
基于Tri-Training的制冷系统半监督故障诊断
2022-08-18 03:25:52任正雄崔晓钰陆海龙张运乾
制冷学报 2022年4期
任正雄 韩 华 崔晓钰 陆海龙, 张运乾
(1 上海理工大学能源与动力工程学院 上海 200093;2 重庆美的通用制冷设备有限公司 重庆 401336)
制冷系统一旦发生故障,安全性、经济性将急剧下降。目前我国居民建筑及商用建筑空调能耗达总能耗的20%~50%,因此必须做好故障预防工作,延长制冷系统使用寿命[1]。得益于计算机科学和人工智能的发展,基于数据驱动的方法被广泛应用于制冷系统故障诊断中并已取得丰富成果[2-4],该方法既无需构建精确的物理模型也不依赖于丰富的专家知识,但训练故障诊断模型需要大量的有标签数据。此处“标签”是指数据对应的输出,即机组的运行状态,正常运行或故障类别。实际中冷水机组采集的大量运行数据一般为未知运行状态的无标签数据,以往的故障诊断方法无法直接利用,而有标签数据通常需要人工标定,耗时耗力且相当有限,导致大量无标签数据中的信息无法利用[5],影响了故障诊断技术在制冷领域的推广和应用。同时,无标签数据虽未直接包含标记信息,但它们与有标签数据是从相同的制冷设备采样,数据源独立且可能同分布,其中包含的数据分布信息对建立模型大有裨益[6]。如何利用大量的无标签数据改善制冷系统故障诊断性能,是目前的研究热点之一。
半监督学习(semi-supervised learning,SSL)旨在解决数据的标签问题,无需依赖外界交互、自动地利用无标签数据辅助少量有标签数据进行学习[6]。故障诊断领域常用的半监督学习方法为协同训练法[7],可以从一个数据集的全部特征中选出多个不同的特征集,作为样本的描述,每个特征集被称为数据的一个“视图”。协同训练是基于不同特征集的多视图数据学习方法[8],需要在两个充分冗余的视图上分别训练分类器,根据两者之间的分歧利用无标签数据。
目前,制冷空调领域的半监督学习方法研究较少[9-11],制冷系统采集到的海量数据中蕴含了丰富多变的工况状态信息,系统内部非线性、耦合性、部分负荷性的复杂运行状态、故障等均会对设备运行状态产生影响。同时,考虑到制冷设备的经济性,现场运行机组的传感器通常远不及实验室多,采集数据很难分成多个充分且条件独立的视图。因此,本文对协同训练的改进模型Tri-Training[12]进行研究,该模型无需多个充分冗余的视图,通过单视图学习训练3个基分类器,并基于分歧给无标签数据贴上伪标签,实现对无标签数据的挖掘[13-15]。