
基于支路功率估计的配电网拓扑识别
2022-08-24 09:26:44郭少飞李铁成陈天英张卫明吴巨豪
电力系统及其自动化学报 2022年8期
郭少飞,李铁成,陈天英,张卫明,李 泽,吴巨豪
(1.国网河北省电力有限公司电力科学研究院,石家庄 050020;2.西安交通大学电气工程学院,西安 710115)
随着新型电力系统的发展,新能源和新型负荷的随机性和波动性使配电网的开放性、不确定性和复杂性不断增加,给配电网运行带来了新的挑战[1]。为保证电力系统安全、稳定和经济运行,需要对电网进行实时的状态估计、安全评估、网络重构以及继电保护在线整定,而这些任务的执行均以当前的网络拓扑为基础[2-4]。因此,快速准确的拓扑识别对于实现配电网的可观、可测和可控性尤为重要。
目前配电网的拓扑识别方法大致可分为以下3类:①基于配网潮流和枚举的传统拓扑识别方法,有规则法[5-6]、树搜索法[7-8]、矩阵法[9]、新息图法[10]、图论法[11]等,这些方法在原理上高度依托的数据采集与监视控制系统数据稳定性差,遥信数据经常误报、未报,识别结果具有较大的不确定性,且需要的量测设备冗余度较高,而大多老旧城区或郊区的配电网装设量测较少,此类方法实用性较差。随着量测技术的发展,文献[12-13]基于微型同步相量量测装置μPMU(micro-synchronous phasor measurement unit),通过枚举法,将测量的电压相角与各拓扑下的估计值进行内积匹配以实现拓扑识别,准确度较高,但枚举法计算量大、耗时长,同时装置成本较高,难以大规模应用于配网,此类方法实用性受限。②基于数据驱动的拓扑识别方法。文献[14]基于数据驱动的回归方法对导纳矩阵进行初步估计,再通过改进牛顿-拉夫逊法进行矫正;文献[15]则基于解耦线性潮流方程推导了导纳矩阵与测量值之间的线性关系,并提出了一种全最小二乘回归方法。两种方法均能在拓扑识别的过程中完成了线路参数估计,但所需采集的数据量大,不宜用于运行方式多变的配网。此外,前者耗时长,后者耗时短但因模型的过度线性化,仅适用于辐射形配电网。从数据驱动角度来识别拓扑的还有机器学习算法[16-17],速度快,鲁棒性强,但需要大量样本离线学习,较难应用于老旧或扩建中的配网。③基于智能优化的拓扑识别方法。文献[18-19]以潮流计算值与量测值误差最小为目标函数,将拓扑识别问题重构成混合整数线性规划模型,电网规模小时可通过割平面法获得最优解,电网规模较大时则难以获得最优解,多通过启发式算法求取较好的可行解。其中,文献[18]采用了Distflow潮流模型,计算速度快,但仅适用于辐射形配电网;文献[19]提出了多周期算法,具有广泛的适用性,并为提高准确度和鲁棒性,但该算法耗时较长,识别的实时性较差。
