
诗人密码:唐诗作者身份识别
2022-08-02 03:57:08张益嘉鲁明羽
中文信息学报 2022年6期
周 爱,桑 晨,张益嘉,鲁明羽
(大连海事大学 信息科学技术学院,辽宁 大连 116026)
0 引言
作者身份识别(Authorship Attribution),简单地说,就是对人们各自的言语、写作特点在统计量上的差异进行分析、处理、归纳和推理的过程[1]。其理论基础是文本的语言结构特征表现了作者个人在写作活动中的言语特征,是作者个人风格不自觉的深刻反映,这些特征可以在一定程度上进行量化并以此确定匿名文本的作者。作者身份识别最早源于1851年 Augustus De Morgan 使用词长频率统计方法分析、鉴别莎士比亚作品的研究[2]。随后,字符、句法、语义等特征均被用于作者识别研究中,并取得了一些进展。目前,研究内容从传统文学作品作者身份识别,拓展到恐怖分子身份识别[3]、遗书真伪验证[4],以及病毒源代码作者身份识别[5]等方面。
作者身份识别相关研究可以大致分为数字人文和计算语言学两种。在数字人文研究中,重点主要放在实际有争议的作者身份或文学风格分析的案例上;而在计算语言学研究中,研究者则更多地关注现有作者身份数据集的表现以及确定最可靠的技术[6]。在研究方法方面,除了基于统计的多元统计分析[7-8]、文本距离[9]以及压缩算法[10],机器学习算法如随机森林[11]、支持向量机[12]和朴素贝叶斯[13]等也已成功应用于作者身份识别任务。近年来,深度学习模型如 RNN[14]、CNN[15]胶囊网络[16]等也开始应用于短文本作者身份识别,并取得了较高的识别率。作者身份识别在多种语言中都得到了广泛的研究。然而,对中文而言,作者身份识别的研究仍处于起步阶段,大部分研究者还是关注于传统文学作品的作者身份识别[17],目前,还没有用于作者身份识别的公开的标准语料库,最受关注的问题仍是《红楼梦》的作者到底是谁[11]。
唐代是我国古典诗歌发展的全盛时期。唐诗不仅具有很高的文学和艺术价值,同时对中国乃至世界的文化和历史也有很深远的影响。作为一种特殊的文学体裁,大部分唐诗都非常短,即使是像《长恨歌》这种长篇叙事乐府诗,也只有840字,因此完全可以将唐诗作者身份识别任务归为短文本作者身份识别。同时由于受到格律和字数的限制,唐诗在保证音节和谐的基础上,既具有整体性,又具有跳跃性。唐诗的整体性体现为多个意象都为诗歌的同一个情感和主题服务,而唐诗的跳跃性则体现为文字的省略,这不仅导致了以字代词,一字多义的现象非常常见,而且还存在部分如‘鸡声茅店月,人迹板桥霜。’这种只使用意象即只有名词而缺乏动词的诗句,或如‘香稻啄馀鹦鹉粒,碧梧栖老凤凰枝。’