
基于深度学习的天网图像质量评价研究
2022-08-03 08:59农忠海刘向荣
数字通信世界 2022年7期
农忠海,刘向荣
(广西警察学院,广西 南宁 530023)
0 引言
近几年,公安机关开展天网工程建设,全国摄像头数量已超过2 000万个[1],视频监控在公安侦查破案、治安防控、警务指挥、社会管理等公共安全领域发挥了重大作用。天网视频监控系统对公共安全及时预防、现场处理和现场管控,应对突发事件起到非常重要的作用。
天网是大型社会视频监控系统,监控点规模庞大、所处环境复杂,在视频监控图像的获取、压缩、传输等过程中难免会存在一些异常干扰因素,这些都会造成图像质量的下降(降质、失真),从而导致其中包含的信息丢失,视频监控图像经常出现抖动、模糊、偏色、画面冻结、黑屏与播放延时、亮度异常、视频源丢失等异常现象。
往往因为一些天网摄像头关键点图像质量不好,直接影响了公共安全相关业务工作。面对海量前端摄像机,如何及时、准确地管理与掌握前端摄像机的视频图像质量,保障监控系统良好运行,及时处理故障,提高维护效率,进一步提高图像联网监控系统的建设与应用,促进治安防控体系的完善,已成为天网视频监控系统真正发挥作用急需解决的问题,也是确保系统发挥良好社会效益的重要任务。
对天网视频图像质量监测,最初阶段是采用人工检查的主观评价方法,随着监控摄像机数量在逐年增加,该方法已经无法完成工作任务。现在普遍采用视频质量轮巡系统的客观评价方法,对大规模视频图像质量的检测,在效率上有了很大的提高。视频质量轮巡系统所采用的核心算法是基于传统的无参考图像质量评价方法,主要采用基于人工特征提取的方法,该方法解决了天网视频图像质量监测存在误报率高、漏报率高、准确度不高等问题。本文主要研究应用深度学习算法提高天网视频监控异常图像发现的准确性。
1 图像质量评价方法概述及存在问题
1.1 图像质量评价方法概述
图像质量评价有主观、客观两种方法[2]。主观图像质量评价方法就是采用人工肉眼观看的方式,由人对正常图像和异常图像进行评价的方法。在图像数量少的情况下,可以采用主观图像质量评价方法,但是像天网这样具有海量监控图像的系统,该方法就难以完成任务。客观图像质量评价方法就是通过计算机程序根据一定的参数对图像质量进行判定的方法,而使用全参考图像进行判定的叫全参考客观图像质量评价方法,使用部分参考图像进行判定的叫半参考客观图像质量评价方法,不使用参考图像进行判定的叫无参考客观图像质量评价方法[3]。
全参考图像质量评价需要将失真前图像的所有信息和失真图像进行对比,如均方根误差(MSE)和峰值信噪比(PSNR)[4]。半参考图像使用失真前图像的部分信息作为参考,对失真后图像质量进行评价。全参考和半参考的图像质量评价方法多用于图像传输和压缩。
1.2 存在的问题
在实际应用中,如果要对图像的清晰度衰减程度进行评价,图像清晰度的衰减可能来自于传输和压缩,此时可以通过和压缩传输前的图像进行比对来衡量其衰减程度。但更多的图像质量问题是来自于聚焦错误或其他意外故障,这是我们主要关注的异常情况,此时图像的来源即摄像机端的图像已经失真,没有无失真图像可参考,所以要用无参考图像质量评价方法。无参考图像质量评价是一种无须原始图像任何信息,直接对目标图像进行质量评价的方法,是实际应用中最广泛的评价方法。
