
面向网络爬虫的智能拦截系统
2022-08-12 01:54马超勇李秋贤周全兴
现代信息科技 2022年7期
马超勇,李秋贤,周全兴
(凯里学院 大数据工程学院,贵州 凯里 556011)
0 引 言
搜索引擎对网络资源的收集与整理,带来了网络资源的高度共享与高速传递,同时使得网络爬虫技术日益普及。据搜索引擎巨头Google 透露,2012年,Google 的网页爬虫Googlebot 每天都会经过大约200 亿个网页,并且追踪着约300 亿个独立的URL 链接。此外,Google 每个月的搜索请求接近1 000 亿次,而确保这一切如常进行的强大后盾就是网络爬虫技术。
对一些网站来说,爬虫所带来的流量远远超过真实用户的访问流量,甚至爬虫流量要高出真实流量一个数量级。大型网站还可以应对,但这对许多中小型网站来说往往是毁灭性的打击。网络爬虫的危害不仅仅局限于流量攻击和数据资源泄漏,同时还有用户的恶意行为攻击(重放攻击、特定行为攻击),例如通过爬虫实现定时打卡签到、抢购秒杀商品、抢购优惠券、自动投票等从中薅取羊毛,获得利益,极大地破坏了公平性并有损其他用户的正常体验。通过引入智能拦截系统可避免后端数据被有不良意图的爬虫抓取,保护网站内容和用户隐私的安全。因此,如何检测和拦截爬虫,增加非法爬虫的抓取难度,减少爬虫带来的负面影响,已成为许多网站亟待解决的问题。反爬虫在保障网站正常运行、保护网站数据和用户隐私安全方面有着重要的意义。
1 爬虫的分析与防护
知己知彼方能百战不殆,若要对爬虫进行拦截,首先得知晓爬虫的请求特征,从而依据其特征构造反爬虫技术。
1.1 爬虫的特征
初级爬虫请求头可能还是原生爬虫程序自带的,如Python 中的requests 模块,请求头默认为python-request/x.xx.x,网站可通过请求头Headers 中的User-Agent 并结合Referer 进行检测分析,区别正常用户与爬虫程序。
