
基于数据词典的中文分词算法优化实现
2022-08-12 01:54鲍曙光
现代信息科技 2022年7期
鲍曙光
(武警海警学院 职业教育中心,浙江 宁波 315801)
0 引 言
分词技术是中文自然语言理解的基础,中文分词技术的重点和难点是分词算法、新词发现、歧义消除等。目前,常用的中文分词工具有很多,包括盘古分词、Yaha 分词、Jieba分词、清华THULAC 等。中文分词技术已经比较成熟,有些研究者利用神经网络模型来实现分词技术。本文作者查阅了相关文章,发现介绍中文分词技术现状和原理的文章比较多,但具体描述算法实现的文章并不多。本文力求用简洁实用的模型和翔实可靠的实验数据,阐述基于数据词典中文分词算法优化的实现。文中所使用的分词算法是课题小组基于C#自行开发的分词算法,课题小组通过对算法的设计和改进,了解影响分词算法运算速度的主要因数,完成了几种基本分词算法的设计与实现,并将之应用于新词发现和歧义消除。
1 分词算法
分词算法可以分为三大类:第一类是基于数据词典的分词算法,第二类是基于统计分析的分词算法,第三类是混合算法。本文介绍的是基于数据词典的分词算法。
1.1 基本思路
基于数据词典的分词算法的原理很简单,即先将文章分成段,再将段分成句子,然后对句子进行分词。假设句子由个字符组成,那么存在1+2+3…+=(+1)/2 种字符串组合(称为“待匹配词”),将待匹配词与词典中的现有词进行匹配,最终输出匹配结果。假设字符数=100,可能存在的待匹配词为100×101/2=5 050 个,如果将段落分成5 句由20 个字符组成的句子,那么待匹配词组合数为:5×20×21/2=1 050 次。
1.2 基本框架
本文作者采用Visual Studio 2012 作为开发环境,编写了分词算法类Segmentation、数据库操作类DatabaseMethods、文件操作类FileMethods、数据库词典构造和维护类DatebaseDictionary 等操作类,代码如图1所示。

图1 分词算法代码缩略图
1.3 常见算法
根据从字符串中获取字符顺序的不同,分为正向分词算法和逆向分词算法。根据匹配时最长词与最短词优先顺序的不同,分为最长词匹配算法和最短词匹配算法。根据是否匹配所有待匹配词,分为全匹配算法和单匹配算法。