将支持向量机(support vector machine,SVM)[16]、K近邻学习(k-nearest neighbour, KNN)[17]、随机森林(random forest, RF)[18]作为基分类器,建立基于Tri-Training的制冷系统半监督故障诊断模型,研究大量未知类别无标签数据的利用方法,挖掘无标签数据所含信息,改善制冷系统故障诊断性能,并对该模型故障诊断性能的主要影响因素展开分析。
1 Tri-Training算法原理
Tri-Training[12]的基本思想如图1所示。首先,通过有放回采样,处理类别已知的有标记数据集L,训练得到3个有差异的基分类器hi(i=1,2,3);其次,标记类别未知的无标签数据集U中的数据x,若其中两个基分类器对x的预测结果一致,即pj(x)=pk(x)(j,k≠i),则认为该预测结果为x的伪标签pi(x)并将其加入hi的训练集中,如此形成hi的新训练集Li←Li∪{(x,pi(x))}。类似地,另外两个基分类器的训练集也分别扩充,然后3个分类器继续训练,如此重复迭代直至hi均无变化。
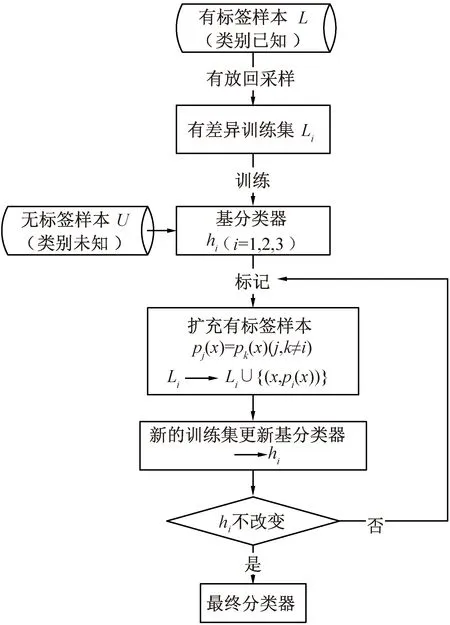
图1 Tri-Training算法基本原理
在训练过程中,若hj和hk对x的预测正确,则将伪标签数据补充至hi,进入下一步训练;否则,将获得带有噪声标签的数据,进而会对最终结果造成影响。为减少标记过程中产生的噪声数据,该算法基于D. Angluin等[19]的理论结果,根据分类噪声率和每轮训练分类的错误率决定伪标记数据是否可以用于更新分类器[12]。
2 基于Tri-Training的制冷系统半监督故障诊断
制冷系统在运行过程中,随着冷热负荷的变化,设备的运行工况也在时刻发生改变,以往的故障诊断研究仅可针对少量已知运行状态的有标签数据训练故障诊断模型,导致大量包含丰富状态信息的无标签数据信息闲置,无法利用所有数据中的完全信息构建故障诊断模型。本研究在分析Tri-Training原理的基础上,建立基于Tri-Training的制冷系统半监督故障模型。
2.1 故障诊断过程
基于Tri-Training建立的制冷系统故障诊断模型工作流程如图2所示,图中不同颜色的点代表不同的类别,灰色代表未知类别。步骤如下:
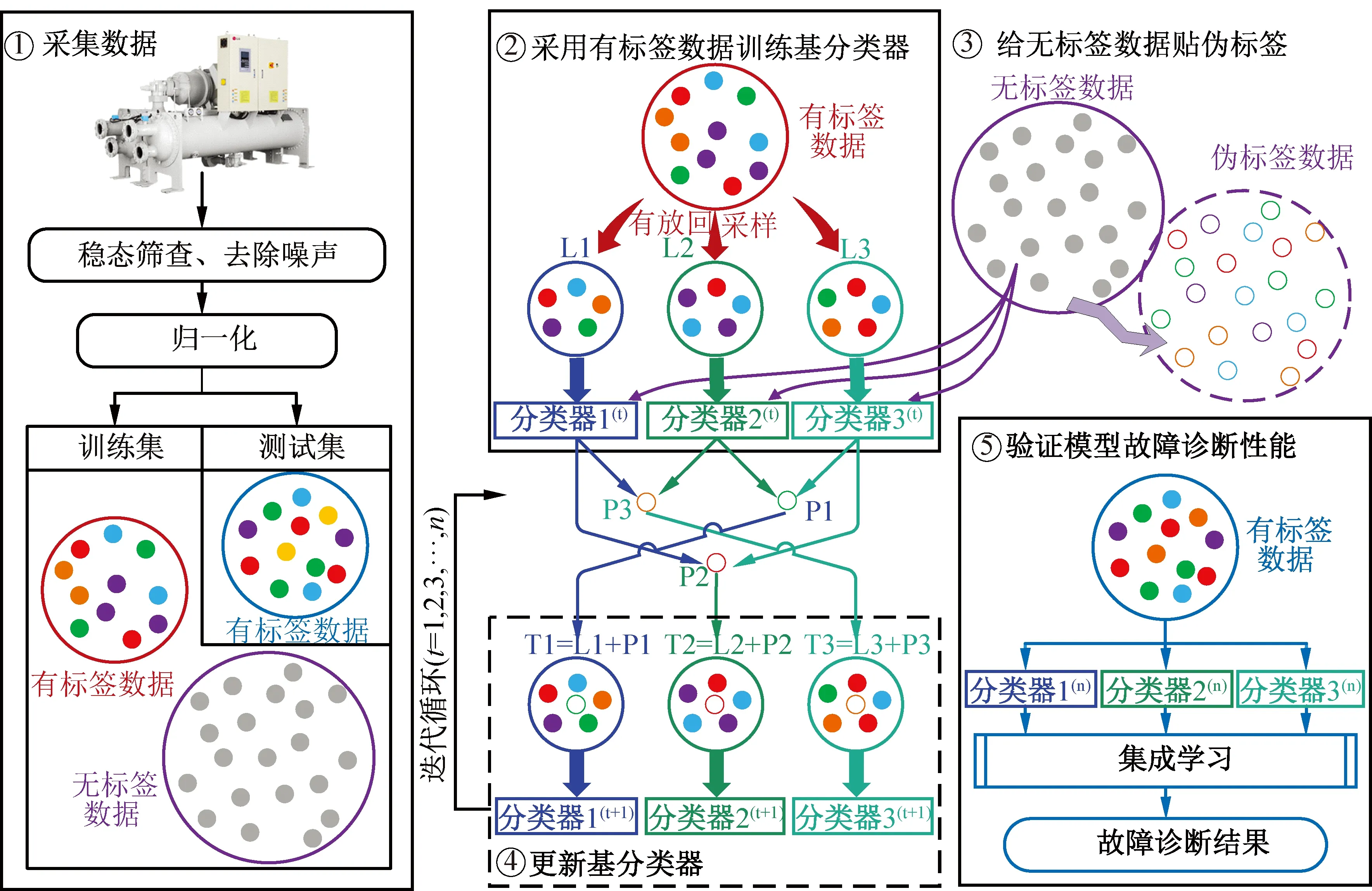
图2 基于Tri-Training的制冷系统半监督故障诊断流程
1)数据预处理。将通过制冷系统故障模拟实验采集到的实验数据进行稳态筛查并去除噪声,在标准化处理后随机分为训练集和测试集,并设置训练集中包含大量无标签数据。
2)训练基分类器。通过有放回采样将有标签数据随机分为3个数量相同的子训练集L1、L2和L3,并分别训练3个基分类器。
3)无标签数据贴标签。采用3个基分类器对无标签数据进行预测,当两个基分类器所贴标签一致时,该数据被认为具有较高的置信度,作为新的有标签数据(伪标签数据P1、P2和P3)扩充至第3个基分类器的训练集中(T1、T2和T3);当两个基分类器所贴标签不一致时,该数据重新放回无标签数据集。
4)更新基分类器。综合有标签数据和伪标签数据重新训练基分类器,并重复步骤3进行迭代训练,直至基分类器不发生改变。
5)故障检测与诊断。集成循环结束后的3个最终基分类器进行故障检测与诊断,通过投票获得的诊断结果。
2.2 制冷系统故障数据来源与预处理
本文采用ASHRAE-1043RP[20]故障模拟实验数据对故障诊断模型进行分析,该实验对象为1台316 kW的离心式冷水机组,制冷剂为R134a,冷凝器和蒸发器均为壳管式换热器。诊断类别及缩略词如表1所示。实验过程中,数据采集间隔时间为10 s,共测试27个工况,特征参数为64个,包括48个传感器直接测量参数和16个计算参数。此外,考虑到故障的严重程度,将故障分为4种程度,本文采用的研究数据将4种严重程度混合。
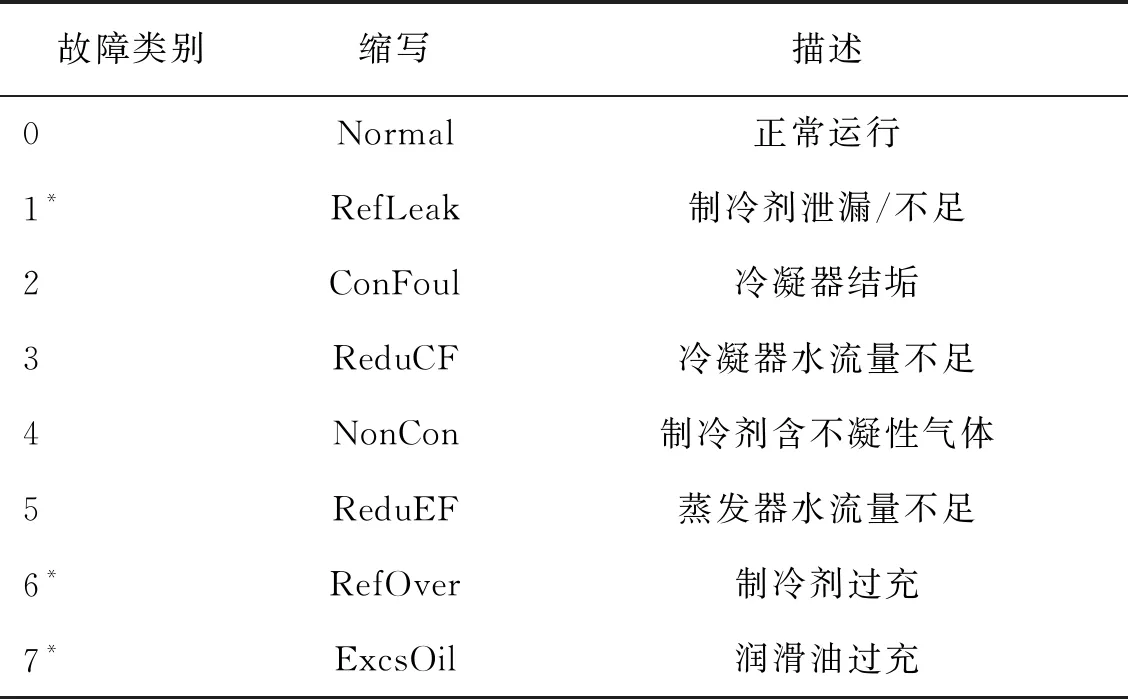
表1 制冷系统正常运行及7类典型故障
为模拟制冷机组有标签数据少且无标签数据多的情况,随机选取12 000组数据,去掉其中6 000组数据的标签作为无标签数据,剩余6 000组有标签数据中3 000组作为测试集,剩下的3 000组与6 000组无标签数据组合作为训练集。研究中,有标签数据、无标签数据及测试数据均为随机采样得到,不同数据集、不同机组运行状态数据的工况存在差异,一定程度上可以适应实际中工况不同所致的情况,但实际运行中的性能有待实际数据进一步验证。
3 实验验证及结果分析
3.1 基于Tri-Training的制冷系统半监督故障诊断分析
