
基于自动编码器的时间序列预测混合模型①
2022-08-04 09:58滕进风黄健刚
计算机系统应用 2022年7期
路 强,滕进风,黎 杰,凌 亮,丁 超,黄健刚
1(合肥工业大学 计算机与信息学院,合肥 230009)
2(黄山旅游集团水电开发有限公司,黄山 245899)
3(南京航空航天大学 经济与管理学院,南京 211106)
时间序列预测在许多工业和商业应用中发挥着重要作用,例如金融市场、网络流量、天气预报和供水行业等. 在这些场景中,人们可以利用大量关于过去行为的时间序列数据来预测将来的值[1–3]. 时间序列预测的主要挑战是提高预测能力以满足日益增长的多步预测需求. 目前,时间序列预测在实际应用中关系到经济社会生活的各个方面. 因此,在这项工作中,本文将研究时间序列的多步预测性能.
传统的线性回归方法主要包括自回归,移动平均,自回归综合移动平均模型(ARIMA)等. 而非线性机器学习模型主要包括人工神经网络、支持向量回归和梯度提升决策树等[4–6],它们在时间序列预测方面也取得了良好的效果. 目前,深度学习技术可以更加高效的提取数据的特征. 经典深度学习框架有深度神经网络,卷积神经网络,循环神经网络(RNN)[7]等. RNN 是一种在时间上进行递归的神经网络,但它存在梯度消失和梯度爆炸的问题. 长短期记忆网络(LSTM)[8]使用3 个门控机制来解决梯度爆炸和梯度消失问题,它在长序列预测中表现得更好. 门控循环单元(GRU)[9]作为LSTM 的变体,GRU 与LSTM 具有相似的性能,它简化了LSTM 的门控结构,降低了网络的训练时间. 然而这些方法在对序列数据中的长期和复杂关系进行建模时仍然具有局限性. 为了提高预测精度很多信号处理方法被用于时间序列预测,在这些模型中,信号处理方法将时间序列进行分解和去噪处理[10,11]. 在时间序列数据中,不同的数据分量可能具有不同的特征,现有的常见混合模型无法充分利用不同分量的特征.
为了解决上述问题,本文提出了一种新型的混合多步预测模型. 通过采用奇异谱分析对数据进行预处理,再结合本文设计的自动编码器网络结构对预处理后的数据进行预测,可以实现对复杂数据建模的能力.主要贡献如下:
1)提出了一种端到端的时间序列预测混合模型,该模型可以用于时间序列数据的多步预测. 该混合模型的预测精度优于单一模型.
2)采用SSA 将原始时间序列数据分解为不同的趋势分量,SSA 可以从原始数据中提取数据的不同趋势信息. 同时设计了新的基于ConvLSTM 和BiGRU自动编码器结构,该模型能够进行短期和长期特征学习.
3)使用真实世界的2 个供水数据集和3 个公开的时间序列数据集评价所提出的模型. 实验结果表明,与所有基线方法相比,该模型在多步预测评价指标下几乎都获得了最好的预测性能,证明了模型在时间序列预测方面的优越性.
本文的其余部分安排如下: 第1 节介绍了相关的工作. 第2 节阐述了所提出模型的设计与实现. 第3 节评价了模型的预测性能,并对实验结果进行了详细讨论. 第4 节对本文进行总结.
1 相关工作
目前,为了更好地提高时间序列预测的准确性,很多信号处理的方法被用于时间序列预测. 例如,Zhang等人[12]采用小波变换(WT)获取交通流的时变和周期性特征,建立了季节性ARIMA 进行预测. Ahani 等人[13]提出了一种多步预测系统,集成了经验模式分解(EEMD),最小二乘支持向量回归(LSSVR)和长短期记忆神经网络(LSTM). Chang 等人[14]提出了一种基于小波变换和Adam 优化的LSTM 神经网络混合模型,用于时间序列数据预测. 此外,很多方法采用了数据分解技术来提取数据不同的趋势信息进行预测. 例如,Tang 等人[15]通过WT 和SSA 对金融时间序列进行分解重构去噪,将平滑序列引入LSTM 得到预测值. Li 等人[16]利用变分模式分解(VMD)将非平稳月降水时间序列分解为几个相对稳定的固有模式函数(IMFs),然后为每个IMF 建立一个极限学习机预测模型,最后将预测值累加得到预测结果. Liu 等人[17]采用SSA 将原始数据进行分解,同时使用CNNGRU 和SVR 分别预测不同的分量数据. Zhu 等人[18]通过VMD 来捕捉时间序列的趋势和可变性信息,通过引入双向门控循环单元实现对天然橡胶期货的短期预测. 在这些信号处理方法中,WT 可以提取时频信息,EEMD 和VMD 可以提取趋势信息. 然而,SSA 具有严格的数学理论和少量的参数,并且可以有效地提取信号的趋势信息,因此被选为信号处理的方法.
