
SEHive:基于类型增强的Hive强制访问控制模型与实现
2022-08-10 08:12汤定一韩伟力
计算机应用与软件 2022年7期
汤定一 韩伟力
(复旦大学软件学院 上海 200433)
0 引 言
据IDC估计,到2025年每年将产生163 ZB的数据[1]。企业可以通过数据分析得到有价值的信息。例如,大型互联网公司收集海量的用户行为信息用于发现客户需求进而提供有针对性的营销;金融企业根据海量历史交易数据训练欺诈检测模型以控制风险;医疗机构收集健康数据用于生成更好的诊疗模型。
随着数据在数量、种类和产生速度方面的增长,需要面向大数据的数据分析工具。Apache Hive作为基于Apache Hadoop[2]的数据仓库服务,提供与SQL查询语言类似的HQL查询语言,用于方便高效地对海量数据进行分析。Hive构建在Hadoop 2.x核心组件(Hadoop通用,Hadoop分布式文件系统(HDFS),MapReduce和YARN)之上,为用户提供了挖掘数据价值的能力。
为保护存储的数据安全,当前Hive访问控制模型包括以下三种:基于存储的授权、基于SQL标准的授权和Hive默认授权。(1) 基于存储的授权通过HDFS提供一种自主访问控制模型,虽然能够保护元数据不被恶意用户破坏,但是没有提供细粒度的访问控制。(2) 基于SQL标准的授权提供了一种基于角色的访问控制模型。通过SQL语句,可以创建角色,给用户赋予角色和给角色赋予操作数据的权限。但该模型需要确保用户仅通过hiveserver2访问Hive服务,且必须限制用户执行非SQL语句。(3) Hive默认授权的设计目的仅为防止用户误操作,而非防止恶意用户访问未被授权的数据。
SELinux采用强制访问控制(MAC)解决自主访问控制安全性不足的缺陷。Linux自带的自主访问控制(DAC)依据程序拥有者与文件的读、写和运行权限来决定是否允许访问。使用DAC存在两个主要问题:(1) root具有最高权限,文件拥有者可以变更文件读写权限。如果恶意用户获取了root权限,那么他就能对所有数据进行恶意操作。(2) 文件拥有者如果错误地将文件配置为任何人可读写,那么非常容易遭到恶意用户的攻击。使用MAC可以解决这两个问题,通过针对特定程序与特定文件进行权限管理,使得以root身份运行的程序也不能任意访问文件,即使文件所有者错误地分配了权限仍可能确保安全,因为每个主体只能根据域与类型的对应关系访问客体。
大数据中通常包含大量个人隐私数据,例如私人金融账户和交易信息、健康诊疗报告信息等。在处理包含隐私信息的数据时,如果在没有额外保护的情况下将其存放在集群中,将会使所有用户都能访问它,从而造成隐私泄露的风险。因此,如果要对隐私数据进行分析,必须进行身份验证和访问控制。
现有开源工具,如Apache Ranger[3],Apache Sentry[4],用于提供对包括Hive在内的Hadoop生态系统的细粒度访问。
