
基于加权K-近邻分类的非视距识别方法研究
2022-08-19 02:55:44韦子辉解云龙王世昭叶兴跃张要发方立德
电子与信息学报 2022年8期
韦子辉 解云龙 王世昭 叶兴跃 张要发 方立德*
①(河北大学质量技术监督学院 保定 071002)
②(计量仪器与系统国家地方联合工程研究中心 保定 071002)
③(保定市产业计量工程技术研究中心 保定 071002)
1 引言
近年来,室内定位在技术手段、定位精度、适用范围方面取得了长足的进步,也逐渐渗透到人们的日常生活中,例如养老院中对老人的看护、办公区域对工作人员的管理、火灾救援等。在无线定位技术中,超宽带定位技术具有时域分辨率高、抗多径干扰能力强、穿透能力强的特点[1,2],相比于超声波定位、红外线定位、射频识别定位(Radio Frequency IDentification, RFID)等定位技术可实现更高精度定位,在精确定位应用中具有极大潜力。
由于脉冲超宽带(Impulsive Radio Ultra-Wide-Band, IR-UWB)具有一系列的优良特性,越来越多的研究人员投身于超宽带定位技术的研究,国外多家公司进行超宽带定位芯片的研究,其中脱颖而出的是爱尔兰DecaWave公司生产的DW1000定位射频芯片,具有较高的精确度。在定位系统中,视距情况下,直达信号被准确识别,定位精度较高,但在实际应用中,室内环境复杂,会产生较大的定位误差,而误差的主要来源是遮挡造成时延引起的误差和信号反射引起直达信号的错误判断[3]。如果采用错误的直达信号,严重影响定位性能,故需要提前进行非视距(Non-Line-Of-Sight, NLOS)的判断,对NLOS信道进行剔除,使用视距(Line-Of-Sight, LOS)环境信道计算,得到更高精度的位置估计。因此,NLOS环境的识别一直是超宽带定位领域的一个重要研究方向。
NLOS识别算法对IR-UWB定位意义重大,是解决NLOS干扰的最直接手段,其中传统的识别技术可以分为3类,即基于距离估计的方法、基于信道冲击响应的方法和基于位置估计的方法。基于距离估计的方法主要使用概率密度函数或范围估计的方法来区分LOS和NLOS。Yan等人[4]利用测量距离的贝叶斯先验概率,用贝叶斯序贯检验来区分NLOS。王长强等人[5]将卡尔曼滤波与测距残差相结合,通过计算观测值与卡尔曼滤波预测值之间的差,与设定阈值比较后识别有无NLOS存在。基于距离估计的方法在坐标计算之前识别NLOS,而基于位置估计的方法则在位置估计过程中识别NLOS,甚至会依次使用计算得到的位置坐标进行NLOS识别。Casas等人[6]在存在可用冗余距离测量值的情况下,通过比较距离值的不同子集产生的位置来识别NLOS,当没有冗余距离测量值或多个距离测量值属于NLOS时,该方法无效。