
满足LDP的多维数据联合分布估计①
2022-08-25 02:52褚雪君龙士工
计算机系统应用 2022年8期
褚雪君, 龙士工, 刘 海
1(贵州大学 计算机科学与技术学院, 贵阳 550025)
2(贵州大学 贵州省公共大数据重点实验室, 贵阳 550025)
1 引言
随着移动互联网与大数据的发展, 数据规模也以前所未有的速度不断增长, 数据属性之间的相互关系变得复杂多样, 多维数据已是一种常见的数据发布类型[1]. 在实际应用中, 大量的多维数据被存储在多个分布式组织中, 进行集成后, 这些多维数据将成为做出更好决策和提供高质量服务的宝贵资源.由于数据挖掘和分析技术的提升, 发布多维数据会带来很高的信息价值, 但多维数据中常包含许多隐私信息, 为了保护这些隐私信息在数据发布的过程中不被泄露, 通常会使用差分隐私保护技术. 传统的差分隐私技术将原始数据集中到一个中心服务器, 然后发布满足差分隐私的信息, 通常称其为中心化差分隐私保护(CDP). 因此中心化差分隐私技术始终基于一个可信的第三方数据收集者并保证不会窃取或泄露用户的敏感信息的前提. 然而想要找到一个真正可信的第三方数据收集者是非常困难的. 鉴此, 在缺少可信的第三方数据收集者的情况下, 本地化差分隐私(LDP)[2–4]应运而生, 目前已在业界得到应用. 但多数的本地化差分隐私技术不适用于多维数据, 若直接将其应用于多维数据会造成通信开销较大, 可用性差等问题.
目前, 本地化差分隐私技术已经成为继中心化差分隐私技术之后一种强健的隐私保护模型. 首先, 用户对原始数据进行满足 ε-本地化差分隐私的扰动, 然后将其传输给第三方数据收集者, 数据收集者收到扰动后的数据再进行一系列的查询和求精处理, 以得到有效的统计结果. 对本地化差分隐私的研究和应用, 主要考虑以下两个方面问题: (1) 如何设计满足ε -本地化差分隐私的扰动算法; (2) 数据收集者如何对收集到的数据集进行求精处理, 以提高统计结果的可用性. 本文中,求精处理即通过基本推理和机器学习的方法来捕捉收集到数据集的联合概率分布[5–7]的过程.
为解决数据收集阶段的隐私泄露, 本地化差分隐私保护通信开销较大以及数据收集者求精处理的问题,本文提出了RR-LDP算法和LREMH算法, 主要工作如下:
(1) 提出了一个适用于多维数据的本地差分隐私保护算法(RR-LDP). 该算法相比直接将RAPPOR[8]应用于多维数据上极大地降低了通信开销.
(2) 结合期望最大化(EM)算法和LASSO回归模型, 提出了一种高效的多维数据联合分布估计混合算法(LREMH). 在真实数据集上进行性能评估, 实验结果表明LREMH算法在精度和效率之间取得了平衡.
2 相关工作
Erlingsson等人[8]提出RAPPOR应用随机响应技术和布隆过滤器来实现本地化差分隐私, 并应用在谷歌浏览器上. 苹果的差分隐私团队提出使用one-hot编码技术对敏感数据进行编码, 并部署CMS算法分析Safari中最流行的表情符号和媒体播放偏好. 文献[9]通过结合LDP与集中式数据模式, 提出具有高可用性的混合模型BLENDER. 文献[10]针对移动设备收集隐私数据问题, 构建了Harmony系统, 该系统支持满足LDP的统计分析与机器学习功能. 随机响应技术及其变体在收集分布式用户统计数据的安全性方面具有优势, 已成为LDP研究的热点. 但目前多数的LDP机制并不适用于多维且多值的数据.
