
地震动强度参数估计的可解释性与不确定度机器学习模型
2022-08-31 13:07陈蒙王华
地球物理学报 2022年9期
陈蒙,王华,2*
1 电子科技大学资源与环境学院,成都 611731 2 电子科技大学(深圳)高等研究院,广东深圳 518110
0 引言
地震引起的强地面运动会造成建筑结构破坏和倒塌,是震后人员伤亡和财产损失的主要原因,同时还会诱发滑坡等次生灾害.地震发生后,快速估算地震动强度参数(峰值加速度PGA、峰值速度PGV、峰值位移PGD和加速度反应谱PSA)得到地震动图(ShakeMap)(Wald et al., 2005; 李俊等, 2010; 陈鲲等, 2010; 刘军等, 2016),可用于评估震后损失,指导应急救援和灾后重建工作.地震发生前,分析潜在震源区可能产生地震动强度,可获得地震动参数区划图或地震危险性图, 以作为房屋保险等的重要参考,更有助于国土空间规划和重大工程项目(例如核电站、水库大坝、跨海大桥等)的设计和建设.
计算(或预测)地震动强度参数的方法主要有三种:数值模拟、地震动预测方程(Ground Motion Prediction Equation,也称作地震动衰减关系)和机器学习.常用的数值模拟方法包括有限差分法(Graves, 1998; Kozdon et al., 2013; Zhang et al., 2014)、有限元法(Bielak et al., 2005; Duan, 2010)、谱元法(Komatitsch et al., 2004; Lee et al., 2009)、有限体积法(Benjemaa et al., 2009)以及这些方法的结合(Meng and Wang, 2018; Wu et al., 2018).数值方法可以模拟断层破裂和波场传播的全过程,具有明确的物理意义.但是准确的地震动模拟需要精确的震源信息和地下结构速度模型,并且计算量巨大.地震动预测方程(Boore et al., 2014; Campbell and Bozorgnia, 2014; Chiou and Youngs, 2014; Idriss, 2014)形式明确、计算速度快,是地震动图和地震危险性分析中常用的方法.但是现代地震动预测方程复杂(Abrahamson et al., 2014; Campbell amd Bozorgnia, 2014),函数形式和特征变量的选取没有统一标准,依赖研究人员的主观性,且易忽略各特征之间的非线性耦合作用.
随着人工智能技术的发展,用于预测地震动强度参数的机器学习方法受到越来越多的重视,相关方法主要可以分为两类:
(1)基于纯数据驱动演化的预测模型
(2)基于监督学习回归模型的地震动强度参数预测
主要是通过多种地震记录信息,训练得到可用于预测地震动强度参数的机器学习模型.例如Arjun和Kumar(2009)利用单隐藏层前馈神经网络和84456条K-NET记录到的强震动数据,训练出了适合日本地区的PGA预测机器学习模型.Alavi和Gandomi(2011)采用模拟退火算法优化用于地震动强度参数预测的神经网络,解决了人工神经网络参数学习过程中的局部收敛问题.Ameur等(2018)采用随机自适应模糊神经网络,同时利用模糊逻辑和人工神经网络的优点,提高训练速度,构建了PGA、PGV和PGD预测机器学习模型.Derakhshani和Foruzan(2019)考虑深度学习在模拟复杂非线性关系和自动特征提取方面的优势,采用深度学习模型预测了PGA、PGV和PGD.此外,Wiszniowski(2019)还提出采用可逐步训练的Fahlman级联相关神经网络来构建地震动强度参数预测机器学习模型.Hamze-Ziabari和Bakhshpoori(2018)提出采用以分类与回归树(Classification and Regression Trees, CART)和M5′模型树为基础学习器的集成学习进行地震动强度参数预测.
以上工作存在三方面问题:(1)震后震害概率评估和地震危险性分析是相关工作的关键,除了直接给出地震动强度参数的预测结果,相关结果的不确定度(或置信程度)也尤为重要,而这是决策树、神经网络等单点回归模型所无法实现的;(2)演化建模方法中,为保证方程的合理性,其复杂度受限,导致预测精度欠佳;(3)基于神经网络(特别是深度学习)方法的预测精度高,然而其可解释性饱受地球物理领域学者质疑.针对这些问题,本文拟采用自然梯度提升(NGBoost)算法(Duan et al., 2020) 替代决策树或神经网络模型,通过给出预测结果及置信区间,更好地完成了地震动强度参数预测任务.为解决模型的可解释性问题,本文结合SHAP(SHapley Additive exPlanations)值机器学习解释算法(Lundberg et al., 2020),分析在PGA和PGV预测过程中NGBoost模型的各个输入特征的重要度和它们对模型预测结果的影响,以给出机器学习模型的预测过程.
本文将先介绍训练地震动强度参数预测机器学习模型所使用的强震动数据和数据筛选方法.接着介绍构建概率密度分布预测机器学习模型所使用NGBoost算法原理.之后介绍地震动强度参数预测机器学习模型的训练过程和结果,以及基于SHAP值的机器学习模型解释.最后讨论了和其他地震动强度参数预测机器学习模型的比较,以及对各个输入特征SHAP值变化规律的物理解释.
