
融合情感词典的改进BiLSTM-CNN+Attention情感分类算法
2022-08-23 14:49杨秀璋郭明镇候红涛袁杰李晓峰李坤琪汪威何世群罗子江
科学技术与工程 2022年20期
杨秀璋, 郭明镇, 候红涛, 袁杰, 李晓峰, 李坤琪, 汪威, 何世群, 罗子江
(贵州财经大学信息学院, 贵阳 550025)
随着互联网迅速发展,以搜索引擎、微博、在线评论、论坛博客等为代表的应用与日俱增,人们可以在网络平台上发表主观性的评论信息及情绪表达,如何快速精准地对这些评论进行情感分类,挖掘出用户的情感态度及主题观点,已成为重要的研究问题[1]。情感分类(sentiment classification)作为自然语言处理领域的一个研究热点和难点,旨在对带有感情色彩的文本进行推理,精准地分析评论者的态度及情感倾向,并划分为积极或消极情绪,最终从文本中得到评论者所持观点,以期提供更精准的推荐或决策支持。因此,如何从用户评论中准确地挖掘出情感倾向具有重要价值[2-3]。
传统情感分类方法通过关键词匹配,检测文本中所包含的情感特征词,再进行情感分数计算并预测其正面和负面情绪。杨鑫等[4]通过情感倾向点互信息(semantic orientation and pointwise mutual information, SO-PMI)算法构建民宿领域词典,完成社交媒体中民宿评论的情感分析。Alejandra等[5]通过计算WordNet词典的相似性以确定特征词的情感倾向,实验证明同类别情感特征词具有同质相似性,并为情感分析提供支撑。刘文龙等[6]利用领域词典对留园构成要素开展情感分析,从而为园林旅游和景点管理提供理论基础。然而,这些方法十分依赖情感词库和分类规则,需要借助专家知识进行大量标注,并且面对大规模文本语料或特定领域的情感分析时,其算法的准确度和鲁棒性较差,缺乏特征词间的语义分析。
近年来,机器学习和深度学习技术兴起,很多学者将机器学习算法和神经网络应用于情感分析领域。高欢等[7]设计集成学习对在线评论实施情感倾向预测,并在酒店、图书领域验证了算法的有效性。邓君等[8]基于Word2Vec和支持向量机(support vector machines, SVM)构建微博舆情情感演化分析模型,有效反应网民对五类主体对象的情感态度。为了进一步结合上下文的语义关系,利用向量空间表征文本,提升情感分类效果,卷积神经网络(convolutional neural network, CNN)和循环神经网络(recurrent neural network, RNN)被应用于情感分析。程艳等[9]提出了一种多通道CNN和双向门控循环单元(bidirectional gated recurrent unit, BiGRU)的神经网络模型,从而提升文本情感特征的提取能力。梁淑蓉等[10]在XLNet基础上增加长短时记忆(long and short-term memory, LSTM)网络层和注意力机制,整个模型的精确率达到89.29%。曾子明等[11]构建双层注意力和双向长短时记忆网络(bidirectional long and short-term memory,BiLSTM)模型,对微博公共安全事件文本进行情感分析。然而,上述方法忽略了上下文语义的关联关系,分类模型在处理情感分类任务时会忽略情感特征词的强度,难以避免引入干扰信息和克服短文本的特征稀疏问题,并且没有突出情感特征词对情感分类结果的贡献。因此,它们较难挖掘到深层次的文本特征,从而限制情感分类的精准度和鲁棒性。