Giulia等人[11]提出基于EM的学习算法从噪声样本空间中估计联合概率分布. 然而它们的方案适用于二维数据, 当维数较高时, 数据的稀疏性会导致很大的效用损失, EM算法的复杂度也会呈指数级上升. Ren等人[12]打破了文献[11] EM算法的局限, 将其拓展用于处理多维数据. Li等人[13]提出使用Copula函数来模拟多维数据的联合分布, 但Copula函数不能处理小域的属性. Cormode等人[14]将Hadamard变换应用于发布本地边缘表, 其优势是节省了通信开销, 但只适用于二进制数据. Zhang等人[15]借鉴PriView[16]的思想提出CLMA方法, 该方法可以在不计算满边际的情况下释放任意方向的边缘表, 并且可以处理非二进制属性.然而, 除了隐私保护带来的噪声误差外还引入了采样误差.
3 基础知识
3.1 本地化差分隐私(LDP)
定义1. ε - 本 地化差分隐私. 对于一个有N条记录的数据集D, 给定随机算法Q满足ε -本地化差分隐私保护,Range(Q) 为随机算法Q的取值范围, 那么算法Q在任意两条记录X1和X2(X1,X2∈D)上得到相同的输出结果X*的概率满足:
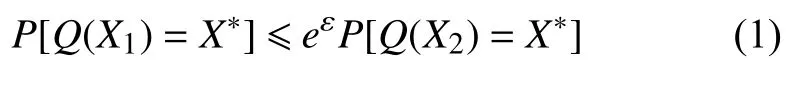
其中, 概率P[·]表 示隐私泄露风险, ε表示隐私预算, 代表了隐私保护水平, 其值越小表示不可区分性越大, 隐私保护等级越高.
性质1. 序列组合性[17]. 给定数据集D和n个隐私算法{Q1,···,Qn} 且算法Qi(1≤i≤n) 满足εi-本地化差分隐私, 那么{Q1,···,Qn}在D上 的序列组合满足ε -本地化差分隐私, 其中,
3.2 随机响应技术
随机响应技术(randomized response) 是本地化差分隐私保护的主流扰动机制, 旨在调查过程中使用随机化装置, 使被调查者以一个预定的概率p进行诚实的回答, ( 1-p)的概率随意进行回答. 除被调查者以外的任何人均不知道被调查者的回答是否真实, 最后根据概率论的知识计算出敏感问题特征在人群中的真实分布情况的一种调查方法. 假设对n个用户的问答进行统计, 得到患病人数的统计值. 其中真实患病的比例记为π, 假定回答“Yes”的人数为n1, 回答“No”的人数记为n2.根据诚实回答的概率θ 可得:
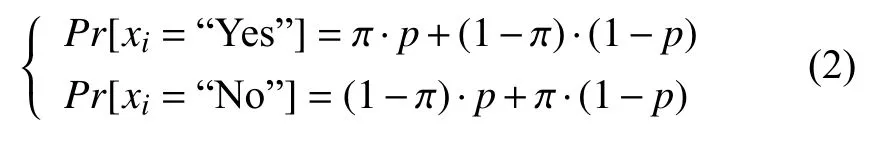
为了得到无偏估计, 可以采用极大似然的方法进行估计:
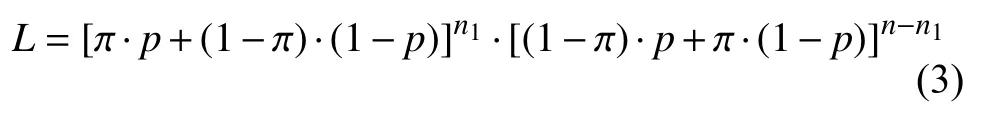

则患病的人数可估计为:

4 满足LDP的多维数据联合概率分布估计
4.1 设计思路
首先, 根据属性域的大小和每个取值在属性域中的位置将所有变量映射为位串, 得到的位串代表了唯一的原始记录. 然后, 通过随机响应技术进行第一次扰动, 得到的结果称作永久随机响应, 并将其保存在用户本地, 在第三方数据收集者请求数据时, 对永久随机响应的结果再做一次扰动, 得到的结果称作瞬时随机响应, 将瞬时随机响应的结果发送给第三方数据收集者.最后, 数据收集者聚合收集到的得到随机噪声样本空间, 利用机器学习技术, 可以从中估计联合概率分布,进行求精处理.
