
基于FPGA 的双源无轨电车的改进型YOLO-V3 模型*
2022-08-31 07:57:30董宜平彭湖湾贾尚杰
电子与封装 2022年8期
董宜平,谢 达,钮 震,彭湖湾,贾尚杰
(1.中国电子科技集团公司第五十八研究所,江苏无锡 214072;2.无锡中微亿芯有限公司,江苏无锡 214072;3.凯博易控车辆科技(苏州) 股份有限公司,江苏苏州 215200)
1 引言
当前,北京、上海、武汉、广州、杭州等大城市保有大量的双源无轨电车,该类电车有着灵活、经济、环保等特点。双源无轨电车普遍采用传统手动搭线方式将集电杆接入高压电网,这样的操作方式存在着效率低、容易误操作以及增加操作员风险等弊端。近年来,研究人员开始采用深度学习网络对集电盒进行自动识别,从而实现搭载过程完全自动化。该方法可以减少搭载时间、提高搭载精度,做到停下即搭载,减少堵车风险,在保护司机的同时可以减少其误操作。第三版传统黑暗网络的主干网络单次检测(YOLO-V3)是常用的基于深度学习网络的目标识别模型,但是以YOLO-V3 网络模型为基础搭建试验平台进行测试时发现,由于集电盒在白天和夜晚的曝光效果不同,同时存在阴天、雾霾、雨雪等天气干扰,多变背景、遮挡和阴影等环境干扰,以及集电盒的大小、高度、拍照角度不一致等原因,导致识别的集电盒出现异常形变,很难进行有效识别。同时,基于YOLO-V3 网络的搭载模型运算速度有待提高,硬件开销较大。
本文提出以轻量化移动网络(MobileNet)为主干网络的改进型YOLO-V3 网络模型,取代传统的以黑暗网络为主干网络的模型,以减少训练时间、提高运算处理速度、降低硬件消耗和提高识别性能。
2 YOLO-V3 和改进模型建立
2.1 YOLO-V3 网络
YOLO-V3 是一种可以全输入的目标检测算法,即不需要对输入模型进行裁剪。该算法能快速将被测目标从复杂环境中分离出来,从而降低深层网络的训练复杂度,减少深度学习过程中的硬件开销。YOLO-V3 网络模型如图1 所示,图中蓝色虚线框中是黑暗网络-53(Darknet-53),由53 个卷积层组成。卷积层包含如下几部分:一个Darknet 的2 维卷积Conv2D 采用3×3 和1×1 的卷积核对图片进行目标特征提取;一个批量归一化层通过反向传播对训练过程中的梯度参数进行更新,使训练最快得到最优解;一个具有激活函数的层帮助参数进行更新。其中残差网络由两级卷积网络叠加和主分支输出的同维度张量得到。同时,采用快捷链接可以有效解决卷积层训练过程中网络模型梯度退化、网络误差不断累积等问题,保障YOLO-V3 深度训练高拟合度。
