
基于卷积神经网络的评论文本兴趣点推荐算法①
2022-08-25 02:52申晋祥鲍美英
计算机系统应用 2022年8期
申晋祥, 鲍美英
(山西大同大学 计算机与网络工程学院, 大同 037009)
1 引言
近年来, 随着社交网络、智能手机以及移动设备自动定位技术的发展, 使得基于位置的社交网络(locationbased social networks, LBSN)得以快速发展[1], 典型的LBSN应用有Foursquare、Yelp、Gowalla、Facebook、大众点评和街旁等, 在LBSN中兴趣点(point-of-interest,POI)推荐是目前研究的热点.
POI推荐注重研究用户和POI的相关信息对用户行为的影响, 更好地了解用户可能感兴趣的地理位置及出行活动, 探索新的POI以便在正确的时间为用户进行合适的推荐, 有效解决了大数据环境下“信息过载”的问题[2–5], 丰富用户的生活体验, 同时也对促进旅游发展、商家精准营销等, 提高经济收入具有重要意义.
基于LBSN的POI推荐已有大量研究[6–9], 其中大多数的研究都是考虑地理位置、用户签到行为、社交关系、兴趣点类别、流行度、评论文本以及时间因素等, 融合多个因素进行POI推荐, 实验证明推荐模型能够提高POI推荐性能. 但仍然存在签到数据稀疏、评论文本信息利用不够充分等问题. 高榕等人[10]提出GeoSoRev模型, 融合兴趣点的评论文本信息、用户社交关联以及地理位置信息3个因素进行POI推荐, 采用基于矩阵分解的主题模型挖掘评论文本中的隐藏“主题”, 模型在准确率和召回率等多个指标都有明显提高. 王啸岩等人[11]提出SoGeoCom模型, 融合兴趣点评论文本信息、用户社交网络和地理位置信息进行POI推荐, 采用隐狄利克雷分布(latent Dirichlet allocation,LDA)从评论文本中获取主题以及表征主题词, 有效提高推荐准确率和召回率. 但所述模型都是基于词袋或文档主题模型处理评论文本信息[12], 不能深度提取评论文本的潜在特征表示. 目前基于卷积神经网络(convolutional neural network, CNN)技术已广泛应用于文本处理. 冯浩等人[13]提出MFM-HNN模型, 融合评论文本信息和用户签到信息以提高兴趣点推荐性能,利用卷积神经网络处理评论文本信息提取特征表示,捕获更精确的上下文特征, 具有更好的推荐性能, 但模型没有能够基于深度学习技术融合多种上下文信息.
基于上述原因, 提出RT-CNN模型, 通过CNN处理评论文本内容深度提取上下文语义和情感信息, 深度挖掘用户情感倾向、用户兴趣偏好以及位置兴趣点属性信息, 再融合签到行为和地理影响因素进行POI推荐. 实验证明模型能够有效提高推荐性能.
2 基于CNN的评论文本兴趣点推荐模型
在LBSN中有大量的历史签到数据, 其中所包含的多源异构信息为深入分析用户兴趣偏好进而为用户推荐偏好的POI提供丰富的内容. 主要有签到的POI地理位置、时间、POI的类别、用户的社交以及评论等信息, 推荐模型可以融合多个因素, 采用不同方法从签到数据中提取相关信息以便准确为用户生成POI推荐. 为便于后叙内容理解, 表1列出了所用符号解释.

表1 符号解释
2.1 地理位置建模
通常情况用户更偏好距离自己活动空间较近的POI,正如Tobler地理学第一定律所讲的任何事物都相关,距离近的事物之间的相关性更大. 在实际生活中, 用户在远离其生活空间的POI签到概率较小, 因此地理位置的远近对用户的签到行为有很大影响. 为预测用户ui对未签到位置lj的签到兴趣, 可由以下优化过程得到.