目前的天网视频质量轮巡系统基于传统的无参考图像质量评价方法,采用基于人工特征提取的方法,对图像的模糊、曝光、偏色以及遮挡等指标进行判断,在对于单一摄像机或者网上公开的图像质量数据集如LIVE、TID2008/TID2013等进行判断方面取得了较好的效果,但在实际应用中效果并不理想。基于传统方法的图像质量评价方法主要存在模型容量小,无法考虑摄像机的多样性,以及在实际使用中场景的复杂性,对实际场景泛化能力差等缺点。
1.3 深度学习模型
深度学习是一种模拟人脑神经网络的一种算法,在很多专门领域应用达到了像人脑一样学习、归纳的效果,目前在图像质量评价方面也有一些应用研究。比如,在计算视觉与模式识别领域顶级国际会议CVPR 2014上,Kang等人的论文“Convolutional Neural Networks for No-Reference Image Quality Assessment”[5]设计的卷积神经网络(CNN),对图像的一部分和整幅图像都进行质量评价。
深度学习卷积神经网络(CNN)的特征提取层参数是通过训练数据学习得到的,避免了人工特征提取,通过同一特征图的权值共享,大幅减少了网络参数,同时也降低了图像质量评价实现的复杂度。CNN具有良好的容错能力、并行处理能力和自学习能力,在处理二维图像问题上具有良好的鲁棒性和运算效率。因此,应用深度学习,在天网视频监控图像质量评价方面将有比传统方法更好的效果。
2 基于深度学习的天网图像质量检测研究
2.1 总体研究思路
本文研究使用深度学习卷积神经网络(CNN)模型算法对视频监控图像进行质量检测。首先人工对天网中存在的异常视频监控图像进行抓取;然后人工标定异常图像为清晰、轻微模糊或严重模糊,并对应的异常图像提取历史记录的清晰图片;接着对输入图像进行裁剪和缩放预处理,处理后的数据在tensorflow serving进行数据训练,以获得有效的图像质量评价模型。本文的图像质量评价算法基于优化卷积神经网络(CNN),进行天网视频监控图像质量评价方法有三种,分别是清晰度评价、曝光评价和偏色评价。
陈欣的“基于深度学习的无参考模糊图像质量评价方法研究”[6],采用传统CNN方法在图像上取不同的块分别计算清晰度值然后求平均,由于图像空白区域和被虚化的部分都是模糊的,因此会将这两种图像评价为偏向模糊,实际上这两种图像都是正常的清晰图像。针对天网视频监控图像的特点,本文提出取所有图像块的均值作为整张图的评价值,将整张图像采样同时输入网络,考虑图像不同区域清晰度的差异,尤其是对存在大面积空白和背景虚化的图像。
通过tensorflow serving构建卷积神经网络,以从监控平台抓取的图片作为训练数据,训练出可以评价图像清晰度、曝光和偏色模型并测试效果,采用“理论模型→原型系统→实验验证→理论模型”的做法。
2.2 实验过程
2.2.1 数据获取
训练卷积神经网络所用的数据主要来自天网抓取的图像数据,包括多种前端设备,从分辨率为1080 p图像到CIF图像,工作模式包括可见光和红外,场景包括室内、室外、交通、卡口等多种场景共32 516张图像,取出60%作为训练集,分别取20%作为验证集和测试集。
2.2.2 数据标定
