
基于Python 的蔬菜销售系统设计
2022-08-18 01:56张雁涔
无线互联科技 2022年11期
张雁涔
(忻州职业技术学院,山西 忻州 034000)
0 引言
近几年,国内蔬菜市场价格波动剧烈,严重影响养殖种植者的工作和消费者的生活,尤其当出现重大疫情及自然灾害影响国家和人民运作生活时,建立一个完善的蔬菜销售情况分析系统,可以让人们能够看到全国各地区蔬菜价格及销售情况,从而不必恐慌,让国家及有关政府能够有效监测农产品销售波动[1],从而有针对性部署,已成为急切之事。 本文的蔬菜销售情况分析可视化系统有助于同时搜集、分析、比较多种蔬菜种类的市场售价与相关数据,并根据不同时期的蔬菜价格涨跌情况进行分析和预判,主要可分为短期与中长期两种情况。 此外,根据研究得到的成果将蔬菜当期的销售现状通过更为直观的形式表现出来,可交给从事农业生产的企业或个体作为栽种参考,也可帮助当地政府部门在把控蔬菜市场价格动态方面提供宏观数据,方便其进行决策[2]。
采用Python 语言,选取适合的算法以蔬菜价格波动为核心进行研究,构建一个以特征和影响为维度的蔬菜销售情况的分析框架,形成一个用户可操作的系统,优化用户体验,为用户提供更加直观,方便使用的界面。
1 相关技术
本文用Python 编程语言设计了蔬菜销售情况分析系统,主要借助以下的几种技术。
1.1 Python 介绍
Phthon 在众多计算机语言当中,属于比较容易应用与功能较多的一种,使用该语言编写的程序代码属于开源性质,可以兼容多种平台;在编写程序的过程中不但包括抽象类型也有函数类型,前者主要基于分析对象,后者则更侧重于分析过程。 Phthon 语言既可以根据需要进行嵌入,也可以持续扩展内容,基于Phthon编就的数据库较为丰富,能够在其中根据需求进行下载或更换。
1.2 Django 框架技术
