
基于深度学习的单图像超分辨率重建综述①
2022-08-04 09:58邢苏霄陈金玲李锡超
计算机系统应用 2022年7期
邢苏霄,陈金玲,李锡超,陈 彤
(南京烽火天地通信科技有限公司,南京 210019)
图像超分辨率重建(super-resolution reconstruction,SR)是计算机视觉和图像处理领域中一个极具挑战性的热门研究课题. 大多数成像设备会受到硬件、环境等多种因素的干扰,使得图像的分辨率并不能满足实际应用的需要. 为了提高图像空间分辨率,研究学者们开始尝试在不改变成像设备的前提下,利用图像处理、机器学习等算法将低分辨率(low resolution,LR)图像重建为高分辨率(high resolution,HR)图像[1]. 正是因为深度学习能自适应地学习LR 图像与HR 图像之间的非线性映射关系这种特性,使得基于深度学习的图像SR 算法明显优于传统方法,因此也成为单图像超分辨率重建(single image super-resolution,SISR)的主流研究方法. 同时,SR 技术在医学图像的分析与识别[2]、人脸超分辨率[3]、视频监控与安全[4]、遥感图像[5]等实际场景中有着广泛的应用.
近年来,大量介绍SISR 方法的文献[6,7]以及与超分辨率相关的综述类文章[8,9]层出不穷,这些文献中都对近年来SR 领域提出的各种新型算法、设计的新型网络框架、新型的应用场景等进行了研究与总结. 与之不同的是,本文按照学习方法的差异性将基于深度学习的SISR 问题分为两大类: 有监督的SISR 方法和无监督的SISR 方法. 先全面介绍了与SISR 问题相关的储备知识,然后详细论述了以上两类方法的最新理论和研究进展,同时比较了不同算法之间的异同点和优缺点,最后对该领域存在的问题和未来的发展方向进行了总结和展望.
1 SISR 方法的理论基础
本节将从问题定义、基准数据集、评价指标和损失函数等方面对SISR 方法的理论基础展开详细的调研,并对其中涉及到的相关基础知识和理论实现进行论述.
1.1 问题定义
日常生活中,由于成像设备、成像环境等多种退化因素的影响,人们获取到的图像通常是LR 图像,其退化过程如图1 所示. 设Ix为由退化模型输出的LR 图像,Iy为原始的HR 图像.

图1 图像退化过程
那么,LR 与HR 图像之间的关系则可以表示为:

其中,D(·)表示退化函数,δ表示退化因子.
图像退化过程中的退化函数、模糊因子、噪声等因素通常都是未知的,而能够被直接获取的只有LR 图像Ix. 因此,在不改变硬件设备的条件下,要获取更高空间分辨率的图像只能通过LR 图像进行重建. 那么其重建过程可以表述为:

其中,F(·)表示超分辨率重建模型,为重建后的HR 图像,θ为模型中的参数. 由图1 可知,图像退化是由运动模糊、成像模糊、加性噪声等多种因素共同影响的,则图像的退化过程[10]可以由符号化后的式(3)进行表述:

其中,Iy⊗k表示原始高分辨率图像与模糊核的卷积过程,↓s表示下采样因子,nσ表示加性噪声. 而基于深度学习的SISR 的实现过程就是模型不断迭代学习的过程,在找到低分辨率图像与高分辨率图像之间最佳非线性映射关系之后,损失函数达到最小值. 重建过程的损失函数可以由式(4)进行表示:
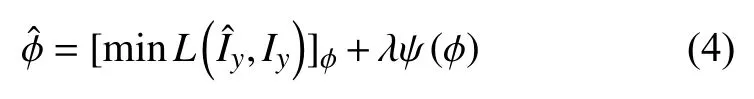
其中,L(,Iy)表示由超分辨率模型重建后的HR 图像与真实的HR 图像之间的损失函数,λ为折衷参数,ψ(ϕ)表示正则化项.
1.2 常用数据集
数据作为深度学习算法的建模必不可少的基本要素之一,其数据量的多少以及数据质量的好坏将直接影响着目标模型的效果. 现如今,SISR 领域有着各式各样的数据集用于模型的训练与测试,这些数据集在图像的数量、图像的质量、图像的分辨率、图像的多样性以及图像的成像环境等方面都有所不同. 其中,大多数数据集仅包含HR 图像,不包含用于模型训练和测试所需的不同放大倍数下的LR-HR 图像对,需要通过双三次插值算法实现图像对的构造.
本节将对常用的SISR 数据集进行调研,汇总结果如表1 所示. 本节列出了各类数据集在图像数量、图像格式、图像类型、图像平均分辨率以及图像中所包含的类别信息. 其中,Set5[11]、Set14[12]、Urban100[13]、BSDS100[14]、Manga109[15]常作为模型重建效果评估的基准数据集. 同时,研究者们也常常倾向于多个数据集共同参与模型的训练与测试,例如T91[16]与BSDS300[14]的结合,DIV2K[17]与Flickr2K[18]的结合. 其次,一些其他视觉领域的数据集也参与到SR 模型的训练过程中,如ImageNet[19]、MS-COCO[20]、VOC2012[21]、CelebA-HQ[22]、L20[23]等.
