
基于Centernet的口罩佩戴检测算法研究
2022-08-28 07:44邢春雨郑平
现代信息科技 2022年10期
邢春雨,郑平
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.安徽理工大学 电气与信息工程学院,安徽 淮南 232001)
0 引 言
新冠疫情当前,佩戴口罩作为一种物理层面的隔绝措施,对阻止新型冠状病毒传播具有一定防护作用。而部分民众防疫意识淡薄,常在公众场合不佩戴口罩。现在公众场合识别未佩戴口罩人员基本上依赖于人工来完成,但环境复杂、场景多变、人流量大等诸多原因,需要花费许多时间成本以及人工成本,且有一定可能误判漏判。基于深度学习的目标检测,能够快速在图像和视频中提取到有价值的信息,在诸多领域中都展现出非常好的效果,得到了广泛应用。本文区别于传统的目标检测算法,引入centernet 和注意力机制,并进行改进,旨在提高检测精度,从而更效监督人们佩戴口罩情况,提高公众口罩佩戴率。
1 目标检测简介
目标检测领域发展至今已有二十余载,从早期的传统方法到如今的深度学习方法,精度越来越高的同时速度也越来越快,这得益于深度学习等相关技术的不断发展。不同于图像分类任务,目标检测不仅要解决分类问题,还要解决定位问题。目标检测的发展可以分为传统目标检测和基于深度学习的目标检测两个时期。
传统目标检测算法主要有以下缺点:(1)准确率不高(2)运算速度有待提高(3)正确识别的结果可能不止一个。
主要介绍基于深度学习中的Anchor free目标检测算法。基于Anchor 的目标检测通常转换成对候选区域进行分类以及回归,由于Anchor 太多导致计算复杂,及其所带来的大量超参数都会影响模型性能。近年的Anchor free 技术则摒弃Anchor,通过确定关键点的方式来完成检测,大大减少了网络超参数的数量。
(1)CornerNet是Anchor free 技术路线的开创之作,此网络模型是一种新的检测方法,由原来的对目标边界框的检测转化为对边框的左上角和右上角即关键点的检测,而无须设计Anchor box 作为先验框。
