
基于改进YOLOv5s的烟支外观缺陷检测方法
2022-08-23 07:16刘鸿瑜袁国武
计算机技术与发展 2022年8期
刘鸿瑜,袁国武
(云南大学 信息学院,云南 昆明 650504)
0 引 言
中国烟草产业产量一直位居世界第一,2020年,中国烟草行业利税总额达到了1.28万亿,上缴财政总额达到了1.2万亿,可以说,烟草是中国的支柱产业之一。而云南烟草占据全国烟草总量的一半左右,烟草产业对于云南的发展起着至关重要的作用。卷烟是烟草公司生产的最主要产品,在卷烟自动化生产过程中,难免会产生一些烟支外观缺陷。在以前的生产流水线上,仅靠人工去分辨缺陷。而目前的自动生产流水线上烟支的生产速度达到了200支/秒,靠人工去分辨缺陷已经不太现实,因此,迫切需要自动化的烟支外观检测和分类技术。
外观缺陷检测有传统的图像处理检测和机器学习检测两大类,近年来快速发展的深度学习方法是机器学习中的一类。在深度学习中,外观缺陷检测属于目标检测的范畴,目标检测算法主要有R-CNN[1-3]、SSD[4]、YOLO[5-8]等,这些方法在很多目标检测领域都有着广泛的应用,取得了大量科研成果。Wang W等[9]将数据增强技术应用于Faster R-CNN网络,在道路表面损坏图像检测中精准率和召回率的调和平均值达到了62.55%。吴则举等[10]在Faster R-CNN里面引入在线难例挖掘(OHEM)算法,在轮胎外观缺陷检测中的准确率达到了95.7%。Li Y等[11]在SSD的基础上提出了一种基于MobileNet-SSD的表面缺陷检测方法,用来检测罐装密封容器表面缺陷,召回率达到了89.42%。Tian Y等[12]将YOLOv3网络和Dense-Net网络有效地结合起来,应用于果实外观形状检测,以此来监测作物生长和营养状况,实验的精准率和召回率的调和平均值达到了81.7%。张广世等[13]在YOLOv3网络中增加了网络预测尺度的种数,提高了对于小尺寸缺陷的检测能力,在齿轮外观缺陷检测中召回率达到了95.63%。何国忠等[14]将注意力机制加入到YOLOv4网络,用来对电路板外观缺陷进行检测,平均检测精度达到了91.40%。
目前,还没有看到深度学习方法用于烟支外观缺陷检测和分类方面的研究。在自动化高速烟支生产流水线上,由于对高检测精度和高分类精确率的需求,基于最新提出的YOLOv5s网络,该文提出以下改进用来更好地对烟支外观缺陷进行检测和分类:
(1)对于烟支外观缺陷数据集,除了应用YOLOv5s的数据增强(Mosaic)方法,还采用了随机中心旋转(Rand Center Rotation)、合成新样本[15](SMOTE)和高斯噪声(Gaussian Noise)的数据增强技术,使数据从原始的2 000张图片有效扩增到8 000张;
(2)在YOLOv5s网络的骨干网络层(Backbone)引入通道注意力机制(SE-Net),提升了特征图不同通道之间目标信息的相关性表述;
(3)优化激活函数,用Swish[16]函数替代Leaky ReLU。Swish函数具有平滑、非单调的特性,这有利于提升网络的分类能力;
(4)优化损失函数,将原网络的GIoU[17]改用DIoU[18],DIoU弥补了GIoU的模型收敛速度问题,而相较于将真实框和预测框的形状不一致考虑进来的CIoU[18],DIoU更关注预测框和真实框中心点的位置,这能够更好地对小目标进行检测,更适合于文中烟支外观缺陷数据集。
1 烟支外观缺陷概述