由于深度学习算法在数据特征提取方面的强大功能,目前也有大量的工作在时间序列预测领域取得了令人瞩目的成绩. 例如,Sagheer 等人[19]提出了一种深度长短期记忆(DLSTM)模型用来捕捉时间序列数据中的非线性动态和长期依赖关系. Zhang 等人[20]提出了一种基于双向长短期记忆(Bi-LSTM)网络模型用于时间序列数据的预测. Hu 等人[21]采用了一种将卷积神经网络与双向长短期记忆网络相结合的模型,用于预测城市的用水需求. Essien 等人[22]提出了一种用于多步预测的端到端模型,该模型包含一个深度ConvLSTM编码器-解码器架构,应用于智能工厂时间序列数据的预测. Salinas 等人[23]提出了DeepAR,这是一种产生精确概率预测的方法,基于对大量相关时间序列训练自动回归的递归网络模型. 因此,深度学习方法在时间序列预测方面具有广泛的应用. 同时,它们使用由多个非线性变换组成的架构来映射数据中的高级抽象.
根据以上文献,信号处理方法和深度学习方法在时间序列预测方面有着广泛的使用. 然而,由于不同数据具有不同的特征,单一的深度学习方法在对数据中的长期和复杂关系进行建模时具有一定的局限性. 基于此背景,在本研究中,提出了一种新的混合模型. 使用奇异谱分析对数据进行预处理,再结合本文设计的自动编码器网络用于对预处理后的数据进行预测,该模型可用于供水数据的预测,同时模型也可以应用于其他时间序列数据的预测任务.
2 方法
2.1 问题描述
在本研究中,多步(即序列到序列)预测是一个重要的时间序列预测问题,本文将时间序列预测制定为有监督的机器学习任务. 多步时间序列预测的目标是使用大量关于过去行为的时间序列数据来预测将来的值,给定一个一维的单变量时间序列,xt∈{x1,x2,···,xN−1,xN},N为原始序列的长度. 对于多步提前预测,监督机器学习模型的输入X是xt−w+1,···,xt−1,xt,输出是yt+1,yt+2,···,yt+k. 本文使用固定长度的滑动时间窗口方法构建X、,得:
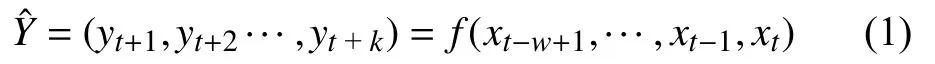
其中,w是滑动窗口时间序列的长度,k是需要预测的时间序列的长度.
2.2 总览
在本节中,将描述如何使用SSA-ConvBiAE 模型实现时间序列数据的预测任务. SSA-ConvBiAE 模型的总体流程如图1 所示. 首先,对原始数据进行处理,主要是对数据的缺失值进行填充和归一化操作,处理后的数据被划分为训练集和测试集; 通过数据分解步骤,将训练集和测试集进行分解和重构,来获取不同趋势的分量数据; 然后,将获取到的训练集不同的分量数据分别输入到自动编码器网络用于模型的训练,经过迭代保存训练好的模型. 最后,将测试集分量输入到对应训练好的模型中用于预测,将不同分量的预测结果相加得到最终的预测结果.

图1 总体预测模型的管线图
2.3 提出的模型
本文提出的SSA-ConvBiAE 模型的整个过程如图2 所示,详细说明如下.
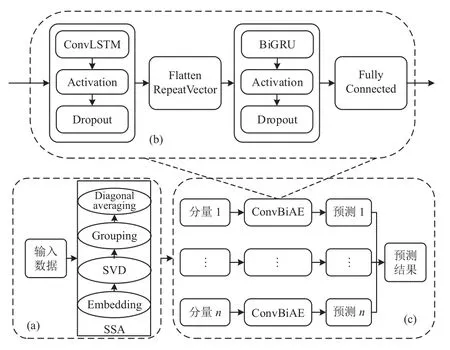
图2 SSA-ConvBiAE 模型结构图
2.3.1 数据分解
为了提高模型预测的准确性,采用SSA 信号处理方法将原始的时间序列数据进行预处理,SSA 是用于时间序列分析有效的非参数算法,SSA 可以有效地实现信号的分解和重构. 此外,SSA 具有严格的数学理论和较少的参数,并且可以很好地识别时间序列的周期、准周期和趋势信息. 本文选择这种非参数方法将原始的时间序列分解并从原始数据中提取不同的趋势分量. 具体如图2(a)所示,SSA 经过4 个步骤分别是: 嵌入(embedding)、奇异值分解(SVD)、分组(grouping)和对角平均化(diagonal averaging),可以将原始的时间序列数据进行分解和重构,并获取数据不同的趋势信息,用于模型的训练和预测. SSA 的详细步骤描述如下:
1)嵌入. 首先选择适当的窗口长度L(2 ≤L≤N),将一维的原始时间序列X=(x1,x2,···,xN)转化成多维的序列Z=(Z1,Z2,···,ZK),Zi=(xi,xi+1,···,xi+L−1)T∈RL,其中,K=N−L+1,可得轨迹矩阵Z=(Z1,Z2,···,ZK)=表示为:

可以看出矩阵Z为汉克尔矩阵,即沿对角线元素相等.