由于抓取图像的前端设备的种类非常多,且场景多,不同类型的前端成像效果不同,为了减少人工标定时的复杂度,我们将图像清晰度分为清晰、轻微模糊、严重模糊三个等级。
一级:清晰图片,指图像内容边缘清晰、细节纹理丰富,清晰度无明显衰减。
二级:轻微模糊,指图像的内容大致都能看清,边缘不够锐利,画面中的纹理不明显,清晰度有一定程度的衰减。产生该问题的主要原因是轻微的失焦。
三级:严重模糊,指图像有明显的模糊,导致部分内容已经无法分辨,纹理和边缘基完全看不到。产生这种问题的主要原因是严重的失焦。
对于不同分辨率的图像清晰度的比较,我们仅考虑实际分辨率下图像内容是否清晰,即以达到图像分辨率极限作为最清晰,所有图像在标定时以原始分辨率查看。
2.2.3 数据预处理
由于采集的图像大多是1080 p和720 p的高清图像,1080 p单帧的输入节点数为1920×1080×3,如果直接输入原图,则需要对整张图像进行卷积,计算量非常大,会严重影响图像质量评价系统的运行效率,所以要对输入图像进行裁剪和缩放。
对于清晰度评价算法则不能对图像进行缩放,因为缩小图像会导致图像的高频信息丢失,无法分辨图像的清晰度,所以采用裁剪下的图像块作为输入。在原图像上等间距裁剪20个1×64的图像块,将20个1×64的图像在垂直方向层叠,生成一个高20宽63的三通道图像。
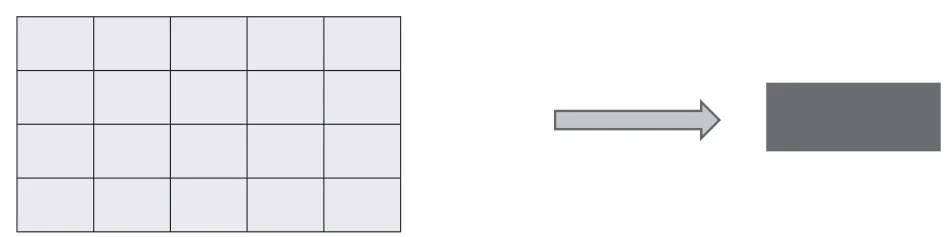
图1 图像块裁取方式
这里假设图像在垂直方向的分辨率和水平方向分辨率是相同的。在实际应用环境中,由于sensor和镜头像差,垂直方向和水平方向的分辨率是不同的,但相对于图像清晰度出现异常情况和正常情况清晰度的差别,垂直和水平方向分辨率的差异可以忽略,为了减小计算量和内存占用,提高运行速度,从图像中随机裁剪1×64的图像块作为输入。
实际图像各部分的分辨率是不一致的,如果对所有选区的样本进行标定,则工作量太大,难以实现,所以近似图像每个部分分辨率一致。由于清晰度值是连续的,采用一个数值来表示每个图像清晰度,将不同三个清晰度值分别映射到0、0.5和1。
对于曝光和偏色算法,将图像统一缩放到96×96,然后随机裁剪出64×64的图像块作为输入,这样既保留了图像颜色和亮度信息,又能反映出图像整体的亮度和颜色分布。分别用偏蓝值和偏红值来表示图像偏色程度,用一个曝光数值来表示图像曝光情况。
2.2.4 模型训练
清晰度评价模型的输入大小为1×64,基于CNN的分类网络,将网络结构在水平方向上做卷积和池化,在20个图像块分别经过相同参数的卷积和池化以及一个全连接层后,得到一个大小为[batch_size,20,36]的tensor,batch_size为一个batch的样本图像数目,20表示输入中包含的20个图像块样本,36为每个样本最后的输出节点数,最后将20个样本中每个样本的36个节点合并成一个720节点的向量,经过一个全连接层,输出1个清晰度值。取所有图像块的均值作为整张图的评价值,对整张图像采样同时输入网络考虑了图像不同区域清晰度的差异,尤其是对存在大面积空白和背景虚化的图像。传统CNN方法在图像上取不同的块分别计算清晰度值然后求平均,由于图像空白区域和被虚化的部分都是模糊的,因此会将这两种图像评价为偏向模糊,实际上这两种图像都是正常的清晰图像。

图2 清晰度评价网络