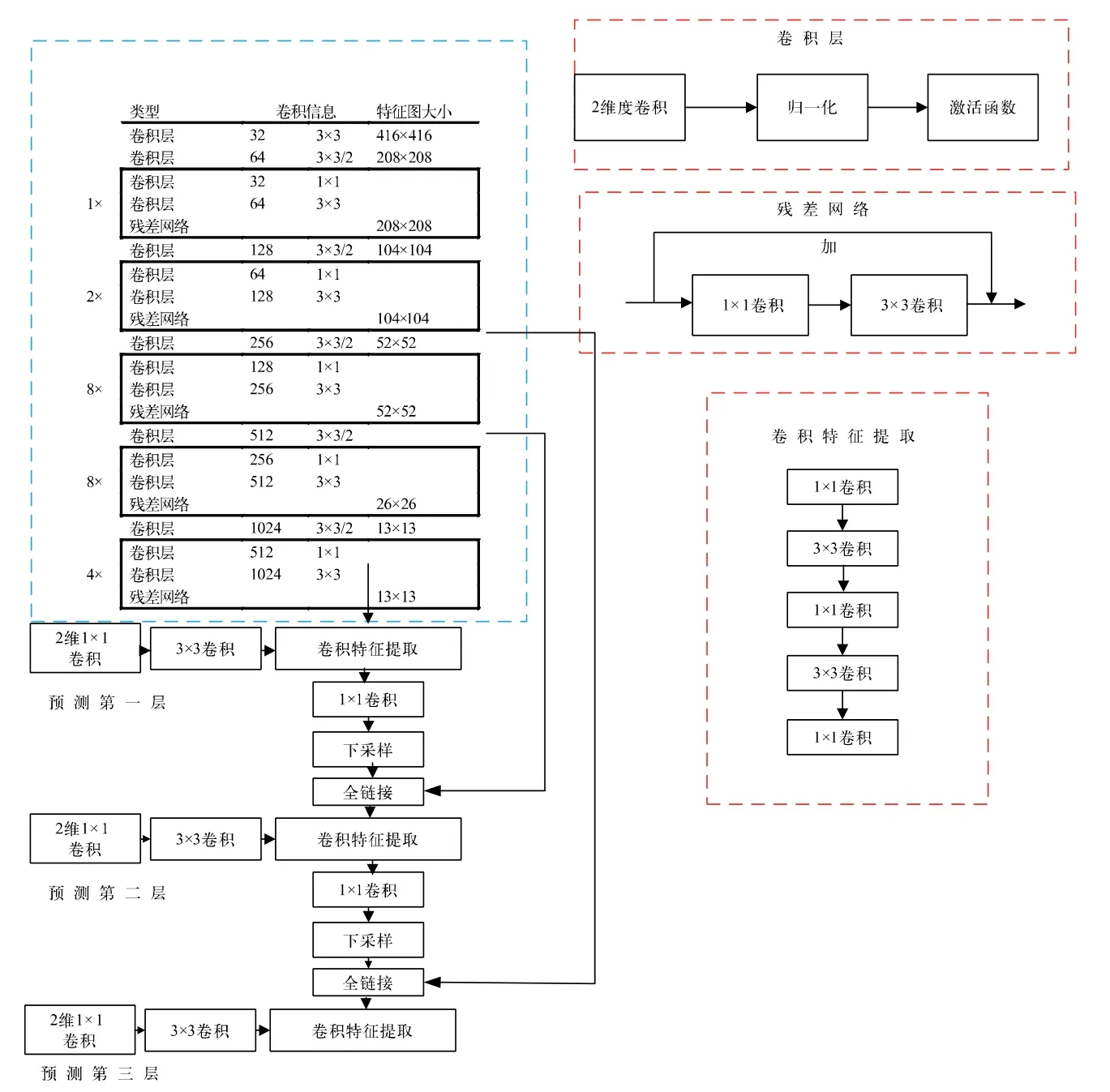
图1 YOLO-V3 网络模型
YOLO-V3 模型的Darknet 主干网络由5 组残差层组成,数据处理流程如下:1)输入分辨率为416×416×3 的图片,经过1 次选采样传递给下一级残差网络;2)输入分辨率为208×208×64 的选采样图像,经过一级的残差网络处理,传递给下一级的2 次下采样;3)输入2 次下采样的104×104×128 图像,经过2 级的残差网络处理,传递给下一级的3 次下采样;4)输入3 次下采样的52×52×256 图像,经过8 级的残差网络处理,传递给下一级的4 次下采样;5)输入26×26×512的4 次下采样图像,经过8 级的残差网络,传递给下一级的5 次下采样;6)输入13×13×1024 的5 次下采样图像,经过4 级的残差网络,传递给下一级的32 次采样,完成Darknet-53 的网络处理。
经过Darknet-53 的网络处理后, 再通过YOLO-V3 的3 个特征对目标进行多尺度特征检测。多尺度特征检测1:输入416×416 的图像,经过79 层的卷积网络后,利用1×1 和3×3 的卷积运算,再经过32 次下采样得到输出分辨率为13×13×255 的特征图。较小的特征图具有更大的感受视野,主要用于大的目标特征提取。多尺度特征检测2:输入416×416 的图像,经过91 层卷积网络后的上采样卷积与第61 层特征图融合,得到91 层较细致的特征图。再经过16 次下采样,输出26×26×255 的特征图。中等的特征图有中等的感受视野,主要针对中等的目标特征提取。多尺度特征检测3:输入416×416 的图像,经过91 层的卷积网络后的上采样卷积与第36 层特征图融合,得到91 层较细致的特征图。再经过8 次下采样,输出52×52×255 的特征图。最大的特征图有最小的感受视野,主要用于小型的目标特征提取。