2)奇异值分解. 通过SVD,轨迹矩阵Z可表示为:
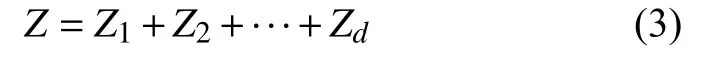
3)分组. 该过程将区间{1,2,···,d}划分为多个离散子集I1,I2,···,Im,其中m是组数,则矩阵Z可表示为:
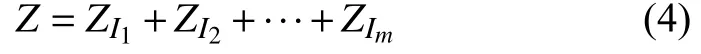
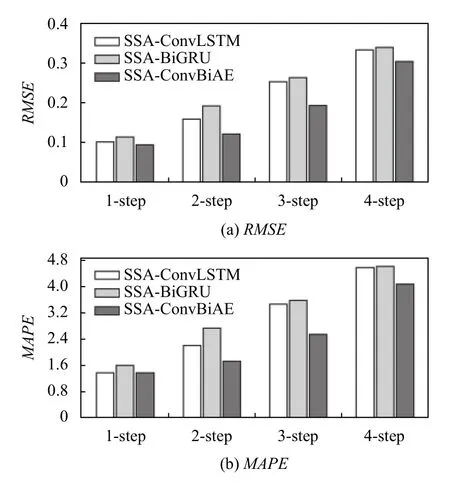
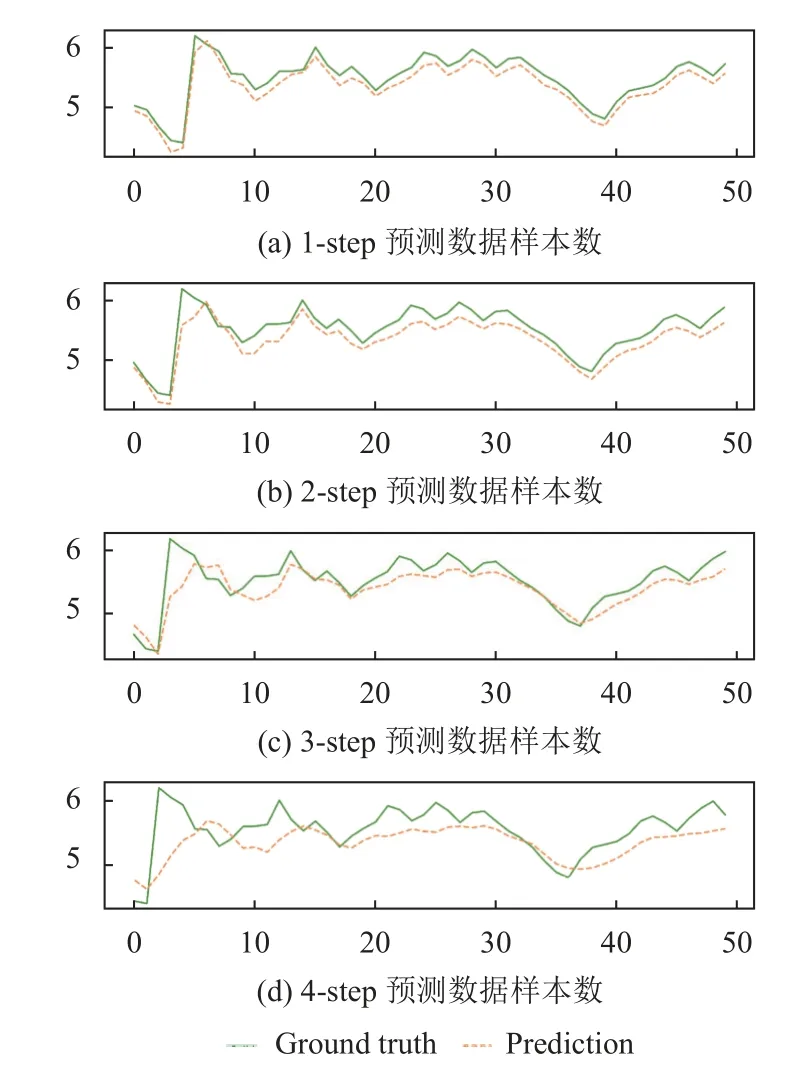
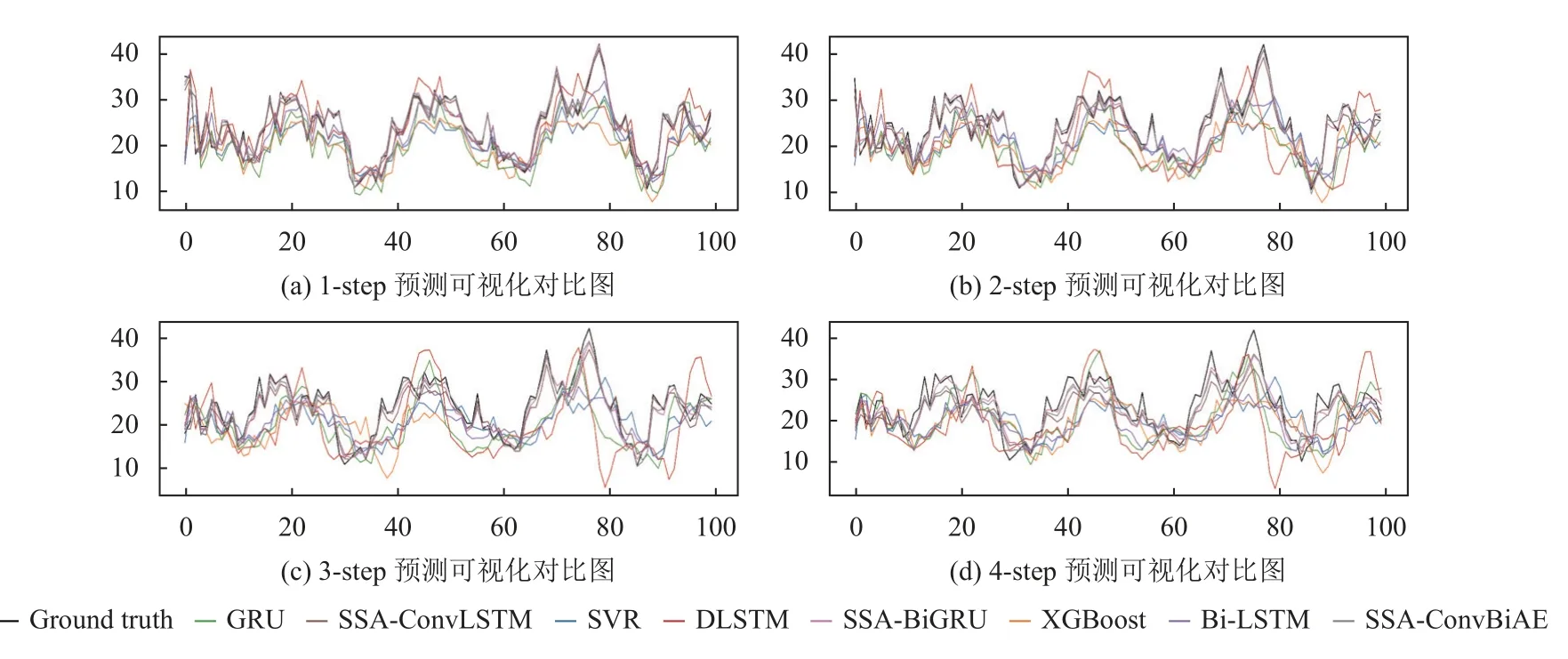
4)对角平均化. 该过程旨在将分组序列的每个矩阵转换为长度为N的新序列,设Z为L×K的矩阵,L∗=min(L,K),K∗=max(L,K),N=L+K−1,且当L 2.3.2 自动编码器 自动编码器可以解决序列到序列建模的问题,其中输入和输出均为序列. 本文设计了基于ConvLSTM和BiGRU 的自动编码器结构,具体如图2(b)所示,提出的网络模型结构主要分为编码器和解码器. 1)编码器有一层ConvLSTM,一层激活函数tanh 和一层Dropout 函数堆叠在一起作为编码层.ConvLSTM[24]作为LSTM 的一种变体,虽然LSTM 可以有利地捕获长输入序列的长期依赖,但它的各个门控结构之间采用的是由全连接的方式构建的,因此模型在训练时需要更多的参数. 而ConvLSTM 用卷积算子替换了全连接层算子,使得它在输入到隐藏状态以及与各个门控结构之间的转换都具有卷积操作. Conv-LSTM 继承了卷积算子中稀疏连接和参数共享的优点,可以减少全连接结构的冗余. 此外,ConvLSTM 不仅能够提取时间特征,通过卷积操作还可以有效对空间信息进行特征提取. 同时,ConvLSTM 通过门控机制克服了梯度消失的问题,也保留了LSTM 可以捕获长时间记忆的优点. 因此,本文选择ConvLSTM 作为编码器.它的计算公式如下: 其中,σ、tanh、∗ 和°分别表示Sigmoid、tanh 操作、卷积运算和Hadamard 积;it,ft,Ct−1,Ct和ot分别代表各种门控机制;xt表示输入数据,ht−1表示前一个ConvLSTM单元输出的循环状态,ht表示当前时刻的循环状态;W和b分别代表门控机制的权重向量和偏差向量. 2)解码器由一层BiGRU、一层激活函数tanh 和一层Dropout 函数堆叠在一起作为解码层. BiGRU 模型一种双向循环神经网络,它可以利用正向和反向信息. 双向门控循环单元将两个传输方向相反的隐藏层连接到同一个输出层. 因此,输出层具有输入序列中每个点的过去和未来状态的完整信息,从而做出更准确的预测. BiGRU 是在GRU 基础上进行正向和反向训练并将结果进行线性融合,这样不但可以提取过去的特征,也可以提取未来的特征,同时数据复用,而且每个时刻输出值是由两个方向的GRU 共同决定. BiGRU的思想是将常规GRU 神经元分为前向状态和后向状态. GRU 的计算公式如下所示: 其中,σ表示激活函数Sigmoid,tanh 是候选状态的激活函数,∗是点积操作,xt表示输入向量,更新门zt可以确定保留多少先前存储的信息,重置门rt可以将多少先前存储的信息与新输入集成在一起.ht−1表示上一时刻隐藏层的状态,ht表示当前时刻隐藏层状态.h˜t表示候选状态.W是与输入相关的权重矩阵,b表示偏差向量. 