这种为了押韵而造成的宾语前置,这些都导致了唐诗中存在一定数量的句法结构不完整或混乱。这也为我们的识别任务造成了一定的困难。由于现有的中文句法分析及分词软件都是针对现代汉语设计的,在唐诗文本上表现较差,因此,分类任务中常用的句法特征和词汇特征并不适用于唐诗语料。唐诗的另一个特点是题材丰富多样,并极具代表性。比如我们通常说王维和孟浩然是山水田园诗人,而岑参、高适则以边塞诗闻名。因此,对唐诗作者身份识别而言,题材特征将可能成为一个有效的特征。
针对上述归纳的唐诗作者身份识别存在的问题和特点,本文构建胶囊网络(Capsule)和Transformer的集成模型,用于分别提取唐诗的局部语义信息和全局语义信息。同时,由于没有已标注题材的唐诗语料库,我们使用文本主题模型(LDA)提取每首诗的主题作为唐诗的题材信息。本文的主要贡献总结如下:
(1) 建立了用于作者身份识别的全唐诗语料库——QuanTangShi,扩展了中文作者身份识别的应用范围。
(2) 针对唐诗整体性与跳跃性统一的特点,提出了胶囊网络和Transformer的集成模型 Cap-Transformer,更充分和全面地提升唐诗各个层面特征的捕获能力。
(3) 提取唐诗的题材特征用于作者身份识别中,实验表明该特征确实对提升作者身份识别准确率有一定作用。
(4) 对Cap-Transformer模型生成的错误输出进行原因分析,揭示了模型的局限性,并针对唐诗文本的特殊性,提出了唐诗作者身份识别任务未来的研究方向及挑战。
1 模型介绍
作为一种特殊的文学体裁,唐诗不仅具有跳跃性,而且还具有整体性。组成唐诗的各种文字符号本身及蕴含其中的不同要素共同营造了诗歌的意境。因此,不仅需要捕获唐诗的细节信息,也需要整体把握唐诗的全局信息。Capsule模型将网络层携带信息的最小单元由神经元变为胶囊,又使用动态路由机制代替池化,因此Capsule模型可以在提取特征的同时降低信息损失[18]。而Transformer[19]跟LSTM[20]一样,可以作为全局特征提取器。将Transformer与Capsule模型通过双通道的形式进行集成,可以兼顾两个单通道模型各自的优点,提升唐诗各个层面特征的捕获能力。下面将分节详细介绍本文所提出的作者身份识别模型及模型中的重要功能模块。
1.1 整体框架
为了使表述更加清晰,本文引入了一些符号来 描述作者身份识别任务。设所有可能的作者集合为A={a1,a2,…,an},对于每一位作者ai∈A有训练样本集Ti={Ti1,Ti2Tim},作者身份识别的任务是学习训练集建立作者风格特征,并根据此模型对匿名文本t指定一个最可能的作者ak,(ak∈A)。图1为本文提出的作者身份识别集成模型的整体框架,共有输入层、嵌入层、网络层、融合层和输出层五个部分组成。