爬虫一般具有很强的目的性,往往只针对需求向某个或某些接口发起大量请求,而且对接口发起的请求是多线程运行的,同时为了防止被封禁IP,可能会使用动态代理IP 来防止被查处,爬虫的请求过程如图1所示。
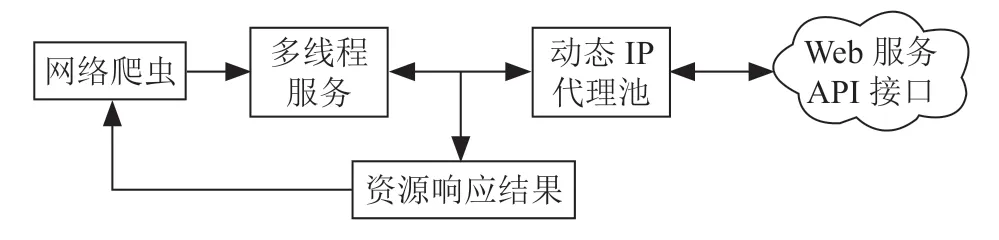
图1 单机多线程爬虫请求过程
1.2 爬虫的防护
下面列举常用且较为有效的爬虫防护措施:
(1)设置robots.txt 协议来规范爬虫行为,该协议并没有采用技术手段来实现反爬,只是一个申明,往往只对搜索引擎的爬虫有效,而对有目的性的爬虫却束手无策。
(2)在进行重要操作之前设置验证码(如图形验证码、滑块验证码、点选验证码),但这会在一定程度上降低用户体验度。
(3)通过自定义规则实现签名,从而防止篡改参数,这要求客户端和服务端都使用相同的特定算法对请求参数进行加解密,一般通过绑定时间戳(timestamp)、随机字符串(nonce)计算得到签名(signature)。
(4)因为参数防篡改操作有些是在客户端完成的,爬虫攻击者仍然可以通过解析JavaScript 获得其中的加密算法,所以通常会加上JavaScript 混淆。
(5)全局数据提交加密,即对提交的数据(如{uname:123,pwd:456})进行加密,123 和456 这两个要提交的数值需要先进行加密(对称加密算法或非对称加密算法),再转换16 进制提交,返回的JSON 数据使用相同的算法进行解密。
(6)如果某个IP 在一个时间点大量请求服务器资源,服务器后台可以阻断其后续访问操作,即限制IP 单位时间内的访问次数。
(7)可以将API 接口与静态资源进行绑定,但凡不是事先请求绑定的静态资源,都不会向客户端暴露API。
2 爬虫与反爬虫的技术交锋
