
基于词频和信息熵改进的卡方特征选择
2022-08-22 15:39:20张振康王韩林晏飞扬
计算机仿真 2022年7期
刘 辉,张振康,王韩林 ,晏飞扬
(1. 重庆邮电大学通信与信息工程学院,重庆 400065; 2. 重庆邮电大学通信新技术应用研究中心,重庆 400065; 3. 重庆信科设计有限公司,重庆 401121)
1 引言
文本分类的表示模型一般采用向量空间模型,它有着高维稀疏的缺点,严重影响着文本分类的效果。特征选择是解决向量空间模型高维度缺陷的有效方法,通过选取优质的特征子集来代表原始的字符集合,达到有效表示文本、提高表示效率的目的。信息论和统计学思想指导了特征选择方法的设计,一些常用方法如基尼指数、文档频率、信息增益、互信息、卡方统计、期望交叉熵等均受此启发[1]。已有研究表明,CHI相比于其它特征选择方法更具有优势[2]。
传统的CHI方法虽然有着时间复杂度低、效果良好等优点,但也存在不足。该方法统计了特征词的文档频率,用来评估特征词对文本分类的重要程度,但是忽略了词频的影响力,造成了低频词缺陷;有些时候,对分类起到干扰作用的词项,会被误认为重要词汇,进入到文本表示集合中,这就引入了负相关因素。针对以上不足,一些学者做了大量研究工作。徐明等人[3]将频度参数引入到传统模型中,用改进的卡方统计方法进行微博特征提取,取得了较好的实验效果。马莹等人[4]通过引入项的频度、分散度、集中度等因子对模型进行加权改进,并验证了此方法的有效性。冀俊忠等人[5]由方差统计策略出发,联合IG与CHI,挖掘了更多类别特征;裴英博等人[6]通过引入文本的分散度、集中度等因素对模型进行加权,提高了其在类分布不均匀语料集上的分类精确度。闫健卓等人[7]基于类间词频和类内分布熵,为卡方统计量添加了词频信息,提高了特征项的类别表示能力。李平等人[8]提出相关系数,增加特征项在类别中的影响力,从而减弱负相关性。宋呈祥等人[9]定义了频度分布相关性系数,选择局部强相关性特征,提升了不均衡数据集的分类指标。谢娜娜等人[10]提出倾向性选择因子,对小类别特征的“负相关性”起到一定抑制作用。忽略了不均衡数据集中特征词类间分布差异性。李富星等人[11]针对类内分散度、类间集中度同权的缺点,引入平衡因子,改进了类别区分词的提取效果。刘海峰等人[12]引入比例因子α,按照其正、负相关性进行分类并赋以不同权重以改善CHI模型的特征选择能力,但是比例因子需要通过经验来选择,误差较大。樊存佳等人[13]提出自适应比例因子,削减了人为选取比例因子带来的误差。
对于特征选择而言,希望满足这样的原则,即特征词在本类中均匀出现,覆盖大多数文档,且多次出现,在类外分布较少,凸显本类特征词的代表能力。针对以上原则,提出改进的卡方统计方法弥补既有模型的不足。利用词频信息的分布,获取类内分散的词汇;利用信息熵的权衡,获取类间集中的词汇。
2 CHI特征选择方法
CHI特征选择方法常被用来评估特征项tk和类别ci的相关程度。卡方值越大,特征含有的类别信息越多,特征也就越重要。假设特征项tk和类别ci之间满足一阶自由度的分布条件,则特征tk对于类别ci的χ2统计值计算如式(1)所示
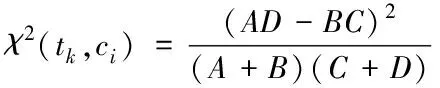
(1)
其中,A表示包含特征tk且属于类别ci的文档数,B表示包含特征tk且不属于类别ci的文档数,C表示不包含特征tk且属于类别ci的文档数,D表示不包含特征tk且不属于类别ci的文档数。