SVM、KNN、RF三种有监督学习广泛应用于制冷系统故障诊断相关研究。采用SVM、KNN、RF作为基分类器,建立基于Tri-Training的制冷系统故障诊断模型。采用正确率、查准率、查全率和F-measure值来评价各模型的诊断性能,已关注的类别为正类,其他类别为负类,根据分类器在测试数据集上的诊断正确与否,会出现如下4种情况:TP表示将正类诊断为正类的样本数;FN表示将正类诊断为负类的样本数;FP表示将负类诊断为正类的样本数;TN表示将负类诊断为负类的样本数,Precision表示查准率,Recall表示查全率,各评价指标的计算式如表2所示。

表2 各评价指标计算式
图3所示为各模型的制冷系统故障诊断结果,由图3可知,挖掘无标签数据信息后的Tri-Training故障诊断正确率相比SVM和KNN均有较大提升,较SVM提高22.00%,但相比RF反而降低,原因可能为RF是多个决策树(decision tree,DT)[18]的集成,DT数量和特征选择的随机性导致模型对故障的识别具有随机性,而且数据伪标签的获得需要综合考虑3个基分类器。图中SVM、KNN与RF的诊断性能相差较大,SVM(72.00%)和RF(98.13%)的正确率差值为26.13%,当采用性能差异过大的模型作为基分类器时会影响Tri-Training的贴标签过程,降低伪标签数据的置信度。
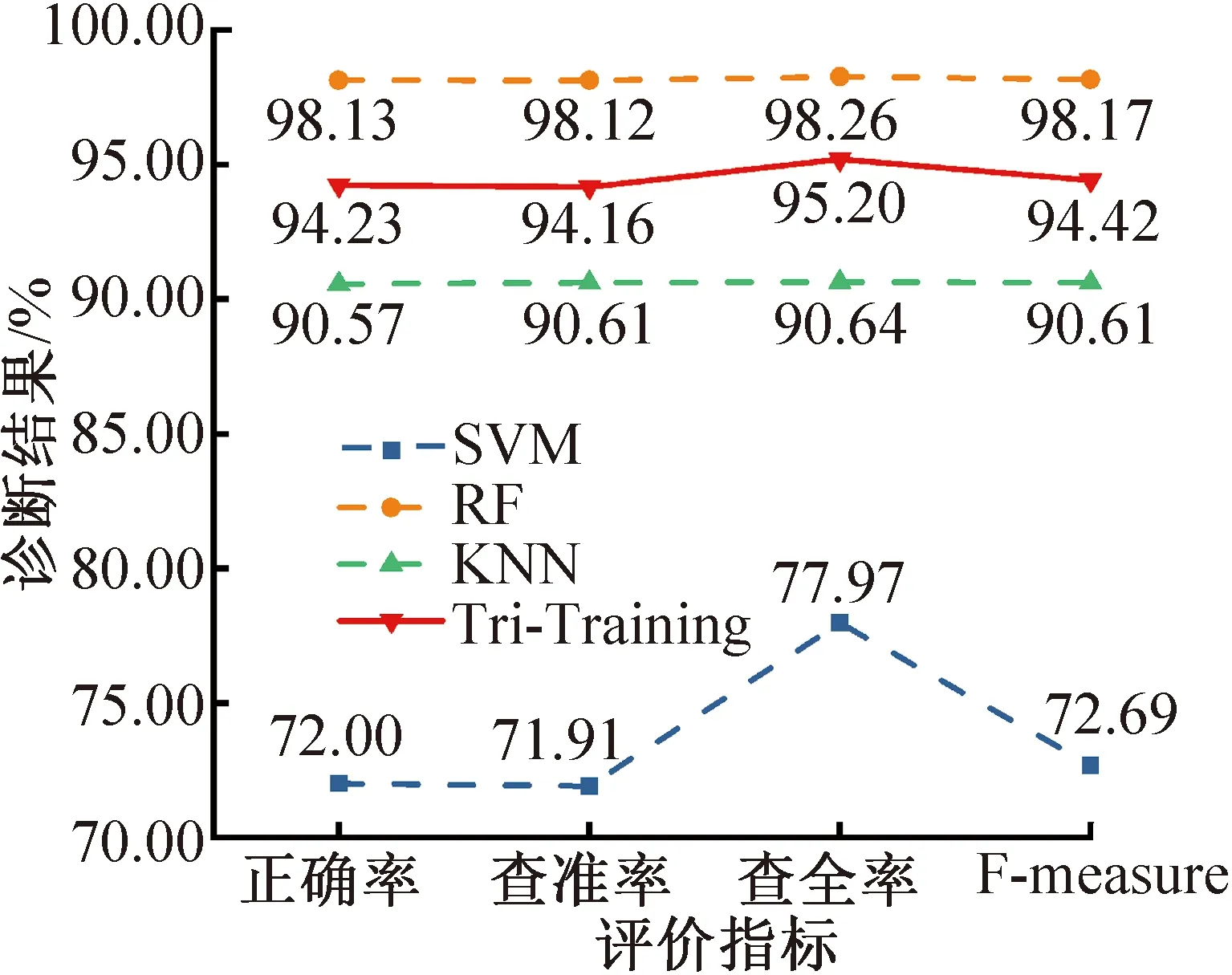
图3 各模型的制冷系统故障诊断结果
3.2 基分类器优化
Zhou Zhihua等[12]强调,Tri-Training采用的基分类器不可以是弱分类器,弱分类器会降低贴标签过程的可靠性。本节考虑基分类器性能对制冷系统故障诊断的影响,优化基分类器模型,讨论优化后Tri-Training模型的故障诊断性能。
采用十折交叉验证[21]及网格搜索方法进行参数寻优,并将最优参数代入模型中对测试集数据进行诊断。惩罚参数C和核参数γ是SVM的两个重要参数;KNN的性能主要受所选最近点的个数k和距离计算参数p的影响;在DT的数量n和最佳特征个数m是RF模型的主要参数。优化上述参数,结果如表3所示。由表3可知,各模型优化后的诊断正确率均提升,其中SVM的提升尤为显著(26.63%),KNN次之(7.66%),RF提升仅为1.14%。3种模型优化后的诊断性能差异较小,正确率均约为99%。
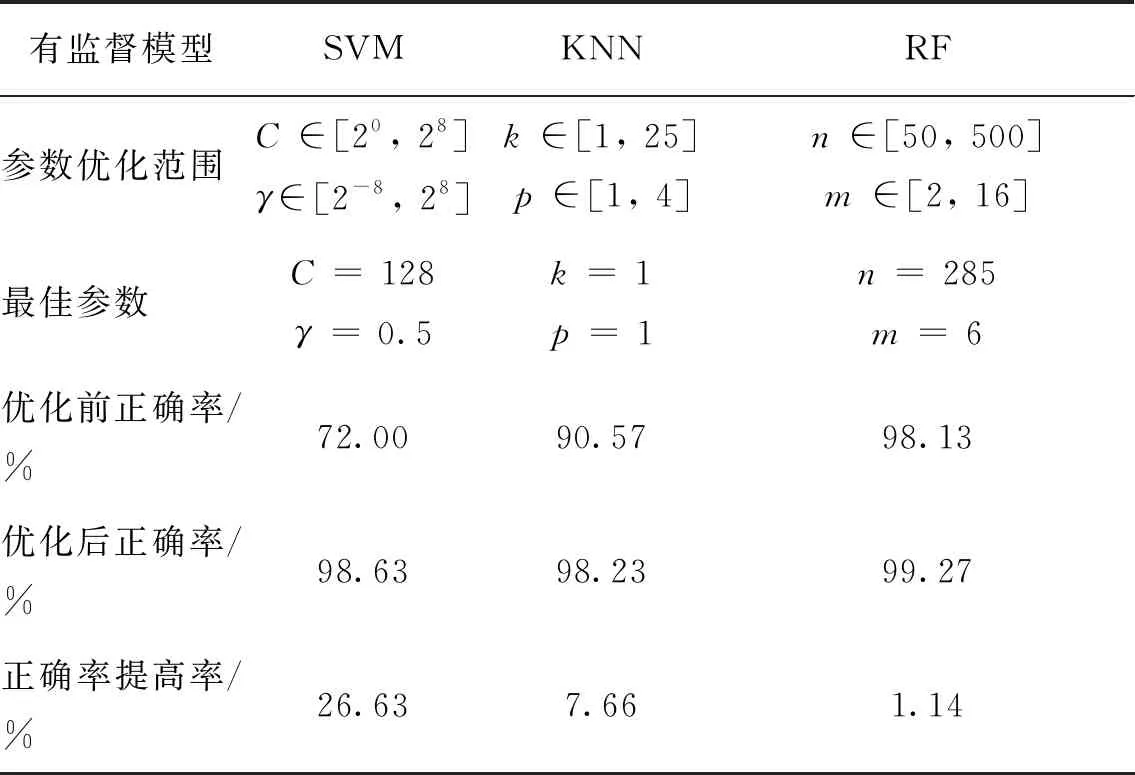
表3 有监督模型参数优化结果