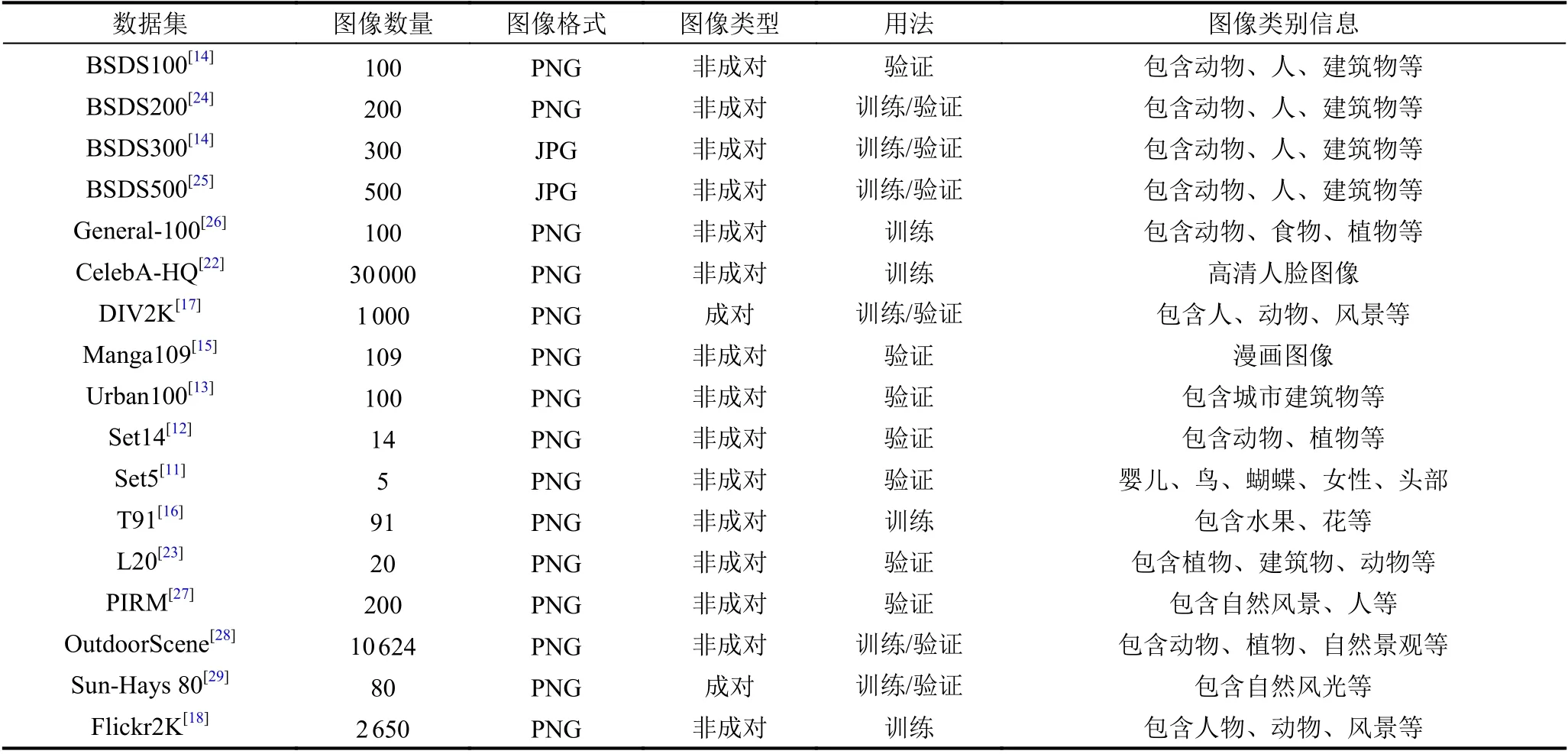
表1 SISR 领域基准数据集
1.3 评价指标
根据测量方法的不同,可以将图像质量评价(image quality assessment,IQA)方法[30]分为: 通过人类视觉对图像质量进行感知的主观评价方法和通过数值计算进行定量分析的客观评价方法. 其中,主观评价方法相较于客观方法更加符合实际应用,但其需要消耗更多的人力和时间资源,所以基于客观评价方法进行定量评估是目前超分辨率重建领域的主流评价指标,本节将对以上两类评价方法进行简要论述.
(1)峰值信噪比(peak signal-to-noise ratio,PSNR)[31]是目前应用最为广泛的用于图像重建质量评价的指标之一. 在SR 任务中,PSNR是由最大像素值与两幅图像之间的均方误差来定义的.PSNR值越大表明图像的质量越好,其计算公式如式(5)所示. 其中,MAXI表示图像中最大像素值,MSE表示两个图像之间对应像素差值平方的均值,单通道和多通道图像的MSE计算原理如式(6)、式(7)所示.