Gustafson等人[7]通过利用间接路径测量所包含的地理位置信息来判断NLOS,不需要先验知识是此类方法的优点,但由于附加约束条件并不总是存在,因此很难确保有效识别NLOS。过去几年,基于信道冲激响应(Channel Impulse Response, CIR)进行NLOS识别发展迅速,冲激响应波形受传输路径影响明显,不同的传播路径有不同冲激响应,故可以从冲激响应波形中提取特征参量进行NLOS识别。孙希延等人[8]以此为根据建立均方根时延扩展和平均超量延迟的概率分布模型作为标准,将信道瞬时分布与标准分布间的KL散度(Kullback-Leibler Distance)做似然比检验进行NLOS识别。随着机器学习技术在无线通信中的应用,支持向量机[9](Support Vector Machine,SVM)、支持向量数据描述算法[10](Support Vector Data Description, SVDD)、导入向量机[11](Import Vector Machine, IVM)、决策树[12]等方法被应用到NLOS识别中,并显示出较好的识别效果,但实际应用中,这些算法训练比较困难,设计高效、轻量级的识别方案非常困难。
本文以构建一个识别准确率较高、环境适用性较强、计算复杂度较低的实时NLOS识别方法为目的,从接收信号中截取有用信号段,对有用信号段进行特征提取,选取合理特征参量集进行信号分类。本文提出一种新型特征参量–饱和度,并与前人提出的特征参量结合,利用Relief算法和互信息特征选择(Mutual Information Feature Selection,MIFS)算法选择最优特征子集,根据特征与分类标签的相关性确定特征权重,提出了一种基于加权K-近邻(Weighted K-Nearest Neighbor, WKNN)分类的多特征参量NLOS识别方法,建立NLOS识别系统模型。实验分析了训练样本数和K值的选取对WKNN分类性能的影响,综合确定了优选方案。实验表明:本算法在一些复杂环境中仍能获得较高的识别准确率。本系统流程如图1所示。
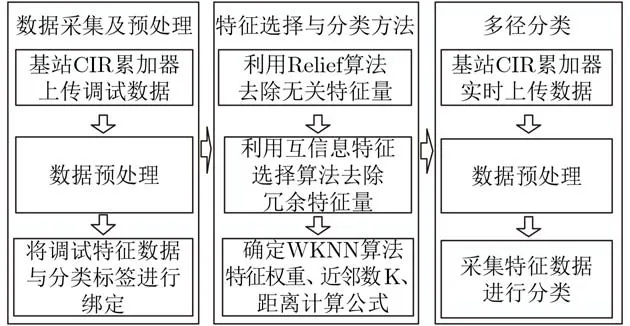
图1 NLOS识别方法流程
2 基于CIR波形的NLOS特征量构建
IR-UWB信道冲激响应波形易受传播路径影响,在NLOS传播环境下,障碍物对信号的吸收和反射都会投射到波形中,故可以利用数据挖掘在波形中提取特征参量,从频域和时域方面进行分析。在NLOS信道传播下,信号穿过障碍物,信号衰减会造成最大振幅和总能量的减小,信号阻塞会造成上升时间、平均附加时延和均方根时延的增大,信号发散会造成偏度和峭度的变化,故可以将这些特征参量作为NLOS状态识别的依据。