Sentry可为存储在Apache Hadoop集群上的数据和元数据提供基于角色的细粒度授权。它的特点是对于每个数据库或框架策略是独立的,且具有由独立的管理员维护的能力。它将权限分配给角色,再将角色分配给组,这样间接通过组将角色分配给成员用户。Ranger提供基于访问策略的授权模型,由允许访问控制列表(Allow ACL)和拒绝访问控制列表(Deny ACL)来描述访问控制。它的特点是提供了一个可统一控制整个Hadoop集群安全性的管理控制台。它支持直接将权限赋予用户和组。
文献[5]概括性地将Hadoop原有授权模型、Apache Ranger和Sentry使用的模型总结为Hadoop生态系统访问控制模型HeAC。该模型直接或间接通过组和角色向用户分配不同的权限。在HeAC的基础上提出了将属性加入RBAC模型以实现更细粒度的权限管理[6]。该扩展将属性引入用户、组、服务和数据对象。同时,该模型也引入了组层次结构,根据组上定义的偏序关系,高级组从低级组继承角色。文献[7]也对基础RBAC模型进行了扩展,在HDFS文件层次结构中抽象出了数据组的概念,通过定义不同的数据组和其上的继承关系,用于简化多源异构数据的管理。这些工作和文献[8-9]均为基于RBAC模型的扩展。
文献[10]将ABAC模型与原生Hadoop相结合,提出了一个纯ABAC访问控制模型。通过主体、对象、环境或上下文来进行访问控制决策,满足多个用户在不同时间、位置和条件下以不同粒度访问数据的安全需求。文献[11-12]也将ABAC模型及其扩展应用到Hadoop平台。
综上所述,现有工作通常都是在RBAC模型和ABAC模型的基础上进行扩展。然而,在金融和医疗等对于隐私数据的保护有更高安全性要求的行业中,现有工作没有给出较好的解决方案。因此,我们提出了Hive上基于类型增强的强制访问控制模型(TE-MAC)。该模型机制与SELinux[13]采用的类型增强访问控制机制类似,解决了Hive自带的DAC模型安全性不足的问题,最大限度地减小用户可访问资源的范围,实现了最小特权原则。TE-MAC将访问主体与域关联,数据对象与类型关联,授权规则由策略文件中域与类型的允许访问规则组成。同时,引入了用户组层次关系,使得数据组拥有的域可以通过偏序关系继承,便于结构化管理权限。
1 SEHive访问控制模型:TE-MAC
本文提出了在Hive上的类型增强访问控制模型TE-MAC。此模型将域分配给用户和组,将类型分配给对象,通过域和类型之间的规则进行访问控制。其概念模型如图1所示。
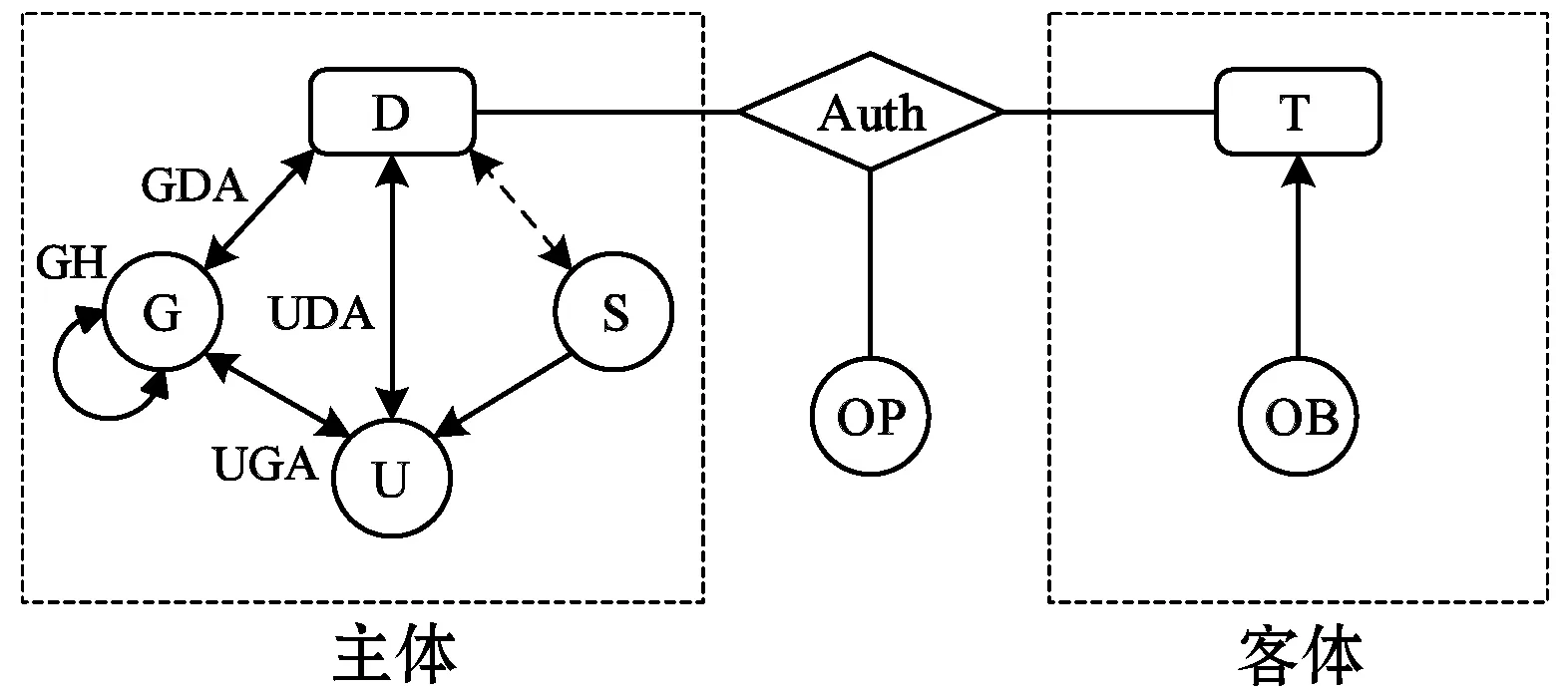
图1 TE-MAC模型对象间关系图
TE-MAC的基本组件包括:用户(U)、组(G)、会话(S)、域(D)、类型(T)、数据对象(OB)和对象上的操作(OP)。用户是使用Beeline客户端通过连接到hiveserver2进行交互以访问Hive服务和数据对象的人员。组是系统中具有相似组织职权的用户的集合。域和类型对应着访问的主体和客体,域与用户和组关联,类型与数据对象关联。在TE-MAC模型中,制定域到类型允许操作的规则,以实现类型增强的强制访问控制。