纵使网站有图片验证码,爬虫编写者也可以使用OCR识别技术进行识别验证;纵使有滑块识别,也有图像处理、灰度差校验,从而计算缺口距离出现偏移量;纵使有汉字点选、语序点选,也有CRNN-CTC 汉字识别、YOLO3 汉字定位以及JIEBA 分词;纵使是Google 的ReCAPTCHA2 和Hcaptcha,都可使用Tensor Flow机器学习框架进行图像分类、模型训练,以解决验证码问题。
2.1 技术交锋之抓包工具概述
利用Fiddler 抓取Web 网站和手机应用数据包(但在已做风控的应用中,一般无法直接抓取或篡改其数据包,从而无法实现一些操作,原因是应用程序会检测用户是否开启了Wi-Fi 代理(检测到开启Wi-Fi 后会立即断开网络/拒绝访问)或在服务端对数据进行签名校验,以此来检测数据是否被篡改。
Fiddler 抓包会有局限性,诸如对WebSocket 的数据抓取支持不太友好,且应用程序检测到Wi-Fi 代理后会自动断开网络,导致无法抓包。利用HttpCanary 抓包可解决以上问题,相较于Fiddler,该抓包工具无须使用Wi-Fi 代理即可对本地应用程序进行抓包,同时还可以抓取小程序应用的数据包。
未做风控的APP 应用比已做风控的APP 应用更容易遭受爬虫的攻击,因为未做风控的APP 应用可直接通过抓包工具获取API 接口,而做了风控的APP 应用可能已进行安全加固,但爬虫攻击者仍可以解固脱壳,逆向反编译得到加密算法,用代码实现一套相同的算法再通过爬虫向服务器发出请求。
除使用上述抓包工具分析HTTP 请求以外,还可以使用Wireshark 对人脸识别/指纹识别考勤机与服务器交互数据进行抓包嗅探,攻击者识别其数据传输协议是TCP 协议或是HTTP 协议后很容易受到重放攻击,但凡和服务器处于一个VLAN,都可以实现不在场签到,这源于服务器是将人脸或指纹数据下发到考勤机,由考勤机去比对数据是否与本地存储的数据相吻合,如果吻合则携带SN 机器序列号、用户ID、时间戳等信息请求服务器。