综上所述,传统拓扑识别方法具有较广的适用范围,但大多对量测要求较高,因此实用性较差;基于数据驱动的拓扑识别方法的实时性和准确性较好,对量测要求不高,但所需训练样本较多,在实际配网中难以准确、全面地获取,且不便于应对配网的改建和扩建;基于智能优化的拓扑识别方法的适用范围较广,准确性较好,但对于大电网的实时性较差。因此,目前拓扑识别领域尚少有能同时兼顾对量测要求低、实时性好、准确性高并且适用范围广的实用方法。
为兼顾上述要求,本文基于支路功率估计,计算潜在网络拓扑并缩小其范围,实现最佳网络拓扑快速匹配。本文的主要贡献在于:首先,通过回路分析法与叠加定理推导出附加功率的公式,结合独立回路等数量的支路功率量测与初始网络潮流完成各支路功率的初步估算;其次,引入功率损耗构建修正方程,对初估支路功率估计进行迭代修正,保证算法的准确性;再次,根据修正支路功率列举较优匹配拓扑及其邻拓扑,保证算法的时效性;最后,分别比较潮流计算结果与量测值,选出最佳匹配网络拓扑。该算法适用于辐射网、环网和扩建中的配网,能够在一定的数据误差下,仅需利用少量量测和单个时间断面信息便可正确识别出网络拓扑,准确率高,实时性好。
1 回路分析法的附加功率
对于任一n节点、b支路的配网,其包含该n个节点且不形成任何回路的子网称为树,树上的n-1条支路为树支,其余b-n+1条支路为连支,单个连支与树形成的回路为基本回路,是一种特殊的独立回路,其个数为l=b-n+1,树支(实线)和连支(虚线)确定的简单配网,如图1所示,其中n=7,b=8,l=2。

图1 简单配网Fig.1 Simple distribution network


2 基于支路功率估计的拓扑识别方法
结合第1节的讨论,可得配网拓扑识别思路如下:①通过实时量测与潮流计算求解各独立回路的附加功率,通过与初始网络拓扑的潮流叠加完成对支路功率的初步估计;②考虑支路功率损耗,修正初估支路功率;③将功率估计值小的支路列为可能开断的线路,据此列举可能的网络拓扑,分别进行潮流计算,将结果与量测进行比对,筛选出最匹配的网络拓扑。
2.1 支路功率的初步估计

对于支路无功的估计,其过程与有功基本一致,不同之处在于方程右边应减去TTδQN的相应元素。当功率量测装置没有安装于以PV节点为末节点的道路上时,TTδ'QN的相应元素均为0,此时支路无功的估计过程与有功完全一致。
2.2 对初估支路功率的修正
前文的推导和计算均基于无功率损耗的理想条件,因此同一独立回路中的各支路附加功率相等。而实际上,线路功率损耗的存在使得附加功率在不同支路上具有不同的值,第2.1节中估计的支路功率实则是利用带量测支路上的附加功率求得的,其他支路上的功率估计值会与真值有不同程度的偏差,且通常真值越小的支路受影响越大。因此需要考虑功率损耗对初步估计的支路功率进行修正。
图2为某网络中支路i-j的示意,分别列写2种网络状态下的有功损耗表达式,有
