基于Scrapy框架爬取豆瓣图书的设计与实现
2022-08-12 03:30史媛
山西电子技术 2022年4期
史 媛
(山西机电职业技术学院,山西 长治 046011)
1 什么是Scrapy框架
Scrapy是一个开源协作的框架,基于Twisted,它适用于Python快速、高层次地进行屏幕抓取和抓取web站点信息,从页面中提取结构化数据,常用于数据挖掘、信息处理或存储历史数据等程序中[1]。它提供的框架结构简单明了,架构清晰,模块之间耦合程度低,扩展性很强,任何人可以根据爬取数据的需要对其进行修改,代码编写简单。其还提供了如BaseSpider、sitemap等爬虫基类,功能强大,适用面广泛[2]。
Scrapy框架主要包含了以下几个模块[3],分别是:
● Engine,它是整个框架的核心,主要处理整个系统的数据流,触发事务。
● Item,定义爬取数据的数据结构,爬取到的数据会被赋值成该对象。编写者要根据爬取对象自己编写代码定义其数据结构。
● Scheduler,接受Engine发过来的请求并加入到队列中,在Engine再次请求的时候提供给Engine。
● Downloader,下载网页的内容,并将网页内容返回给Spiders。
● Spiders,定义爬取的逻辑和网页解析规则,主要负责解析响应并生成提取结果和新请求。这部分需要编写者根据网页信息和爬虫的逻辑自己编写。
● Item Pipeline,将从Spiders要爬取的网页中抽取的项目进行处理,清洗、验证和存储爬取到的数据。这部分需要编写者根据爬取结果存储形式和后续用途自己编写。
● Downloader Middlewares,和Downloader之间的连接,处理二者之间的请求和响应。
● Spider Middlewares,Engine和Spiders之间的连接,处理Spiders输入输出的响应和新的请求。
Scrapy中的数据流都由Engine控制,原理如下:
首先,先找到目标网站,然后抓取URL页面的内容。根据response的内容对页面进行分析、抓取,最后将抓取到的数据进行存储。这些模块形成一个循环,直至要抓取的URL为空,网页抓取就结束[4]。
接下来,就来看看Scrapy框架在爬取数据中如何设计各个文件和应用。
2 Scrapy框架爬取数据应用
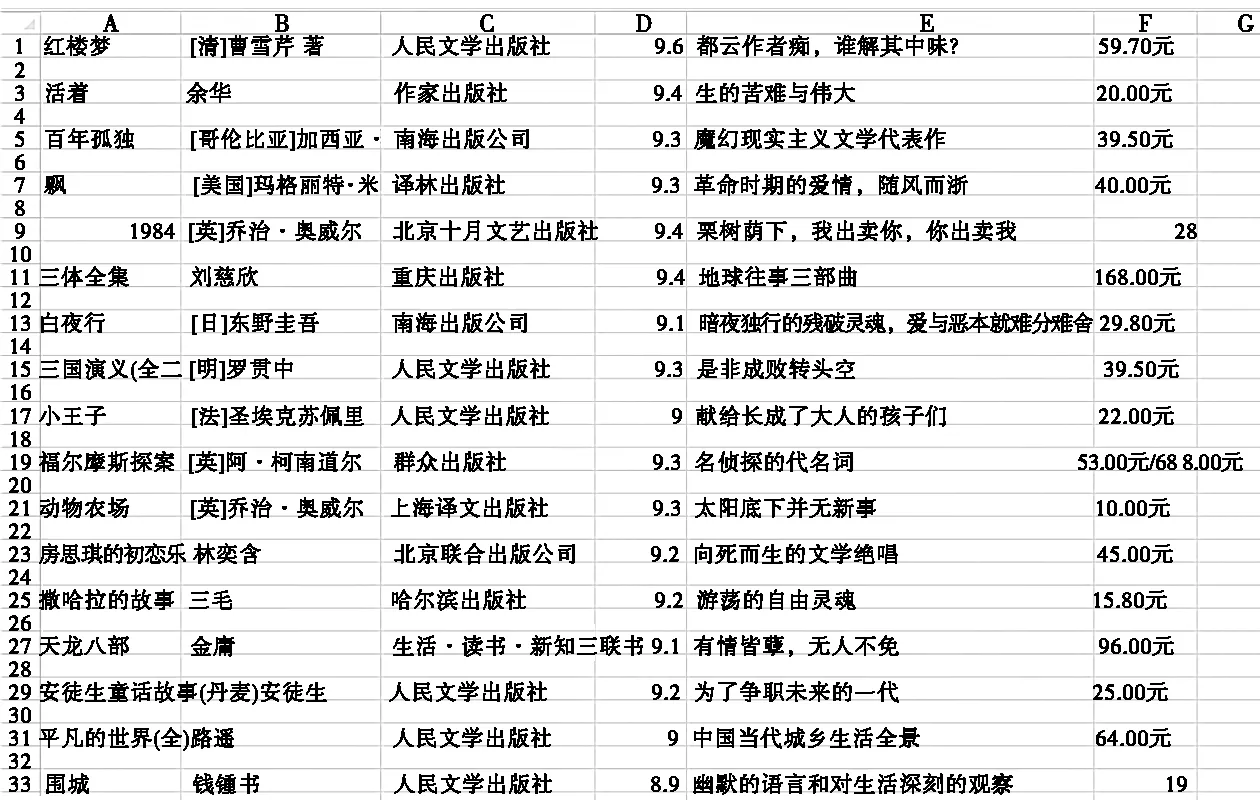
我们以豆瓣图书前250排名的网页为例。
2.1 创建Scrapy工程
在命令提示符窗口中,使用命令“scrapy startproject工程名称”,在Python文件存储位置处创建Scrapy工程。然后进入到工程中,使用命令“scrapy genspider爬虫名称要爬取网页的地址”,生成爬虫文件。网页地址为:https://book.douban.com/top250?start=0。
2.2 分析网页
使用谷歌浏览器打开上述网址,按下F12键,打开该网页的开发者模式,进入到Elements标签中,获取当前文档的DOM信息,从中定位我们要爬取数据的位置,如图1所示。

图1 豆瓣图书DOM信息
所有图书信息都在
这个总标签下,每本图书都分别在的标签下。从这个标签向下展开,图书名称在