YOLO-V3 模型过于庞大,该网络的卷积层大概需要106 个。部署到FPGA 上需要转换模型和优化参数。由32 位的浮点运算转换成16 位的定点运算以及权重参数模型都要占用FPGA 内部大量的缓存,对硬件消耗较大。而且YOLO-V3 对复杂环境下的车载集电盒辨识度不高,特别是在夜晚、摄像头采集边缘等情况下无法有效识别。下面对YOLO-V3 模型进行改进从而解决上述问题。
2.2 改进型YOLO-V3 网络
MobileNet 的深度可分离卷积在确保精度的前提下,可以满足双源无轨道电车集电盒的识别需求。MobileNet 主要由深度卷积和逐点卷积组成,其结构如图2 所示。图像处理流程如下:深度卷积首先将输入为416×416×3 的图像分为3 个通道,每个通道只和一个卷积核进行卷积运算。产生的特征值的通道数和输入的通道数一致,但是无法有效扩展特征向量,不能获取不同空间上的特征值。采用1(输入通道数)×1(输出通道数)的卷积核进行逐点卷积,组成新的包含空间信息的特征值。
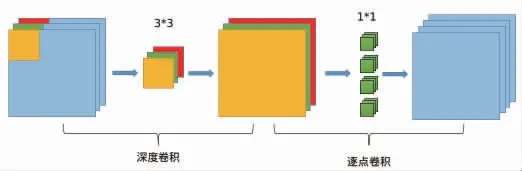
图2 深度可分离卷积网络模型
基于MobileNet 的深度可分离卷积模型的改进流程如图3 所示。改进后的网络可有效避免传统网络反馈过程中,梯度过大导致输入为负值时经过ReLU 激活函数后输出为零,从而导致网络崩溃的情况。采用线性输出后的数据在有效保留了各个通道信息的同时,亦保留了MobileNet 卷积层数少的优势。改进结构中MobileNet 将95%的计算时间用于有75%的参数的1×1 卷积。1×1 卷积在FPGA 部署过程中可以采用查找表的形式,不占用大量运算处理单元,经过一级流水就能得到结果,效率提高明显,同时减少了硬件开销。
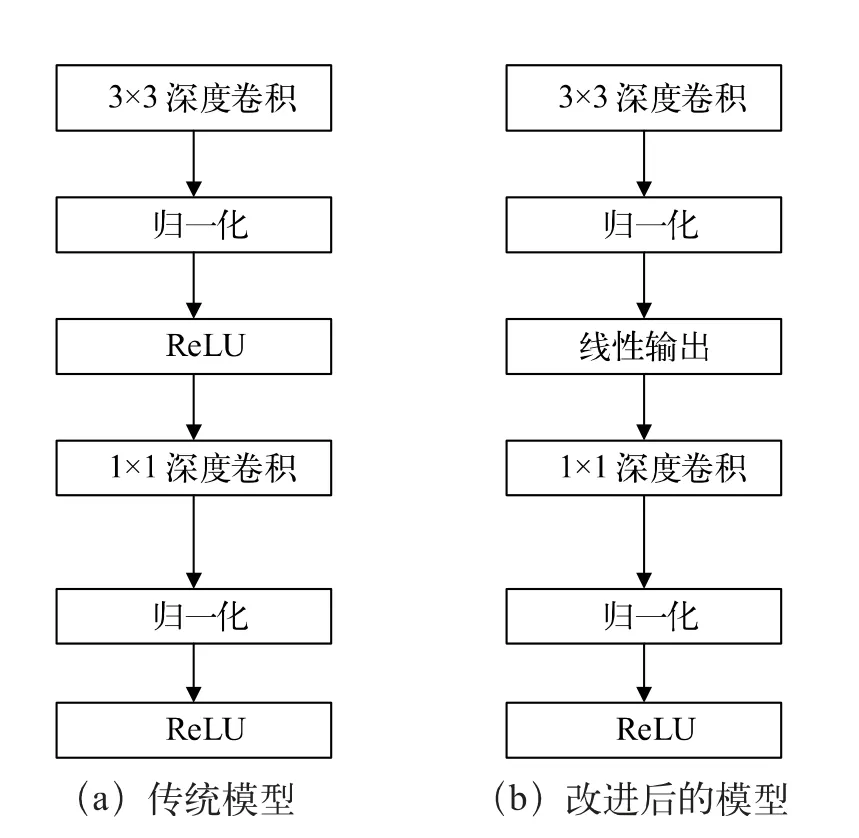
图3 基于MobileNet 的深度可分离卷积模型的改进流程
用 改 进 的 MobileNet 代 替 YOLO-V3 中 的Darknet 架构,改进的YOLO-V3 网络架构如图4 所示。蓝色方框内为深度可分离卷积和标准卷积,深度和逐点卷积都跟随一个激活函数。改进MobileNet 共28 层,具体图像处理流程如下:1)输入416×416×3 的图像,经过下采样校准卷积3×3×32 转换为208×208×32 的图像输出;2)经过标准卷积变换后输入13 层的深度可分离卷积,输出13×13×1024 的数据;3)输入13层的13×13×1024 深度可分离卷积输出数据,经过K值为7、步长为1 的平均池化,输出7×7×1024 的图像,防止过拟合;4)全链接层把输入为7×7×1024 的池化特征值转化为1×1×1024 的特征值,采用分布式表示;5)Softmax 层输出1×1×1024 的特征值。
