
基于注意力机制和Parallel DenseNet 的文本情感分析
2022-08-18 01:56陈大文
无线互联科技 2022年11期
陈大文
(江苏金盾检测技术股份有限公司,江苏 南京 210000)
0 引言
随着计算机与信息技术的发展,人们已经越来越离不开网络。 随之,信息出现了爆炸式的增长。 据统计,截至2020 年4 月,中国网民使用网络人数已经达9.04 亿,互联网普及率已经达64.5%[1]。 网络已经成为人们现代生活中的重要组成部分。 因此,网民可以在微博等社交媒体公共平台上发布各种自己的情感看法和评论。 利用自然语言处理技术,在舆情分析方面,对热点话题和评论进行分析,理解人们所表达的情感色彩,对政府了解民意、预防危害事件有一定的积极性作用;在情感对话方面,对人话语进行分析,可以创造情感机器人抚慰人的心灵、陪伴人类;在市场竞争方面,对物品的评论进行分析,可以帮助商家提升物品质量,同时也可以帮助顾客对该物品下是否购买的决定。
文本情感分析又称意见挖掘,是指对带有情感色彩的主观性文本进行分析,挖掘其中蕴含的情感倾向,对情感态度进行划分[2]。 文本情感分析组成部分,如图1 所示。 文本情感分析主要由原始数据获取、特征提取、分类器和情感类别输出4 个部分组成。 其中,特征提取和分类器是文本情感分析结果好坏的重要部分。
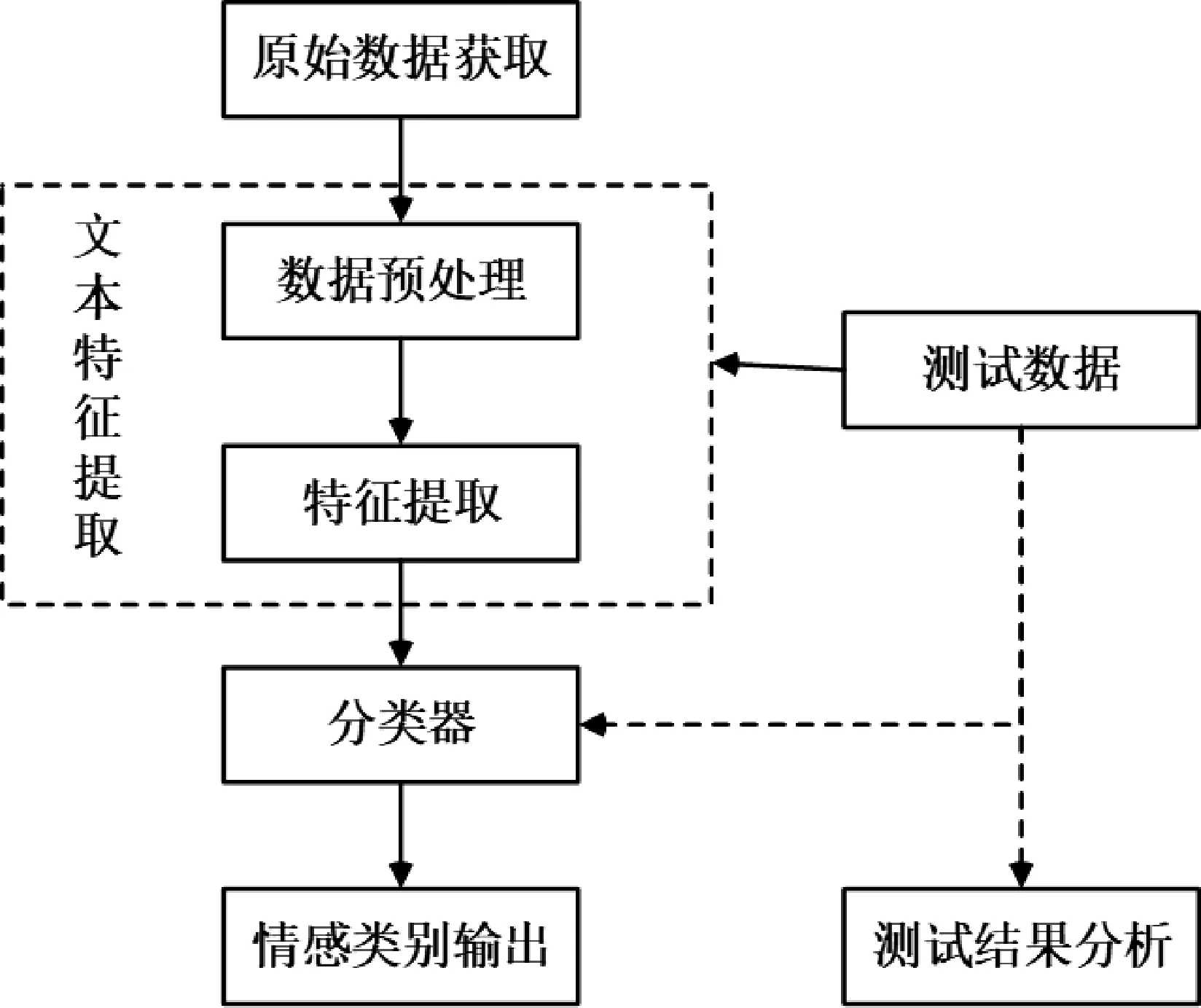
图1 文本情感分析组成部分
因此,从分类器来看,目前主要有基于词典、基于传统机器学习和基于深度学习3 种文本情感分析方法。 基于词典的文本情感分析方法是指根据带有情感信息的词语,对文本情感分数进行计数和加权,以此获得文本情感倾向。 基于传统机器学习的文本情感分析方法不依赖于词典,具有自我学习文本情感特征的能力[3]。 基于深度学习的文本情感分析方法可以学习更加高级、难以描述的文本情感特征,即使是非常抽象、难以人工表述的特征,也可以学习提取,以此作为文本的重要特征。
