
基于决策知识学习的多无人机航迹协同规划①
2022-08-25 02:51刘丽华杜溢墨陈丽娜
计算机系统应用 2022年8期
曾 熠, 刘丽华, 李 璇, 杜溢墨, 陈丽娜
1(解放军31008部队, 北京 100091)
2(国防科技大学 系统工程学院, 长沙 410073)
航迹协同规划[1]是实现多无人机自主行为导航与控制的关键技术, 也是对环境感知决策的具体体现形式, 其目的是规划出最优的航迹策略, 以解决目标搜索、飞行避碰、编队控制等问题. 现有关于航迹协同规划方法主要有启发式方法[2]、Voronoi方法[3]、遗传算法[4]、粒子群算法[5]等, 由于外界复杂环境影响, 行为变化的不确定性对航迹规划提出了更高的任务需求[6,7].
从无人机群体行为决策[8,9]与状态变化的内在驱动机制看, 复杂的群体行为通过简单的局部交互知, 需要遵循一定的标准知识才能保证整个系统可控性. 决策知识[10]是实现自然语言与环境信息交互的一种接口, 它采用标准化的规则格式实现机器指令与外界信息的交互理解, 是目前智能机器领域的研究热点[11]. 文献[12]采用知识本体的思维构建了任务规划的概念层次, 给出了决策知识学习在无人机航迹协同规划上的逻辑推理应用. 但该方法只描述了外部环境的概念形式, 缺少对无人机动作和状态内部驱动的知识表示. 文献[13]运用层级式表达方式对无人机环境信息进行概念抽取, 在航迹序列点位置上部署决策点, 并赋予基于决策树的知识学习方法. 但该方法计算航迹代价较高,容易陷入局部最优状态, 较难保证全局航迹规划最优.文献[14]使用神经网络指导无人机建立了一个决策知识框架, 用于推理目标搜索中的环境知识和状态, 从而获得最优策略. 但该方法未考虑事件触发与系统内在关系, 较难保证任务背景中的知识学习能力[15,16].
综上所述, 从信息处理的角度探讨性地提出了一种基于决策知识学习的多无人机航迹协同规划方法.该方法基于马尔可夫决策过程, 重点构建决策知识库,形成基于事件触发-知识驱动的群体决策机制, 通过引入意义接受性学习理论增强决策知识学习的相关性,以获取多无人机航迹规划的最优策略.
1 系统设计
1.1 任务描述
多无人机协同航迹规划问题是将每台无人机同时从不同的起点到相同目的地或侦察点, 生成可行的飞行轨迹, 这些轨迹由一组协同全局最小代价的优化准则和约束条件定义, 包括最小化无人机被摧毁的风险,以及无人机内外部环境限制和威胁动态. 如图1所示,多无人机航迹协同规划任务描述中, 任务空间中有3台无人机和6个威胁区域以及部分地形障碍, 需要通过系统状态不断调整优化动作, 对每台无人机形成一个动作序列, 每个动作又形式化表示为协同决策和任务优化问题.

图1 多无人机航迹协同规划任务描述
1.2 系统框架
针对无人机航迹协同规划的连续动作空间特征,将知识决策框架分为数据支持层、模型生成层和策略控制层. 如图2所示, 它是整个系统的基本框架.
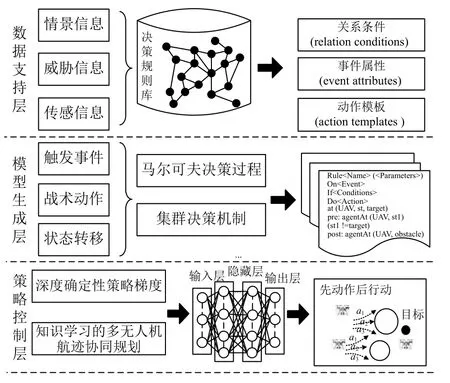
图2 基于决策知识学习的多无人机航迹协同规划系统框架
(1)数据支持层: 主要将空间数据库的信息和无人机传感器获取的环境信息、威胁信息、历史经验等进行知识的实例化表示, 对情景任务进行有效分析, 形成具有图结构的决策知识库, 同时赋予了相关事件属性、动作模板和关系条件, 其功能包括事件触发、行为动作和状态转移等.