1 NGA-WEST2强震动数据库和数据筛选
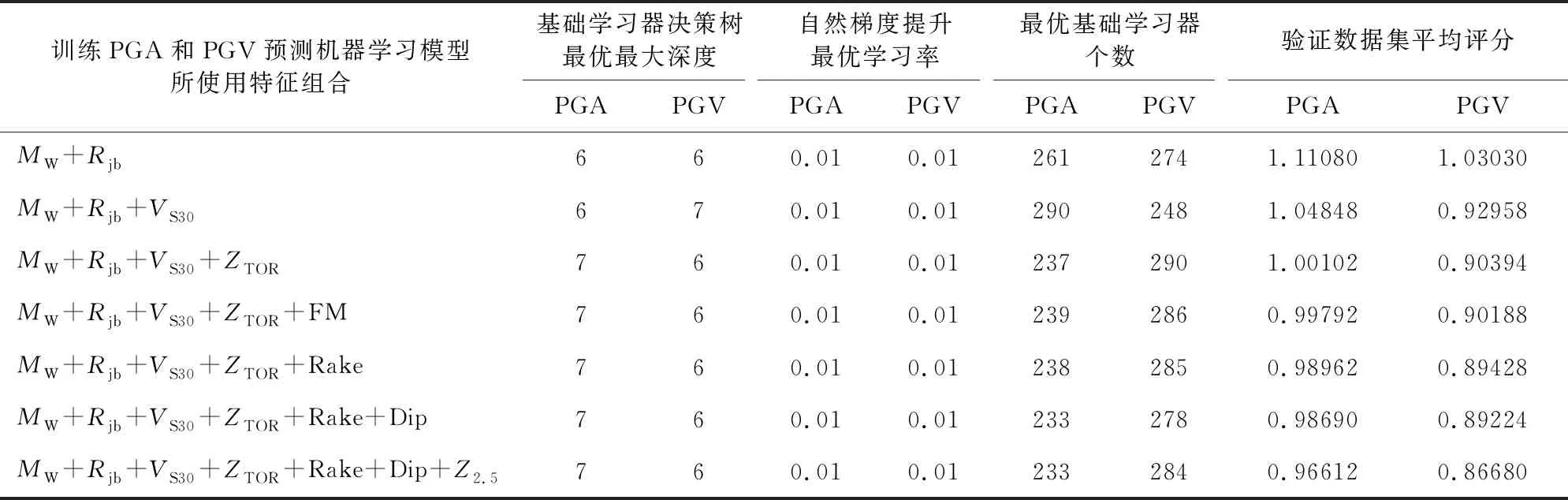
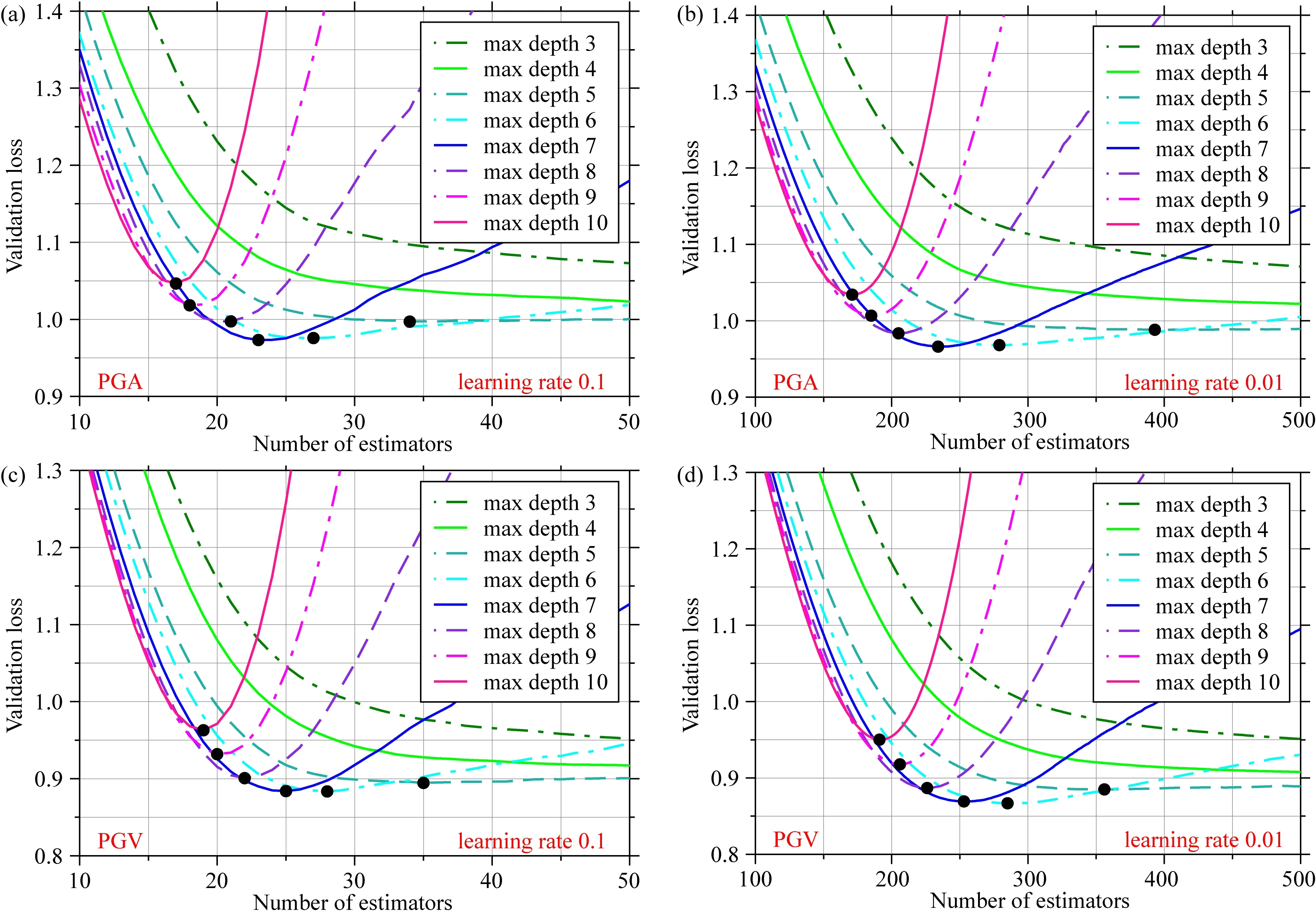
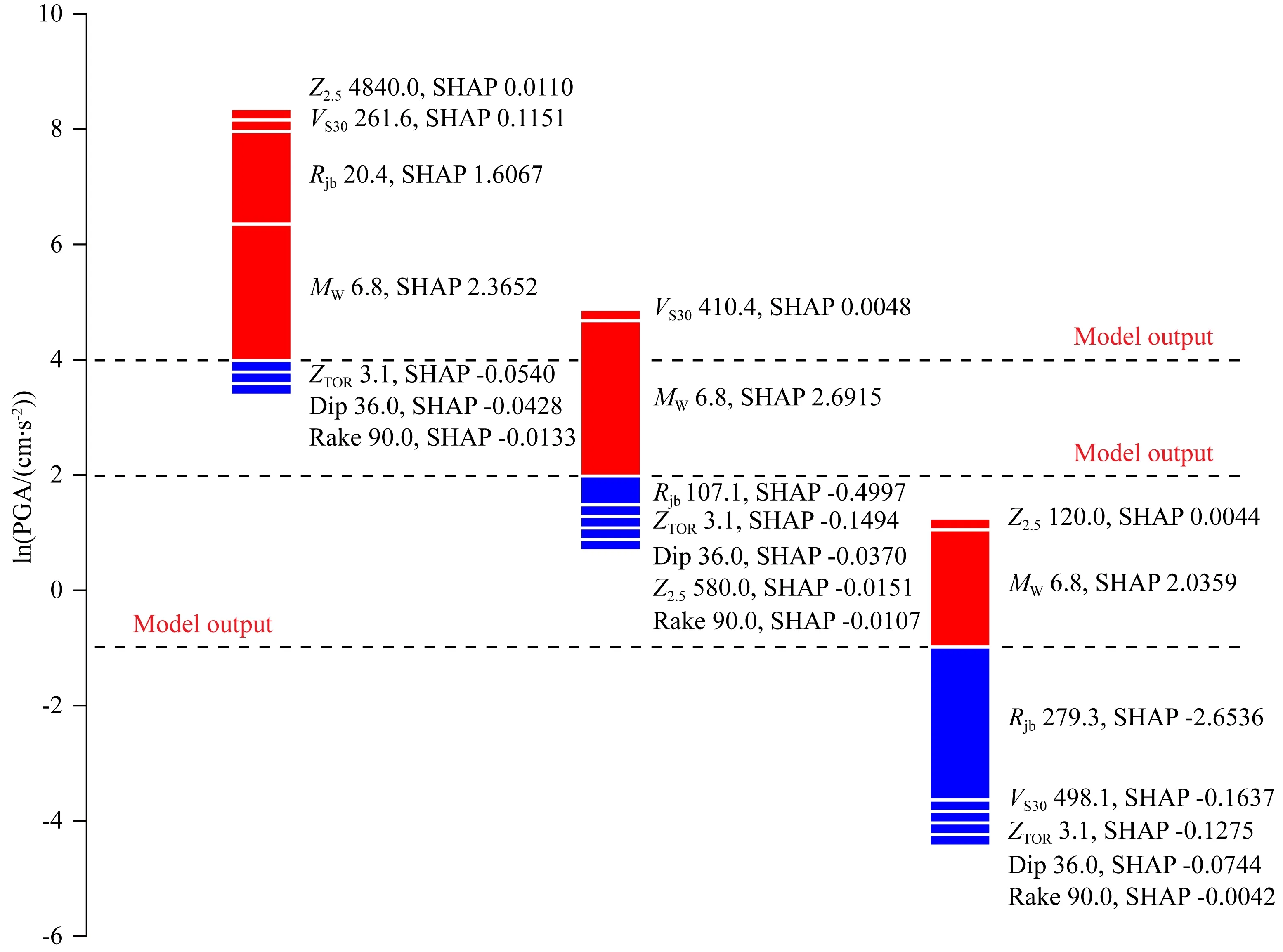
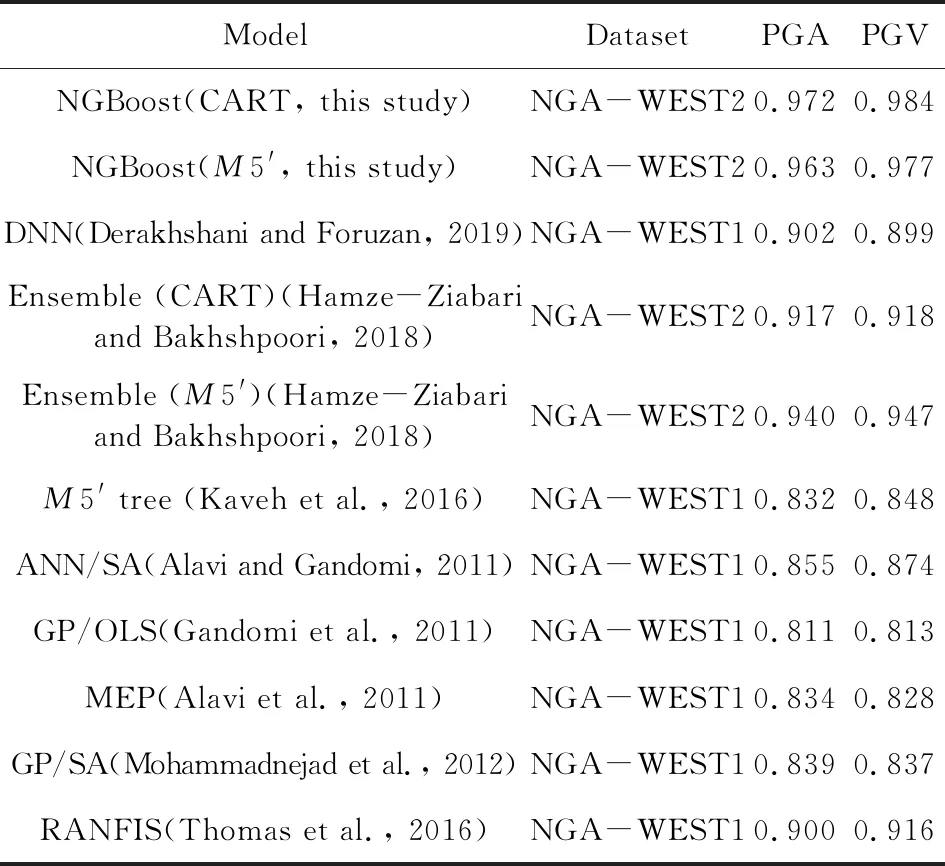
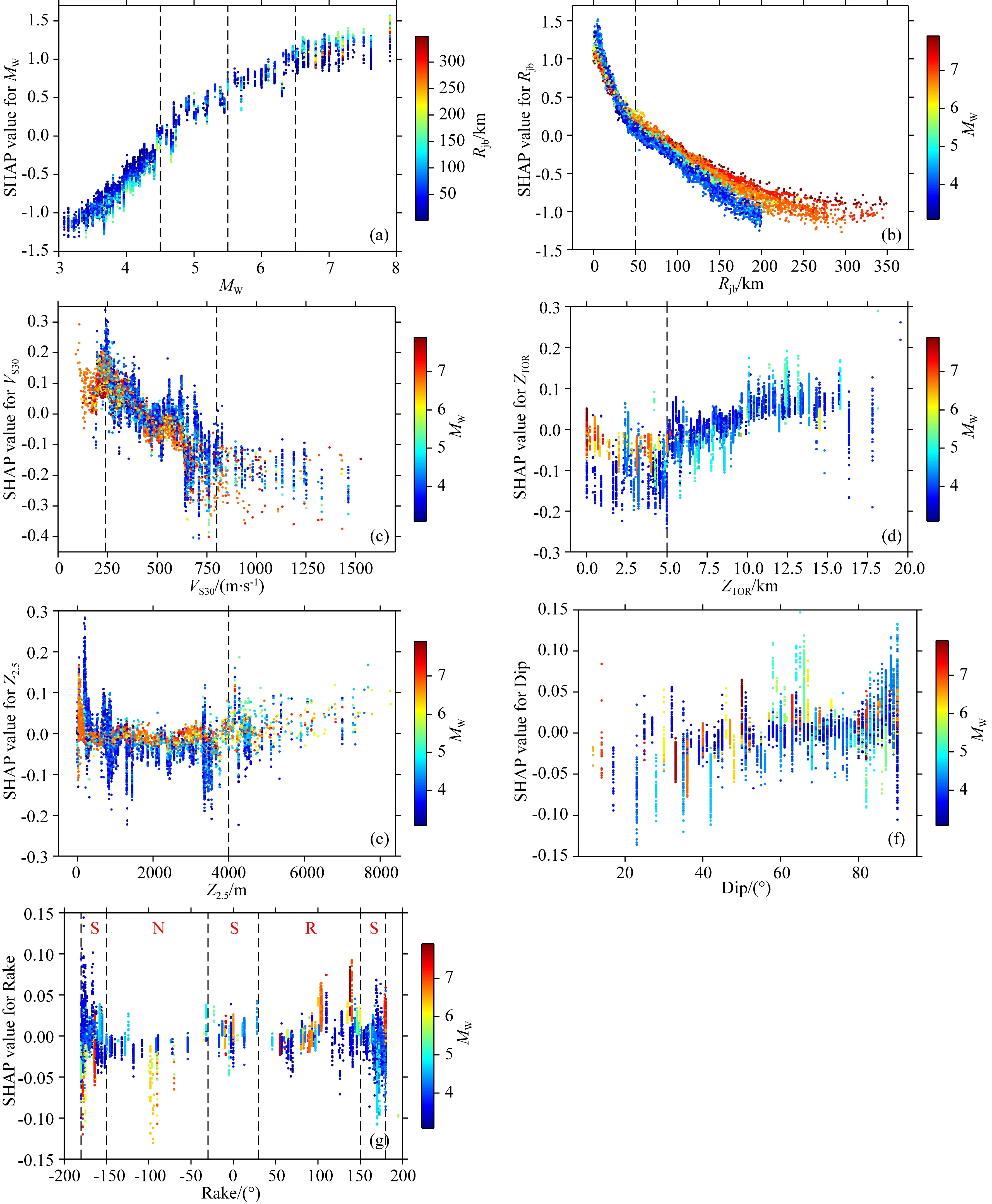
浅部地壳是具有较大破坏力的地震的多发区,为训练出适合活跃构造区浅部地壳地震的地震动强度参数预测机器学习模型,本研究选择采用NGA-WEST2强震动数据库.NGA-WEST2强震动数据库是太平洋地震工程研究中心(Pacific Earthquake Engineering Research Center)为发展适合浅部地壳地震的下一代地震动预测方程而建立的数据库(Bozorgnia et al., 2014),是目前最完备的强震动数据库.2015年1月新修订的NGA-WEST2强震动数据库共收录来自599个地震(包含233个M>5的全球地震和266个3.5 为获得更好的机器学习模型性能,需要对训练数据进行筛选与清洗.参考其他地震动预测方程(Abrahamson et al., 2014; Boore et al., 2014)和地震动强度参数预测机器学习研究,本研究采用如下标准从NGA-WEST2强震动数据库中筛选数据:(1)只选用包含完整元数据信息(震级、震源机制、地下30 m平均S波速度VS30等)的强震动数据;(2)去除S波触发的波形不完整的地震动记录,去除因采样率或增益异常而导致反应谱异常的地震动记录;(3)去除深震和俯冲带地震(参见Abrahamson et al.(2013)表2.1),只选取发生在活动构造区的地壳地震;(4)按照Abrahamson et al.(2013)公式2.1确定不同年代和地区数据选取的最大震中距(见附图A1),去除Joyner-Boore震中距过大的地震记录;(5)去除地下以及两层建筑物以上的强震动记录(参见Boore(2013)表2.1),只选择能够反映自由场地效应的地震记录;(6)由于余震的高频部分比普通地震系统性地低约20%~40%(Boore and Atkinson,1989,1992; Abrahamson and Silva, 2008),故去除余震数据;(7)去除观测记录少于3个的地震记录.最终,选取了282个地震的12107条记录用于机器模型训练.震级分布范围为3.1~7.9,Joyner-Boore断层距分布范围为0.1~348.9 km,VS30分布范围为89.3~2016.1 m·s-1.具体数据分布如图1所示. 自然梯度提升算法(Natural Gradient Boosting,NGBoost)(Duan et al., 2020)是一种新的提升算法,它通过引入自然梯度解决了利用提升算法进行概率密度分布预测的难题.自然梯度代表黎曼空间中的最速下降方向(Amari, 1998).相比普通梯度,自然梯度可以使机器学习过程更加高效稳定(Duan et al., 2020). (1) 图2 用于地震动强度参数预测的NGBoost算法示意图x表示输入特征;y表示观测地震动强度参数;θ(m)、Pθ(m)(y|x)、S(Pθ(m),y)和S(Pθ(m),y)分别表示第m个提升阶段的地震动强度参数概率密度分布的参数向量、地震动强度参数概率密度分布、预测结果评分和评分的自然梯度; m=0为预测参数的初始值;第m个提升阶段的基础学习器f(m)(x)由输入特征x和前一阶段评分的自然梯度(Pθ(m-1),y)训练得到.Fig.2 Block diagram of NGBoost algorithm for ground motion parameters predictionx is input features; y is observed ground motion parameters; θ(m), Pθ(m)(y|x), S(Pθ(m),y) and S(Pθ(m),y) are predicted parameters of probability distributions, probability distributions, scores of probability distribution and natural gradients of scores at the mth upgrading stage, respectively. If m is 0, the predicted parameters are initial values. The base learner f(m)(x) at the mth boosting stage is trained with input features x and natural gradients of scores (Pθ(m-1),y) at the previous boosting stage. 其中f(m)(x)为第m个提升段使用的基础学习器,ρ(m)为学习器比例因子,η为加权系数.