
基于少样本学习的农业领域短文本分类研究
2022-08-10 08:08麻之润董慧洁
湖北农业科学 2022年13期
麻之润,费 凡,黎 芬,董慧洁,彭 琳
(1.云南农业大学大数据学院,昆明 650000;2.绿色农产品大数据智能信息处理工程研究中心,昆明 650000)
随着信息技术的发展,互联网沉淀了大量的文本数据。在农业领域如农业气象、农资商品等,这些文本多以短文本的形式出现。如何对这类文本信息进行有效分类,既方便网络维护运营者的管理以及发掘其信息价值,又能够让大众方便快捷地选择自己感兴趣的内容,这是文本分类方向研究的热点问题。
文本分类任务是自然语言处理领域的一项基础且十分重要的工作,是当前该领域的研究热点之一。该任务主要指根据已经定义好的类别标签对现有的一段文本进行标注。分类的文本又分为长文本和短文本;和长文本相比,短文本的时效性更强,具有明显的数据稀疏性,同时也存在着高噪声、高度依赖上下文语境等问题[1],这是现阶段短文本分类面临的难点问题。
1960—2010 年,研究人员主要基于统计模型来研究文本的分类,如朴素贝叶斯(NB)模型、K 近邻(KNN)方法、支持向量机(SVM)方法等。Maron[2]研究了一种根据文档内容自动分类的方法;李静梅等[3]在假设特征独立性的基础上,就朴素贝叶斯的原理和应用等问题进行讨论,并通过期望值最大法提高了其分类精度。余芳[4]基于web 文本的特征利用朴素贝叶斯算法实现了一个文本分类系统,并获得了很好的分类效果。Cover 等[5]提出了一种最近邻决策规则用于文本分类。庞剑锋[6]提出了一个能够有效将文本分类算法和反馈方法相结合的方法,并建立了可行的系统。湛燕[7]基于K-近邻、K-均值算法,提出了一种学习权值算法可以间接的优化聚类结果。Joachims[8]讨论了如何使用支持向量机运用在文本分类任务中。2009 年,TF-IDF 通过TF 词频和IDF 逆文本频率指数来评估单词或者片段短语对一个完整语料库的影响程度,如果一个陌生词语在某篇随机的文章中出现的频率很高,但是在这个完整语料库中出现的频率较低,则其TF-IDF 值较高,即重要程度较高[9]。Mikolov 等[10]提出了新颖的word2vec 模型,用于从庞大数据集中计算单词的连续矢量表示。Pennington 等[11]提出了一个新的全局对数线性回归模型,在多项任务方面优于相关模型。
随后文本分类进入从机器学习到深度学习的快速发展道路。Kim[12]提出了一种用于文本分析的CNN——TextCNN。Iyyer 等[13]提出了一个简单的深度神经网络DAN,与同类模型相比仅需花费少量培训时间就能够获得同等的成绩。Tai 等[14]提出了一种LSTM 对树型网络拓扑的概括Tree-LSTM,在一些任务上强于LSTM。Grave 等[15]探讨了一种简单有效的文本分类方法FastText,并获得了良好的效果。2017 年,Vaswani 等[16]提出了几乎仅靠注意力来完成任务的Transformer 模型,同时提出了可伸缩点积注意力。上述方法虽然在文本特征提取能力方面有了提升,但仍需要大量的文本数据作为支撑。
本研究中的“少样本”是指维度小、数量小的样本[17],短文本指不超过200 个字符的文本[18]。对于文本分类任务,目前常见的方法都需要基于大规模的人工标注数据集。对于农业领域的文本,大规模标注数据成本很高,而且需要与原来的数据一起进行重新训练。在图像领域借助少量样本对新样本进行分类的技术发展比较成熟,文本领域目前没有广泛应用的成熟技术[19]。Vinyals 等[20]定义了一个少样本数据集miniImageNet,一共有100 个类别,每个类别有600 个样本,用于少样本的研究。Han 等[19]在EMNLP 2018 中提出了一个少样本的关系数据集,包含64 种关系用于训练,16 种关系用于验证和20 种关系用于测试,每种关系包含700 个样本。本文基于此展开研究,提出的方法可以借助少量的样本对农业领域的文本进行分类。
1 相关理论
1.1 少样本学习
少 样 本 学 习(Few sample learning,Few-shot learning,FSL),也称小样本学习(One sample learn⁃ing)[21]或单样本学习(One-shot learning),可以追溯到21 世纪初[22]。这里few-shot 有计量的意思,指少样本学习,机器学习模型在学习了相当类别的数据后,只需要少量的样本就能够快速学习,对应的有单样本学习,可看作样本量为一情况下的一种少样本学习。少样本学习按照使用方法可分为3 种。①模型微调法。数据集分布相似的前提下,在目标小数据集上对源数据集训练好的分类模型进行个别层参数微调,该方法因数据集分布不同易产生过拟合的结果。②数据增强法。利用辅助信息增强样本特征,如添加标签数据进行样本数据扩增、添加多样特征进行样本特征空间增强,便于模型提取特征,该方法因增加数据信息易引入噪声数据。③迁移学习法。在一定关联下,利用学会的知识和特征迁移到新知识的学习。本文主要从迁移学习模型方面着手展开少样本学习研究。
1.2 预训练模型
预训练的思想究其本源是模型的全部参数不是以往的随机初始化,而是通过特定任务(例如语言的模型)进行一些预训练。试验表明,在大型的完整语料库中进行预训练(PTMs)能够习得通用语言的表示,而这对之后的NLP 具体任务很有帮助,避免了从最初开始训练新模型。
预训练模型自提出后便得到飞速发展,先后出现了ELMo[23]、ULMFiT[24]、BERT[25]、XLNet[26]等先进的预训练语言模型。其中Devlin 等[25]引入了一种称为BERT 的表示语言模型,它用Transformer 双向编码器表示,目的是联合调节(jointly conditioning)所有层的左右和上下文,进而预训练其深度双向的表示,以此证明双向的预训练对语言的表示非常重要,同时也证明了预训练表示的便捷性,减少了众多复杂的特定任务设计等需求。Transformer 结构模型抛弃了传统的CNN 和RNN,整个网络结构是由Atten⁃tion 机制完全组成。更准确地说,Transformer 仅由self-Attention 和Feed Forward Neural Network 组 成。本 质 上,Transformer 是 一 个Encoder-Decoder 的 结构,其左侧是编码器,目的是使语料经过输入后能够生成相应的特征向量;右侧是解码器,其输入有两部分构成,一部分是左侧编码器的输出结果,另一部分是已经预测的结果,目的是获得最终的条件概率。其具体结构如图1 所示。
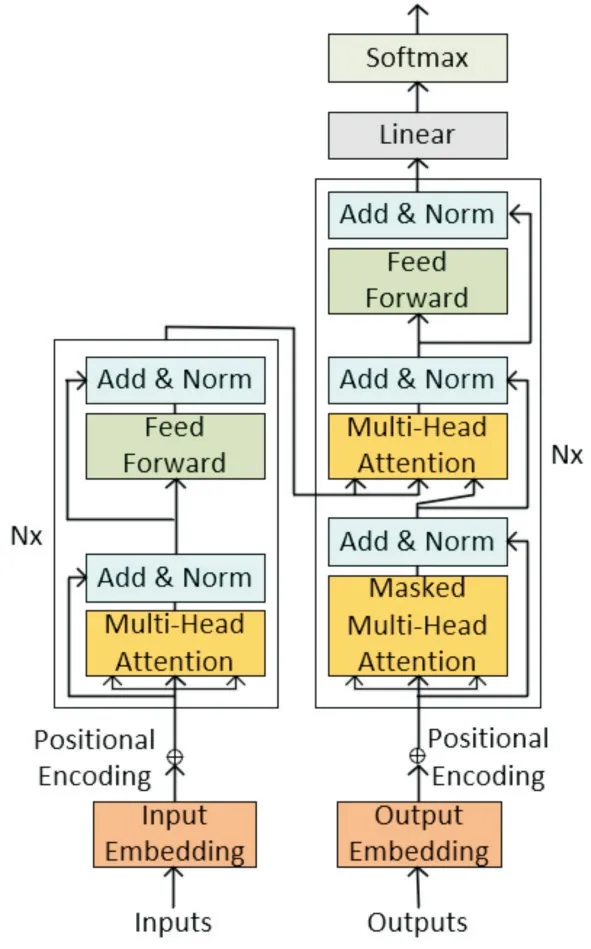
图1 BERT 中应用的Transformer 网络
其中,Attention(Q,K,V):Attention( )
Q,K,V=softmax,Feed Forward Neural Network 的全连接层第二层线性的激活函数为FFN( )
Z=max(0,ZW1+b1)W2+b2
BERT 模型针对的是英文或字的word 粒度的完形填空学习层面,并没有考虑运用训练数据中的词法、语法结构以及语义的相关信息,并以此来建模学习。相对而言,百度的ERNIE 模型先是对词和实体等语义单元进行掩码操作,能够让模型了解完整语义的表示;ERNIE 用训练数据中的词法、语法的结构以及语义中的相关信息来统一建模,在语义表示方面较大地提高了其通用表示的能力。BERT 模型和ERNIE 模型的遮掩策略区别如图2 所示。