本系统的开发是以Django 作为基础性框架,此应用也是由Phthon 语言编写而成,同时也属于开源类型,需要在Web 的应用框架当中进行使用。 由于Web 框架在建立之初是基于MVC 模式,即模型(Model)、视图(View)和控制器(Controller)。 其中,控制器部分无需用户自行调配,自动设定为系统默认。 因此,Django 框架中存在一种MTC 模式,即模型(Model)、模板(Template)与视图(Views)[3]。
模型(Model),即数据存储层,负责管理数据库当中的各种信息,可以进行增添数据、删减数据、修改数据或查询数据等操作。
模板(Template),是表现层,当中负责的职能包括接收申请、处理请求与回复作答。
视图(Views),属于业务逻辑层,主要对退回的html 进行封存与建造。
1.3 爬虫技术
爬虫技术从本质上来说属于算法语言编写而成的脚本,适用于大多数网站和搜索引擎,可以根据特定要求在网络上自动获取相关信息,还可以按照要求爬取一定时间范围内的数据并进行实时更新。 Web 爬虫在实际操作过程中,需要把URL 种子加入下载列表,并直接在列表最前端选择一个URL 下载链接,使爬虫系统直接与网页相连[4]。 成功爬取网页所需内容之后,可以将其储存到系统数据库。 如果想继续获取网页的其他数据,也可以将网页链接作进一步解析,从中得到一个新的URL 种子,然后不断重复上述步骤,直到目标信息全部获取完毕,方可停止爬虫系统的运行,然后将得到的信息整合后存储到系统的MySQL 库中,以便及时调取。
1.4 影响蔬菜价格因素分析
造成蔬菜售价发生变化的要素主要包括以下两种:其一,存在于销售市场内部,主要指的是产品供应与购买需求这两个基础性因素。 其二,外部因素的影响,包括政府制定政策以及发生农业类疫情灾害等对价格的影响。 只有找出影响蔬菜价格主要因素,才能正确构建模型分析预测价格。
2 需求分析
2.1 用户需求