Web 服务或应用软件没有做风控将是一件非常危险的事情,等同于数据在网络中透明传输,用户可以任意截获并修改数据,实现自动化操作,而实际的软件开发更应该遵循零信任原则,即对传输中的全局数据进行加密(可采用自定义密钥+RC4/AES/DES/RSA 等算法对请求参数以及响应参数进行加密,再转换为Base64 或16 进制传输)。
2.2 技术交锋之提高准入条件
目的性爬虫接触黑灰产业较多,一般网站或APP 应用都有手机号码注册和登录机制,目的性爬虫为达到某些特定目的而通过接码平台注册大量虚假账号,极大地影响了公司决策与正常业务的开展。下面给出相应的解决方案:
(1)屏蔽虚拟号段注册登录(虚拟号段即运营商虚拟号,并非正常用户使用的手机卡)。
(2)双向验证,即注册时需用户发送特定文本至指定的服务号码,该服务号码会自动回复,给用户下发验证码,用户依据收到的验证码即可成功注册,如图2所示。

图2 国内12306 使用该方案示例
(3)注册后还需实名认证(采用行业内先进的阿里云身份认证)方可进行敏感或相关活动操作。
3 平台设计与实现
3.1 拦截系统架构设计
系统旨在对包括但不限于对数据库表增删改查的API 接口做防护,其目的是防止API 接口被盗用/盗刷,减少服务器负载以及预防非法操作,使用ProxyServlet 作反向代理。用两个过滤器(Filter),一个用于传输过程中的加解密,另一个用于对请求进行解析校验以判断其是否合法,系统架构设计图如图3所示。
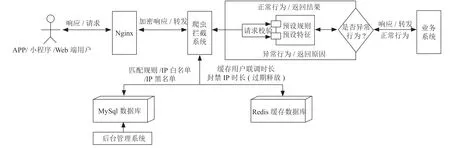
图3 系统架构设计图
3.2 拦截系统功能模块设计
3.2.1 数据传输加解密模块
