
基于词语聚类的汉语口语自动推送素材研究
2022-08-02 03:57:06杨冰冰赵慧周王治敏
中文信息学报 2022年6期
杨冰冰,赵慧周,王治敏
(1. 北京语言大学 汉语国际教育研究院,北京 100083;2. 北京语言大学 信息科学学院,北京 100083)
0 引言
新冠肺炎在全世界的蔓延使得在线学习成为一种趋势。在线学习资源如何满足学习者的学习需要,如何为学习者提供丰富的、可供选择的个性化学习素材,如何联通汉语学习者与教师这两部分群体,是目前特殊大环境下亟待解决的问题,也将是语言教育创新发展、适应互联网时代发展面临的问题。
本文面向在线学习中的汉语口语教材自动定制,对其所需要的学习素材进行研究。教材自动定制需要联通词汇、场景、话题等模块,构建相应的推理模式。关于词汇资源的研究,目前很多词汇知识库的研究主要分基于规则和基于统计两种,也有学者利用文本分类中特征提取的方法在大规模分类语料中自动获取领域词语[1]。基于词语聚类,一些学者对不同话题领域的词表进行了研究[2-4]。关于对外汉语教学中的话题分类,《国际汉语教学通用教程大纲》[5]列出了包括22个话题以及其下的小话题与常用表达,一些学者构建了汉语话题库[6]和汉语教学资源库[7-8],目前对汉语交际场景的研究有杨寄洲在《对外汉语教学初级阶段教学大纲》[9]中列举的36个交际场景,其后刘华等[10]根据影视片段,总结了63个交际场景。现有研究对该研究具有一定的参考作用,但是目前学界对生活类话题下的二级话题的研究还不够深入,且缺少对交际场景和话题关联的相关研究,对汉语口语的特点也缺少分析。
因此本文以适用于汉语教材自动推送的教材素材为研究对象,通过对口语词汇特点的分析以及词语聚类,总结口语话题及场景,构建话题-场景对应的口语素材库,为在线口语教材自动推送提供资源支持。
1 汉语口语词汇特点分析
本文以汉语生活类口语为切入点,收集了10 341句生活类语料。语料来源于《英语会话8000句》中生活类话题下的句子共4 152句以及真实场景的对话录音共6 189句。《英语会话8000句》作为英语口语的代表教材,经过长期的使用可以证明其话题覆盖面较宽,句子实用性较强,且与汉语口语教材有一定的差异,经过筛选与改写后可以作为汉语口语教材的原始语料。关于口语录音,本文对生活中常见话题、场景进行了真实场景的录音,通过机器转写与人工校对形成本文的另一部分基础语料。笔者所处语言环境为北京的高校,录音场所为北京内的交际场所。通过对全部语料进行机器分词和人工校对[11],去除数字、英文字母后共提取出词汇6 803个。
1.1 词类分布特点分析
在对全部词汇进行分词与词性标注的基础上,我们发现在口语会话中各类词汇分布如图1所示。
图1表示在所有口语语料中各词类丰富度情况,总体来看,在口语会话中名词种类最多,数量为3 279个,占全部词汇的49%。其次为动词,数量为1 741个,占比26%,再者为形容词,数量为496个,占比7%,副词数量为278个,占比4%。这四种词类包含的词语种类最多,共占全部词汇的85%,与汉语词类构成相符。时间词、量词、代词数量丰富,数量分别为139个、135个、115个,体现出口语对话中用词的特点。在口语对话中存在一部分固定短语,如“不好意思、没关系、可不”等,数量为78个。在口语语料中也有一部分成语,但是数量不多,为44个。另外助词、语气词、拟声词,其他词类,因词条种类数量较少在图中不予展示。从各词类丰富度来看,名词、动词、形容词依旧是口语学习的重点,语气词、助词等属于封闭类词类,数量不多,但是重点词语较多,如语气词中的“吧、呢”;助词中的“的、了”等。
词频反映一定范围内词语的常用度,下文将对口语对话中各词类的词频进行统计分析。