图1 唐诗作者身份识别集成模型Cap-Transformer的基本框架
首先,对输入的唐诗文本分别使用Word2Vec和BERT获取输入文本的词向量特征矩阵Wnode和Bnode,同时使用LDA获取唐诗的题材特征,并使用独热向量表示。将词向量与题材向量拼接,分别输入胶囊网络和Transformer得到唐诗的文本特征表示。最后,将两种特征表示拼接起来,送入全连接层进行降维,并使用softmax函数进行归一化,得到最终的分类结果。
1.2 题材特征提取
题材是诗歌文本独有的特征。唐诗题材丰富,通常包括送别、边塞、咏史怀古、山水田园等。很多唐朝诗人都有自己擅长的诗歌题材。比如李商隐更擅长写无题的爱情诗,而王昌龄则以边塞诗闻名。因而题材特征是唐诗作者身份识别任务的重要特征之一。本文选择使用LDA提取诗歌主题特征代替诗歌的题材特征。
LDA作为一种无监督的聚类算法,首先需要解决的问题是确定唐诗题材的个数。但是,目前学界对于唐诗题材的总数没有明确的定义。因此,我们需要对生成的LDA模型进行评估。根据Blei[21]的观点,LDA模型最常用的评估方法是使用困惑度。然而,这里有一个有趣的现象:数学上严格的模型拟合计算如最大似然值和困惑度等,并不总是与人类对模型质量评估的看法一致[22]。因此,本文使用主题一致性指标(Coherence Score)来衡量主题词在语料库中出现的频率,进而反映主题中高分词之间的语义相似度。
具体的做法是,使用不同的主题数(K),建立不同的LDA模型,计算主题一致性,最后选择一致性得分最高的那个“K”作为唐诗的题材个数。选择一个主题一致性得分达到峰值或快速增长的“K”值,通常意味着有意义或可解释的主题。
因为中国古典诗歌没有合适的外部语料库来计算词义的概率,所以本文选择U-Mass[23]计算主题一致性。具体的计算如式(1)所示。
其中,vi,vj是一组主题词,ε是平滑因子,用以保证最终返回的score是一个实数。
其中,D(vi,vj)表示包含vi,vj的文档数,D(vi)表示包含vi的文档数。
1.3 Cap-Transformer模型
唐诗文本既具有跳跃性,又具有整体性,因此传统的针对浅层的单模型文本分类算法不能很好地提取到唐诗的深层语义特征。本文提出了一种Cap-Transformer 集成模型,分别利用胶囊网络(Capsule)和Transformer来提取文本的局部特征和全局语义特征,通过集成的形式更全面地得到唐诗的多层次特征表示。