针对这些问题,提出一种改进BiLSTM-CNN和注意力机制的情感分类模型,通过引入情感词典来优化特征词的权重,再结合BiLSTM-CNN和Attention模型进行分类,以期为商品推荐和舆情分析做出更好的决策提供理论和实践支撑。
1 相关工作
1.1 基于情感词典的情感分类
情感词典指带有情感色彩的词或词组以及对应情感极性和情感强度的集合,领域情感词典在文本挖掘和自然语言处理领域发挥着重要的作用[12]。基于情感词典的分析方法是对评论文本进行特征词匹配,结合语法规则来计算情感分数。目前国内开放的情感词典主要包括知网(HowNet)[13]、大连理工大学情感词汇本体库[14]、清华大学情感词典[15]、同义词林[16]等。安璐等[14]结合大连理工大学情感词汇本体库,融合主题与情感特征对微博突发事件进行情感演化分析。Li等[17]利用情感词典构建分类模型,对视频弹幕评论开展情感分析,并有效提取7个维度的情感分布。马晓慧等[18]融合情感词典,提出一种基于语义相似性度量和嵌入表示的情感分类方法。张鹏等[19]结合理论和情感词典,对微博突发事件进行对应的情感分析和舆情引导策略研究。Xu等[20]通过扩展情感词典来提升情感分类的准确性,并证明了情感词典对评论文本情感分析的重要意义。崔彦琛等[21]构建网络舆情情感词典识别消防突发事件。
然而,基于情感词典的分类方法需要通过专家经验进行特征划分,十分依赖情感词库及分类规则的制定,导致其扩展性较差。此外,随着社交媒体评论数量日益增长,该类方法面对大规模文本语料或针对特定领域的情感分析时,其算法的准确率较低,也缺乏特征词间的语义分析和关联挖掘,从而导致基于情感词典的方法在领域文本情感分析中效果不理想。
1.2 基于机器学习的情感分类
近年来,基于机器学习的情感分类方法越来越多,其分类效果也得到一定提高。常用方法包括SVM、K最近邻(k-nearest neighbor, KNN)、决策树(decision tree, DT)、朴素贝叶斯(naive bayes, NB)、隐马尔可夫模型(hidden markov model, HMM)等[22-23]。王婷等[22]详细总结了基于传统机器学习的情感分析方法。张冬雯等[24]结合Word2Vec和SVMperf对中文评论数据进行情感分类研究。Lu等[25]提出了一种基于SVM和四类情感词典的情感分析方法,并对影评文本进行分析及评估。李明等[26]通过卡方检验方法进行文本特征选择和降维,详细对比朴素贝叶斯、SVM、决策树、KNN的4种情感分类方法。Gonzalo等[27]通过构建贝叶斯网络分类器对Twitter舆情事件开展情感分析研究。
上述方法虽然提升文本情感分类的准确率,但只能提取评论文本的浅层知识,缺乏考虑上下文依赖关系,忽略语义知识及情感特征词对文本情感分类的影响,并且没有结合注意力机制突出情感特征词的重要程度。此外,早期基于机器学习的文本分类方法主要通过词频、词频及逆文档频率(term frequency inverse document frequency, TF-IDF)、信息熵、互信息等技术提取文本特征,再调用机器学习算法进行文本分类,但这些评估函数大多基于统计学原理,缺乏对海量评论文本数据的有效分类。
