
基于自编码器的冰箱压缩机振动信号特征提取及故障检测
2022-08-20 08:33:16刘恒冯涛王晶杨伟成
家电科技 2022年4期
刘恒 冯涛 王晶 杨伟成
1. 北京工商大学 北京 100048;
2. 中国家用电器研究院 北京 100037
0 引言
异音检测是压缩机产线质量检测的重要工序环节,许多专家学者在压缩机检测方向进行了深入研究并取得了优质的成果[1-4]。近年来,随着机器学习的快速发展,深度学习被引入到机械故障检测中,并取得了成果。通常,故障检测包括特征提取和分类两个步骤。从原始信号中提取故障特征,然后通过人工经验判断或模态识别技术进行分类[5-7]。尽管这些方法取得了一定成果,但其良好的性能需要大量标记数据。对于实际使用的压缩机,很难收集到足够的标记数据。杨斌等人[8]提出了一种基于特征的迁移神经网络(FTNN),利用实验室机器的诊断知识来识别实际机器的健康状态以解决样本数据少的问题。李春阳等[9]利用数据增强的方式开发出一种基于卷积生成对抗网络模型用以解决训练样本稀少的问题。在实际中,压缩机大多在正常状态下运行,呈现正常信号样本丰富,故障信号样本稀少的特点。为解决冰箱压缩机故障信号样本稀少的难题,本文应用自编码器模型,以大量正常信号样本为基础,研究冰箱压缩机正常信号样本共性特征的提取方法,进而实现压缩机的异音检测。
1 自编码器模型
自编码器由编码器和解码器两部分构成,编码环节通过输入原始数据对数据进行压缩,得到低维数据空间中的特征向量,该特征包括原始特征的本质信息。而解码环节通过前向传播对自编码器的参数进行优化调整,最终学习到原始数据的特征。如图1所示。

图1 自编码器结构
自编码器编码、解码过程可表示为[10]:

其中,σα为激活函数,在编码阶段采用的为Relu激活函数,W为输入数据的权重,b为偏置。

其中,σβ为激活函数,在编码阶段采用的为Relu和Sigmoid激活函数相结合的方式,W'为输出数据的权重,取W'=WT,b'为偏置。通过不断更新各层的调节权重和偏置参数,使重构误差达到最小,达到最优网络。
Adam算法(Adaptive Moment Estimation Algorithm, Adam)广泛用于深度学习优化的学习,不仅可以采用动量法作为参数的更新方向,还可以通过矩估计法调节每个参数的学习率。由于Adam算法对超参数具有很强的鲁棒性,因而在深度学习领域被广泛应用。Adam算法参数的更新差值为[11]:

其中,Δθt为需要更新的参数; 为对一阶梯度的校正,可以提供增大学习率的参数,加速训练能力;为对二阶梯度的校正,提供减少学习率的能力;为常数;α为学习率。
2 自编码器特征提取方法
自编码器声信号共性特征提取流程如图2所示,步骤如下:

图2 自编码器异常振动检测流程
(1)采集原始振动信号。
(2)对采集的信号进行预处理,图3 a)、图4 a)分别为采集到的正常样本信号通过不同预处理后的频谱图。
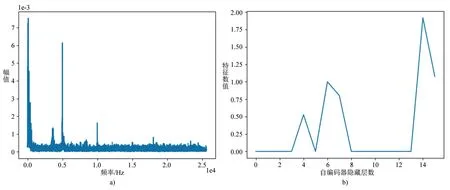
图3 经过频域FFT变换后的频谱图及提取到的自编码器共性特征

图4 经过频域FFT对数谱变换后的频谱图及提取到的自编码器共性特征
(3)划分为训练集和测试集。
(4)把训练集的样本作为自编码器的输入、将解码后的输出当作重构目标,损失函数为:

(5)将正常样本输入到编码器中得到的输出即为正常信号的共性特征信息,提取到的隐藏层共性特征如图3 b)、图4 b)所示。
(6)将测试集中的振动信号输入网络通过重构误差对比进行故障检测分类。
由于故障样本较难收集,考虑到测试集数据正负样本差距较大,需对故障样本进行重叠采样以建立一个平衡的数据集,本文对原始样本进行一定重叠比例分割的方法。采用重叠分割的方法对数据进行扩充,样本扩充示意图如图5所示,这样做既可以保证数据信息不会损失,同时还能提高样本数量。在选择样本长度的问题上,过短的信号样本会导致信息量不足,过长的样本又会使整体模型学习时间过长,所以选择一个适合的样本长度也是至关重要的。

图5 样本扩充示意图
样本扩充公式如下:

其中,N为以重叠率η分割后的样本数量,L为一段声信号样本的长度,len为预先设置分割后的样本长度。
3 检测结果与讨论
以某型冰箱压缩机为研究对象,在生产线上采集其壳体振动信号,振动信号采集过程中所使用的设备主要包括带有Pulse系统的计算机、采集卡及加速度传感器。采集过程如图6所示,将加速度传感器贴在处于工作状态中的压缩机外表面,并用Pulse系统将压缩机的振动信号录制下来。采集到的振动信号由专业人员进行分类,包括正常和异常两种压缩机振动信号。涉及的故障类型主要包括无油、内排气管焊堵、阀减震弹簧与内排气管间隙大、吸油管脱落、内排气管碰壳。采集到正常数据893个,故障数据52个,采用预处理后得到正常信号样本4937个,故障信号样本为532个。其中训练集只包括正常样本,数量为2000个;测试集包括正常和故障样本两类,分别取500个,训练集与测试集的样本并不重叠。
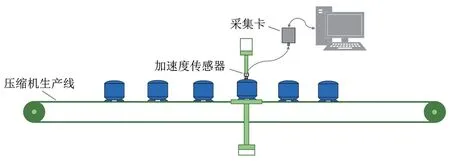
图6 采集装置连接示意图
自编码器模型使用正常数据训练得到,正常数据的重构结果与正常原始数据相差较小;但是将故障数据代入该自编码器模型中,所得到的重构结果就会与故障原始数据有较大的误差,可以对重构误差设置相应的阈值以实现故障机的识别,通过均方差计算可确定最优阈值作为故障分类标准。图7为采用频域FFT对数谱的数据处理方式得到的正常、故障样本均方差图,从图中可以看出正常样本与故障样本的均方差分布以6100左右为界限,最后可进行细化测试,找到最佳阈值的位置。

图7 正常、故障样本均方差图
选择合适的数据处理方式在学习模型中起到了一个关键的作用,考虑样本为一维时域信号,通常信号数据处理方式有时域处理、FFT频域处理等处理方式,这里选用FFT频域处理和FFT频域对数处理两种方式进行不同学习率对学习模型的影响,为了消除随机误差的影响对每组分别进行5次测试,并以测试集最终的平均准确率为结果。表1为不同数据处理方式和学习率实验结果。
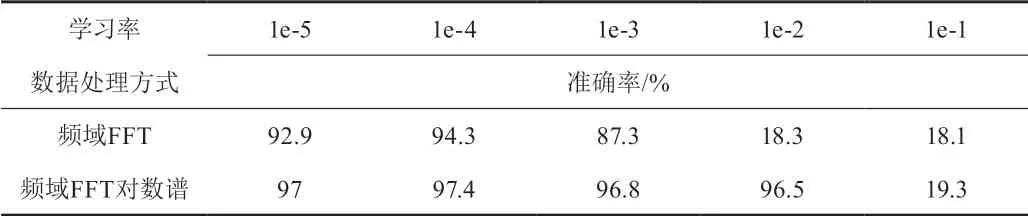
表1 不同数据处理方式和学习率实验结果
使用频域FFT及频域FFT对数谱的数据处理分别在不同学习率下的故障分类准确率如表1所示。由表1的结果可以看出,利用频域FFT及频域FFT对数谱进行数据处理时,最优的准确率出现在学习率为1e-4和频域对数谱的数据处理方式上。随着学习率的增加,识别准确率出现了不同程度的下降。从图8的PR曲线来看,频域FFT对数谱和频域FFT均具有较好的学习性能,但使用频域FFT对数谱要更胜一筹。分析其原因,使用频域FFT数据处理时,不仅可以避免信号的多样性及不确定性,还可以提高频率的分辨率。而使用频率FFT对数谱的数据处理方式,对数谱数值小的部分差异的敏感程度要比数值大的部分的差异敏感程度更高,且信号更接近于人耳实际听取的声音,所以更有利于增加其分辨能力。
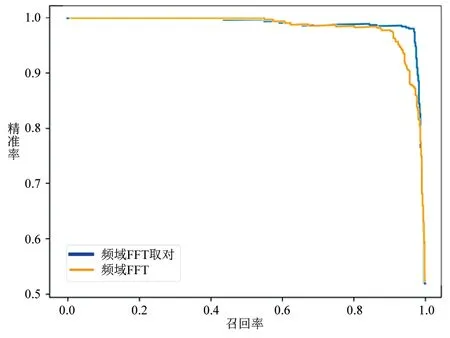
图8 不同数据处理下的PR曲线
4 结论
为了在少量故障压缩机样本的条件下进行故障检测,本文提出了一种共性特征提取及检测的自编码器系统。学习模型由全连接层的自编码器网络堆叠而成,并用两种数据处理方式进行对比分析,利用非标记数据样本来发掘数据中的内部结构,根据测试结果可以得出:使用频域FFT对数谱的数据处理方式且在学习率为1e-4的条件下,具有较好的分类结果,准确率达到97.4%。
综上所述,在选定合适的自编码器参数和频域FFT对数谱的条件下,自编码器可以用于压缩机的异常振动监测。本文所有的样本数据虽然采集于往复式冰箱压缩机,但是本文所用到的自编码器模型并不限于适用往复式冰箱压缩机,也适用于其他类型压缩机。
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:06
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化·高一版(2018年10期)2018-11-08 11:06:56
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
雷达学报(2018年3期)2018-07-18 02:41:34
电子设计工程(2017年20期)2017-02-10 03:39:29
火控雷达技术(2016年1期)2016-02-06 02:17:55
电子器件(2015年5期)2015-12-29 08:42:24
无线电通信技术(2015年3期)2015-12-23 11:37:02