Capsule模型:Capsule模型是对传统CNN模型中的最大池化操作做出的改进,最大池化操作只保留特征向量中的最大值,会造成特征损失。Capsule模型使用一组神经元构成的胶囊代替CNN中的神经元,改变了传统神经网络标量与标量相连的结构。在各个网络层中,每个胶囊携带的信息从1维增加到了多维,因此可以携带更多的具有跨越性的特征信息。相邻两个胶囊层之间通过动态路由算法(Dynamic Routing)将该层胶囊保存的计算结果传递给上层胶囊,从而实现在提取文本节点特征的同时降低底层特征的损失,也降低噪声对分类结果的干扰。动态路由算法描述如式(3)~式(5)所示。
其中,sj为上层胶囊的输入,u为下层胶囊的输出,W为相邻两层之间的权值矩阵,cij为耦合系数,表示下层胶囊i激活上层胶囊j的可能性,bij的初始值设置为0,通过动态路由更新cij,进而更新bij,挤压函数squash及更新bij的计算如式(6)~式(8)所示。
其中,vj为上层胶囊的输出,由于胶囊输出向量的模长代表类别的概率值,挤压函数将向量的模长限定在[0,1]区间,输出向量的模长越大,代表文本所属该类的概率越大。
如图1所示,胶囊网络首先对输入的字符向量矩阵做卷积运算,经过挤压函数后形成主胶囊层,经过一次基于注意力机制的路由协议后连接分类胶囊层,得到唐诗的局部特征。
Transformer模型:Capsule模型在本质上是对CNN池化操作的改进,在N-gram卷积层依旧使用了多个卷积核进行卷积操作,因此只能捕获文本序列的局部特征,提取不到全局语义信息。而Transformer则是对LSTM的改进,传统的LSTM由于在序列化处理时依赖于前一时刻的计算,所以它们并行效率低,模型运行速度慢。Transformer模型通过多头自注意力机制可以在并行计算的同时捕获长距离依赖关系,充分学习到唐诗的全局语义信息。计算如式(9)所示。
Transformer模型主要用Seq2Seq,采用编码器-解码器结构,本文用于文本分类任务,因此只用到了其中的编码器结构,通过增加单词位置编码、残差连接、层归一化处理、前向连接等操作,处理输入序列并将序列信息压缩成固定长度的语义向量。如图1所示,字符向量输入模型后先进行了位置编码来填补注意力机制本身不能获得单词顺序信息的缺陷。然后,模型依靠自注意力机制更有效地去捕获对唐诗语义有重要作用的词,并且消除干扰词的影响。而多头自注意力机制则可以学习不同子空间中的语义表示,最后将它们拼接到一起获取长距离的语义信息。
模型集成:胶囊网络在提取文本局部特征的同时减少了信息损失,Transformer则通过自注意力机制遍历整个文本序列,从而提取到全局语义特征。本文采用的集成模型可以结合胶囊网络和Transformer各自的优势,综合考虑文本的局部语义信息和全局语义信息,提高分类效果。由于分类标签数固定,胶囊网络和Transformer具有相同的输出维度,因此本文在模型集成阶段采用合并拼接的方式,即拼接两种网络生成的特征向量,再通过一个全连接层映射到最终的分类向量中。假设胶囊网络的输出向量为HC=(hC1,hC2,…,hCn),Transformer单元的输出向量为HT=(hT1,hT2,…,hTn),集成后的特征向量为H,计算如式(10)所示。