1.3 基于深器学习的情感分类
随着深度学习和人工智能的兴起,以词向量模型为基础,融合深度神经网络、隐含狄利克雷分布(latent dirichlet allocation, LDA)模型、注意力机制的情感分类方法逐渐出现。Mikolov等[28]提出了Word2Vec模型,通过训练大规模语料得到低维词向量,从而表征语义信息,常用框架包括CBOW和Skip-gram。随后,融合词向量或词嵌入的深度神经网络模型开始逐渐应用于评论文本情感分类任务中。陈可嘉等[29]利用Word2Vec实现股市情感词典的自动构建。张海涛等[30]通过卷积神经网络对微博舆情数据进行情感分类研究,相较于SVM模型,CNN模型能够实现更细粒度的情感特征识别。邱尔丽等[31]通过字符级CNN技术完成公共政策网民支持的分类研究。李天赐等[32]设计并实现多输入通道卷积神经网络(multi-input channel convolutional neural network, MIC-CNN)模型,最终中文新闻情感分类的精确率比普通CNN提高2%~3%。
同时,由于循环神经网络(RNN)可以联系上下文突出文本序列信息,它也被应用于自然语言处理领域。为进一步解决RNN模型的梯度爆炸和梯度消失问题,提出门控递归单元网络(gated recurrent unit, GRU)和LSTM并应用于文本分类任务。李云红等[33]提出了一种基于循环神经网络变体和卷积神经网络的文本分类方法。郑国伟等[34]通过LSTM模型对金融领域的新闻数据进行分类。张腾等[35]结合卷积神经网络和双向门控循环神经网络对舆情事件评论的短文本进行情感分析。刘启元等[36]提出一种基于上下文增强LSTM的多模态情感分析模型。Yang等[37]结合社交媒体的上下文关系,设计一种基于改进LSTM的情感分析方法,分别对新浪微博和Twitter数据集进行实验。为更好地提取重点关注的文本数据,注意力机制被引入深度神经网络及自然语言处理任务中。杨鹏等[38]基于注意力机制的交互式神经网络模型提升情感分类的效果,结合上下文语义和方面词语义交互式建模。Wang等[39]结合LSTM模型和注意力机制实现情感分类研究。姚苗等[40]提出了自注意力机制的Att-BLSTMs模型并应用于文本分类研究,提高分类的准确率。
综上所述,在情感分类理论和应用中,基于情感词典、机器学习和深度学习的方法均取得一定的研究成果。BiLSTM模型可以提取上下文语义知识,CNN模型可以捕获具有代表性的局部特征,Attention机制能够突出词语的重要性,强化网络模型的学习和泛化能力。但这些模型在处理情感分类任务时往往会忽略情感特征词的强度,情感语义关系比较单薄,没有突出关键特征,从而影响分类精确度和效率。此外,上述方法未结合情感词典和深度学习两者优势,面对大规模情感分析或特定领域的情感分析时,效果不理想。为提升文本情感分类的性能和扩展性,从多个角度考虑情感分类的互补性及协调性,提出一种改进BiLSTM-CNN和注意力机制的情感分类模型。该分类模型通过融合情感词典优化特征词的权重,降低特征维度,利用卷积神经网络高效提取代表性的局部特征,引入双向长短时记忆网络捕获上下文语义特征,再结合注意力机制构建句子词向量,最终由Softmax分类器计算情感分类结果,从而完成细粒度的情感分类,并取得良好的准确率和鲁棒性。