初始值(θ(0))利用M个基础学习器经过M个提升阶段的M次修正后得到要预测的概率密度分布的参数向量(θ(M)).训练中,后续基础学习器拟合之前基础学习器和学习目标间的残差.训练完成后,各学习器按比例因子ρ(m)缩放.参数θ的类型取决于概率密度分布(如采用正态分布表示各样本预测结果时,参数θ=(μ,logσ)).通过评分标准S比较预测概率分布和观测数据以表示预测结果和真实数据间的差异来构建损失函数.NGBoost算法的详细描述参见Duan等(2020)算法1.相比于同样可进行概率密度分布预测的贝叶斯深度学习方法(Neal, 2012),NGBoost算法计算量更小. 本文利用机器学习工具Scikit-Learn将数据随机分成训练集(80%)和测试集(20%).分别来训练和验证评价机器学习模型.输入特征的选取是机器学习模型性能的关键,但对于地震动强度参数预测研究目前尚缺乏统一标准.本研究测试了不同输入特征组合.首先选取矩震级MW、Joyner-Boore断层距Rjb、地下30 m平均S波速度VS30、断层类型FM和断层顶部距地表距离ZTOR等最常用的特征(Alavi and Gandomi, 2011; Derras et al., 2014; Thomas et al., 2016; Ameur et al., 2018; Dhanya and Raghukanth, 2018; Hamze-Ziabari and Bakhshpoori, 2018; Akhani et al., 2019; Wiszniowski, 2019)作为输入特征.考虑到断层类型FM是依据滑动角Rake定义(Boore et al., 2014),同样测试了滑动角Rake和断层倾角Dip作为输入特征的情况.此外本文还测试了Z2.5(即S波速度达到2.5 km·s-1时的深度)作为输入特征时的模型表现,该特征曾用于模拟浅层沉积物放大效应之外的盆地放大效应(Campbell and Bozorgnia, 2014),但相比于其他特征属性,Z2.5值的缺失率过高(24%),故使用平均值代替缺失内容.应力降、断层破裂速度和方向等数据缺失率过高(约70%~90%),没有被选作输入特征.Joyner-Boore断层距(Rjb)隐含了上下盘效应(Boore et al., 2014),因而没有增加其他输入特征模拟上下盘效应.最终,本文选择以下7种特征组合作为模型输入: (1) 矩震级MW+Joyner-Boore断层距Rjb; (2) 矩震级MW+ Joyner-Boore断层距Rjb+地下30 m平均S波速度VS30; (3) 矩震级MW+ Joyner-Boore断层距Rjb+地下30 m平均S波速度VS30+断层顶部深度ZTOR; (4) 矩震级MW+ Joyner-Boore断层距Rjb+地下30 m平均S波速度VS30+断层顶部深度ZTOR+断层类型FM; (5) 矩震级MW+ Joyner-Boore断层距Rjb+地下30 m平均S波速度VS30+断层顶部深度ZTOR+滑动角Rake; (6) 矩震级MW+ Joyner-Boore断层距Rjb+地下30 m平均S波速度VS30+断层顶部深度ZTOR+滑动角Rake+断层倾角Dip; (7) 矩震级MW+ Joyner-Boore断层距Rjb+地下30 m平均S波速度VS30+断层顶部深度ZTOR+滑动角Rake+断层倾角Dip+VS达到2.5 km·s-1的深度Z2.5. 由于NGBoost的基础学习器CART对于特征缩放不敏感,故没有对特征进行线性函数归一化和标准化.本研究使用K-折交叉验证和网格搜索确定最优的超参数:基础学习器最大深度(max depth)、学习率(learning rate)和基础学习器个数(number of estimators).基础学习器最大深度取值在3~10;学习率取Duan等(2020)的推荐值0.1和0.01.基础学习器个数统一取为4000次,选取使得验证数据集平均评分最小的基础学习器个数.K-折交叉验证实验中,训练数据集被随机分成5组,当其中1组用于验证时,剩余4组用于训练.完成训练后,取使5次验证误差均值最小的模型训练整个训练集数据.表1展示了选取不同特征组合作为输入时,最佳超参数下的模型表现.可见:(1)选用越多的特征获得的机器学习模型性能越优;(2)使用滑动角作为输入特征的效果优于使用断层类型;(3)当基础学习器最大深度分别取7和6,学习率取0.01,基础学习器个数分别取233和284时,PGA和PGV预测机器学习模型性能达到最优.图3进一步展示了当使用所有特征(MW+Rjb+VS30+ZTOR+Rake+Dip+Z2.5)时,验证数据集的平均评分随基础学习器最大深度和学习率的变化.最终我们将所有特征属性作为输入,利用验证得到的最佳超参数训练PGA和PGV预测模型. 图4显示了模型预测结果和实际结果比较,可以看出:(1)模型表现良好,预测结果在训练集和测试集上都与真实值接近;(2)基于NGBoost算法的地震动强度参数预测机器学习模型具有良好的泛化能力(训练集和测试集的预测表现接近).为进一步分析机器学习模型的性能,计算了机器学习模型预测值与实际观测值的比值、相关系数R、平均绝对误差MAE和均方根误差RMSE,并与其他地震动强度参数预测机器学习研究进行了比较.