
面向多人多生物属性的跨视角步态追踪系统①
2022-08-25 02:51黄彬源罗咏东谢家辉李志文周成菊潘家辉
计算机系统应用 2022年8期
黄彬源, 罗咏东, 谢家辉, 李志文, 周成菊, 潘家辉
(华南师范大学 软件学院, 佛山 528225)
1 引言
1.1 研究背景
生物特征识别技术正受到学术界和工业界的广泛认可, 因为它可以通过人类的行为特征进行属性识别.生物特征识别领域中包含了许多的技术, 其中不乏虹膜识别、人脸识别等广为人知的生物识别技术. 然而,这些方法包含以下缺陷: 对伪装后的特征辨别效果差,只能在短距离内进行识别, 同时在大多数情景下都需要受试者的主动配合[1].
以人脸识别在实际中的应用缺陷为例: 犯罪分子通常会以戴口罩或者是易容的方式再次出现, 此时由于人脸特征被隐藏, 通过人脸识别的方式极难识别; 另外是在疫情常态化的当下, 戴口罩成为常规的出行方式, 这同时也加剧了人脸识别的难度; 再则是人脸识别的距离有限, 这对于实际应用中监控摄像头的素质也提出了更高的要求, 因此也增加了硬件成本[1].
而步态识别(gait recognition)技术则成为解决上述问题的关键. 步态识别旨在通过分析人的行走模式进而对其进行属性识别, 每个人特有的生理结构决定了其独有的步态, 因此人体的步态具有唯一性和稳定性, 这也成为了步态识别可行性的基础[2]. 步态识别可以在2K摄像头(公安主流摄像头)下达到最远50 m的识别距离, 同时不需要受试者的主动配合, 并且可以从人体的全身捕捉特征, 它不依赖于人体的某一部分,因此受到的约束就少. 基于上述优势, 步态识别也被称为当下安防领域中极具应用前景的生物识别技术.
1.2 国内外研究现状
目前, 步态识别技术的实现主要分为两大类: 一类是传统的基于机器学习的步态识别算法, 另一类则是基于深度学习的步态识别算法. 基于机器学习的步态识别研究重点之一是解决视角变化的问题[3–11]. 其中,部分方法通过学习更高的专业知识来提取视角恒定的步态特征, 另一部分方法则通过构建视图转换模型(view transform model, VTM)来规范化不同的视角.Kusakunniran等人[3]提出了基于视角恒定特征的步态识别框架将不同的视角归一化. 此外, Kusakunniran等人[4]还利用截断奇异值分解技术(truncated singular value decomposition, TSVD)构建了视角转换模型, 该技术可以将图库样本和探针样本的不同视角转换为同一视角.上述传统算法虽然可以达到比较高的实验精度, 但在实际应用中却难以克服各种复杂的协变量的影响(如行人服饰变化, 视角发生较大改变), 缺乏一定的鲁棒性和普适性. 而基于深度学习的步态识别算法虽然没有明确地对视角的变化进行建模, 但依然可以实现良好的跨视角步态识别性能. 现有的基于深度学习的步态识别方法大致可以分为两类: 第1种是基于模板图的方式, 该方法将所有的步态轮廓压缩成一个步态信息的模板. Wu等人[12]首先介绍了基于CNN的从步态能量图像(GEI)中捕捉步态模式深度特征的方法. Shiraga等人[13]使用 2D CNN 从GEI中提取步态特征. 尽管上述的方法尽可能期望使用模板表征丰富的步态时序信息, 但是不可避免的散失了时序信息和细粒度的空间信息[14], 因此并不适合在实际的系统进行应用. 第2类则是基于剪影图序列的方法, 利用卷积直接编码来自原始步态轮廓序列的时空表征从而可以获得更为丰富而全面的步态时序信息, Zhang等人[14]提出基于LSTM的步态识别算法以捕获更长时间范围的时间信息. 为了提高步态识别的灵活性, Chao等人[15]提出GaitSet算法将步态视为一个集合而不是一个序列, 从而获得更为丰富的步态样本数量并取得优异的性能, Huang等人[16]提出了一种基于信息加权模块和局部特征流调节模块进行步态特征学习. Sepas-Moghaddam等人[17]提出使用双向递归神经网络的学习关系序列中提取的部分特征. Ding等人[18]提出了一种顺序卷积神经网络SRN从新颖的角度学习时空特征.
在应用领域方面, 国内的银河水滴科技发布了全球首个步态识别互联系统“水滴慧眼”, 该系统可以实现远距离、多视角的步态识别, 且适用于大范围人群密度测算, 在安防领域、智能交通、智能家居和医疗康养方面有较为广泛的应用. 上述系统功能较为完备且适用范围广, 但仍然存在一定的局限性. 一方面, 上述系统的研发与采购成本均较高; 另一方面, 上述系统更多关注于受试者的步态身份信息, 一旦身份信息失效, 系统则无法提供其他的参考信息. 因此, 本文开发了一款低成本、支持实时多信息跨视角检测的智能安防系统, 在保证安防系统的基础身份识别之外, 拓展了步态年龄与性别信息辅助筛选, 配合路段追踪的功能,可以很好地满足安防常规需求, 具有重大的现实意义.
2 系统设计
2.1 系统结构介绍
本系统的全名为面向多人多生物属性的跨视角步态追踪系统, 意指本系统的算法设计面向现实应用场景, 致力于解决现实场景中可能出现的多行人, 跨视角,多种行走状态等应用难点问题. 系统通过合理而高效的算法设计对上述的协变量进行有效处理并得到了行人的多种生物属性.
本系统宏观上可以分为4大模块: 行人检测和追踪, 行人分割, 算法模型训练, 系统实现, 如图1所示.首先, 对于输入的视频序列, 系统首先通过行人检测模块将行人从若干种复杂的街头事物中分离开来; 其次,通过行人追踪模块从视频中提取出某个特定行人在视频中的完整步态序列. 接着, 系统通过行人分割模块进行前景和背景的分离, 得到行人的二值化步态序列图.最后, 系统通过特征提取算法模型对提取到的二值化步态序列图进行不同任务的训练并由此分析出行人的身份,年龄, 性别等多种生物属性. 在系统实现中, 我们提供了一个Windows系统下的客户端, 同时客户端已打包好算法模型运行时所需的环境依赖, 因此可以对用户输入的视频进行实时的属性分析.