(2)CenterNet 与CornerNet 检测算法不同,CenterNet的结构十分简单,它摒弃了左上角和右下角两关键点的思路,而是直接检测目标的中心点,其他特征如大小,3D 位置,方向,甚至姿态可以使用中心点位置的图像特征进行回归,是真正意义上的Anchor free。该网络还提出了两个模块:级联角池化模块和中心池化模块,进一步丰富了左上角和右下角收集的信息。
(3)FSAF 网络提出了一种FSAF 模块用于训练特征金字塔中的Anchor free 分支,最佳匹配的特征都可以被每一个对象选择。在该模块中,Anchor box 的大小不再在特征预测中起决定作用,实现了模型自动化学习选择特征。
(4)FCOS 网络实现了无须锚点,并且提出了Center ness 即中心度的理念。该算法通过去除Anchor,所以能够减少不必要的复杂运算,总训练的内存还可以大大地减少。性能:FCOS 的性能优于现有的一阶段检测器,并且FCOS还可以替代作二阶段检测器Faster RCNN 中的RPN,并且很大程度上都要优于RPN。经分析其性能对比如表1所示。
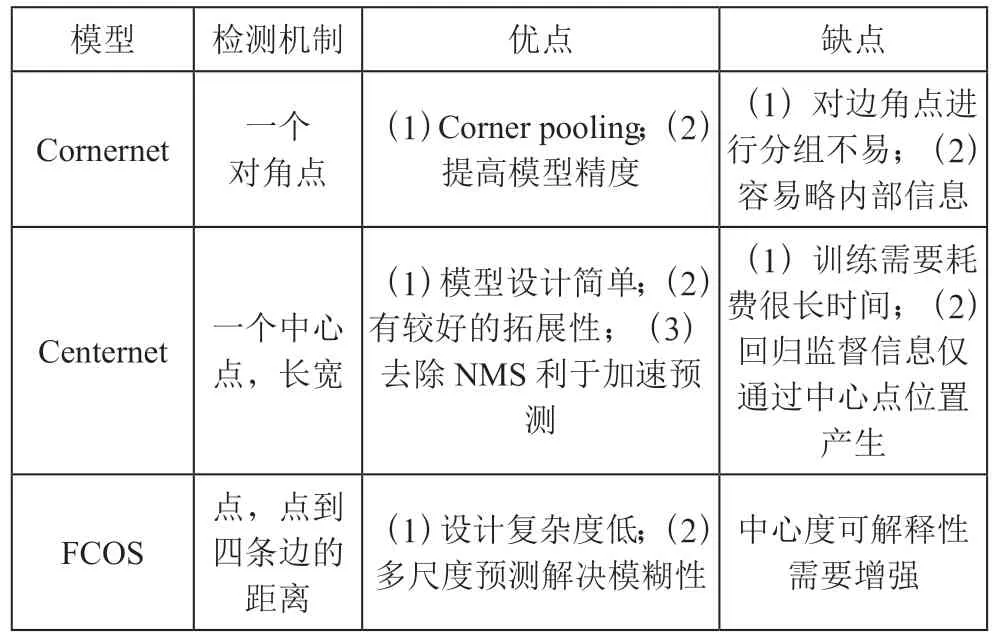
表1 Cornernet 和Centernet 和FCOS 性能对比
2 算法原理
2.1 Centernet 简介
目标检测需要对物体的位置做出精确识别,目前常用物体检测器都比较低效,因其不仅需要详细的检测出每个潜在的物体所在区域还要对检测出的区域进行分类,然后在进行需要另外的后处理操作。 而centernet,作为一个anchor free 模型,通过对关键点进行预测来找到中心点而将目标对象bounding box 的中心点进行建模,然后再将所有其他对象属性进行回归。
Centernet 通过将待检测的目标输入到特征提取网络中,以高斯核的方式将中心点分布在feature map 上并生成热力图,利用每个峰值点周围的图像特征回归得到目标的宽和高,训练过程中采用监督学习的方式。
其核心思想如图1所示,通过直接预测中心点和物体尺寸,把检测问题转换为关键点问题,去除anchor,每个位置仅有一个正样本,不再使用NMS;对于物体尺寸,直接预测目标框大小。分别提取左上角和右下角特征,预测左上角和右下角的位置,将左上角和右下角组成候选框。通常embeddings 在相同目标对象的角点中具有很高的相似度,而在不同目标对象中的角点中有着相当大的距离。

