
基于气象与非气象因素的客流量单数逐日预测模型
2022-08-03 07:36夏江江
气象与环境科学 2022年4期
乔 媛,姜 江,夏江江,白 帆,蒋 志
(1.北京市气象服务中心,北京100089;2.中国科学院大气物理研究所,北京 100029;3.北京市门头沟区气象局,北京 102300)
引 言
客流量单数(以下简称为客单数)的实际含义是指客流量中有效的收入来源部分,即达到商场后的顾客真实买单的单数。客单数是经营环节中非常重要的指标,因为客单数越多,经营者的收入自然也越多。事实上,经营者常感到客单数变化的不可测、不可控。原因在于客单数受到很多因素的影响,且短期内的客单数会呈现出比较复杂的非线性特征。加之国内大部分经营者的信息化起步较晚,存在着历史数据不连续或数据量较少的问题,致使以往的研究很难对客单数的影响因素进行深入分析,造成了客单数的相关研究中,预测值和真实值之间存在着较大的偏差,难以开展进一步的业务化应用工作。
以往的客流量相关研究当中,更多的是针对各类自然风景区[1],而对居民区附近超市的客单数研究较少。考虑到景区是门票制,景区的门票数可以相当于超市的客单数,因而前人的研究方法同样可以借鉴。早期的景区客流量预测方法以传统的时间序列预测思路为主,如指数平滑模型[2]、时间序列模型[3-4]、多元回归[5-6]、网络搜索方法[7]等,但这些模型缺少对样本学习的过程,重点放在时间趋势的外推,对具有线性特征的客流量有很好的预测效果,但往往难以实现复杂的非线性客流量预测。随着机器学习理论的深入推进,一些新的人工智能算法在电力、交通、旅游、气象等短期非线性序列预测中得到了大量应用[8-9]。如BP神经网络、支持向量机、最小二乘支持向量机、反向传播神经网络等[10-13],均在客流量短期预测中取得了很好的应用效果。
由于经济学与气象学领域的学科交叉性,在预测要素的选择时,气象因子在其中发挥的作用总是一定程度上被忽视[14-16]。实际上,气象因子对客流主体的影响是不可忽略的。比如,天气的“好”“坏”是可以直接感受到的。好的天气会让潜在的顾客感觉身体舒适、心情舒畅,使其出行购买的欲望得到提升。反之,当天气条件不好的时候,会让潜在顾客的出行购物欲望降低。另外,从交通角度来说,天气条件也影响着顾客目的地可达的难易程度。天气条件有利,目的地可达程度容易,促使购买变为现实。反之,天气条件不利,目的地可达程度变难,导致购买行为减少。当然,“好天气”“舒适的气候”或“感到舒服的天气”,在不同的人群中可能存在着一定的差异[17-18]。Martin等[19]的研究中也明确指出这些概念是相对的,对于一些人来说感到“舒适”时,可能对另一些人来说则是相反的。就此问题,前人在相关的预测研究中会加入“气候舒适度”作为一项输入因素,以此来减弱客体主观感受的差异,从而能够尽可能地代表多数人的感受[20-21]。