将参数优化后的SVM、KNN、RF作为基分类器重新建立Tri-Training模型,采用相同制冷系统数据集进行验证,故障诊断结果如图4所示。由图4可知,与3.1节中未优化的模型相比:1)有优化Tri-Training模型的诊断正确率提升5.20%(99.43%比94.23%),更高诊断性能的基分类器可以建立具有更高诊断性能的故障诊断模型;2)有优化Tri-Training模型的各项评价指标均高于有监督学习模型,证明基分类器的差异性会影响模型总体性能,较小的差异可减少伪标签数据的噪声。

图4 有监督学习模型与Tri-Training的诊断性能
此外,由于优化后的RF模型与Tri-Training故障诊断性能差异不明显,采用DT模型代替RF模型,将参数优化后的SVM、KNN、DT作为基分类器建立Tri-Training*模型。图5所示为故障诊断结果,由图5可知,虽然DT的诊断正确率低于RF,但Tri-Training*的故障诊断性能与Tri-Training接近且高于半监督学习模型,再次证明本研究提出方法的有效性。同时,Tri-Training*的故障诊断性能优于RF模型,表明采用RF作为半监督模型的基分类器不会影响模型的定性分析。
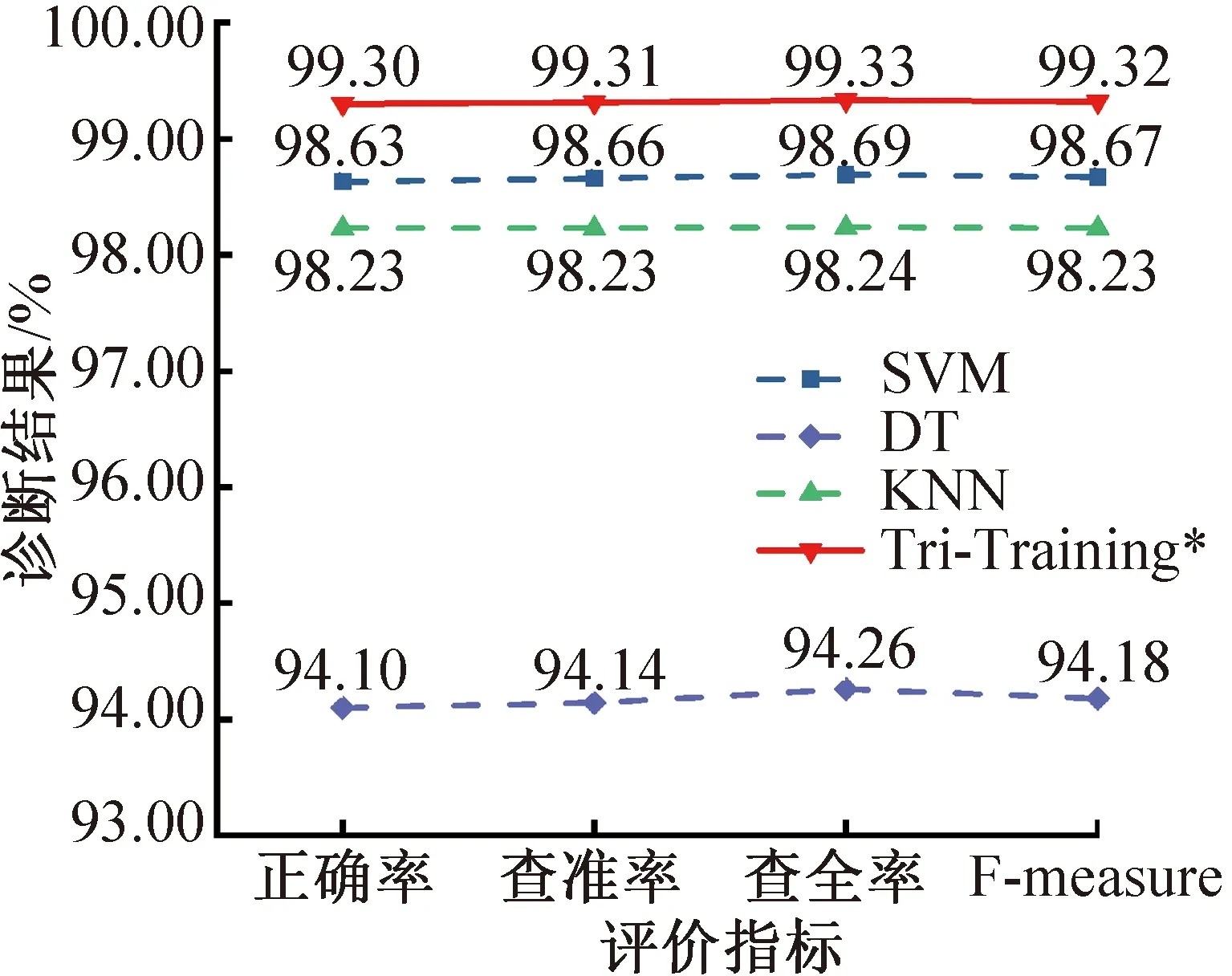
图5 有监督学习模型与Tri-Training*的诊断性能
图6所示为无优化Tri-Training模型和有优化Tri-Training模型分别对具体故障类别的诊断性能。由图6可知,正常状态的正确率由90.99%增至98.63%,制冷剂泄漏/不足(故障1*)的诊断正确率由77.18%增至97.83%。有优化Tri-Training模型可将各类别的诊断正确率均匀维持在99.00%,基分类器诊断性能越高,训练得到的制冷系统半监督故障诊断模型越能挖掘出无标签数据深层次的可用信息。

图6 无优化与有优化Tri-Training性能对比
3.3 不同基分类器对制冷系统半监督故障诊断的影响
由上述研究结果可知,3个基分类器的差异会影响模型的诊断性能,本节采用有优化SVM、KNN、RF构建不同基分类器的Tri-Training模型,讨论基分类器对模型性能的影响,不同组合方式及诊断结果如图7所示。
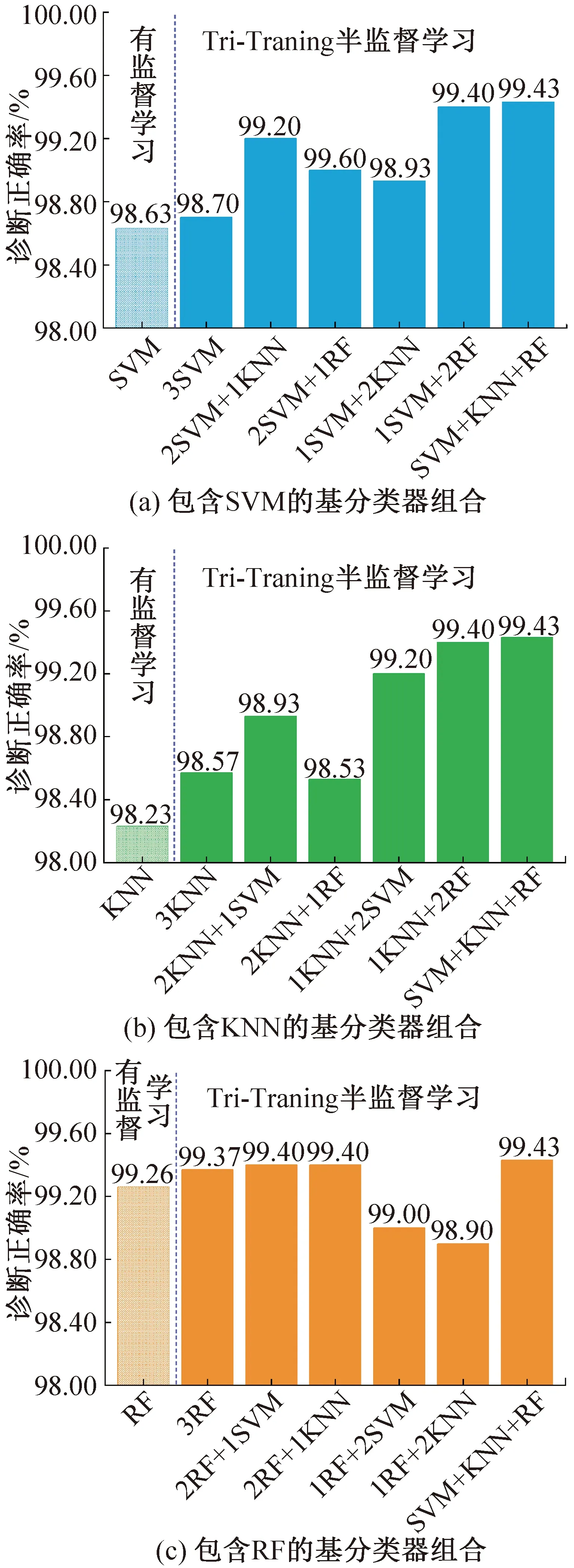
图7 不同基分类器组合诊断结果