(2)模型生成层: 主要利用马尔科夫决策过程对无人机群体的状态和动作进行建模, 得出最优状态-动作值, 产生最优策略; 通过群体决策机制对无人机当前状态、情景和动作进行分析, 形成决策知识与无人机系统的信息交互, 为航迹规划的策略控制提供数据支撑.
(3)策略控制层: 主要采用深度确定性策略梯度(deep deterministic policy gradient, DDPG)对当前无人机群体的动作和状态进行训练, 通过引入意义接受性学习理论, 提出基于知识决策学习的深度确定性策略梯度算法, 不断调整选择最优策略, 将新的群体协同决策经验知识映射存储于至知识库, 以提高航迹规划的准确性.
2 决策过程
2.1 基于马尔科夫的决策过程
马尔科夫决策[17]过程对序贯决策问题进行了数学定义, 为多无人机决策和任务优化提供了一种端到端的学习框架. 根据马尔科夫决策过程, 将无人机航迹规划表示为一个五元组模型 (S,A,P,R,γ) . 其中,S为无人机在当前航迹序列下可以到达的所有状态的集合,A表示无人机可以在环境中选择的所有动作的集合,P和R表示从状态s到状态s′执行动作a的概率和奖励(a∈A且s,s′∈S), γ ∈[0,1]为决定当前或未来奖励重要性的折扣因素.
在每个时间步长t, 无人机的状态为st,at为无人机在该状态下执行的动作, 无人机从环境交互中获得奖励rt, 并在下一时间步到达状态st+1. 同时, 无人机在每个时间步长选择的动作由策略集π 决定, 一个包含在策略 π 的元素π (a|s) 表示无人机在某个状态s所采取行动a的概率. 在所有策略中, 有一个最优策略π*, 当无人机遵循该策略时, 可以获得最大奖励Rt, 从步长t的开始时间到结束时间, 累积奖励表示为:

状态-动作值函数Qπ(s,a)计算为Qπ(s,a)=E[Rt|st=s,at=a,π]表示无人机在当前状态下执行动作的过程. 当执行最佳策略π*时 , 则为最优状态-动作值函数满足贝尔曼最优性方程[17].

状态-动作值函数将通过不断迭代等式最终收敛Q*(s,a) 产 生最优策略
2.2 决策知识库
根据任务区域内所有实体在空间上的布局, 将区域内的每个实体进行知识表示, 初始化为一个图形化的决策知识库SD_Net. 存储在SD_Net中的每个知识结构对应无人机的不同危险程度和航迹序列位置, 其作用是将当前无人机采样的环境信息和系统状态与知识库的知识进行信息交互, 供无人机系统学习训练.SD_Net的结构为, 其中为概念层次的层次结构分为系统状态(由马尔可夫决策过程生成的状态网络层次)、触发事件(由历史不确定事件所构成的网络层次)和环境知识(由历史态势环境的背景知识构成的网络层次);E为链接各概念层次的关系;I为具体的实例, 存储了所有不同任务背景下的案例知识;At为马尔可夫决策过程形成的行为动作和奖励. SD_Net模型如图3所示,以Protégé平台[11]进行构建, 封装为基于SPARQL语言的OWL模型[12], 存有500余个概念层次实体和6 000余个案例知识, 用SWRL调试分析无人机群体决策的情景分析, 形成决策知识.

图3 无人机决策知识库模型
知识库SD_Net作为无人机航迹规划的初始规决策知识, 是当前系统知识认知结构中已有的概念层次,但在动态任务的决策过程中由于外部威胁区域的不确定性, 需要利用当前状态和动作不断进行调整优化, 学习到最优策略达到航迹规划效果.