其中,Dense是一个映射到类别数上的全连接层。
最后,对集成后的特征向量H使用softmax分类器得到每个类别的概率值,选择其中数值最大的作者类别为预测的诗歌作者。
2 实验
在这一部分,我们首先介绍了用于作者身份识别的全唐诗语料库——QuanTangShi的建设,然后介绍了参与模型性能评估的全唐诗数据集以及常用的评价指标,包括准确率(Acc),精确率(P),召回率(R)和Macro-F1值(F1),并报告了模型在数据集上的性能评估结果,包括与现有基线的性能比较消融实验以及错误分析。
2.1 QuanTangShi 语料库
为了构建QuanTangShi语料库(1)语料库及相关代码:https://github.com/zhouai9070/QuanTangshi-AA-,我们从网上收集了全唐诗的电子文本。但是这些原始的数据存在诸如重复、错误、乱码,以及像《戏为六绝句》这种多首诗歌共用一个诗题而导致的多条数据被识别成为一条数据的现象。最重要的是,原始语料中存在905首无名氏或未标注作者的诗作,这些唐诗不适用于作者身份识别任务,所以将其删除。以王维的《相思》为例,经过预处理的数据形式如下:[‘王维’(作者) ‘相思’(诗题) ‘红豆生南国,春来发几枝。愿君多采撷,此物最相思。’]。
经过预处理之后的语料库共包括2 300个作者的44 734首唐诗。表1给出了该语料库的基本统计信息。可以看出,语料库的数据是极不平衡的,近半数的唐代诗人只创作了1~2首诗。只有不到20位诗人,一生创作了超过500首诗。归功于白居易对自己诗集的整理,全唐诗里共收录了他创作的2 844首诗,成为收录最多的诗人。
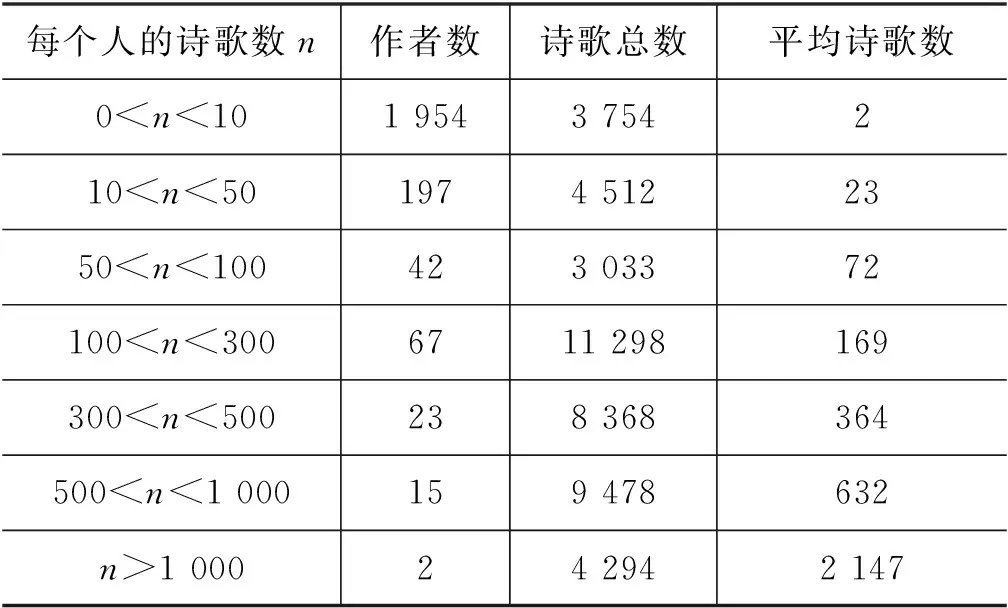
表1 全唐诗语料库数据统计
2.2 数据集
从表1可以看出,全唐诗语料是极其不平衡的,而作为一个分类任务,作者身份识别的准确率受到作者个数和作者样本数两个因素的影响,因此,本文根据作者样本数对作者排序,建立了“Top Num Group”数据集,并将其分成了5个小数据集 (TopNum2, TopNum5, TopNum10, TopNum20 and TopNum40) 对模型性能进行评估。这些数据集不论在作者个数还是作者样本数上都有差异(表2),能够在不同的场景中测试我们的模型。

表2 Top Num Group数据集数据统计
2.3 实验结果分析