当要从全类当中挑选特征词时,就需要在类别特征词的基础上进行筛选。具体来说,有两种策略,分别为求最大值和加权平均。计算公式如下:

(2)
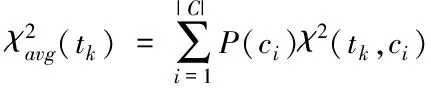
(3)
其中,式(2)将出现的最大卡方值作为特征的全局卡方值,式(3)综合看待各类别卡方值的贡献,结合类别频率,平衡了数据倾斜问题。
3 卡方统计方法的改进
3.1 基于词频信息的改进
由式(1)可以知道,它只考虑了特征项是否在文档中出现,而不管其出现了多少次。对于同样的只在某一类别ci中出现而在其它类别很少出现特征项,在某一文档内出现次数越多的特征项比出现次数少的类别表征能力更强。所以只统计在类别中出现的文档数是不够的,还应该考虑到其在文档内的不同词频数对类别表征能力的影响。
卡方统计方法并没有把词频考虑进来,这样就造成低频词泛滥的情况。如果同一类的两个特征项,它们的文档频率相差不大,则卡方值也就接近。但是,在类内频繁出现的词语应该比不频繁出现的词语更具有代表性。所以应当考虑特征项在类内的频度信息,使得高频词汇的类别表征能力强于低频词汇。为了得到专属类别的特征项,需要排除一些在本类中大量出现,在其它类中也大量出现的词汇。
Yang等人[14]提出了CMFS特征选择算法,结合了文档频率和DIA关联因子的优点,从类内和类间两个角度综合地评判一个特征的分类重要性程度。为解决CHI的低频词缺陷,借鉴了CMFS的思想,在词汇的基础上,改进原有方法,提出CMFS_CHI特征选择方法,改进方法的公式如下
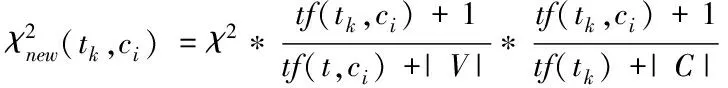
(4)
其中,tf(tk,ci)表示特征tk在类别ci中的词汇频率,tf(t,ci)表示在类别ci中所有特征的频率总和,tf(tk)表示特征tk在整个训练集中的词汇频率,|V|表示特征的初始数目,|C|表示类别的数目。
3.2 基于类内信息熵的改进
卡方统计量衡量的是特征项tk和类别ci之间的相关程度,特征项对于某类的卡方值越高,其与该类之间的相关性越大,携带的类别信息越多。卡方统计量在衡量类别特征词的权重时,会引入干扰,这是该方法的固有缺陷。根据相关程度判别特征项与类别的所属关系,虽然简单高效,但是有将负相关的特征项误判为正相关的可能性,若负相关的特征项参与表示本类别,会对最终的文本分类结果产生消极影响。
为了消除负相关特征的不利作用,已有学者作了一些研究。袁磊等人[15]从判断条件出发,对特征项的相关性进行了区分,完全排除负相关特征。当AD-BC> 0时,认为特征项对分类起到积极作用,属于正相关特征;当AD-BC≤ 0时,认为特征项对分类起到消极作用,属于负相关特征,但是,忽略了中频词携带的文本分类信息,造成分类精度下降。刘海峰等人[12]引入赋权因子,按不同权重从正相关特征、负相关特征中提取分类信息,改善CHI模型的特征选择能力,但是,赋权因子又造成了不可避免的调节误差。
为了更好地识别特征词的相关性,引入了类内信息熵[16]的概念。通过比较本类的信息熵和全类平均信息熵,有效度量特征词的相关性,排除负相关特征词的干扰,将具有类别表征能力的特征词纳入本类。类内信息熵的定义如下

(5)
其中tf(tk,diq)为特征tk在ci类的第q个文本出现的频数。分析此式可以看出,当特征词在类内分布得越均匀,而不是集中在某几个文档,越有资格代表该类,相应熵值也在反映这一变化,表现为熵值越大。