近年来,较流行的文本情感分析模型使用卷积神经网络(CNN)[4]和循环神经网络(RNN)[5]。 虽然,这类模型优先考虑位置和顺序信息,能较好地学习句子中的局部特征,以此来进行分类但是忽略了全局特征。2021 年,Yan 等[6]通过将Parallel DenseNet 融入CNN网络中,进行短文本情感分析,可以较好地提取局部特征和全局特征,得到更好的短文本情感分析效果,但是对于该模型来说全局特征和局部特征对情感分析贡献度是一样的。 这显然存在一定的问题。
本文基于上文Parallel DenseNet 提出了一种融合注意力机制和Parallel DenseNet 的ATT-Parallel Dense-Net 文本情感分析模型[7]。 该模型不仅可以同时提取文本的局部特征和全局特征,还可以为局部特征和全局特征设置学习不同的权值,以期待得到最好的文本情感分析效果。
2 相关工作
根据特征提取和分类器的不同方法,文本情感分析主要有基于情感词典的情感分析方法、基于传统机器学习的情感分析方法和基于深度学习的情感分析方法,如图2 所示。
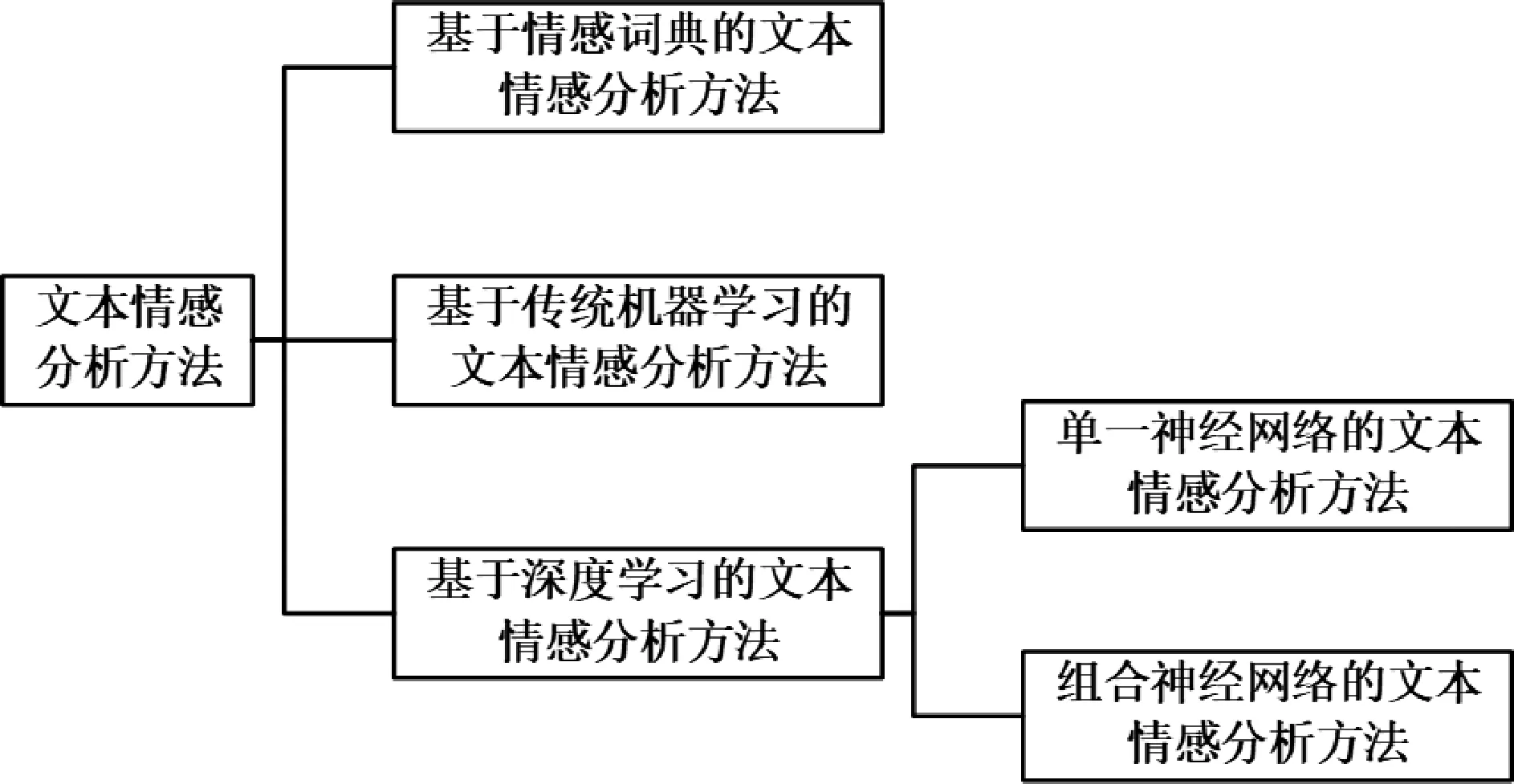
图2 文本情感分析方法分类
基于情感词典的情感分析方法是指根据带有情感信息的词语,对文本情感分数进行计数和加权,以此获得文本情感倾向。 现有的情感词典都是人工构造的,需要消耗大量的人力与物力。 例如,SentiWordNet[7]情感词典是一部国外最早的情感词典,它将含义一致的词语放在一起,并且赋予了代表正面或者负面的情感极性分数。 当一句话出现时,就可以根据每个句子中每个词的情感极性分数进行累加得到最终的每个句子的情感极性分数,而这些分数就代表了每个用户的情感倾向。 与英文情感词典不同,中文情感词典主要有NTUSD[8]、How Net 和情感词汇本体库[9]等,这些情感词典中分别包含不同数量的褒义词和贬义词。 在早期得到了广泛的应用,然而因为人工量大、难以维护,所以逐步退出了历史舞台。