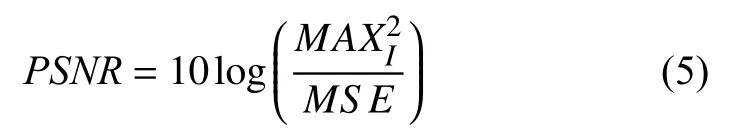
单通道的MSE:

多通道的MSE:
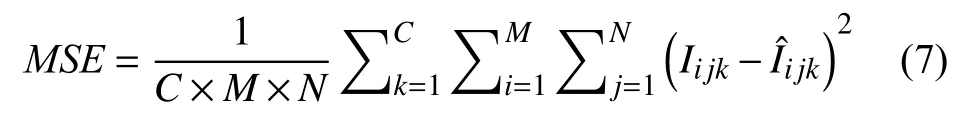
(2)结构相似性评价(structural similarity index measure,SSIM)[32]是用于比较图像间亮度、对比度、结构细节的相似度指标. 与PSNR相比,SSIM与人类视觉系统对图像结构提取方面的适应性更加契合,SSIM的取值范围为[0,1]. 图片的结构相似度越大,表示其失真程度越小,也说明图像的质量越好,SSIM的原理实现如式(11)所示.
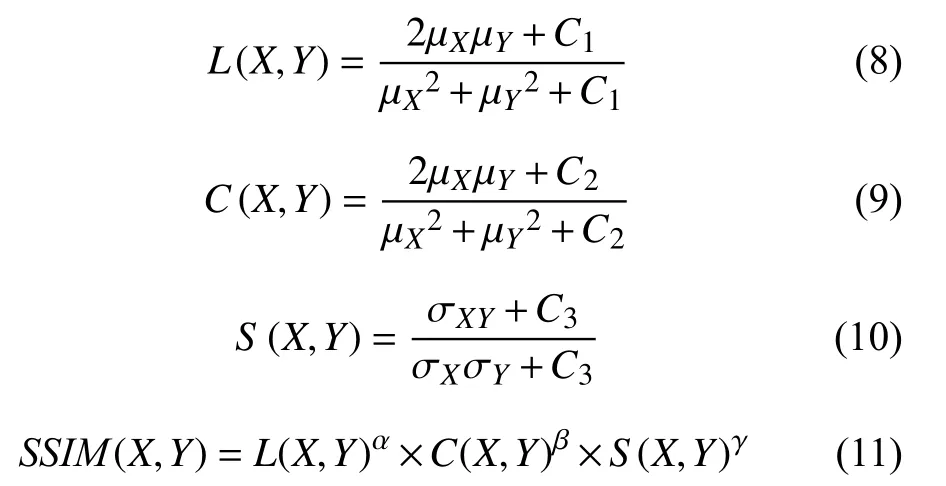
其中,µX和µY分别表示图像X,Y的像素均值,σX和σY分别表示X,Y的像素标准差,σXY表示图像X,Y的协方差.C1、C2、C3是常数,C1=(K1×L)2,C2=(K2×L)2,C3=C2/2,一般有K1=0.01,K2=0.03,L=255. 权重参数 α ,β ,γ 能够分别控制亮度、对比度和结构细节对结构相似度的重要性.
(3)平均意见得分(mean opinion score,MOS)[33]是属于IQA 中一种常用的图像质量评价主观方法,也是在图像感知质量评价方面最可靠的方法. 该方法要求参与评测的人员对被测图像从图像的清晰度、对比度、颜色、外观细节等方面进行视觉感知并打分,最后的评估得分是每一个评级份数的算术平均分,分数范围由坏至好分别为1 到5 分. 但是这种方法会因为评测标准的不同或人为偏见等不可控因素的影响而存在一些缺陷和局限性.
(4)基于学习的IQA 方法是为了减少人为因素的干扰,更好地评估图像的视觉感知质量,在大型理想参考图像数据集上通过学习的方式对图像进行质量评估的一种算法. 2017 年,Kim 等人[34]提出了基于CNN 的全参考图像质量评估模型DeepQA,该方法结合失真图像、主观评分和客观误差图进行模型的训练并对图像的视觉相似性进行预测. Ma 等人[35]和Talebi 等人[36]分别提出了MEON 和NIMA 的无参考IQA 神经网络,该方法不需要真实的参考图像,直接从视觉感知分数中进行学习并预测图像的质量分数. 基于CNN 的方法能够在视觉感知评估方面表现出更好的性能,但需要更多的数据资源.
除了上述几种常见的方法外,还有一些通过特定任务(图像分类、人脸识别、图像分割等)来间接衡量SISR 性能的方法. 同时,基于相位一致性和图像的梯度大小来计算图像的特征相似性[37]的方法也被用来评估图像的质量. Blau 等人[38]在2018 年的论文中提出,图像的感知质量和图像的失真是相互矛盾的,随着图像失真度的降低,图像的视觉感知质量也会随之降低.所以,PSNR和SSIM这两种定量分析的方法仍是目前图像SR 领域应用最为广泛的IQA 方法.