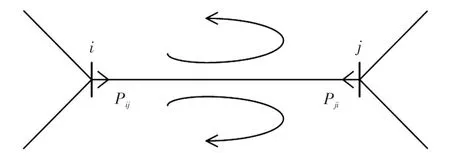
图2 支路i-j示意Fig.2 Schematic of branch i-j

式中:Pij为初始网络支路i-j首端的有功功率,方向以i指向j为正;Pji为末端有功功率,方向以j指向i为正;则分别为待识别网络支路i-j的首末端有功功率;分别为初始网络和待识别网络支路i-j的有功损耗。


对于一个量测布置合理的n节点、b支路、m量测的配网,式(19)和式(21)所示方程组有b+n-1+m个独立方程和2b个未知数,由第2.1节所述量测布置原则可知:量测数不少于独立回路数,即m≥b-n+1,因此方程数b+n-1+m>2b,由式(9)可求得该方程组唯一解ΔP,该ΔP实则为具体到支路两端的附加有功功率。
为提高支路功率修正的准确性,可对该修正方程进行迭代计算。每次将修正后的支路功率代替修正前的支路功率来估算新的功率损耗,再用新的功率损耗对支路功率进行新一轮修正,在收敛精度为10-3时,一般只需迭代2~3次即可达到收敛。最后通过相应下标的S'=S+ΔS便可完成对初估支路有功的修正。
2.3 网络拓扑判定
在对支路功率进行修正后,与同一独立回路中其他未开断支路相比,开断支路的功率估计值应小得多,但测量误差的影响仍然存在,可能导致在所属回路一致的邻近支路间的误判,因此需要留有一定裕度。综合以上分析,可以得出判断支路开断的原则:各独立回路中,功率估计值最小的支路为最有可能开断的支路,与其同属相同独立回路的功率估计值次小的邻近支路为较有可能开断的支路。判定流程可分为以下2个阶段。
(1)构建大概率开断支路集合与备选支路集合,具体步骤如下:
步骤1将修正后的支路功率估计值按升序排列。
步骤2取前l(独立回路数)条支路,观察由这些支路在回路矩阵相应列组成的矩阵是否满秩,若不满秩,去除排序较后的线性相关列及对应支路,并按顺序补充新的支路,重复该过程直至所形成矩阵满秩,则该l条支路即为大概率开断支路集合。
步骤3根据各条大概率开断支路在回路矩阵的相应列,选取列绝对值一致的功率仅次于该大概率开断支路的支路作为备选支路,若无列绝对值一致的支路则无备选支路。
(2)按邻拓扑搜索比较差异度,具体步骤如下:
步骤1根据大概率开断支路集合形成较优匹配拓扑。
步骤2定义仅有1组开断支路不同的拓扑互为邻拓扑,列举较优匹配拓扑的邻拓扑。
步骤3对较优匹配拓扑及其邻拓扑分别进行潮流计算,结合量测值计算差异度,即

式中:下标k表示量测编号;为量测值;为潮流计算值;w为量测权重,与量测误差的平方成反比。为方便起见,本文算例将沿用先前步骤用到的支路功率量测,不再增添其他类型量测。
步骤4对差异度进行比较,若某邻拓扑的差异度最小,则将该拓扑作为新的较优匹配拓扑,并返回步骤2;若较优匹配拓扑的差异度最小,则输出该拓扑为拓扑识别结果。