基于传统机器学习的文本情感分析方法是指不依赖于词典,具有自我学习文本情感特征能力的方法。该方法是一种通过给定的数据训练模型,通过模型预测结果的一种学习方法。 该方法研究至今,已经取得了诸多有效的成果,分为有监督模型、半监督模型与无监督模型。 有监督模型是指训练带有情感极性的文本样本,得到模型,后根据模型预测无情感极性的样本。该类方法对样本集依赖度大。 当样本集足够全且多时,效果较好。 当样本集不全且少式时,效果一般。 半监督模型是指在有监督模型的基础上,模型具有训练提取未带情感极性文本样本能力的模型。 该模型从一定程度上可以解决带有极性数据集稀缺的问题。 无监督模型是指模型可以自动学习未带极性数据集特征判别其所属情感倾向。 通常而言是根据提取特征之间的距离而判断的,在情感分析中所用较少。 然而,因为其所提取的特征较浅且不全,随着深度学习的出现,该类方法得到了一定的冲击。
基于深度学习的文本情感分析方法是指可以学习更加高级、难以描述的文本情感特征。 即使是非常抽象、难以人工表述的特征,它也可以学习提取,以此作为文本的重要特征的模型。 该类模型是从传统机器学习方法引申而来的,它由两种类型构成。 一是单一神经网络构成的模型,二是组合神经网络构成的模型。而单一神经网络构成的模型一般以CNN 与RNN 两类为主。 Kim[4]提出的TextCNN 就是以CNN 构成的用于文本情感分析的方法。 该方法通过一维卷积来获取句子中n-gram 的特征表示,其对文本浅层特征的抽取能力很强。 然而,该方法却无法提取远距离特征和全局特征。 Liu[5]提出的适用于情感分析的RNN 模型就是以RNN 构成的用于文本情感分析的方法。 该方法通过RNN 模型来提取文本特征,其对远距离特征提取能力强,然而却无法提取浅层特征与全局特征。 