图1 系统结构图
2.2 行人检测
在行人检测阶段, 我们使用YOLOv4算法[19]对输入的视频序列进行检测. YOLOv4算法[19]由CSPDark net53网络、SPP-Net (spatial pyramid pooling networks)网络、PANet (path aggregation network)网络以及YOLOv3检测头组成, 其中CSPDarknet53网络解决了其他大型卷积神经网络框架的梯度信息重复问题, 即将梯度变化集成到特征图中, 有效减少模型参数量和运算量, 在保持推理速度的同时缩小了模型尺寸; SPPNet网络主要对任意尺寸的特征图直接进行固定尺寸的池化, 以获得固定数量的行人特征; PANet网络进行参数聚合以适用于不同水平的行人检测, 最后由YOLOv3检测头实现对大中小3类目标的检测. YOLOv4算法对行人特征进行有效提取、集成和映射, 实现了系统运算速度和行人检测精度的完美平衡.
如图2所示, 我们将行人视频的帧序列划分成横纵网格, 如果某个行人的中心落在这个网格中, 则这个网格就负责预测边界框的位置信息、置信度以及类别信息. 计算出行人的ID置信度分数后, 系统根据预设的阈值过滤分数不佳的边界框, 对保留的边界框进行非最大值抑制算法处理, 得到每个行人的边界框.

图2 YOLOv4目标检测示意图
2.3 行人追踪
因为系统应用于多人的复杂场景, 需要对视频中出现的每一个行人目标进行追踪. 我们采用多目标追踪中比较成熟的Deep-Sort[20]. Deep-Sort算法[20]主要有4个步骤: 数据输入、卡尔曼滤波、匈牙利匹配和输出, 如图3所示.