2.4 支路量测布置与回路矩阵生成
本节对所提方法的主要流程进行了讨论,从中不难看出,回路矩阵是贯穿本文方法的一个关键点,支路功率量测的布置则关乎到能否正确进行支路功率的估计。对此,在第2.1节中指出了量测布置应遵循的原则:矩阵BM行满秩,可见回路矩阵还是验证量测布置合理性的重要依据。为此,对回路矩阵的生成及其与量测布置的关系进行分析。
对于同一电路,在各支路、节点的编号和方向相同时的节点-支路关联矩阵A和回路矩阵B的关系[23-24]为

式中,A为不含参考节点行的(n-1)×b阶降阶关联矩阵,当节点i为支路k的首、末端点时,其元素aik分别为1和-1;当节点i非支路k的端点时,aik=0。
若按“先树支后连支”对支路排序,矩阵A和B可分别写成[AtAl]和[BtE],其中下标t对应于树支,下标l对应于连支,E为单位矩阵,故式(23)可写为
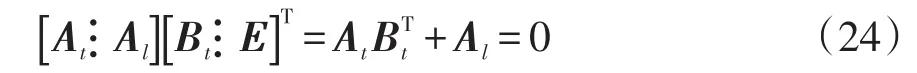
式中:At和Al分别为关联矩阵的树支和连支部分;Bt为回路矩阵的树支部分,即有

故可求得回路矩阵为

对于简单网络,可以人工挑选树支和连支并进行排序,但在复杂网络中或需要独立回路灵活变动的情况下,人工挑选显然不能满足要求,需要连支的自动识别和编排。
由关联矩阵的性质可知,在关联矩阵中,可以构成回路的各支路所对应列向量之间线性相关,而树支所对应的列向量之间线性无关,那么树所对应的向量组即为极大线性无关组。因此可以通过求取极大线性无关组来划分树支和连支,比较简便的方法是将关联矩阵化为行阶梯矩阵,极大线性无关组即由各行首个非零元素所在列组成,其对应的支路即为网络的树支,其余为连支。
值得注意的是,由此法确定的连支一般对应于关联矩阵中列号较大的列向量,因此可以通过对支路排序的调整确定不同的连支,从而灵活地生成回路矩阵。
对于已布置量测的配网,可将带量测支路对应的列向量移至最右列来生成回路矩阵,使带量测支路尽可能成为连支以遍布所有独立回路,然后提取回路矩阵中带量测的列向量组成矩阵BM,观察其是否行满秩以验证量测布置的合理性,若否,则应增添量测于能使BM行满秩的支路。
对于未布置量测的配网,则可在求取回路矩阵的同时提供一种布置参考,即:布置于使BM行满秩的支路上,如直接布置于连支。
综合本节所述,基于支路功率估计的拓扑识别具体算法流程如图3所示。本文算法的核心如下:
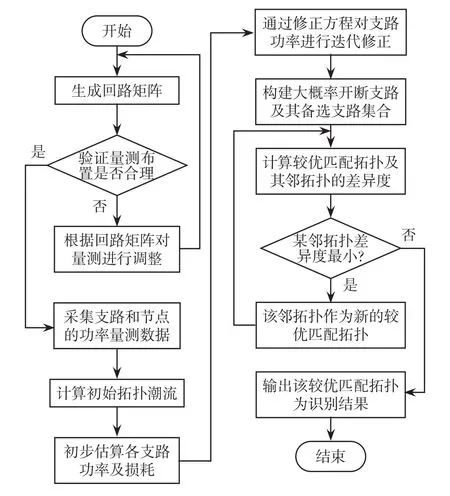
图3 拓扑识别算法流程Fig.3 Flow chart of topology identification algorithm
(1)利用实时量测量和初始潮流,根据回路分析法和叠加定理求取附加功率,用以初步估算支路功率;
(2)利用功率损耗构建修正方程,通过对功率损耗的估计并代入修正方程迭代,对支路功率进行迭代修正;