2.3 群体决策机制
无人机群体作为一个行为可控的复杂系统, 在马尔科夫模型的状态和动作基础上, 关键在于任务平台能够针对特定的触发事件, 以决策知识为驱动, 需要自主进行行为决策与状态变化, 因此提出基于事件触发-知识驱动决策机制. 其中, 事件触发为无人机外部触发条件, 通过事件检测器对底层数据进行事件提取, 与所建立的知识库进行匹配, 构建事件与动作行为的映射关系. 作为背景知识的一部分, 事件触发与任务区域的不确定环境进行交互, 在一定程度上提高了决策过程的可解释性[18], 同时节约了存储和计算资源; 知识驱动是内部驱动机制, 根据协同航迹规划需遵循的规则, 群体行为通过局部交互知识产生, 逐渐扩散到全局知识,以发现、执行和调整3种动作规则, 支撑自主行为决策和状态变化的概念化、形式化的知识表示, 从而明确任务空间相关要素与系统状态转移的关联关系. 如图4所示, 多台无人机进入指定任务区域执行任务, 在情景T的触发下产生状态, 根据SD_Net知识库中的概念层次, 分别使用案例规则知识, 形成不同状态下的行为选择, 从而规划出一个连续动作空间.

图4 多无人机决策知识情景分析
3 航迹规划方法
3.1 深度学习框架
在群体决策的知识分析后, 多台无人机航迹协同规划形成了一个连续动作空间, 需要寻找优化速度较快且适用于大规模数据的函数逼近器[17], 使群体决策达到最优策略. 将深度DDPG算法[19]应用于连续动作空间, 主要由态势环境、经验池、行动者网络和评论家网络4个部分组成. 其中, 态势环境和经验池的功能分别用于生成和存储知识, 在不断与环境交互的过程中, 无人机系统获取环境知识并将其存储于经验池中以备学习, 并实时映射于知识库SD_Net; 行动者网络用于确定无人机系统选择行动的概率, 当无人机与环境交互时, 它会根据行动者网络选择行动; 评论家网络根据环境状态评估无人机系统选择的操作, 行动者网络基于评估修改选择行动的概率. 为使行动者网络更具稳定性, 在行动者网络的输出中加入了探测噪声Nt,即样本大小, 使每个动作为at=μ(st|θμ)+Nt, 其中θμ表示在行为者网络中显示评论家网络的参数, 行为者网络通过策略梯度近似计算评论家网络参数:
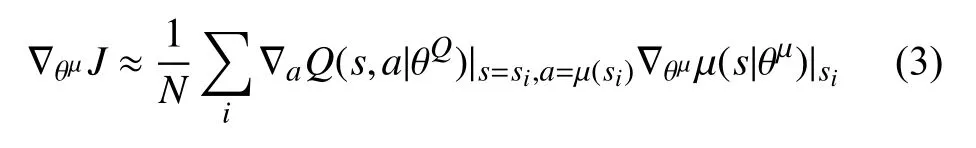
其中, θQ表示行动者网络中评估参数, 通过最小化损失函数更新评估参数:
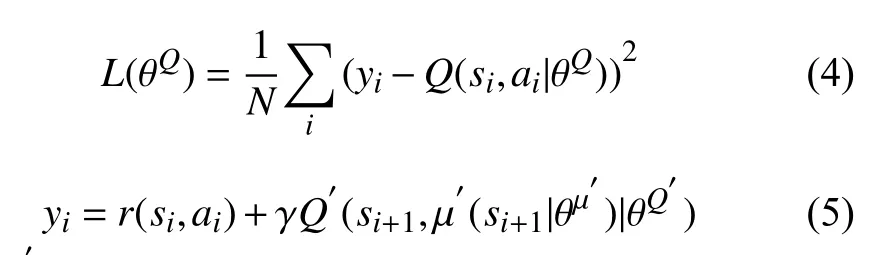
其中, θQ为评论家网络中的目标网络,N为学习经验数量.评论家网络的参数更新方法采用软更新的方法来提高训练的稳定性θ′←τθ+(1-τ)θ′, τ ∈[0,1]用于确定更新程度.