鉴于此,建立一个科学准确的、且能够反映出客流量与天气等要素之间定量关系的短期超市客单数预测模型,对超市经营团体乃至整个商业服务行业的实用价值是非常明显的。本文将基于2019年北京西北部地区42家同一品牌下,且规模大致相同的超市逐日客单数资料,结合超市地理位置相对应的气象要素数据,在梳理气象因子与客单数之间关系的基础上,试验多种机器学习方法来建立与天气有关的客单数逐日预测模型。所得研究结果能够较为准确地预测客单数,有助于经营者对商业行为开展提前规划和科学决策,充分利用人力和物力成本,进行节能减排。
1 数据与方法
1.1 客单数数据
客单数的数据来自北京西北部地区42家中型超市。它们均不是新开超市,不存在由于超市环境、商品结构和补货能力的差异影响。同时,它们均隶属于同一品牌,也不会存在不同的商品价格差异,以及不同的员工销售技能差别。研究中曾指出空间距离、经济收入、人口密度都是影响热点客源市场客流量的主要因素[22-25]。本文所选择的42家超市都是以周边稳定的居民区为主要对象的中型超市,各个超市的购买能力较为稳定,因而也会更多地产生对天气因素的依赖。2020年年初开始受限于疫情的影响,客单数的数据较为特殊,为避免信息干扰,仅获取2019年有完整记录以来共365天的样本进行数据分析。由于整体数据量过小,为避免缺测数据量过高对预测结果带来的影响,则从42家不同超市中,筛选出缺测数据量低于5%的超市,共34家。其中,海淀区31家,丰台区1家,东城区1家,昌平区1家。
1.2 气象数据
根据缺测数据量低于5%的34家超市具体的经纬度坐标,分别将其对应到地理位置最接近的气象站点(表1)。共匹配到气象站点12个,分别为A1001、A1024、A1029、A1034、A1054、A1061、A1065、A1068、A1069、A1074、A1076和A1445,涉及的基础气象要素为日平均气温、日相对湿度、日平均风速和日总降水量。
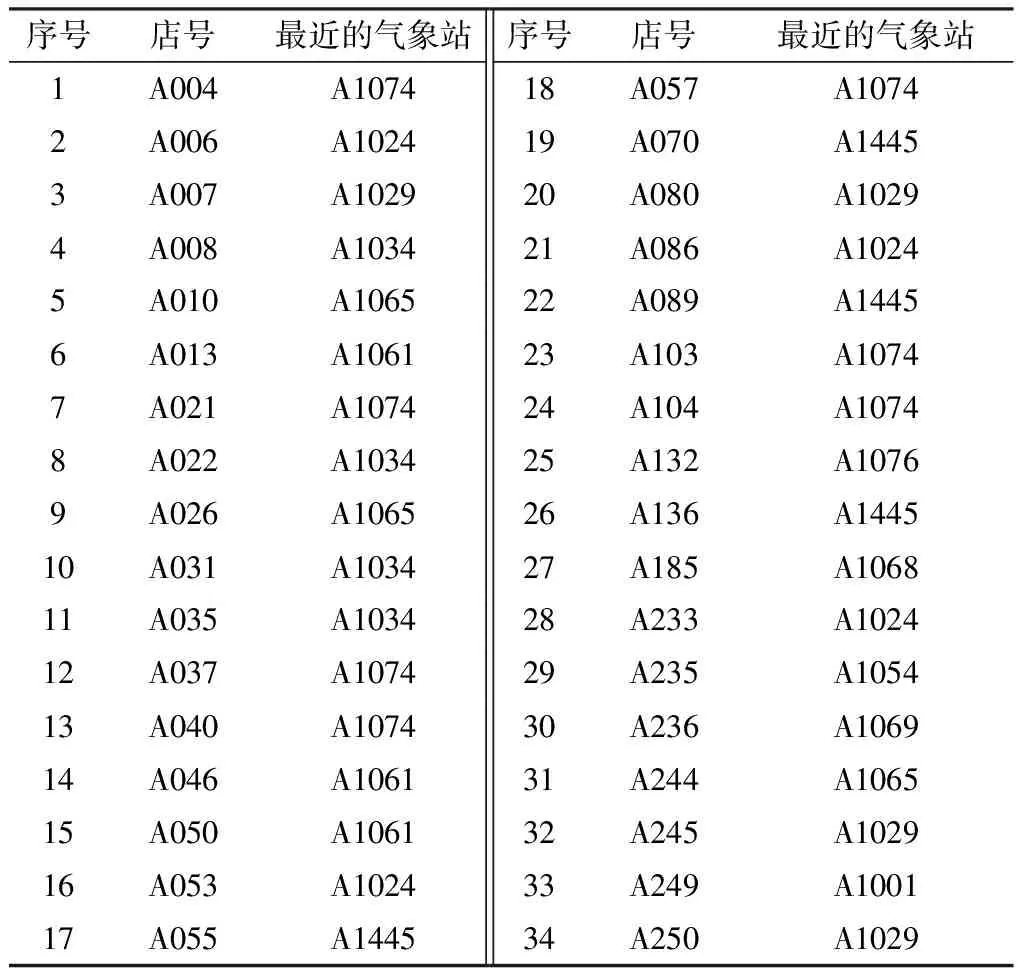
表1 北京西北部地区34家超市店号及其地理位置最近的气象站点
1.3 方 法
1.3.1 输入因子
在预测模型中输入的气象因子包括气温、相对湿度、风速和降水量。同时,考虑到天气现象的“好”与“坏”不易描述,也较难统一,在输入因子选择时,还采用了舒适度指数(Effective Temperature,ET)来反映气温、相对湿度、风速对人体舒适度的综合影响[26],计算公式如下:
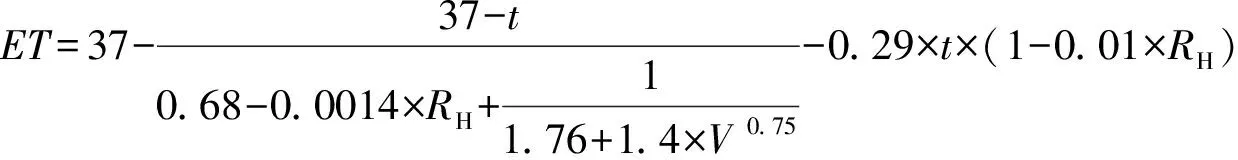
(1)
其中,t为气温(单位:℃),RH为相对湿度(单位:%),V为风速(单位:m/s)。ET指数能够覆盖从寒冷到炎热的各种气候类型,可反映出人体的普遍感知。其中,降水量不同于其他的气象因子,降水量具有不连续的非正态分布的特点,因而单独将降水量按日累积雨/雪量进行了等级转化(表2)。

表2 降水量等级表
另外,超市经营者认为“星期”“是否节假日”和“是否节气”都与北京地区的购买习惯有一定的关联。比如顾客偏向于周五至周日、或者在节假日和节气当天去采购商品。综合考虑,最终可输入的因子共为8项,其中气象因子5项,非气象因子3项,具体见表3。