本文所使用的相关符号定义如表1所示.
4.2 本地差分隐私保护
在本文的本地化差分隐私保护机制设计如算法1所示, 其中包含3个关键的步骤.

算法1. RR-LDP算法xij,j=1,2,···,d Aj f|Ωj|输入: 用户数据记{ }, 属性集 , 随机翻转概率, 位串长度Ti输出: 随机翻转后的位串1≤j≤d 1. for xij |Ωj| sij 2. 根据取值将 映射为一个长为 的位串f sij ˆsij 3. 根据 随机翻转 中的每一位, 得到扰动后的位串4. end for ˆsij Tij 5. 对 进行瞬时随机扰动, 得到∑dj=1|Ωj| Ti 6. 将翻转后的每个位串连接起来得到一个 位的向量 并返回

上述过程为永久随机响应. 永久随机响应可以保证用户端相互通信时的隐私安全问题, 抵御纵向攻击.由于每条记录中所有属性的取值是独立的, 故所得到的二进制位串可唯一代表一条记录.

由于服务器每次请求数据时都要做一次瞬时随机响应, 所以服务此每次请求相同的数据得到的结果都是不同的, 此时就可以保证服务器不能通过多次请求数据进行推断攻击.
在本文的RR-LDP方案采用一元编码的方式进行二进制转换, 相比于RAPPOR[8]所使用布隆过滤器进行二进制转化的方法, 本文映射后的位串长度更小且由于布隆过滤器使用哈希函数进行映射会出现哈希冲突造成映射后的位串冲突, 而RR-LDP则不会.

4.3 隐私分析
定理1. 在用户端进行的永久随机响应过程满足ε1-本地化差分隐私, 其隐私保护等级为:

证明: 令S表示用户初始的位串,S′表示经过本地随机翻转的位串.S1和S2分别代表两个不同用户的记录, 令它们的条件概率比值记作RR,RR=P(S′=S*|S=S1)/P(S′=S*|S=S2), 它与隐私保护等级ε1相关. 由式(6)可以得到位串的每一位翻转的概率为f/2, 不翻转的概率为1 -f/2, 由文献[8]可得到RRmax=((2-f)/f)2,此时的隐私保护等级 ε1=2ln((2-f)/f) , 其中f为随机翻转概率. 根据差分隐私序列组合性质[17],d维数据记录的本地翻转满足 ε1- 本地化差分隐私, 其ε1=2dln((2-f)/f) , 其中d为原始数据集D中属性的个数.
定理2. 在用户端进行的瞬时随机响应过程满足ε2-本地化差分隐私, 其隐私保护等级为:

证明过程与定理1类似, 详见文献[8]. 因为相同的转换是由所有用户独立完成的, 所以上述本地化差分隐私保护适用于所有分布式用户.
4.4 基于期望最大化算法(EM)的联合分布估计算法
EM算法是在存在缺失或不完整数据的情况下获得最大似然估计的常用方法. 它特别适合于RAPPOR[8]这种只收集它们的噪声表示且真实值未知的应用中.文献[12]中的EM算法主要分为以下3步:
P(ω1ω2···ωk)=1/(∏kj=1|Ωd|)
第1步: 初始化, , 设置均匀分布分布作为初始的先验概率;

EM算法具有较高的精度, 但对初始值比较敏感,当初始值选择合适时, 上述方法能达到较好的收敛效果. 然而文献[12]将联合分布初始化为均匀分布, 显然不是最优的, 当属性个数k增大时, 由于Ω1×Ω2×···×Ωk中所有组合的样本空间爆发性增长, 算法的复杂度也会急剧上升, 阻碍良好的收敛. 同时多维数据呈现出的稀疏性也会带来较大的误差, 从而导致最终的估计达不到所需的效用.