3.2 知识相关性学习
为提高训练效率, 将意义接受性学习理论(meaningful receptive learning, MRL)[20]引入协同任务规划的学习训练中, 其原理是将无人机所需学习的态势环境内容与SD_Net中的背景知识和概念层次进行关联.
首先, 设计一个知识相关性函数fr(s)评估当前状态与知识库SD_Net中知识的相关性.

其中,Dmaximum为无人机与环境中目标之间的理论最大距离, ρ1、 ρ2和 ρ3为常数. 首先, 在每个时间步长, 计算群体决策知识的相关性, 将其存储于知识库SD_Net中, 筛选出与当前学习状态最相关的知识用于任务规划. 然后,按照DDPG算法的时序差分差错(temporal difference error, TD-error)[21], 来评估评论家网络的目标网与行动者的行动网之间的差异, 选择与当前状态最相似的知识. 最后, 采用先学习后选择动作方式输出最优策略.如图5所示, 以二维离散场景为例, 无人机在当前时间步长有左转一定角度a1、前进a2、右转一定角度a3等3个离散动作可供选择. 假设在当前状态s下, 神经网络将输出动作a1, 这将导致任务失败. 在每个学习时间步骤, DDPG算法会根据当前状态选择一个动作a2并执行, 在调整学习和动作选择的顺序后, 本文所提算法根据当前状态s选择最适合学习的经验, 在学习过程结束后, 神经网络的参数会发生一定程度的变化,由于学习到的知识是与状态s相似的经验, 参数更新后的神经网络输出a3, 使无人机能够安全避开威胁区域.
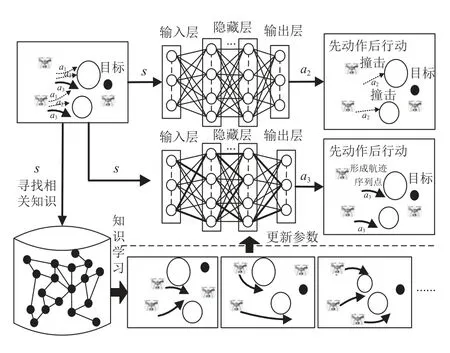
图5 知识相关性学习
3.3 算法实现
在每个时间步长t中, 计算每个状态st的经验相关性函数fr(st), 将其存储于知识库SD_Net中, 提出基于决策知识学习的深度确定性策略梯度算法(knowledge learning decision-PPDG, KLD-PPDG). 其过程是知识库SD_Net中的知识结构从 (st,at,rt,st+1,E,I,)变化为(st,at,rt,st+1,E,I,fr(st)), 在每个时间步长t中, 根据知识库中每个知识选择当前状态Nt个知识(si,ai,ri,si+1,E,I,fr(si))i=1,2,···,Ntd进行排序; 然后, 根据每个采样经验的当前状态fr(st)和fr(si), 形成一个最小值阈△fr=|fr(st)-fr(si)|, 根据TD-error的δi更新这些知识选择概率; 最后, 这些知识用于更新网络的参数. 具体算法如算法1所示.

