
基于XGBoost算法的上市公司财务报表舞弊识别研究
2022-08-09 06:16吴贞如
计算机时代 2022年8期
吴贞如
(南京审计大学信息工程学院,江苏 南京 211815)
0 引言
财务报表是反映公司财务状况、经营业绩以及可持续发展情况的结构性描述,是投资者、股东、债权人、公司员工以及其他利益相关者决策的主要的参考文件。目前,财务报表的真实性主要依赖于管理者的道德标准、财务报表的稳健审计以及审计师出具的审计报告和意见。但是,大多数财务报表舞弊是在管理层意识到或同意的情况下实施的。近年来,国际资本市场的一体化和经济模式的复杂化给新兴市场投资带来巨大的商业挑战,操纵财务报表以逃避本国税收或将资本转移到海外的动机和机会持续增加。相关文献研究表明,当前财务报表舞弊现象十分严重:犯罪分子越来越擅于规避监管机制,舞弊行为越来越复杂。此外,根据美国注册舞弊审查员协会发布的《2020 年全球职务舞弊与滥用职权调查报告》数据,虽然财务报表舞弊的发生频率低于资产挪用和腐败等因素,但是造成的经济损失却远高于其他舞弊,严重损害了资本市场的可持续发展。因此,识别财务报表舞弊行为,对维护投资者的利益和保障资本市场的可持续发展具有重要意义。
随着计算机技术的高速发展,各领域进入大数据和人工智能时代,机器学习因为能够快速有效地处理大量数据被广泛应用。基于机器学习算法构建财务报表舞弊行为识别模型能够改善传统财务报表舞弊识别方法过度依赖人力的不足。因此,本研究基于机器学习中的XGBoost 算法构建财务报表舞弊识别模型,提高财务报表使用者对潜在舞弊的意识,识别财务报表舞弊行为,减少因财务报表舞弊行为造成的损失,维护资本市场的可持续发展。
1 研究现状
Hamal和Senvar认为财务报表舞弊识别需要复杂的分析工具和技术,而不是审计师所采用的传统方法。财务报表舞弊识别是一个典型二分类问题。作为人工智能的重要分支,机器学习是解决分类问题最前沿的方法和技术。Gupta 和Mehta通过实验证明使用机器学习算法构建的财务报表舞弊识别模型比传统的方法具有更高的准确性。相比于传统的统计方法,基于机器学习算法不但可以处理大量数据进行更准确的分类和预测,而且不需要像传统的统计方法进行假设,可以更有效地处理非线性问题。