其中,H∈RM×N为签到权重矩阵,Hij为1表示用户ui在位置lj有签到, 为0表示没有签到. 把矩阵参数U、L的两个正则化项加入式(1)防止过拟合, 如式(2):
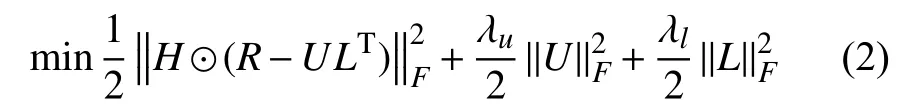
其中,λu、λl是正则化参数,是Frobenius范数, 其优化问题采用梯度下降的方法获得局部最优解.
由事物相关性规则, 如果用户对位置lj的邻近若干位置感兴趣则对位置lj感兴趣的可能性也很大, 因此可以对矩阵分解模型中缺少的地理位置通过邻近位置加权的方法加以补全, 目标函数的最小化如式(3)所示:

其中,B=γULT+(1-γ)AT,A∈Rn×n, γ是邻近位置影响是正则化项,sim(lj,lx)的权重参数,是位置lj邻近位置lx的地理权重, 采用高斯函数如式(4):
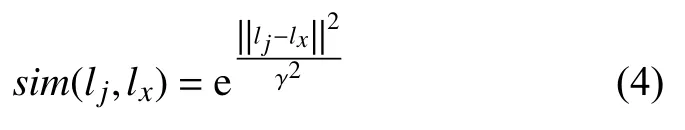
2.2 评论文本建模
充分利用评论文本信息能够有效缓解签到数据稀疏问题, 采用CNN能够深度挖掘评论文本潜在特征,将其融入POI推荐有重要作用.
2.2.1 用户情感倾向建模
利用CNN处理评论文本信息获取用户情感倾向模型, 以词向量作为输入数据, 以情感倾向作为输出数据. 模型分为4层: 嵌入层、卷积层、池化层和输出层.具体过程如下:
1)嵌入层: 将用户ui的所有评论文本的单词合并成一个文档, 利用词向量模型将每个单词按照出现的先后顺序映射为相应的词向量, 生成用户ui词序不变的词向量矩阵. 如式(5)所示, 其中,wp表示第p个词的词向量表示.

2)卷积层: 把输入的用户词向量矩阵Mi进行卷积操作提取新的特征, 每个神经元Nq中对应d×t的过滤器Fq,d表示嵌入维度,q表示卷积窗口大小, 每层有y个神经元, 每个卷积对应产生一个特征如式(6):
其中,f表示激活函数ReLU, ⊗表示卷积操作,bq是过滤器Fq对应的偏置项.

3)池化层: 采用最大池化操作从上下文特征向量中提取最大的特征向量生成新的固定维度的特征, 最大池化操作能够有效处理评论文本长度不同的问题,对特征进行压缩减小其规模, 并且只提取主要特征, 即降低网络计算的复杂度又避免过拟合的现象. 池化特征表示如式(7)所示:

4)输出层: 将池化层中提取的评论文本情感特征向量输入到Softmax函数, 计算各情感的预测概率并和标准实验数据对比获得误差, 采用梯度下降和反向传播进行误差传递来更新参数.
模型最后输出用户情感倾向分为3种: 1、0、-1,1表示感兴趣, 0表示一般, -1表示不感兴趣. 结合签到权重矩阵, 通过函数重构使得情感评分S值在(-1, 1)范围, 显然用户签到行为与用户情感分数相关.
2.2.2 用户兴趣与位置POI属性建模
对于位置POI评论文本内容通过CNN能够深度提取其潜在特征, 采用Softmax逻辑回归函数定义用户发布评论的概率函数如式(8)所示:
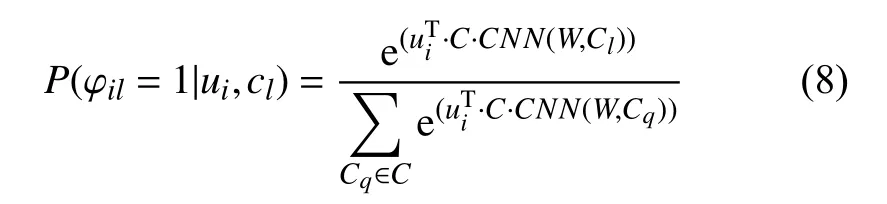
其中, φil表示用户ui是否发布了评论cl,cl是评论文本集合,C∈Rq×d是一个交互矩阵, 用来分析用户ui是否发布了评论cl,CNN(W,Cl)表示通过CNN提取的评论文本特征,W是CNN的内部权重. Softmax函数的输出值相互关联, 其概率总和为1, 要获取用户潜在特征向量ui, 将概率函数式(8)转换为目标函数式(9)求解得到.
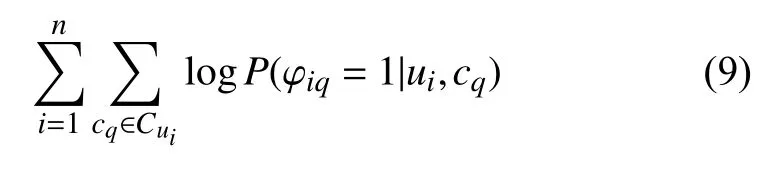
与此同理, 分析评论ck与位置lj的相关性概率函数如式(10)所示:
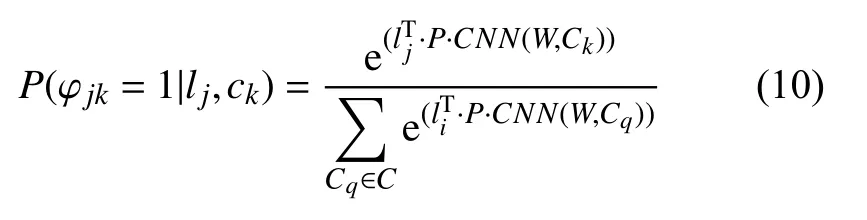
要获取位置潜在特征向量lj, 将概率函数式(10)转换为目标函数式(11)求解得到.

3 RT-CNN模型优化及算法实现
RT-CNN模型融合签到行为R、地理位置影响B、用户情感倾向S、用户潜在特征U以及位置潜在特征L, 针对签到数据R稀疏的问题, 通过卷积神经网络处理,充分挖掘和利用评论文本信息能够有效缓解, 其中的S、U、L都是从卷积神经网络中学习得到的,W是卷积神经网络权重值,P是概率函数. RT-CNN模型需要解决最大化优化问题, 优化问题利用梯度下降的方法学习目标函数局部最优解. 在词向量模型中, 主要有Skipgram和CBOW两种模型, 前者是给定文中的某个词来预测上下文内容, 而后者是给定上下文来预测上下文之间的结果. Skip-gram模型虽然预测次数要多于CBOW,但通过多次的预测、调整会使得词向量更加准确. 因此,通过Skip-gram模型获取词向量矩阵. 负抽样不仅能够减少训练过程的计算负担, 而且还能提高其结果词向量的质量, 采用负抽样方法近似计算目标函数.
RT-CNN算法的伪代码如算法1.

算法1. RT-CNN算法的伪代码Cuiui∈U Cljlj∈L输入: R, , , ,输出: Top-N POI 1)随机初始化W、U、L、P、C 2)采用CNN获取用户情感倾向S的值3)通过U和L计算B 4) While (not convergent) do∂ξ∂U∂ξ∂L∂C∂ξ∂ξ∂P∂ξ∂B 5)计算 , , , ,U←U+η∂ξ∂U 6)进行更新7) L、C、P、B分别类同6)依次进行更新8)通过反向传播方法调整CNN中的参数9) End UTL 10)计算 推荐Top-N POI给用户
4 实验结果与分析
4.1 实验数据集
为了验证RT-CNN模型的性能, 需要进行一次实验. 选用Foursquare网站(https://download.csdn.net/download/weixin_41665541/10219398)数据集中纽约(NYC)和洛杉矶(LA)的签到及评论数据, 对两个数据集进行预处理, 过滤掉签到次数小于10的用户和访问次数小于10的POI, 实验数据集统计如表2所示. 数据集分成3份, 80%作为训练集, 10%作为验证集,10%作为测试集.