算法1. KLD-PPDG 1.初始化知识库容量D, 无人机数量N, 样本大小Nt, 重播周期K, 训练集M, 以及范例α和β;Q(s,a|θQ) μ(s|θμ)θQ θμ 2.随机初始化评论家网络 和行动者网络 , 它们的权重分别为 和 ;Q′ μ′ θQ′←θQ θμ′←θμ 3.初始化目标网络和 , 权重分别为 和 ;

4.初始化经验池R;5.for 集合=1, M do 6. 初始化一个随机进程N进行动作探索;7. 接收初始观察状态s1并设置p1 =1;8. for t=1, T do fr(st)9. 计算经验相关值 ;10. if t=0 mod K then i~P(i)=pαi/∑jpαj Nt(si,ai,ri,si+1,E,I,fr(si))i=1,2,···,Ntd 11. 根据样本概率 , 取样 个经验;fr(st) fr(si)Δfr=|fr(st)-fr(si)|12. 根据每个采样经验的当前状态和 , 形成一个最小值阈 ;ωi=(D·P(i))-β/maxjωj 13. 计算重要性采样权重 , 根据式(4)设置yi=r(si,ai)+γQ′(si+1,μ′(si+1|θμ′)|θQ′)δi=yi-(si,ai|θQ)14. 计算TD-error值 ;pi←|δi|15. 更新知识优先值 , 通过式(1)计算奖励值R, 通过式(2)最小化损失函数更新评价网络的参数, 通过策略梯度近似评估行动者网络参数式(3);16. 更新目标网络θQ′←τθQ+(1-τ)θQ′θμ′←τθμ+(1-τ)θμ′17. endif at=μ(st|θμ)|si+Nt π*=argmax a∈A Q*(s,a)18. 基于当前策略和探测噪声选择动作 ; 产生最优策略 ;at rt st 18. 执行动作 并观察奖励值 和下一个状态 ;(st,at,rt,st+1,fr(st))19. 存储 至SD_Net中;20. endfor 21.endfor
KLD-PPDG算法利用MRL理论计算连续知识相关性选择适合不同时间的学习知识, 还调整算法中学习和动作选择的顺序, 增强历史相关经验知识对当前状态下规划决策的影响, 提高算法的收敛速度.
4 实验分析
结合军民融合研究项目, 本文主要通过Netlogo平台验证所提出方法的有效性.
4.1 航迹规划分析
航迹规划分析的实验如图6所示, 采用3台无人机在某作战区域执行侦察任务, 在Netlogo中实时导入知识库SD_Net的概念层次, 针对该区域的探测雷达和突发威胁, 描述为马尔可夫决策过程的行为状态. 由图6(a)可知, 生成多条航迹序列点作为历史航迹经验知识. 由图6(b)可知, 运行PPDG算法后, 形成的航迹规划效果. 由图6(c)可知, 运行KLD-PPDG算法后, 3台无人机从各初始位置触发, 将无人机所需学习的态势环境内容与SD_Net中的背景知识和概念层次进行关联, 然后以先学习后动作方式, 执行每个航迹序列点上的状态转移和TD-error计算, 重复以上过程, 使知识得到充分利用, 最终形成一个最优的轨迹规划策略.

图6 航迹规划结果
4.2 性能分析
(1)航迹综合协同评价[22]
航迹综合协同评价指标是测量多无人机协同规划的重要评价指标, 对于任务区域和威胁区域的不断, 使无人机航迹序列点在KDL-PPDG学习过程中不断更新迭代, 引入航迹综合协同评价指标[4]说明本文所提KDL-PPDG方法在航迹协同规划中群体决策的性能.如图7所示, 3台无人机任务航迹协同综合评价变化曲线, 在实时复杂的探测雷达和突发威胁环境态势下, 其航迹综合协同评价指标(图7(a))和单个无人机的协同评价指标(图7(b)), 在迭代至50次时其航迹代价值差距逐步变小且趋于收敛稳定, 这说明对于真实环境信息的感知, 每台无人机在经过多次知识学习后, 目标航迹序列点上的状态和动作选择趋于最优. 主要是由于本文方法在初始阶段构建了一个决策知识库SD_Net,体现了决策知识对航迹规划的优势, 使用TD-error对知识相关性进行评估, 以更新目标网络策略的方式, 不断更新知识库中的知识, 得到最优航迹规划的策略.