一个用户可以属于由directUG函数定义的多个组。根据directUT,用户可以拥有多个域。同理,根据directGT,组也可以拥有多个域。OBJECT-PRMS是数据对象权限的集合,它是数据对象和操作的叉积的集合。
从用户到其拥有的权限可由如下方法得到。首先,用户通过直接拥有的域或间接通过所属组拥有的域得到了拥有的域的集合。其次,通过域与类型之间的允许访问规则得到了域拥有的OBJECT-PRMS的集合。最后,通过用户通过域和类型,间接得到了拥有的OBJECT-PRMS的集合。这与基于存储的Hive授权不同,其OBJECT-PRMS直接被分配给用户和组。也与基于RBAC的Hive授权模型不同,其中通过授予或撤销用户角色来给用户分配或删除权限。这反映了TE-MAC模型的优势,可以更灵活地修改用户拥有的域、数据对象对应的类型,同时支持域和类型之间访问规则的修改,这对于灵活多变的数据组织形式更为方便。
在TE-MAC模型中,域可以直接分配给用户,也可以分配给组,相比现有的RBAC模型只支持给组分配角色更灵活。组层次结构(TH)被引入系统,G上定义了偏序关系,写为≥G。组的继承关系从低到高。比如,g1≥gg2表示g1组继承g2组拥有的域。在这个例子中,称g1是资深组,g2是初级组。在组层次结构(GH)中,组的有效域是直接分配给该组的域与其所有初级组的有效域的并集。该定义是递归的,其中最初级的组具有相同的直接分配的域和有效域。用户的有效域是用户拥有的有效域和用户所属组拥有的有效域的并集。
用户创建的会话(Session)具有用户的全部权限。会话需要具有多种权限,以访问所需的Hadoop以及Hive中的服务和对象,但会话对于服务如Yarn管理器的访问权限不在TE-MAC模型的讨论范围。TE-MAC模型的主要优点是解决了Hive自带的DAC模型安全性不足的问题,最大限度地减小用户可访问资源的范围,实现了最小特权原则。此外,它引入了组层次结构的概念,该概念使得组可以继承拥有的域并减轻安全管理员的负担。
1.1 基础对象和对象间关系
(1) 用户(U)表示具有合法访问Hive服务的用户。组(G)表示Hadoop或轻量级目录访问协议(LDAP)中的用户组。会话S表示通过Beeline客户端访问hiveserver2的连接,会话与用户之间是多对一关系,即每个用户可以发起多个会话,而每个会话对应一个用户。
(2) 数据对象(OB)表示Hive中的数据库、表、列等对象。
(3) 用户操作(OP)表示Hive中对数据对象的操作,包括增、删、查询等。
(4) 域(D)可以直接分配给用户和组,再间接通过用户和组分配给会话。会话与域之间是多对多关系,即一个会话可以拥有多个域,一个域也可以被多个会话拥有。类型(T)与数据对象是一对多关系,类型可以对应多个数据对象,每个数据对象唯一对应一个类型。
(5) 用户与组的关系directUG:U→2G,等价地,UGA⊆U×G。