烟支主要分两个部分:如图1(a),左部白色部分为烟棒,右部深色部分为滤嘴。在烟支生产工艺上,根据生产流水线的外观缺陷形成原因,云南中烟工业有限责任公司将烟支外观缺陷分为以下四类:斑点(Dotted)、褶皱(Folds)、错牙(unTooth)、无滤嘴(unFilter)。其中,斑点指在烟支外表上有大小不一的黑点、污点等,主要由烟棒纸印刷不合格或者后期受到染色形成;褶皱主要指烟支上有一些皱纹样的形状,主要由生产机器用滤嘴纸卷过滤嘴或用烟棒纸卷烟丝造成;错牙指烟支的包装纸在卷烟丝的过程中没有对齐,主要由生产机器造成;无滤嘴主要由生产机器出现问题无法包装过滤纸造成。具体烟支外观缺陷图像见图1(b)-(e)。

图1 烟支外观类型
2 YOLOv5s网络模型介绍
YOLOv5系列包括YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种模型[19],其中YOLOv5s体积最小,速度最快,最适合应用到自动化烟支外观缺陷检测中。YOLOv5s网络大致可以分为四个模块:Input、Backbone、Neck、Head。
2.1 Input
(1)Mosaic数据增强。把四张图片通过随机缩放、随机裁剪、随机排布的方式拼接成一张图片。
(2)自适应图片缩放。即对原始图像自适应地添加最少的黑边,这样可以提升推理速度。
2.2 Backbone
(1)Focus。原始608*608*3的图像输入之后,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,变成304*304*32的特征图,保证了在下采样的同时不丢失图像信息,同时减少了每秒浮点运算次数,加快了计算速度。
(2)CSPNet[20]。CSPNet从图像中提取丰富的信息特征,将梯度变化集成到特征图,解决了网络优化中梯度信息重复的问题,大幅减少了计算量,提升了精确率。
(3)Leaky ReLU激活函数。该函数在训练过程中使所有神经元都被激活,从而使所有的参数进行更新,提升了网络的表达能力。
2.3 Neck
采用了FPN+PAN[21-22]结构,深层的特征图携带有更强的语义特征,浅层的特征图携带有较强的位置信息。FPN就是把深层的语义特征传到浅层,而PAN则是把浅层的定位信息传导到深层,两者相结合,增强了网络特征融合能力。
2.4 Head
采用GIoU_Loss做Bounding box的损失函数,GIoU不仅关注重叠区域,还关注其他的非重叠区域,反应预测框与真实框之间的重合度。
3 改进的YOLOv5s网络模型用于烟支外观缺陷检测
3.1 数据增强
从云南中烟工业有限责任公司获取的总烟支外观数据集有2 854张图片,经筛选和灰度处理,仅有2 000张有效图片。对原图像进行适当的数据增强,扩增后得到的图片数量为8 000张。
(1)随机中心旋转。将原始图像随机选取一半的图片按照中心点不变的原则,随机旋转一个角度。图像中心点坐标的公式为:

(1)
其中,图像的左上角坐标为(left,top),右下角坐标为(right,bottom),图像中心点为(xcenter,ycenter)。图像上任意一点绕中心逆时针旋转任意角度后,新的坐标位置的计算公式为:
(2)
其中,(X0,Y0)为图像上某一点旋转前的坐标,θ为旋转的角度,(X1,Y1)为图像上某一点旋转后的坐标。