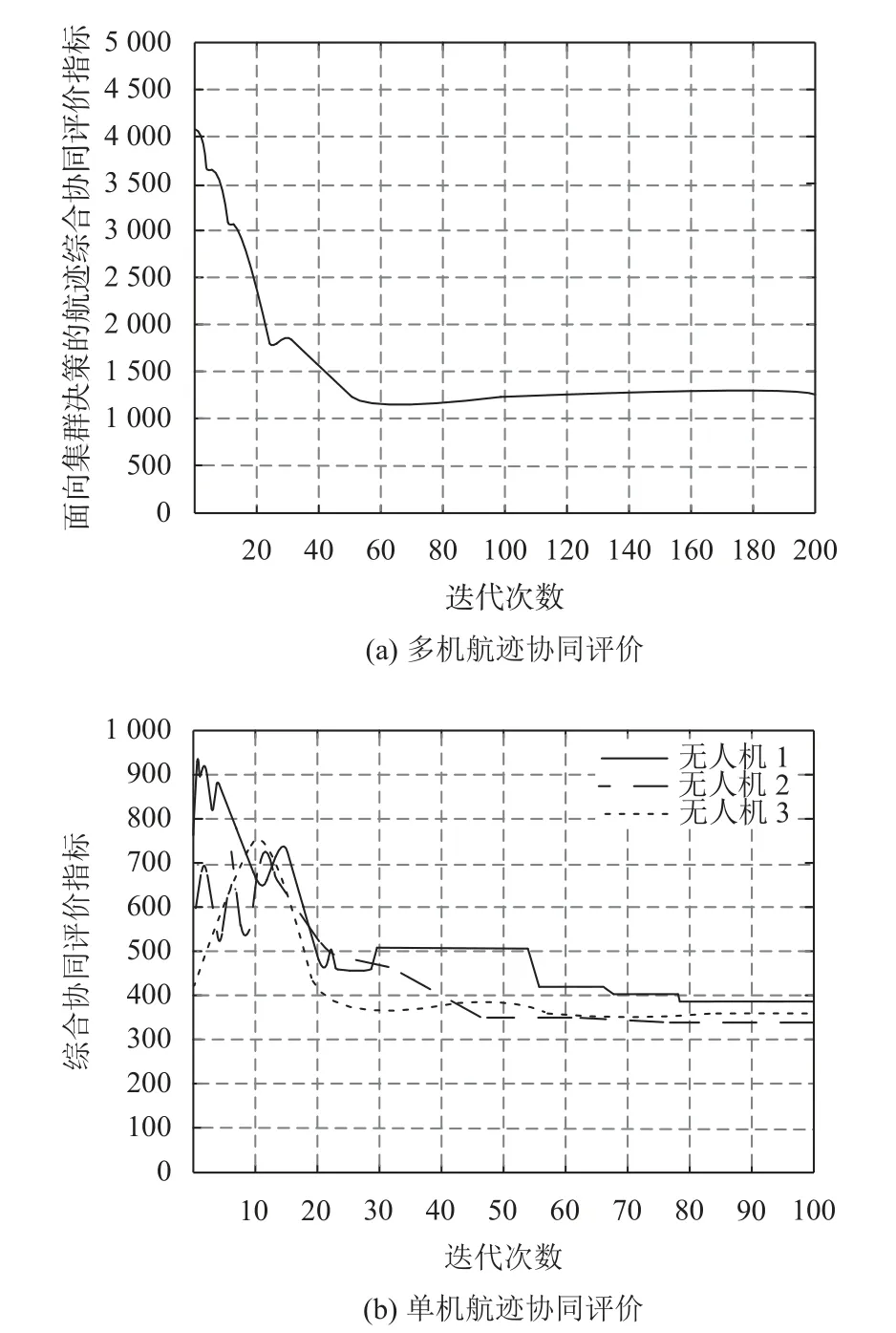
图7 任务航迹代价变化曲线
(2)平均奖励比较[19]
为进一步说明KLD-PPDG算法在航迹规划的有效性, 与现有遗传算法(GA)、粒子群算法(PSO)、PPDG算法进行性能比较. 性能比较平台利用Matlab对数据进行编程, 形成各方法的导入压缩包, 从深度强化学习的奖励值这个指标衡量不同方法下的航迹规划效果.深度强化学习的奖励值描述了在无人机群体决策过程中对威胁区域的避障效果, 表示为多台无人机在每个计算迭代次数内遵循最优策略所获得的平均奖励. 由图8可知, 本文所提KLD-PPDG算法在500以内的迭代次数时, 其平均奖励值时会出现微小的振幅, 这有利于算法跳出局部最优解区域, 在第500次迭代后平均奖励值迅速提高, 并于3 500次迭代后逐步收敛稳定,奖励值固定在16附近, 这种情况主要受益于PPDG中行动者网络与评论家网络的相互作用, 使目标网络逐步靠近最优策略, 同时引入MRL知识相关性计算, 使无人机遇到威胁区域后采用先学习后动作的方式成功规划出新的航迹知识, 这种规划调整方式使无人机在当前状态下基于知识库历史经验做出更好的决策, 加强当前状态与知识库的联系, 提高算法的收敛速度. 而PSO算法在虽然在奖励最优值方面靠近KLD-PPDG算法, 摆脱了局部最优困扰, 但随着迭代次数的增加,其值不稳定; GA算法则由于采用启发式的方式进行航迹序列点计算, 计算空间较大, 导致平均奖励值的振幅较大且在短时间内无法稳定.