数据挖掘是一种有效的工具,它可以执行复杂的计算过程,如大数据集中确定模式,从而可以成功地检测脉冲信号分类所需的有意义的信息和模式。Mucchi等人[13]提出利用峭度(kurtosis,k)对NLOS和LOS信道进行区分,并且对接收信号的质量进行排序,但成功率仅达到了74%。张浩等人[14]提出一种基于偏度的NLOS区分算法,该算法在室内办公环境中识别率较高,但在室内其他环境或者室外环境中识别率比较低。利用单一特征参量进行NLOS识别性能不是很好,故很多学者提出多种特征参量融合进行识别。纪元法等人[15]提出一种基于峭度和均方根时延扩展联合似然比检验区分NLOS状态的算法,获得较高的准确率。Guvenc等人[16]提出了一种新的基于峭度、平均附加时延和均方根时延扩展等多径信道统计量融合的非视距识别技术,正确识别率可达90%以上。上述特征参量的数学模型如表1所示。其 中h(t) 为 信 道 冲 激 响 应 函 数,μ|h|,σ|h|分 别 为|h(t)|的平均值和标准差。

表1 各特征参量的数学模型
以上特征参量是针对整个CIR波形的特征参量,没有针对某一传播路径进行分析,而传播中的定位信号第1路径的判断对定位精度有较大影响,故在识别NLOS信号中可以将第1路径的衰减程度作为一种识别特征。
在LOS传播环境下,第1条识别路径即为直射路径,也是最强路径,在NLOS传播环境下,直射路径在传播过程中要穿过1个或多个障碍物,由于障碍物的相对介电常数大于1,所以会造成一定程度的衰减,为减少接收信号中噪声部分对NLOS识别的干扰,设置噪声阈值,如图2所示,蓝色线即噪声阈值,该阈值的设定既考虑了噪声影响,也考虑了第1路径严重衰减低于阈值而不能识别的可能。本文考虑在NLOS环境传播下障碍物对第1路径的吸收,对第1路径的衰减程度做一个量化,故提出饱和度S。表达式如式(1)所示
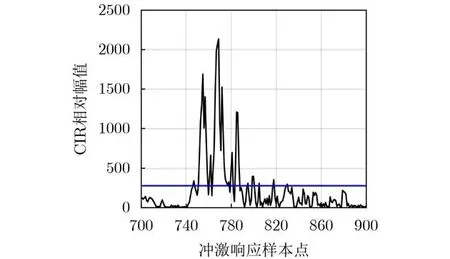
图2 CIR波形阈值设置示意图

3 特征选择与分类算法
3.1 特征选择
如图3所示为室内特征参量箱线图,可以看出在室内传播信道下,上升时间和饱和度箱图重合部分很少,区分传播信道的效果较好;最大振幅、总能量、平均附加时延只能部分区分,效果不明显;偏度、峭度、均方根时延箱图重合部分很多,基本无法区分。但不同的信道会产生不同的特征分布,而且仅凭直观的对各参数值的分布观察,不能有力地判断使用哪几个特征参量作为分类的基础。并且,在提出的特征参量中,不可避免地会存在无关、冗余的特征,需要进行特征选择[17]。特征选择阶段选用多信道特征参数数据,采用Relief特征选择法[18]和MIFS[19]方法进行筛选,首先利用Relief特征选择法衡量特征与分类标签间的相关性,进而选择对分类效果影响显著的特征量,然后利用MIFS方法过滤掉冗余性较大的特征,挑选出分类效果最佳的特征子集进行分类。