测试集结果显示:(1)PGA和PGV的预测值与观测值间误差在±30%以内的比例分别约为70%和80%(见图5),优于Derakhshani和Foruzan(2019)利用深度学习和NGA-WEST2强震动数据库训练得到的模型(原文分别为65%和60%);(2)PGA和PGV预测值与实测值的相关系数分别为0.960和0.976,平均绝对误差分别为0.511和0.451,均方根误差分别为0.655和0.585,预测结果的相关系数均优于Derakhshani和Foruzan(2019)深度学习的结果(表2为本模型的性能,表3为Derakhshani和Foruzan(2019)论文的结果). 表1 对于PGA和PGV预测,不同输入特征组合对应的最佳超参数和验证数据集平均评分Table 1 For prediction of PGA and PGV, the best hyperparameters and corresponding average scores of validation dataset for different set of input features 图3 对于PGA和PGV预测,当学习率(0.1和0.01)和基础学习器最大深度(3~10)取不同值时,验证数据集平均评分随基础学习器个数的变化.训练机器学习模型预测PGA和PGV时使用了所有特征属性(MW+Rjb+VS30+ZTOR+Rake+Dip+Z2.5)图中黑点为基础学习器最大深度取不同值的验证数据集的最小平均评分.Fig.3 For prediction of PGA and PGV, the variations of average scores of validation dataset with the number of estimators for different learning rate (0.1 and 0.01) and max depth of estimator (3~10). All the input features (MW+Rjb+VS30+ZTOR+Rake+Dip+Z2.5) are used when training these models for prediction of PGA and PGVThe black dots represent minimum average scores of validation dataset for different max depth of estimator. 图4 机器学习模型预测的PGA和PGV与实际观测值的比较. 模型的训练集(80%)和测试集(20%)从NGA-WEST2强震动数据库中随机选取Fig.4 Comparisons between the machine learning model for predicted and observed PGA and PGV. The training (80%) and testing (20%) dataset are randomly selected from NGA-WEST2 strong motion dataset 图5 机器学习模型预测PGA和PGV与观测值的比值的统计直方图. 模型的训练集(80%)和测试集(20%)从NGA-WEST2强震动数据库中随机选取Fig.5 Histograms of ratios of machine learning model for predicted and observed PGA and PGV. The training (80%) and testing (20%) dataset are randomly selected from NGA-WEST2 strong motion dataset 表2 NGBoost算法训练出的PGA和PGV预测机器学习模型的性能指标. 模型的训练集(80%)和测试集(20%)从NGA-WEST2强震动数据库中随机选取Table 2 Performance of the trained NGBoost algorithm for PGA and PGV prediction. The training (80%) and testing (20%) dataset are randomly selected from NGA-WEST2 strong motion dataset 表3 基于深度学习的PGA和PGV预测结果指标(Derakhshani and Foruzan,2019)Table 3 Performance of PGA and PGV prediction by a Deep-Learning method (Derakhshani and Foruzan, 2019) 相比其他地震动强度参数预测机器学习模型,基于NGBoost算法的机器学习模型不仅可以给出准确预测值而且可以给出预测结果的概率密度分布.图6展示了对于2004年美国加州ParkfieldMW6.0地震(EQID=1018)、2009年美国加州San BernardinoMW4.45地震(EQID=1018)和2007年日本Chuetsu-okiMW6.8地震(EQID=278),机器学习模型预测的PGA和PGV的概率密度分布.