(3)根据修正后的支路功率构建大概率开断支路及其备选支路集合,列举较优匹配拓扑,通过邻拓扑搜索计算比较差异度选出最优匹配拓扑。
3 算例分析
本节选用IEEE-33节点配电系统和雄安新区实际双花瓣配电系统作为算例,对所提方法进行验证分析。
3.1 IEEE-33节点配电系统
IEEE-33节点配电系统拓扑如图4所示,图中:虚线表示联络线,联络开关常开,配网开环运行,在需要为失电负荷供电或为经济运行而进行网络重构时,联络开关则按需闭合,传统配网多为此类运行模式。
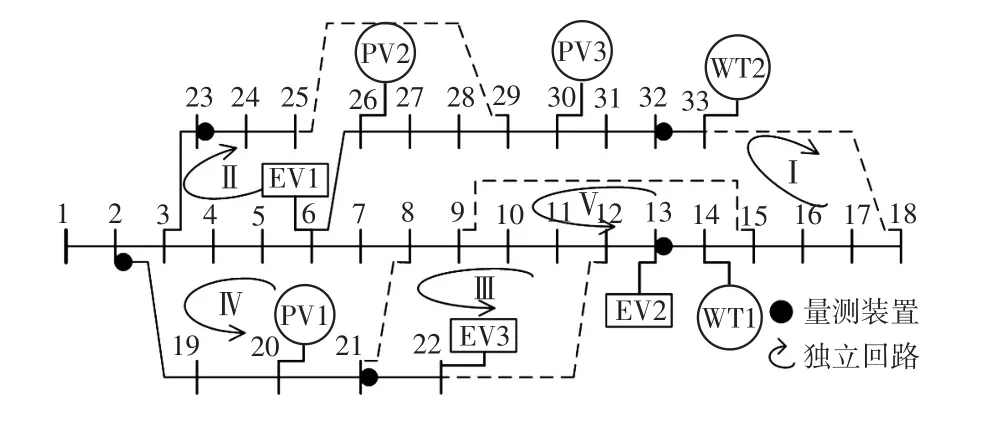
图4 IEEE-33节点配电系统Fig.4 IEEE 33-bus distribution system
在系统中接入5组分布式电源和3组电动汽车,其中WT1和WT2表示风力发电机,PV1、PV2和PV3表示光伏电站,EV1、EV2和EV3表示电动汽车。假设风力发电机能维持机端电压恒定,将所在节点设为PV节点,光伏电站和电动汽车所接节点设为PQ节点[17],所使用的功率断面信息:WT1和WT2出力均为450 kW,PV1、PV2和PV3出力均为250 kW,EV1、EV2和EV3功率均为200 kW。
设置支路功率量测误差为1%,具体安装位置见图4中圆点;考虑到传统配网对负荷多采用基于智能电表或负荷预测的伪测量,设置各节点功率量测误差范围为10%~50%[19]。所有误差均服从“3σ”原则的高斯分布。
3.1.1 量测布置验证
首先对量测布置的合理性进行验证,以量测支路为连支生成回路矩阵,独立回路的划分与编号如图4所示,从中挑选相应列向量组成的BM正好是一个反向单位矩阵(单位矩阵的左右镜像),即连支均为带量测支路。
若将支路32-33首端的量测装设于支路11-12首端,会生成不同的回路矩阵,BM也会变为
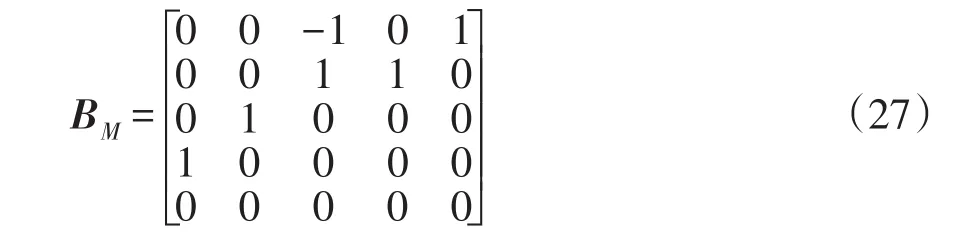
可见,BM的行秩为4,不满足量测布置原则,因此需对量测布置进行调整。回路矩阵中连支对应的列向量由一个1和若干个0构成,可见除BM第3列对应的支路11-12外,其余带量测支路均为连支,因此结合回路矩阵,应将支路11-12首端的量测安装于图4所示独立回路I上的支路,如本例原设的支路32-33首端。
3.1.2 拓扑识别结果
预设支路6-7、8-21、10-11、26-27、12-22开断,其余支路闭合。通过Matlab编程算得节点功率量测误差为10%时修正前后的视在功率估计值S'、S″与实际值Sactl,如图5所示。为方便比较和观察,图5仅截取有明显差异的Sactl<0.4 MV·A的部分曲线。
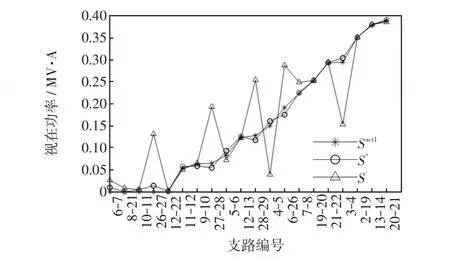