(2)合成新样本。在烟支外观数据集中,有一些样本较之其他样本较少,样本数据极不平衡,影响分类器效果。因此采取SMOTE[21]方法来平衡样本数量。SMOTE是基于插值的方法,能为小样本类合成新样本,步骤为:(a)将每个样本对应到特征空间,根据样本不平衡比例确定好一个采样倍率N,这样可以确定采样的趟数。(b)对每一个小样本(x,y),根据欧氏距离找出K个最邻近样本,从中随机选取样本点(Xn,Yn)。在特征空间中样本点与最邻近样本点的连线段上随机选取一点满足式(3),得到新样本点(Xnew,Ynew)。(c)重复以上步骤,直到大、小样本数量平衡。
(Xnew,Ynew)=(x,y)+rand(0,1)×
((Xn-x),(Yn-y))
(3)
(3)高斯噪声。对原始图像和进行过上述数据增强的图像,随机选取部分图片复制一份来加高斯噪声。高斯噪声对图像的每一个像素都有一个符合同一高斯分布的加性噪声,具体加性高斯公式如式(4)。
G(x,y)=f(x,y)+n(x,y)
(4)
其中,G(x,y)是被添加高斯噪声后的图像,f(x,y)是原图像,n(x,y)是高斯加性噪声。
3.2 通道注意力机制
Hu J等[23]最早提出通道注意力机制,根据重要程度给各个通道分配不同的权重。为了进一步提高网络的表达能力,也为了更好地获取烟支外观缺陷特征,在网络的CSP模块嵌入SE-Net[24],研究特征图的各个通道之间的相关性,增强对通道信息的敏感程度。SE-Net结构主要包含全局平均池化层、全连接层、激活函数层,结构见图2。

图2 SE-Net网络结构
首先,对输入大小为w*h*n的特征图进行全局平均池化操作,得到1*1*n大小的特征图;其次,在全连接层对1*1*n大小的特征图做非线性变换得到权重;scale层则将权重分别乘到输入特征图的对应通道特征上再输出,得到包含通道注意力的特征图。该文将SE-Net加在Backbone模块的三个CSP结构后面,从而保证不同特征经过SE-Layer层之后让更重要的特征能够有更高的权重,使模型有更好的检测和特征提取能力。
3.3 Swish激活函数
Swish激活函数的提出,使得在一些环境下ReLU函数被替换成为了可能。通过实验,验证了Swish函数在文中数据集上面的有效性。原始YOLOv5s网络中采用的是Leaky ReLU函数,该文用Swish函数进行改进。一方面,由于采用的模型较深,Swish函数非常适合于深层次网络,且其具有的无上界有下界、平滑、非单调的特性,在文中模型性能提升中发挥了重要作用。另一方面,烟支外观缺陷数据集有很多不规则的缺陷,使用Swish函数,能够更好地对这些不规则的缺陷特征进行类别区分。
Swish函数的公式如下:
(5)
3.4 DIoU损失函数
损失函数的选择对模型收敛效果有着很大的影响,在改进的YOLOv5s模型中采用DIoU作为损失函数。DIoU将目标框与预测框中心点之间的距离、重叠率以及尺度都考虑进去,使得目标框的回归变得更加稳定。在实验中,相比于GIoU和CIoU,DIoU更关注预测框和真实框中心点的位置,更适合于烟支外观缺陷数据集。DIoU函数见式(6):
(6)
其中,b、bgt分别代表预测框和真实框的中心点,ρ代表两个中心点之间的欧氏距离,c代表能够同时包含预测框和真实框的最小闭包区域的对角线距离,IoU函数的计算公式如下:
(7)
其中,Bgt代表真实框,B代表预测框。
3.5 改进后的YOLOv5s网络结构