约84%的实际观测值位于机器学习模型预测的85%置信区间内,说明机器学习模型可以很好地预测地震动的概率密度分布,且对于近场和远场都有很好预测. 图6 基于NGBoost机器学习模型的PGA和PGV的概率密度分布预测. 数据为2004年美国加州Parkfield MW6.0地震(EQID=1018)、2009年美国加州San Bernardino MW4.45地震(EQID=1018)和2007年日本Chuetsu-oki MW6.8地震(EQID=278)图中黑点和青点分别为训练集和测试集中的观测值. 蓝线表示机器学习模型预测值,其中绿线表示85%置信区间. 色标表示预测的概率密度分布.Fig.6 The predicted probability density distributions by the proposed NGBoost model. Dataset are the 2004 Parkfield MW6.0 earthquake, 2009 San Bernardino MW4.45 earthquake and 2007 Chuetsu-oki MW6.8 earthquakeThe black and cyan dots are the observations in the training and testing datasets, respectively. The blue lines are the predicted values by machine learning models where the green lines indicate the 85% confidence intervals. The predicted probability densities are color-coded shown in the color bar. 复杂模型(如深度学习)在地震动参数预测任务中给出了相当准确的预测结果(Derakhshani and Foruzan, 2019),但地震专家却难以分析这些复杂预测过程与客观事实的相符程度.事实上,以CART作为基础学习器的集成学习模型在训练完成后,可通过基尼指数(Gini importance)或者Saabas 值等方式来计算特征对模型输出的全局重要性(由于篇幅的限制本文不展开讨论).但仍难以给出局部样本对模型输出的影响,且无法量化不同特征之间的相关性(相互耦合),不足以为预测过程给出确切的解释. 为理解模型对地震动强度参数预测的机理,我们引入了一种统一的解释框架:SHAP(SHapley Additive exPlanations)(Lundberg and Lee, 2017; Lundberg et al., 2019, 2020).对于NGBoost这类决策树集成模型,SHAP框架结合了局部解释方法LIME(Local Interpretable Model-agnostic Explanations)(Ribeiro et al., 2016)和经典Shapley值估计方法(Shapley, 1953).基于LIME方法,SHAP框架利用若干个线性模型对待解释复杂模型进行逼近,并逐个计算这些线性模型中各个特征的Shapley重要性估计值,以此定量表示预测过程中,每个特征对预测的贡献.对于带有M个特征的简化输入x′,贡献值g(x′)定义如式(2),其中,φ0为平均贡献值,φj为特征j的Shapley值.当令φ0为模型输出的期望E(f(x))时,SHAP输出将近似等于模型的真实输出.SHAP框架的详细介绍见Lundberg和Lee(2017)、Lundberg et al.(2019,2020),限于篇幅,不再赘述. (2) 以2007年日本Chuetsu-okiMW6.8地震3条记录(Joyner-Boore断层距分别为20.4、107.1和279.3 km)为例,本文利用SHAP框架对PGA预测结果进行初步解释.3条记录中,各个输入特征的SHAP解释结果如图7所示.可以看出:(1)矩震级MW和Rjb距离对PGA预测贡献远大于其他特征(SHAP值的绝对值大);(2)Rjb距离对PGA的SHAP值(即贡献值)随距离增大而逐渐减少,当Rjb距离较大时,其对于PGA预测的贡献为负.这些与地震学理论相符,证实了SHAP值机器学习解释算法的有效性. 为进一步分析各个特征(MW、Rjb、VS30、ZTOR、Rake、Dip和Z2.5)在整体上如何影响PGA和PGV预测,我们计算了所有地震动记录的各特征对PGA和PGV的SHAP值,并绘制了SHAP值摘要图(图8).在SHAP值摘要图中,各个特征按重要度(SHAP值绝对值的平均值)由上至下排列.对于图中的每一个特征,每个点表示每一次预测该特征的SHAP值.所有预测按SHAP值大小沿X轴排列,并在出现相同值时沿Y轴堆叠以显示数据分布.数据点颜色表示输入特征值的大小.如果颜色随SHAP值连续变化说明输入特征对预测的贡献随输入特征值的大小连续变化. 