为了使编码层的输出可以作为解码层的输入,在编码层之后通过使用一个重复向量层(repeat vector).该层的主要功能是重复来自编码层的最终输出向量,以便解码层能够重建原始输入序列. 最后,在解码层之后通过一个全连接层,用来输出数据的预测值. 2.3.3 预测分量 多个分量的预测过程,具体如图2(c)所示,将SSA 获取到的n个分量数据分别作为每个自动编码器模型的输入数据进行模型的训练,保存训练好的模型.将不同的测试集分量分别输入到对应的训练好的自动编码器模型中进行预测,最后将不同分量的预测值进行求和,得到最终的预测结果. SSA-ConvBiAE 模型是一个健壮的,可扩展的端到端时间序列多步预测模型. 奇异谱分析可以从原始数据中提取数据不同的趋势信息,同时本文设计的自动编码器网络结构能够进行短期和长期特征学习,该混合模型可以用于时间序列的多步预测. 为了更好地反映出模型的预测值跟真实值的差距,在SSA-ConvBiAE 模型中采用的损失函数是均方误差. 同时,使用了基于随机梯度的优化算法Adam,每次迭代时更新模型参数. 损失函数的计算方法如下: 本文的实验环境是基于Windows 操作系统,使用Python 语言对代码进行实现. 深度学习框架主要采用了TensorFlow,模型算法的实现是使用Keras,它是基于TensorFlow 的深度学习库. 硬件环境的配置是Intel(R)Core(TM)i7-7700K CPU @4.20 GHz、32.0 GB内存和NVIDIA GeForce RTX 2080 8 GB GPU. 本文提出的模型在5 个数据集进行了实验,其中包括2 个真实的供水数据集和3 个公开的时间序列数据集. TH-reservoir 和 XH-waterworks 是由黄山旅游集团水电开发有限公司提供的黄山风景区供水数据集.Milan-air[25],Delhi-meantemp[26]和Global-power[27]是从Kaggle 网站获得的公开的时间序列数据集. 5 个数据集的详细描述如下所示: 1)TH-reservoir: 该数据集是黄山风景区某水库的水位值,数据集包含了黄山风景区某水库2017 年1 月1 日到2019 年12 月31 日每天的水位值. 2)XH-waterworks: 该数据集是黄山风景区某水厂的供水量,数据集包含了黄山风景区某水厂2017 年1 月1 日到2019 年12 月31 日每天的供水量. 3)Milan-air: 该数据集是米兰空气中PM2.5浓度数据,数据集包含2020 年7 月24 日到2020 年9 月20 日每小时PM2.5浓度的平均值. 4)Delhi-meantemp: 该数据集是印度德里市的天气温度数据,数据集包含2013 年1 月1 日至2017 年1 月1 日每天温度的平均值. 