4.5 基于LASSO回归的联合分布估计算法
LASSO回归最早由Tibshirani于1996年提出[18],文献[8]将它和最小二乘法用于收到噪声样本后的解码工作. 如第4.1节所述, 位串是原始记录的唯一代表. 随机翻转后, 本地用户会产生大量不同程度的噪声样本. 此时,可以利用Mβ来估计噪声样本空间的联合分布, 其中M是预测变量,是响应变量, β是回归系数向量, 这里的目的是估计M上的分布, 而不是原来的域. 响应变量→y可以根据已知的随机翻转概率f, 从位串中估计出来. 因此, 唯一的问题就是求出一个准确的回归系数 β.基于LASSO回归的联合分布估计主要包含以下几步:

4.6 LREMH算法
基于EM的算法在样本足够的情况下, 可以表现出良好的收敛性, 但也会产生很高的复杂度. 其高复杂度是因为它迭代扫描用户的数据, 并构建一个先验分布表, 其大小为然而, 在多维情况下, Ωj的组合是非常稀疏的, 且有很多零项. 同时, 由于EM对初始值的选择敏感, 均匀分配的初始值会导致收敛速度较慢. 然而基于LASSO回归的联合分布估计方法可以有效地解决由于多维数据的稀疏性导致的过拟合和效率慢的问题, 但与基于EM的算法相比, 精度略有下降.
为了在精度和效率之间取得平衡, 本文提出了LREMH算法, 该算法首先用基于LASSO回归的方法估计初始值, 这样得到的初始值会比均匀分布的初始值更加精确, 同时对基于EM算法的收敛性有积极的改进作用, 然后根据LASSO回归模型计算出冗余候选项, 并消除他们, 从而提高计算效率, 最后使用EM算法进行迭代计算得到一个较为准确的估计值.

算法2. LREMH算法Aj|Ωj|f CTi输入: , , , 索引集 ,P0(ω1ω2···ωk)输出:j∈C 1. for each do···|Ωj|2. for each b=1, 2, , do ˆyj[b]=∑Ni=1Tij[b]3. 计算yj[b]=[ˆyj[b]-N(p+0.5fq-0.5fp)]/(1-f)(q-p)4. 计算5. end for 6. end for→y=[y1[1],···,y1[|Ω1|]|···|yk[1],···,yk[|Ωk|]]7. 令M=[(Ω1)×(Ω2)×···(Ωk)]8. 令→β=Lasso(M,→y)9. 计算 /*使用回归分析计算初始值*/P0(ω1ω2···ωk)=→β/N 10. 返回C′={x|x∈C,P0(x)=0}11. 令i=1,···,N 12. for each do j=1,···,k 13. for each do···|Ωj|14. for each b=1, , do Tij[b]=1 15. if P(Tij|ωj)=∏|Ωj|b=1q*images/BZ_236_1717_1856_1722_1881.pngimages/BZ_236_1717_1866_1722_1891.pngimages/BZ_236_1717_1876_1722_1901.pngimages/BZ_236_1717_1887_1722_1912.pngimages/BZ_236_1717_1897_1722_1922.pngTij[b]·ωj[b]images/BZ_236_1857_1856_1862_1881.pngimages/BZ_236_1857_1866_1862_1891.pngimages/BZ_236_1857_1876_1862_1901.pngimages/BZ_236_1857_1887_1862_1912.pngimages/BZ_236_1857_1897_1862_1922.pngp*images/BZ_236_1897_1856_1902_1881.pngimages/BZ_236_1897_1866_1902_1891.pngimages/BZ_236_1897_1876_1902_1901.pngimages/BZ_236_1897_1887_1902_1912.pngimages/BZ_236_1897_1897_1902_1922.pngTij[b]-ωj[b]images/BZ_236_2040_1856_2046_1881.pngimages/BZ_236_2040_1866_2046_1891.pngimages/BZ_236_2040_1876_2046_1901.pngimages/BZ_236_2040_1887_2046_1912.pngimages/BZ_236_2040_1897_2046_1922.png16. 