图3 Deep-Sort算法效果图
卡尔曼滤波跟踪根据目标检测算法得到的前一帧某一个目标的目标信息, 并对其进行跟踪和预测, 得到该目标在后一帧的具体信息. 经过卡尔曼滤波器跟踪模块处理后, 视频中每一帧图像中包含的信息不仅是经目标检测算法得到的目标信息, 而且包括跟踪算法得到的目标跟踪信息. 然后使用匈牙利匹配对两种信息进行匹配, 得出最终的检测跟踪结果, 从而避免跟踪目标被多次检测, 降低算法的性能. 同时算法在匹配中还引入了级联匹配, 让更常见的目标分配的优先级更高, 更能应用于复杂的场景.
2.4 行人分割
在行人分割阶段, 我们使用UNet++算法对从视频序列中检测得出的行人序列进行前后景分离, 从而去除衣服条纹以及街道背景等噪声对于识别准确的影响.
UNet++网络由一对完全对称的编码器和解码器构成, 并通过连接的方式, 将编码阶段获得的浅层特征映射同解码阶段获得的深层特征映射结合在一起, 细化图像, 根据得到的特征映射进行预测分割, 最后一层通过卷积做分类. 同时, 将每一层上的特征提取器进行相互的连接, 以达到对特征提取器进行共享的目的. 在训练过程中, UNet++网络可以自行学习得出哪一层的特征信息更为重要, 从而在特征的提取中有更好的表现,具体表现在图像分割中对边缘的处理更为优异.
由于行人分割所得到的步态剪影序列图将作为特征提取网络的直接输入, 其分割效果以及效率将在很大程度上决定网络是否能够提取得到细粒度的步态特征以及系统能否对输入的视频进行高效的处理, 因此选用合适的算法能帮助系统提高身份及属性识别的准确率. 常见的前后景分离算法有基于机器学习的高斯混合模型算法[21]以及基于K邻近的背景分割算法[22],以及基于深度学习的MaskRCNN[23]、CGNet[24]、UNet[25]和UNet++[26]等.
图4 展示了各种常见的分割算法的结果对比, 其中MaskRCNN和UNet++分割结果更好.

图4 4种语义分割算法得到的行人步态剪影图
平均交并比(mIoU)是指模型对每一类预测的结果和真实值的交集与并集的比值的平均值, 即结果越接近1效果越好. 表1中所展示的mIoU是在同等实验条件下进行测试的结果. 通过比较, 我们发现UNet++在比MaskRCNN更少的参数量的情况下, 达到同等的分割效果. 所以, 结合图4语义分割的效果和表1算法效率之间的比较, 并考虑实际落地应用需要, 即在保持较好分割效果的同时应保持分割模型的轻量化. 本文选择了轻量化且分割效果较好的UNet++模型作为我们的分割算法.

表1 不同分割模型参数量以及平均交并比数据
2.5 特征提取算法模型
在算法模型方面, 本系统参考Fan等人[27]提出的网络架构, 并在其基础上针对不同识别任务的需要进行模型的优化和改良, 最终在不同的识别任务上达到了相对优异的准确率. 本系统所用于模型训练的特征提取网络结构如图5所示.
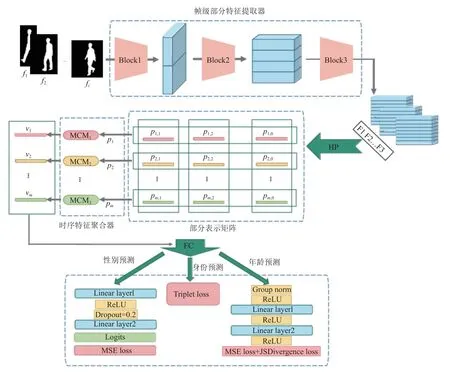
图5 系统整体算法模型图
Fan等人[27]提出的特征提取网络的输入是一系列连续的步态图像(64像素×44像素), 首先, 将包含t帧的步态轮廓序列逐帧输入网络. 在网络中, 首先对输入的步态图像进行处理的模块是帧级部分特征提取器(framelevel part feature extractor, FPFE), 这是一种特殊设计的卷积网络, 用于挖掘行人步态中蕴含的局部细粒度信息, 并输出每帧步态图像fi的空间特征Fi,i∈1,2,···,t.
FPFE由3个块组成, 每个块由两层焦点卷积层(FConv)组成, 目的是提取每帧的部分信息空间特征.FConv (focal convolution layers)是卷积的一种新应用,它可以将输入的特征图从上到下分割成若干部分, 然后对每一部分分别进行卷积, 最后水平维度上拼接各个分割出来的子模块成为一个整体模块.
通过FPFE模块后的特征图序列记为SF={Fi|i=1,···,t}, 接着, 我们将其输入到水平池化HP模块. HP模块以提取人体不同部分的信息特征为目标, 将特征图Fi水平分割为n个部分. 对于Fi的第j部分Fj,i, HP模块通过全局平均池化和全局最大池化将其向下采样到列向量Pj,i中, 并将其作为中间结果:

经过HP模块后, SF中的每个特征映射将转换为n个部分级特征向量, 由这些特征向量得到部分表示矩阵 (part representation matrix, PR-Matrix), 我们将PRMatrix记为:

PR-Matrix中相应的向量行可以记为:
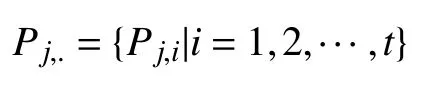
其中,Pj,i代表人体第j部分, 第i个时刻的步态特征.因此,Pj,.可以表示人体第j个部分的时空运动表示. 我们将Pj,.通过微动作捕捉模块(MCM)聚合到特征向量vj,.中, 从而可以提取出第j部分的微运动特征, 上述过程用公式表示为:
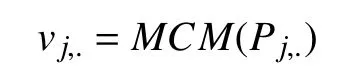
其中,MCMj为 第j个微动作捕捉模块. MCM的作用在于将经过HP模块输出后的帧级部分特征向量映射为微运动特征向量. MCM包括两个部分: 分解动作模板编辑器(MTB)和时间池化(TP). MCM模块工作流程图如图6所示. 接下来将首先对MTB模块进行描述,然后是TP模块.
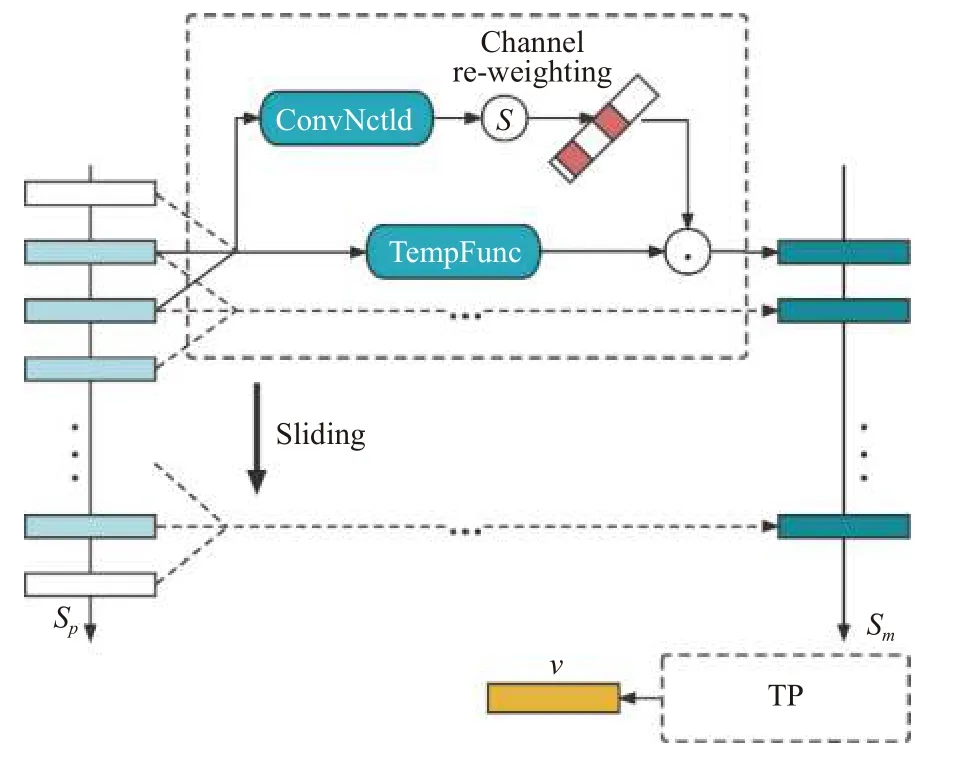
图6 MCM模块工作流程图
在MTB模块中, 设Sp={Pi|i=1,2,···,t}是PRMatrix的某一行, 代表人体特定部分的步态时空表示.MTB将尺寸为2r+1的一维全局平均池化和一维全局最大池化应用于Sp的每个时刻, 从而得到分解动作特征向量序列Sm, 上述过程用公式表示为:

为了获得对分解动作更有鉴别性的表示, MTB引入了通道注意力机制来对每个时刻的特征向量重定权重, 该过程采用了一维卷积核进行权重分配, 重新加权后的微运动分量的表达式为:
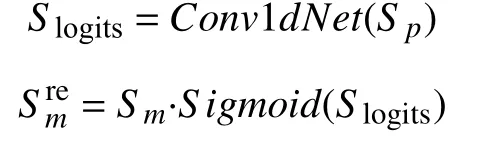

通过TP模块之后, 我们会得到MCM模块最终输出的特征向量vj,.