5)Global-power: 该数据集是一个家庭在4 年内的有功功率电力消耗数据,数据是每分钟收集一次,经过累加计算得出每天的消耗量,数据集包含2006 年12 月16 日至2010 年11 月26 日每天消耗量的值. 上述黄山风景区供水数据集包含少量的缺失数据,因此使用线性插值的方法进行填充. 在实验中,将80%的数据用作训练集,其余20%用作测试集. 为了评价模型的多步预测性能. 在本文中,使用了输入步长大小为18 的滑动窗口机制,进行多步预测. 另外,将输入数据进行归一化处理,其公式如下所示: 其中,xnor表示归一化后的数据,x表示输入的样本数据中某一个值,xmax,xmin分别表示样本数据中的最大值和最小值. 为了验证所提出模型的预测性能,本文进行了5 个实验. 在每个实验中,将SSA-ConvBiAE 模型的预测性能与以下基线方法进行比较: 1)SVR[5]: 支持向量回归,它使用历史数据来训练模型并对数据进行预测. 2)XGBoost[6]: 它是一个端到端的梯度提升决策树模型,是一种高效且广泛使用的机器学习方法. 3)GRU[9]: 门控循环单元,GRU 通过简化门控结构使得网络更易计算,降低了模型的训练时间. 4)DLSTM[19]: 通过堆叠多个LSTM 块,构建一个深度LSTM 神经网络. 5)Bi-LSTM[20]: 主要使用前向和后向LSTM 来捕捉过去和未来隐含的信息,然后将两部分结合起来形成最终的预测输出. 6)SSA-ConvLSTM: 消融实验. 奇异谱分析和ConvLSTM 的混合模型,详细描述请参见第2.3 节. 7)SSA-BiGRU: 消融实验. 奇异谱分析和BiGRU的混合模型,详细描述请参见第2.3 节. 本实验采用3 种评价指标对模型的预测结果进行评价,具体如下: 平均绝对误差(MAE): 均方根误差(RMSE): 平均绝对百分比误差(MAPE): 在本节中,为了研究所提出模型的多步预测性能,对涉及到的所有模型进行1-step 到4-step 的预测. 表1,表2 和表3 给出了2 个真实的供水数据和3 个公开时间序列数据在几种不同模型上的预测误差评价结果. 表1 SSA-ConvBiAE 模型和基线方法对TH-reservoir 和XH-waterworks 数据集的预测结果 通过表1 的实验结果,可以发现: 在供水数据案例研究中,SSA-ConvBiAE 模型可以实现准确的多步预测结果,混合模型的预测精度优于单一模型. 这表明SSA 对数据的分解,可以获取数据不同趋势的分量信息,从而降低了时间序列的复杂度,提高了模型的预测精度. 与其他几种基线方法相比,SSA-ConvBiAE 模型的多步预测几乎具有最好的预测精度,这表明设计的基于ConvLSTM 和BiGRU 结构的自动编码器模型可以有效地提取数据特征,适用于时间序列预测. 同时,为了验证模型不仅可以用于供水数据预测,本文也在3 个公开的时间序列数据进行了实验,通过表2 和表3的实验结果可以发现,所提出的模型在公开的数据集上都有优异的表现,表明模型具有一定的泛化能力. 