自定义的响应加密算法用于业务系统的响应加密,业务系统无须设置加解密,减少重构,只有前端需要解密数据,且前端可以通过后台设置指定的加密方式加密请求参数,拦截系统接收到请求参数,自动解密后将其转发给业务系统。
目前,拦截系统引入的加密算法有摘要加密(MD5、SHA)、对称加密(AES、DES)、非对称加密(RSA)。
通过后台数据库定义的加密算法、解密算法,利用Java反射创建对象。对请求的参数进行解密(若解密失败直接由拦截系统返回),获取解密参数后,对参数进行SQL注入替换、XSS 注入替换,再将经处理的参数转发给业务服务器。在数据得到业务服务器的响应后,对数据进行指定算法加密,并将加密后的密文返回。
3.2.2 IP 黑白名单模块
依据后台自定义的IP 黑白名单配置,判断当前IP 是否在黑名单之中(或国外IP 禁访是否开启),如果当前IP 在黑名单之中,则直接拦截并触发后台设定的规则。获取客户端IP 方式会先解析请求头Header 得到x-forwarded-for、Proxy-Client-IP、WL-Proxy-Client-IP、HTTP_CLIENT_IP、HTTP_X_FORWARDED_FOR,如果均不存在则直接获取客户端IP 地址。
3.2.3 维度拦截信息模块
不同维度拦截状态描述,如单位时间内超过设定的请求次数、对请求进行UserAgent、Referer、Host 的校验,达到预期设定的错误后直接返回并触发后台设定的规则。
3.2.4 请求时序拦截模块
请求时序拦截模块包含两部分功能,第一部分功能是后台设置父子接口,即须在请求A 接口(父接口)之前先请求B 接口(子接口),即便是这两个接口没有任何关联。由后台服务器校验当前请求是否为父接口,如果是则进行时序校验,仅当校验通过后交由业务服务器处理;第二部分功能是静态资源关联,即某一个接口或某一些接口关联着一个静态资源,第一种模式是在请求接口的时候会先判断静态资源是否被该客户端访问(可能存在网络延时分区问题),如果静态资源没有被访问则直接进行拦截处理,这样就忽略了网络延时分区问题。