相比有监督学习,Tri-Training在大部分情况下可以有效改善分类器的诊断正确率。基于本研究数据,所有组合方式中SVM+KNN+RF 的诊断正确率最高(99.43%),当3个基分类器采用相同学习器时(3SVM、3KNN、3RF),诊断正确率较监督学习(SVM、KNN、RF)分别只提升0.07%、0.34%、0.11%,低于其他组合方式,说明基分类器的多样性对模型的影响较大。
在基分类器包含SVM的Tri-Training组合中,1SVM +2RF诊断性能较佳,诊断正确率比SVM提高0.8%;在包含KNN的组合中,1KNN+2RF诊断性能较佳,诊断正确率比KNN模型提高1.2%。RF比SVM、KNN学习性能更高,正确率达到99.26%,所以包含RF不同组合的诊断正确率普遍较高,体现出强学习器对Tri-Training的影响。其中一个RF的组合方式(2SVM+1RF、2KNN+1RF)正确率均低于其他组合,甚至低于RF的有监督学习,说明较低性能的SVM、KNN会对贴标签及投票过程产生负影响;1SVM+2RF、1KNN+2RF和SVM+KNN+RF的诊断性能较好,正确率高于3RF,由此可知,Tri-Training故障诊断基分类器的选择,要综合考虑基分类器自身的诊断性能与基分类器之间的多样性。
3.4 各类故障诊断性能分析
由于1SVM+2RF、1KNN+2RF、SVM+KNN+RF三种组合的Tri-Training诊断结果较为优异,因此进一步与有监督学习模型(SVM、KNN、RF)进行对比,研究Tri-Training对不同故障类别的诊断性能。
故障诊断正确率如图8所示,3种Tri-Training模型对各类故障的诊断趋势相似,对正常运行的数据诊断效果较差,局部故障较系统级故障诊断正确率更高,系统级故障中,对制冷剂过充(故障6*)的诊断正确率达到100%,制冷剂泄漏/不足(故障1*)和润滑油过充(故障7*)较难识别。Tri-Training模型对3种系统级故障的诊断性能提升明显,均优于有监督学习模型,1SVM+ 2RF、1KNN+2RF对故障1*的诊断正确率比SVM高3.40%,对故障6*的诊断正确率达到100%,比KNN高3.90%,3种模型对故障7*的诊断结果相同,比KNN高1.73%,比SVM和RF高0.86%。Tri-Training模型对冷凝器结垢(故障2)、冷凝器水流量不足(故障3)和蒸发器水流量不足(故障5)3类局部故障的诊断正确率均为100%,制冷剂含不凝性气体(故障4)的诊断正确率为99.69%,比KNN高1.24%。此外,Tri-Training对正常数据的诊断效果显著低于故障数据,且诊断正确率相比3个基分类器无显著提升。