因此,后来的研究者普遍将RNN 与CNN 相结合企图在模型中同时提取文本的浅层特征和远距离特征。 何野等[10]2021 年提出的LSTM-CNN 模型就是将LSTM 与CNN相结合在中文电子商务网站评论上获得了较好的准确率。 李俭兵等[11]2021 年提出的跳转LSTM-CNN 模型也是将LSTM 与CNN 相结合解决纯LSTM-CNN 模型训练较长短文本效率低下的问题,可以很好地获取局部特征。 郭勇等[12]2021 年提出的结合改进Bi-LSTM 和CNN 的文本情感分析模型同时获得浅层特征和长距离依赖特征,在Twitter 上获得了较好的改进。 程艳等[13]2021 年提出的融合卷积神经网络与双向GRU 的文本情感分析胶囊模型利用双向GRU 与CNN 提取特征在酒店评论数据集上获得了较好的效果。 刘道华等[14]2021 年提出的一种加权词向量的混合网络文本情感分析方法将CNN 与ATT-BiGRU 相结合,两者分别提取特征,再将其进行组合,最终分类任务,效果较好。 然而,这些方法虽能同时提取浅层特征和远距离特征,但是因为其将两种或两种以上网络进行组合,效率比较低,速度较慢且从某种程度上来说依赖数据集。 数据集若小,则效果一般。
Yan 等[6]2021 年通过将Parallel DenseNet 融入CNN 网络,进行短文本情感分析,可以较好地提取局部特征和全局特征,且速度较快,得到更好的短文本情感分析效果。 然而,对于该模型来说,全局特征和局部特征对情感分析贡献度是一样的。 事实上,对于情感分析任务来说,局部特征和全局特征贡献度是不同的,局部特征大于全局特征。
因此,本文基于上文Parallel DenseNet 提出了一种融合注意力机制和Parallel DenseNet 的ATT-Parallel DenseNet 文本情感分析模型[7]。 该模型不仅可以同时提取文本的局部特征和全局特征,还可以为局部特征和全局特征设置学习不同的权值,以期待得到最好的文本情感分析效果。