(6) 用户与域的关系directUD:U→2D,等价地,UDA⊆U×D。
(7) 组与域的关系directGD:G→2D,等价地,GDA⊆G×D。
(8) 用户组的层次关系GH∈G×G,组的偏序关系使用≥g表示。令gi和gj为两个组,如果gi≥ggj成立,则gi继承gj的权限。
(9) 数据对象与类型之间的关系directOBT:OB→T,表示每个数据对象与一个类型对应。
1.2 用户和组的有效域
(1) 组的有效域代表组拥有的域的集合,由组直接拥有与间接通过偏序关系继承的域构成。定义为:
(2) 用户的有效域代表用户拥有的域的集合,由用户直接拥有与间接通过组拥有的域构成。定义为:
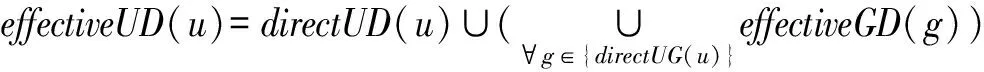
1.3 会话的有效域和权限
(1) 用户与会话的关系userSession:S→U。
(2) 会话的有效域effectiveD:S→2D,等价地:effectiveD(s)⊆effectiveUD(userSession(s))。
(3) 权限判断规则:Authorization(d,t,ops)(s:S,ob:OB,op:OP)=(d∈effectiveD(s))∧(directOBT(ob)=t)∧(op∈ops)。
策略文件中定义的规则为(d:D,t:T,ops:2OP)三元组,表示允许域以给定的操作方式访问类型,其中ops表示操作的集合。权限判断过程分为两步:首先得到会话拥有的域集合,以及数据对象的类型。其次,在规则中进行匹配,是否存在这样一条规则,使得域d属于effectiveD(S),且类型t与数据对象的类型directOBT(ob)一致,且该请求的操作op在给定的操作方式集合ops当中。
2 TE-MAC模型的实现
在开源安全工具Apache Sentry的基础上进行扩展,实现了本文提出的TE-MAC模型。Sentry的主要组件是策略引擎,策略提供器和插件。策略引擎用于根据策略控制所有对服务和数据对象的访问。策略提供器用于解析和存储策略,支持基于文件和基于数据库的策略提供器。插件是绑定到Hive服务的组件。当产生访问数据对象的请求时,插件将会调用策略引擎,该引擎将根据策略提供器中定义的策略对请求进行评估然后做出判断。如何基于Sentry实现强制访问控制机制面临三个主要挑战:1) 如何使得用户在访问时通过TE-MAC机制,而非Sentry原有RBAC策略,这需要系统化的实现。2) 策略如何存储和维护,Sentry维护的是RBAC的策略,而TE-MAC模型需要维护和提供MAC策略查询。3) 如何实现SEHive的鉴权。
对于第1个挑战,本文在插件组件中重新实现Hive会话钩子接口以配置访问控制所需要的属性。实现Hive权限验证接口以重新定义权限判断机制和返回结果过滤机制。对于第2个挑战,本文在策略提供器中实现提供器后台接口类,用于加载和解析策略文件。实现列出权限方法以返回缓存的权限。对于第3个挑战,本文在策略引擎组件中,实现策略引擎接口类,用于控制访问请求。