表1,表2 和表3 显示了SSA-ConvBiAE 模型和其他基线方法在5 个时间序列数据集上的多步预测任务的性能. 可以看出,SSA-ConvBiAE 模型在多步预测范围的评价指标下几乎都获得了最好的预测性能. 模型与其他基线方法预测结果相比,详细描述如下. 表2 SSA-ConvBiAE 模型和基线方法对Milan-air 和Delhi-meantemp 数据集的预测结果 表3 SSA-ConvBiAE 模型和基线方法对Global-power 数据集的预测结果 1)预测精度. 以TH-reservoir 数据集为例,从表1中可以看出: 所提出的模型SSA-ConvBiAE 极大地提高了多步预测的性能,这表明该模型在长期预测能力方面取得了优异的效果. 例如,对于1-step 的供水数据预测任务,SSA-ConvBiAE 模型和SVR 和XGBoost 模型相比,RMSE误差降低了约71.45%和71.27%. 这主要是由于SVR 和XGBoost 等方法难以处理复杂的非平稳时间序列数据. SSA-ConvBiAE 模型和GRU 模型、DLSTM 模型和BiLSTM 模型相比,RMSE误差降低了约72.28%、71.39%和72.21%,这主要是由于针对具有不同特征的时间序列数据,这几种模型的预测结果会有所降低. 从表1 可以看出,经过SSA 进行数据分解,预测精度得到了明显提高,这表明提出的混合模型是有效的. 2)消融分析. 为了验证SSA-ConvBiAE 模型采用自动编码器网络结构的有效性,将SSA-ConvBiAE 与SSA-ConvLSTM 和SSA-BiGRU 模型进行了比较. 以TH-reservoir 数据集为例,从图3 中可以看出,在RMSE和MAPE两种不同的实验评价指标下,可以清楚地看到提出的SSA-ConvBiAE 比SSA-ConvLSTM和SSA-BiGRU 具有更好的预测结果. SSA-ConvBiAE与SSA-ConvLSTM 和SSA-BiGRU 模型相比,从1-step预测可以看出,RMSE分别降低了约7.22%和17.80%.实验表明,ConvLSTM 充分捕捉了序列数据的时间和空间分布,同时模型中结合BiGRU,使输出层具有输入序列中每个点的过去和未来状态的完整信息,可以融合更多的序列特征,提高了模型的预测性能. 因此,表明了本文提出的自动编码器网络结构可以有效地提取数据特征. 图3 消融实验预测结果对比 3)多步预测. 从以上的实验结果可以看出,在5 个不同的数据集上SSA-ConvBiAE 模型预测精度在多步预测范围内明显要高于其他基线方法. 以TH-reservoir和XH-waterworks 数据集为例,从表1 中可以看出,本文提出的SSA-ConvBiAE 模型在1-step 到4-step 的预测结果几乎都获得了最好的预测性能,这表明提出的混合模型是可行的. 因此,该模型可以用于供水数据和其他时间序列任务的预测,同时本文提出的SSA-ConvBiAE模型不仅可以用于短期预测,还可以用于中长期预测. 