3 融合注意力机制和Parallel DenseNet 的ATTParallel DenseNet 文本情感分析模型
3.1 ATT-Parallel DenseNet 模型
为了提高文本情感分析的准确率,本文结合注意力机制和Parallel DenseNet,设计了一个新的情感分析模型ATT-Parallel DenseNet。 如图3 所示,该情感分析模型主要包括数据预处理模块、生成词向量Embedding层模块、分类器模块。 而分类器模块主要包括2 个卷积特征提取模块、Attention 层、Concatenate 层、Full connection 层和Softmax 层。
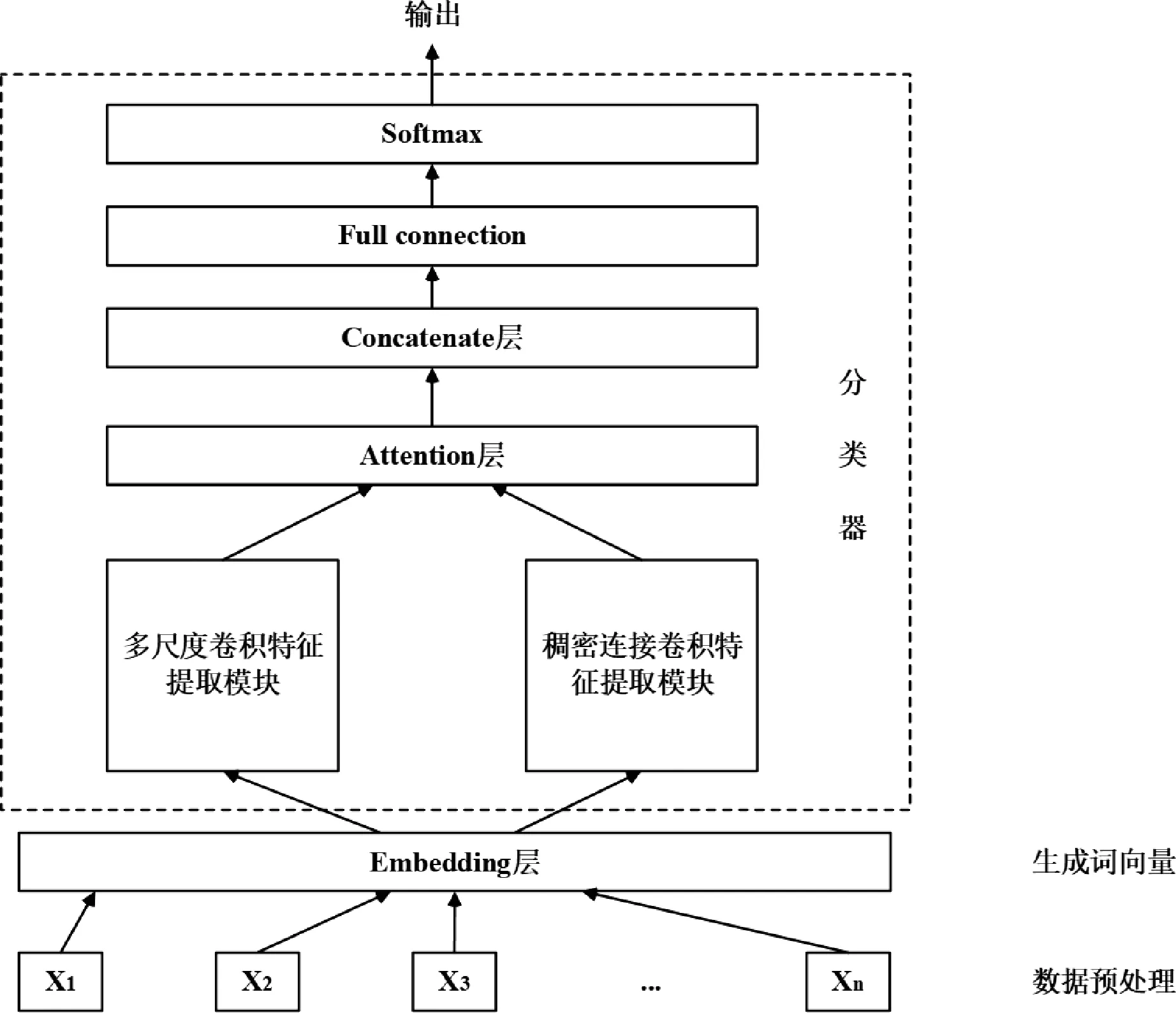
图3 ATT-Parallel DenseNet 情感分析模型
数据预处理阶段主要是因为原始的文本拥有许多停顿词和换行符或者一段英文文章大小写不一致等格式不统一混乱问题。 因此,数据预处理阶段将把停顿词和换行符这类多余的符号词语清理掉,将大小写不一致的词语换成统一的小写字符;然后将处理好的数据通过Word2Vector 进行向量化即生成词向量阶段;接着将词向量放入分类器中进行处理提取出重要特征;最后通过全连接层和Softmax 层得到分类结果。
3.2 Embedding 层
Embedding 层就是词嵌入层。 初始的文本计算机是无法理解的,只有将文本转化为词向量或者句向量,计算机和神经网络才能理解并进行处理。 本文主要使用Word2Vector 来实现词语向量化。 该模型将词语转化为300 维的词向量。 Word2Vector 的本质是将原始的稀疏词向量通过模型映射到高维空间中使得所获得的词向量既不稀疏又准确。 当表示的词向量方向和尺度都很相近时,则表示这两个词之间的词意十分接近。如图4 所示,文本最开始将每个词转化为one-hot 编码词向量即第i个词对应的词向量第i维就应该是1;然后通过Word2Vector 后得到的新词向量第j维就应该是1,而这个第j维跟前词向量对应的第i维表示的词是一致的。