图2 BERT 和ERNIE 之间不同的遮掩策略
2 试验
2.1 数据获取
本试验数据从淘金地-农业网的农业问答板块问答分类页面爬取,遵循国家法律与该网站的爬虫协议——robots.txt,并保证该数据仅用于此次文本分类研究,不外传与分享,不用于商业用途。首先分析了该网站的可视化结构与前端代码,知悉其数据传输方式为get 方式;再查看代码,找到其页面所需要的问答信息的具体标签,判断该标签是否能准确地定位到这个问题,判断该标签的惟一准确性;然后判断不同问题页面实现翻页的方式方法;最后尝试爬取单独页面并将信息写入csv 文件中,成功后调试代码,逐步实现爬取所有问题页面的相关信息并逐行写入csv 中。利用Scrapy 框架、Urllib、Requests等库,运用python 编程语言,从html页面的特定标签中爬取问答分类页面所有问句对,存入csv 文件中。该问句对分为养殖技术、粮油种植、蔬菜种植、瓜果种植、药材种植五大类,又可分为问题集和满意答案集。
2.2 数据清洗
数据清洗是整个数据分析过程中极其重要且不可或缺的一个环节,是对获取数据进行再一次审查与校对核验的过程,主要为了舍去多余重复的信息,改正现存的错误问题,直至可以获得一致的数据。常见的数据清洗步骤分为预处理阶段的数据导入与查看、缺失数据清洗、格式内容清洗、逻辑错误清洗、不相关数据清洗和验证关联性等。本研究共爬取了10 000 多条数据对,经过分析发现有部分残缺值并删除,部分重复值经过对比后删除,部分数据带有特殊格式和符号经正则表达式删除。通过上述环节对残缺数据、错误数据、重复数据进行审查与删除,后经人工随机校对,保留了12 433 条问句对。对该数据集进行分析处理,然后分组,S0 组为5 大类全量数据集,S1 组为5 大类等比缩小数据集,S2、S3、S4 为继续等比例缩减后的5 大类数据集。
随机从短文本问题集中选取其中的70% 数据作为训练集,20% 数据作为测试集,10% 数据作为验证集,数据集统计如表1 所示。部分问题集训练语料见表2。