例如,字符串“我爱中华”,图2展示了不同的取词方式。

图2 不同匹配算法取词结果图
通过上图我们可以更好地理解正向、逆向分词算法和最长、最短词匹配算法,主要区别在于匹配时取词方式不同。全匹配算法和单匹配算法主要区别在于匹配次数的不同,全匹配算法的匹配次数为(+1)/2 次,单匹配算法是全匹配算法的优化算法,即对某一字符对应的所有待匹配词进行匹配时,一旦有一个待匹配词与数据词典中的现有词匹配就会结束匹配,因此单匹配算法的匹配次数小于前者。
“逆向最长词单匹配算法”简化代码为:


例句:我爱中华人民共和国
逆向取词算法中,对以上例句进行分词,当=9,=5,=2 时,取字符Line.Substring(n- i - 1, 1)=“华”,待匹配词Line.Substring(j, n-i-j)=“中华”。
影响分词匹配速度和准确度的关键是数据词典结构和算法优化。下文详细介绍不同数据词典和算法的实验比较结果。
2 数据词典
课题小组采用txt 文件和关系数据库作为数据词典的存储介质,它们各有利弊。
2.1 数据库词典
课题小组建立以下结构的表,组织数据词典。词典内容以《现代汉语词典(第6 版)》为基础,进行数字化:
(1)数据表AllWord(存储所有字、词或短语的表)
ID、CCharacter、Word、Meaning(ID 号、字符、词、词的释义)
表记录格式为:


(2)数据表CharacterIndex(存储以某字为首字符的所有词组成的字符串索引表)
ID、CCharacter、WordString、WordNum、CallNum、atFrontValues、atBackValues(ID 号、字符、该字对应所有词组成的字符串、由该字组成词的个数、该字在样本中出现的次数、该字在词首出现的概率、该字在词尾出现的概率)
表中字段WordString,格式为:
阿:阿鼻地狱:阿昌族:阿斗:阿尔茨海默病:阿尔法粒子:阿尔法射线:阿飞:阿伏伽德罗常量:阿公:阿訇:阿拉伯人:阿拉伯数字:阿兰若:阿罗汉:阿猫阿狗:阿门:阿片:阿婆:阿Q:阿是穴:阿嚏:阿姨:阿附:阿胶:阿弥陀佛:阿谀