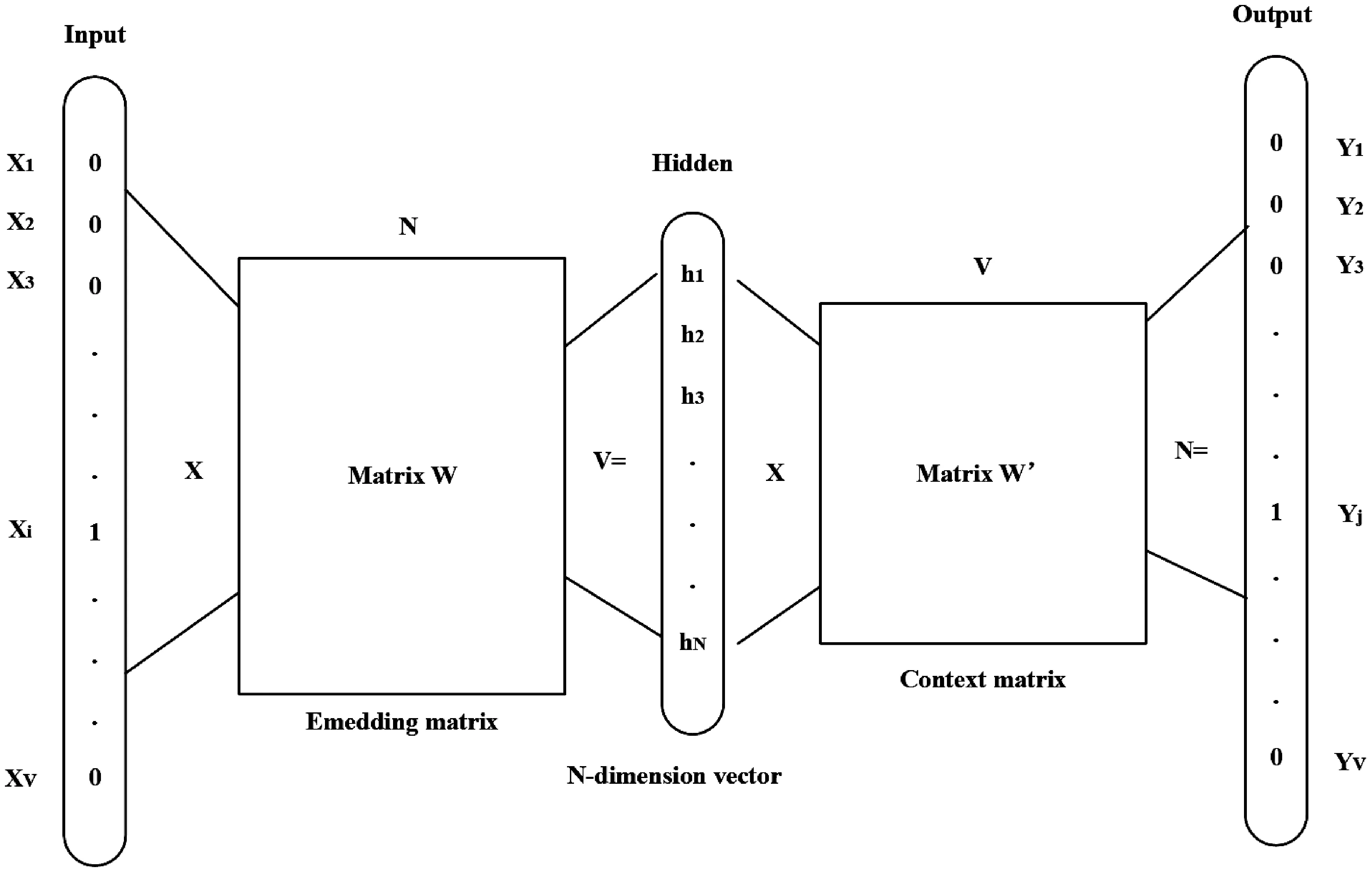
图4 Word2Vector 模型
3.3 Parallel DenseNet 模型
该模型将Embedding 层输出的词向量矩阵输入两个卷积特征提取模块,分别提取全局特征和局部特征,分别为多尺度卷积特征提取模块和稠密连接卷积特征提取模块。
3.3.1 多尺度卷积特征提取模块
首先,令xi∈Rd为文本中第i个词的d维预训练词向量,则原始输入文本可以表示为矩阵x0=[x1,x2,…,xm]m×d,然后将x0同时输入大小为5× d、4× d、3× d、2× d的卷积层进行特征提取得到y1、y2、y3、y4,接着将其输入大小为46,47,48,49 的最大池化层进行最大池化操作得到新的特征矩阵x1、x2、x3、x4。 最后,将新的特征矩阵相合并得到该多尺度卷积特征提取模块的特征矩阵x2。
3.3.2 稠密连接卷积特征提取模块
首先,令xi∈Rd为文本中第i个词的d维预训练词向量,则原始输入文本可以表示为矩阵x0=[x1,x2,…,xm]m×d;然后,将x0串行输入大小为5×d的卷积层进行特征提取,将原始输入文本矩阵、经过一次卷积变换后的特征矩阵和经过二次卷积变换后的特征矩阵相合并得到新的特征矩阵x2;最后,将新的特征矩阵输入大小为46 的最大池化层,得到该稠密连接卷积特征提取模块的特征矩阵x1。
3.4 Attention 层
注意力机制是一种类似人脑的注意力分配机制,它对重要的区域投入更多的资源,以获取更多的细节,对无用的信息则进行抑制。 其中,该部分的实现公式为:

其中,h为上文所产生的特征矩阵如X1和X2,W和b为Attention 的权重和偏置量,a是最终产生的主注意力分数。 在训练过程中,不断地更新W和b以得到最好的a。
