
基于轻量化神经网络的端到端人脸识别技术研究
2022-08-31 08:11:57曹戈杨周有
电脑知识与技术 2022年18期
关键词:人脸识别
曹戈杨 周有


摘要:移动端设备由于计算能力有限和实时使用的速度限制,需要开发轻量化的人脸识别的深度学习算法。算法核心在于通过网络的结构与计算参数设计,减少无关的特征冗余与非必要数据流动。本研究设计以Ghost模块嵌入的TinyYOLO- MobileNet V3端到端识别网络,总结出在特征图中以小尺度替代大尺度,在计算上以线性计算代替小尺度卷积计算的设计思想。基于该思想,本研究完成了端到端架构设计并在实验中完成了对框架的性能测试。
关键词:人脸识别;Ghost模块;TinyYOLO;MobileNet V3
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)18-0003-03
开放科学(资源服务)标识码(OSID):
1 引言(Introduction)
人脸作为特殊的生物ID具有自然性、唯一性和不一致性,如何高效低耗地利用人脸特性做图像识别是人脸识别的主要任务[1]。基于空间利用[2]、深度、多路径、宽度、特征图利用、通道提升和注意力提升等用于人脸识别的DCNN技术层出不穷[3]。但现有模型在执行端到端识别任务过程中计算代价与复杂度过高,不适合移动端和边缘计算设备等不具备高性能图形处理单元(GPU)的场景。
常用图像识别轻量卷积神经网络主要有 SqueezeNet[4]、BlazeFaceNet[5]、MnasNet[6]、TinyYOLO[7]、GhostNet[8]、EfficientNet[9]、MobileNet[10~12]等。这些轻量级架构在移动端检测的端到端架构中检测识别精度受限。该问题主要来源于架构的轻量化追求与特征提取的过参数化要求的矛盾,轻量化网络较少的参数不可避免带来的是拟合能力的弱化。针对该问题,本研究设计了基于深度可分离卷积的TinyYOLO-MobileNet V3的端到端架构,并在MobileNet V3中引入Ghost模块保证轻量化并增益精度。最后针对公开数据集和作者实拍数据,完成测试。
2 轻量级神经网络技术(Light weight neural network technology)
2.1 TinyYOLO 算法简介
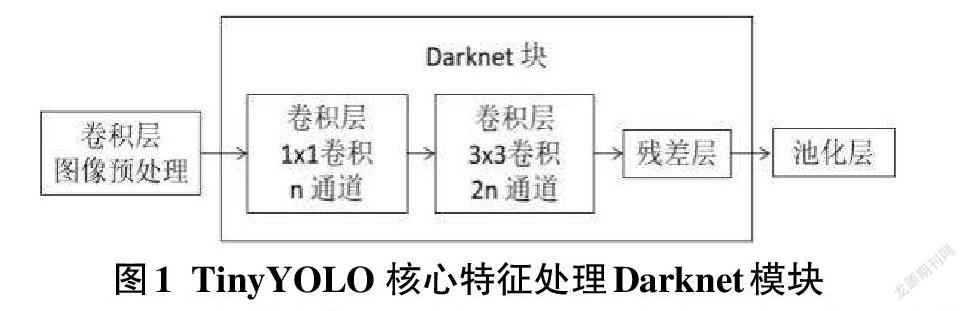
TinyYOLO的特征提取器为Darknet,由卷积残差块和池化层组成,结构如图1所示,由卷积层和中间的最大集合层组成,最后一个卷积层用于进行边界框预测。与其他网络不同,TinyYOLO不是一个传统的分类器,而是通过将图像划分成不同的边框网格,输出一个置信度分数,预测边框实际上包围了某个对象的确定性。对于每个边界框,单元格还预测一个类别并给出所有可能类的概率分布,最后通过一个卷积层有一个1×1的内核,用于将数据减少到被划分成的网格的大小。
2.2 MobileNet算法简介
用计算成本更低的深度可分离卷积代替传统卷积以降低计算成本,如图2所示。在MobileNet V3中,网络没有使用最大池化来减少空间维度,但一些深度层的跨度为2,最后是一个全局平均池化层,然后是一个全连接层或1×1卷积,用于做分类。各层使用Swish作为激活函数,如图3所示。
在深度卷积层之前是一个作为扩展层卷积,该层增加了通道的数量。整个Mobile Net V3堆叠了多个上图2所示的架构块以替代传统的深度卷积残差网络,做了替代达到加速计算的目的。Hardwish层使用了h-swish函数,如式(1)所示。
[h_swish(x) = x×ReLU6(x + 3)6] (1)
式中,[x]為输入。h-swish函数作为激活函数是Google 为Android 设备(原型测试于Google Pixel的移动平台上,以TensorFlow Lite 为开发框架)。V3中使用了Squeeze-and-Excitation Networks(SE)模块,通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。模块没有使用sigmoid,而是使用h-swish函数作为粗略的近似值。通过采用近似计算的方法,节省了激活函数的计算成本。在V3的架构能够处理更小的1×1特征图,并由于摒弃了其他轻量级网络的瓶颈层和深度卷积层,提高了精度损失。