第二种模式是第一种模式的增强改进,请求接口能正常返回,但是如果在预设的时间内没有请求有关静态资源,则会回滚数据或将该用户标记为Robot,功能模块所在系统位置如图4所示。

图4 功能模块所在系统位置图
3.3 开发语言环境和数据库设计
拦截系统的开发采用的是IDEA 开发工具,开发语言为JAVA,前端框架采用HTML、JQuery、LayUI,后端框架采用SpringBoot、MyBatis-Plus,数据库使用Redis、MySQL。
平台数据使用MySQL 进行存储, 通过Redis 来缓存拦截配置,其中Redis 缓存采用的序列化方式为JdkSerializationRedisSerializer,所涉的数据类型有String、List、Hash,缓存的具体内容为:
(1)存储IP 黑白名单信息。
(2)存储当前选择的加解密算法对象和拦截信息对象。
(3)存储请求时序信息。
(4)存储不同维度信息。
(5)存储拦截IP 信息。
系统初始化过程是先通过查询MySQL 数据库获取传输加解密规则、拦截维度选择、IP 黑白名单、维度信息初始化,并将其转至Redis 存储,从而减少与数据库的直接交互。
平台存在两个系统,分别是拦截系统和管理系统,其MySQL 数据库都是共用的。平台中部分数据库表如表1、表2、表3、表4、表5所示。
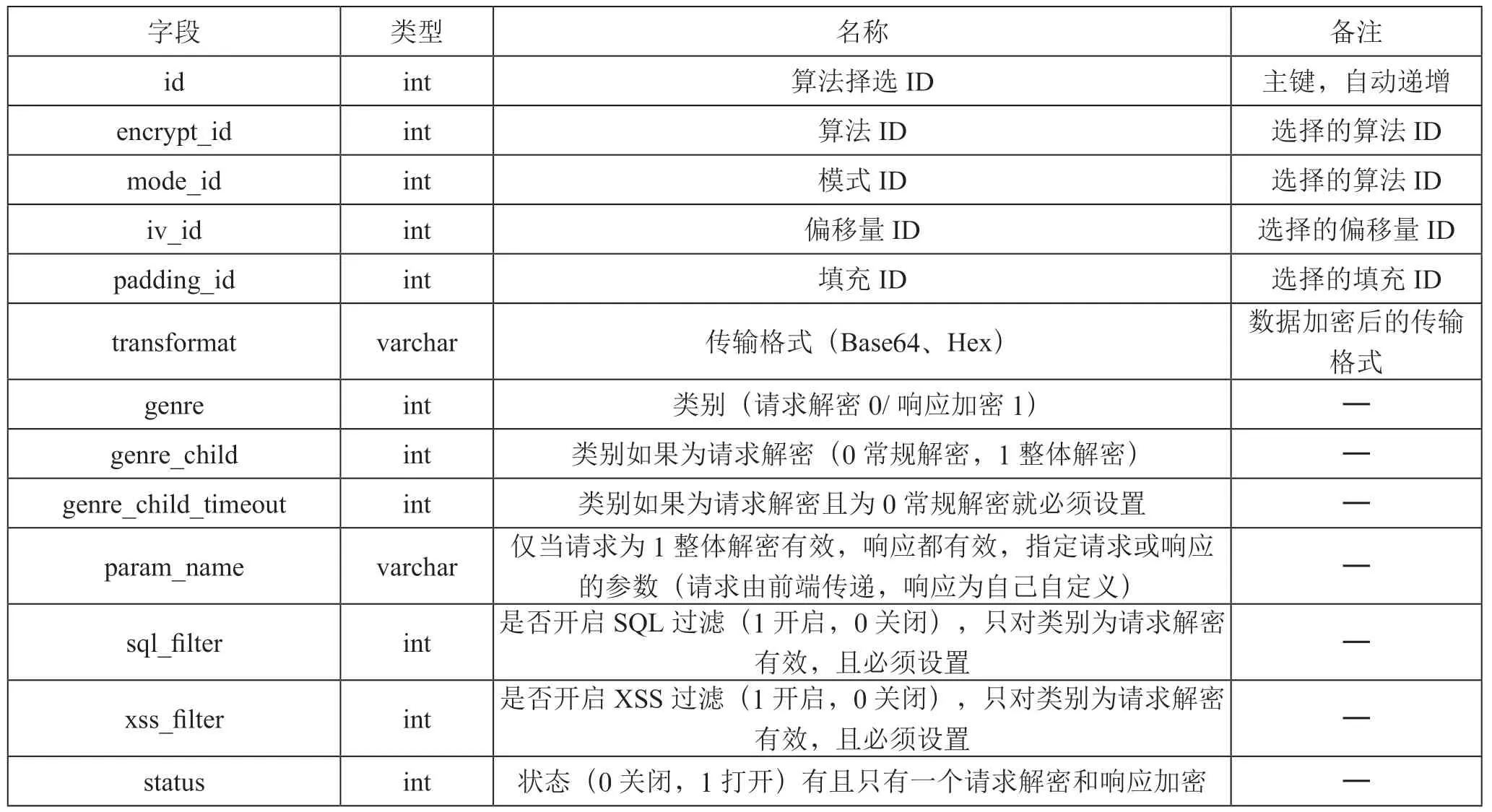
表1 算法择选信息表

表2 拦截触发条件信息表

表3 拦截API 接口信息表
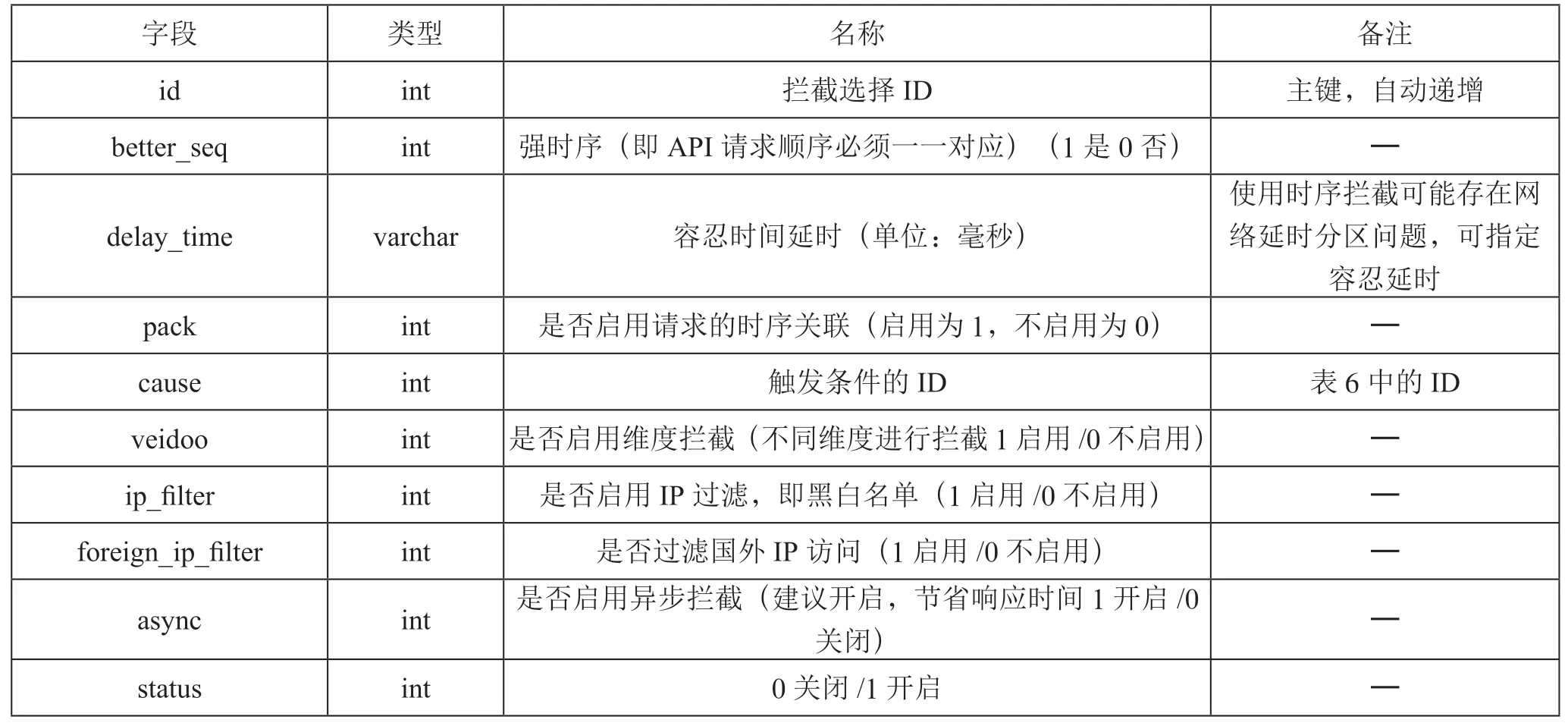
表4 拦截规则择选信息表