图1 Cneternet 核心思想
与anchor 系列模型的区别:
(1)anchor free 模型一般通过目标的中心点建模,基于anchor 的模型通过预先设置的anchor 建模。基于anchor的模型需要设置有关anchor 的许多超参数。每个位置的样本数不同:anchor free 模型输出特征图上的一个位置只设置一个样本,而基于anchor 的检测模型会设置多个样本(同一个位置设置多个不同形状anchor)。正样本的确定方式不同:anchor free 模型正样本通过位置确定,基于anchor 的检测模型正样本通过IOU 来确定。
(2)centernet 的输出分辨率大,下采样率只有4(output_stride=4),其他检测模型普遍为8 ~16。使其对小目标的召回效果比较好。centernet 不需要nms,只需要找到heatmap 的峰值就好。
(3)同一个类别的两个物体的中心点相同,模型只能给出一个物体检测框,原因是因为输出特征图同一个位置只设置一个样本,可以用类似fpn 的结构来解决这个问题。
与图2类比,centernet 与cornernet 采用相似的关键点检测思路,都是要heatmap 思想和focal loss 进行训练,但是centernet 不需要对关键点进行分组操作。

图2 cornernet 瞄框
下文图3,图4,图5为预测不同任务中的不同属性。

图3 object size
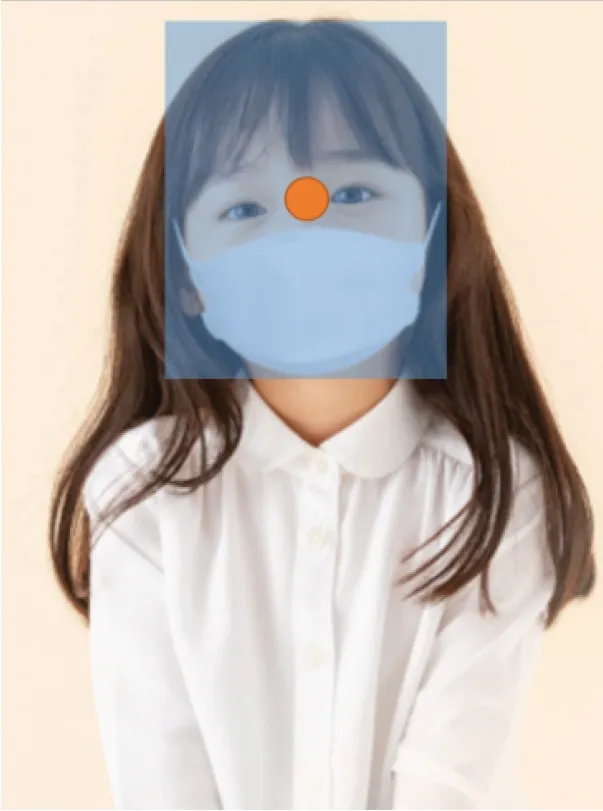
图4 depth

图5 key point heatmap
(1)检测任务中直接预测目标框的大小。
(2)centernet 算法目标框的中心点产生监督信息并使用损失函数计算loss。
2.2 损失函数
当centernet 用于普通的目标检测时,其head 分为三个部分:heatmap、reg、wh,对应三个损失的计算。公式如下:
heatmap (即热力图,在目标检测的图像处理中,采用二维高斯核来表示关键点。)
heatmap 的峰值的位置就是目标的中心点。将模型heatmap 的输出进行通过3×3 的卷积核进行最大池化处理,保留局部最大值,然后选择每个类别的topk(100)个像素点,再通过每个类的topk 中(topk x C)选出所有类的topk。接着通过topk 个像素点的位置找到该点对应目标的wh 和offset,最后解析出目标框。
目标是输入:

输出:




(2)首先使用一个 Gaussian kernel 将所有的keypoint绘制到heatmap 上。当同一个类别的Gaussian 有重叠的时候选择element-wise maximum。
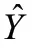

和是focal loss 的超参数,代表图片中keypoint 的个数。一般设置=2,=4。
(3)REG(是超参数一般是指在总loss 的比例,及正则化的权重,w 需要正则化的参数)由于输出步长的会导致离散误差的产生,所以需要计算每个keypoint 的local offset(局部偏移)O^∈RRW×RH×2。比如一个点在原图的位置是(5,7),由于输出步长为4,所以点映射到输出特征图上的位置应该为(1.25,1.75),但是因为要取整,所以点在特征图上的位置就变成了(1,1),0.25 和0.75就变成了局部偏移量。
(4)(=,其中是矩阵,是矩阵,是矩阵)
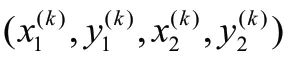