3 端到端人脸识别架构(End-to-end face recognition architecture)
3.1 GhostNet模块
通常卷积层中的卷积核越少,速度越快,但表现力也越差,因为最终得到的特征图越少。而GhostNet的设计思想为:通过使用比完全卷积更便宜的特征提取操作(被称为原主干网络的Ghost),合成额外的特征图可以弥补这一点[12]。因为不同通道的特征图在CNN的训练过程中很类似。
本研究在此提出基于深度可分离卷积的Ghost模块,结构如图4所示。首先通过Keras深度学习框架的Lambda层分割数据,执行小规模的深度可分离卷积,生成了少量的特征图。然后通过简单的线性变换创建Ghost特征。这些特征图与原特征图相连接通过线性层加权输出,从而达到以更具成本效益的方式复现了这些冗余的特征图,参数量降低为原来的一半。
3.2 端到端架构
本文基于TinyYOLO与MobileNetV3搭建如图5所示的端到端人脸识别框架,其中,TinyYOLO负责人脸定位,MobileNet负责人脸识别。TinyYOLO的主干网络,主干网络采用一个7层卷积加最大池化层的网络提取特征,YOLO嫁接网络采用的是58*56、26*26的分辨率探测网络,TinyYOLO去输出层将框定的人脸特征直接输入融合了Ghost Module的MobileNetV3中,最后通过SoftMax完成识别。
该网络的优势在于通过下列方法兼顾精度与运算速度:在神经网络的层间数据流动中,通过更多的小型特征图弥补对单个大型特征图的计算不足(权衡宽度乘法与深度乘法);通过廉价的线性或小尺度计算替代昂贵的卷积运算;在模块中大量运用了深度可分离卷积处理输出。
4 实验分析(Experimental analysis)
4.1实验数据与训练细节
采用FDDB公开数据集[13]完成算法的训练,该数据集包含2845张图片,共有5171个人脸作为测试集。测试集范围包括:不同姿势、不同分辨率、旋转和遮挡等图片。并采用手机拍照收集的图片作为验证集。并在实测中比较所提出架构与YOLO-SqueezeNet和YoLo-MobileNetV3_Small等端到端框架的检验识别能力,在训练中的评价函数为识别的RMSE误差。训练平台为Colab,步数为500。训练结果如图6所示,可以看出,所提出的架构训练成本低,算法迅速收敛并且所提出的Ghost模块能有效捕捉人脸特征。
在移动端,基于tensorflow lite将算法迁移到用TensorFlow自带的工具来fine-tuning训练上诉架构,将生成的pb文件转换为tflite文件,后用Android studio打包成apk。在实际环境中,通过手机相册数据及实时自拍检测部署后的识别能力。
4.2 实验结果
与其他典型轻量化端到端框架的对比结果详见表1,通过实验结果可知,本研究方法具有更轻量化的架构和更高的识别精度。
在实拍和手机端对移植算法的检测中,可以看出,算法能有效定位和识别人脸。
5 结论(Conclusion)
本研究设计了基于TinyYOlO与Ghost模块改进的MobileNet V3的端到端人脸识别框架,总结了兼顾轻量化和精度的设计思想,并最终在现有数据集和作者自拍识别的实验中进行验证,实验结果证明了该架构的精确有效。相较于主流架构YOLO-SqueezeNet(3.8M 参数量,0.5092s检测识别速度,72%识别精度)与YOLO-MobileNetV3_Small(3.9M参数量, 0.6106s检测识别速度,82%识别精度),本文的架构在1.4M参数量下,检测识别速度为0.2192s,识别精度为90%。
参考文献:
[1] Nirkin Y,Wolf L,Keller Y,et al.DeepFake detection based on
discrepancies between faces and their context[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2021.