随着网络时代的发展,“互联网+”得到了快速发展。 农业相关大数据分析主要用来做决策分析,包括价格趋势预测、影响农产品价格的因素、农产品的区域特征分析等。 决策者在系统上了解到蔬菜的销售情况并制定决策,销售情况随着价格波动改变,且影响着未来的销售趋势,从而影响很多的农户或者商家。 基于这种情况,蔬菜销售情况分析系统就应运而生了。
2.2 功能需求
基于Python 的蔬菜销售情况分析系统所用的数据需要通过爬虫从农产品网中实时地进行数据采集,当需要处理的数据成功进入系统分析库时,下一步为预处理环节,即借助数据挖掘技术对现存数据作类型区分,并根据这些数据对未来的走向进行预判,系统流程如图1 所示。
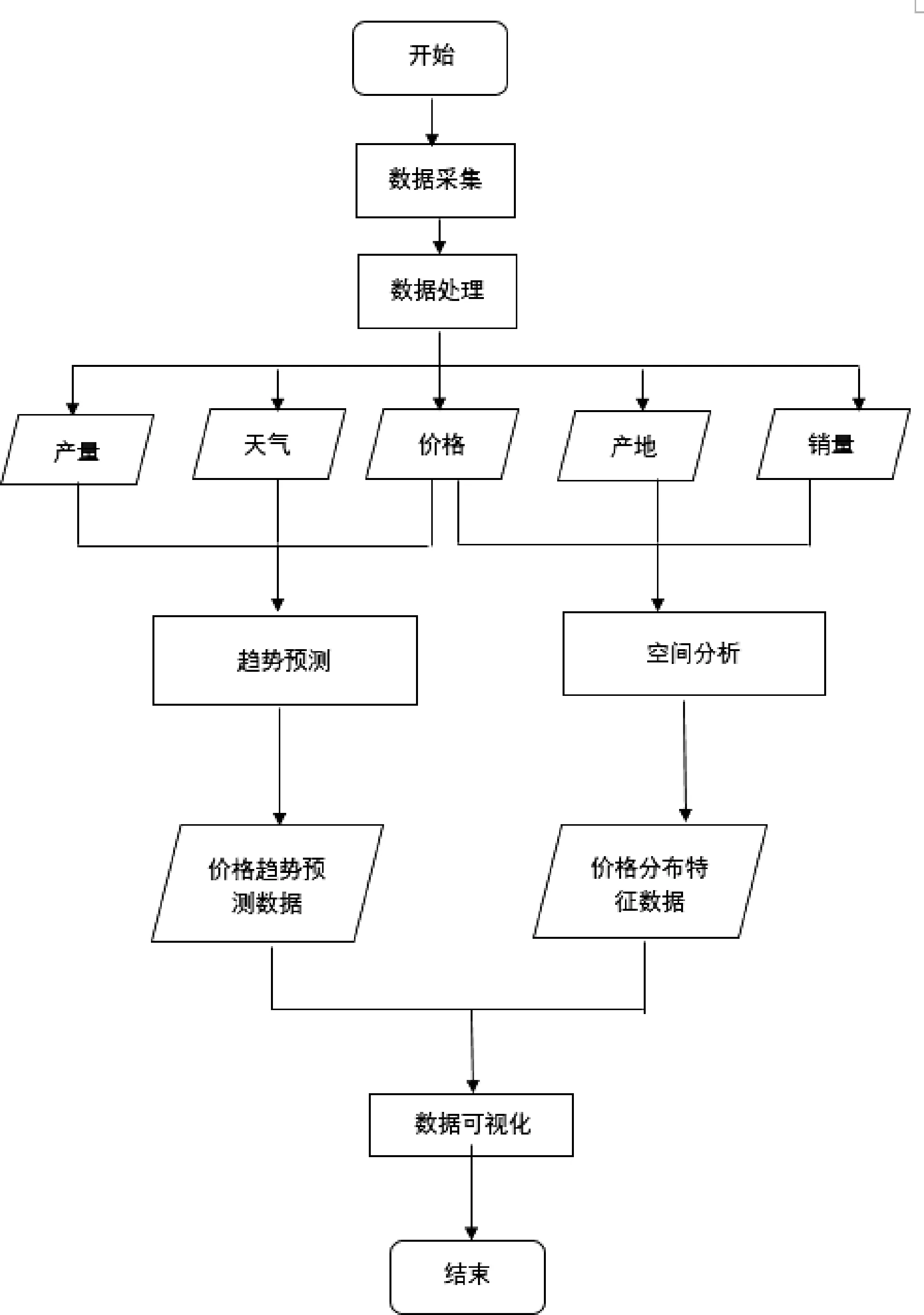
图1 系统流程
2.3 数据流图
基于Python 的蔬菜销售情况分析系统,一般来说,数据流图的类型主要有两种,即顶层图与分层图。 为了让数据分析结果更加清晰直观,本系统只对顶层与0层的数据流图进行制作。 其中,图2 即顶层数据流图。然后进一步作具体分析就得到了图3 的0 层数据流图。
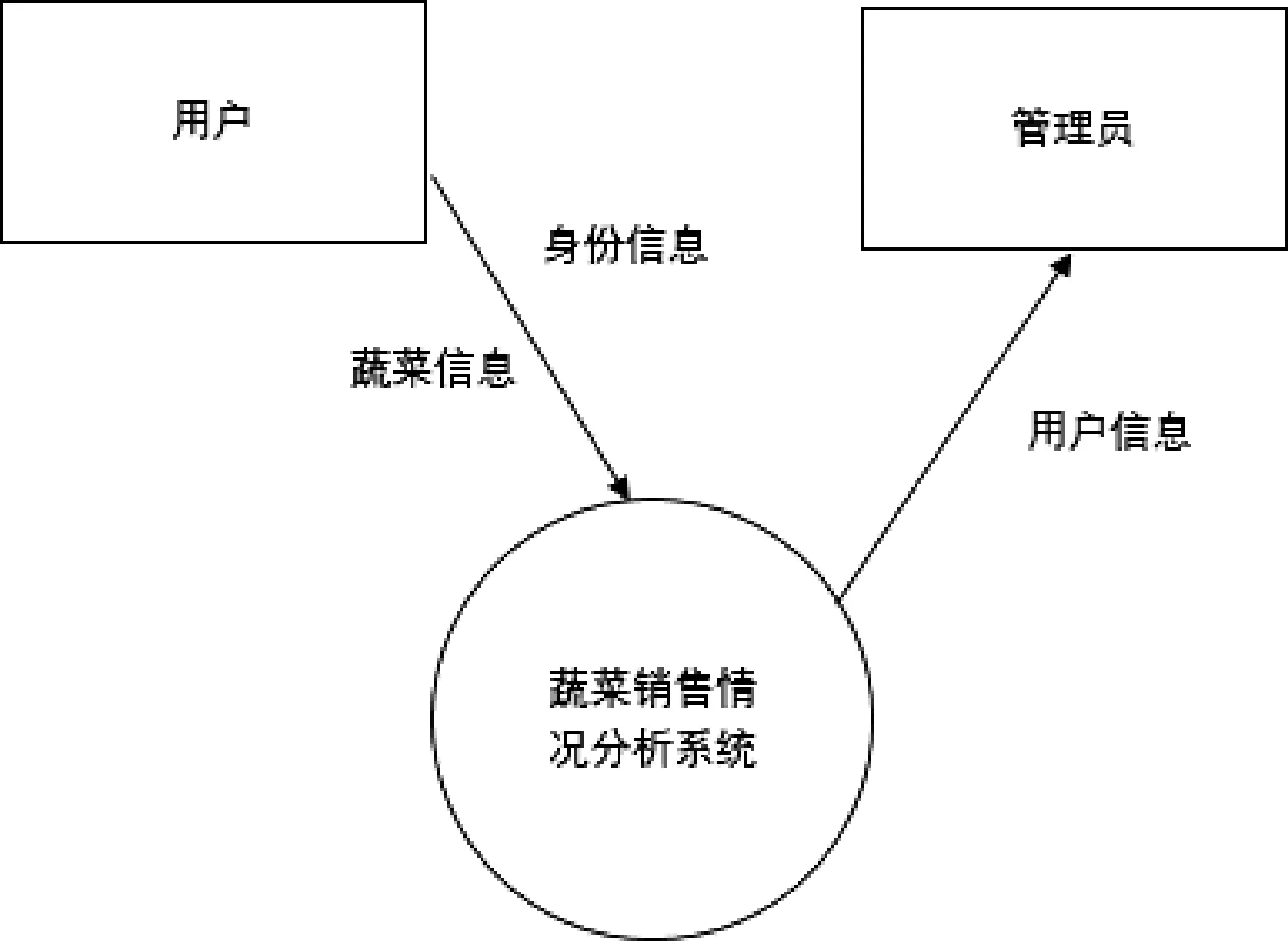
图2 顶层数据流
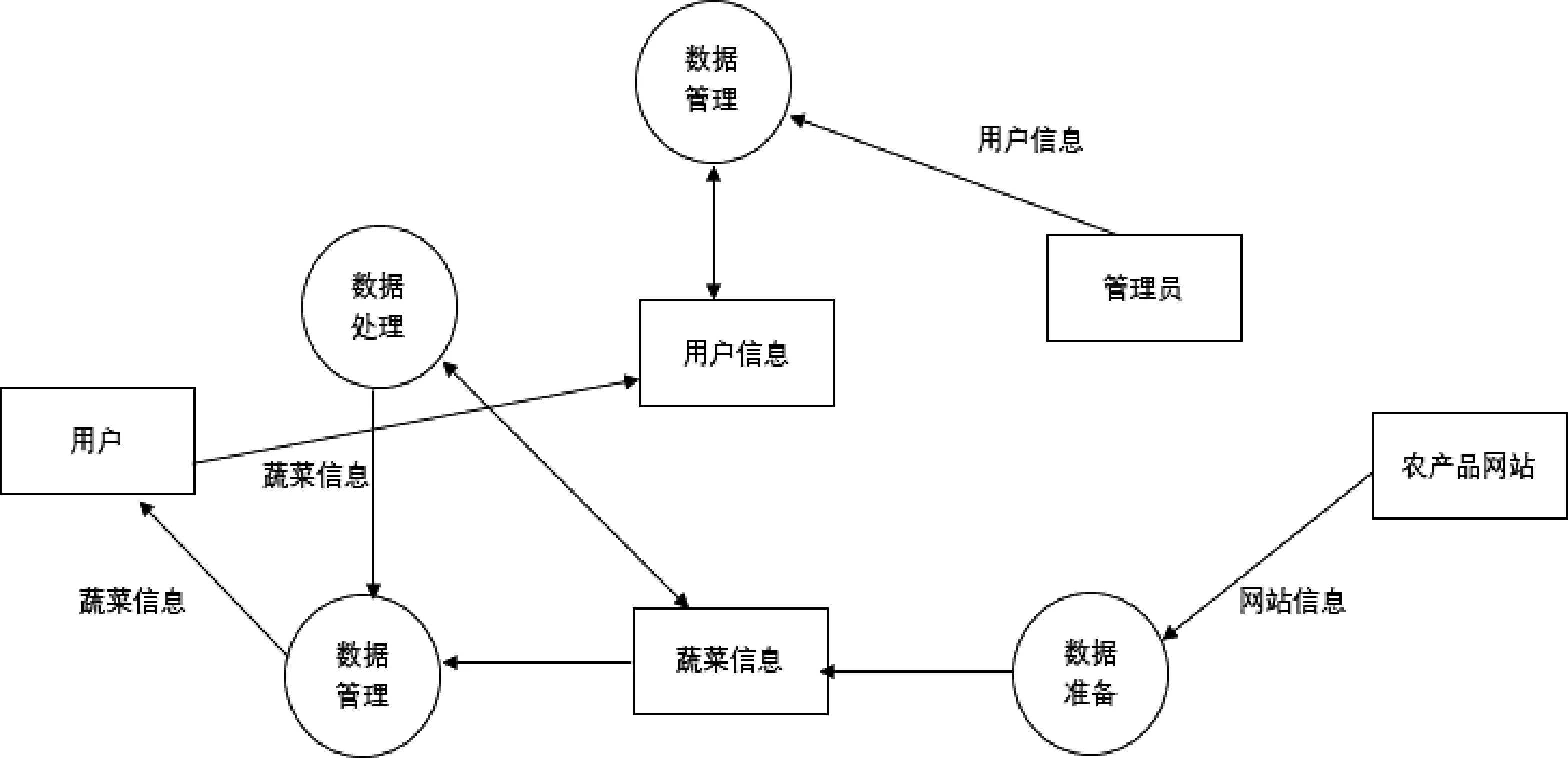
图3 0 层数据流
3 概要设计
3.1 总体设计
本次研究过程中建立的蔬菜销售分析系统,主要由Phthon 语言编写而成,当中设置有多个功能板块,主要有如下几种:用户板块、管理板块、数据展示板块、数据处理板块。
3.2 用户模块
用户登录时,如果没有账户,则需要注册账户。 但是,应当指出的是,该账户不能修改。 系统当中的每个账号都独一无二,通过用户名来进行区分。 在注册界面上,需要准确填写随机形成的验证码,当完成注册之后,系统会自动跳转到登录界面,用户需要再次填写用户名与密码,显示登录完成后,相应的用户名也会被系统存储到session 当中。 用户之后可以在个人信息界面对基本信息和登录密码进行修改。