模型在运行时分为两个阶段,第一个阶段是策略制定和加载。安全管理员使用策略文件来制定安全策略,由策略提供器解析策略文件,将策略进行缓存。
第二个阶段是鉴权阶段,如图2所示。当在Beeline上键入一个连接到hiveserver2的命令时。该命令经过解析器阶段和语义分析器阶段。然后进入SEHive授权框架阶段。通过在hive-site.xml文件中配置的绑定层(Hive插件)探测到这次请求,将这次访问的主体和客体传递给SEHive策略引擎。策略引擎获取参数,从策略提供器中查找与之相关的规则,然后判断主体能否访问客体。
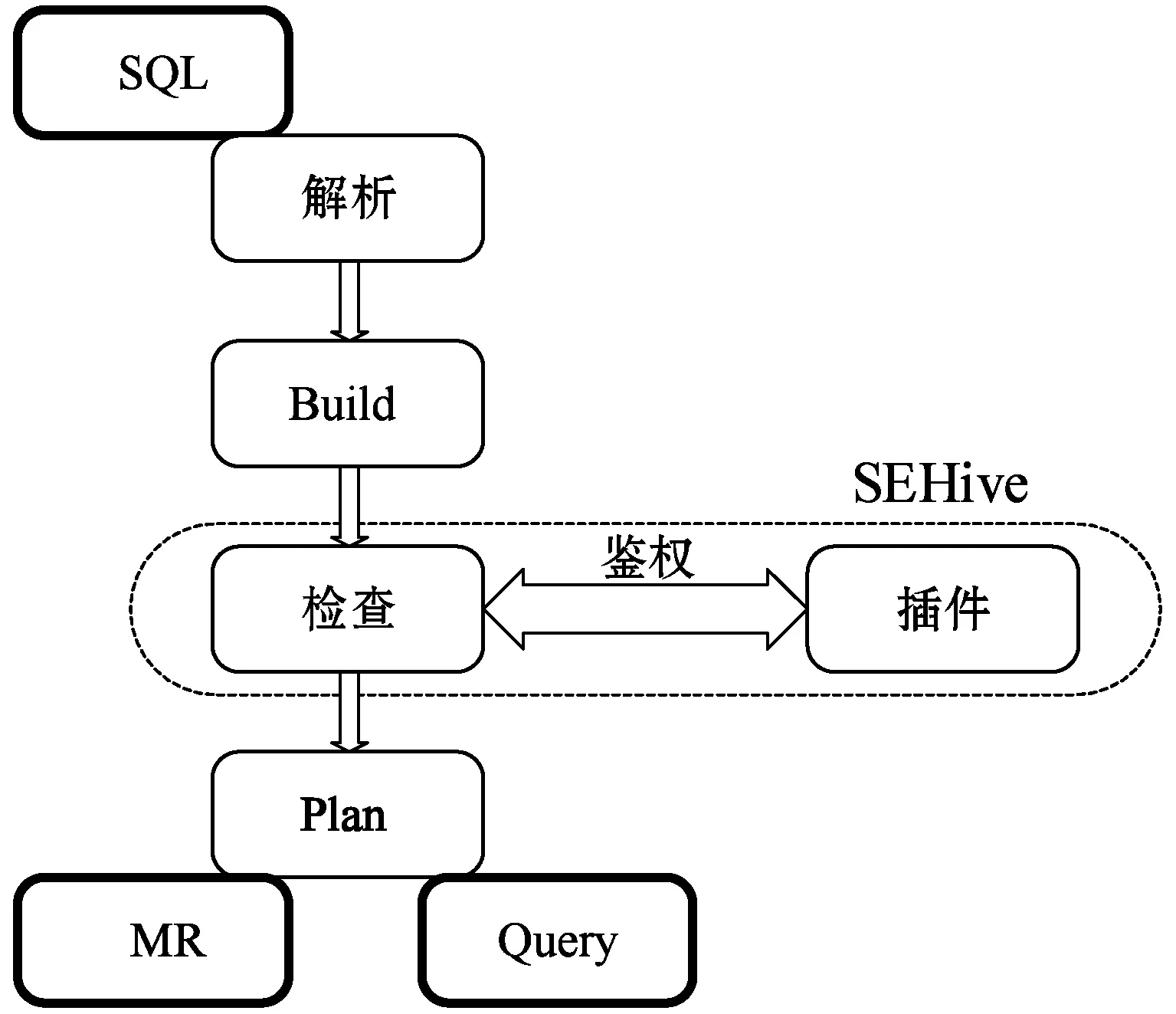
图2 HiveQL查询流程
2.1 插 件
首先配置Hive的会话钩子(Session Hook)属性,该钩子函数会在用户通过Beeline客户端连接到hiveserver2的初始化阶段调用,用于配置授权所需准备工作。通过实现HiveSessionHook接口类来进行配置。在钩子函数中,实现了以下9个操作。1) 开启Hive授权验证,使得每次访问都经过图2中所示鉴权流程。2) 配置SemanticAnalizerHook,指定该会话在提交HiveQL请求时调用的鉴权方法。3) 设置DoAS参数,该参数决定以会话用户身份或是运行Hive服务的用户身份访问HDFS。同时,需要相应地在Hadoop配置文件中进行修改以决定是否允许代理。4) 设置权限将表的所有权限赋予数据所有者。5) 设置安全命令的白名单,仅允许用户访问安全命令,其中白名单设置与Sentry相同。6) 对于每个连接用户,创建一个HDFS暂存目录,设置其目录的权限为700,即只有会话用户拥有该目录全部权限。7) 配置属性限制列表,确保安全属性不被用户修改。8) 设置会话用户,为之后的鉴权方法做准备。9) 配置作业属性为会话用户,使得Map Reduce任务的访问控制列表(ACL)为会话用户。
其次,实现SemanticAnalizerHook指定的鉴权方法。这就需要实现HiveAuthorizationValidator接口类中的checkPrivileges方法和filterListCmdObjects方法。其中checkPrivileges方法用于检查会话用户是否有在给定的输入和输出对象上执行给定的操作类型的权限。filterListCmdObjects方法用于根据当前用户的权限对结果选择过滤。首先通过将操作映射到权限的预定义映射表,将操作转换为对应权限。然后树形遍历访问列表中的数据库和表,将可访问的数据库或表作为结果返回。如果没有访问权限或访问列表为空将通过抛出错误来拒绝访问。
2.2 策略提供器
策略提供器负责从策略文件中加载和解析策略,然后在数据结构中进行缓存,并提供其他模块可以获取权限的方法。需要实现ProviderBackend接口类。其中包含用于获取域到类型访问规则的getPrivileges方法,以及用于获取用户所拥有域和数据对象所拥有类型的getTypeEnforcement方法。实现PolicyFiles类用于加载和解析基于TE-MAC模型的策略文件。