[2] Khan A,Sohail A,Zahoora U,et al.A survey of the recent architectures of deep convolutional neural networks[J].Artificial Intelligence Review,2020,53(8):5455-5516.
[3] Chai J Y,Zeng H,Li A M,et al.Deep learning in computer vision:a critical review of emerging techniques and application scenarios[J].Machine Learning With Applications,2021,6:100-134.
[4] Li G F,Tong N N,Zhang Y S,et al.Moving target detection classifier for airborne radar using SqueezeNet[J].Journal of Physics:Conference Series,2021,1883(1):012003.
[5] Bazarevsky V,Kartynnik Y,Vakunov A,et al.Blazeface: Sub-millisecond neural face detection on mobile gpus[J].arXiv preprint arXiv:1907.05047,2019.
[6] 杨国亮,朱晨,李放,等.基于改进MnasNet网络的低分辨率图像分类算法[J].传感器与微系统,2021,40(2):142-145,153.
[7] 燕红文,刘振宇,崔清亮,等.基于改进Tiny-YOLO模型的群养生猪脸部姿态检测[J].农业工程学报,2019,35(18):169-179.
[8] 程春阳,吴小俊,徐天阳.基于GhostNet的端到端红外和可见光图像融合方法[J].模式识别与人工智能,2021,34(11):1028-1037.
[9] Xiao Y H,Zhou J Y,Yu Y Z,et al.Active jamming recognition based on bilinear EfficientNet and attention mechanism[J].IET Radar,Sonar & Navigation,2021,15(9):957-968.
[10] 郭奕君,阿里木江·阿布迪日依木,努尔毕亚·亚地卡尔,等.基于MobileNet网络多国人脸分类识别[J].图像与信号处理,2020(3):146-155.
[11] Kadam K,Ahirrao S,Kotecha K,et al.Detection and localization of multiple image splicing using MobileNet V1[J].IEEE Access,9:162499-162519.
[12] Han K,Wang Y H,Tian Q,et al.GhostNet:more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020,Seattle,WA,USA.IEEE,2020:1577-1586.
[13] Jain V,Learned-Miller E.Fddb:A benchmark for face detection in unconstrained settings[R].UMass Amherst technical report,2010.
【通聯编辑:梁书】
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
学生天地(2020年31期)2020-06-01 02:32:06
电子制作(2019年14期)2019-08-20 05:43:34
中国交通信息化(2018年1期)2018-06-06 07:29:55
电子制作(2017年17期)2017-12-18 06:40:55
中国公共安全(2017年7期)2017-10-13 08:18:26
电子制作(2017年1期)2017-05-17 03:54:46
中国公共安全(2017年9期)2017-02-06 03:05:32
现代工业经济和信息化(2016年6期)2016-05-17 05:36:23
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:51
