
基于近红外光谱和机器学习的无创血糖浓度回归研究
2022-08-25 03:10:38李莹周林华
长春理工大学学报(自然科学版) 2022年3期
李莹,周林华
(长春理工大学 数学与统计学院,长春 130022)
糖尿病是一种内分泌疾病,患者的胰岛素分泌不足或身体未能有效利用胰岛素,导致体内血糖过高。糖尿病患者的持续高血糖会导致身体器官产生病变,特别是对眼睛、肾脏、神经、心脏、血管造成的慢性损害尤为严重[1]。据国际糖尿病联盟公布的数据,2019年全球约有4.63亿年龄在20~79岁的成人患有糖尿病,预计到2045年,这一数字将上升到7亿。目前临床尚无治疗糖尿病的药物,只能使用有创技术控制人体血糖水平以达到控制糖尿病的目的。
有创技术易对患者造成伤害的缺点促进了微创和无创血糖技术的发展。微创血糖检测技术对皮肤的损伤较小,常见的微创技术有皮下植入式生物传感器、超声渗析、微渗析等[2-3]。无创血糖检测技术主要集中在光学领域[4],光学方法优点是安全、快速、简单、经济,无创血糖测量技术在光学领域的应用主要集中于近红外光谱法、中红外光谱法、拉曼光谱法等[5-7]。
近红外光导检测器的灵敏度高且近红外光对皮肤的穿透能力高达1~100 mm,使近红外方法成为光学技术的研究重点。葡萄糖耐量实验(OGTT)为无创血糖研究中采集数据的经典方法,可以在短时间内采集实验所需的光谱数据和血糖浓度数据[8],但由于实验条件限制,采集的样本量是有限的。在近红外光测量人体葡萄糖浓度的研究中,通常选择的测量部位为手指、前臂、手掌等,但测得的葡萄糖光谱极易受到环境变化、个体差异、散射等多个因素影响,采集的数据存在较大误差[9-10]。
多因素干扰是近红外光测量血糖技术难以向前推进的重要原因,这些因素引起的误差直接影响回归模型预测血糖浓度的精确性。“M+N”理论认为误差来源主要为内部误差和外部误差,内部误差是血液中非目标成分对光谱的影响,外部误差成分则较为复杂,包括测量过程中产生的随机误差、皮肤的散射等[11-12]。一般最常用的方法是使用数据预处理方法和非线性回归模型联合的方法消弱多因素导致的误差。数据预处理可以有效减轻随机误差的影响,常用方法有归一化处理、叠加平均处理、多元散射校正等[13]。常用的非线性回归模型如支持向量机、神经网络、随机森林等算法可以从采集光谱中提取血糖的有效信息,提高无创血糖的预测精度[14-17]。