计算17. else P(Tij|ωj)=∏|Ωj|b=1(1-q*)images/BZ_236_1772_1980_1778_2005.pngimages/BZ_236_1772_1991_1778_2016.pngimages/BZ_236_1772_2001_1778_2026.pngimages/BZ_236_1772_2012_1778_2036.pngimages/BZ_236_1772_2022_1778_2047.pngTij[b]-ωj[b]images/BZ_236_1915_1980_1921_2005.pngimages/BZ_236_1915_1991_1921_2016.pngimages/BZ_236_1915_2001_1921_2026.pngimages/BZ_236_1915_2012_1921_2036.pngimages/BZ_236_1915_2022_1921_2047.png(1-p*)images/BZ_236_2011_1980_2017_2005.pngimages/BZ_236_2011_1991_2017_2016.pngimages/BZ_236_2011_2001_2017_2026.pngimages/BZ_236_2011_2012_2017_2036.pngimages/BZ_236_2011_2022_2017_2047.pngTij[b]-ωj[b]images/BZ_236_2154_1980_2160_2005.pngimages/BZ_236_2154_1991_2160_2016.pngimages/BZ_236_2154_2001_2160_2026.pngimages/BZ_236_2154_2012_2160_2036.pngimages/BZ_236_2154_2022_2160_2047.png18. 计算19. end if 20. end for 21. end for ω1ω2···ωk∈C′22. if P(Ti1···Tik|ω1···ωk)=0 23.24. else P(Ti1···Tik|ω1···ωk)=Πj∈CP(Tij|ωj)25. 计算26. end if 27. end for 28. 初始化 t=0 /*迭代次数*/29. repeat i=1,···,N 30. for each do ωc∈(Ω1)×(Ω2)×···(Ωk)31. for each do Pt(ωc|TiC)=Pt(ωc)·P(TiC|ωc)/ΣωCPt(ωc)·P(TiC|ωc)32.33. end for 34. end for Pt+1(ωc)=∑Ni=1Pt(ωc|TiC)/N 35. 令36. 更新t=t+1 maxPt(ω1ω2···ωk)-maxPt-1(ω1ω2···ωk)≥δ 37. 直到P(Ac)=Pt(ωc)38. 返回
本文提出的LREMH算法主要包含以下3个步骤:
第1步: 计算初始值, 根据永久随机响应翻转概率f和瞬时随机响应的翻转概率p和q, 使用基于LASSO回归的联合分布方法计算初始值(第1–10行).
第2步: 消除冗余项, 利用基于LASSO回归的联合分布估计方法得到联合分布为0的属性并消除他们(第11, 22–23行).
第3步: 更新迭代, 根据永久随机响应翻转概率f和瞬时随机响应的翻转概率p和q, 使用基于EM的联合分布估计算法通过组合每个属性来计算得到一个特定的位串组合的所有条件分布, 通过贝叶斯定理计算它们对应的后验概率. 得到后验概率后, 通过计算后验概率的平均值来更新先验概率. 在下一次迭代中利用更新后的先验概率计算后验概率. 使用上述方法进行迭代直至收敛(第12–37行).
上述LREMH算法具有两个优势:
(1) 回归分析能够非常有效地选择稀疏的候选项.因此, EM算法可以只计算这些稀疏候选项上的条件概率, 而不是所有候选项上的条件概率, 从而降低了时间和空间复杂度.
(2) EM算法对初值比较敏感, 尤其是在候选空间稀疏的情况下. 回归分析可以对联合分布产生较好的初始估计. 相对于均匀赋值的初值, 使用回归分析生成的初值可以进一步加快EM算法的收敛速度.
4.7 满足本地化差分隐私证明
证明. 在LREMH算法中, 所有的输入数据的都是经过RR-LDP算法处理后的数据, 且LREMH算法的整个流程中没有任何操作引入其他隐私保护和随机扰动, RR-LDP算法的永久随机响应和瞬时随机响应根据定理1和定理2证得分别满足 ε1-本地化差分隐私和ε2-本地化差分隐私, 根据本地化差分隐私的性质1(序列组合性)可证得, LREMH算法满足ε -本地化差分隐私, 其中ε =ε1+ε2.