本节主要介绍模型在Top Num Group数据集上的性能评估结果,包括涉及题材信息的LDA的参数选择、与现有模型的性能比较以及消融实验。
参数选择:由于现有的唐诗语料库没有题材信息的标注,本文选用LDA提取的文本主题信息代替唐诗的题材信息。但是,LDA是一个无监督的聚类模型,需要提前确定主题个数。目前学界对于唐诗题材的总数没有明确的定义,因此,我们使用不同的主题数(K),建立了不同的LDA模型,计算主题一致性,最后选择一致性得分最高的那个“K”作为唐诗的题材个数。选择一个主题一致性得分达到峰值或快速增长的“K”值,通常意味着有意义或可解释的主题。图2反映了主题一致性得分(C)随不同数据集上主题个数(K)的增加而变化的趋势。
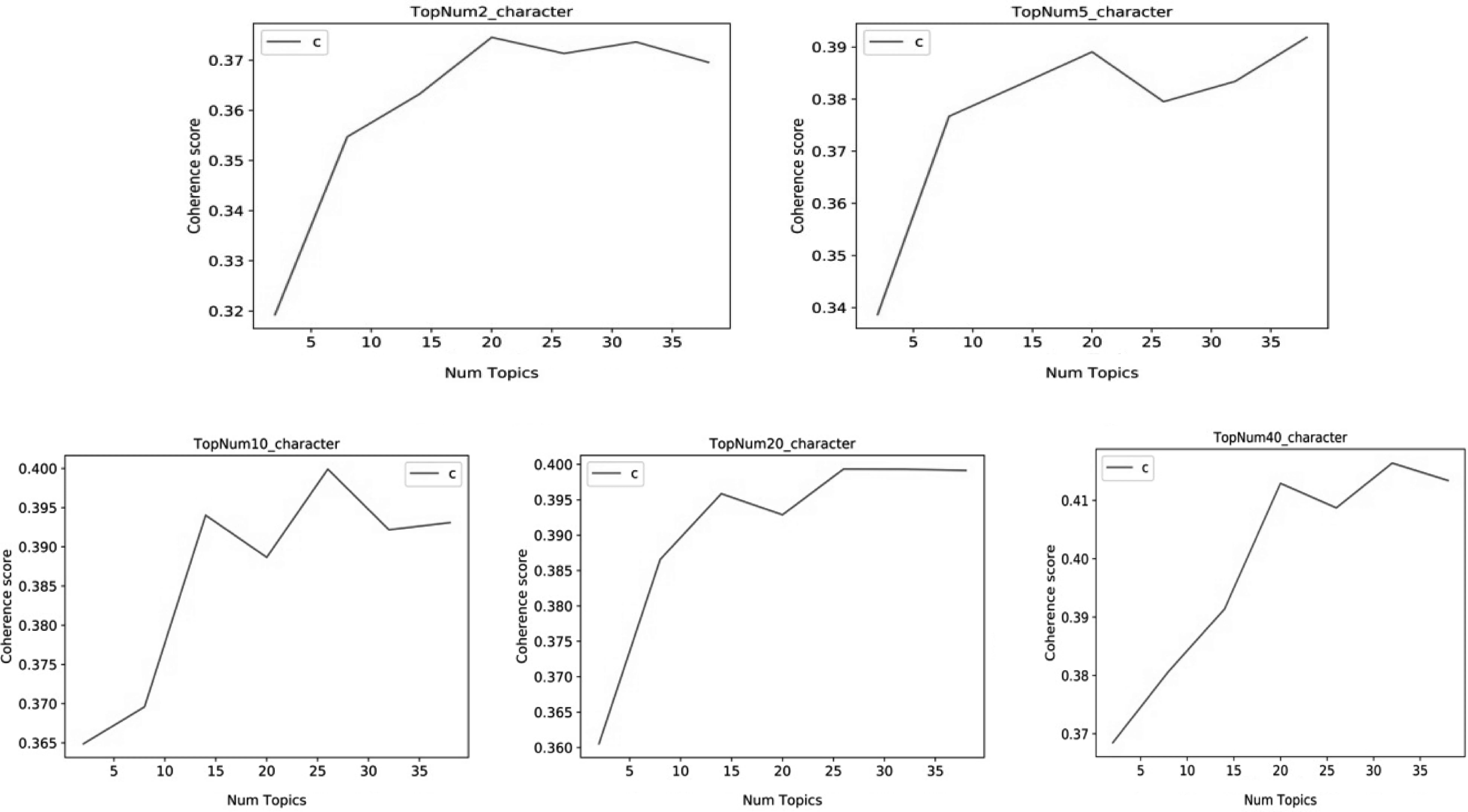
图2 Top Num Group数据集上的主题一致性得分
性能比较:为了验证本文所提方法的有效性,我们将本文模型和现有方法在Top Num Group数据集上进行了比较,实验结果如表3所示。本文所选取的当前先进的代表性研究包含了传统的机器学习方法和深度学习方法两个大类。2007年易勇等人[24]首次将朴素贝叶斯(NB)用于古典诗歌作者身份识别任务,并在区分李白和杜甫诗歌的二分类问题上取得了理想的结果。SVM则较广泛地应用于长文本,特别是文学作品作者身份识别任务[12]。但是,机器学习算法需要依赖人工参与和大量的特征工程,在模型预处理成本和工作效率方面均不及深度学习方法。随着网络短文本的出现,CNN[15]开始广泛应用于短文本作者身份识别领域并且与BiLSTM和RNN相比具有更好的鲁棒性。2017年Transformer[19]提出了一种新的模型架构, 不仅在机器翻译任务中效果良好,而且由于编码器端是并行计算的,训练时间大大缩短。BERT[25]使用预训练的语言模型,可以更准确地获取上下文信息,在2018年在11项NLP任务中取得了最好的结果。
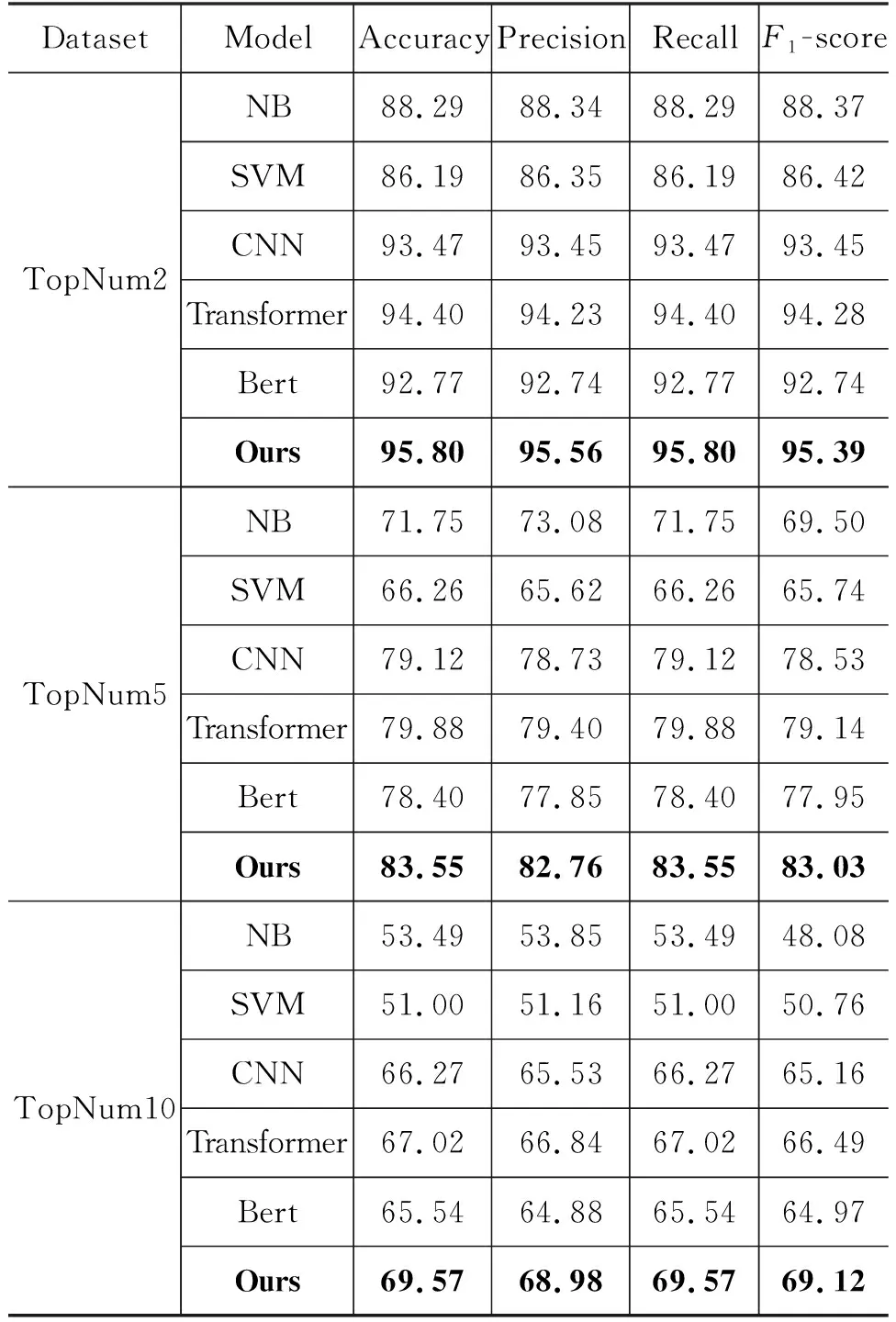
表3 本文模型与现有方法的性能对比 (单位: %)

续表
如表3所示,深度学习算法的效果要优于机器学习算法。NB在二分类问题中可以获 得较好的结果,然而随着作者人数的增加, 准确率下降较快, 相
比较而言,SVM的识别准确率更高也更稳定。之前BERT在11项NLP任务中都取得了理想的效果,可是本文的实验却得到了相反的结果。只有部分数据集的识别准确率可以与CNN的基本持平。大部分数据集的结果远不及CNN。主要原因是现有的BERT-Base Chinese预训练模型是基于现代汉语训练的,并不适用于像唐诗这样的古汉语数据集。在各个数据集上,Transformer的效果要优于CNN,这主要是因为Transformer能够更好地获取长距离的语义信息,这也体现了诗歌的整体性特点。与现有的模型相比,本文的模型不仅携带了更多的特征信息,还降低了噪声的干扰,又可以有效地捕获长距离信息,实现了更强的上下文提取能力,在整体性能上平均性能提升了1.1%。