图7 用于PGA预测的不同输入特征的SHAP值统计结果(以2007年日本Chuetsu-oki MW6.8地震的三条Joyner-Boore震中距Rjb为20.4、107.1和279.3 km记录为例)图中虚线标注了对于不同记录的机器学习模型预测值,柱状图中各部分的颜色长度表示SHAP值的大小,颜色表示SHAP值的正负(红色为正,蓝色为负).Fig.7 The computed SHAP values of different input features for three strong motion records (the 2007 Chuetsu-oki MW6.8 earthquake with distances at 20.4, 107.1 and 279.3 km)The dashed lines are the predicted PGAs by trained machine learning model where the height of each bar indicates the magnitudes of SHAP values. The color represents the signs of SHAP values (red color indicates positive value, and blue color indicates negative value). 图8 对于PGA和PGV预测,所有输入特征的SHAP值摘要图图中各个特征后的数值表示特征的重要度,每个点表示每次预测不同特征的SHAP值,颜色代表特征的值.这些点按SHAP值大小沿X轴排列,并在出现相同值时沿Y轴堆叠以显示数据分布.Fig.8 For prediction of PGA and PGV, the SHAP summary plot of all input featuresThe number behind input features are the feature importance. The dots are SHAP values of different features for different predictions. The color indicates the value of input feature. These points are plotted horizontally, and stacking vertically when they have the same SHAP value to show the distribution of data. SHAP值摘要图展示了一些工程地震学中常见可以说明机器学习模型合理性的现象:矩震级MW的特征重要性随震级增大而增大,较高的矩震级MW普遍带来较大的正向贡献,而当矩震级较低时,其对地震动参数的影响则不如高值那样稳定(蓝色范围明显宽于红色范围);Rjb距离、VS30的特征重要性则随特征值增大而减小,且较低的Rjb、VS30对预测结果的贡献值不稳定(蓝色范围明显宽于其他颜色).此外,图中还揭示出一些可能被忽视的现象:(1)Rjb对PGA预测的重要度低于其对PGV的重要度;(2)断层顶部深度ZTOR的SHAP值在PGA和PGV的预测结果解释中存在“长尾”现象(见ZTOR红色点),这意味着模型认为较大地震会使得PGA和PGV的预测结果更大. 基于NGA-WEST2强震动数据库,本文利用NGBoost算法训练出了可用于PGA和PGV概率密度分布预测的机器学习模型.考虑到平均绝对误差和均方根误差受单位影响较大,本研究采用预测结果与实际观测值(包括测试集和训练集)的相关系数作为评价指标,以便于同已有研究进行比较. 与深度学习(Derakhshani and Foruzan, 2019)、以CART为基础学习器的集成学习(Hamze-Ziabari and Bakhshpoori, 2018)、M5′模型树(Kaveh et al., 2016)、以M5′模型树为基础学习器的集成学习(Hamze-Ziabari and Bakhshpoori, 2018)、单隐藏层神经网络(Alavi and Gandomi, 2011)、最小二乘和遗传编程混合算法(Gandomi et al., 2011)、多表达式编程(Alavi et al., 2011)、模拟退火和遗传编程混合算法(Mohammadnejad et al., 2012)、随机自适应神经网络模糊推理系统(Thomas et al., 2016)等诸多方法相比,NGBoost算法的预测值与观测值具有更高的相关系数(表4).表中大部分研究采用了和本研究类似的数据筛选方法,并且NGA-WEST1强震动数据库包含在NGA-WEST2强震动数据库之中.因此,数据对于比较结果的影响可以忽略不计. 表4 不同研究机器学习模型预测PGA和PGV与观测值的相关系数(R)的比较 此外,Hamze-Ziabari和Bakhshpoori(2018)指出,使用M5′模型树做基础学习器的集成学习算法表现优于以CART为基础学习器的集成学习.相比于CART,M5′模型树的叶节点使用线性模型,并且经过剪枝和平滑处理后,单棵M5′模型树的性能更优.本研究对原有NGBoost算法进行改进,使用M5′模型树作为基础学习器进行了相同的实验.