4 实验与分析
4.1 数据预处理
为了验证本文模型的合理性和有效性,本文选取了4 个广泛使用的基准语料库并在其上进行实验,主要包括:GameMultiTweet 数据集、SemEval 数据集、SSTweet 数据集和 IMDB 电影评论数据集。 Game MultiTweet 数据集是通过搜索游戏数据等游戏主题构建的。 在这个数据集中,本文获取了12 780 条数据,这些数据被标注为三类别。 SemEval 数据集是由Twitter情绪分析任务创建的20 K 数据组成的。 在这个数据集中,本文获取了7 967 条数据,这些数据被标注为三类别。 SS-Tweet 数据集是情绪强度Twitter 数据集。 在这个数据集中,本文获取了4 242 条数据,这些数据被标注为三类别。 IMDB 电影评论数据集是电影评论的数据集。 在这个数据集中,本文获取了25 000 条数据,这些数据被标注为两类别。 首先,对数据集进行预处理,过滤掉非ASCII 字符、清洗换行符以及将大写字母转换为小写,并使用Word2Vector 初始化评论文本的词嵌入信息;然后将数据集按8 ∶1 ∶1 的比例随机分为训练集、验证集和测试集。
4.2 评价指标
本文采用准确率(ACC)、召回率(REC)和F1 作为评价指标,计算式如下:
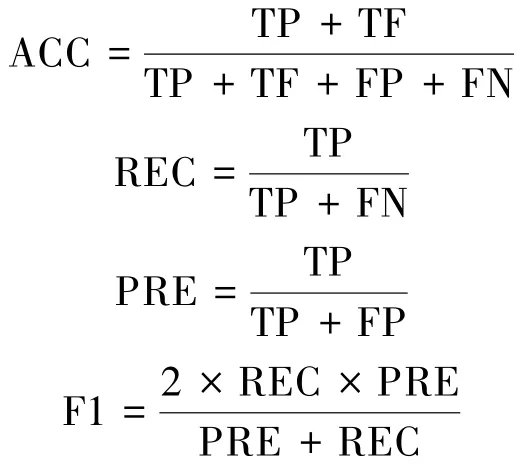
其中,TP 表示预测为正样本且分类正确的样本,TF 表示预测为负样本且分类正确的样本数,FP 表示实际为负样本但是分类错误的样本数,FN 表示实际为正样本但分类错误的样本数。
4.3 对比实验和参数设置
本实验将ATT-ParallelDenseNet 模型与以下3 种模型进行对比。
(1)文献[4]提出的TextCNN 模型。
(2)文献[15]提出的fastText 模型。