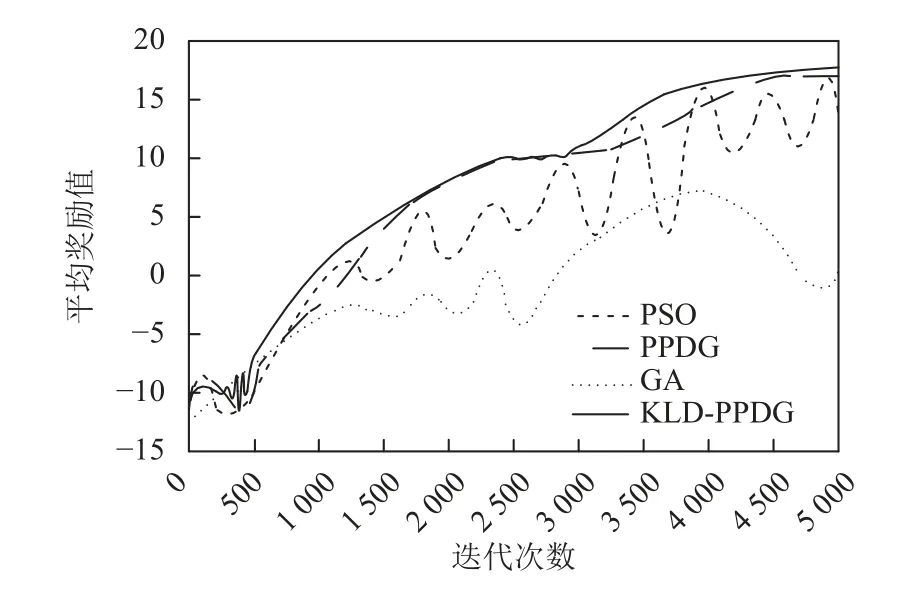
图8 平均奖励比较
5 结论与展望
本文在分析马尔科夫决策过程的行为状态变化的基础上, 提出了基于决策知识学习的深度确定性策略梯度算法, 与其他基于深度学习的多无人机航迹协同任务规划研究不同的是, 本文将决策知识库作为深度学习经验池的知识储备, 态势环境和经验池的功能分别用于生成和存储知识, 并将意义接受性学习理论引入协同任务规划的学习训练中, 以增强决策知识的相关性学习能力. 但无人机群体航迹协同规划是一个复杂的大规模优化问题, 当无人机数量较大时会出现连续空间不稳定现象, 下一步将充分考虑空间和时序的约束, 进一步优化领域情景知识, 从多维空间数据展开研究.
猜你喜欢
航空学报(2022年9期)2022-10-14
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
青少年科技博览(中学版)(2019年2期)2019-06-20
知识文库(2019年2期)2019-06-11
决策(2018年8期)2018-12-10
小天使·四年级语数英综合(2018年1期)2018-07-04
珠江水运(2015年11期)2015-07-24
中国报道(2015年6期)2015-06-19
科学导报·学术论坛(2013年5期)2013-06-26