图A2展示了使用M5′模型树和CART作为基础学习器构建NGBoost模型,对2004年美国加州ParkfieldMW6.0地震、2009年美国加州San BernardinoMW4.45地震和2007年日本Chuetsu-okiMW6.8地震预测结果的比较.结合表4所示,两者预测结果接近,表明M5′模型树并不能显著提升NGBoost算法性能. 基于NGBoost算法的地震动强度参数预测机器学习模型不但具有高的预测精度,而且通过计算SHAP值还可以从数据角度分析输入特征如何影响地震动强度参数预测.图9和图10分别给出所建立的机器学习模型对PGA和PGV预测时各输入特征与其对应的SHAP值之间的关系. (1)图9a和图10a中,随着矩震级MW增加其对应的SHAP值呈近似分段线性增加(虚线为分段处),且增加的幅度逐渐减少.对近场(<2 km)PGA预测(图A3a),MW对地震动强度预测的贡献值不随MW值增大而增大,表明PGA随MW的变化是非线性的,存在“近震饱和”现象.“近震饱和”现象是由于对于近场记录,断层破裂面上每个子断层产生的地震波的持续时间都较短,并且到达观测点的时间也不同,很难线性叠加产生较大振幅(Yenier and Atkinson, 2014).这些分段现象也说明了在某些地震动预测方程中震级项使用分段线性函数的合理性(Campbell and Bozorgnia, 2014). 图9 PGA预测过程中各个输入特征的SHAP值依赖图.SHAP值依赖图展示了输入特征值变化对模型预测带来的影响横坐标表示各个特征的值,纵坐标表示各个特征的SHAP值.颜色表示对所考察特征依赖程度最大的其他特征的取值.(g)中的N、S和R分别代表正断层(-150° 图10 PGV预测过程中各个输入特征的SHAP值依赖图.SHAP值依赖图展示了输入特征变化如何影响模型预测横坐标表示各个特征的值,纵坐标表示各个特征的SHAP值.颜色表示对探究特征影响最大的另一个特征的值(g)中的N、S和R分别代表正断层(-150° (2)随着Rjb距离逐渐增大,Rjb的贡献值不断减小,并在约45和150 km后两次出现减小速率放缓(图9b和图10b).45 km后的减小速率放缓可能与面波或Lg波出现相关.150 km后出现的减小速率放缓可能与S波的莫霍面反射波(SmS波)出现相关(Zhu et al., 2019). (3)VS30的SHAP值并非一直随VS30值的减小而增加(图9c和图10c).当VS30值低于240 m·s-1(图中虚线对应的值)时,其对应的SHAP值会出现降低,且SHAP值降低的点MW值较高.这与Aboye等(2011)利用1D等效线性模型计算出的场地放大系数随VS30值的变化规律是一致的,可能是由于地震动强度过高时出现的场地非线性效应所致. 除了分析主要输入特征影响外,ZTOR、Z2.5、Dip和Rake等次重要特征的SHAP值依赖图也展示出了一些有趣的现象.例如对于活跃构造区地壳地震,断层较浅时(ZTOR<~5 km)的ZTOR的SHAP值整体上低于断层较深时的值(图9d和图10d).这说明浅层的软弱带破裂受速度强化控制,滑动弱化距离更大,需要更多的破裂能,通常会导致较低的破裂速度和滑动速率,进而导致较低的PGA和PGV(Somerville and Pitarka, 2006).当断层较浅时,ZTOR的SHAP值随ZTOR值增大而减小(图9d和图10d),可能是由于发震深度增加导致的几何衰减的增大所致.当断层较深时,ZTOR的SHAP值随ZTOR值增大而增大(图9d和图10d),可能是由于发震深度增加导致的地震应力降的增加或品质因子Q的增大所致(Abercrombie et al., 2021).当Z2.5>~3 km时,对于PGA和PGV预测,Z2.5的SHAP值均随Z2.5值的增大而增大(图9e和图10e),此时Z2.5主要反映3D盆地效应,对PGA和PGV都是放大作用(Campbell and Bozorgnia, 2013).当Z2.5<~1 km时,对于PGA预测,Z2.5的SHAP值随Z2.5值的增大而减小(图9e),而对于PGV预测,Z2.5的SHAP值随Z2.5值的增大而增大(图10e).此时,Z2.5主要反映浅层沉积物效应(Campbell and Bozorgnia, 2013).浅层厚沉积物的自振频率低,离频率较低的速度的频率更近,离频率较高的加速度的频率更远,从而导致PGV的增加和PGA的减小.SHAP值摘要图中观测到的Rjb对PGA预测的重要度低于PGV也可能与位移和速度的频率不同相关(图8).频率越高受几何衰减影响越明显.对于PGA和PGV预测,Dip的SHAP值均随Dip值缓慢增加(图9f和图10f),表明Dip越大预测PGA和PGV越大.对于PGA和PGV预测,Rake的SHAP值随Rake值近似呈周期性变化,并且当地震为走滑断层(-180° 基于NGA-WEST2强震动数据库,本文利用NGBoost算法训练出了适合预测活跃构造区地壳地震PGA和PGV的机器学习模型.在测试集数据上,PGA和PGV预测结果和实际观测结果的相关系数可达0.972和0.984,优于目前所有基于NGA-WEST2或NGA-WEST1强震动数据库的地震动强度参数预测机器学习模型.