2.3 策略引擎
策略引擎主要提供判断访问是否被允许的方法。根据传入的主体,客体和操作所需权限。首先根据主体请求策略提供器,得到会话的有效域集合effectiveD(s)。其次,得到客体的类型。最后,在访问规则中进行匹配,判断是否允许访问。通过实现PolicyEngine接口类的validatePolicy方法,同时该类需要维护ProviderBackend的对象用于获取权限。
2.4 策略文件
策略文件共分为4个部分。第一部分描述用户与域的映射和组与域的映射。它们是多对多的关系。第二部分描述不同组之间的偏序关系。组的层次结构可以视为有向无环图,每个偏序关系为图中的一条有向边。第三部分描述数据对象与类型之间的关系,每个数据对象对应一个类型。第四部分描述访问规则,一条规则包括由域,类型和允许的操作组成的三元组,表示允许域以给定的操作方式访问类型。
3 SEHive的实现
本节将Hive置于Hadoop生态中,站在整体的层面来分析。图3展示了多层访问控制决策和执行点,用于对包括Apache Hive和HDFS之类的服务中的资源进行授权访问。该架构描绘了几个Apache项目如何协同以实现SEHive。
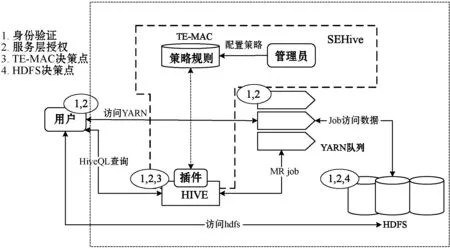
图3 Hadoop整体安全机制架构
首先,Kerberos可用于用户和身份管理以提供身份验证。
用户通过身份验证后,第一层访问控制机制为服务层面的授权。该层控制对Hive等Hadoop生态系统服务的访问,远早于访问Hive服务所提供的数据。它还检查是否允许用户访问Hadoop守护程序(例如Hadoop NameNode,YARN资源管理器)以提交任务或查询状态。
通过服务层授权之后,当用户尝试通过Apache Hive数据服务发出HiveQL命令时,被SEHive模型在Hive中配置的插件检测到,调用TE-MAC模型中的策略引擎进行鉴权操作,这是第三层访问控制机制。由于Hive中的数据对象存储在HDFS中,可以根据需求配置为两种模式,其区别在于用户是否需要具有HDFS中对象的访问权限。因此第四层访问控制机制为HDFS层面的授权。
我们通过实际应用场景对这两种模式进行讨论。在模式一中,数据分析师可以通过Apache Hive使用HiveQL访问数据,但可能不允许通过MapReduce作业访问HDFS中相应的数据文件。在这种情况下,发出HiveQL命令的用户被更改为运行Apache Hive服务的用户。在模式二中,审计员可能需要同时具有Apache Hive和HDFS中对应数据访问权限。通过配置SEHive的插件组件中DoAS属性来满足这两个用例的需求。假设Alice是通过会话访问Apache Hive的用户,而Bob是运行Apache Hive服务的用户。将DoAS设为false,运行HiveQL的用户是Bob。对于DoAS为true,Alice在Hive和HDFS上都必须具有访问数据的权限。
