
基于注意力双线性池化的细粒度舰船识别
2022-08-23 07:16姜孟超范灵毓李硕豪
计算机技术与发展 2022年8期
姜孟超,范灵毓,李硕豪
(1.军事科学院 战略评估咨询中心,北京 100091;2.96962部队,北京 102206;3.国防科技大学 信息系统工程重点实验室,湖南 长沙 410073)
0 引 言
细粒度图像识别的目的是识别同一大类别下的不同子类,相对于普通的图像识别它的特点在于:细粒度图像识别的粒度更为精细,比如细粒度图像识别往往是对一些不同种类的鸟或者对不同种类的汽车等进行识别,需要精确地识别出它是哪种鸟或者哪款车等。而普通的图像识别一般是在不同物种之间进行识别,例如仅仅识别出猫和狗,而不需要识别出到底是什么种类的猫和狗。
研究细粒度的主流方法主要是基于强监督学习的识别方法、基于弱监督的识别方法和基于无监督的识别方法。强监督学习的方法[1-3]需要对图像进行类似bounding box或者part annotations的标注,该方法需要进行大量的人工标注,标注成本较高;无监督学习的方法[4]虽然不需要任何人工标注,减少了高标注成本的弊端,但是因为没有任何作为指导机器学习的标签信息,导致识别的准确率往往不高。基于弱监督学习的方法[5-7]解决了以上两种监督方法的不足,它只需要每个图像有一个对应的标签就可以进行学习,不需要花费大量的标注成本,同时也能达到较好的识别精度。
细粒度图像识别的关键在于学习到图像的判别性特征,当前研究细粒度图像识别的方法大多是基于弱监督的局部定位、裁剪图像区域和多级训练的方法[8-10]。这些方法虽然也可以达到很好的识别率,但是存在局部定位不准确及经常裁剪到一些背景区域,由此给训练模型带来多余背景噪声的问题,而且多级训练的方法往往有复杂的网络结构,使得模型的参数比较大、时间复杂度比较高。
针对以上情况,该文提出使用一种双线性约束的通道和空间注意力方法直接引导模型学习到图像的判别性特征,从而提高模型的识别率。
主要贡献如下:
首先,在仅有类别标签的弱监督环境下,利用带有通道和空间注意力的两个网络分支充分挖掘图像的通道特征和空间特征,使得网络捕获更多的可区分性局部特征;同时再利用一个不含注意力机制的主分支去捕获图像的全局特征,以增强网络的表征能力。
然后,对学习到的通道注意力特征和空间注意力特征进一步利用双线性池化操作,促使通道注意力特征和空间注意力特征进行特征融合,提高不同特征之间的相互依赖性,从而学习到图像更丰富的局部判别性特征。
最后,提供了一个自然场景下的细粒度舰船图像数据集,共有2 360张图像,包含七个种类,该方法在此数据集上取得了较好的识别效果。
1 相关工作
1.1 细粒度图像识别
目前有很多关于细粒度图像识别的网络模型,一类是典型的基于图像判别性区域定位的方法,Mask-CNN[3]不仅使用全连接网络(FCN)在细粒度图像中定位目标和判别性部分,而且还将预测的分割视为目标和部分的掩模。Peng等人提出代表性的模型OPAM[11]通过生成Object和Part级别的特征进行细粒度图像识别。Yang等人提出了自我监督导航网络(NTS-net)[12],在不使用人工部件标注的弱监督环境下,利用导航模块引导网络定位到图像的判别性区域,通过一种反馈和审查的方法学习到图像的显著部位特征来进行细粒度图像识别。