(3)文献[16]提出的BiLSTM-Attentions 模型。
本实验中的词向量维度为300,模型设置每个batch 中含128 个样本数据,完成一个epoch 需要50 次迭代。 本实验共训练4 个模型,选择Adam 为优化器,设置学习率为0.001;采用dropout 函数防止过拟合,参数设置为0.5。
4.4 实验结果分析
同样的数据采用不同的模型处理进行对比实验。将提出的模型与TextCNN 模型、fastText 模型以及BiLSTM-Attentions 模型作比较, 从分类的准确率(ACC)、召回率(REC)和F1 这3 方面评估其可行性和有效性。 表1 展现了本文的模型与基准模型结果。 从结果上可以看出,本文的模型可以获得较好的准确率。
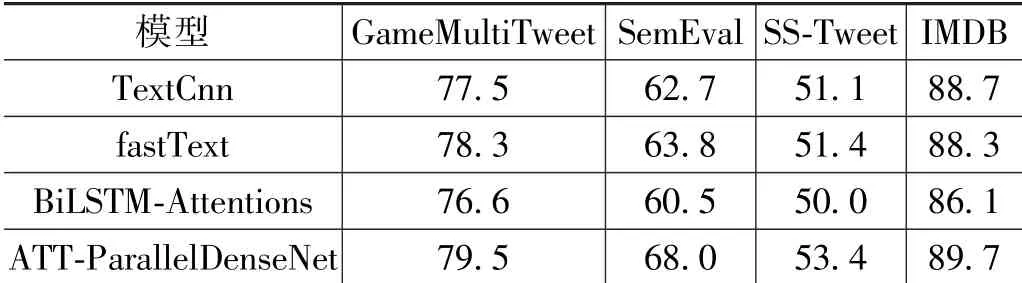
表1 各个模型在各个数据集上的结果对比
5 结语
本文基于上文Parallel DenseNet 提出了一种融合注意力机制和Parallel DenseNet 的ATT-Parallel Dense-Net 文本情感分析模型。 该模型在数据预处理阶段把停顿词和换行符这类多余的符号词语清理掉,将大小写不一致的词语换成统一的小写字符;将处理好的数据通过Word2Vector 进行向量化,即生成词向量阶段;将词向量放入分类器中,两个特征提取模块进行处理提取出重要特征,然后通过attention 模块为提取的特征分配权值,通过全连接层和Softmax 层得到分类结果。 实验比较了本文的模型与TextCNN,fastText 和BiLSTM-Attentions 几种深度学习模型的好坏。 实验结果表明,本文的模型比其他模型有一定的优势。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
噪声与振动控制(2015年4期)2015-01-01