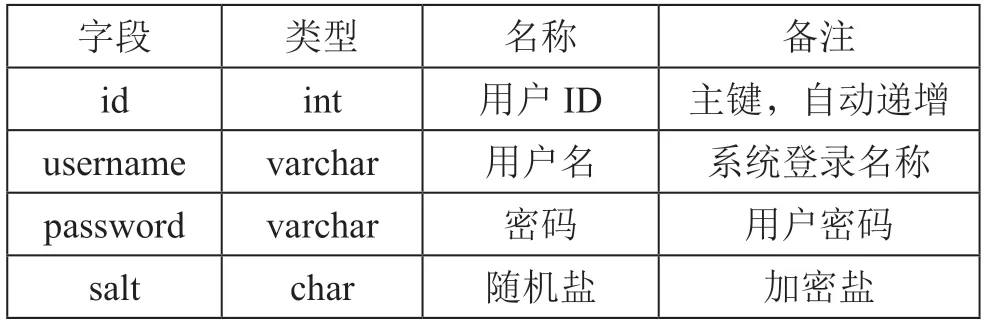
表5 管理系统用户信息表
3.4 管理系统功能预览
因拦截系统无界面,由管理系统进行控制管理,故下面仅展示管理系统控制台及其部分功能页面,系统控制台及系统功能页面如图5、图6和图7所示。
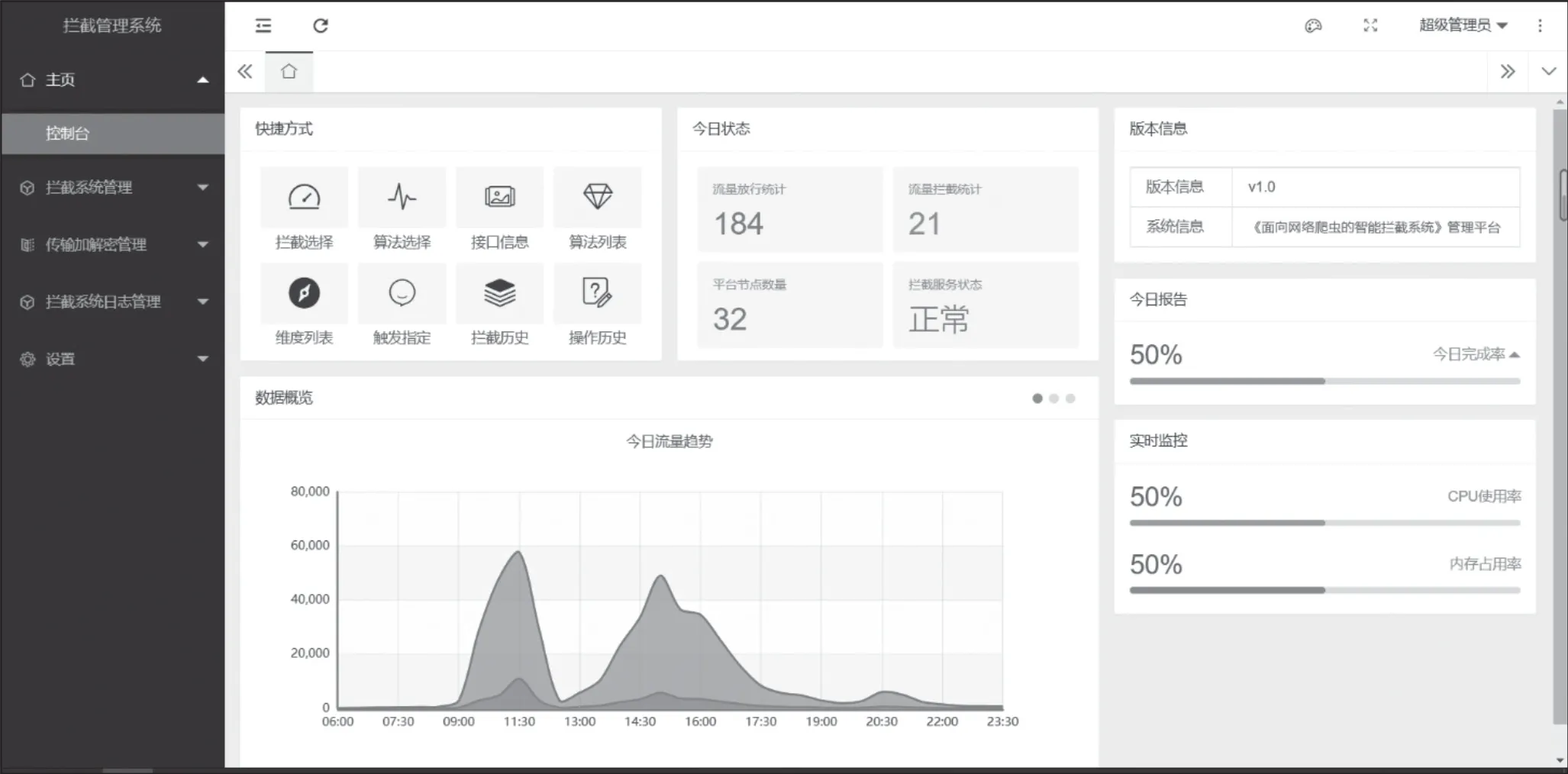
图5 管理系统控制台及系统监控图
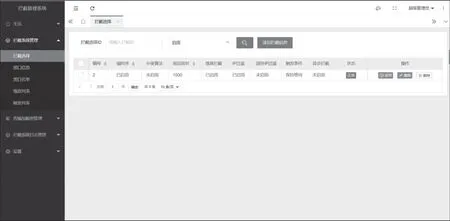
图6 管理系统拦截规则配置图
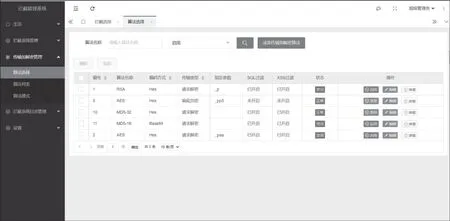
图7 管理系统数据传输加解密配置图
4 结 论
拦截系统属于反向代理服务,避免了与业务系统的代码耦合。另外该拦截智能可控、灵活多样,依据自定义的维度设定即可实现拦截,并在单位时间内限制最大请求,同时结合字段加密,提供了接口服务的安全保障,维护了资源数据安全,规避了接口攻击。
然而,系统仍存在缺陷,如配置需要手动配置,由于没有引入机器学习故而不能自动对参数进行优化,有待完善的内容包括:爬虫识别算法进一步优化、引入更为完善的爬虫识别技术(如设计陷阱捕获)、引入其他机器学习识别爬虫等,增强对爬虫的识别能力。真正实现完整的防护、细腻的检测、智能的拦截。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
软件导刊(2017年4期)2017-06-20
电子制作(2017年9期)2017-04-17
网络空间安全(2016年3期)2016-06-15
电子技术应用(2016年6期)2016-03-18
火控雷达技术(2016年1期)2016-02-06
四川师范大学学报(自然科学版)(2015年1期)2015-02-28
软件工程(2014年11期)2014-11-15