(3)数据表NewWord(存储提取的新词的表)
ID、Word、WordLength、WordKind、ExtractNum、PossibleValues、ExampleSentence(ID 号、字词、词的长度、词的类型、被提取次数、可能为新词的概率、例句)
数据表记录格式为:
19654 奥委会3 0 19 3 感谢|国际|奥|委|会|长期|以来|为|中国|体育|事业|发展|作出|积极|贡献
2.2 TXT 文件词典
可以将数据库词典转化为txt 文件,即每一条记录对应一行,去掉不需要的字段,保留关键字段。
例如:可将AllWord 表转化为AllWord.txt,即去掉其他字段,只保留Word 字段。可将CharacterIndex 表转化为CharacterIndex.txt,即去掉其他字段,只保留WordString 字段。
2.3 数据词典优劣比较
课题小组对Access 数据库、SQL Server 数据库与txt文件等不同介质的数据词典进行性能比较。本文中所有算法的测试选用配置较低的个人计算机(基本配置:CPU 为Intel(R) G630 2.7 GHz;内存为12 GB;系统为win764 位旗舰版)来实现。不同数据词典的测试结果如表1所示。
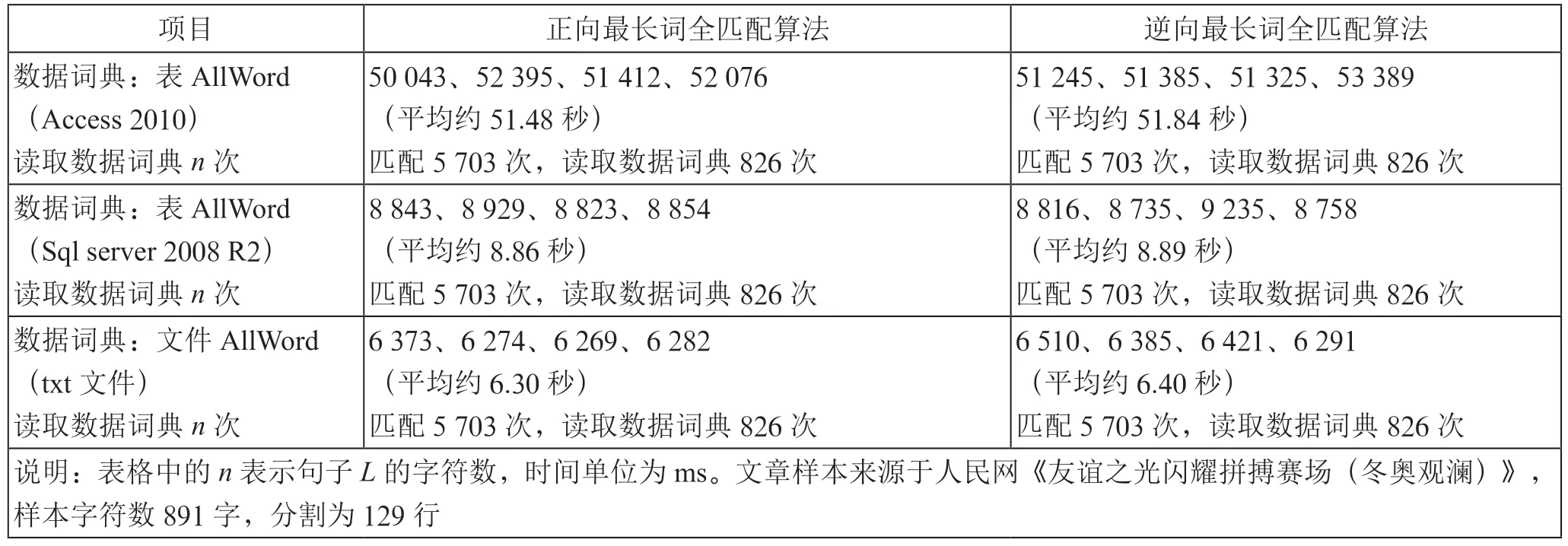
表1 不同数据词典的测试结果列表
显然,从以上实验数据可以看出,数据词典类型对算法速度的影响较大,txt 文件比大型数据库SQL Server 和小型数据库Access 更加高效和便捷,但是txt 文件在数据词典维护和可视化方面存在一定的不足。在访问速度上,SQLServer 具有较大优势;在安装和使用方面,Access 更为简单和灵活。经过综合考虑,对于单机版分词算法,课题小组选择Access 进行数据词典的生成和维护,选择txt 文件作为分词算法的数据来源,使它们能够充分发挥各自的优势。
3 算法优化