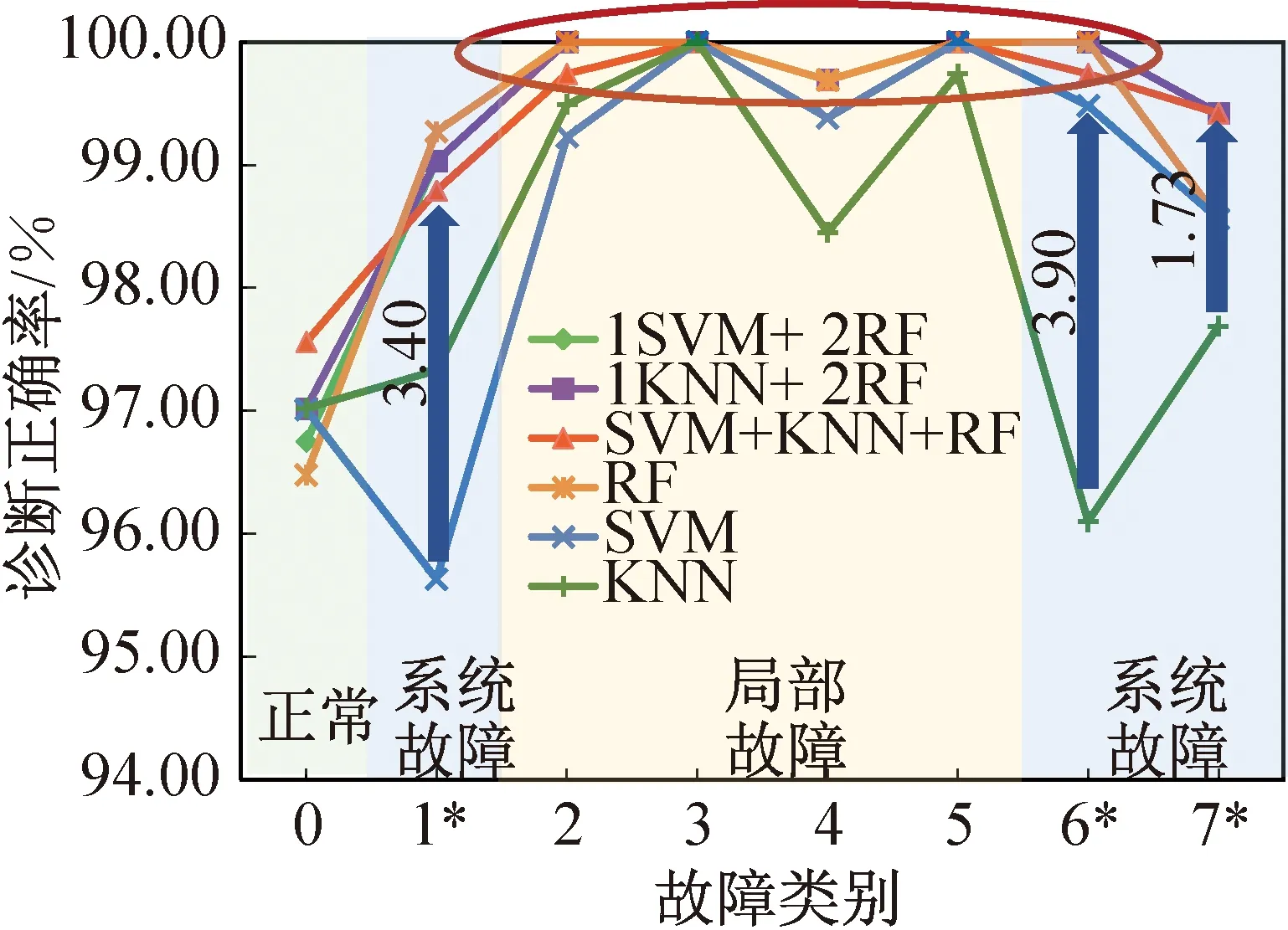
图8 对各类故障的诊断正确率
图9所示为各诊断模型诊断结果的混淆矩阵,并据此计算虚警率(正常数据误报为故障的比例)、漏报率(故障数据误报为正常的比例)、误报率(故障A误报为故障B的比例),计算结果如表4所示。制冷系统正常运行是常态,观察正常类别的诊断情况有助于分析模型的故障检测性能。Tri-Training将正常运行虚警为制冷剂泄漏/不足和润滑油过充的系统级故障(黄色部分),SVM+KNN+RF的虚警率最低(2.44%),相比诊断性能较好的RF显著降低,但总体变化较小。有监督模型的漏报情况(绿色部分)比Tri-Training复杂,SVM的漏报数据有23个,KNN漏报数据有16个,而采用半监督学习的Tri-Training后,漏报率降低显著,1KNN +2RF的漏报数据降至1个。误报最多的是KNN,为26个(0.99%),误报最少的是1SVM +2RF,为2个(0.08%)。此外,其他模型误报率相差较小,Tri-Training均易误报为制冷剂过充故障。综上所述,Tri-Training对各类故障的诊断正确率高,且虚警率、漏报率、误报率均降低,漏报情况显著改善。
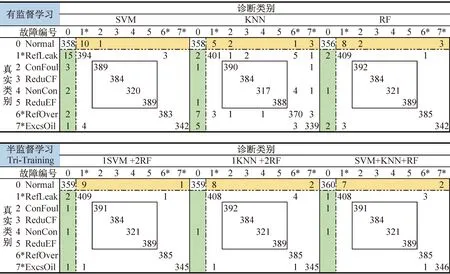
图9 各模型诊断结果混淆矩阵
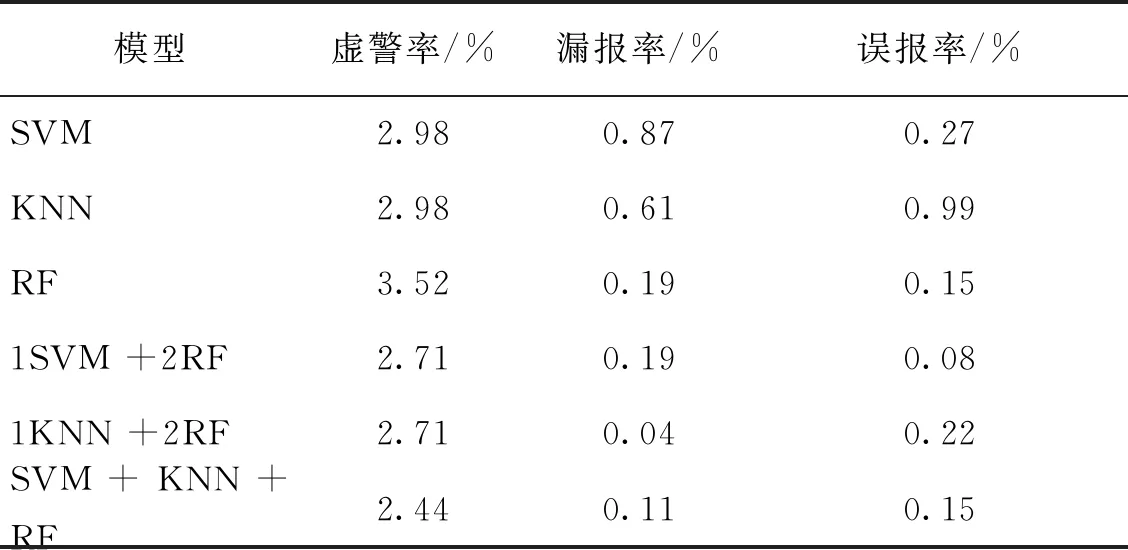
表4 各模型虚警率、漏报率与误报率
4 结论
制冷系统大量运行数据为未知类别的无标签数据,已知类别的有标签数据(特别是有标签故障数据)难以获得,本文提出基于Tri-Training的制冷系统半监督故障诊断模型,有效利用无标签数据所含信息,改善故障诊断性能,并采用ASHRAE数据进行验证。得到结论如下:
1)基于Tri-Training的制冷系统半监督故障诊断模型可以有效利用制冷系统中大量的无标签数据进行半监督学习,挖掘出无标签数据中包含的丰富制冷系统状态信息,采用这些信息辅助有标签数据建立的半监督故障诊断模型对冷水机组7类典型故障和1类正常运行的诊断正确率达到99.43%,比传统有监督学习模型(SVM、KNN、RF)的正确率、查准率、查全率和F-measure值均有提升,对较难识别的系统级故障也可以得到较好的诊断结果。