综上所述,针对低频词缺陷和负相关问题,在考虑文档频率的基础上,融合分布状况,加入词频信息,然后为了获取类别词汇,降低噪声因素干扰,改进了判决条件,提出最终改进的卡方统计方法(ICHI),其公式如下

(6)
基于ICHI的特征选择算法如下:
输入:训练集文本D,类别集合C,特征选择维度N。
输出:特征集合Fi。
1)将训练集文本D进行预处理;
2)由类别ci生成类别集合Fi;
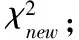
4)针对类别集合Fi中的每个特征词,使用式(5)计算类内信息熵和平均信息熵;
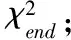
6)将各类别集合放到一起,使用式(2)确定重复词的卡方值,然后依据卡方值进行降序排序;
7)输出TopN个特征作为Fi,算法结束。
4 实验与分析
4.1 实验环境和数据
实验在Pycharm2019环境下进行,采用的编程语言是python3.7,电脑系统是windows10,使用了SVM分类器进行文本数据的分类实验。整体流程如图1所示。语料集合选用的是复旦大学李荣陆教授整理的新闻语料库。选取其中的电脑、运动、历史、环境、政治,共5个类别。从中各抽取500篇文档,按照4:1的比例分类训练集和测试集。分词工具采用的是中科院的NLPIR汉语分词系统[17]。数据集的分布如表1所示。
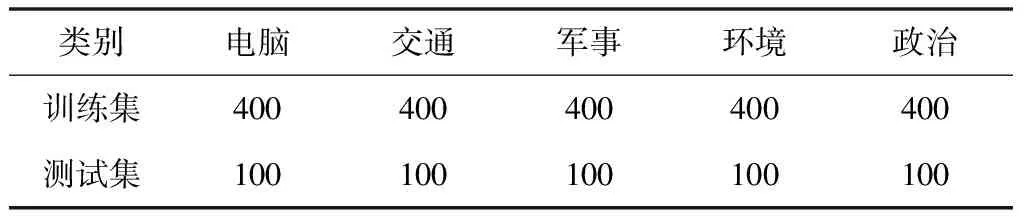
表1 数据集分布
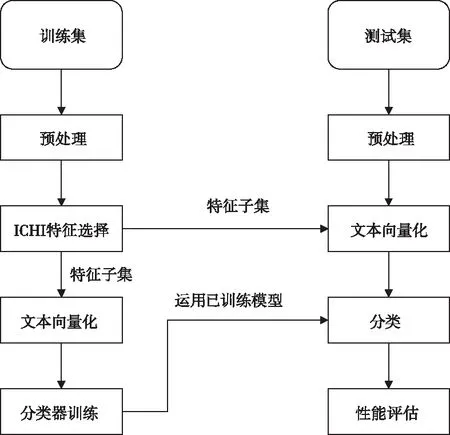
图1 文本分类流程
4.2 评价指标
衡量具体类别上的实验性能有查准率P(precision)、查全率R(recall)、F1值等指标,如式(7)~(9)所示。衡量全体类别上的实验性能有宏查准率(macro_P)、宏查全率(macro_R)、宏F1值(macro_F1)、准确率(accuracy)等指标,如式(10)~(12)所示。

(7)
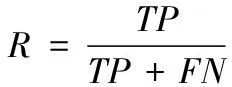
(8)
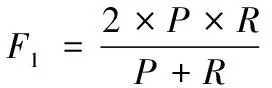
(9)
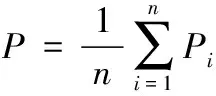
(10)
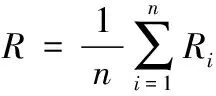
(11)
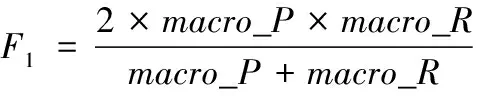
(12)
其中TP为真正例,FP为假正例,FN为假反例,TN为真反例。
4.3 实验结果与分析
对数据集中的文本数据进行预先处理,包括分词、去除停用词等。使用IG、CHI、WCHI[18]、ICHI三种特征选择方法对词汇组成的特征集合依据分类重要性进行特征寻优,并
按照特征的重要程度进行排序,依次选取位置靠前的多组特征子集展开实验。
图2和图3对 IG、CHI、WCHI、ICHI进行了对比实验,从而验证ICHI的分类正确性和性能。从图2可以看出,ICHI的整体准确率要高于CHI、WCHI和IG。随着特征维度的增加,三种特征选择方法的准确率开始提高,后期由于冗余信息的加入,增长缓慢,甚至下降。其中ICHI的准确率在1300维时达到最高,为87%;WCHI的准确率在1600维时达到最高,为84%;CHI的准确率也在1600维时达到最高,为83%;IG的准确率在1900维时达到最高,为83%。从图3可以看出,ICHI在大部分维度上的表现好于其它对比算法,四种特征选择方法的宏F1值在1300维时达到最高,ICHI与IG、CHI、WCHI相比,分别提高了2.91%、2.02%、1.57%。