3.3 管理员模块
系统管理员有权限进入系统后台,当成功登录管理员账号后,可以对自己的登录密码进行更换或查看用户的相关信息。
3.4 数据处理模块
本系统中的蔬菜信息都是通过爬虫技术爬取的。所以数据处理模块主要有数据采集、数据清洗、数据转换、数据挖掘。
3.4.1 数据采集
利用Python 的爬虫技术爬取各农业网站上的价格及影响因素的信息,该工具需能够监测网站数据的变化[5],然后将变化的网页爬取下来用于后期的分析,具备解析网页的能力。
3.4.2 数据清洗
去掉“脏”数据,在采集数据的时候,数据会可能出现残缺、错误、重复等情况,为了确保数据的准确性、完整性、一致性、唯一性、适时性、有效性,就需要对数据进行“清洗”。
3.4.3 数据转换
由于数据来自不同的网站,自然就有不同的语义和规范,所以需要对采集后的数据进行命名检查将同种数据以同样的命名来表示,使得系统内的数据达到一致性和完整性,还需要对数据质量进行判断确保后面分析结果的准确性及合理性。
3.4.4 数据挖掘
数据挖掘的主要目的是为了发现隐藏的可用信息,而过程中需要先对海量数据进行搜集,然后才能建立相应的分析模型,在模型当中可以对数据进行基础的分类操作,也可以对某项数据未来的走向进行预判[1]。 数据挖掘技术作为一项先进的技术应用,相比于人工检索和处理信息的速度,显然数据挖掘技术拥有更多优势,不仅可以同时处理较多数据信息,还能从中准确得出有价值的数据分析。
3.5 数据展示模块
将提炼后得到的数据作可靠性与有效性等评估后,将数据分析进行可视化展示。
4 数据库设计
本次设计选择的数据库为MySQL,数据库具体的操作工具为Navicat 可视化工具,严格遵循数据库设计规则进行表table 的设计。 在数据库的设计过程中,为了保证其完整性,表的设计完全按照一对一,一对多的规则进行。 本次设计的系统数据库包括的信息有:管理员、用户以及蔬菜信息,如图4 所示。