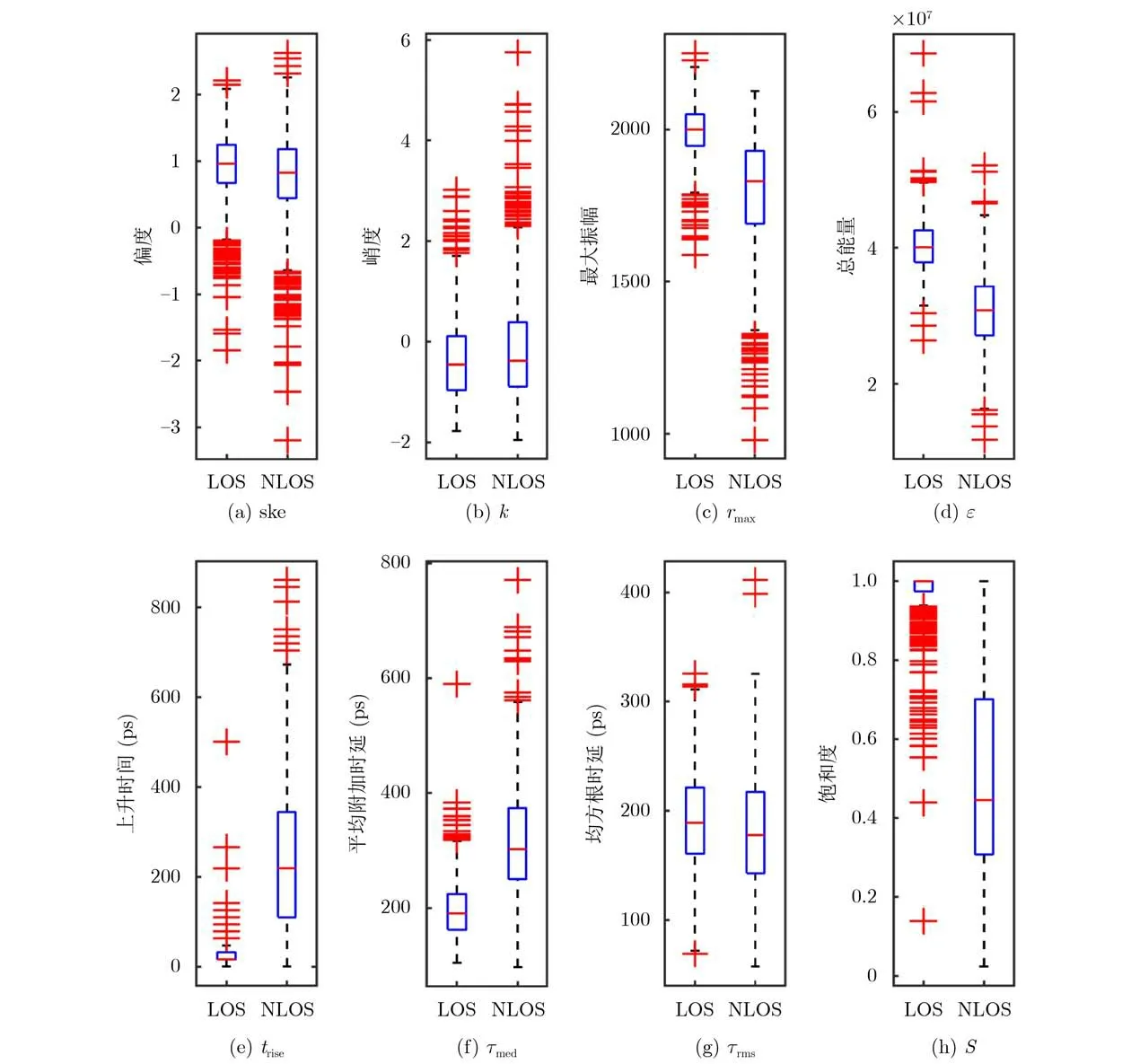
图3 室内特征参量箱线图
3.2 Relief特征选择法
Relief算法是过滤型特征选择算法中性能较好的一种,应用于数据预处理阶段,运行效率高、适用性强[20]。该算法是根据每个特征与类别标签的相关性确定不同权值,选取权值较大的特征参量作为降维后的特征子集。主要思想为:在训练样本集中随机选取m个样本,对每个样本R找到同类近邻样本H和不同类近邻样本M,根据式(2)求出样本各特征与类别标签的相关性,并求得各特征的平均权重。相关性越大表示该特征参量对样本的区分能力越强
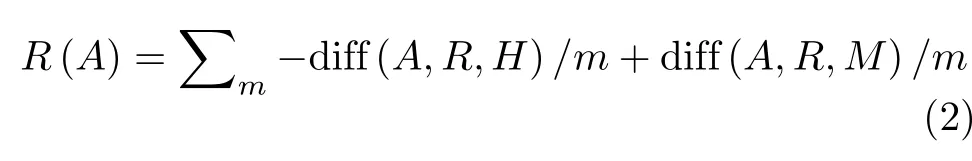
其中,R(A)为 第A个特征的权重,d iff(A,R,H)和diff(A,R,M)分 别为选取样本R与同类近邻样本H和不同类近邻样本M在特征A上的差值。
利用Relief算法计算上述8个特征参量的相关性值,如表2所示。相关性越大表示该特征参量对样本的区分能力越强,故提取最大振幅、上升时间、平均附加时延、饱和度作为新的特征子集,实现降维的目的。
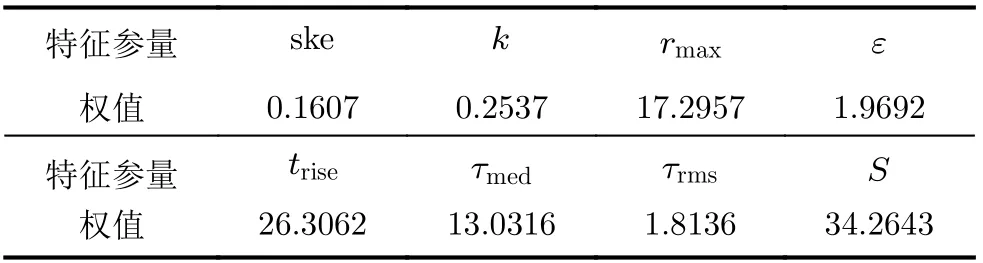
表2 各参量与分类标签的相关性
3.3 MIFS算法

将得到的最大振幅、总能量、上升时间、平均附加时延、饱和度利用互信息进行冗余度分析如表3所示。通过对上述特征量的分析,冗余度较小的特征量为上升时间、最大振幅、饱和度。
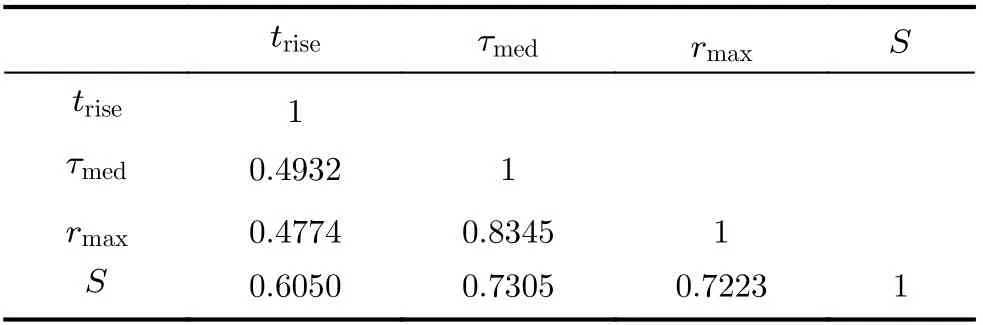
表3 两特征参量之间的冗余度
通过Relief算法和MIFS算法对CIR特征参量的相关性和冗余性分析,选取相关性较大、冗余性较小的3个特征参量即上升时间、最大振幅、饱和度作为最佳选取特征集。
3.4 分类算法
定位中NLOS信道的鉴别实际也是对信道的二分类过程。从使用单一特征参量鉴别,到使用似然比进行多参量融合鉴别,在提高信道鉴别精度方面有了很大的进展。同时,机器学习在室内定位和信号分类领域的进展也引起了人们极大的关注,这些研究致力于开发一种更好、更鲁棒的算法来对数据进行分类和识别,在这些工作中,有一些经典的分类器,如支持向量机、人工神经网络、决策树、贝叶斯方法[21,22],也有一些它们的变体和组合。在NLOS识别中,尽管可以使用许多的分类技术,但一些分类器结构复杂,计算量较高,并不适用在较高频率的实时定位NLOS识别中,本文选取WKNN分类方法进行实时识别,计算负担较低,分类耗时较短,且在复杂的分类问题中仍具有较高的灵活性,故该分类器较为适用。