表3 机器学习模型的输入因子
1.3.2 机器学习方法
鉴于经济学与气象学领域的学科交叉性,在预测方法选择时,使用了多种解决回归问题的机器学习方法,以充分利用各种方法的特点,尽可能地降低预测值和真实值之间的偏差。具体如下:
(1)多元回归方法(Multiple Regression,MR):常被用来研究一个因变量与多个自变量之间的关系问题。具体公式如下:
yj=β0+β1x1+β2x2+…+βmxm+εj
(2)
式中,β0,β1,…,βm均为模型的回归系数,εj为随机残差。
(2)支持向量机(Support Vector Machine,SVM):SVM方法通过核函数将输入低维的原始数据映射到高维的新特征空间,同时将非线性回归问题转化成线性回归问题。其中,SVM的线性回归模型为
f(x)=wφ(x)+b
(3)
式中,w、b是待估参数,φ(x)是非线性映射。
(3)随机森林(Random Forest,RF):随机森林构造出多棵决策树,当需要对某个样本进行预测时,统计每棵决策树对该样本的预报结果,然后通过投票法从这些预报结果中选出最后的结果。随机森林算法本质上是在决策树的训练过程中引入随机属性,对样本进行有放回采样,对属性进行无放回采样。
(4)迭代决策树(Gradient Boost Regression Tree,GBRT):单决策树由于功能太简单,并且非常容易出现过拟合的现象,于是引申出了许多变种决策树,就是将单决策树进行模型组合,形成多决策树,比较典型的就是迭代决策树和随机森林。GBRT是一种迭代的决策树算法,算法由多棵决策树组成,所有树的结论累加起来做最终结果。
(5)K最邻近分类算法(K-Nearest Neighbor,KNN):如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
(6)多层感知器(Muti-Layer Perception,MLP):多层感知器主要是模拟生物神经系统对真实世界物体所做出的交互反应,通过调整内部大量节点之间相互连接的关系,达到处理信息的目的。通常在测试的过程中可以不断调整节点数以取得最佳预报效果。其中,输入层的每个节点,都要通过加权求和和激活函数(激活函数有很多种,本文使用的是比较常用的Sigmoid函数)来与隐藏层每个节点做点对点的计算。输入层的数值通过计算分别传播到隐藏层,再以相同的方式传播到输出层,得到最终的输出值,同时也要将输出值和样本值作比较,根据计算所得误差再对神经网络中的权重和阈值进行调整。
1.3.3 检验方法
为客观地对比多种方法得到的预报差异,选用均方根误差(Root Mean Squard Error,RMSE)来检验预报效果,公式如下:
(4)
式中,ri为某样本的客单数预报值,ti为相对应的客单数的真实值,n为试验样本总数。在本文中由于样本量较少,很难单独分月或者分季节去进行预测,所以在检验环节的均方根误差计算中,采取样本总量(365天)的5%(18天)进行交叉验证。