近年来,诸多学者基于机器学习方法构建财务报表舞弊识别模型,并从不同的角度,使用不同的方法进行研究。Chyan-Long分别使用人工神经网络和支持向量机筛选出重要的财务变量和非财务变量,然后使用分类回归树、卡方自动交互检测器、C5.0 和快速无偏高效统计树等四种决策树进行分类,通过实验证明用人工神经网络筛选并用分类回归树处理变量构建的财务报表舞弊识别模型准确率最高。Yao等人分别采用逐步回归和主成分分析降低变量维度,使用支持向量机、分类与回归树、反向传播神经网络、逻辑回归、贝叶斯分类器六种机器学习方法识别财务报表舞弊行为,通过实验表明基于逐步回归和支持向量机融合方法构建财务报表舞弊识别模型的准确率最高。黄志刚等人使用逻辑回归前向步进的方法筛选出敏感指标并构建整体舞弊敏感指标集输入到朴素贝叶斯、随机森林、K 邻近算法、支持向量机等机器学习算法中,并发现随机森林、支持向量机在识别上市公司财务报表舞弊行为的准确率都超过了80%。
2 研究方法
2.1 数据采集
本研究使用的数据来源于中国股票市场与会计研究(CSMAR)数据库中的2011-2020年深沪A股上市公司年度财务报表,其中选取了283个舞弊财务报表,共涉及126 家上市公司。为控制外部环境和行业因素,本研究在选取非舞弊样本时参照两个准则:一是舞弊样本数据和非舞弊样本数据涉及的上市公司属于同一个行业,二是舞弊样本数据和非舞弊样本数据来自同一个年度。按照这两个准则,并以1:2 的匹配比例选取252 家上市公司共566 个非舞弊财务报表。最终,本研究选取849 个财务报表作为财务报表舞弊识别模型的检测样本,共涉及378 家上市公司。样本行业类型汇总和样本年份分布情况如表1和图1所示。
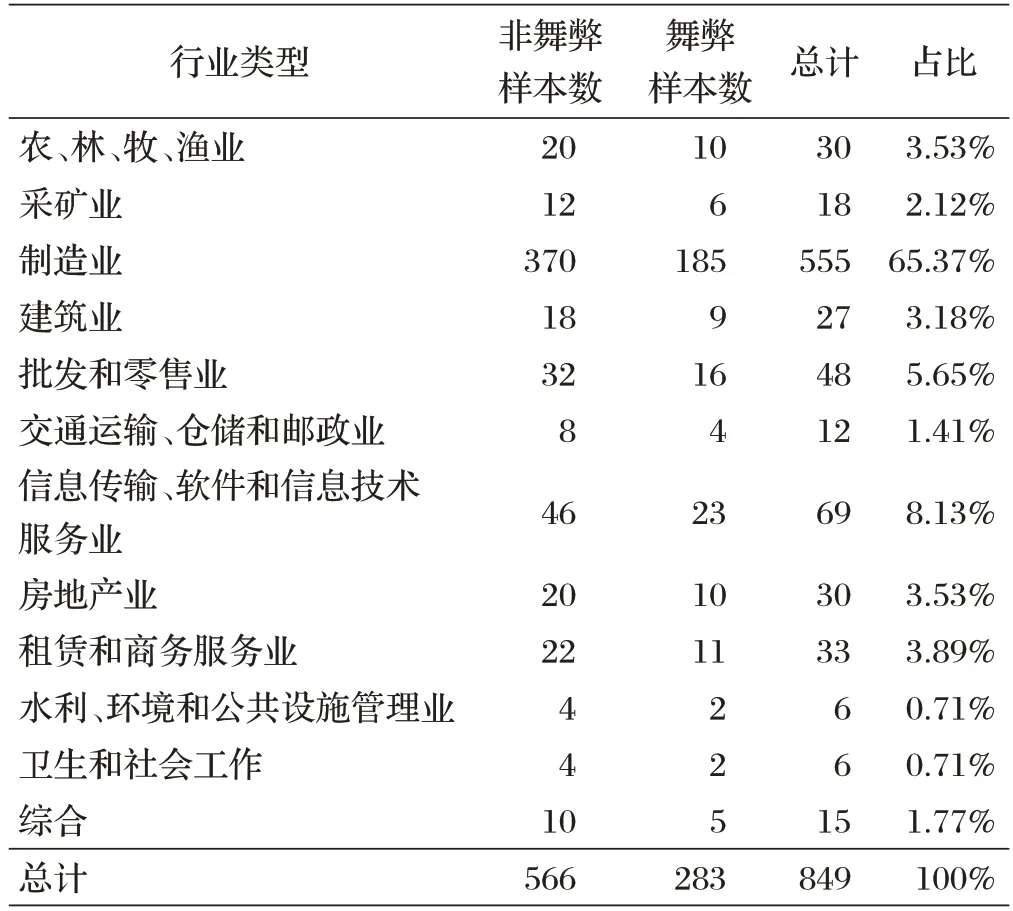
表1 样本行业类型汇总
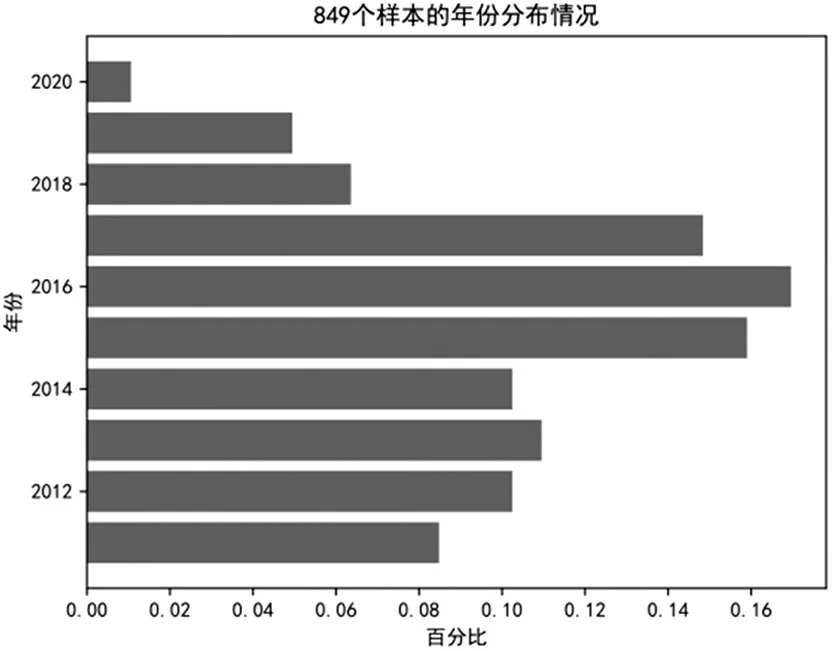
图1 样本年份分布情况
从表1 可以看出,制造业上市公司涉及财务报表舞弊最多,占比超过50%。从图1 可以看出,2015~2017年期间,财务报表舞弊发生的频率偏高。
2.2 变量选取
2.2.1 变量初选
为提高模型预测的准确率,选择合适的财务舞弊识别指标十分关键。因此,在现有的研究基础上,基于五个维度,即偿债能力、经营能力、盈利能力、发展能力和治理结构,本研究初步选取26个用于衡量财务报表舞弊的指标,分别由22 个财务变量和4 个非财务变量组成,如表2所示。

表2 初选变量
2.2.2 变量筛选模型
信息值(IV)可以评价变量对目标影响程度的指标,即衡量变量的预测能力。信息值的计算是基于证据权重(WOE),一种通过分组处理原始变量的编码形式。对于第i组,证据权重的计算如下。