2 改进情感分类模型
基于中外相关学者的研究成果和传统深度神经网络模型的缺点,构建基于情感词典和BiLSTM-CNN+Attention的情感分类模型。
2.1 算法总体框架
该模型共包括数据采集及预处理、改进情感分类模型和实验评估三个部分,其总体框架如图1所示,具体步骤如下。
步骤1首先通过Python和XPath构建自定义爬虫抓取大众点评网贵州景区数据集,利用Jieba工具进行中文分词及数据预处理,过滤掉无效特征词。
步骤2引入大连理工大学情感词汇本体库进行情感特征词提取,通过权重加成优化特征矩阵,包括基础词典调用、否定词构建、程度副词构建、语法规则构建等步骤。
步骤3经过情感词典改进的词向量会将文本中的每个词汇表征为相应的向量空间,并嵌入输入层;接着经过BiLSTM-CNN+Attention模型,其结构如图2所示。该卷积层由多个滤波器组成,池化层会高效提取代表性的局部特征,再利用BiLSTM层捕获上下文语义特征,其输出会通过Attention机制进一步突出所提取的关键性词语,并赋予相关权重,最终由Softmax分类器计算情感分类结果。
步骤4情感分类评估包括基于深度学习算法的性能评估、基于机器学习算法的性能评估和正负评论数据集性能对比。
2.2 数据预处理
在进行情感分类任务前,需要对语料进行数据预处理操作,主要包括以下内容。
(1)分词。抓取风景评论数据作为实验语料,中文分词采用Jieba工具完成,并导入自定义词典进行专有名词识别,如“黄果树瀑布”“西江千户苗寨”“镇远古镇”等。
(2)停用词过滤。通过Python导入哈尔滨工业大学停用词表、百度停用词表和四川大学停用词表进行数据清洗,过滤掉如“我们”“的”“这”等停用词以及标点符号。
(3)异常值处理。在中文文本中还会存在一些异常的特征词,此时需要进行适当的转换及人工标注,从而为后续的文本分类提供辅助。
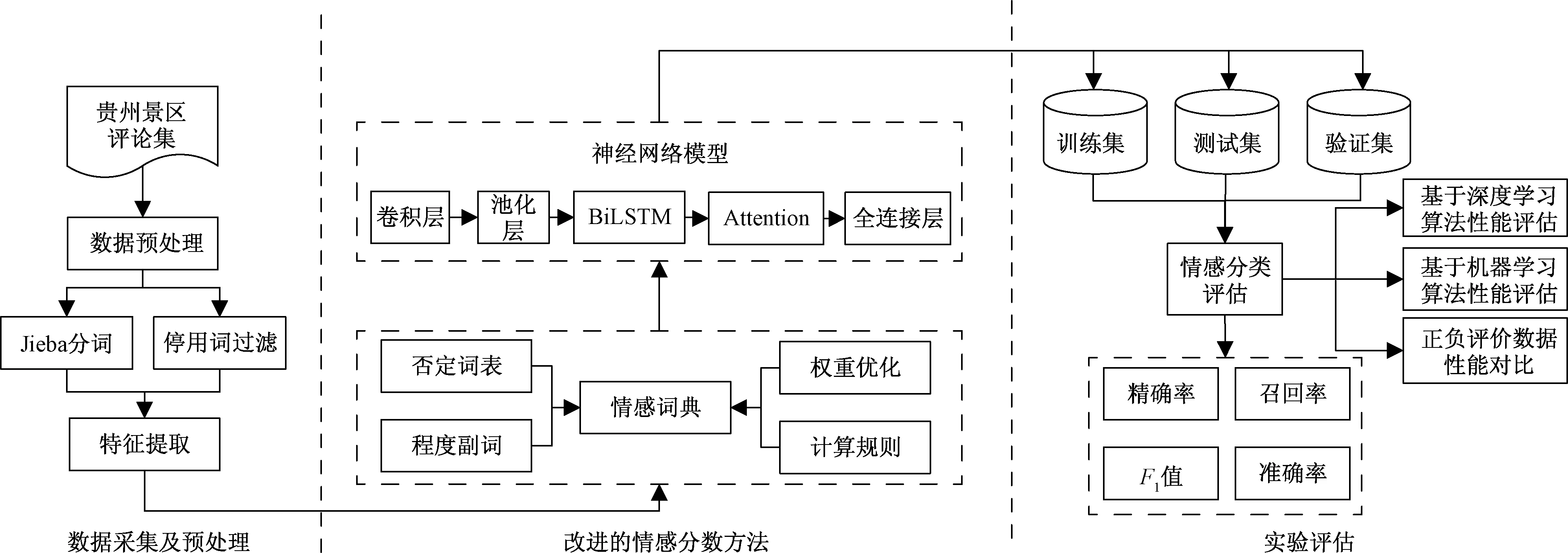
图1 改进BiLSTM-CNN和Attention的情感分类模型框架图Fig.1 The framework of an improved BilSTM-CNN and Attention sentiment classification model
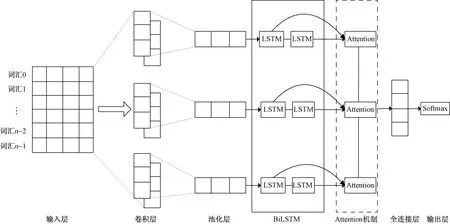
图2 BiLSTM-CNN+Attention模型结构Fig.2 The structure of BilSTM-CNN +Attention model
(4)分类标注。所抓取的评论数据共包括一星~五星评价,将四星和五星划分为好评,其余数据标注为差评。
经过上述处理,得到质量更高的文本语料,从而提升分类效果。最后将清洗后的数据及类标存储至CSV文件中,进行后续的情感分类实验。
2.3 情感词典改进
选择大连理工大学情感词汇本体库作为情感词典[4],该词典共涵盖27 466个特征词,将情感细粒度划分为“乐”“好”“怒”“哀”“惊”“惧”“恶”7大类和21小类,每个词汇均具有词性种类、情感类型、情感强度等多种属性,如表1所示。其中,情感强度包括5个等级,其分数分别为1、3、5、7、9;整个情感词的极性涉及中性、褒义、贬义3类,对应值为0、1、2。在该情感词典的基础上进一步改进,将非大连理工大学情感词汇本体库中的特征词权重设置为1,其余情感特征词对应的强度在原来的基础上加1。从而既保证情感特征词对分类模型的加成,又保证非情感特征词对分类模型的影响。最终特征词的情感强度计算公式为
