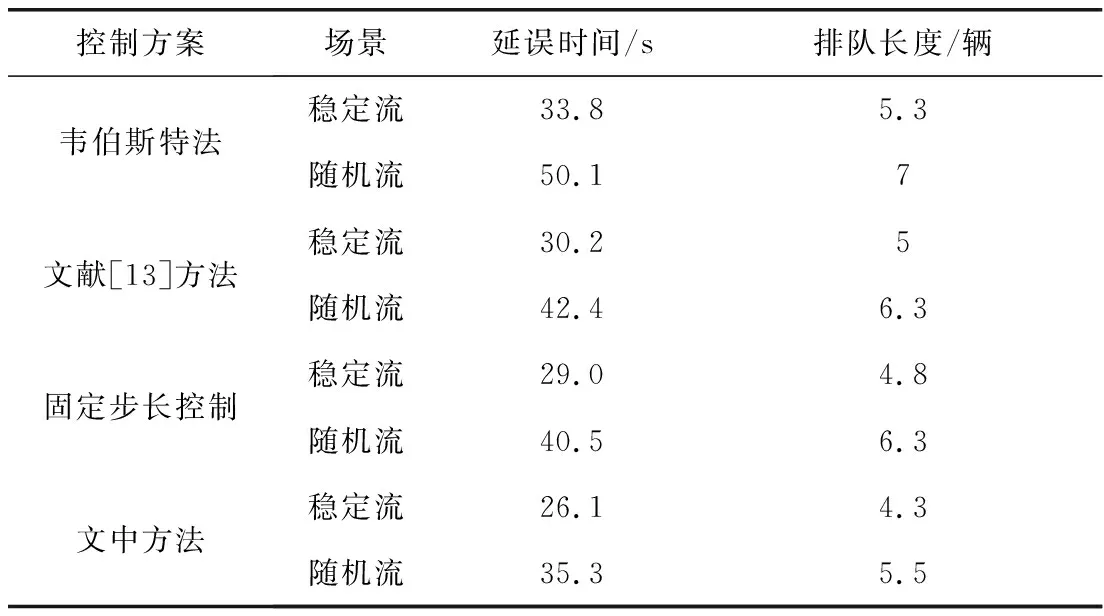
Step 5当t Step 6当t Step 7若t 不定步长动作的训练迭代流程为: Step 1仿真总时长为M,初始化当前迭代次数t=0,神经网络训练间隔ttrain,目标神经网络更新间隔ttarget。 Step 2获取当前交通状态st,神经网络输出各相位动作对应的Q值,选择最大Q值对应的动作at,根据at确定下一相位pt和下一相位绿灯时间gpt。 Step 5当前仿真时间m Step 6当前仿真时间m Step 7若当前仿真时间m Sumo是一个开源的、空间上连续、时间上离散的微观交通仿真软件[12],使用Sumo对兴中大道与松苑路交叉口(交叉口渠化如图1)的交通信号控制进行研究,该交叉口一共有4个相位(图2)。交叉口流量见表1。 图1 交叉口渠化Fig. 1 Channelization of the intersection 图2 交叉口相位相序Fig. 2 Phase sequence of the intersection 表1 交叉口流量Table 1 Traffic flow of the intersection 表2 超参数设置Table 2 Hyperparameters setting 分别在稳定流和随机流的场景下进行仿真训练,一共仿真训练60回合,每回合仿真运行25 000 s。其中随机流服从均值为稳定流交通量的二项分布,各车道每秒以相应概率输入车辆进行仿真。 为验证文中方法的收敛性,将笔者方法与原D3QN算法进行收敛性对比,图3为2种算法在稳定流场景下每回合的奖励值变化,图4为2种算法在随机流场景下每回合的奖励值变化。从图4和图5可知,改进的D3QN算法收敛性优于原D3QN算法。 图3 稳定流下的奖励值Fig. 3 Rewards under stable flow 图4 随机流下的奖励值Fig. 4 Rewards under stochastic flow 由于已有的强化学习自适应控制方法多采用固定步长动作模式,在强化学习固定步长动作模式中,时间步长Δt不应过长,考虑到最小绿灯时间,分别取Δt为8、9、10 s,仿真结果图5表明在固定步长动作控制模式中,时间步长Δt为8 s时控制效果最优,更高的交通状态采集频率对应更好的信号控制效果。不定步长动作模式各个相位绿灯时间取值范围如表3。 表3 各相位绿灯时间取值范围Table 3 Value range of green light time of each phase 图5 不同时间步长控制延误时间Fig. 5 Control delay time with different time steps 为进一步验证文中方法的效果,将文中方法与韦伯斯特法、固定步长控制、文献[13]方法进行对比,并使用不同的随机数种子进行仿真取平均值,采集连续1 h的延误时间和排队长度。表4为4种控制方法在稳定流和随机流场景下的延误时间和排队长度,显然,稳定流场景下的延误时间和排队长度均优于随机流场景。两种场景中,笔者方法均能获得最优控制效果,与其他3种方法相比,延误时间分别平均降低了26.2%、15.2%、11.4%,排队长度分别平均降低了20.1%、13.3%、11.6%。 表4 控制效果对比Table 4 Comparison of contral effect 提出了一种改进的D3QN自适应交通信号控制方法,使用不定步长动作控制模式同时输出相位和绿灯时间,构造了以空间占有率为优化目标的奖励函数。相比于已有方法,文中方法的收敛性得到了提升,延误时间和排队长度得到了优化。 此次研究的对象是混合车流在单交叉口的自适应控制,下一步研究可以区域路网为研究对象,综合自适应控制与绿波协调控制,结合车路协同技术,对路网的交通状态进行优化并对其进行评价;也可以某一类车辆如公交车辆为研究对象进行公交优先控制以期改善公交信号控制效果,提高城市公共交通运行效率。3 算例分析
3.1 实验准备



3.2 实验结果




4 结 语
猜你喜欢
作文周刊·小学一年级版(2020年40期)2020-10-19 04:42:20电子测试(2018年15期)2018-09-26 06:01:04重庆交通大学学报(自然科学版)(2017年3期)2017-05-17 03:37:32娃娃乐园·3-7岁综合智能(2016年4期)2016-10-24 02:47:36自动化学报(2016年8期)2016-04-16 03:38:51中国房地产业(2016年2期)2016-03-01 01:25:37西北工业大学学报(2015年1期)2016-01-19 03:29:56哈尔滨师范大学自然科学学报(2015年6期)2015-04-23 08:20:35系统工程学报(2015年3期)2015-02-28 19:54:01河南科技(2014年14期)2014-02-27 14:12:02