2)3个基分类器故障诊断性能的差异性会影响故障诊断模型的总体性能,3个基分类器之间较小的性能差异可以减少伪标签数据的噪声。无优化的SVM(72.00%)+KNN(90.57%)+RF(98.13%)模型基分类器性能失衡,影响Tri-Training的贴标签过程,降低伪标签数据的置信度,导致模型的诊断性能低于RF(有监督学习)。有优化的SVM(98.63%)+KNN(98.23%)+RF(99.27%)模型基分类器性能差异小,模型诊断性能均高于有监督模型。
3)基分类器诊断性能越高,训练得到的故障诊断模型越能挖掘出制冷系统大量无标签数据的可用信息。对基分类器模型进行优化后故障诊断性能提高,分别采用优化前后基分类器建立故障诊断模型,有优化Tri-Training较无优化Tri-Training诊断正确率提升5.20%。
4)3个基分类器类别的多样性有利于提高伪标签样本的置信度。采用3个相同基分类器的3SVM、3KNN、3RF较有监督学习模型SVM、KNN、RF诊断正确率分别仅提高0.07%、0.34%、0.11%,均低于其他组合方式的故障诊断模型。而基分类器多样的SVM+KNN+RF为故障诊断性能最优组合。
5)基于Tri-Training的制冷系统半监督故障诊断模型对系统级故障的诊断正确率较SVM、KNN、RF可提升1.73%~3.90%,1KNN+2RF、1SVM+2RF对制冷剂过量故障的诊断结果可达到100%。同时,模型对正常运行的识别率低于故障数据,利用无标签数据对正常运行的识别率无明显改善。从对各故障的混淆矩阵中可以得出相同结论,利用无标签信息的半监督模型可有效降低漏报率和误报率,但虚警率降低较小。
猜你喜欢
煤气与热力(2021年10期)2021-12-02 05:11:38
中华养生保健(2020年7期)2020-11-16 01:14:26
电子测试(2018年1期)2018-04-18 11:52:35
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
故事会(2016年15期)2016-08-23 13:48:41
汽车维护与修理(2016年3期)2016-02-28 13:16:54
电测与仪表(2014年15期)2014-04-04 12:05:20