1.4 损失函数
损失函数是深度学习模型迭代优化过程中必不可少的重要元素之一. 在SISR 任务中,损失函数的选择至关重要,其通过计算误差来衡量HR 图像的重建质量. 而长期的研究发现,多种损失函数的共同指导更能在多方面指导HR 图像的重建过程. SR 领域中最为常见的损失是像素损失,但由于像素并不能对图像的重建质量进行绝对评估,所以内容损失、对抗损失、先验损失等各类损失函数应运而生,以下将介绍几种常用的损失函数.
(1)像素损失(pixel loss): 该损失是最为简单常用的一类损失函数,其主要以像素为基础衡量两幅图像之间的差异,包括L1、L2 损失[39]以及L1 损失的一种可区分的变体Charbonnier 损失[40],其具体表达式分别如式(12)、式(13)、式(14)所示. 这类损失能够提高模型的收敛速度,但是缺乏对图像内容以及语义信息的考虑,常会出现重建图像过度平滑的现象.
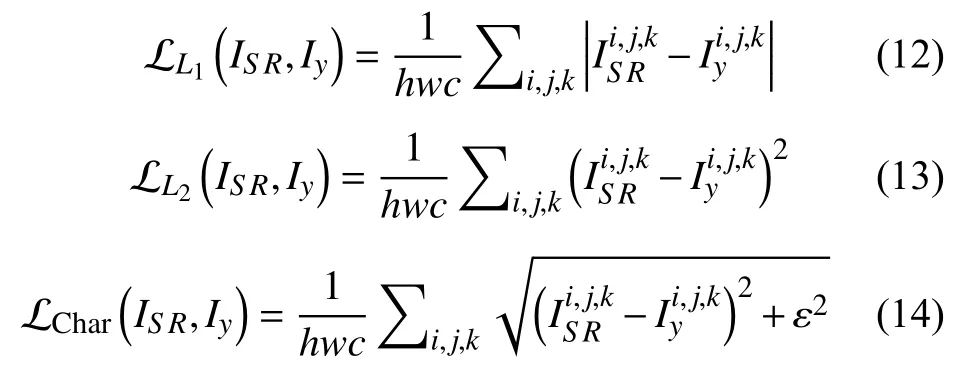
(2)内容损失(content loss)[41]: 该损失也常被称为感知损失,如式(15)所示. 其主要是从图像内容理解和感知层面对图像质量进行评价,通常使用预先训练好的图像分类网络对两幅图像之间的语义差异进行评估,从而提高重建图像的视觉相似性和真实度.

(3)纹理损失(texture loss)[42]: 该损失主要源自于风格迁移领域,其常被称为风格常见损失,如式(17)所示. 通常使用重建图像与原始图像不同通道之间的相关性来度量两幅图像在颜色、纹理、对比度等方面的相似性.
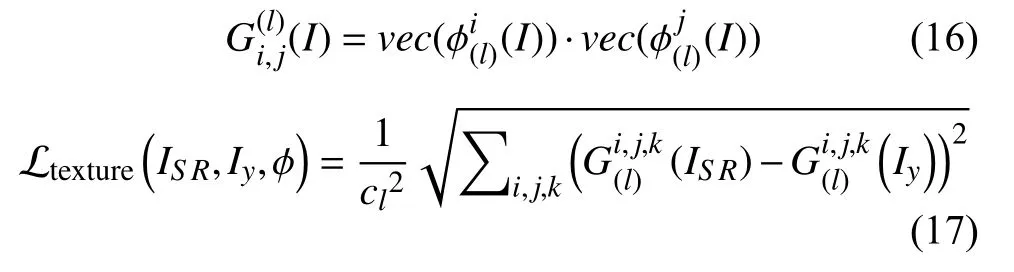
(4)对抗损失(adversarial loss)[43]: 该损失的提出主要是由于对抗生成网络(generative adversarial networks,GANs),GANs 由生成器和判别器组成,如式(18)所示.SISR 任务中的生成器为超分模块,而判别器主要用高层的语义信息来鉴别生成图像的真实性,从而使得重建后的HR 图像更加真实.
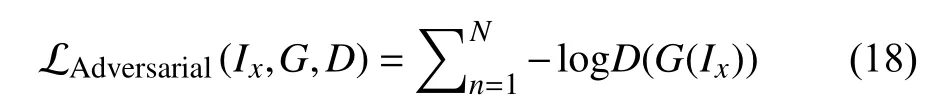
(5)先验损失(prior loss)[44]: 该损失主要是将稀疏先验、梯度先验和边缘先验等知识引入到SISR 模型中,如式(19)、式(20)所示. 该损失将已知的先验作为约束条件放入损失函数中,从而能够优化图像的一些特定信息,使得重建的效果能够朝着预期的方向发展,重建后的HR 图像也将包含更多的纹理细节.