s(w)=v(w)p(w)
(1)
式(1)中:v(w)为词汇的情感强度;p(w)为词汇的情感极性;s(w)为词汇的情感值。
接下来将情感词典改进后的特征词及权重转换为词向量形式,情感特征词所对应的词向量权重会有所加成,并通过词向量进一步表征词语之间的内在语义知识和关联信息,最终作为输入矩阵传入Attention和BiLSTM-CNN模型实现情感分类。
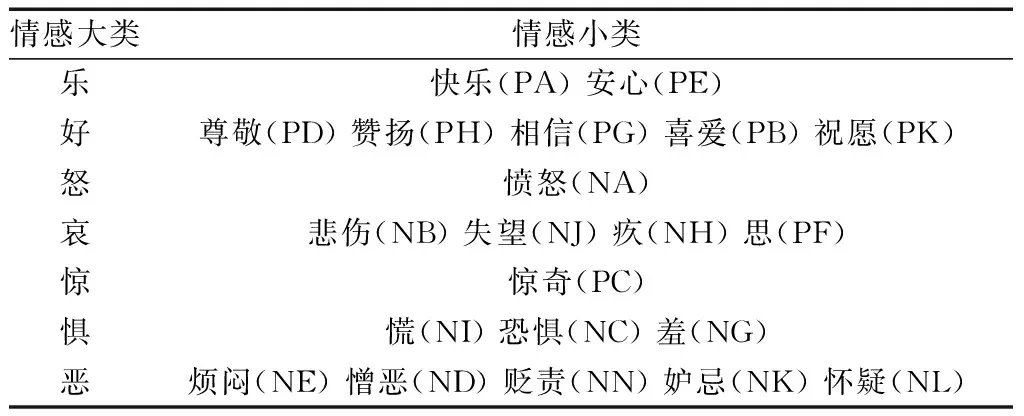
表1 情感分类关键词Table 1 Keywords of emotion classification
2.4 卷积神经网络模型
CNN利用卷积核滑动搜集句子信息来提取特征,再通过所提取的局部特征完成文本分类,通常包括输入层、卷积层、池化层和全连接层。

(2)
式(2)中:f为ReLU激活函数;wd为大小为d的卷积核;Vi为输入层的词向量;bd为偏置项。
通过设置卷积核对输入词向量Vi进行特征提取,滑动滤波器映射得到局部特征集合Hd,其计算公式为
(3)
池化层作用于卷积层的输出特征集合上,旨在降低数据维度,同时保持文本特征统计属性并增大模型的适应性。采用最大池化方法来提取特征,其计算公式为
si=max{Hd}
(4)
经过池化层提取出文本的局部重要特征,接着所有池化层得到的特征在全连接层进行组合,得到输出向量S为
S={s1,s2,…,sn}
(5)
最后将全连接层输出向量S输入Softmax分类器中进行评论文本的情感分类。同时,为防止出现过拟合现象,引入Dropout机制随机抽取数据进行训练。重点是融合CNN和BiLSTM模型。
2.5 双向长短时记忆网络模型
BiLSTM可以从正向和反向对句子进行编码,提取上下文语义特征。其网络结构会通过BiLSTM模型能够有效阻止梯度消失和梯度爆炸问题,从而更好地捕捉双向语义依赖。从正负两个向对情感特征词深度训练,进行细粒度的情感分类。
BiLSTM模型的计算公式为
(6)
(7)
(8)

通过构建BiLSTM-CNN模型,结合上下文语义知识来提取文本的局部特征,一方面解决局部特征丢失问题,另一方面有效保障对长距离依赖和前后属性关联的特征,为后续的文本情感分类提供支持。
2.6 双向长短时记忆网络模型
Attention机制能够有效增强神经网络模型对局部特征的关注,提高不同词语对于整个文本分类的贡献程度,并赋予不同的权重。在所研究的文本情感分类任务中,如果某个词语对句子语义的贡献较大,则赋予更大的权重,反之赋予更小的权重,通过这种方式有效地将单词级别的特征融合成句子级别的特征,提高关键词信息对情感分类效果的影响。注意力机制的处理过程如式(9)~式(11)所示。
ut=tanh(wcyt+bc)
(9)
at=sofmax(wT,ut)
(10)
(11)
式中:式(9)是通过tanh激活函数对yt进行非线性变换,最终得到属性表示向量ut;yt为BiLSTM结构输出的向量,yt=[y1,y2,…,yn];wc为训练的参数向量,bc为对应的偏置;式(10)采用softmax函数计算各个分量ut的权重,得到的at表示权重重要性;wT为转置矩阵;式(11)表示对yt重要性加权和的句子向量,用v表示。