在本节中,将选择SSA-ConvBiAE 模型的相关参数. SSA-ConvBiAE 模型的超参数主要包括: 批次大小、训练次数、隐藏层单元数、卷积核的尺寸、Dropout和数据分量个数. 在实验中,将批次大小设置为32,训练次数设置为100,隐藏层单元设置为128,卷积核的尺寸设置为1×3,Dropout 参数设置为0.1. 数据分量的个数是SSA-ConvBiAE 模型的一个非常重要的参数,本文通过尝试不同的数据进行对比预测实验来选择最佳值. 在实验中,从[2,3,4,5,6,7]中选择不同的分量个数并分析预测精度的变化. 如图4和图5 所示,横轴代表不同的分量个数,纵轴代表RMSE和MAE两种不同的评价指标的变化. 图4(a)和图4(b)分别显示了数据集TH-reservoir 和XH-waterworks 不同分量个数的RMSE和MAE的预测结果. 可以看出,当分量个数为5 时,误差最小. 同样图5(a)和图5(b)分别显示了数据集Milan-air 和Delhi-meantemp 的预测结果,当个数为6 时,结果达到最小值,图5(c)显示了数据集Global-power 的预测结果,当个数为4 时,结果达到最小值. 这表明不同的分量个数会极大地影响预测精度,因此需要通过不同参数的对比实验来选择最佳值. 图4 不同的SSA 分量在TH-reservoir 和XH-waterworks 数据集上的预测性能比较 图5 不同的SSA 分量在Milan-air,Delhi-meantemp 和Global-power 数据集上的预测性能比较 为了更好的理解SSA-ConvBiAE 模型的预测结果,选择对TH-reservoir 的部分测试集样本数据进行预测结果可视化,图6(a)–图6(d)分别显示了模型1-step到4-step 的预测范围的可视化结果. 从图6 中1-step 和2-step 预测的可视化结果来看,SSA-ConvBiAE 模型在数据的局部最小值和局部最大值处的预测结果都非常的接近真实值,这表明SSA 将数据分解成不同的趋势分量后,自动编码器结构中ConvLSTM 充分捕捉了序列数据的空间和时间分布,具有自动特征提取方面的优势,而BiGRU 可以融合更多的序列特征,提高了模型的预测性能. 从图6 中3-step和4-step 的预测可视化结果来看,模型预测的总体趋势接近真实值,但在局部最小值和局部最大值处的预测结果要低于前两步预测. 尽管ConvLSTM,BiGRU可以捕捉数据集中的长期依赖性,但针对复杂数据的预测,长期预测的结果也会有所降低. 从图6 中的1-step到4-step 的预测结果,可以看出奇异谱分析与自动编码器网络的结合是有效的,该模型可以提取序列数据的时间特征,可以很好地拟合数据,以及准确预测数据的变化趋势. 同时,在5 个数据集上的预测结果可以看出,在针对具有不同特征的时间序列数据,本文提出的模型在预测结果方面都具有优异的表现. 