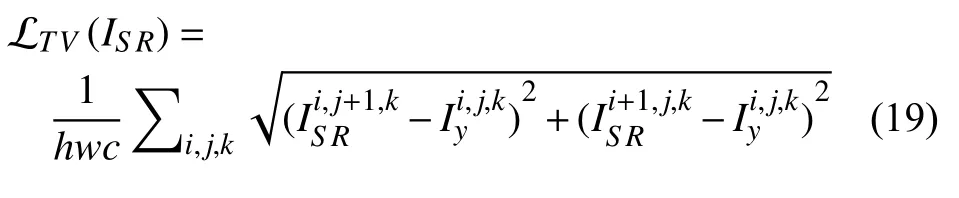

2 有监督的SISR 深度学习方法
目前,大多数基于深度学习方法的SISR 模型均侧重于使用LR 图像和HR 图像进行模型训练,也即这类模型都属于有监督的深度学习模型. 虽然不同模型之间的差异性较大,但是他们均是由模型框架、网络设计、学习策略等组件组合而成,以适用于各种SR 任务. 因此,本节将从网络的类型和网络的框架两个层面对有监督的SISR 方法进行分类,并对其中的代表性算法进行介绍.
2.1 基于网络类型
根据网络设计的差异性,可以根据网络设计的不同将有监督的深度学习超分辨率重建网络分为以PS NR为导向的SISR 方法和以视觉感知为驱动的SISR 方法.
2.1.1 以PSNR为导向的SISR 方法
随着卷积神经网络(convolutional neural network,CNN)在图像分类领域的成功应用,SISR 方法也在CNN模型的启发下取得了显著的进步,而前期基于深度学习的SISR 模型大多数均是以获取较高的PS NR为导向,也即通过像素损失来指导网络的学习过程. Dong等人[45]首次将传统的稀疏编码方法与深度学习相结合,提出了基于深度卷积神经网络的端到端单图像超分辨率重建算法(super-resolution convolutional neural network,SRCNN). 随后,Kim 等人[46]加深网络层数以提取更深层次的图像特征,并且为了减少网络参数、提升特征图利用率,进一步提出了基于深层卷积的VDSR 和DRCN. 由于深层网络容易出现梯度爆炸或梯度消失的现象,ResNet 的思想也参与到SR 任务中,Zhang 等人[47]基于残差密集块构建了RDN,该网络实现了全局残差的学习和局部特征的融合,并在PS NR上取得了不错的性能. 同时,为了突破固定放大倍数的限制,实现对深入图像的任意放大,Shi 等人[48]提出了一种基于像素重排思想的ESPCN 方法用于超分辨率重构. 为进一步实现对LR 图像的非整数缩放,Hu 等人[49]提出了可通过单一模型解决任意缩放因子问题的全新模型Meta-SR,并在基准数据集上取得了优越性能. 为了解决LR 与HR 图像映射空间的不确定性,DBPN[50]、DRN[51]、SRFBN[52]等方法利用反馈机制在网络迭代学习的过程中对图像的重建特征进行约束,从而减少可能的函数空间并在PSNR上显示出更好的重建性能.为了进一步提升PSNR,attention 机制被引入到SR 领域,该机制能够有效提升网络的表征能力以及加强信息的流动性,典型的算法有RCAN[53]、SAN[54]、HAN[55]等. 因此,CNN 与各类深度学习策略的有效结合,使得以PSNR为导向的SISR 方法取得了较为完善的重建性能.
2.1.2 以视觉感知为驱动的SISR 方法
SR 问题也可以看作是一种图像转换的任务,也即输入一张退化的LR 图像,经过模型处理后得到一张高质量的HR 图像. 考虑到以PSNR为导向的重建方法常常会导致高频信息的缺失,重建后的HR 图像过度平滑,与真实的HR 图像在视觉感知上存在一定的差异. Johnson 等人[41]在 2016 年则提出利用感知损失来衡量重建后的图像质量,以此来提升模型的重建性能. Ledig 等人[30]在2016 年提出了一个以视觉感知为驱动的SRGAN 方法,该方法首次将生成对抗网络(generative adversarial network,GAN)[44]用于SISR 领域,并在MOS 上表现出了卓越的性能. 随后,大量以视觉感知为驱动的基于GAN 的SR 方法被提出,例如Wang等人[56]通过在ESRGAN 中引入密集残差块(residualin-residual dense block,RRDB)来提高网络的性能;Soh 等人[57]基于自然流形鉴别器设计了NatSR,使得重建后的图像具有更加真实的纹理和更加自然的细节信息; Wang 等人[29]则基于特征的空间信息感知提出了SFTGAN,该方法让图像的纹理信息恢复更精细、更接近于真实的HR 图像; Ma 等人[58]发现基于上述方法重建后的HR 图像常常存在明显的结构变形问题,于是提出了结构保留的SPSR 网络,该方法能在缓解图像结构变形的同时还能够生成丰富的问题细节; 为了更好的构建LR 图像和高频信息之间的关系,Lugmayr等人[59]基于归一化流设计了能够基于低分辨率输入学习输出的条件分布的SRFlow,该方法能够探索超分辨率的解空间并生成多样性的图像,且最终的生成图像在感知度量上均优于当前最优的GAN 方法. 尽管现有的以感知为驱动的SISR 方法的确能够有效提升图像的感知质量,但是仍会出现伪影、几何变形等现象.