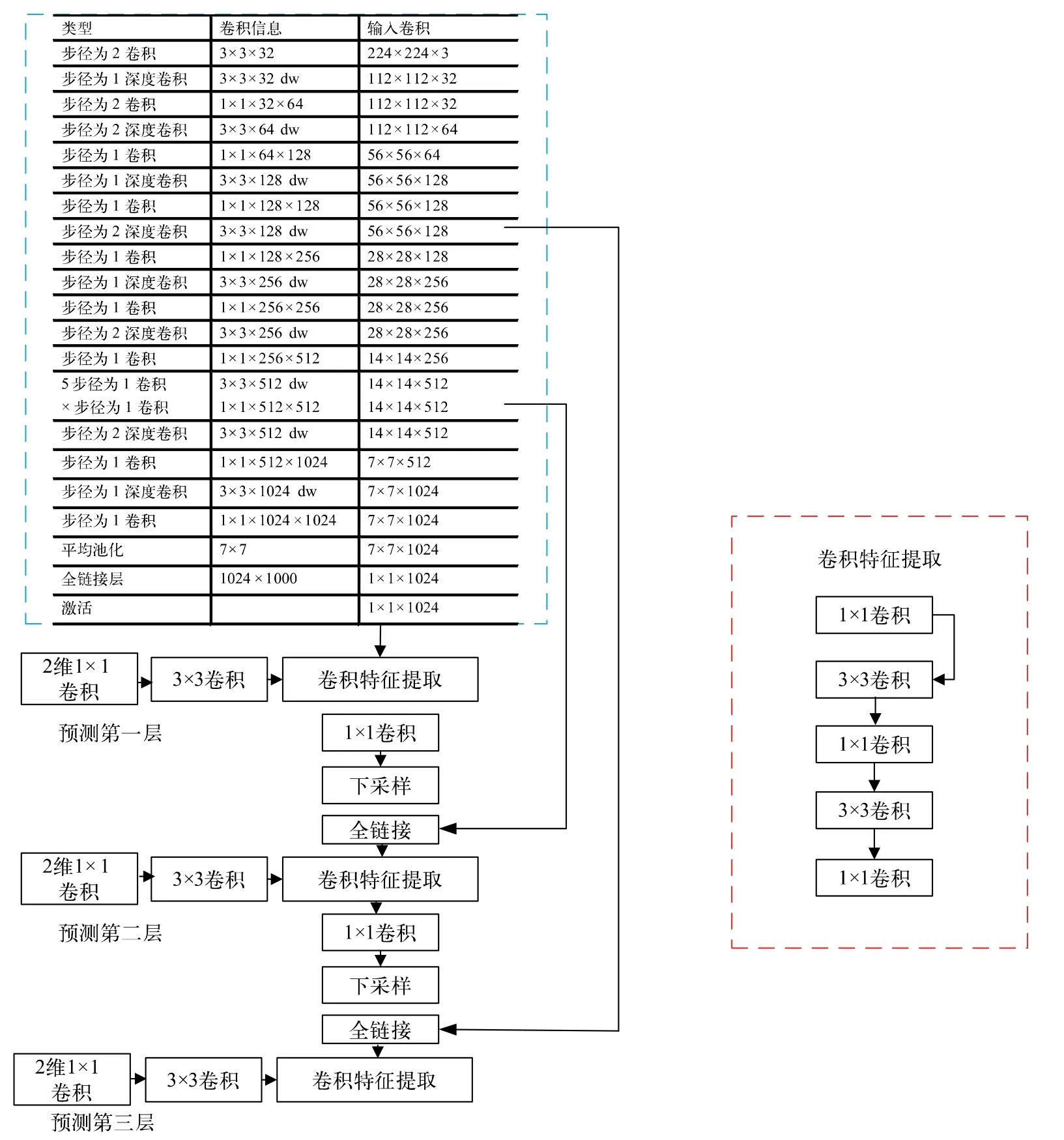
图4 改进型YOLO-V3 网络模型
改进型YOLO-V3 网络相比于YOLO-V3 网络,卷积层数从106 层减少至28 层,大大减少了所需要的参数。用深度卷积和逐点卷积代替原有标准卷积核,减少了卷积运算次数,实现了通道和区域的分离。
2.3 损失函数计算
为了更好地评估预测值与目标值的差距,有效指导下一步训练的权重值,本文引入损失函数进行评估。改进型YOLO-V3 网络的损失函数主要由3 个部分组成。
2.3.1 置信度
置信度是为了预测目标是否存在预测框内概率值,由二分类任务交叉熵损失函数构成,其中正例和负例的概率和为1。
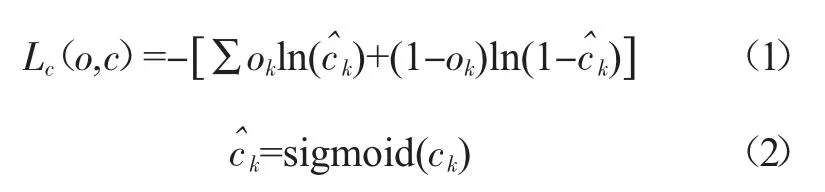
其中Lc代表置信度损失函数,o 为样本标签值,c 为模型预测样本为正例的概率,k 为样本个数。预测值通过sigmoid 函数激活,从而减少没有目标值的部分权重的计算,减少计算量。
2.3.2 边框准确度
边框网络模型如图5 所示。在网络架构中,对偏移量进行了约束,防止边框的中心在随机位置,导致训练不能收敛。图中cx和cy分别表示中心的xy 坐标值,Pw和Ph为锚点的宽度和高度,σ(tx)和σ(ty)代表预测框的中心点和坐标轴的距离,tw和th分别代表预测框的横纵偏离度,最终得到bx、by、bw、bh4 个边框相对特征图的位置和大小参数[1]。
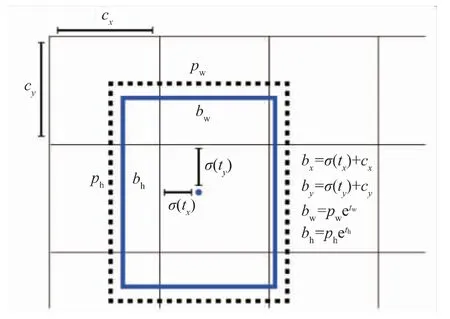
图5 边框网络模型
均方误差损失函数L1为:
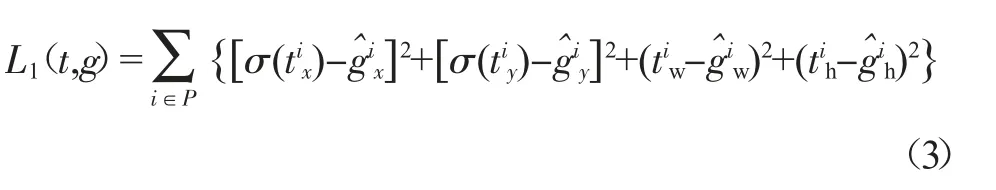
2.3.3 对象分类误差
当第i 个网格的第j 个锚点可以确定为所需要的目标时,这个锚点才去计算对象的分类损失函数。对象分类误差同样由二分类任务交叉熵损失函数构成:
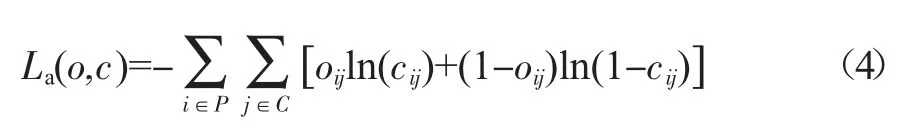

其中La为对象分类损失函数,C 代表网格内的锚点。
3 训练和实测结果
3.1 训练模型