2 结 果
2.1 气象因素与客单数间的关系
不同超市的客单数与气象因子相关关系的差异是非常明显的,有的甚至与气象因子基本不存在相关关系,如店号为A235和A236这两家超市。经与超市的销售部门沟通和实地调研发现,A235和A236两家超市均位于北京地区的五环外,居民区和人口密集程度相对其他超市的差距非常大。同时,这两家超市所在的小区附近0-3 km内均没有大型正规的品牌商场和超市,没有可替代的实体购买渠道,并且这两家超市的位置均位于小区居民楼内,其销售模式波动或更依赖于“是否节假日”,与气象因子的关联性相对较低(表4)。因此,在下文的预测试验中去掉了A235、A236两家超市。
另外32家超市的相关分析结果中,客单数与气象因子间相关性最高的为气温(相关系数为0.11~0.71,平均值为0.45,有97%的超市通过0.01的显著性检验),其次为舒适度(相关系数为0.11~0.70,平均值为0.44,同样有97%的超市通过了0.01的显著性检验)。客单数与气温及舒适度均呈现正相关关系,反映出随着气温和舒适度指数的升高,客流量会在一定程度上增加。客单数与风速(相关系数为-0.37~0.08,平均值为-0.11,有31%的超市通过0.01的显著性检验)、相对湿度(相关系数为-0.18~0.24,平均值为0.08,有47%的超市通过0.01的显著性检验)和降水量(相关系数为-0.18~0.06,平均值为-0.05,有6%的超市通过0.01的显著性检验)多呈现负相关关系,这表明随着风速、相对湿度和降水量的降低,客流量会在一定程度上有所增加(表4)。

表4 北京西北部地区34家超市2019年客单数与气象要素的相关性
32家超市的日平均客单数为358~5490单,平均单数为2241单(图1)。各个超市本身的日客单数的差异为363~6653单。客单数本身的波动性变化是非常明显的,而8项输入因子的变化也是造成这种波动性的主要原因。

图1 北京西北部地区32家超市2019年平均客单数
2.2 仅气象要素作为输入因子
根据相关分析的结果,首先尝试将气温、舒适度、风速、相对湿度和降水量5项气象因子作为输入因子,6种模型预测结果显示,对逐日客单数预测效果最佳的是SVM模型(图2)。

图2 北京西北部地区32家超市基于5项气象因子的6种模型预测效果对比
对5项气象输入因子的预测效果利用RMSE进行对比发现,分别有43.75%的超市采用SVM模型,21.88%的超市采用MR模型,12.50%的超市采用GBRT模型,12.50%的超市采用KNN模型,6.25%的超市采用RF模型,3.12%的超市采用MLP模型。其中,平均预测效果最好的店号是A245,其平均日客单数为358单。6种方法预测结果的RMSE为33.9~38.0单。平均预测效果最差的店号是A035,其平均日客单数为5358单。6种方法预测结果的RMSE为519.5~632.5单。
2.3 非气象因素作为输入因子