另一类是直接抽取图像判别性特征的方法,Wang等人通过1×1的卷积核[13]作为小的“patch检测算子”设计一个非对称的、多支路的网络结构学习有区别的mid_level patches,避免了识别和定位之间的权衡。Zheng等人提出一种新颖的三线性注意力采样网络(TASN)[14],以从数百个用于细粒度图像识别的parts提案中用teacher-student的方式学习微妙的判别性特征表示。
1.2 视觉注意力机制
视觉注意力机制是模拟了人类在观察事物的时候总是首先关注最显著的特征这一特点,DT-RAM[15]提出了一种循环视觉注意力机制的动态计算时间模型,该模型可以在动态步骤中挖掘最显著的特征。Zhao等人提出多样化的视觉注意力网络(DVAN),以明确追求关注特征的多样性,更好地学习图像的判别性特征。Fu等人提出了一种循环的注意力卷积神经网络RA-CNN来反复学习多个尺度上的注意力特征。MA-CNN进一步通过设计通道分组模块,在单个尺度上生成多个一致性注意特征图。但是这种注意力分组模块是通过人为设计出来的,可能不适应实际情况,缺少灵活性。以上提到的注意力方法大多只是在图像通道层面做注意力,提取图像的通道特征,却忽略了对于细粒度图像识别同样重要的空间特征。而该文提出的方法可以同时在图像通道和空间层面提取图像的细粒度判别特征,弥补了现有方法的不足。
2 注意力双线性池化网络模型
细粒度图像识别最大的挑战在于图像类间差异小,类内差异大,具体表现在同一类别的物体从不同角度拍摄下来呈现出不同的姿态,因此让网络充分学习到不同类别的判别性特征是细粒度图像识别的关键。如图1所示,设计了一种注意力双线性池化的方法,通过两个通道和空间注意力分支分别学习图像通道层面的特征和空间层面的特征,用以充分挖掘到图像的局部特征,同时抽取了卷积神经网络的最后一层作为主分支,用于捕获图像的全局特征。为了使学习到的通道特征和空间特征得到交互并更好地关联起来,利用双线性池化操作对通道特征和空间特征再进行特征融合。最后将融合后的局部特征和全局特征concat起来,再经过一个全连接层输出去做最后的预测。

图1 注意力双线性池化网络模型
2.1 通道注意力机制
对于每个特征图C*H*W来说,通道注意力机制是在每个通道(channel)维度C上学习到不同的注意力权重,但是在平面维度H*W上的权重不变,通道注意力关注的是“是什么”的问题,它侧重于关注的是图像的不同特征。利用Hu等人提出的Squeeze-and-Excitation Networks(SENet)[16]作为通道注意力分支,如图2所示,主要包含Squeeze和Excitation两部分。
Ftr是一个C*H*W的特征图,经过全局平均池化(global average pooling),将C*H*W的输入转化成1*1*C的通道统计,如下式:
接下来进行Excitation操作,将前面Squeeze操作得到的Zc经过一个全连接层,即W1乘以z,然后再经过一个ReLU层δ和全连接层,最后再经过激活函数σ得到通道注意力权值s。
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
在得到通道注意力权重之后,就可以对原来的特征Uc图进行channel-wise multiplitation,对应于下面的公式中的Fscale。

图2 SENet网络模块
2.2 空间注意力机制