其中(x|X)是分组后本组财报舞弊样本数占总财报舞弊样本数的比例;(y|Y)是分组后本组财报非舞弊样本数占总财报非舞弊样本数的比例。因此,证据权重越大,财报舞弊样本数量越多。信息值是通过证据权重的加权求和计算得来的,其计算如下。
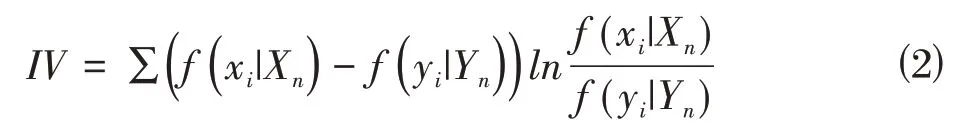
由公式⑵可知,信息值为非负数。变量的信息值越大,表明该变量对目标分类的预测能力越强。因此,本研究引入信息值构建财务舞弊指标筛选模型,各个初选指标的信息值如图2所示。
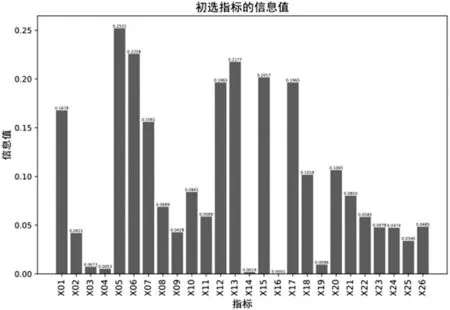
图2 财务舞弊识别初选指标信息值
信息值大于0.03 为具有预测能力的指标。因此,本研究最终选取了21个指标:流动比率(X01)、速动比率(X02)、存货周转率(X05)、应付账款周转率(X06)、应收账款周转率(X07)、应收账款与收入比(X08)、总资产周转率(X09)、存货与收入比(X10)、股东权益周转率(X11)、资产报酬率(X12)、投入资本回报率(X13)、总资产净利润率(X15)、长期资本收益率(X17)、总资产增长率(X18)、营业总收入增长率(X20)、营业总成本增长率(X21)、每股净资产增长率(X22)、独立董事所占比例(X23)、董事会持股比例(X24)、监事会持股比例(X25)、十大股东持股比例(X26)。
2.3 XGBoost算法
XGBoost 算法基于梯度提升树算法,在目标函数中增添了正则化项,可以降低模型的复杂度,避免过拟合,其目标函数如公式⑶和公式⑷所示:
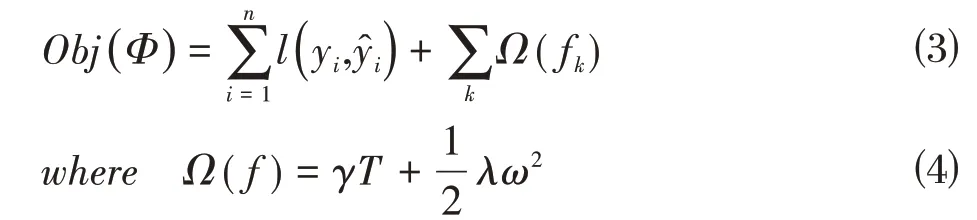
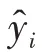
XGBoost算法在目标函数的求解过程中进行迭代操作以及二阶泰勒展开,如公式⑸所示,提高了求解速度和模型的训练速度。
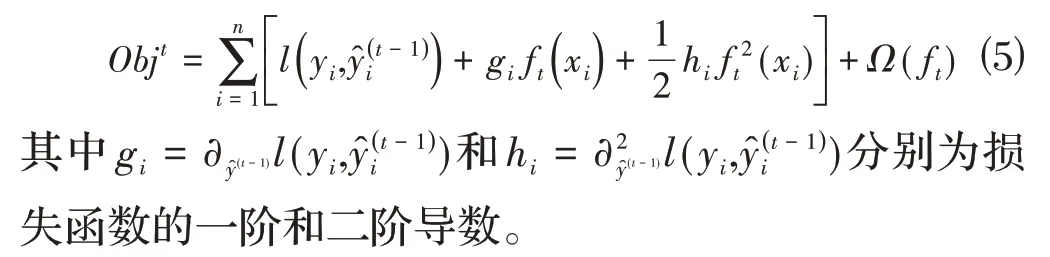
XGBoost 算法提前对特征值进行排序,然后保存为块结构,所以能够最大化地确定分割点的标准。此外,为满足数据处理后的特征值是稀疏的情形,XGBoost 算法对缺失值设置一个确定的引流,进而大幅度地提高算法的效率。
2.4 模型构建
本次研究共抽样849 个数据样本,涉及378 家上市公司,并通过指标筛选模型确定了21 个指标,其中包括17 个财务变量和4 个非财务变量。经过数据归一化,使用五折交叉验证方法将样本数据分为训练集和测试集,并采用XGBoost 算法作为分类器构建财务报表舞弊识别模型。研究设计流程如图3所示。