发出HiveQL命令时,如果SEHive中的DoAS属性为true,还需要用户具有访问YARN队列的权限,因为该命令会导致MapReduce或Tez任务,该任务也将提交给YARN队列。由于这些任务将访问HDFS中的数据,因此用户也应具有HDFS文件的权限。
通过这四层安全机制,SEHive通过与其他安全机制集成,能够实现用户在发出HiveQL命令时得到保护。确保从身份验证到访问Hive服务授权,再到访问Hive中提供的数据和HDFS中存储的数据,以及执行MapReduce任务的Yarn队列在访问数据时的安全。
4 SEHive的评估
本节通过实验来说明模型的有效性。实验在一台CPU配置为Intel(R)i7- 4790 CPU @ 3.60 GHz,具有32 GB RAM,安装64位Windows系统的计算机上进行。使用VMware软件构建了3台Ubuntu 16.04虚拟机,每个虚拟机具有4 GB RAM和单核CPU。每个虚拟机中安装Hadoop 2.8.1,构成一个由三个节点组成的Hadoop集群,其中一个是主节点,另外两个是从节点。Apache Hive 2.1.1安装在主节点上。
4.1 用 例
考虑以下应用场景,Hadoop集群中有三个用户Alice、Bob和Manager。这三个用户以不同的权限访问同一Hadoop集群中的数据。它们都能使用Beeline客户端访问Hive服务。Bob允许查看car database下customer表中的数据,以及car database下facilities表中的数据,但不能对这两张表进行修改操作。仅允许Alice访问car database下customer表中的数据,同时可修改该表中的数据。但facilities表对其不可见。而他们共同的上级Manager同时拥有他们的权限。
定义组sale、analyst和manager。其中manager≥gsale,manager≥ganalyst。sale组包含的域为sale_t,analyst组包含的域为analyst_t。根据组的偏序关系,manager组包含salt_t和analyst_t域。customer表对应的类型为customer_t,facilities表对应的类型为facilities_t。
权限定义如下:
策略1:Allowsale_tcustomer_t{getattrreadwrite}
策略2:Allowanalyst_tcustomer_t{getattrread}
策略3:Allowanalyst_tfacilities_t{getattrread}
根据策略1可知,拥有sale_t域的用户拥有类型为customer_t的数据对象的查看、读和写权限。根据策略2和策略3可知,拥有analyst_t域的用户拥有类型为customer_t和facilites_t的数据对象的查看和读权限。通过组层次结构,简化了域的分配。