WKNN分类算法是一种较为成熟的机器学习分类算法,多用于信号处理领域[23,24]。该算法的思路是:在训练数据集中特征向量与类别已知的情况下,对测试样本进行分类,确定各特征参量的权重,计算测试数据与训练数据之间的距离,将距离按照从大到小的顺序排序,得到距离最小的K个训练数据,将这K个数据中出现最多的类别作为测试数据的预测类。采用WKNN分类算法需要考虑训练数据集的数量、特征参量的权重、距离的计算、K值的选取。
在计算距离前,需对训练数据集及测试数据做归一化处理,防止特征向量数值差别过大影响权重,并通过使用Relief算法确定的各特征参量与分类标签的相关性判断各特征参量的权重。权重计算如式(4)所示

K值的选取对NLOS的识别率有较大的影响。若出现两个类在测试数据的WKNN算法中具有相同的数量,则会出现该测试数据不能判断类别的情况,为避免这种情况发生,一般K值选择奇数。训练数据集数量不同,最优K值也不同。若K值取得过小,则算法易受信号干扰的影响,容易发生过拟合,使分类结果不稳定;若K值取得过大,则会造成泛化误差大而近似误差大的情况,容易发生欠拟合,同时,K值过大也会增大算法的时间开销。为说明精度与K值的关系,并确定最优K值,绘出了它的K-精度曲线如图4所示。
从图4可以看出,对于不同数据集数量,K-精度曲线也不同,但它们都有相同的趋势:K值较小时,分类精度较低,随K值增大,分类精度逐渐增大,当K增大到一定程度时,分类精度逐渐减小。由图可以得到最优K值在10附近,K确定为9。为了保证识别的实时性和识别的正确率,将训练数据集定为300,包括150组LOS信道和150组NLOS信道,防止因分类数据的不平等导致识别率的降低。

图4 K-精度曲线
4 实验及结果分析
4.1 实验平台
如图5所示,本系统由标签、基站、以太网供电(Power Over Ethernet, POE)交换机、上位机(电脑)构成,采用到达时间差(Time Differences Of Arrival, TDOA)计算距离,每个基站都存在数据采集单元和处理单元,基站与POE交换机之间采用以太网线进行连接,供电的同时进行数据传输,标签采用电池直接供电。为了采集CIR数据,运动的定位标签不断地向基站发送定位请求信号,基站和标签使用的天线均为全向天线。基站利用UDP协议将CIR数据上传到上位机进行分析。上位机接收到CIR数据包进行处理,显示波形,每个数据点按接收到的先后顺序排列,间隔为15.65 ps。
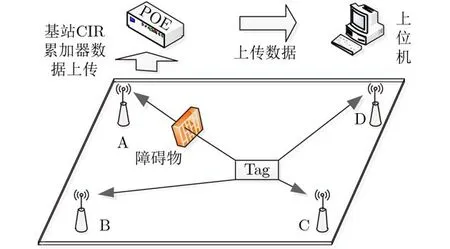
图5 NLOS识别系统图