原始数据是双源无轨电车在不同环境和路况下,通过集电盒下的摄像头得到的。选取部分图片作为训练集,首先用软件进行图片标定,然后对数据集进行模式转换,将视觉目标分类格式转换为YOLO 格式的文本文件。文件包含边框中心点的x 坐标与图片的宽度比值、边框中心点的y 坐标与图片的高度比值、边框的宽度与图片宽度比值以及边框的高度与图片高度比值。
搭建改进型YOLO 网络的运行环境并编译成功,分别创建训练和测试数据集。安装英伟达的并行架构计算软件后,利用七彩虹RTX 3060 Ti 显卡进行GPU训练。
3.2 运算结果
因为环境因素的影响,比如白天和夜晚的曝光效果不同、不同天气、背景多变、遮挡和阴影等环境干扰,还有集电盒本身的大小、高度不一致,拍照角度不一致,都可能导致识别的集电盒出现异常形变和尺寸变化。将基于Darknet-53 主干网络的YOLO-V3、基于Tiny 主干网络的YOLO-V3-Tiny 和基于MobileNet 主干网络的改进型YOLO-V3 的数据进行不同场景下的测试,对比结果如表1 所示。改进模型在准确性(F1 score)和交并比(IoU)上有明显提升,平均精度也明显优于其他两种网络。权重大小仅为28 MB,可以较好地部署到移动设备等低功耗需求的设备中去,减少缓存和算力消耗。

表1 不同网络模型测试结果对比
YOLO-V3 和改进型YOLO-V3 模型训练过程中的损失函数曲线如图6 所示。从图中可以看出,YOLO-V3 在迭代50000 次后趋于收敛,损失函数值为0.06%。改进型YOLO-V3 的损失函数值在500 次迭代后收敛较快,4000 次后趋于平均,损失函数为0.03%。改进后的YOLO-V3 模型比传统网络收敛速度加快90%,稳定后损失函数值降低50%,识别精度更高。

图6 YOLO-V3 和改进型YOLO-V3 训练过程中的损失函数曲线
3.3 硬件结构
在改进型YOLO-V3 网络的环境要求下,利用神经网络常用平台建模,采用浮点网络模型和校准数据集作为训练的输入,基于Xilinx 软件搭建硬件系统[2-8],其硬件结构如图7 所示。硬件系统由摄像头、H.264 编解码、直接内存控制器(DMA)、A53 控制器、深度学习处理单元(DPU)和DDR 存储器组成。摄像头采用1920×1080@30 ps 的车载网络摄像头,支持日夜模式,可以满足不同场景下对图像质量、流畅度的要求;H.264 编解码采用PL 逻辑单元,最大支持2K 的视频编解码,由网络控制器和编解码器组成;A53 为系统的应用处理层,实现系统调度和实时显示等功能;DPU主要作为改进型YOLO-V3 网络的卷积计算单元,存储器主要用于缓存图像和权重值。