消融实验:为了验证本文模型中各模块的有效性,对模型进行了消融实验。实验结果如表4所示,-No表示去掉当前模块后模型在Top Num Group数据集各类别中的性能表现。
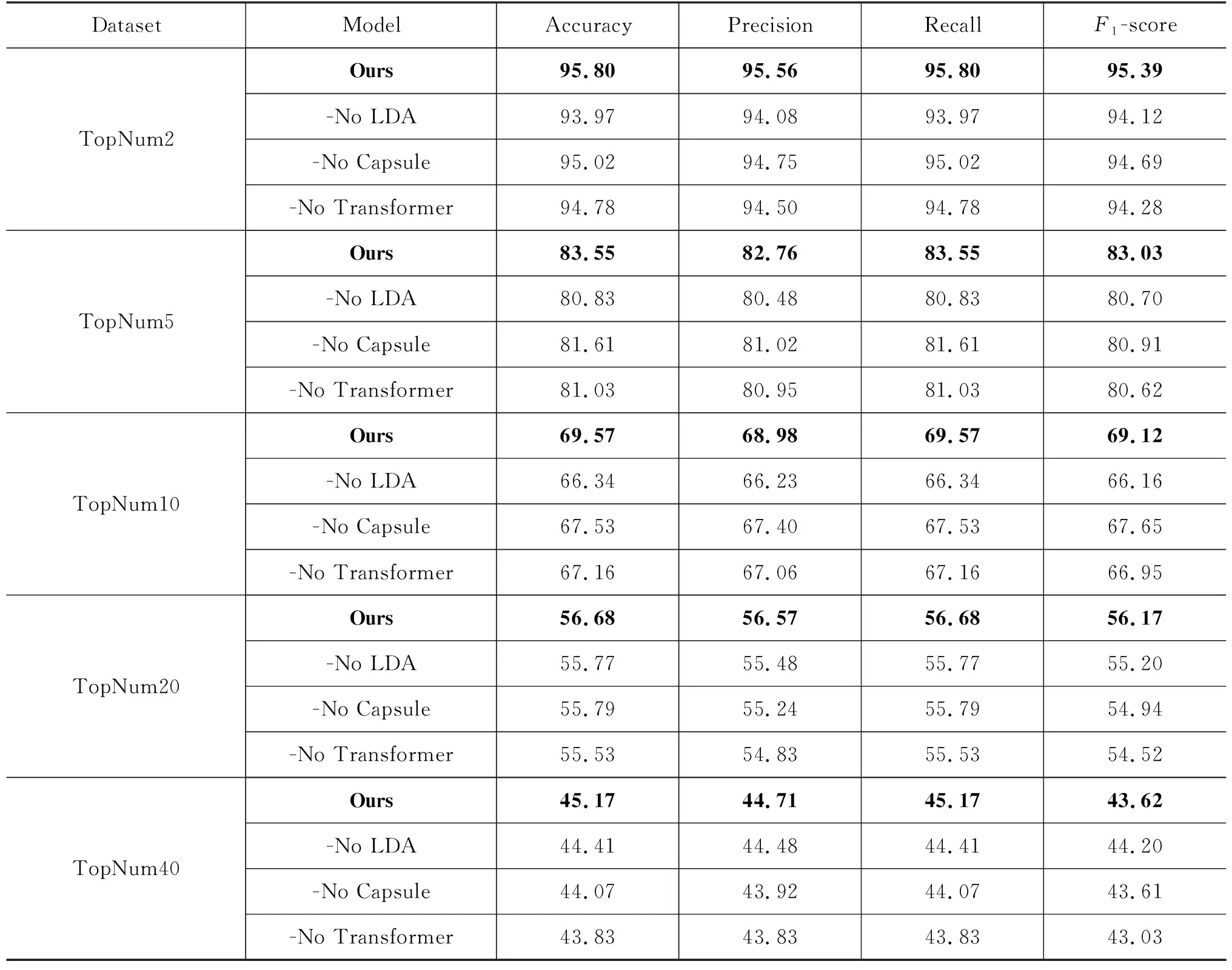
表4 模型各组件的消融实验结果对比 (单位: %)
由实验结果可知模型的三个组成部分均能使模型性能有不同程度的提升,其中LDA的效果最为明显,使模型的平均性能提升了0.97,但是随着作者人数的增加,LDA的作用逐渐下降,可能是随着作者人数的增加,题材特征的显著程度逐渐降低。对比表3的Transformer和表4的-No Capsule对应数据也可以看出题材信息对模型性能提升的作用。
Transformer的多头自注意力机制可以学习不同子空间中的语义表示,捕获长距离语义信息。实验表明,只使用Capsule模型并不能有效地获取诗歌的长距离上下文信息,而在整体上理解诗歌。Transformer的引入使得模型的性能有了明显的提升。
Capsule模型使用一组神经元构成的胶囊传递信息,相较CNN可以做到在提取特征的同时降低信息损失。表3的CNN和表4的-No Transformer对应数据的差异,除了显示LDA的作用外,也展示了和CNN相比,Capsule模型在特征提取上的优势。
2.4 错误分析
在前边各节中,我们展示了Cap-Transformer 模型是如何进行作者身份识别的。但是,在某些情况下,模型无法完成任务并生成错误的输出。分析错误原因可以揭示模型的局限性,并有助于确定下一步的研究方向。在本节中,我们对 TopNum10数据集进行错误分析,将其错误归为4类,每一类错误所占的比重如图3所示。需要说明的是,尽管本文进行的错误分析结果仅适用于 TopNum10 数据集,但类似的错误原因也是其他数据集的错误来源。
常识矛盾:诗歌内容或诗题中常常会出现一些常识性的外部知识,这些知识可以辅助作者身份识别,但是我们的模型忽略了对这些外部知识的表示,导致出现了一些简单的识别错误。例如,刘禹锡那首著名的《酬乐天初逢席上见赠》,首先我们知道乐天是白居易的字,根据常识,这首诗不可能是白居易写的。但是,模型却错误地把这首诗分给了白居易。再比如说温庭筠的《戏令狐相》,这里‘令狐相’指的是令狐绹,他在公元850年以后升任宰相,因此,这首诗不可能在850年以前创作,而模型则认为该诗的作者是杜甫(712—770)。