在信号传播过程中,接收信号强度会随着传播距离的增加造成衰减,并且不同障碍物有不同的介电常数,衰减也不同,一些特征参量中隐含这种衰减特性,使用这种距离衰减严重的特征参量作为分类标准会使分类精度降低。为了验证本文NLOS识别算法的性能,利用已有的定位装置(基站和标签)开展了不同信道下使用不同特征参量的识别精度对比研究。包括室内办公环境(CM1)、玻璃阻塞(CM2)、墙体阻塞(CM3)、工况阻塞(CM4)、室外10 m人体阻塞(CM5)、室外30 m人体阻塞(CM6)等不同信道,如图6所示。

图6 实验环境
4.2 识别算法性能评定指标
为了评估本文NLOS识别系统的识别效果及不同环境的泛化能力,选用混淆矩阵(confusion matrix)[25]来度量该识别系统的性能,将预测分类与实际分类划分为4种情况,真阳性(TP)、伪阳性(FP)、真阴性(TN)、伪阴性(FN),如表4所示。

表4 混淆矩阵
混淆矩阵统计的是个数,很难衡量模型的优劣,故在混淆矩阵的基础上使用准确率(Accuracy,A)作为性能度量指标。计算方式如式(7)所示

4.3 单一参量性能分析
本文旨在使用CIR波形中提取的特征参量来进行NLOS识别。尽管之前的工作已经提供了可用于解决此问题的参数,但在实际不同环境信道下可能效果并不好,故在此分析了单一特征参量在不同信道下的识别精度,如表5所示。对比同种环境不同距离CM5和CM6信道识别精度,发现某些特征参量受传播距离影响严重,造成识别率降低,如总能量ε在CM5环境下识别精度可达99.67%,但在CM6环境下仅达到88.67%,故这类特征参量需尽量减少使用。对比不同环境下的识别精度,发现单一特征参量在某一信道下的识别率可以达到90%以上,具有较好的识别效果,但该特征参量在另一信道下识别精度仅为60%。由此可得,使用单一特征参量进行识别仅适用于个别环境信道,对其他环境没有较好的适用性。
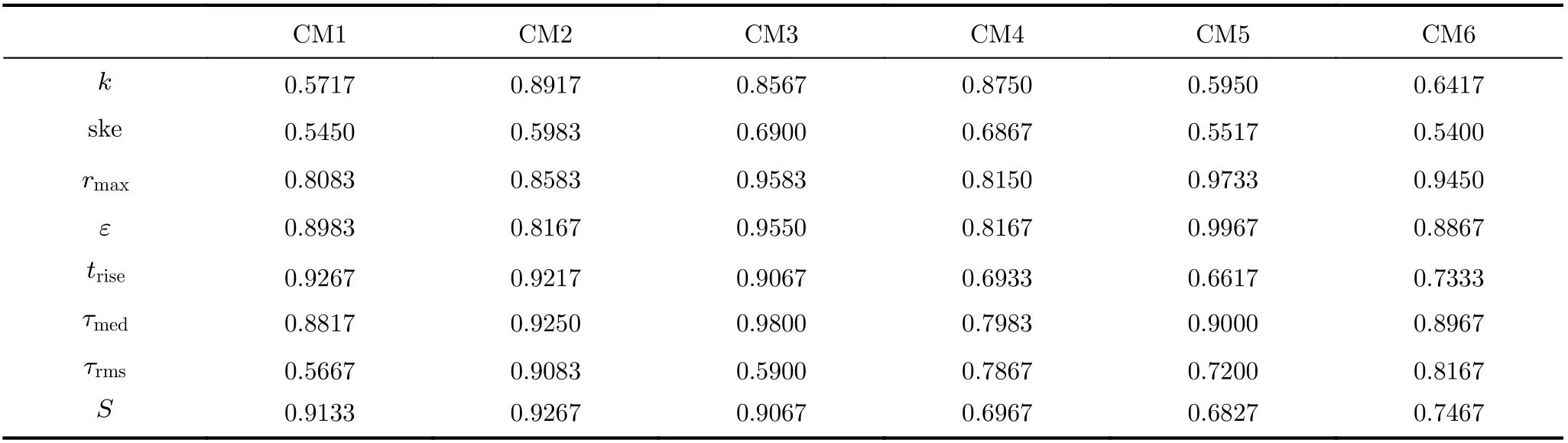
表5 单一参量在不同信道(CM)下的识别精度
4.4 多参量融合性能分析
本文所提算法利用Relief特征选择法和互信息特征选择法进行特征筛选,选择上升时间、最大振幅、饱和度作为最优特征子集进行WKNN分类。WKNN参数设置:每种传播信道训练样本数设置为200,共1200组训练数据、近邻数K设置为9、距离计算采用欧氏距离。
在室内办公环境下进行400次分类实验,该WKNN分类效果图如图7所示,其中,红色○和蓝色△分别为正确识别的LOS和NLOS信道,黑色☆和绿色*分别为错误识别的LOS和NLOS信道。WKNN分类识别率达到97.25%,平均单次识别耗时0.024 s,有较好的分类性能。
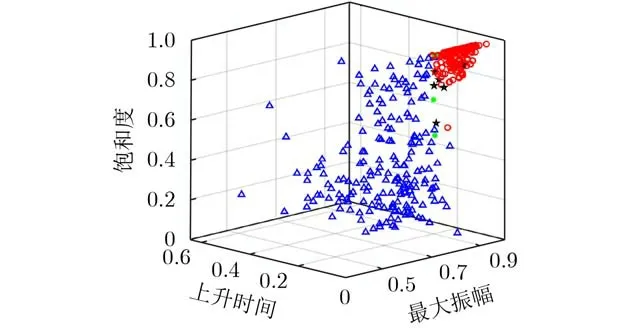
图7 WKNN分类效果图