图6 SSA-ConvBiAE 模型的可视化预测结果(其中,纵坐标表示水位 (m)) 为进一步表明模型的预测结果,选择SSA-ConvBiAE模型与其他基线方法的预测结果进行可视化对比,如图7(a)–图7(d)所示,不同的模型对TH-reservoir 数据集进行1-step 到4-step 预测结果可视化,可以看出,采用SSA 对数据进行处理后,混合模型的预测结果明显优于单一模型,预测结果更接近真实值,与SSA-ConvLSTM和SSA-BiGRU 模型相比,SSA-ConvBiAE 模型在多步预测范围内获得了更好的预测性能. 同时本文也选择了对Milan-air 数据集进行预测结果可视化,如图8(a)–图8(d)所示,展示了不同模型的预测结果. 图7 SSA-ConvBiAE 模型与基线方法对TH-reservoir 数据集的预测结果可视化对比图(其中,纵坐标表示水位 (m),横坐标表示样本数目) 图8 SSA-ConvBiAE 模型与基线方法对Milan-air 数据集的预测结果可视化对比图(纵坐标表示: PM2.5 浓度 (μg/m³),横坐标表示样本数目) 本文提出的一种端到端的时间序列预测混合模型,SSA-ConvBiAE 模型是一个健壮的,可扩展的端到端模型可以用于时间序列数据的多步预测. 在提出的SSA-ConvBiAE 模型中,采用SSA 将原始时间序列数据分解为不同的趋势分量,SSA 可以从原始数据中提取数据不同的趋势信息,同时本文设计了新的基于ConvLSTM 和BiGRU 自动编码器结构,模型能够进行短期和长期特征学习,该混合模型的预测精度优于单一模型. 在真实世界的2 个供水数据集和3 个公开的时间序列数据集上进行实验来评价所提出的模型. 实验结果表明,与所有基线方法相比,该模型在多步预测评价指标下几乎都获得了最好的预测性能,证明了SSA-ConvBiAE 模型在时间序列预测方面的优越性.这表明提出的模型不仅可以应用于供水预测领域,同时对于其他时间序列数据预测也具有一定的适用性.在未来的研究计划中将继续深化研究SSA-ConvBiAE模型在时间序列数据方面的预测性能,特别是针对多变量的时间序列预测问题.


2.4 损失函数

3 实验分析
3.1 实验环境
3.2 数据描述
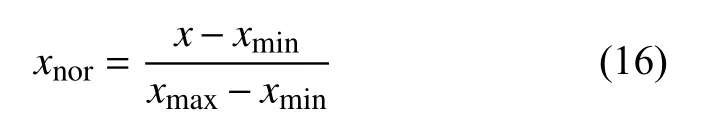
3.3 基线方法
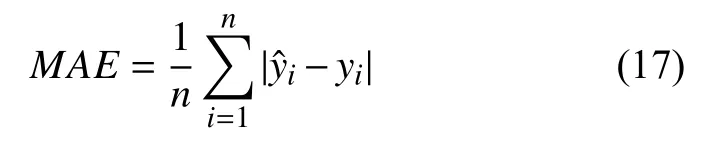

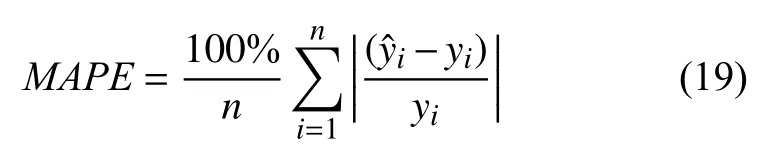
3.4 实验结果



3.5 模型参数选择


3.6 模型解释

4 结论
猜你喜欢
农业工程学报(2022年12期)2022-09-09
领导文萃(2022年11期)2022-06-08
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
读者·校园版(2020年19期)2020-09-16
智族GQ(2019年9期)2019-10-28
英美文学研究论丛(2018年1期)2018-08-16
科技与创新(2017年5期)2017-03-28
金点子生意(2014年4期)2014-04-10
中学生英语高效课堂探究(2008年9期)2008-11-17