得益于NGBoost的预测机制,模型除了直接给出实值结果,还能为每个预测结果提供合理概率密度分布,进而为地震危险性概率分析提供定量分析依据.这是目前其他地震动强度参数预测机器学习研究所忽视的. 为解释机器学习模型,分析机器学习模型的预测过程是否符合内在物理规律和实际观测,研究各个特征对预测结果的影响和重要程度,计算了各个特征的SHAP值.SHAP值显示的各个输入特征对PGA和PGV预测的影响基本与地震动预测方程研究一致,但同时也展示出一些以往研究所忽视的现象.例如,对于活跃构造区地壳地震,浅部破裂(ZTOR<~5 km)ZTOR的SHAP值整体上低于深部,且多为负值,表明相比于深部破裂浅部破裂有着更低的PGA和PGV.这可能是由于浅部破裂受速度强化控制所致.并且浅部ZTOR的SHAP值随ZTOR值增大而减小,深部ZTOR的SHAP值随ZTOR值增大而增大.这可能与随发震深度变化的几何衰减、应力降和品质因子Q的变化相关.当Z2.5较小(Z2.5<~1 km)时,Z2.5对PGA和PGV的影响是相反的.可能是因为当Z2.5较小时,Z2.5主要反映浅层沉积物效应而不再是3D盆地效应.浅层沉积物厚度的变化会影响共振频率的变化.加速度和速度频率不同,受到的影响不同.Rjb对PGA和PGV预测的重要度不同,也可能与加速度和速度的频率不同相关. 致谢谨此祝贺陈颙先生从事地球物理教学科研工作60周年. 附录 图A1 对于不同年代(1933—2000,2001—2005和2006—2011年)和不同震级的地震,选取地震记录时使用的最大Joyner-Boore震中距Fig.A1 For different times (1933—2000, 2001—2005 and 2006—2011) and moment magnitudes, the maximum Joyner-Boore epicentral distances used for selecting seismic data 图A2 对于2004年美国加州Parkfield MW6.0地震(EQID=1018)、2009年美国加州San Bernardino MW4.45地震(EQID=1018)和2007年日本Chuetsu-oki MW6.8地震(EQID=278),使用M 5′模型树作为基础学习器和使用分类回归树作为基础学习器的预测结果比较图中黑点表示测试集中的观测值,虚线表示使用M 5′模型树作为基础学习器的预测结果,实线表示使用分类回归树作为基础学习器的预测结果.Fig.A2 For the 2004 Parkfield MW6.0 earthquake, 2009 SanBernardino MW4.45 earthquake and 2007 Chuetsu-oki MW6.8 earthquake, the comparisons of prediction results using M 5′ model trees and classification and regression trees as base learnersThe black dots indicate observations in testing dataset, the dashed lines indicate predicted results by trained models using M 5′ model tree as base learner, the solid lines indicate predicted results by trained models using classification and regression tree as base learner.2 地震动强度参数预测机器学习模型训练和结果分析
2.1 自然梯度提升算法



2.2 机器学习模型训练
2.3 机器学习模型性能分析





3 基于SHAP值的地震动强度参数预测机器学习模型解释

4 讨论

5 结论

 猜你喜欢
环球时报(2022-07-13)2022-07-13数学教学通讯·小学版(2022年4期)2022-05-29环球时报(2022-03-14)2022-03-14西部探矿工程(2022年2期)2022-02-14非常规油气(2021年5期)2021-11-13科学大众(2020年12期)2020-08-13文萃报·周二版(2020年23期)2020-06-19震灾防御技术(2019年3期)2019-06-02电影(2018年8期)2018-09-21中国公路(2017年18期)2018-01-23
猜你喜欢
环球时报(2022-07-13)2022-07-13数学教学通讯·小学版(2022年4期)2022-05-29环球时报(2022-03-14)2022-03-14西部探矿工程(2022年2期)2022-02-14非常规油气(2021年5期)2021-11-13科学大众(2020年12期)2020-08-13文萃报·周二版(2020年23期)2020-06-19震灾防御技术(2019年3期)2019-06-02电影(2018年8期)2018-09-21中国公路(2017年18期)2018-01-23