当仅选择星期、是否节假日、是否节气3个非气象因子作为输入因子时,同样利用相同的95%的样本作为训练集,5%作为测试集,结果显示,6种预测方法对逐日客单数预测效果最佳的是RF模型(图3)。

图3 北京西北部地区32家超市基于3项非气象因子的6种模型预测效果对比
利用RMSE结果进行对比,分别有34.38%的超市采用RF模型,31.25%的超市采用SVM模型,21.88%的超市采用GBRT模型,9.38%的超市采用MR模型,3.11%的超市采用MLP模型;没有超市采用KNN模型。平均预测效果最好的店号是A245,其平均日客单数为358单。6种方法预测结果的RMSE为43.0~46.7单。平均预测效果最差的店号是A035,其平均日客单数为5358单。6种方法预测结果的RMSE为537.0~639.7单。
2.4 全因素作为输入因子
当选择气温、风速、相对湿度、降水量级别、ET指数共5个气象因子,加上星期、是否节假日、是否节气3个非气象因子,共8项混合输入因子,利用同样的训练集和测试集,预测结果显示,6种预测方法中对逐日客单数预测效果最佳的是GBRT模型(图4)。

图4 北京西北部地区32家超市输入为8项因子的6种预测模型效果对比
利用RMSE结果进行对比,分别有28.13%的超市采用GBRT模型,25.00%的超市采用MR模型,21.88%的超市采用SVM模型,15.63%的超市采用RF模型,9.36%的超市采用KNN模型;没有超市采用MLP模型。平均预测效果最好的店号是A245,其平均日客单数为358单。6种方法预测结果的RMSE为29.3~39.4单。平均预测效果最差的店号是A035,其平均日客单数为5358单。6种方法预测结果的RMSE为446.8~555.4单。
2.5 不同输入因子的预测效果对比
当5项气象因素作为输入因子时,有43.75%的最优结果来自SVM模型,基于GBRT、KNN、MR、RF、SVM、MLP得到的平均RMSE及6种方法得到的平均RMSE的均值分别为191.4、195.5、169.6、190.9、164.3、187.8和183.2单。
当3项非气象因素作为输入因子时,有34.38%的最优结果来自RF模型,相应顺序的平均RMSE分别为174.4、136.7、153.0、138.7、182.9、187.4和162.2单。
当全因素作为输入因子时,有28.13%的最优结果来自GBRT模型,相应顺序的平均RMSE分别为146.1、157.3、134.4、145.0、138.8、175.1和149.4单。全因子的平均预测效果最佳(图5)。
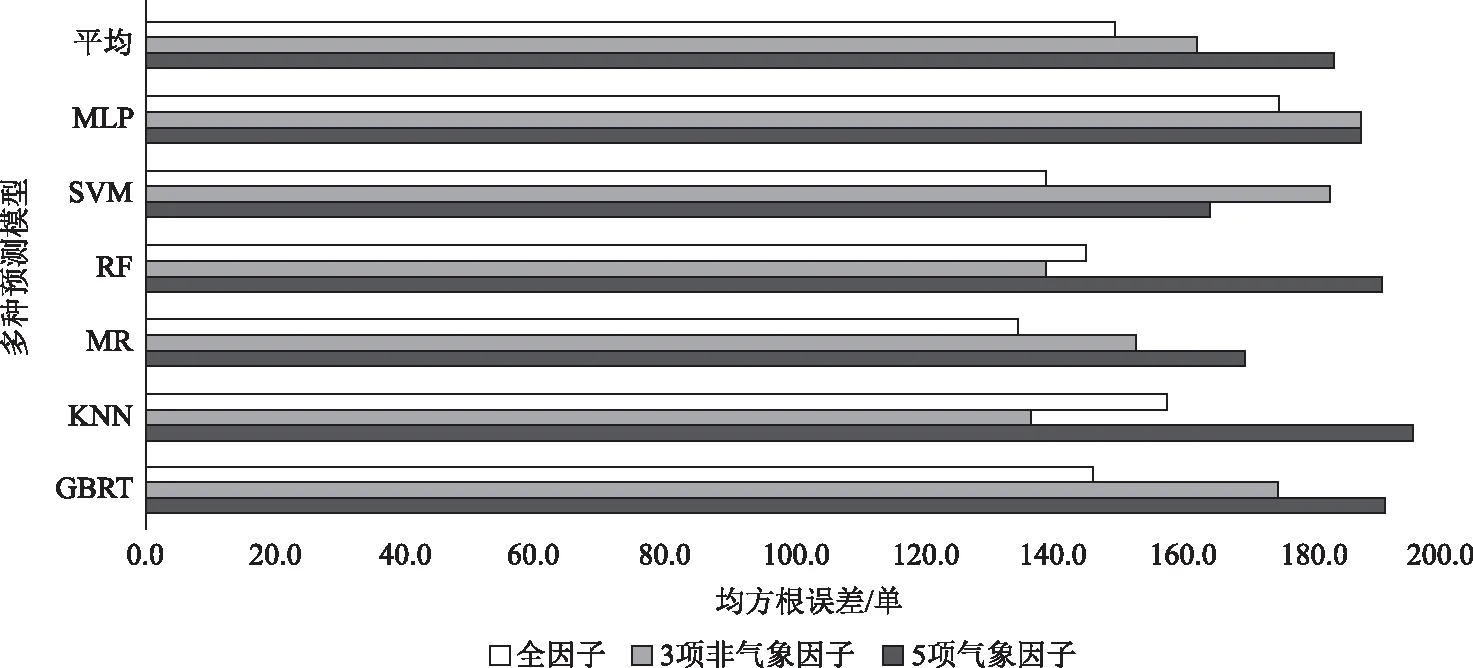
图5 北京西北部地区32家超市不同输入因子的6种方法平均预测效果对比