信号传播环境的复杂程度不同会造成信道冲激响应差异程度不同,不同特征对环境也有不同的识别能力,并且不同的特征之间存在不一样的冗余度,故如随意将之进行融合对识别能力有一定影响。本文提出的识别方法考虑到了特征与分类标签之间的相关性和特征与特征之间的冗余性,有效地提高了识别精度。为验证本文提出的识别方法的性能优越性,采用不同特征融合进行了不同信道下的实验对比,如表6所示。

表6 多参量对不同信道(CM)的识别精度
可以看出本文提出的rmax+trise+S3种参量融合识别方法在不同信道下均达到了95%以上的识别精度,并且对比同一环境下CM5和CM6不同距离信道下,识别精度并不会受到影响。在计算复杂度相当的情况下,其余不同特征参量融合方法可能在某一环境下比本文提出的方法识别精度要高一点,但在别的环境信道下较低,不能达到有效识别的程度。故本文提出的识别方法识别精度较高,环境适用性较强。
5 结论
复杂的室内情况下,人体遮挡、墙体遮挡、铁制品遮挡等非视距效应严重影响信号的传播时间,这对室内定位精度的提高提出了严峻挑战。本文旨在构建一个识别准确率较高、环境适用性较强、计算复杂度较低的实时NLOS识别系统,提出一种基于CIR的WKNN快速分类算法。在前人使用的CIR特征参量基础上提出了一种新型特征参量,利用Relief算法讨论了特征参量与分类标签的相关性,利用MIFS算法分析了特征参量间的冗余性,得到新特征子集,最后分析特征参量之间的相关性获得各特征参量的权重,得到WKNN快速分类算法。
本文讨论了WKNN快速分类算法的训练数据集数量和最优K值。并为了验证本算法的有效性与适用性,利用该算法在不同环境下开展了实验研究和结果分析。实验结果表明,本文的NLOS识别算法在不同环境下仍达到95%,平均单次识别耗时0.024 s,具有较高实时性和环境适用性,保证了复杂室内环境下较高的识别精度。
猜你喜欢
电子制作(2017年23期)2017-02-02 07:17:06
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
西北工业大学学报(2015年4期)2016-01-19 03:31:47
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:44
物理实验(2015年9期)2015-02-28 17:36:51
电子设计工程(2015年8期)2015-02-27 12:05:33
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:32
声学技术(2014年2期)2014-06-21 06:59:14
振动工程学报(2014年4期)2014-03-01 01:15:41
现代防御技术(2014年6期)2014-02-28 18:26:23