表1 数据集统计 (单位:条)

表2 部分问题集训练语料
首先将预处理好的数据集输入基于BERT 和ERNIE 预训练模型进行文本表示,具体过程为:将输入数据转换成嵌入向量X,根据嵌入向量得到q,k,v3 个向量,分别为每个向量计算score(score=q×k),用score 归一化操作(),达到稳定的梯度,对score 施加以softmax 激活函数。再分别取出本数据集的表示向量,该向量携带了大量的背景信息,具有丰富的表达能力。最后将这些向量输入全连接层,经过一系列的权重调整,得到分类结果。分类模型结构如图3 所示。同时,将处理好的数据集在决策树模型上做对比试验。

图3 分类模型结构
2.3 试验环境
1)试验硬件。CPU 为Intel Xeon E5-2678 v3,内存容量为128G,内核为48 核,显卡为GeForce RTX 3090,显存容量为24 GB,操作系统为Ubuntu 18.04.5 LTS,Python 版本为3.8,PyTorch 深度学习框架,框架版本1.7.1,Cuda 版本为11.0。
2)参数设置。BERT:batch_size=128,pad_size=32,learning_rate=5e-5,hidden_size=768,num_epochs=6;ERNIE:batch_size=128,pad_size=32,learn⁃ing_rate=5e-5,hidden_size=768,num_epochs=6。
2.4 评价标准
本研究从试验评价指标的准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值来对决策树模型基于BERT 模型和ERNIE 模型的农业短文本分类算法的分类结果展开分析。
准确率(Accuracy)指分类器分类正确的样本与总样本之比。
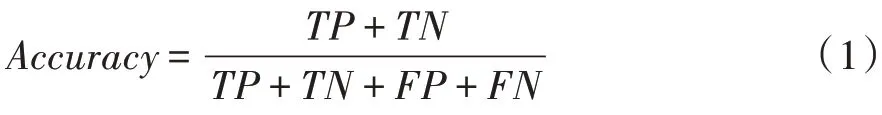
精确率(Precision)也称为查准率,指分类正确的正例个数与分类为正例的实例个数之比。

召回率(Recall)也称为查全率,代表分类正确的个数与实际正例的个数之比。

F-Measure 为精确率和召回率的综合评价指标。
当β=1 时,


式中,TP代表正例的样本预测依然为正例,FP代表负例的样本预测为正例,FN代表正例的样本预测为负例,FP代表负例的样本预测依然为负例。
2.5 试验结果
对比试验结果见表3。由表3 可以看出,小样本数据集中,随着数据量的变少,不论是传统模型还是预训练模型,准确率、精确率和召回率均存在下降趋势;而基于ERNIE 预训练模型的准确率、F1值处于较高水平,远高于同数据的决策树模型。因此,本研究提出的基于BERT 模型和ERNIE 模型的农业短文本分类算法能够在数据量不足的情况下,便捷、有效地识别出文本所属的农业领域类别。

表3 对比试验结果 (单位:%)
3 小结
本研究在处理农业领域短文本分类任务时,面对该领域经过标注的文本数据稀缺的现状,以及对大量无标签数据进行标注又耗费人力物力的问题,构建了适用于农业短文本分类的小样本数据集,并根据数据量的大小分成不同的组别;然后构建了基于BERT 和ERNIE 预训练模型的农业短文本分类算法,并与基于决策树模型的农业短文本分类算法进行对比分析。结果表明,构建的农业短文本分类算法能够在数据量不足的情况下依然获得较高的分类效果。下一步还将在农业领域文本数据集的基础上继续完善模型和开发应用系统。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
时代英语·高二(2018年7期)2018-12-03
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
时代英语·高二(2018年3期)2018-06-06
初中生世界·七年级(2017年9期)2017-10-13
中国老区建设(2016年1期)2016-02-28
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