改进的YOLOv5s算法将目标检测任务重新定义为一个单一的回归预测问题。首先对输入图像进行自适应缩放和数据增强,使图像标准化,丰富数据集。然后采用Focus对图像进行切片,经过CSP Darknet53和SE-Net来提取图像多尺度的特征进行学习和对不同特征相应地赋值权重,再经SPP池化模块对图像进行特征分离,用FPN+PAN结构从不同的主干层对不同的检测层进行特征融合。最后通过处理网络预测结果并对图像特征进行预测,生成目标边界框和预测类别概率。
该文用于烟支外观缺陷检测的YOLOv5s网络结构见图3。在Input端,首先进行数据增强,有效扩增烟支数据集,使各种缺陷数据集间达到平衡;然后在Backbone模块添加注意力机制,使得烟支外观图像中重要的特征有了更高的权重;然后用Swish函数替换Leaky-ReLU,增强了网络对某一缺陷类别中特殊形状缺陷的烟支的识别分类能力;再使用DIoU作为损失函数,让网络更加关注烟支外观缺陷这种占比很小的缺陷,从而能够更好地对模型进行优化,使实验效果提升。
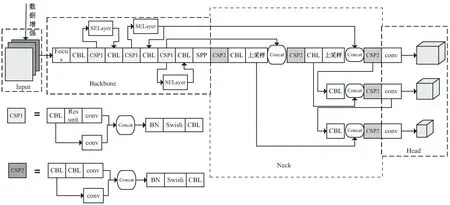
图3 用于烟支外观缺陷检测的YOLOv5s网络结构
4 实验结果及分析
4.1 实验数据集
烟支外观缺陷数据集已在第2部分中做了相关介绍,在实验部分,对正常、斑点、褶皱、错牙、无滤嘴五种类别的烟支外观数据集使用labelImg工具进行了标注,生成对应的xml文件。
标注示例见图4。

图4 烟支标注示例图
将增扩得到的数据集按6∶2∶2的比例划分为训练集、测试集、验证集,采取按类别随机划分的方式。最终,训练集五种类别各960张,共4 800张,验证集、测试集五种类别各320张,共3 200张。
4.2 实验环境
实验采用PyTorch框架,在Windows 10上运行。实验电脑配置如下:CPU为 Intel Core i7-10700k,GPU为RTX 2080Ti,内存为32G。
4.3 评价指标
实验评价指标采用Precision(精确率)、Recall(召回率)、mAP(平均检测精度)和mSpeed(平均检测时间),Precision(P)和Recall(R)的计算公式为:
(8)
(9)
其中,TP为预测为某一类别实际也为这一类别的数量,FN为预测不为某一类别实际为这一类别的数量,FP为预测为某一类别实际却不为这一类别的数量。
由P值和R值可以得到一条精确率-召回率(P-R)曲线,曲线与坐标轴围成的面积即AP值,计算公式为:

(10)
mAP即将所有类别的AP值求平均,计算公式为:
(11)
其中,n是类别数,APi是第i类类别的AP值。平均检测时间mSpeed是检测出所有图片所需的时间的平均,包括图像预处理、PyTorch FP16推理、后处理和非极大值抑制(NMS)处理时间。
4.4 实验结果及分析
首先对网络进行参数的初始化,用训练集和验证集来对网络进行训练,期间通过对学习率、权重大小及训练轮次等参数进行相应的调整,使实验效果达到最好。最终的参数设置如下:批处理大小(batch size)设置为32,学习率(lr)设为0.01,训练次数(epoch)设置为200。实验训练结果见图5。
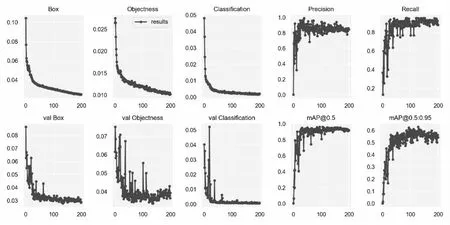
图5 实验训练结果
图5中,Box指DIoU损失函数均值,Objectness指目标检测loss均值,Classification指分类loss均值,这三个值越小表示效果越好。训练过程这三个值几乎接近0,且在测试过程中这三个值也很低且收敛。另外,Precision值和Recall值稳定在0.9左右。而mAP@0.5指IoU为0.5时所有类别的平均AP。mAP@0.5:0.95指在不同IoU(0.5-0.95,步长0.05)上所有类别的平均AP。最后,mAP@0.5稳定在0.9左右,mAP@0.5:0.95稳定在0.6左右,上述所有指标表明模型效果较好。