就是目标的大小,因为坐标都已经除以下采样率了,所以计算出来的是在输出特征图上的大小,解析目标框后乘以下采样率就会得到在原图上的坐标。
2.3 CBAM
在对于人脸的口罩识别中希望能尽可能地多关注口罩信息而尽可能多的忽略脸部其他信息。因此在口罩佩戴检测中加入注意力机制CBAM 可以有效地实现这一目标。
CBAM是一个比较简单并且有效的注意力模块,它的核心思想是利用其中的中间特征图。注意力的权重是可以通过中间特征图的空间维度和通道维度进行预测,之后再与原来的特征图相乘进行自适应性调整。
CBAM 可以分为两个部分:通道注意力模块和空间注意力模块,彼此间相互独立形成了两部分,不仅能减少参数量,提高网络的性能。并且可以作为现成的模块加入到其他网络结构中实现集成。CBAM 是一个通用模块,它属于一个轻量级。由此特性,所以它可以很容易即成到CNN 得的架构中。并且可以和一些基本的CNN 模型进行端到端的训练。将CBAM 集成到用于分类和检测的模型中,性能会有一定程度的提升。因此,CBAM 具有广泛的应用性。CBAM可以分为两个部分:通道注意力模块和空间注意力模块。
CBAM的两个部分通道注意力模块和空间注意力模块。通道注意力模块:加入通道注意力可以更好地关注通道中的特征信息,通过学习的方式来自动获取各个特征通道信息存在的重要性。空间注意力模块:加入空间注意力的目的是为了更好地关注位置的信息,通过建立空间层面中feature map的内在关系更好地提取特征信息,分析比较哪些区域是有用信息,哪些是不太重要的信息。所以CBAM 可以将通道信息和空间信息结的卷积模块合起来,将网络模型的“注意力”放在重要的信息上。
基于ResNet 网络结构,基于残差模块内嵌入通道和空间注意力模块。经过1×1 卷积,3×3 卷积和1×1 卷积后,依次加入通道注意力模块和空间注意力模块,如图6所示。