分词算法中的主要操作是词的匹配和数据读取。减少匹配次数可以通过“单匹配”算法实现。在实验中发现,最短词单匹配算法比全匹配算法可以减少约50%的匹配次数,最长词单匹配算法比全匹配算法可以减少约30%的匹配次数,但是在访问数据词典相同次数的情况下,运算时间几乎一样。这也充分验证了每次访问数据库或文件时,需要消耗的时间长、资源多,相较于读取数据库或文件(涉及硬盘数据读取)的时间,循环匹配操作(主要为内存之间数据操作)的时间可以忽略不计(测试实验中发现,前者是秒级,后者是毫秒级)。为此,算法优化的方法有两个:一是减少数据词典的访问次数;二是优化数据结构,建立索引表。
3.1 减少数据词典访问
在分词算法中,最原始的方法是匹配多少次,就要对数据词典访问同样的次数。这种算法消耗的时间很长,可参看表2第1 条数据。
利用数组缓存的功能,尽量减少在循环算法中对数据词典的访问:
(1)读取数据词典次的思路。在分词算法第1 层循环中,按照一定的顺序读取句子中的每个字符,然后在AllWord 文件或表中,取出以该字符为首字符的所有词(以下称“前缀词”),再将这些前缀词组成前缀词字符串(WordString),与待匹配词进行匹配。
(2)只读取数据词典1 次的思路。可以在分词算法第1 层循环前,一次性取出句子中所有字符的前缀词字符串,将其存放在数组中,供分词算法在第2 层循环中匹配使用。
算法的测试数据如表2所示。
从表2中可以发现,从读取数据词典(+1)/2 次变成读取数据词典次的算法,所花费的运算时间呈数量级减少。
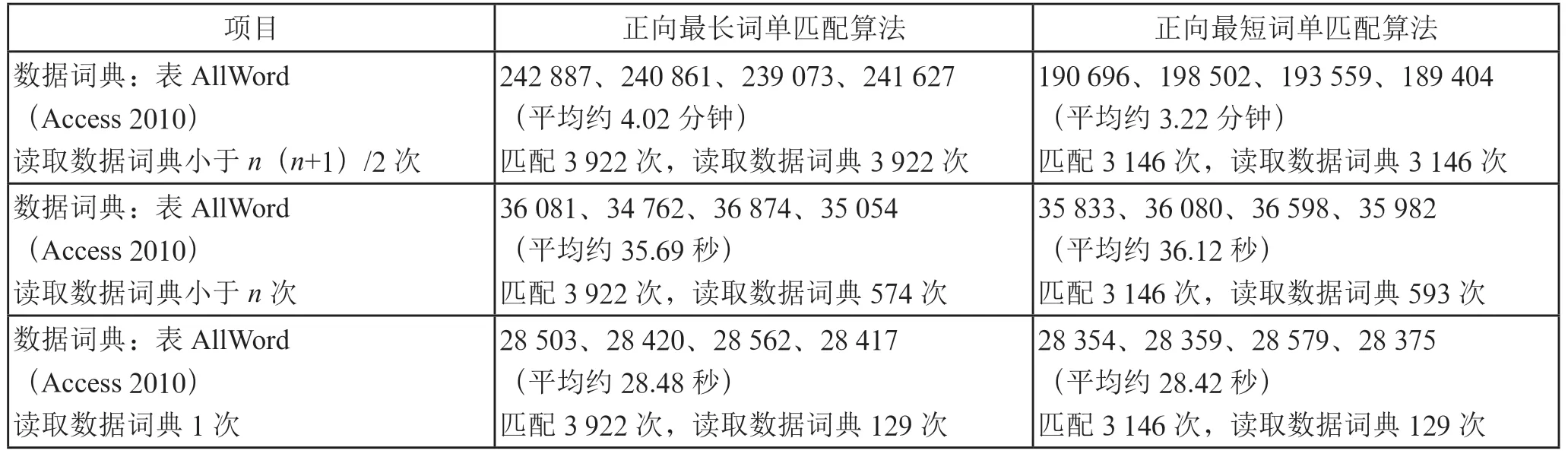
表2 读取数据词典不同次数的测试结果列表
3.2 访问索引数据词典
课题小组根据《现代汉语词典(第6 版)》建立的AllWord 数据表,共包含65 134 条记录,所建立的CharacterIndex 索引表共包含8 260 条记录(整理过程可能存在一定误差)。数据表AllWord 中的CCharacter 和Word 是一对多关系,而索引表CharacterIndex 中的字段CCharacter和WordString 是一对一关系。索引表CharacterIndex 的数据组织方式虽然不符合关系数据库范式要求,但是在这里却能够发挥重要作用,也是本文分词算法的创新点。在建立CharacterIndex 索引表后,可以将分词算法优化成只访问一次数据词典,就可以取出某一句子所有字符对应的WordString,并将其存放在数组中供第2 层循环中匹配。通过实验对比可以证实,建立CharacterIndex 表对匹配算法的速度具有很重要的影响,测试结果如表3所示。