vj,.表征了人体特定部分的微运动特征. 而人体各个部分的完整微运动特征则需要各个部分并行的MCM模块进行共同表征, 各个MCM模块共同构成了时间聚合器(temporal feature aggregator, TFA)模块, TFA的输出为vfinal={vj,.|j=1,2,···,n} .
最后, 我们使用独立的FC层将vfinal映射到度量空间得到向量vfc. 对于身份识别任务, 我们使用三元组损失函数对vfc进行身份识别任务的训练.
对于年龄和性别识别任务, 由于batch的大小对年龄的估计结果有较显著的影响, 较大的batch所消耗的显存剧增, 而较小的batch不利于模型突破局部最优值.因此我们使用group normalization归一化方式, 避免batch的大小对数据处理产生显著影响. 在性别分类中,考虑到二分类问题对于复杂的神经网络而言学习难度较小, 可能会出现在数据集上出现过拟合的现象, 因此我们在线性层特别使用了dropput技术. 实验表明, 设定合适概率的dropput概率既能给予参数更活跃的搜索空间, 也能使模型在测试时泛化性更强. 两个子任务中对网络的特殊处理有利于增强模型的非线性表达能力.
我们在GaitPart网络的末端添加了若干线性层以及Dropout层对vfc进行进一步的特征映射, 对于性别任务, 我们使用平均绝对误差作为损失函数; 而对于年龄任务, 我们则联合平均绝对误差和JS散度作为损失函数进行训练. 各个部分的实验均采用Adam作为训练的优化器以及采用LeakyReLU/ReLU作为激活函数.
3 实验结果
3.1 系统设计和运行环境
本系统基于“MVC”的设计思想进行设计, 开发出一款集成步态识别算法的Windows电脑客户端程序.程序的交互界面通过PyQt进行构建. 本系统成功在Windows 64位操作系统上运行与测试. 客户端程序交互界面使用QtDesigner完成设计开发, 算法部分使用Python语言编译实现, 在恒源云平台上进行训练优化.硬件层面, 本系统运行和测试的电脑系统为Windows 10家庭版, CPU为i5-8265U, 内存8 GB, 显卡为MX250.
3.2 数据集介绍
3.2.1 CASIA-B 跨视角步态数据集