图6 ResNet 加入CBAM 后改进的模型
3 实验
数据集采用公开数据集VOC_MASK,将数据分为face和face-mask 两种类别,如图7所示。


图7 数据集的分类
对下图中的专有词汇做出简要说明。通常情况下,GT(Ground Truth)称为真值框,BBox(PredBBox)称为边界框,二边界框是经过网络预测所得到的。AP 指的是某一个类别全部图像中的平均精确度,通常用P-R 曲线下的面积来计算,通常一个越好的分类器,AP 值就会越高。
Mean Average Precision(MAP)是平均精度均值,具体指的是不同召回率下的精度均值。在目标检测中,一个模型通常会检测很多种物体,那么每一类都能绘制一个PR 曲线,进而计算出一个AP 值,而多个类别的AP 值的平均就是MAP。MAP 是对所有的类别求平均AP 值,MAP 的大小一点在[0,1]之间,越大越好,该指标是目标检测算法最重要的一个。一般情况下,单一目标用AP 指标,多个目标用MAP指标。其中log-average miss rate表示对数平均未命中率。Recall 表示实际为正样本中,预测为正样本的比例。实验结果如图8、图9所示
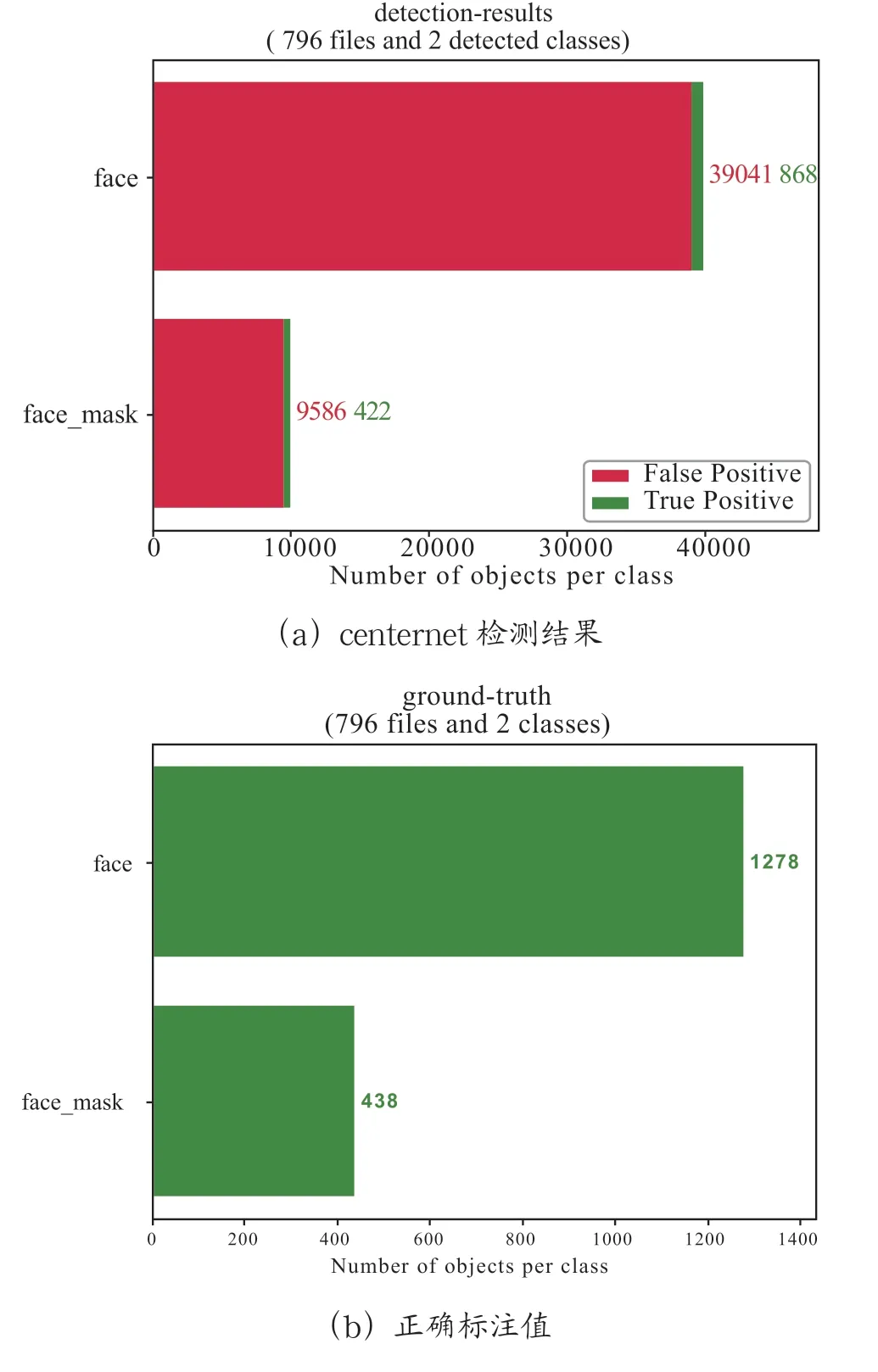
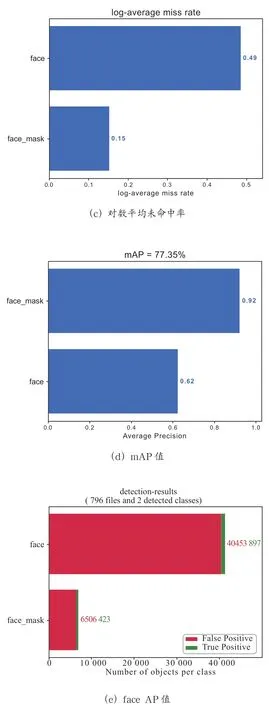
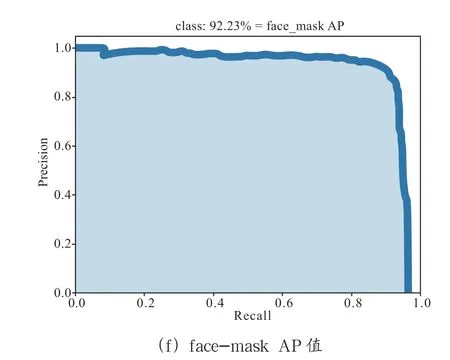
图8 centernet results