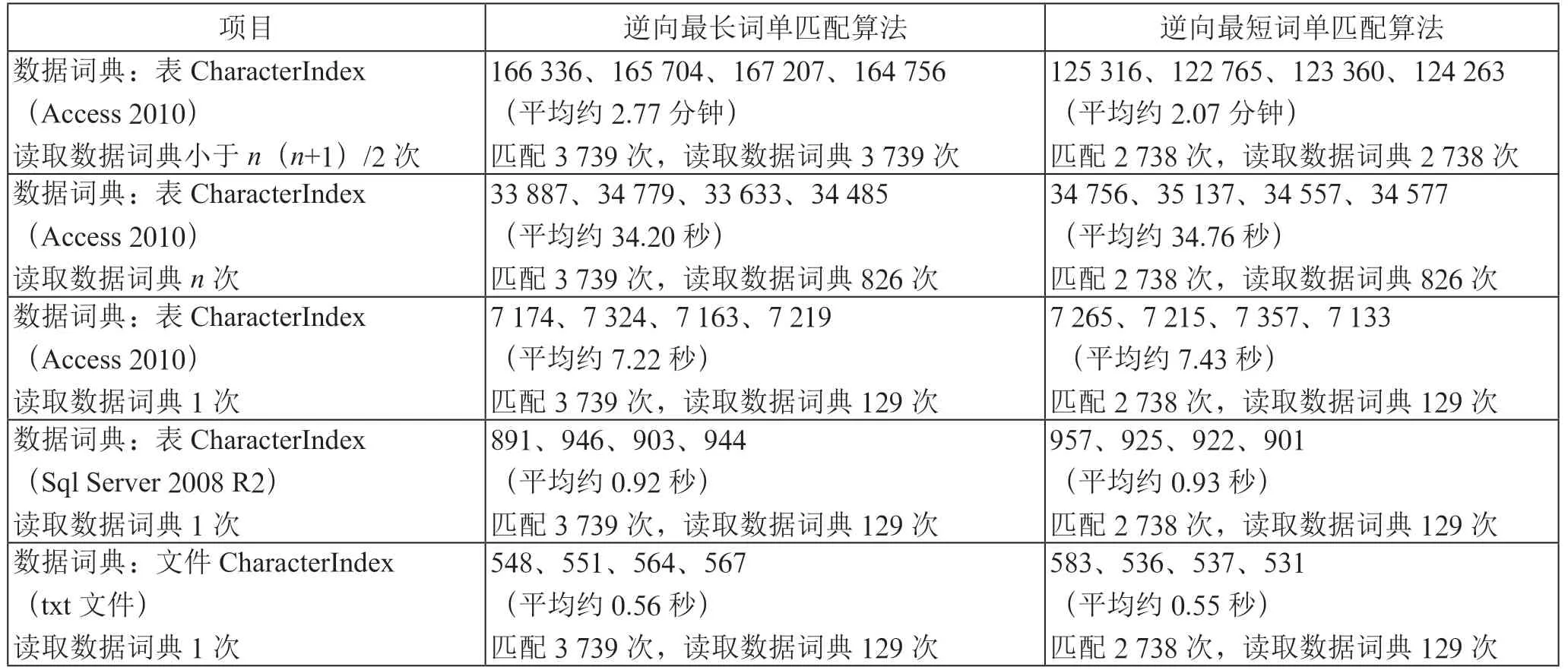
表3 使用索引表的测试结果列表
引入CharacterIndex 格式的数据词典,在不同算法和不同数据结构的情况下,运算速度上有较大差异。
通过实验,将CharacterIndex 表按使用频度倒叙排列,再对匹配算法进行改进,匹配速度又能提升1 倍。将CharacterIndex 表一次性读取到内存数组,匹配速度又能提升1 倍。测试结果如表4所示。
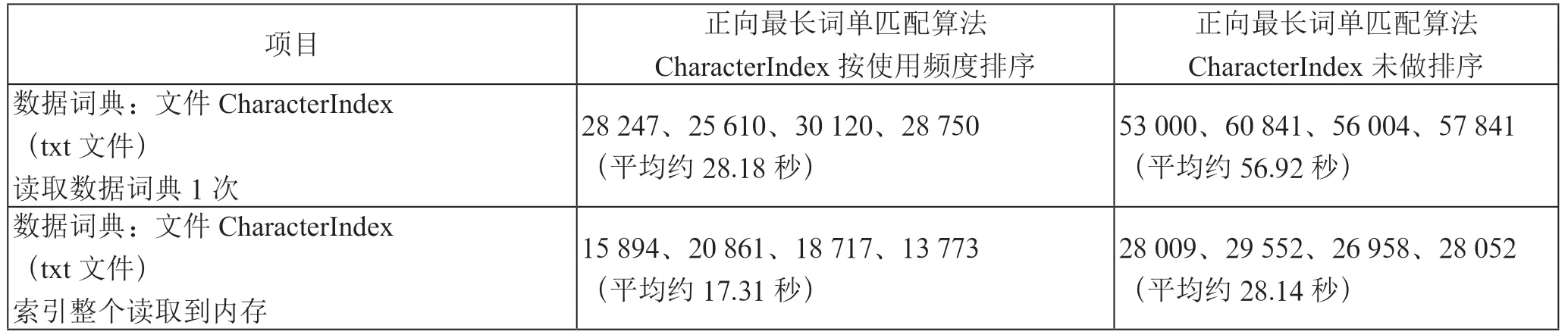
表4 不同排序索引表及读取方式的测试结果列表
4 算法应用
4.1 新词发现
很容易发现,对于个字符,如果进行排序组合的话可以有n种组词可能(包括单字符词)。对于由个字符组成的句子,在分词过程中,匹配了个词,那么新词的可能组合是(+1)/2--种(不包括单字符词)。课题小组制作的数据词典共收录汉字8 260 个,收录两个字以上的词54 165 个,相对于8 260-54 165-8 260 种未登录新词的组合,数据词典中的登录词只能算是沧海一粟。
在实验过程中发现,根据《现代汉语词典(第6 版)》制作的数据词典中,竟然没有收录“游乐场、市长、女孩、中国、舰长、更多、美国、北京、中方、我国、西部、上海、面向”等常用的词。
寻找新词的关键是找到新词组成的规律。通过观察发现,一个句子经过分词后,连续单独字符串中很有可能存在数据词典中未登录的新词,例如:分词结果“不断||科学发展|的|根基”“也有||的|自主|创业|者”中的“夯|实”“敢|闯|新|路|的”都可称之为连续单独字符串,在这些连续单独字符串中存在新词“夯实”“敢闯新路”。或者,该单独字符串前一个词或后一个词与单独字符串毗邻字符组成新词,例如:分词结果“在|”,存在新词“党中央”。课题小组根据这个规律发现新词,然后通过词长、被提取的频度、词的黏连度、词性、上下文信息关联度等来辅助新词的发现。
4.2 歧义发现