最后,经过注意力机制得到向量表示v,将其输入到softmax分类器中得到最终分类结果,从而实现评论文本的情感分类任务。
3 仿真实验分析
为验证所提出算法的有效性和实用性,采用Keras深度学习框架设计神经网络模型,结合情感词典进行对比实验。实验环境为Windows10(64位)操作系统,处理器为Inter(R) Core i7-8700K,内存为32 GB,开发工具为Anaconda3,编程语言为Python3.6。
3.1 数据集和实验环境
实验数据选取在线评价平台“大众点评网”作为文本来源,通过Python自定义爬虫采集2010—2020年贵州省85个景点的情感评论信息,过滤掉无效及重复评论后共计32 000条,如“黄果树瀑布”“梵净山”“西江千户苗寨”等。数据集按照4∶2∶4的比例随机划分成训练集、验证集和测试集,具体数据分布情况如表2所示。

表2 数据集描述Table 2 Dataset description
数据预处理采用Jieba工具实现,通过导入停用词表和专有名词词典进行中文分词和数据清洗,并导入大连理工大学情感词汇本体库进行情感特征词提取和权重优化,从而提升情感分类效果。
3.2 评价指标
情感分类实验的评价指标采用精确率Precision、召回率Recall和F值Fmeasure衡量,其计算公式分别为
(12)
(13)
(14)
式中:TP为情感分类预测正确的数量;FP为将其他情感类别错误预测为该类别的数量;FN为该类别的情感文本被错误预测的数量。
精确率旨在评估算法预测正确的某个类别数量占预测到某个类别的总数量比值,召回率旨在评估算法预测正确的某个类别数量占该类别测试集中总数量的比值。为综合考虑算法的查准和查全效果,通常使用F值来评价分类算法的最终性能。
准确率Accuracy表示分类预测正确的数量占该类情感文本总数量的比值,可以直观地呈现分类效果的好坏,如式(15)所示,主要用它对比各深度学习模型随训练迭代次数的学习效果。
(15)
3.3 实验结果与分析
为保证实验结果更加真实有效,所有景区的评论数据集均进行随机划分,实验采用多次交叉验证,最终实验结果为10次情感分类结果的平均值,从而减小某次异常实验的影响。神经网络模型参数设定方面,最大特征词数设为10 000,文本序列长度设为600,CNN模型的卷积核数量设为128,批次为24,学习率为0.001。同时,BiLSTM模型的正反向神经元数均设置为256,优化算法选择Adam优化器,误差评价选择交叉熵损失函数,并且增加Dropout层防止出现过拟合现象,其参数设为0.3。
通过融合情感词典来改进BiLSTM-CNN和Attention情感分类算法,并与经典的深度学习分类模型进行对比实验,得出表3所示的实验结果。