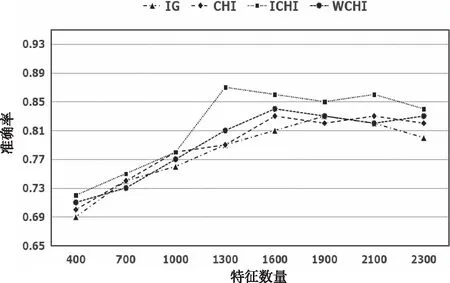
图2 四种特征选择方法的准确率对比
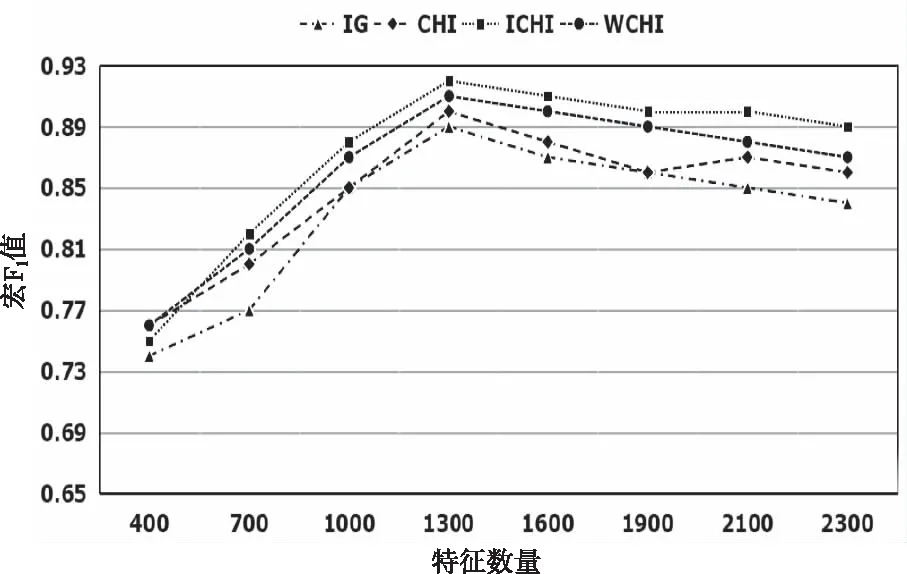
图3 四种特征选择方法的宏F1值对比
ICHI在准确率和宏F1值方面要比IG和CHI表现好,原因在于IG和CHI忽略了词频信息,而ICHI借助CMFS引入了词频因子,该词频因子从类内、类间两个角度考量了一个特征对分类的重要性;对于IG会将特征词不出现的情况作为主导,CHI无法有效识别负相关特征的问题,ICHI借助类内信息熵来识别有效特征,去除噪声特征的干扰。WCHI在CHI的基础上用tfidf加权,所以效果要好于CHI,但是,没有考虑词频在类别中的分布,也没有对负相关特征进行处理,所以,表现不如ICHI。
为了进一步验证ICHI的效果,进行了具体类别上的实验,选取的特征维度是1300维。实验结果如图4~6所示。

图4 各类别的查准率对比

图5 各类别的查全率对比
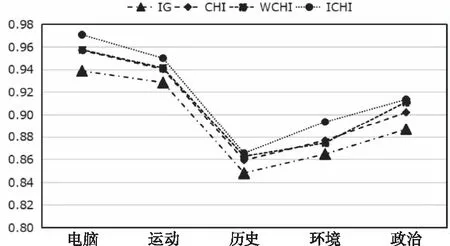
图6 各类别的F1值对比
分析图4~6可知,改进的CHI在大多数类别上明显地比传统的CHI、WCHI和IG表现要好。其中在精确率上,ICHI比IG在政治类上提升最明显,为2.61%;ICHI比CHI、WCHI在环境类上提升最明显,分别为1.57%和0.92%。在召回率上,ICHI比IG、CHI和WCHI在电脑类上提升最明显,分别为4.00%、2.41%和3.54%。在F1值上,ICHI比IG和WCHI在电脑类上提升最明显,分别为3.20%、2.94%;ICHI比CHI在环境类上提升最明显,为1.66%。可以得出,ICHI与IG、CHI、WCHI相比,特征选择的效果要好一些。
分析原因在于改进算法提高了模型的稳定性,一方面从电脑类、环境类、政治类中提取了高关联度特征词,另一方面兼顾了运动类、历史类特征词数量较少的情况,补充了更具代表性的特征词。
5 结语
传统的CHI特征选择方法考虑了特征词在语料集的文本频率,忽略了特征词在具体文本的词汇频率,造成了高频词和低频词的同等看待问题。由于负相关缺陷,导致含有少量分类信息的特征进入类别代表特征中,对分类造成了一定干扰。针对以上问题,本文提出了改进的CHI,从类内、类间两个角度考虑词频信息的重要性,而且通过信息增益理论对负相关特征进行了剔除。结合实验结果分析,ICHI比传统方法的特征选择效果要好。下一步的工作,将在特征词的语义能力上进行探索,借助神经网络技术识别更具代表性的特征进入特征集合或生成丰富含义的特征辅助特征的表达。
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
读者·校园版(2015年7期)2015-05-14 13:11:40
中文信息学报(2015年4期)2015-04-21 08:29:12
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
振动工程学报(2014年4期)2014-03-01 01:15:41