空间注意力机制对于每个特征图C*H*W来说,空间域注意力是在每个通道W上拥有相同的权重,而在平面维度H*W上学习不同的注意力权重,空间注意力主要关注的是物体“在哪里”,注重学习图像的不同的区域。该文利用CBAM[17]模型中的空间注意力模块独立成一个分支,用来重点提取图像的空间特征。如图3所示,将上一层输出的特征图Feature Map作为空间注意力模块的输入,首先沿着通道层面做一个Global Max Pooling和Global Average Pooling,接着再沿着通道进行concat拼接操作。然后经过一个卷积操作,降维为1个通道,之后再经过Sigmoid函数生成空间注意力特征Ms(F),7*7表示卷积核的大小。最后将空间注意力特征权重和该模块输入的原特征图做乘法,得到最终生成的空间注意力特征图。
Ms(F)=σ(f([AvgPool(F);MaxPool(F)]))=

图3 空间注意力模块
2.3 双线性池化
Lin等人提出一种双线性模型Bilinear CNN Models[18],已经被证实在细粒度图像识别上具有良好的识别效果。如图4所示,它由两个CNN特征提取器组成,这两个特征提取器经过卷积和池化后对提取的特征做矩阵外积(matrix outer product),输出的是融合后的特征。这种双线性池化的方法可以用图像平移不变的方式,对图像局部判别性特征进行交互,用以捕捉图像成对的特征关系,进而提升模型的分类性能。

图4 Bilinear CNN网络模型
双线性池化模型由如下一个四元组构成:
B=(fA,fB,P,C)
其中,fA和fB是来自两个不同网络的特征函数,P是一个池化操作,C是一个分类函数。在位置l处进行双线性池化的公式如下:
(l,I,fA,fB)=fA(l,I)ΤfB(l,I)
将通道注意力分支和空间注意力分支输出的注意力特征分别当作图4中双线性池化操作的两个输入特征,并对双线性池化后的特征和主分支学习到的全局特征进行concat拼接,经过一个全连接层和交叉熵损失函数预测识别的结果。为了使双线性池化过程交互到期望类别的判别性特征,对双线性池化单独使用交叉熵损失函数以进行约束。
3 实 验
3.1 实验环境和数据
实验是在一个Intel Core I7-6800K CPU、32 GB内存和Nvidia Geforce 1080Ti的GPU的Ubuntu16.04电脑上进行的,使用基于Imagenet预训练的ResNet 50作为预训练特征。首先把图像统一缩放为448*448大小的输入模型,批量大小设置为16,使用Pytorch1.6,采用随机梯度下降的优化方法SGD对模型进行优化,随机梯度下降的动量设置为0.9,以10-5作为权重衰减值,初始学习率设置10-3。
实验中用的数据集是对互联网公开的舰船图片进行搜集和标注得到的,总共搜集到2 360张图片,每个类别大约330张。包含7种不同类别的舰船,部分示例如图5所示。这些舰船同一类别下拥有不同角度拍摄下的照片,而不同类别之间的相似度很高,同时也存在不同环境的背景,符合细粒度图像识别的特点。

图5 舰船数据集示例
3.2 实验过程
实验开始之前,从网上搜集了大量的舰船图片,并进行了筛选,去掉一些模糊和水印的图像,然后按照舰船的种类进行了整理。首先搭建了图1所示的基于ResNet 50的注意力双线性池化的网络结构,输入一张图片首先加载到RseNet 50的网络模型进行初步的判别性特征提取。然后将提取的特征分成三个分支,两个低层分支分别利用通道注意力机制和空间注意机制提取图像的局部判别性特征,另一个高层分支则用来提取图像的全局特征。接着将提取的局部判别性特征利用双线性池化进行特征融合,最后再将融合后的局部特征和全局特征拼接在一起,经过一个全连接层做最后的分类预测。实验中经过200次的迭代训练,网络模型收敛到平稳状态。