2.2 基于模型框架
根据模型框架的差异性,可以根据框架设计的不同将有监督的深度学习超分辨率重建网络分为预定义上采样网络、单次上采样网络、渐进上采样网络和迭代上下采样网络.
2.2.1 预定义上采样网络
预定义上采样网络(predefined up-sampling network)的实现通常先利用传统的插值算法将输入的LR 图像放大到具有目标尺寸的粗略HR 图像,然后使用深度卷积神经网络(deep convolutional neural network,DCNN)进行特征提取,使得网络能自动学习LR 图像到HR 图像的端到端非线性映射关系,从而实现SR 图像的重建. Dong 等人[26]率先使用预定义上采样的SR 框架提出了SRCNN,首次利用CNN 实现了高质量的重建效果.如图2 所示,该方法解决了LR 图像直接映射到HR 图像的困难,降低了学习的难度,同时也能实现任意缩放因子下的比传统单尺度SR 模型更加精细的重建效果.文献[53,54] 在这种主流框架的基础上对学习策略、模型设计等方面进行改进,使得基于深度学习的SISR模型的性能逐步得到提升. 但是,这种预先处理至目标尺寸的上采样操作会给输入图像带来额外的噪声和模糊,并且使得大多数计算都是在高维空间实现的,使得网络的时间复杂度和空间复杂度要明显高于其他框架.
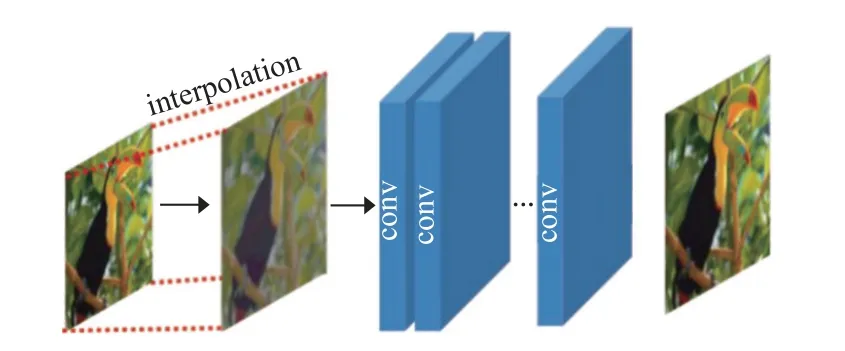
图2 预定义上采样网络
2.2.2 单次上采样网络
单次上采样网络(single up-sampling network)直接在低维空间实现大部分的计算过程,也即在不对输入的LR 图像进行目标尺寸缩放的前提下,利用DCNN进行特征提取,并在网络的后端采用可端到端学习的上采样层(亚像素卷积层或者反卷积)对非线性映射后的图像进行放大,其网络设计如图3 所示. 该方法能有效提高图像的空间分辨率,且相较于预定义上采样网络能够大大降低网络的时间和空间成本,因此,基于这种网络的设计思想,通过对特征提取层、上采样层、学习策略等模块的改进,文献[56,60,61]的方法也取得了更好的性能. 但是,其无法学习到LR 与HR 图像之间复杂的非线性映射关系,而且网络中只进行了一步上采样操作,这样会增加网络的学习难度,同时针对每一个缩放因子都需要训练一个独立的SR 模型,所以无法实现任意缩放尺寸的SR 能力.
图3 单次上采样网络
2.2.3 渐进上采样网络
渐进上采样网络(progressive up-sampling network)利用拉普拉斯金字塔网络在前向过程中重建出不同尺度的SR 图像,如图4 所示. 该网络通过CNN 的级联,输入的LR 图像在每一个上采样阶段都会被重建到一个更高分辨率的HR 图像,这种上采样叠加的操作使得网络能够更好地对浅层特征进行利用. LapSRN[40]、MS-LapSRN[62]和渐进式SR (ProSR)[63]也都采用了这种网络结构,并取得了较单次上采样网络更优的性能,并且ProSR 在网络的学习过程中加强了上下文信息的流行性. 渐进式的上采样网络可以解决多种尺度的SR 任务,面对大尺度放大需求,该框架可以有效降低时间复杂度,但是将学习过程拆分为多个阶段会造成网络性能的不稳定.

图4 渐进上采样网络
2.2.4 迭代上下采样网络
迭代上下采样网络(iterative up and down-sampling network)中加入了一种迭代式的误差修正反馈机制,尝试利用反向传播的机制构建相互连接的上采样模块和下采样模块,从而获取到不同层次的分辨率特征,并利用误差对重建后的HR 图像进行加强,网络结构如图5 所示. Haris 等人[50]基于该网络提出了DBPN,通过上采样层和下采样层交替连接的方式将中间所有的重建结果重建最终的HR 图像. 随后,SRFBN[52]采用了迭代的上下采样反馈块,跳过连接更密集,学习到了更好的表示方法. 该框架下的模型可以更好地挖掘LR-HR 图像对之间的深层关系,产生更深层次的特征,从而提供更高质量的重建结果,但目前反向传播模块的设计并没有明确的标准.