表2 实验数据集统计
4.2 评价指标的设定
使用精确率(Precision)和召回率(Recall)作为评价指标评估算法的性能, 简记为P@N、R@N, 对于一个用户u, 其计算公式如式(12)和式(13).
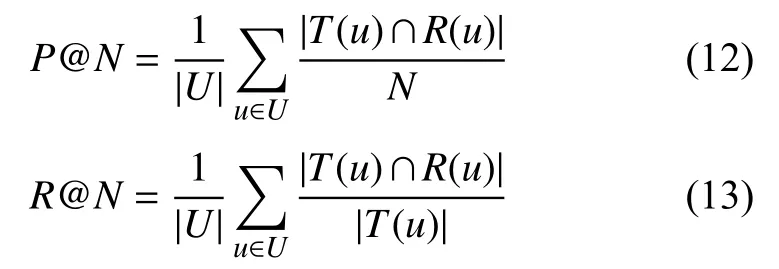
其中,T(u)表示测试集中用户u签到过的POI列表,R(u)表示为用户u推荐的POI列表.
4.3 不同模型比较
选择较新的典型先进模型: SoGeoCom模型[9]、TGSC-PMF模型[12]和MFM-HNN模型[13]与RT-CNN模型比较, 设定N=1, 5, 10. 基于NYC数据集的实验结果如图1和图2所示.
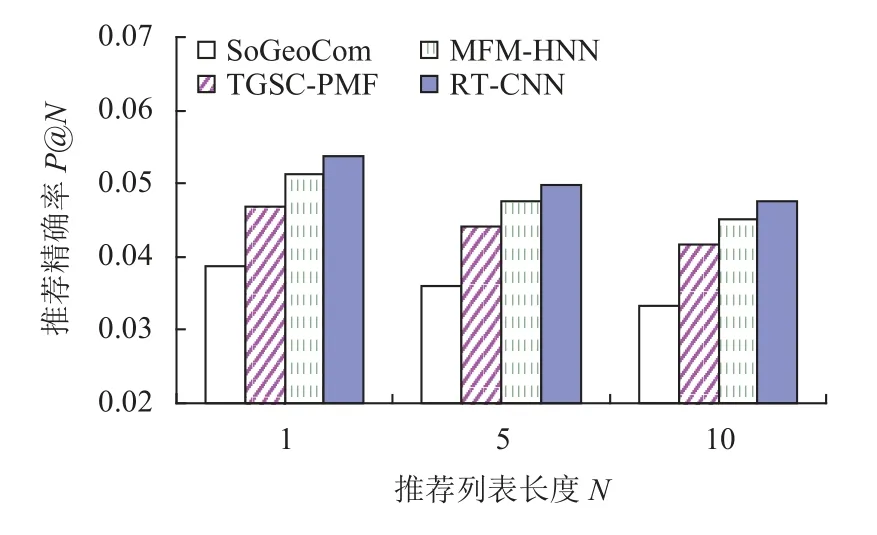
图1 不同模型基于NYC数据集的精确率对比