图5 支路功率估计值与实际值对比Fig.5 Comparison between estimated and actual values of branch power
在图5中,S'与Sactl在某些支路上差别较大,而S″与Sactl基本重合,可见修正效果显著。接下来要确定开断支路的组合,表1列出S″最小的16条支路及其所在的独立回路。
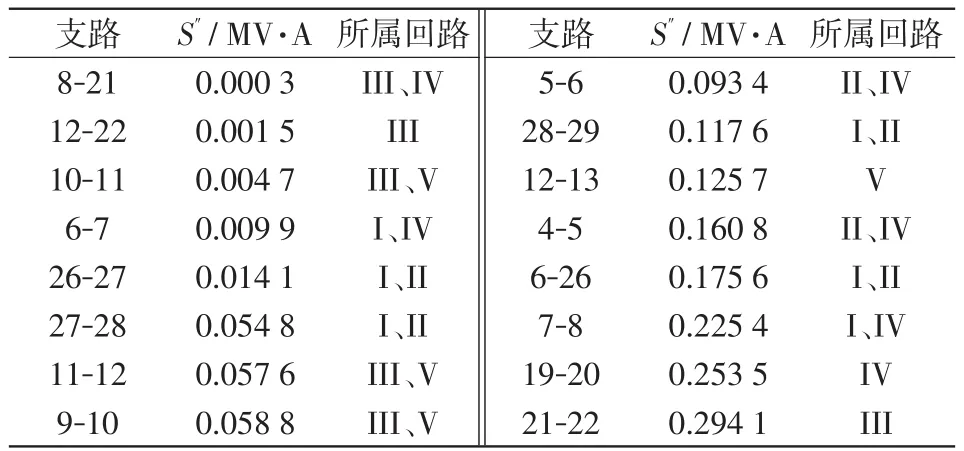
表1 支路功率估计值及所属回路Tab.1 Estimated value of branch power and loops to which it belongs
根据第2.3节第(1)阶段的判定流程可以确定最可能断开的5条互不相关的支路为8-21、12-22、10-11、6-7、26-27,除支路8-21无备选支路外,其余支路的所属回路一致的备选支路分别为21-22、11-12、7-8、27-28。表2列出了全部16种开断支路组合及其差异度。
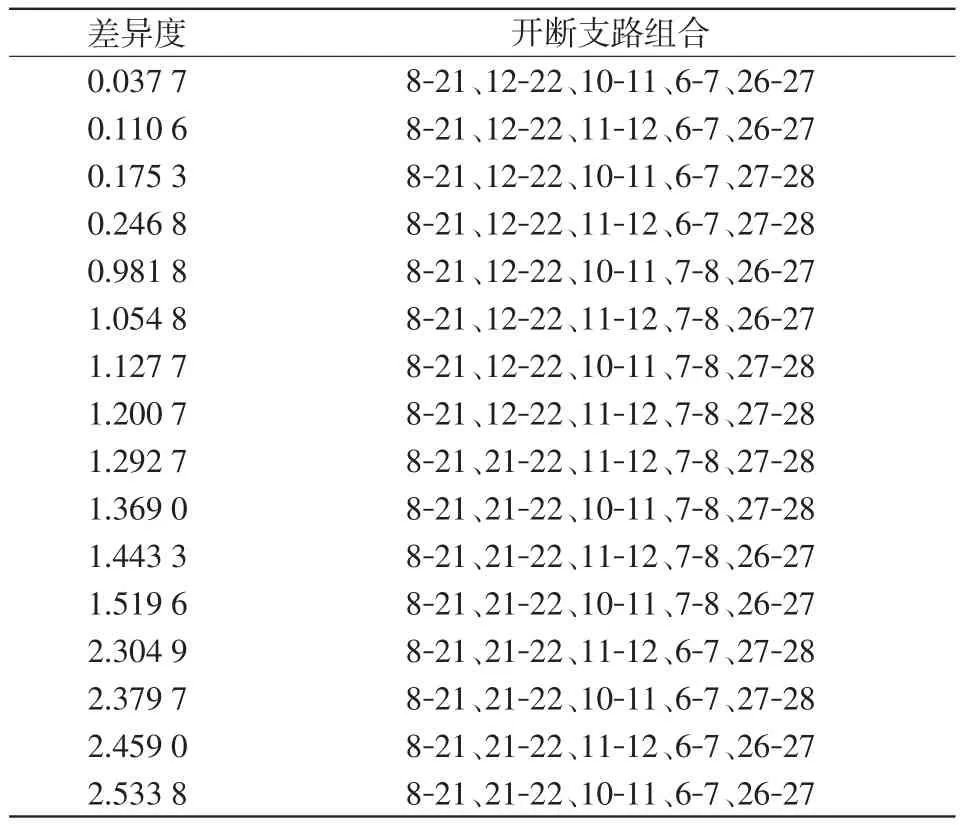
表2 开断支路组合及差异度Tab.2 Combination of open branches and the corresponding difference degrees
根据第(2)阶段的判定流程,较优匹配拓扑的断线组合为8-21、12-22、10-11、6-7、26-27,位于表2的第1行,其邻拓扑共有4个,对应断线组合分别位于表2的第2、3、5和16行,经比较可得较优匹配拓扑的断线组合差异度最小,且与次小差异度相差2倍以上,区分度较好,其与预设的开断支路吻合,拓扑识别正确,全程耗时0.05 s。相较于对全部开断支路组合的遍历,按邻矩阵搜索节约了60%的计算量。
若使用未修正的支路功率估计值S'进行拓扑识别,最可能断开的5条不相关支路则为6-7、8-21、10-11、6-7、12-22,相应的备选支路为7-8、21-22、11-12、5-6。预设的开断支路26-27不在里面,最终不能正确识别,可见支路功率修正对识别准确性的提升来说是非常必要的。
3.1.3 性能分析
在开环运行原则下,IEEE-33节点配电系统可能的拓扑有50 751种,但其中包含大量不符合电网运行要求的拓扑,因此仿照文献[19]的混合整数规划法,选取50种拓扑作为待识别拓扑集合,分别在10%、20%、30%、40%和50%的节点功率量测误差下进行识别。
图6为本文方法与文献[19]算法的识别正确率对比,通过带“o”标和带“*”标曲线的对比,可以看到在不同节点功率量测误差下,本文方法正确率均略高于文献[19]的整数规划法。值得注意的是,带“o”标曲线展示的是本文在最少量测布置(5个支路功率量测)下的正确率,若在更多支路上布置功率量测,或增添其他类型量测,如电压量测等,则所能达到的理想正确率见图6中带“Δ”标曲线,可见增加量测可进一步提高本文方法的准确性。