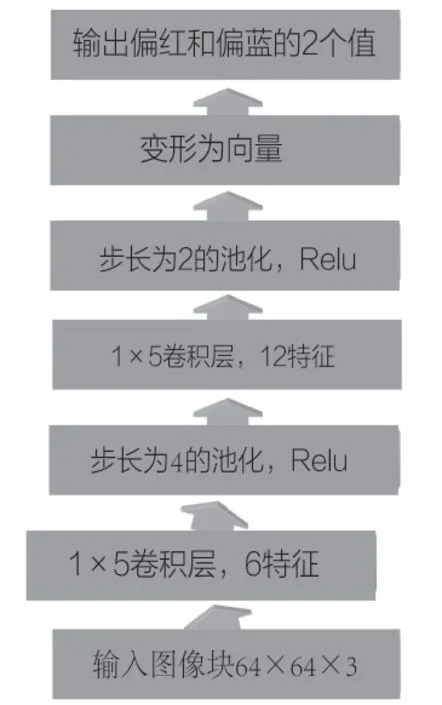
图3 偏色评价网络
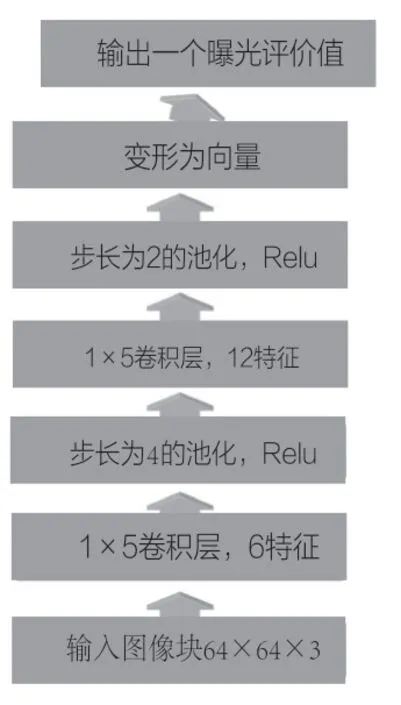
图4 曝光评价网络
曝光评价模型输入为64×64×3,即先将图像缩放到64×64大小,基于CNN回归网络,输出一个值评价曝光程度。
偏色评价模型输入为64×64×3,即先将图像缩放到64×64大小,基于CNN回归网络,输出两个值评价偏色程度。
经过200个epoch的训练,清晰度评价模型交叉熵收敛到0.4,曝光和偏色模型分别收敛到0.09和0.11。
2.3 应用效果与模型验证
部署基于tensorflow serving,分为client端和server端,server端运行在有GPU的服务器上,可以实现同时对多路图像进行分析。
在推断时,在输入图像上取等间距的20个1×64的图像块作为输入x[20],分别得到20个块的分类结果y[20],统计y[20]中三个分类的个数,取个数最多的分类作为整张图片的分类结果。

图5 清晰图像与切块后的输入

图6 轻微模糊图像与切块后的输入

图7 严重模糊图像与切块后的输入
采用皮尔逊线性相关系数PLCC(Pearson Linear Correlation Coefficient)对图像评价方法进行评价,PLCC的数学表达式为

式中,n为图像数量;为主观图像质量评价分值;为客观图像质量评价分值;分别表示两组数据的均值。
应用上述方法在测试集数据上测试了清晰度分辨模型,PLCC达到了0.80。这个结果比已有的研究在LIVE或TID2008等公开数据集上得到的超过0.9的PLCC准确率要低得多。应该是天网实际场景图像比公开数据集的情况复杂,因此准确率相对较低。
应用本图像质量评价模型,通过对天网图像质量轮巡系统上的1000台设备进行了轮巡,检测出存在图像模糊问题的设备26台,准确率0.81,召回率0.82,存在偏色问题的设备5台,存在曝光问题的设备8台。
3 结束语
基于深度学习的天网图像质量轮巡系统,可以利用大数据的优势,对实际应用中摄像机种类多且场景复杂的情况有较好的泛化能力,相对于传统方法更适用于实际应用,提高了发现问题设备的准确率。在应用过程中还可以通过对异常图像的采集,经过人工标定,加入训练数据,后续只要更新模型模块即可不断提高图像质量评价的准确率。得益于当前深度学习硬件加速技术的发展,基于深度学习的天网图像质量轮巡系统可以有很高的运行速度,在短时间内对大量设备进行轮巡,可用于公安部门天网摄像头轮巡,也可拓展延伸到交通部门、电力行业、大型建筑群、运营商监控等建设有大型视频监控系统的领域。■
猜你喜欢
医院管理论坛(2022年8期)2022-10-14
疯狂英语·新读写(2021年10期)2021-12-07
成都信息工程大学学报(2021年2期)2021-07-22
作文·初中版(2021年5期)2021-06-18
家庭影院技术(2020年11期)2020-12-28
家庭影院技术(2020年4期)2020-05-21
电声技术(2020年10期)2020-03-24
启迪与智慧·下旬刊(2019年6期)2019-09-10
扬子江(2018年5期)2018-09-26
体育科研(2014年5期)2014-04-16