图2 不同模型基于NYC数据集的召回率对比
基于LA数据集的实验结果如图3和图4. 由实验结果分析得出, RT-CNN模型在两个数据集上精确率和召回率都高于其他模型. 其中, SoGeoCom模型融合用户社交、地理位置及POI评论文本进行推荐, 认为用户是否真正访问某POI是由3方面因素决定, 分别是用户对POI的兴趣、用户与POI之间的心理距离和物理距离. 兴趣方面可通过对用户的评论文本进行挖掘得到, 心理距离和物理距离则通过社交网络关系建模和地理位置信息建模来获得. 兴趣越大、距离越近,访问概率就越高, 对缓解签到数据稀疏以及冷启动方面有较好的效果. 但是, 模型使用LDA处理评论文本信息, 忽略了评论文本语义上下文信息, 因此表现最差.TGSC-PMF模型通过挖掘兴趣点评论文本信息, 了解用户的兴趣意向, 采用一种自适应带宽核评估方法构建兴趣点之间的地理相关性, 通过分析用户社会关系构建用户之间的社会相关性, 针对用户的分类喜好和兴趣点的流行度构建分类相关性. 最后将各相关分数进行匹配并融合到概率矩阵分解模型中. 也是使用LDA处理评论文本信息, 但模型融合了POI评论文本、地理、社交、分类与流行度信息, 并利用概率矩阵分解模型进行有效处理, 推荐性能高于SoGeoCom模型, 表明融合多种因素能提高推荐性能. MFMHNN模型融合评论信息与用户签到信息进行推荐, 通过CNN充分考虑词序及上下文信息获取评论文本潜在特征表示, 克服了LDA处理评论文本信息所存在的问题, 并利用深度堆栈降噪自动编码器研究了特征矩阵的初始化问题, 推荐性能高于TGSC-PMF模型. 所提模型RT-CNN通过CNN深度挖掘评论文本信息,获取用户情感倾向、用户兴趣偏好以及位置POI属性信息, 融合签到行为以及地理位置影响进行推荐, 在签到数据稀疏的情况下充分利用评论文本隐含的潜在语义和情感信息, 有效地提高了位置POI推荐性能, 实验结果表明, RT-CNN模型具有最好的推荐效果.
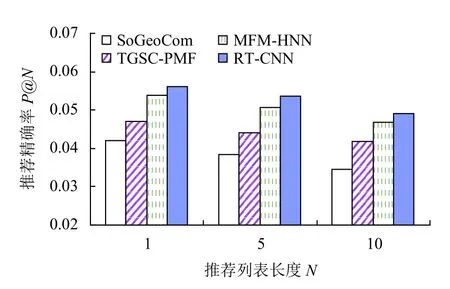
图3 不同模型基于LA数据集的精确率对比
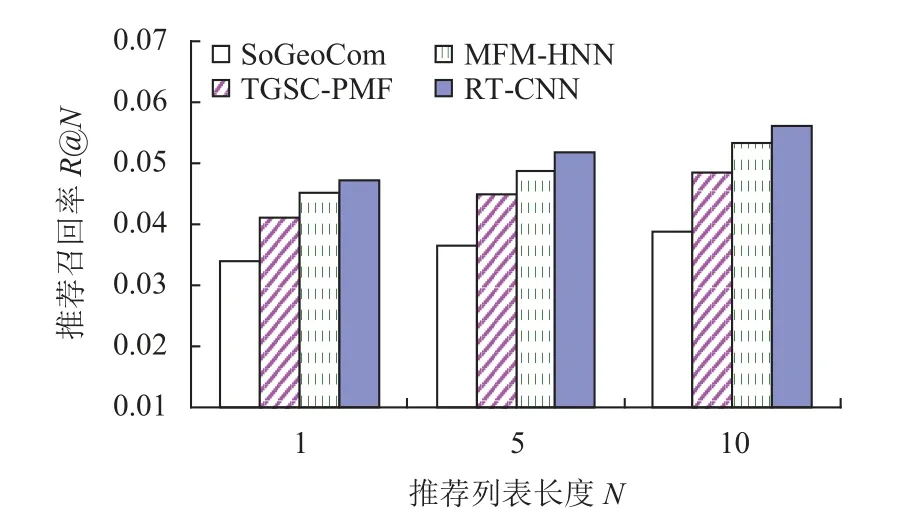
图4 不同模型基于LA数据集的召回率对比
通过不同模型在两个数据集上精确率和召回率的实验结果可以看出, 随着推荐列表长度N值的增大, 推荐精确率P@N逐渐减小, 推荐召回率R@N逐渐增大.这是因为推荐列表中POI的数目越多, 用户真正访问的POI在推荐列表中的比例显然会降低, 也就是说在推荐列表中有很多列出的POI并不是用户真正访问的POI, 从而导致推荐精确率下降. 然而随着推荐列表中POI数目的增加, 则会有更多的用户真正访问的POI出现在推荐列表中, 使得推荐召回率增加.
5 结束语
为缓解位置POI推荐中签到数据稀疏问题, 提出一种RT-CNN模型, 基于卷积神经网络深度提取评论文本内容的隐含信息, 对位置POI和用户进行建模, 同时融合签到行为以及地理位置信息进行POI推荐. 通过实验与其他模型对比, 结果表明模型提高了精确率和召回率, 具有更优的推荐效果.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小天使·三年级语数英综合(2022年4期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
读与写·教育教学版(2017年10期)2017-11-10
汽车导报(2017年5期)2017-08-03
中国新通信(2017年9期)2017-05-27
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
南都周刊(2015年4期)2015-09-10