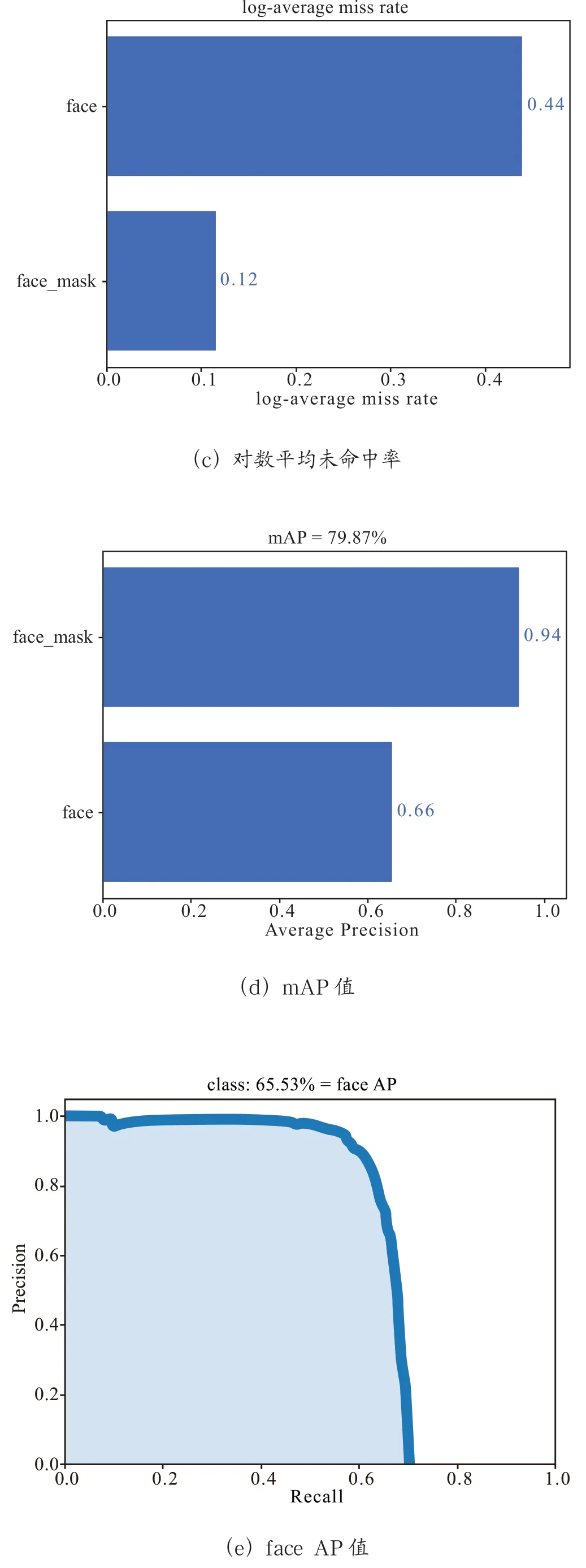

图9 加入CBAM 后的结果
通过图8,图9可知,加入注意力机制CBAM 后,与原始的centernet 对比face 类别的召回率从62.47%到65.53%增加了3.06 个百分点,face-mask 类别的召回率从92.23%到94.21 增加了1.98 个百分点。而map 值从77.35%到79.87%增加了2.52 个百分点。
4 结 论
为应对当下疫情,加强公共安全防护,提高口罩检测的效率。本文提出基于CenterNet 在多个中心点在同一位置的目标检测 ,通过加入CBAM 注意力机制的新网络模型,以提高口罩佩戴检测的性能。对数据分为face 和face_mask 两种类别,在VOC-MASK 数据集上的实验表明,该算法目标检测的性能与原始Centernet 算法相比具有竞争优势。下一步将继续改进本网络模型,以进一步提高检测精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
少儿画王(3-6岁)(2020年4期)2020-09-13
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
新课程·小学(2019年1期)2019-03-18
东方教育(2018年20期)2018-08-22
第二课堂(课外活动版)(2016年2期)2016-10-21
大众摄影(2015年9期)2015-09-06
微型计算机(2009年4期)2009-12-23
中学英语之友·高一版(2008年10期)2008-12-11