改进的YOLOv5s网络在训练过程中,随着epoch数的增加,与其他方法相比,能够更快地收敛,且收敛之后损失函数值最小,验证了改进模型损失函数的有效性,也说明了改进的YOLOv5s网络训练效果优于其他网络。改进的YOLOv5s与Faster R-CNN、SSD及yolov5s的训练次数-损失函数值(E-L)对比见图6。

图6 不同模型训练过程损失函数曲线
图7展示了改进YOLOv5模型可视化的部分结果。

图7 改进的YOLOv5s网络实验结果
为了进一步验证模型的有效性,与其他一些常用的目标检测网络进行实验对比,实验结果见表1。
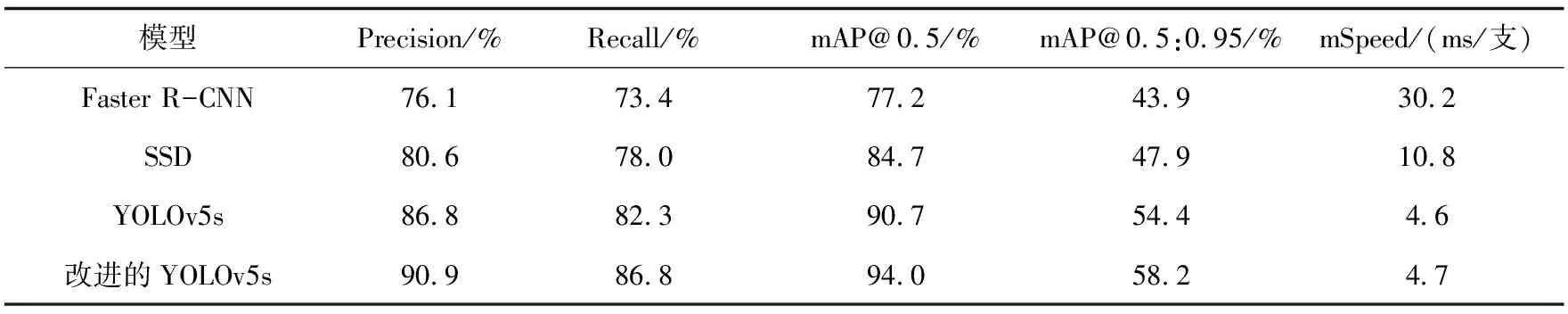
表1 不同网络实验结果对比
表1数据表明,改进的YOLOv5s相比于原先的YOLOv5s,精确率高出了4.1%,召回率高出了4.5%,平均检测精度(mAP@0.5)高出了3.3%,平均检测精度(mAP@0.5:0.95)高出了3.8%,而平均检测速度只增加了0.1 ms/支。应该指出,改进的YOLOv5s网络取得了较大的提升。另一方面,采用的YOLOv5s方法是YOLOv5系列中最轻量的,经改进后,检测精度已与最好的YOLOv5x相差不大,而且由于YOLOv5s架构检测时间非常快,能更好满足未来工业上生产上200支/秒的检测要求,在实际的烟支生产应用场景中,也能更加适合于自动化烟支外观缺陷检测。
图8为不同算法的检测结果,其中,(a)表示原数据,(b)表示标注的数据,(c)-(f)表示采用Faster R-CNN、SSD、YOLOv5s和改进的YOLOv5s方法的结果。可见,该算法在烟支外观数据集上的检测置信度高,漏检少,分类效果好,在不同缺陷下的表现比较稳定,达到了预期。

(a)原数据 (b)标注数据 (c)Faster R-CNN (d)SSD (e)YOLOv5s (f)改进的YOLOv5s
5 结束语
针对烟支自动化生产过程中生产速度快、要求检测精度和分类精确率高等现状,提出了一种改进YOLOv5s的网络模型,将其用于烟支外观缺陷检测与分类。主要创新点在于:在YOLOv5s框架的数据增强模块基础上增加了多种更适合文中数据集的数据增强方法;在YOLOv5s骨干网络引入了通道注意力机制;优化激活函数改用Swish函数;优化损失函数改用DIoU。实验证明,该改进模型在5种常见的烟支外观类型数据集上,精确率、召回率及平均检测精度均有所提升,平均检测速度也能够满足目前烟支生产流水线的检测要求。
猜你喜欢
学苑创造·A版(2022年4期)2022-06-18
阅读(快乐英语高年级)(2022年6期)2022-06-17
西部交通科技(2022年2期)2022-04-27
小学生学习指导·低年级(2022年2期)2022-02-16
初中生世界·九年级(2018年12期)2018-12-22
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
读者(2015年9期)2015-05-04
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