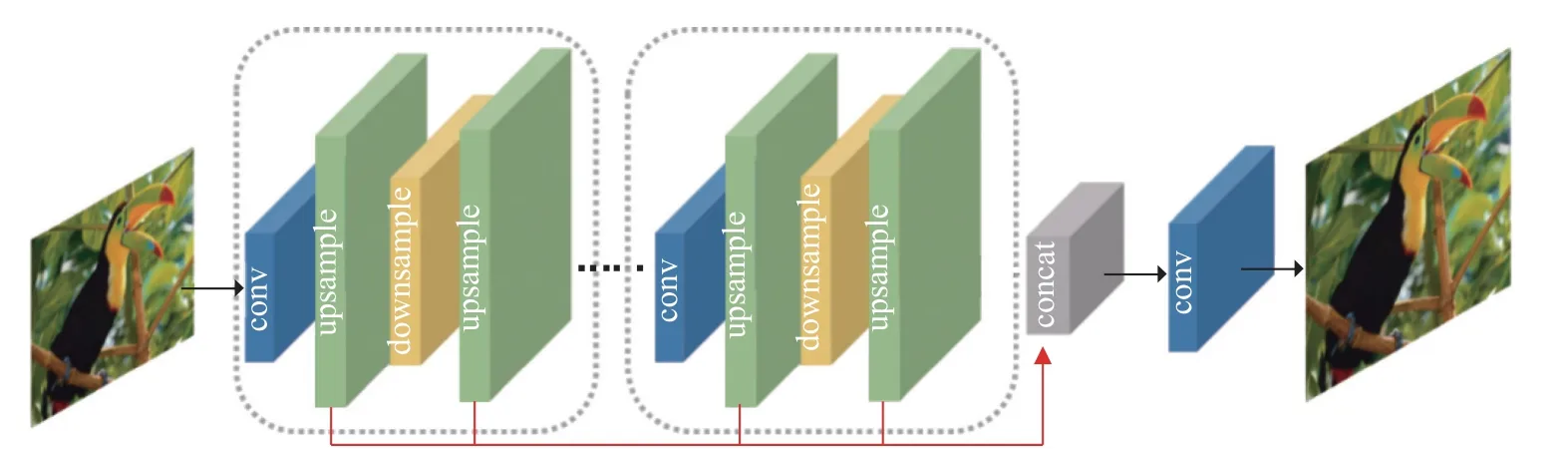
图5 迭代上下采样网络
3 无监督的SISR 深度学习方法
目前,SISR 网络的实现大多数都基于有监督的学习机制,也即使用成对的LR-HR 图像进行模型训练.但想要收集到同一个场景并且具有不同分辨率的图像需要大量的人力和时间成本,而且现有的大多数SR 数据集都需要通过传统的插值算法生成与HR 图像向配对的LR 图像,而这种已知的退化过程对真实场景下的SR 需求并不适用. 因此,基于无监督学习的SR 方法受到研究学者的广泛关注,该方法在训练过程中不需要成对的LR-HR 图像,模型也能学习到真实场景下的图像退化函数,最终获取到的模型更容易适应真实自然场景下的SR 问题. 本小节将对现有的几种无监督学习下的SISR 深度学习方法进行介绍.
3.1 弱监督学习下的SISR 方法
基于弱监督学习的SISR 方法在不利用插值算法构造成对的LR-HR 数据的前提下,使用非配对的LRHR 图像进行网络的训练,在该学习方法下有两种网络训练方式:
一种是先学习HR 图像退化为LR 图像的退化核,再用该函数生成HR 图像对应的LR 图像,以构建成对的LR-HR 数据集用于SR 模型的训练. CVPR2021 年接收的一篇最新的研究无监督学习下的退化感知SISR算法DASR[64],该网络采用无监督学习的方式利用退化表达学习机制自适应地从LR 图像中捕获到具有辨识性的特征,从而获取到准确的退化信息,最后结合对比学习的思想对低分辨率特征进行调制.
另一种是利用循环学习的思想让网络学习LR 图像到HR 图像的映射和HR 图像到LR 图像的退化函数,从而实现相互验证和相互促进. 2018 年,Yuan 等人[65]受到CycleGAN[66]的启发,于是设计了一个由4 个生成器和2 个判别器组合而成的无监督SISR 模型CinCGAN.该网络将HR 图像和LR 图像分别看作两个不同的作用域,并利用CycleGAN 的循环结构来解决真实场景下LR 图像的重建问题.