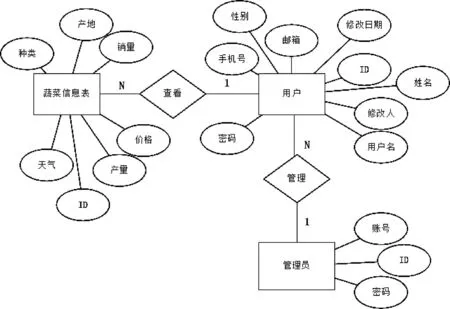
图4 总体设计的E-R 图
本文基于Python 的蔬菜销售情况分析系统还处于较为初期的实现阶段,可以做出简单的蔬菜价格预测以及销售情况可视化展示。 并且对数据的预测是根据已知方程中各变量的数据,在实际应用时操作较为复杂且意义不大。 因此,未来将从这一点出发,尝试在数据未知的情况下对农产品市场价格进行预测和分析。本系统设计与开发时的主要困难在于数据的采集与处理。 由于爬虫得到的数据量小,使得模型的效果并不明显。 建立和完善农产品价格及其相关因素的短期信息系统,有利于提高研究蔬菜销售情况分析的效率和研究范围的覆盖面。
随着研究的深入,相关系统将走出理论层面,为政府及有关决策者制定政策提供有效的信息支持。 农业相关部门应结合技术对涉农信息资源进行收集整理,及时了解农民蔬菜种植定价情况并且了解人们生产生活中的蔬菜需求,以建立信息共享机制。 只有预测与展示时所依赖的数据信息真实全面、及时有效,此类销售情况分析系统才能更贴近实际,也将继续完善功能,提高其应用到实际生活中的可能性。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
小学生优秀作文(低年级)(2021年5期)2021-07-21
现代信息科技(2021年21期)2021-05-07
小太阳画报(2020年3期)2020-04-24
现代营销(创富信息版)(2018年2期)2018-08-15
电子测试(2018年1期)2018-04-18
流行色(2017年2期)2017-05-31
电子制作(2017年9期)2017-04-17
小学生·多元智能大王(2014年3期)2014-03-21
海外英语(2013年8期)2013-11-22