由表3可知,所提出的方法在该数据集情感分类比较中,平均精确率、平均召回率和平均F值都有一定程度的提升。其中,本文方法的平均精确率为0.948 1,平均召回率为0.947 0,平均F值为0.947 5。相比于经典的BiLSTM-CNN+Attention模型,其平均精确率提高约0.008 1,平均召回率提升约0.011 1,平均F值提升约0.009 6,提升效果最高。同时,融合情感词典的TextCNN方法情感分类的F值从0.932 3提升到0.936 4;融合情感词典的BiLSTM方法情感分类的F值从0.923 0提升到0.924 9;融合情感词典的LSTM方法情感分类的F值从0.919 4提升到0.922 1;融合情感词典的CNN方法情感分类的F值从0.929 6提升到0.933 5。总体而言,通过情感词典权重加成,深度学习模型分类效果都有一定程度的提升,表3中的5种模型的精确率平均提升约0.004 2,召回率平均提升约0.004 7,F值平均提升约0.004 4。
同时,为进一步验证融合情感词典方法的有效性,本文方法还与传统的机器学习分类方法进行对比实验,得出的实验结果如表4所示。
其中,相比于未引入情感词典的逻辑回归方法,本文方法的平均精确率、召回率、F值分别提升2.39%、10.61%、6.69%;相比于未引入情感词典的朴素贝叶斯方法,本文方法的平均精确率、召回率、F值分别提升4.25%、15.73%、10.38%;相比于未引入情感词典的SVM方法,本文方法的平均精确率、召回率、F值分别提升4.89%、6.12%、5.51%;相比于未引入情感词典的随机森林方法,本文方法的平均精确率、召回率、F值分别提升2.39%、10.61%、6.69%。该实验结果一方面证明基于情感词典改进的BiLSTM-CNN和Attention方法在旅游景区评论分类效果上更优,另一方面也验证引入情感词典的机器学习方法的性能更好,体现情感词典权重加成及深度学习模型所带来的优势。
为更形象地体现经过情感词典改进的BiLSTM-CNN+Attention模型的良好性能,通过训练数据和验证数据进一步探究其学习过程,得出如图3和图4所示的变化曲线。图3展现各个深度学习模型随着迭代次数增加,其验证集准确率(Val_Accuracy)随训练周期(Epoch)变化的曲线。图4展现各个深度学习模型的误差随训练周期变化的曲线。

表3 基于深度学习的情感分类算法性能评估Table 3 Performance evaluation of sentiment classification algorithm based on deep learning
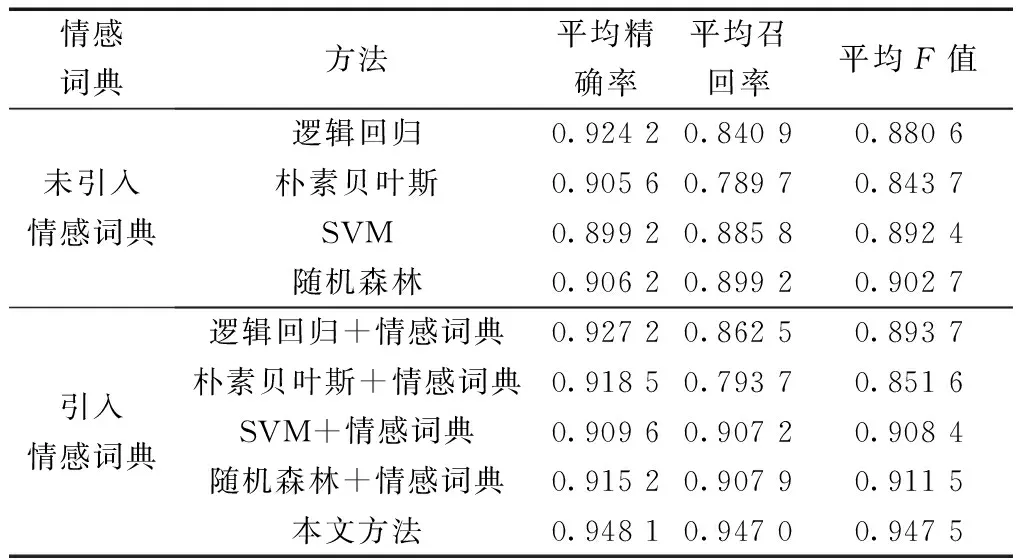
表4 基于机器学习的情感分类算法性能评估Table 4 Performance evaluation of sentiment classification algorithm based on machine learning
由图3可知,与其他各模型相比,基于情感词典的BiLSTM-CNN+Attention模型训练过程更稳定,收敛速度更快,整个曲线趋于平缓,情感分类准确率最终稳定在0.960的位置,并且优于CNN、LSTM、BiLSTM和TextCNN模型。由图4可知,基于情感词典的BiLSTM-CNN+Attention模型的误差(Loss)随训练周期收敛速度更快,并且迅速平缓地下降至0.124 5位置,整个模型取得较好收敛效果。
不仅与经典的深度学习模型、传统的机器学习模型进行综合性对比实验,还分别对景区正面评论和负面评论进行评估,其中图5展示各个模型正面评论的实验结果,图6展示各个模型负面评论的实验结果。