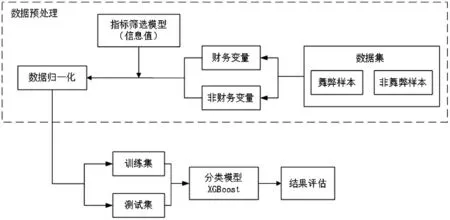
图3 研究设计流程
3 实验与分析
3.1 模型参数设置
利用网格搜索对XGBoost设置参数如表3所示。

表3 XGBoost参数设置
3.2 实验结果
模型在训练过程中会产生样本记忆,如果训练集用于测试会导致测试结果偏高,影响模型的性能。因此,本研究采用五折交叉验证的模型验证方法,以提高模型的泛化能力。
本研究使用逻辑回归、支持向量机、随机森林三种机器学习算法与XGBoost 算法作为财务报表舞弊识别分类器进行了对比,各机器学习算法分类结果如表4所示。
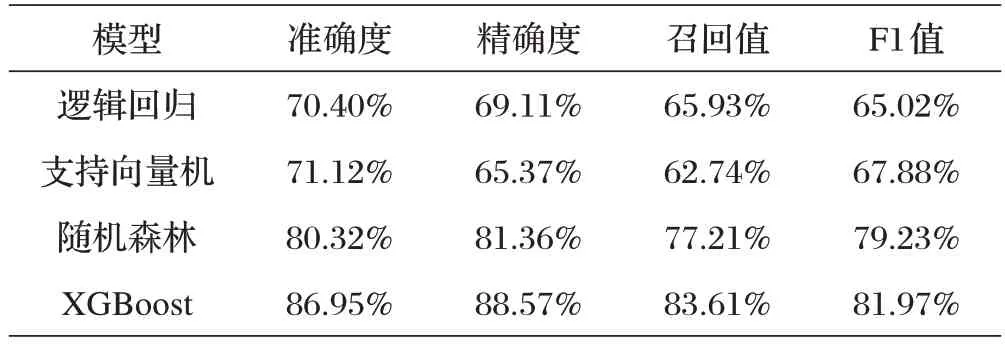
表4 各机器学习算法分类结果评价指标对比
综合考虑各个评价指标可知,基于XGBoost 算法构建的财务报表舞弊识别模型的预测效果是最好的。
3.3 实验结果分析
集成学习将多个个体学习器的方差和偏差结合起来,是一个更全面的强监督学习算法,能够获得更好的性能。所以基于集成学习算法中的随机森林、XGBoost算法构建的财务报表识别模型的性能显著高于基于逻辑回归、支持向量机等个体学习器构建的模型。随机森林的每个决策树随机选择特征子集,而XGBoost 算法使用贪心算法确定最优特征子集,并串行地生成一系列个体学习器,然后使用预测值与真实值之差作为目标函数来优化参数,最终预测值是个体学习器预测值之和。所以,对于不平衡数据集,基于XGBoost算法构建的预测模型分类效果更好。
4 结论
本文得出以下结论:①比较多个机器学习算法构建的预测模型,通过实验证明基于集成学习算法构建的财报舞弊识别模型优于个体学习器。②比较同属于集成学习算法的随机森林算法和XGBoost算法,通过实验证明基于XGBoost 算法构建的财报舞弊识别模型的预测能力更佳。
猜你喜欢
销售与市场(营销版)(2022年4期)2022-04-15
活力(2021年6期)2021-08-05
玩具世界(2020年4期)2020-11-16
现代经济信息(2020年34期)2020-06-08
经济技术协作信息(2018年11期)2019-01-14
汽车观察(2018年9期)2018-10-23
上海建材(2017年4期)2017-10-16
辽宁经济(2017年5期)2017-07-12
现代工业经济和信息化(2016年6期)2016-05-17
中国乡镇企业会计(2015年9期)2015-12-30