5 实验与分析
5.1 实验环境
实验中使用了两个真实数据集, NLTCS和Adult.NLTCS数据集来自美国护理调查中心, 包含21 574名残疾人不同时间段的活动. 成人数据集来自1994年美国人口普查, 包含45 222个居民的个人信息, 如性别、工资和教育水平. 在预处理中对一些连续域进行了离散化处理并删除了一些缺省值.
实验中所使用的软硬件参数如下:
(1) 操作系统: Windows 10;
(2) 硬件参数: IntelCore i5, 2.0 GHz CPU, 4 GB;
(3) 编译环境及工具: Python 2.7, PyCharm.
本文分别从数据集NLTCS和数据集Adult中采样了20%的数据和10%的数据. 算法的效率是通过计算估计时间和估计的精度来衡量的. 每组实验运行10次, 并报告平均运行时间. 为了测量精度, 本文使用了两个数据集上的平均变异距离(AVD)来量化估计的联合分布P(ω) 和原始联合分布Q(ω)之间的接近程度.

为了快速收敛, 将收敛间隙设置为0.001, 在瞬时响应中通常取q=0.75,p=0.5.
5.2 安全性分析
根据第4.7节的结论, LREMH算法是满足ε -本地化差分隐私, 又根据本地化差分隐私的两个性质得到ε=ε1+ε2=2dln((2-f)/f)+log[q*(1-p*)/p*(1-q*)],由于本次实验的p和q是定值, 故ε 的大小只与d(数据记录的数量)和f(永久随机响应的翻转概率)有关, 而两个数据集的数据记录数d也是确定的, 所以本次实验的安全性只与f相关. 从本地化差分隐私的定义可以看出ε 越小,eε就越小, 数据记录之间的差距就越小, 就越难分辨, 安全性就越强, 反之则ε 的值越大, 安全性就越弱,本次实验的f取(0, 1), 根据式(10)可以看出随着f的增大ε 的值会减小, 安全性会增强.
5.3 估计效率对比
(1) NLTCS数据集: 如图1, 对于任一维度k, LASSO回归始终比EM算法和LREMH算法快, 尤其是当k较大时. 由于LASSO回归的时间复杂度主要受用户数量的影响, 所以当k增大时, LASSO回归的计算时间增长缓慢, 而EM算法的计算时间增长较快是因为EM算法必须反复扫描每个用户的位串, 同时, 固定的收敛精度会有更多的迭代从而导致EM算法的时间消耗随着f的增加而增加. 相比之下, LASSO回归可以更有效地估计联合分布. 因为LASSO回归的初始估计可以大大减少候选属性空间和所需的迭代次数, 所以LREMH算法的复杂度要比EM算法小.

图1 NLTCS数据集估计效率对比
(2) Adult数据集: 如图2, EM算法在低维k=2的情况下以可接受的复杂度运行. 当k=5时, EM算法的时间复杂度急剧增加了几倍. 当k进一步增加时, 在120 s内没有返回任何结果. 然而, LASSO回归只需要几秒的时间.
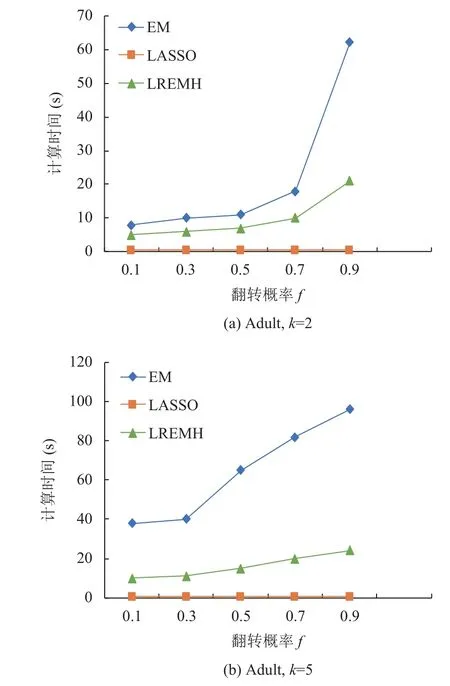
图2 Adult数据集估计效率对比
5.4 估计精度对比
(1) NLTCS数据集: 如图3, 当f很小时, EM算法的AVD误差很小, 但当f增大时, 它会急剧增大, 高达0.28. 相比之下, 即使f= 0.9, LASSO回归的AVD误差也保持在0.1左右. 当f较大时, LASSO回归的AVD误差与EM算法相当, 甚至更好. 这是因为LASSO回归在从M和→y估计系数时对f不敏感. 由于EM算法扫描每条记录的位串, 所以它对f很敏感, 并且容易得到某些局部最优值. 相比之下, LREMH算法在LASSO回归和EM算法之间实现了更好的权衡. 例如, 当f值较小时, 它的AVD误差小于LASSO回归; 当f值较大时, 它的AVD误差优于EM算法.