CASIA-B是目前最为主流的跨视图步态数据库之一. 它包括124个行人样本, 每个行人样本有10种行走状态. 其中, 有6组是处于正常步行状态(NM), 两组是处于携带背包行走状态(BG), 其余的处于穿着外套步行状态(CL). 每种行走状态包含11个不同角度的步态序列(视角的取值0°– 180°, 采样间隔为18°). 因此,整个数据集包含有124 (行人样本) × 10 (行走状态) ×11 (视角) = 13640个步态序列. 由于本系统面向跨视角的应用识别场景, 因此在本文涉及到的算法模型的训练中, 按照主流的测试协议使用了CASIA-B中全部视角的数据进行模型的训练和测试.
3.2.2 OUMVLP大规模跨视角步态数据集
OU-MVLP步态数据集是大阪大学发布的, 目前为止世界上最大的并且具有广泛视野的步态数据集. 该数据集中涵盖了10 307名受试者, 每个受试者每个角度的一段序列作为标签已知的匹配库 (gallery set) 样本, 另一段序列作为标签未知的待识别 (probe set)样本. 其中, 男性5 114名, 女性5 193名,年龄从2到87岁不等. 每个受试者将会从14个视角进行捕获, 范围在0°–90°、180°–270°之间, 每15°为一个分隔. 因此,整个数据集包含有10 307 (受试者样本)×14 (视角)×2(序列数)=288 596个步态序列.
目前在OU-MVLP上主流的测试协议是将10 307个受试者样本划分为训练集和验证集, 其中训练集包含前5 153个受试者, 测试集包含后5 154个受试者. 在训练阶段, 来自所有受试者的gallery和probe序列的图像将同时用于模型训练; 在测试阶段, 仅使用gallery序列独立评估模型表现, 从中随机选择单个帧作为网络输入. 由于本系统面向跨视角的应用识别场景, 并且OU-MVLP数据集拥有年龄与性别标记, 因此本文中的步态年龄与性别估计算法将使用OU-MVLP步态数据集中的全视角的数据集进行训练.
3.3 算法识别效果
基于步态的身份识别算法模型实验在CASIA-B数据集进行训练和测试. 在我们实验的训练阶段, 按照CASIA-B上主流的测试协议使用了数据集前74个受试者(ID: 001–074)的样本数据作为训练集进行训练,然后将剩余的50名受试者(ID: 075–124)将作为测试集进行检验. 在训练阶段, 训练集的每个行人输入网络的步态序列长度为30. 在测试阶段, 我们按照主流协议将测试集拆分为标签已知的匹配库 (gallery set)和标签未知的待识别 (probe set)两个部分. 其中标签已知的匹配库包含测试集中所有ID行人在NM 的前4组步态序列. 标签已知的匹配库样本通过对测试集行人的步态序列进行身份注册以便后续对比. 