3.2 零次学习下的SISR 方法
Shocher 等人[67]最早将零次学习(zero-shot learning)应用到SR 领域并提出完全无监督的SISR 深度学习方法ZSSR. 其利用网络在对输入的单一特定图像进行测试时训练SR 网络的思想,学习图像内部的先验特征,进而预测出图像的退化函数,预估出LR 图像与HR 图像之间的退化关系并恢复出图像的高频细节.ZSSR 的实现不需要大型的SR 数据集,只需要通过学习到的退化函数生成小型数据集,并在该SR 数据集上完成网络的训练. 所以,该方法对真实场景下的图像进行重建时具有更大的优势,但ZSSR 需要对每张特定的图像进行上千次的迭代学习,因此其推理时间要远大于其他基于深度学习的SISR 方法. 2020 年,Soh 等人[68]为解决推理时间过长的问题,将零次学习与元转换学习相结合应用到SR 问题中,从而提出了只需一次梯度更新便可使重建效果可观的MZSR 方法. 虽然,基于零次学习方法的SR 网络在未知退化函数的条件下取得了出色的性能,并且能够有效改善自然场景下LR 图像的重建效果,但仍然会存在噪声和伪影.
4 讨论与分析
为了更加直观地比较SISR 的性能,本节将在4 倍放大因子的条件下,对目前一些典型的有监督和无监督的SISR 算法在Set5、Set14、BSDS100 三个基准数据集上分别计算PSNR和SSIM,从定量分析的角度进行对比分析.
由表2 可知,SRCNN 作为第一个将CNN 引入SISR 领域的算法,其得益于CNN 强大的特征捕获和表达能力,使得SRCNN 对单张LR 图像的重建能力远高于传统的双三次插值方法Bicubic; 其次,密集连接、残差连接、特征金字塔等网络结构也在SISR 领域取得了显著的进步,如VDSR[53]、RRDB[56]、LapSRN[40]等算法; 随后,为了解决SR 的不适定性,提高SISR 网络对真实自然场景图像重建的自适应性和泛化能力,研究人员逐渐将反馈回归机制、基于感知损失、先验损失、生成式建模思想、无监督学习等方法用于SISR领域. 其中,基于归一化流的SRFlow 重建方法取得了优异的重建性能,无监督的重建算法ZSSR 也能有效学习到LR 图像的超分辨率信息,其重建性能超越了经典的SRCNN,也为基于无监督学习方法的SISR 研究打下了坚实的基础.

表2 ×4 放大因子下不同算法在Set5、Set14、BSDS100 数据集下的PSNR/SSIM 指标
尽管各类SISR 算法已经取得了显著的进步,但是对结构复杂、纹理信息丰富的图像重建后还是会存在一定的重建伪影、信息丢失等问题,所以SISR 任务仍然面临着许多挑战.
5 总结与展望
本文对深度学习方法在SISR 领域的最新研究进展进行了详细调研与论述. SISR 技术作为计算机视觉领域的重要研究任务之一,其可以作为刑事侦查、医学诊断、遥感图像等领域的有效辅助工具. 基于深度学习的SISR 算法层出不穷,本文主要围绕基于有监督、无监督的SISR 技术进行讨论,也对其中涉及到的背景知识进行了具体的介绍. 虽然SISR 的性能已经取得了显著的提升,但是仍然还存在很多挑战,以下将对SISR 研究过程中存在的问题和未来发展趋势进行总结.
(1)评价指标
SISR 问题中常用IQA 来衡量SR 算法的性能,PSNR和SSIM作为两个最常用的评价指标. 前者容易导致过度平滑的问题,使得差异较小的图片之间的定量分析误差较大,而后者虽然从亮度、对比度和结构细节方面模拟人类的视觉感知,但是不能完全准确表示图像的视觉感知效果,MOS 虽然与视觉感知质量最为相近,但是其评估过程需要消耗大量的时间和人工成本. 所以,制定通用的、准确的SR 质量评价指标是目前亟待解决的问题.
(2)真实场景图片的SR
自然场景下的图片常常会受到加性噪声、运动模糊、压缩伪影等因素的影响,使得模型面对未知的退化问题,缺少成对的真实场景下的LR-HR 图像. 因此,在有人工设计的数据集上训练的SISR 模型对自然场景图像的重建效果并不理想. 虽然,已经有很多研究方法被提出,但是仍然存在训练难度大、重建细节不够完善等缺点. 因此,针对未知图像退化过程的建模依旧是SISR 的重要发展方向.
(3)网络框架的设计趋势
一个好的网络框架不仅能提升SISR 的性能,还能有效减少模型的时间复杂度和空间复杂度. 因此,后续可以考虑在模型的学习过程中,将全局信息和局部信息、底层特征与高层次特征相结合的思想,利用不同尺度、不同层次的语义信息加强网络对图像特征的表征能力,从而提升SISR 算法的重建性能.
(4)上采样方法的改进
目前使用的上采样方法会存在不能端到端学习、感受野分布不均匀、会产生棋盘效应等问题,因此会导致SISR 算法低效、重建效果不稳定等问题. 同时目前的上采样多为整数倍. 所以,探索出一个高效地、适用于任意放大因子的上采样方法是未来值得进一步研究的方向.
猜你喜欢
今日农业(2022年15期)2022-09-20
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
河南科技(2021年35期)2021-04-25
小天使·二年级语数英综合(2019年10期)2019-11-08
福建基础教育研究(2019年6期)2019-05-28
CHIP新电脑(2016年3期)2016-03-10
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
微型计算机(2009年4期)2009-12-23