3.3 实验结果分析和可视化
使用模型在舰船数据集上进行细粒度识别的准确率可以达到91.3%。同时也与其他主流的细粒度图像识别方法在文中数据集上进行了对比,如表1所示。文中方法比基准模型ResNet 50在准确率上提高了10%;比传统的基于人工标注的方法分别提高了5.9%和4.5%,具体来说,基于人工标注的方法可能会存在人工标注不准确的情况,造成网络学到错误的标签或者特征区域,而文中研究的弱监督方法则有效解决了这个问题,故比传统的人工标注方法好。另外与传统的双线性池化的Bilinear CNN方法、基于注意力机制的RA-CNN方法和分层双线性池化的HBP方法进行了比较,实验结果显示文中方法在准确率上分别提高了4.6%、3.0%和1.2%。
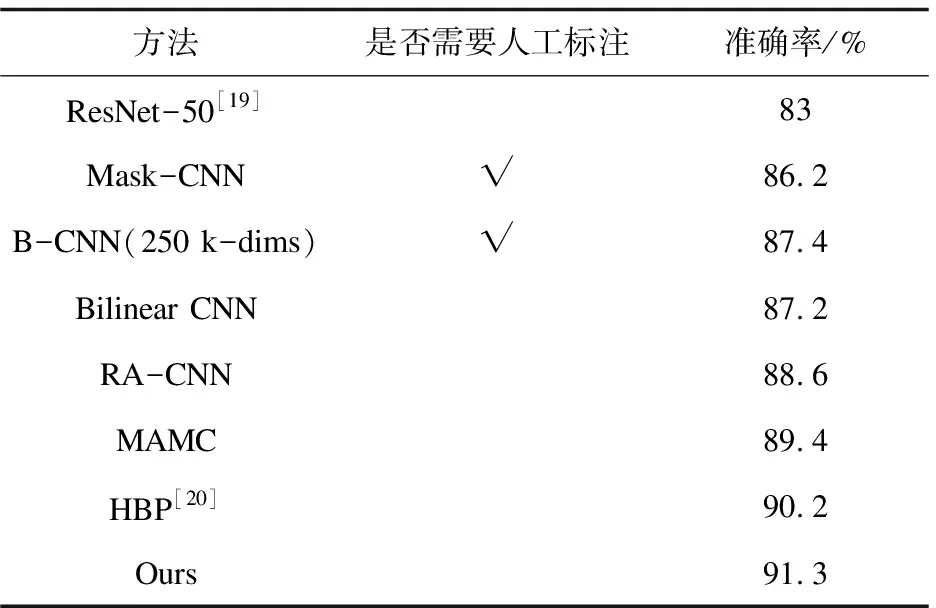
表1 在舰船数据集上与不同方法进行比较的结果
图6展示了文中模型在不同类别的舰船数据上的热力图可视化结果。由图可见,该模型可以很好地关注图片的显著区域,弱化背景区域对分类算法的干扰。
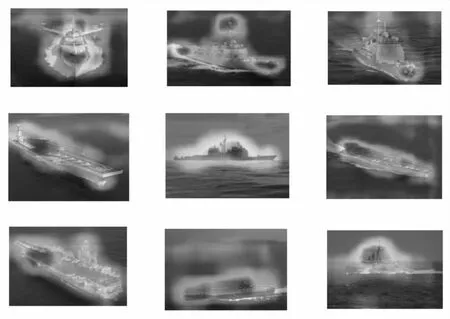
图6 舰船识别可视化热力图
为了研究通道注意力、空间注意力和双线性池化对模型精度的贡献程度,进行了消融实验,如表2所示。当该模型在不使用通道注意力机制模块进行训练测试的准确率只有87.8%,比完整模型下的准确率下降了2.5个百分点,说明通道注意力特征对模型准确率的影响很大;在模型去掉空间注意力模块进行训练测试的准确率相比完整模型下的准确率下降了2个百分点;该模型在不使用双线性池化进行训练测试的准确率下降了1.1个百分点。由此可见,不同模块都对细粒度识别的准确率做出了相应的贡献。
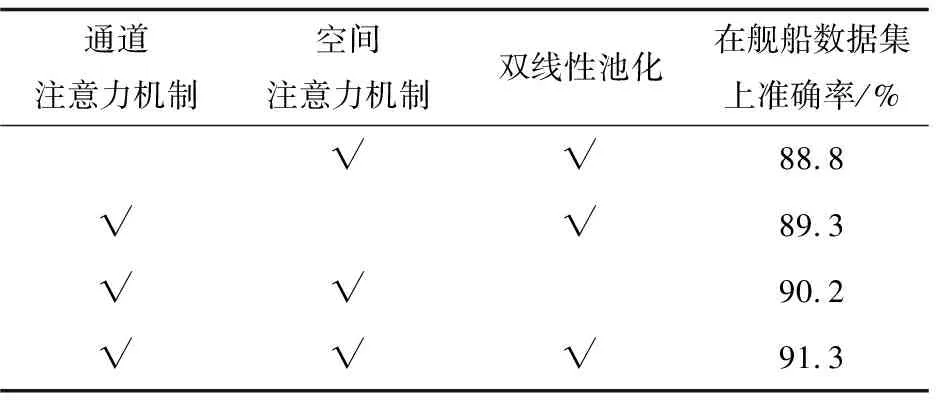
表2 在舰船数据集上进行消融实验的结果
4 结束语
针对自然场景下弱监督的细粒度舰船图像识别进行了研究,提出一种基于注意力双线性池化的细粒度舰船识别方法。通过利用通道注意力机制和空间注意力机制分别在图像的通道层面和空间层面进行判别性特征提取,然后利用分层双线性池化操作对提取到的通道特征和空间特征进行融合,将通道特征和空间特征关联起来作为局部特征,然后再将局部特征和主分支学习到的全局特征进行拼接,最终实现舰船类别的预测。在搜集到的舰船数据集上进行了实验,达到了91.3%的准确率。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
国际商业技术(2022年4期)2022-04-21
小雪花·成长指南(2022年1期)2022-04-09
舰船科学技术(2021年12期)2021-03-29
数码世界(2019年6期)2019-09-09
中国信息技术教育(2016年21期)2016-12-05
第二课堂(课外活动版)(2016年2期)2016-10-21
环球时报(2009-09-16)2009-09-16
中学英语之友·高一版(2008年10期)2008-12-11