标签未知的待识别样本为待查询的集合, 其组成为测试集中所有ID行人在其余状态下的序列, 即剩余的 2组NM、2组CL和 2组 BG 的序列集合. 标签未知的待识别样本中的每个个体通过和标签已知的匹配库样本中的所有个体进行逐一对比以评估模型的准确率. 在测试时, 我们对算法模型在每个视角的表现进行独立的评估, 如表2中的逐列准确率数据展示的是标签未知的待识别样本中从0°到180°的每个查询视角和标签已知的匹配库样本中从0°到180°中所有视角(除去查询视角)的跨视角识别准确率的平均值. 在测试过程中, 完整的步态序列输入到模型中以提取步态特征. 实验中输入的批大小为64, 算法模型的训练总共经过8 000次迭代, 训练全过程的学习率固定在1E–4.
本文所采用的算法模型在中科院的CASIA-B数据集的最终的训练结果如表2所示, 通过比较表明我们的方法优于Chao等人[15]和Zhang等人[14]提出的步态识别算法, 在跨视角的情况且处于多种行走状态下(NM: 95.9%, BG: 91.2%, CL: 77.0%)下身份识别的准确率可以达到88.0%, 说明目前我们的算法模型已经能够捕获到判别性的身份特征并处于相对领先的水平.
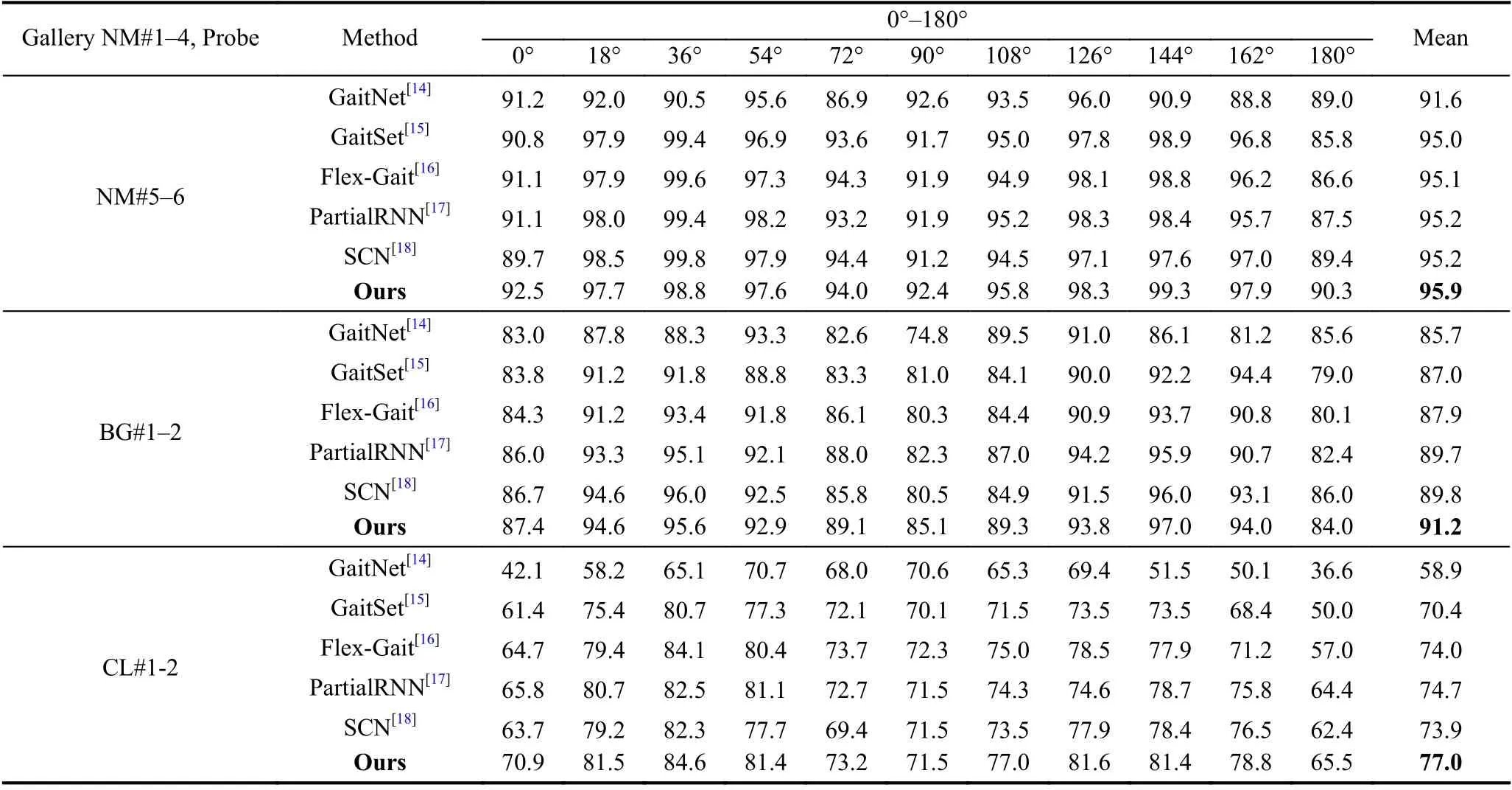
表2 算法模型CASIA-B数据集的Rank-1识别准确率(不包括相同视角)(%)
对于性别分类与年龄估计问题, 我们采用了和身份识别任务相同的步态特征提取器, 并在此基础上自行设计如图所示的分类器, 将高维空间向量映射至二维输出向量. 其中, 性别分类与年龄估计训练过程如图7所示.
在性别分类上, 我们采用性别预测准确率作为我们的评判标准. 图7中“train_acc”表示在训练集上的平均分类准确率, “val_acc”表示在验证集上的平均分类准确率. 经过不少于45 000次的迭代训练后, 算法基本达到收敛状态, 且在验证集中的最高识别率可达95.2%, 泛化至测试集后识别率仍可保持在94.8%的水平. 该算法在性别分类问题上已获取明晰的判别性表示和鲁棒的决策边界.
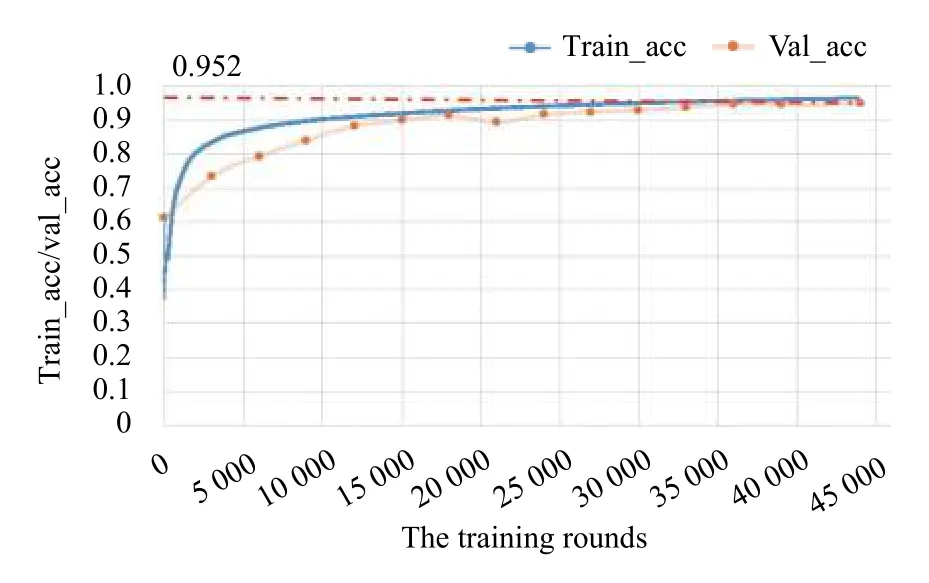
图7 训练集和验证集上的性别识别率
在年龄评估上我们采用平均绝对误差(mean absolute error,MAE)来评估估计年龄的准确性. 假设 ^yi和yi分别表示第i个测试样本的估计年龄和真实年龄,NS表示测试的样本个数,MAE将被计算为:

图8中“train_mae”表示在模型在训练集上的平均年龄误差数据, “val_mae”则表示在验证集上的平均年龄误差. 由图可知, 在经过不少于45 000次的迭代训练后, 训练集上的平均绝对误差逐渐下降, 并且有不断下降的趋势, 而在验证集上的平均年龄误差并没有随着训练而有明显的下降趋势, 这说明模型已经有效收敛. 算法在验证集中的最低平均年龄误差可达7.63岁, 而泛化至测试集后平均年龄误差仍可以保持在7.92岁的水平.

图8 训练集和验证集上的年龄估计平均年龄误差
为佐证本文在性别分类与年龄估计方面的实验效果, 我们将与Xu等人[28]在2021年提出的方法进行对比和分析. 如表3所示, 其中, “GaitSet-Based CNN Framework”是利用PA-GCR (phase-aware gait cycle reconstructor)重建步态周期、利用GaitSet网络提取步态特征的方法, 其跨视角年龄平均分类正确率为94.3%、平均年龄误差为8.39岁. 相比之下, 本文对14个视角下行人的性别预测精度达到了94.8%、年龄估计达到了7.92岁, 算法效果更优, 处于当下前沿领域的高水平层级.

表3 基于步态识别的性别预测结果对比
3.4 在线系统测试
本系统将在模拟安防情景下进行相应的测试. 在测试中, 我们预先录制了多段模拟的“底库视频”及两段模拟的“案发现场视频”, 前者模拟嫌疑人可能逃离的路段视频, 后者则模拟案发路段附近所调取的包含目标嫌疑人的视频. 本系统将对“底库视频”中出现的所有行人步态信息在本地数据库中进行注册和录入,用于与后续“案发现场视频”中的目标嫌疑人员进行比对, 从而确定最终嫌疑人的逃离路段.
图9和图10是本系统对预先录制好的步态视频进行测试的结果. 图10展示的是系统选择嫌疑人ID和筛选年龄条件功能. 其中, 图9为本系统的主页面,用于上传底库和案发现场视频, 并通过系统对比找出底库中步态信息与被选择的嫌疑人最为相似的前3位行人, 返回相应的步态年龄、性别以及所处路段.

图9 系统主页面和ID选择
在测试中, 我们输入了7段测试视频, 视频中共有受试者229名,年龄均为15–63岁, 男女分布均等. 测试结果为: 身份匹配Rank-1准确率为81.93%, Rank-5准确率为94.16%,年龄预测平均年龄误差为7.5岁, 性别识别准确率为91.63%. 从测试结果可以看出, 当识别视角发生改变且嫌疑人通过戴口罩进行面部遮挡并更换着装再次出现在已录入底库中的视频中时, 系统也可以准确地对嫌疑人进行识别, 证明了本系统具备较好的鲁棒性, 可以满足实际应用中复杂的场景需求.
在图10展示更多检测结果页面中, 系统将展示所有在底库视频中出现的行人步态信息与嫌疑人步态信息的对比结果, 并且具备筛选功能: 通过嫌疑人的年龄以及性别信息对海量的行人信息进行进一步的筛选,以辅助应对一些由于特殊情况导致的身份识别不准确的情况, 从而加快查找速度.

图10 展示更多检测结果页面和条件筛选
通过常规的外置摄像头或者安防摄像头, 本系统可以实时捕捉行人的步态信息. 由于算法模型已具有预训练权重并且配备好相应的环境依赖项, 因此当用户上传步态视频后, 系统可以快速地返回相应的结果.上述测试场景中, 在1080Ti的GPU算力环境下, 系统处理视频的速度为每帧0.373 s, 且可在2 s内返回对比结果, 因此可以满足实际场景中实时监测的需要, 具有实际的开发意义.
4 总结
本文搭建了一种可以在视频监控条件下实现多行人多生物属性跨视角步态识别的智能安防追踪系统,该系统适用于安防和寻人等实际应用场景, 可以追踪不同路段处在不同视角处于不同行走状态的行人步态信息并通过系统内置的算法模型对其身份、年龄和性别等属性进行准确高效的分析. 本系统的算法模型基于深度学习理论及算法, 在Fan等人[27]提出的算法基础上加以优化, 同时在目前最为主流的两个大规模跨视角步态数据集——中科院的CAISA-B数据集以及日本大阪大学的OUMVLP数据集上进行了训练和测试并取得了处于相对高水平的准确率, 在跨视角的测试前提下, 身份识别在多种行走状态下(NM, BG, CL)的平均准确率达到88.0%, 性别识别准确率达到94.8%,年龄估计的平均误差在7.92岁, 基本符合实际应用的水准. 与此同时, 系统的开发成本低, 支持实时检测并具备拓展性, 可以根据不同团队的需要进行适应性调整, 因此具有重要的现实意义.
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
意林(2021年5期)2021-04-18
阅读与作文(英语初中版)(2019年8期)2019-08-27
扬子江(2019年1期)2019-03-08
科学之谜(2018年4期)2018-09-17
中国新闻周刊(2017年20期)2017-06-15
小天使·一年级语数英综合(2017年6期)2017-06-07
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