引起切分歧义的情况有很多,对于基于数据词典的分词技术,有很大一部分歧义是因该收录的词而数据词典中未收录引起的,即未登录词的分词歧义。除此之外的歧义可以分为交集型歧义、组合型歧义和真歧义三种类型。交集型歧义如“争|当时|代|先锋|”与“争|当|时代|先锋|”。组合型歧义如“维护|社会主义|法制”与“维护|社会|主义|法制”。真歧义如“乒乓球|拍卖|光|了”与“乒乓|球拍|卖光|了”。发现歧义的思路很简单,就是采用不同算法进行分词,如果得到不同分词结果就表示存在歧义。
使用正向最长词分词算法和逆向最短词分词算法的测试界面如图3所示。

图3 分词算法执行代码图
课题小组对2010年人民日报社论文章(29 871 个字符,分隔后2 676 个句子),用正向最长词分词算法和逆向最短词分词算法,得到有歧义的句子418 句,其中交集型歧义和组合型歧义各占50%左右。用正向最长词分词算法和正向最短词分词算法,得到有歧义的句子383 句。实验结果表明,最长词分词算法和最短词分词算法相互结合,更容易找出组合型歧义;正向算法和逆向算法相互结合,更容易找出交集型歧义。相形之下,使用正向最长词分词算法和逆向最短词分词算法最为高效实用。
5 结 论
课题小组采用自行设计分词算法的方式,得到基于数据库词典的最优分词算法的代码,通过数据实验对比,分析了不同分词算法的特点,阐述了不同算法在新词和歧义发现中的应用,为课题小组在中文自然语言识别、人工智能开发领域提供一定的技术支撑。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
中国外汇(2019年12期)2019-10-10
音乐天地(音乐创作版)(2019年12期)2019-02-09
疯狂英语·新悦读(2017年2期)2017-04-08
海南师范大学学报(社会科学版)(2015年7期)2015-12-28
燕山大学学报(2014年1期)2014-03-11
语文知识(2014年12期)2014-02-28
疯狂英语·原声版(2013年2期)2013-03-18
海外华文教育(2013年3期)2013-03-11
测绘科学与工程(2013年6期)2013-03-11