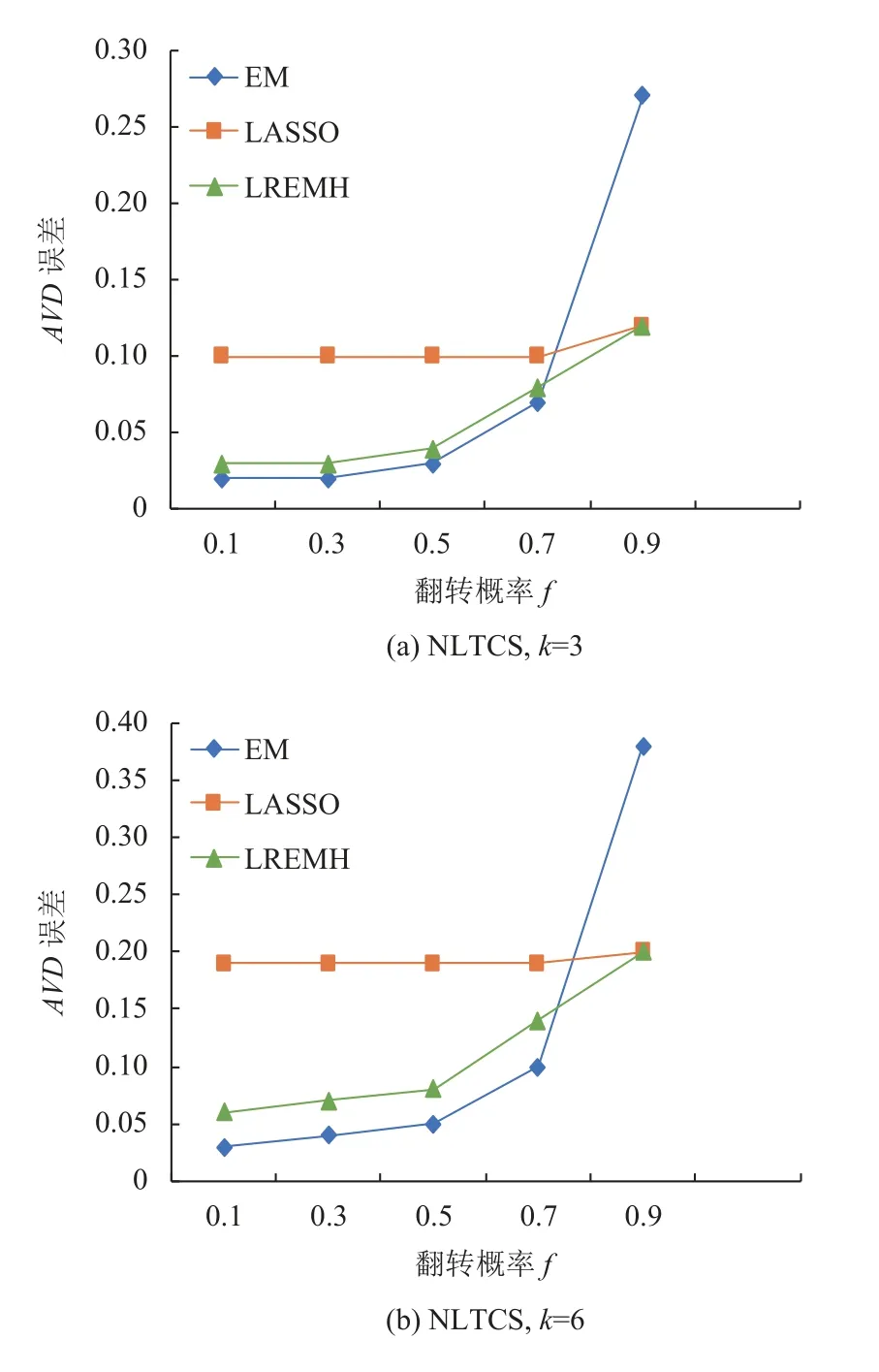
图3 NLTCS数据集估计精度对比
(2) Adult数据集: 如图4, 当k= 2时, LASSO回归的AVD误差几乎不随f变化, 因为回归分析对f不敏感. 而EM算法的AVD误差而随f逐渐增大. 当f很大时, LASSO回归的趋势非常接近EM算法. 因为LREMH算法比EM算法运行的快得多且估计精度于EM算法相差不大, 所以它实现了精度和效率之间的平衡. 另外, 当k= 5时, 估计误差也增大. 而LREMH算法可以在LASSO回归和EM算法之间进一步平衡, 因为当k更大时, 候选集将会更稀疏, 而LREMH算法可以有效地减少候选集的冗余和迭代次数.
根据图1, 图2可以看出LREMH算法的估计效率随着属性维度和f的增加而缓慢下降, 但始终处于EM算法和LASSO回归算法两者之间. 当f>0.7时EM算法的效率急剧下降, 这是因为EM算法对f很敏感, 并且容易得到某些局部最优值. 由于LREMH算法使用LASSO回归快速的估计初始值, LREMH算法对f的敏感度要低于EM算法, 同时使用LASSO回归估计的初始值要比直接使用均匀分布的初始值更加精确, 很好的解决的EM算法对初始值敏感的问题, 而且有效地减少了迭代的次数, 这使得LREMH算法的估计效率一直比EM算法高. 根据图中可以看出, LREMH算法的估计精度随着属性维度和f的增加而下降, 但也在大部分情况下处于EM算法和LASSO回归算法两者之间, 当属性的维度增大时, 需要计算的候选集会变得更加稀疏, 所以EM算法的误差会随着维度和f的增加而增加, 