当全因素作为输入因子时,GBRT、KNN、MR、RF、SVM、MLP预测结果及6种预测方法平均预测结果相比于3项非气象因子预测得到的RMSE分别减少了16.2%、-15.1%、12.2%、-4.5%、24.1%、6.6%和7.8%,预测效果提升最多的模型是SVM方法。同样,当全因素作为输入因子,GBRT、KNN、MR、RF、SVM、MLP预测结果及6种预测方法平均预测结果相比于仅5项气象因子预测得到的RMSE分别减少了23.7%、19.5%、20.8%、24.0%、15.5%、6.8%和18.4%,预测效果提升最多的模型是RF方法。整体而言,全因素作为输入因子时的预测效果相对于其他两种方案都是提升的(图6),且提升效果最多的模型也是预测效果最好的模型,如SVM、RF和GBRT。

图6 北京西北部地区32家超市不同预测方案的客单数均方根误差的降低比率
3 结论与讨论
(1)在通过0.01的显著性检验的结果当中,客单数与气象因素间的相关性反映出随着气温和舒适度指数的升高,客流量会在一定程度上有所增加。而随着风速、相对湿度和降水量的降低,客流量会在一定程度上有所增加。预测结果的分析显示,6种方法预测效果最好的超市均为A245,预测效果最差的均为A035。相对其他超市而言,A245客单数最低,A035客单数最高。整体上,客单数偏低的超市预测效果更优。
(2)在6种预测方法中,当输入因子选择为气温、风速、相对湿度、降水量级别、ET指数,加上星期、是否节假日、是否节气3个非气象因素,共8个进行全因子训练后,预测效果是最佳的。就32家超市的平均预测效果而言,GBRT、KNN、MR、RF、SVM、MLP及6种方法的平均预测效果相比于仅5项气象因子作为输入的预测模型的RMSE减少了6.8%~24.0%;相比于3项非气象因子预测得到的RMSE减少了-15.1%~24.1%。相对而言,渐进梯度回归树预测效果最佳,支持向量机和随机森林的次之,K最邻近分类算法和多层感知器的效果较差。
(3)通过试验6种机器学习方法来建立与天气有关的客流单数逐日预测模型,结果发现机器学习回归方法是可以有效地进行客单数预测的,且考虑的关联因素越多,预测效果也就越好。在后续的业务使用中,只需要输入未来不同地理位置的逐日天气预报结论,即可得到相应超市的客单数逐日预测情况,从而使经营者对商业行为开展提前规划。但需要指出的是,客单数越大的超市预测误差也相对越大,原因在于客单数越大的超市,影响客单数的不可知因素越多且越复杂,比如小区居民的集中程度、年龄分布、文化习惯、周围可替代超市的数量和距离等,并且这些因素都很难获取,导致了不同超市的客单数与气象因素的相关关系差异非常明显,需要未来继续积累相关数据,进一步提高预测效果。
猜你喜欢
小猕猴学习画刊(2021年9期)2021-10-11
现代电子技术(2021年15期)2021-08-06
数学大王·中高年级(2019年5期)2019-06-09
电子制作(2018年16期)2018-09-26
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
小学生导刊(低年级)(2016年12期)2016-12-07
读写算·小学低年级(2015年2期)2015-12-04