图6 正确率对比Fig.6 Comparison of accuracy
在算法效率上,在不同量测误差下,文献[19]方法平均单次识别耗时均在1 s左右,本文方法对各待识别拓扑的平均单次耗时见图7。由于本文算法耗时主要取决于潮流计算次数,当节点功率量测误差为10%~30%时,支路功率估计较为准确,基本上第1次形成的较优匹配拓扑恰与实际拓扑吻合,能在7次潮流计算内完成拓扑识别,耗时不到0.05 s;当节点功率量测误差变大时,较优匹配拓扑与实际拓扑的差别一般也会随之变大,识别耗时较长,但均比对可能断线组合的遍历耗时短。总体上,识别耗时不到文献[19]的1/8。可见,大概率开断支路及其备选支路集合的选取与按邻矩阵搜索列举拓扑使本文方法在效率上具有双重保障。
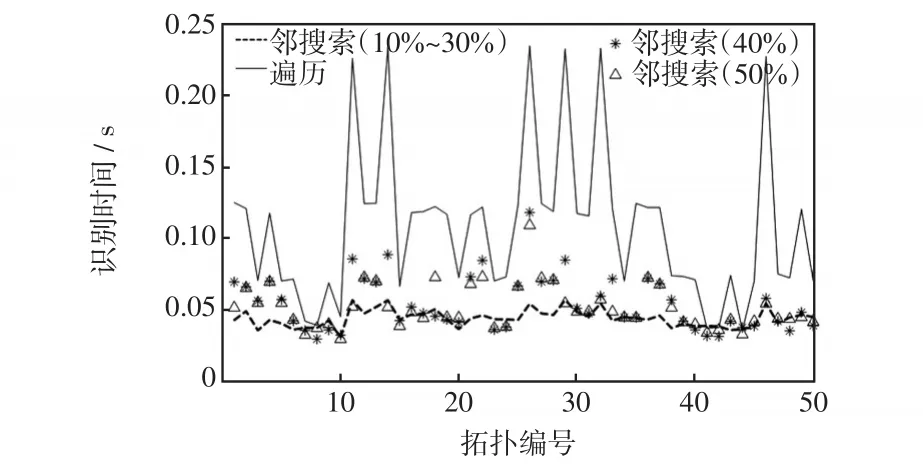
图7 识别耗时对比Fig.7 Comparison of identification time-consumption
综上,本文方法在较少的量测下,利用单个时间断面信息,在不同量测误差下能保持与整数规划法相近的正确率,并在实时性上具有较大的优势。
3.2 10 kV双花瓣配电系统
双花瓣配网拓扑如图8所示,其中节点1、6为两变电站母线,其余节点为开关站母线,4个联络开关常开,用虚线表示,正常运行时花瓣内合环,花瓣间开环,负荷由双线供电,单线开断时供电不受影响,双线开断导致断供时则由联络开关将负荷转至对侧花瓣,是一种供电可靠率高达6个“9”的先进配电网[25]。
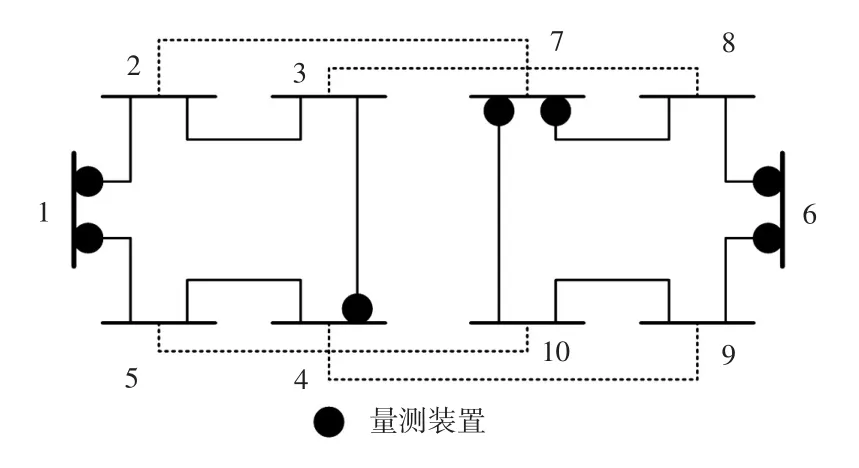
图8 双花瓣配电系统Fig.8 Double-petal distribution system
支路量测的布置与误差设置同33节点算例,节点功率量测因开关站出线均装设有馈线终端装置,量测误差为1%,所有误差均服从“3σ”原则的高斯分布。
由双花瓣配网运行特性可知其运行时实际上是两个独立配网,因此要先判定花瓣间在何处“解环”。思路与前文所述方法一致:先断开4个联络开关,闭合其余开关作为初始网络拓扑计算潮流,分别使用变电站2个出线功率量测对花瓣各进行一次功率估计,若2条开断支路是同一支路,则拓扑识别为单线开断,若开断的是2条不同支路,说明已有负荷转至另一花瓣,则需对另一花瓣进行拓扑识别。
以情况较为严重的母线1故障/检修为例,其所有开关站需转由对侧花瓣供电,常用策略为首开关带路方式和全切全带路方式,如图9和图10所示。若考虑同时发生其他故障或拒动误动,或因其他特定目标的策略,通过对回路矩阵的遍历分析可知可能的网络拓扑共有476种,对每种结构进行4次拓扑识别,结果见表3。
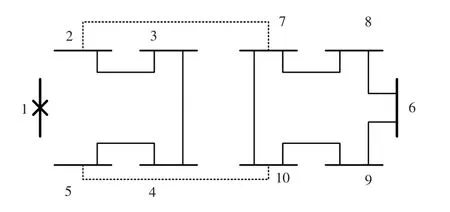