图7 基于Xilinx 搭建的硬件结构
3.4 实测结果
摄像头和处理单元安装在无轨电车的动力控制部分;实地对摄像头进行标定,完成畸变矫正,使得图像更趋于平滑;对集电盒的大小和高度进行校准和软件调试。YOLO-V3 网络和改进网络调试结果如图8所示。由于YOLO-V3 模型较大,处理单张图片平均耗时1247 ms,对应帧率0.8 帧/s,无法做到实时处理,对在黑夜曝光的集电盒无法识别。而改进模型规模较小,平均耗时89 ms,对应帧率11 帧/s,可以满足实时处理的需求,能够准确处理各种复杂环境下的集电盒识别。由对比结果可知改进型YOLO-V3 模型识别精度和准确率有明显优势,能有效识别传统网络无法识别的图像。

图8 实际测试结果对比
4 结论
为解决双源无轨电车集电盒识别应用上的技术难题,通过对传统基于Darknet 主干网络的YOLO-V3网络结构和应用的不足进行分析,提出了一种基于MobileNet 主干网络的改进型YOLO-V3 网络架构。通过仿真训练和实地部署,对真实复杂环境下双源无轨电车进行测试,试验结果表明,改进的YOLO-V3 网络识别精度和处理速度都优于传统网络,可以在双源无轨电车中大规模推广应用。
猜你喜欢
智能制造(2022年4期)2022-08-18 16:21:14
一重技术(2021年5期)2022-01-18 05:42:08
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
测控技术(2018年4期)2018-11-25 09:47:14
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
摄影之友(影像视觉)(2018年1期)2018-03-22 01:12:04
摄影之友(影像视觉)(2017年11期)2017-11-27 02:39:53
中国照明(2016年6期)2016-06-15 20:30:14
电机与控制应用(2015年2期)2015-03-01 03:49:22