下面通过实验来验证模型的有效性。首先在策略文件中配置组的偏序关系、用户和组与域的对应关系、数据对象与类型的对应关系,以及访问策略。当Hive服务启动时,插件从本地策略文件加载策略。
依次使用Alice、Bob、Manager和任意其他用户,通过Beeline访问hiveserver2。使用select * from customer和select * from facilities选择数据,其中select需要read权限。使用load data local inpath’/tmp/tmp_file’ into table customer向customer表中写入数据,其中load需要write权限。各用户执行命令成功与否的状态如表1所示。实验表明,TE-MAC能够最大限度地减小用户可访问资源的范围,实现了最小特权原则。
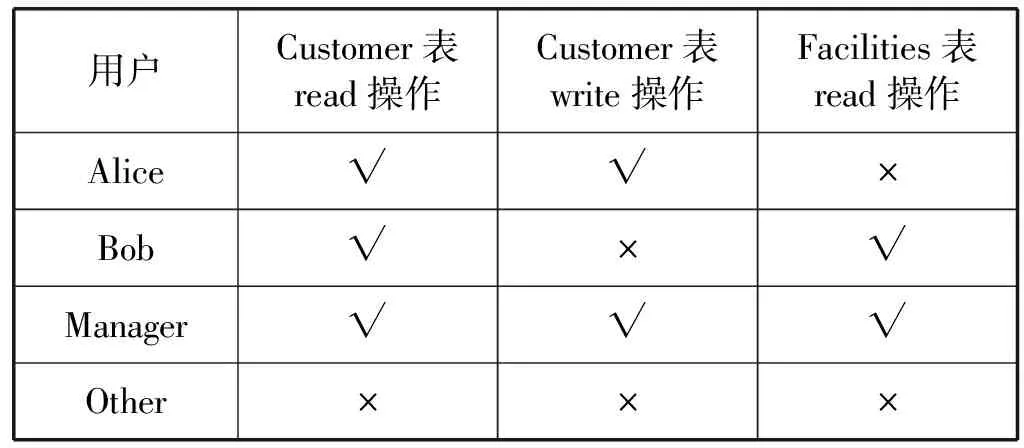
表1 各用户对于表的访问权限
4.2 性能评估
本文通过衡量SEHive模型在访问控制阶段所需时间随访问控制策略数量的变化来进行性能评估。
如图4所示,SEHive模型在访问控制阶段的耗时随策略数量增加呈增长趋势。耗时的增加主要是由于在更多的策略中进行检索所带来的。当策略数量在1 000以内时,SEHive耗时在3 ms以内。当策略数量达到10 000条时,耗时20 ms。当策略数量达到100 000条时,TE-MAC耗时356 ms。而HiveQL查询耗时通常在秒级别或者更多,因此TE-MAC在访问控制阶段的耗时对查询总耗时影响较小。
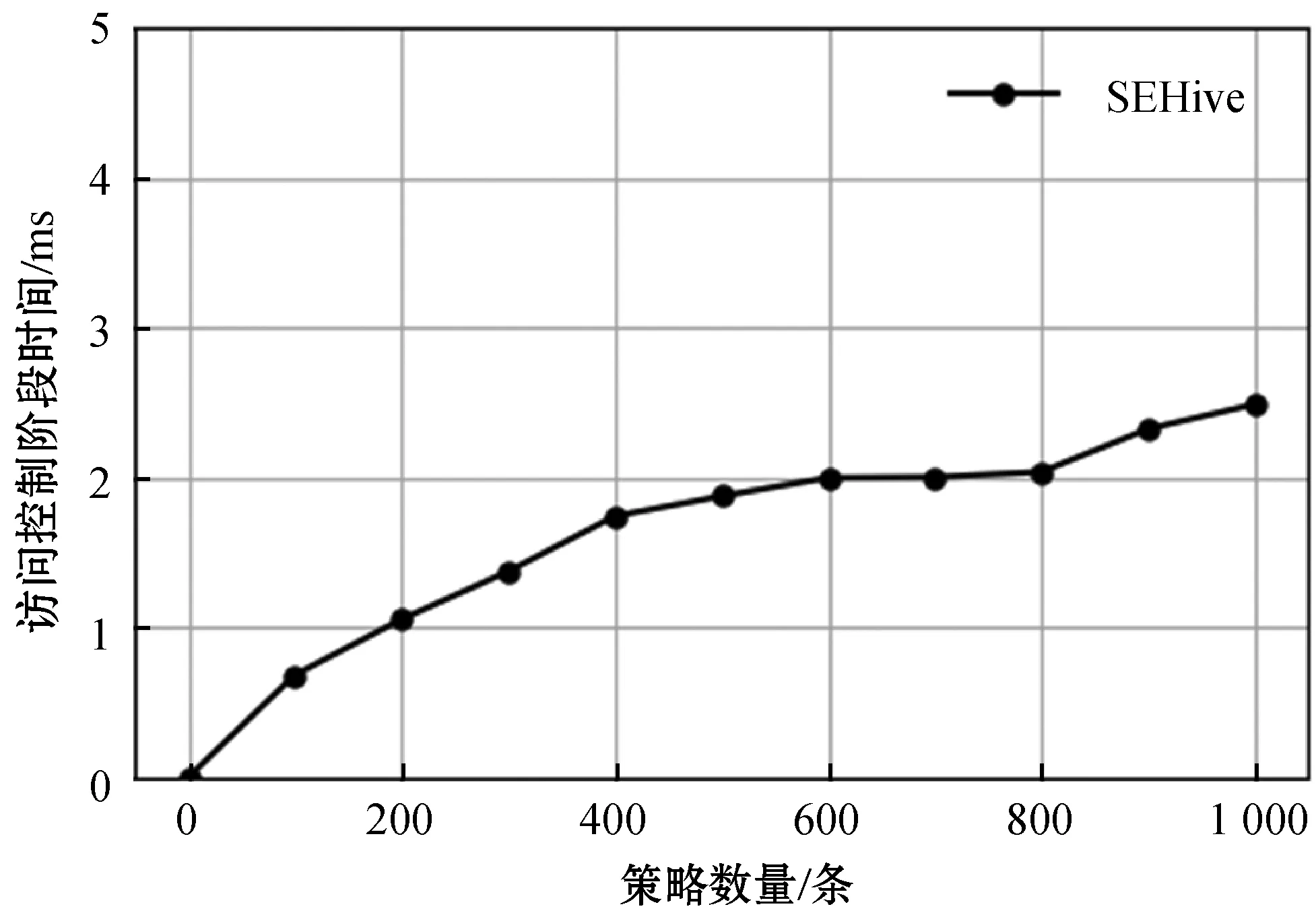
图4 访问控制阶段时间随策略数量变化
5 结 语
本文针对Hive中如何实现强制访问控制,提出了TE-MAC模型。该模型采用了与SELinux中类似的类型增强的强制访问控制机制,将主体与域关联,客体与类型关联,根据域和类型之间的访问规则控制访问,最大限度地减小用户可访问资源的范围,实现了最小特权原则。同时,引入了组的层次结构,通过偏序关系继承域,便于结构化的权限管理。本文在Apache Sentry的基础上实现了SEHive模型。同时,将Hive置于Hadoop中,通过多层访问控制实现了SEHive。最后,通过实验分析验证了模型的有效性,实验说明SEHive在访问控制阶段的耗时对HiveQL查询影响较小。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
小天使·三年级语数英综合(2022年4期)2022-04-28
廉政瞭望·下半月(2021年5期)2021-07-20
中文信息(2018年6期)2018-08-29
意林(2018年3期)2018-03-02
汽车生活(2018年1期)2018-02-02
汽车导报(2017年5期)2017-08-03
中国新通信(2017年3期)2017-03-11
中学生数理化·高二版(2016年4期)2016-05-14
好家长·青春期教育(2014年7期)2014-07-05