本文的目的是消除测量区域中不同位置点的光谱数据差异,使用的数据来自于OGTT实验获得的实验数据。在OGTT实验中,选取1 338~1 667 nm范围内共70个波长作为实验的测量波长,以手指指腹为测量区域。选取测量区域内11个位置点的数据作为实验数据,支持向量回归(SVR)作为回归模型,验证不同位置点数据的差异情况及减小不同位置点数据差异的可行性。
1 数据采集及处理
1.1 数据采集
本次实验采用OGTT葡萄糖耐量实验,参与实验的志愿者一名,实验时间为上午8:00-11:00,实验持续三天。实验所需设备有硬件计算机、Hyperspec™NIR近红外光谱扫描成像仪。近红外光谱仪采用固定位置扫描模式,光谱波长范围为1 338~1 667 nm,光谱分辨率为5 nm;积分时间为35 ms,采样帧频为100。具体实验仪器和采集系统如图1所示。

图1 光谱数据采集设备和采集系统示意图
图1(a)为近红外光谱仪,图 1(b)为光谱数据的采集系统。采集过程中志愿者将手指放入光谱仪固定位置,由光源照射手指产生的反射光进入光谱仪,由光谱仪成像并传入终端的计算机中保存。采集光谱数据的同时进行血糖浓度数据的采集,具体过程为刺取指尖一滴血,将其转移至酶测试纸和传感器进行测量,其精度符合CE标准(DIN EN ISO 15197)。
1.2 数据处理
实验中以手指指腹为测量区域,以测量区域的中心点位置和左右两侧各五个位置点的数据为实验数据,共11组位置点数据,分别记为中心点、左 1、左 2、左 3、左 4、左 5、右 1、右 2、右 3、右4、右5,如图2所示。通过Beer-Lambert定律计算出11个位置点的吸光度数据。每个位置点含有3 000条光谱数据,每条光谱数据有70个波长数据,其中每100条光谱数据对应同一个浓度标签,总共30个浓度标签。同一浓度对应的11个位置的吸光度存在明显的数据差异,因此将实验数据进行归一化处理。
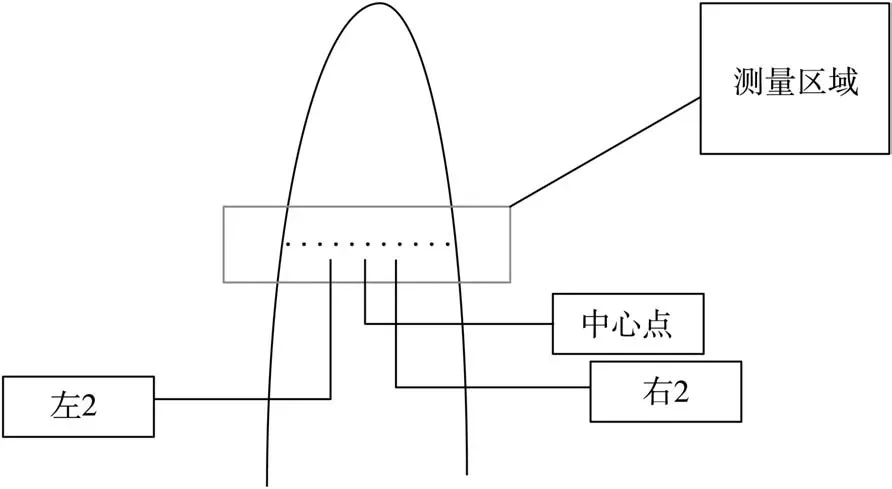
图2 手指测量区域示意图
2 方法
2.1 数据集
实验中采集到的光谱信号为手指的反射光,根据Beer-Lambert定律计算吸光度。吸光度数据作为SVR模型的特征数据,对应的血糖浓度数据作为标签数据。11个位置的吸光度数据共有11组,11组吸光度数据对应同一组浓度标签。每一个位置点的吸光度数据X和血糖浓度数据Y可表示为:


其中,m表示光谱条数;n表示波长个数。本文的实验数据中m=3000,n=70。
2.2 支持向量机SVR算法


3 实验设计与结果分析
本节共设计了3组实验。第一组实验验证不同位置点的数据存在明显差异;第二组实验证明了依次增加位置点的数据作为SVR的训练集,从剩余位置点的数据中随机选取数据作为测试集,仍然不能减小位置差异的影响;因此在第三组实验中进行改进,将11个位置点分成两部分,一部分数据平均后作为训练集,另一部分平均后作为测试集,验证该种方法是否可以减小不同位置点的数据差异。
3.1 评价指标
在本文中,评价模型的预测效果使用克拉格误差网格中的平均克拉克网格误差(P为落在网格A区的概率)和MAE、MSE作为评价指标。克拉克误差网格是评价血糖预测准确度的一个经典方法,网格的A区域代表预测效果最好的区域;MSE为均方差,是指预测值与真实值之差平方的期望值;MAE为平均绝对值误差,是观测值与真实值的误差绝对值的平均值。公式如下:
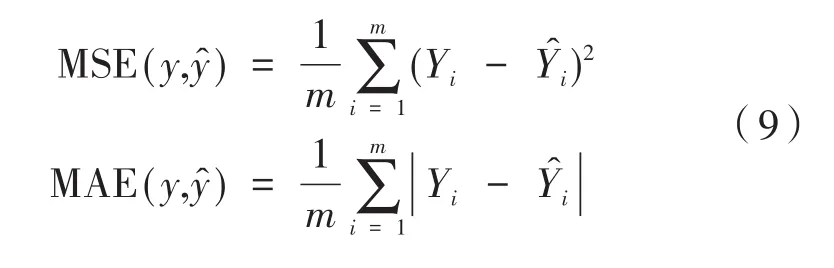
3.2 实验设计及结果分析
3.2.1 第一组实验
第一组实验中一次选择两个不同位置点数据,一个位置点数据作为训练集,另一个位置点数据作为测试集。为方便进行比较,固定左1位置数据作为训练集,其他10个位置的数据依次作为测试集,使用SVR回归模型得到测试集预测结果,如表1所示。在表1中,对于两个相邻位置点,如左1、左2,SVR的预测效果较好;对于不相邻的位置点,预测效果较差,而且位置间隔越远,训练效果越差。这表明邻近位置点的数据的信息相似度更高,距离较远的位置点的数据相似度越低。
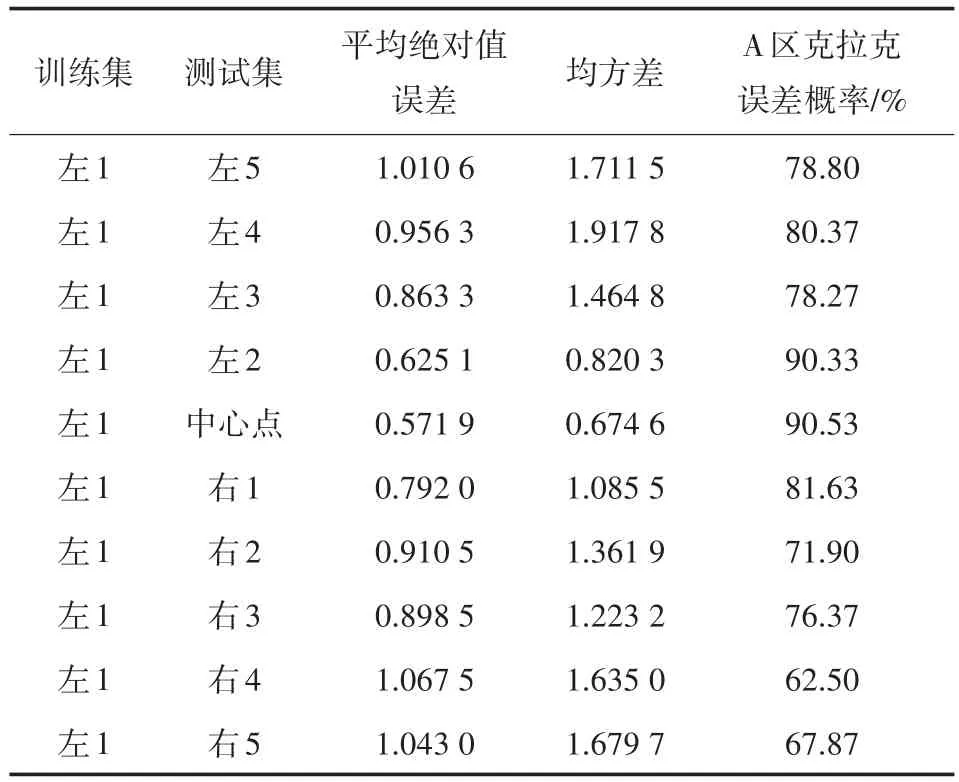
表1 第一组实验结果
3.2.2 第二组实验
第二组实验考虑到使用OGTT实验采集数据的过程中,每次手指放置在近红外光谱仪的位置有偏差,不能保证每次采集到同一位置的光谱数据,因此在实验设计中测试数据和训练数据属于不同的位置点数据。
位置点个数为3,即以中心点位置和左1、右1位置的混合数据作为训练集,从剩余8个位置的数据中随机选取1 000条作为测试集,使用SVR回归模型得到预测结果;位置点个数为5,即以中心点位置和左1、左2、右1、右2位置的混合数据作为训练集,从剩余6个位置的数据中随机选取1 000条作为测试集,在实验数据上依次累加两个位置点的数据作为测试集,从未被训练过的位置点的数据中随机抽取1 000条数据作为测试集,重复上述步骤。实验结果如表2所示,未参与训练的位置点数据作为测试集的预测结果整体在75%左右,预测效果较差。