这种由于未能引用外部知识而造成的常识性矛盾是最常见的错误类别。如图3所示,将近60%的错误都属于这个类别,未来将尝试引入外部知识,解决这一类错误。
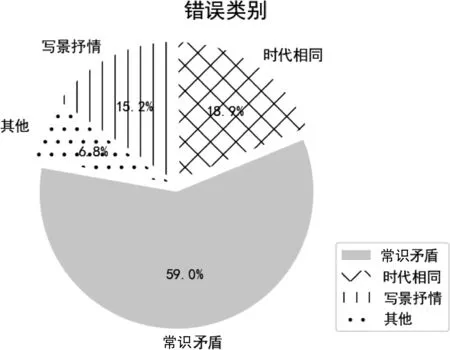
图3 错误类别分布
时代相同:唐诗属于古汉语范畴,语言演变较慢,生活在同一时期的诗人大多使用相同的常用字、常用句式,甚至是常用的韵脚。因此,即使使用拼音、韵脚、平仄等更多样的文本特征也很难区分。比如这类错误大部分都是白居易、元稹和刘禹锡三个人的诗互相识别错误。由于白居易和元稹共同倡导了新乐府运动,即使是专家也不能完全确定两者的诗歌区别,更不用说神经网络模型了。因此,这类错误虽然占比不大,但其将成为今后研究的难点。
写景抒情:这类错误主要针对写景抒情诗的识别。这类诗一般只写景,不叙事,题目和内容也是像王维的《山居秋暝》和杜甫的《绝句》这种完全没有任何外部知识的内容。对于这样的诗歌,即使我们引入外部知识也很难提升识别率。
其他: 还有一些不好归类的错误案例。这些案例导致错误的原因可能不止一个,比如像王维的《叹白发》这种冒名顶替的诗作,或由于年代久远在流传过程中导致的遗失、错漏的情况。这一类错误在图3中被标为其他。
3 结论
针对唐诗文本跳跃性与整体性统一的特点,本文提出了一种双通道的作者身份识别集成模型Cap-Transformer。首先,上通道Capsule可以在提取唐诗各个意象的局部语义特征的同时降低信息损失;下通道Transformer通过多头自注意力机制提取唐诗各个意象共同指示的深层全局语义特征,将两种特征融合,达到了唐诗的跳跃性和整体性的统一。此外,唐诗作为一种特殊的文学形式,题材特征确实提高了唐诗作者身份识别的准确率。在未来的工作中,我们计划为唐诗作者身份识别引入更多的外部知识,并对其进行更恰当的表示,以提升作者身份识别的准确率。
猜你喜欢
中华诗词(2020年5期)2020-12-14 07:44:50
文苑(2020年7期)2020-08-12 09:36:30
文苑(2020年5期)2020-06-16 03:18:32
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
养生保健指南(2017年9期)2017-12-07 01:03:00
时代英语·高二(2017年4期)2017-08-11 11:55:11
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
公民与法治(2016年22期)2016-05-17 04:20:31
语言与翻译(2015年4期)2015-07-18 11:07:45
小猕猴智力画刊(2015年4期)2015-04-28 08:29:07