从图5展示的实验结果来看,本文方法在测试集上的精确率、召回率和F值分别为0.978 1、0.977 8和0.977 9,它们均高于其他分类模型。其中,本文方法正面评论的F值比TextCNN方法提高0.70个百分点,比BiLSTM方法提高1.27个百分点,比LSTM方法提高1.33个百分点,比CNN方法提高0.88个百分点,比机器学习中表现较好的随机森林方法提高2.63个百分点,这进一步反映情感词典对算法模型的优化。
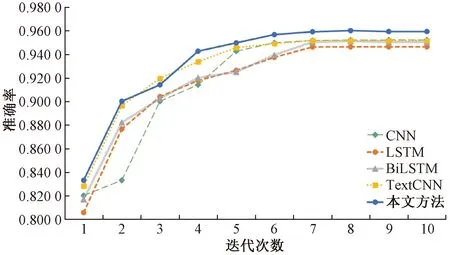
图3 各模型实验准确率的变化曲线Fig.3 The Change curves of accuracy of each model

图4 各模型实验误差的变化曲线Fig.4 The Change curves of loss of each model
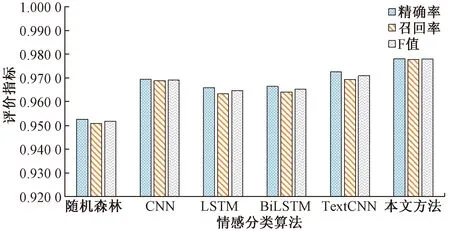
图5 正面评论数据集性能对比Fig.5 Performance comparison of positive reviews dataset

图6 负面评论数据集性能对比Fig.6 Performance comparison of negative reviews dataset
图6展示负面评论数据集的实验结果,由于负面评论数据集相对正面评论更少,并且评论的消极特征词更复杂,所以其精确率、召回率、F值整体均低于正面评论。其中,本文方法在负面评论数据集中的精确率、召回率和F值最高,分别为0.918 1、0.916 1和0.917 1。相较于TextCNN、BiLSTM、LSTM、CNN和随机森林模型,本文方法的F值分别提高2.35%、3.63%、4.36%、2.72%和6.35%。
总之,通过引入大连理工大学情感词汇本体库对贵州景区评论数据进行情感词提取,这些情感特征词一定程度上影响深度学习模型的训练效果,通过加强情感特征词与分类结果的映射关系,进一步提升算法的性能。本文提出的情感分类模型能够有效反映出用户对景区服务及体验的感受,进一步挖掘用户的整体情绪,从而促进管理者做出更好的服务决策。
4 结论
针对深度神经网络在处理情感分类任务时会忽略情感特征词的强度,情感语义关系单薄,影响分类精度的问题,提出一种改进BiLSTM-CNN和注意力机制的情感分类模型,旨在开展细粒度情感分类研究。该分类模型通过融合情感词典优化特征词的权重,利用CNN模型高效提取代表性的局部特征,引入BiLSTM模型捕获上下文语义特征,再结合注意力机制构建句子词向量,最终由Softmax分类器计算情感分类结果。
为验证模型性能,在贵州景区评论数据集上进行实验。实验结果表明,改进BiLSTM-CNN和Attention的情感分类方法在精确率、召回率和F值上均有所提升,提出的模型能够充分加成情感特征词的权重,利用上下文语义特征,提高情感分类性能。本文方法可以应用于文本分类、推荐系统、数据挖掘、自然语言处理等领域,具有良好的准确率和实用性。
未来,一方面将扩大实验数据集,研究该算法的普适性;另一方面将结合深度语义知识,进一步提升模型对情感分类性能的影响。
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
开放教育研究(2020年2期)2020-03-31
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