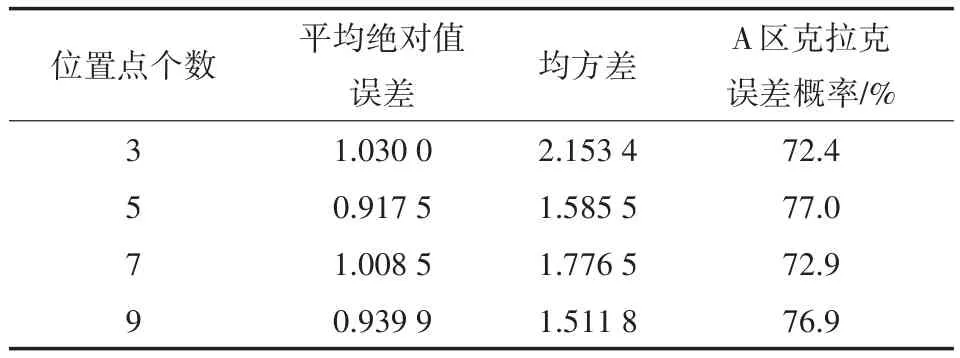
表2 第二组实验结果
3.2.3 第三组实验
原有11组位置点的数据,选取左5、左3、左1、右1、右3、右5共6组数据进行数据平均处理为1组数据,记为新数据1,剩余5个位置的数据进行数据平均处理为1组数据,记为新数据2。将平均处理过后的2组新数据,1组作为训练集,另一组作为测试集,使用SVR回归模型得到测试集预测结果,得到的结果如表3所示,克拉克误差网格图如图3所示。
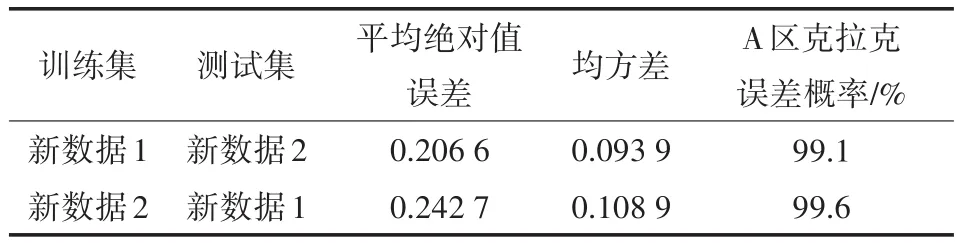
表3 第三组实验结果
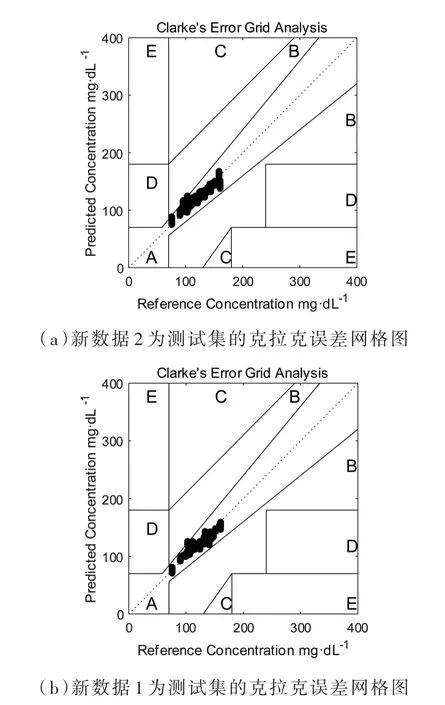
图3 两组实验的误差网格图
由实验结果可以看出,经过平均处理的两组数据的位置差异明显减小,并且克拉克误差网格图表明SVR模型的预测效果良好,两次实验在网格图中A区的样本量达到99%以上,表明第三组实验可以有效降低位置差异的影响。
4 结论
在无创血糖监测领域,OGTT实验是采集血糖数据的经典方法,本文使用OGTT实验获得光谱数据和血糖浓度数据。针对实验数据中不同位置点存在的数据差异问题,设计3组实验验证并成功减小了不同位置点的数据差异。从另一方面来看,减小不同位置点数据的差异一定程度上增加了可用的样本量,在血糖预测的深度回归模型中,大样本量对模型的最终预测有一定的帮助。
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11 03:18:56
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:40
中国特种设备安全(2019年1期)2019-03-13 01:06:26
北京航空航天大学学报(2017年6期)2017-11-23 05:57:36
浙江大学学报(工学版)(2016年10期)2016-06-05 09:20:56
山东青年(2016年2期)2016-02-28 14:25:41
中国光学(2015年5期)2015-12-09 09:00:28