由于LASSO回归只进行一次回归分析的估计, 并没有像EM算法一样进行迭代, 所以其估计的精度在大多数情况下不如EM算法, 但LREMH算法在估计初始值的同时会消除冗余候选项, 解决的初值估计问题, 减少了迭代次数, 降低了得到局部最优的概率,所以LREMH算法在效率和精度之间取得了均衡.
并且由于f的值直接影响了隐私保护等级, 当f增加时, 隐私保护的等级就越高, 也就导致了随着f的增加, 3个算法估计的效率和精度都随之下降, 从图3和图4中可以直观看出当f<0.7时, LREMH算法的估计效率和精度在LASSO回归算法和EM算法中取得了良好的均衡.

图4 Adult数据集估计精度对比
6 总结与展望
多维数据的联合概率分布估计对于数据发布具有重要作用, 本文提出的LREMH算法在满足本地化差分隐私的情况下, 结合期望最大化算法和回归分析方法消除冗余候选项, 用回归分析估计初始联合分布, 然后用期望最大化算法进行迭代计算, 直至收敛. 通过实验验证LREMH算法在精度和效率之间取得了平衡.下一步工作将会围绕如何学习到与原始数据最为拟合的概率图模型, 如何进一步提高发布数据的可用性等方面的问题进行研究.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
上海师范大学学报·自然科学版(2022年3期)2022-07-11
华文教学与研究(2022年1期)2022-04-27
汽车工程学报(2022年1期)2022-02-20
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