图9 首开关带路方式Fig.9 Load transfer by the nearest interconnection switch
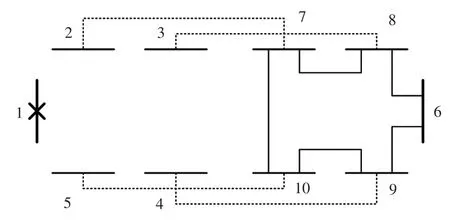
图10 全切全带路方式Fig.10 Load transfer by all interconnection switches

表3 双花瓣配网识别结果Tab.3 Identification results of double-petal distribution network
可见本文方法在环网中也能快速成功地识别出所有拓扑,其中仅有的2次识别错误均来自同一拓扑:首开关带路方式下支路6-8开断。该拓扑下支路2-3传输的功率不到其他支路的2%,在2次错误的识别中,支路2-3不同状态所对应的f相差分别为1.7%和2.5%,说明该支路的开断与否对潮流影响很小。这类误判的根源在于环网运行特性,在某种运行方式下,某环中某支路传输功率可能会非常小,其状态改变对其他支路潮流的影响甚至比不上量测误差,此时单靠计算潮流与量测比对难以正确识别,需结合其他如遥感类的信息,但这种情况发生条件较为苛刻,总体上影响不大。
4 结论
本文基于附加功率对支路功率进行估计,通过功率损耗完成对支路功率的修正,据此列举了较优匹配拓扑及其邻拓扑,并与量测比较选出最佳匹配拓扑。通过算例验证结论如下:
(1)在不同的量测误差下,根据修正支路功率列举的网络拓扑均能基本实现对正确拓扑的含概,由此识别正确率得到了保证,此外,增加量测可进一步提高准确度与鲁棒性;
(2)识别耗时主要取决于潮流计算的次数,大概率开断支路及其备选支路集合的选取与按邻矩阵搜索列举拓扑均能在保证准确度的同时减少拓扑枚举数,从而大幅提高效率,在IEEE-33节点系统中识别耗时不超过混合整数规划法的1/8;
(3)适用于辐射网和环网,能在较少量测下利用单个时间断面信息准确快速地完成拓扑识别,具有较好的实用性。
猜你喜欢
网络安全与数据管理(2022年2期)2022-05-23 13:25:46
能源工程(2020年6期)2021-01-26 00:55:22
电子制作(2018年23期)2018-12-26 01:01:16
汽车维修技师(2017年10期)2017-03-17 02:25:01
足球周刊(2016年14期)2016-11-02 11:47:59
足球周刊(2016年15期)2016-11-02 11:44:02
足球周刊(2016年10期)2016-10-08 18:50:29
电信科学(2016年9期)2016-06-15 20:27:30
电测与仪表(2016年5期)2016-04-22 01:13:46
电测与仪表(2016年13期)2016-04-11 11:21:20