由图2可知,各词类词频与各词类词语数量不一致,在口语语料中,实词的出现频率高于虚词。在所有词类中,动词的词频最高,总词频为19 718次,因为口语小句较多,动词常用度高。其次为代词,代词虽数量不多,但是出现的频次很高,口语对话大多是两人之间的对话,因此进行自我阐述与询问对方时人称代词出现的频率很高。词频第三为名词,总频次为10 909次,名词数量为3 191个,这反映出大部分名词出现频次较低,常用度较高的名词不多。词频第四为语气词,频次为6 132次,语气词是虚词中频率最高的词类。语气词虽数量不多,但是出现频率很高,语气词的高频使用反映了汉语口语的特点。其次为助词,频次为4 598次,使用频率较高。另外在口语语料中,连词、固定短语、区别词、成语等词类的词频较低,在图2中没有展示。因口语对话中多为短小的句子,因此连词的使用较少,成语书面色彩较浓,在口语中不经常使用。
1.2 高频词词汇特点分析
口语中的高频词可以体现口语词汇特点,在口语中词频最高的词为: “我、的、你、了、是、好、吗、不、吧、您”等。在口语中代词“我”的频次最高,这与《中国语言生活状况报告》[12]中“的”词频第一不一致,在口语对话中多为表达自己观点的句子,因此代词“我”的词频比书面语等语体中高。另外,其他人称代词“你”“您”“我们”的词频也很高。
从音节数量来看,在词频为前50的词中,大多为单音节词,数量为41个,双音节词数量较少,仅为9个。单音节词的数量远多于双音节词及多音节词,且最高频的词均为单音节词。从难易程度上看,高频口语词汇中大部分属于汉语低水平词汇,通俗性较强。
为了对高频词的词类分布进行下一步的研究,我们对词频前50各词类数量进行了统计,如图3所示。
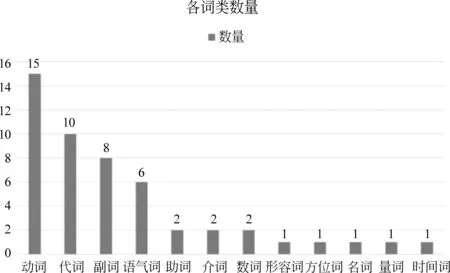
图3 频率前50词类统计图
由图3可知,在高频词中动词数量最多,共15个,其次为代词,数量为10个,副词和语气词的数量也较多。助词、介词、数词中各有两个高频词,形容词、方位词、名词、量词、时间词中各有一个高频词,高频词数量较少。其他没有列出的词类表示频次前50的高频词中不包括这些词类。
2 基于词向量的词语聚类
词语聚类可以把语义特征相似的词语聚在一起,自动推送的汉语教材需要提供各话题、场景的常用词及常用句,词语聚类结果可为话题和场景下常用词的汇总提供参考。本文对全部10 341条语料进行话题的场景的标注,在词语聚类和标注的基础上归纳生活类话题和场景。
2.1 词向量模型
文本的向量化即把文本转化为N维的向量。本研究使用腾讯AL LAB 公开的中文词向量数据[13],包含800万词汇,每个词对应一个200维的词向量,该词向量数据包含很多现有公开的词向量数据所欠缺的短语,所计算的语义相似度较高,且采用了Directional Skip-Gram(DSG)算法作为词向量的训练算法,DSG算法基于广泛采用的词向量训练算法Skip-Gram(SG),在文本窗口中词对共现关系的基础上,额外考虑了词对的相对位置,所生成的词向量能够更好地表达词之间的语义关系。
2.2 K-means聚类算法
K-means算法是最经典的基于划分的聚类方法,首先确定经过聚类得到若干集合的K值,我们将K值设置为500、800和1 000。从全部的词汇向量中随机选择K个数据点作为质心。计算所有向量数据与聚类中心的相似度,离质心越近,相似度越高,计算如式(1)所示。
(1)
计算完成后将数据分配给与其最相似的聚类中心代表的类,并计算下一轮聚类的中心。如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值,我们可以认为聚类已达到期望的效果,算法终止。如果新质心和原质心距离变化很大,需要继续迭代。本文实验将各话题词汇聚类为500类、800类及1 000类,以生病就医类词语为例,该话题下词语分别聚类为10组、15组和21组,实验结果如下:
由表1可知,聚类数为500、800、1 000的每类平均词语数量分别为: 10.08个、7.87个、5.62个,聚类总数越多,同一话题内词汇的聚类数也越多,分类越细致,每类之间的区分度越弱。在聚类数为500的词语聚类中,对药物名称、药物效果及大夫等的划分包含在了一个类里,而在聚类数为800的聚类中,药物名称单独为一类,在聚类数为1 000的聚类中,药物名称根据种类又分为了两个类。因此对于口语话题来说,对于大话题的划分,参考聚类数为500的词语聚类,对于下级话题和场景的划分参考聚类数为1 000和800的词语聚类结果。
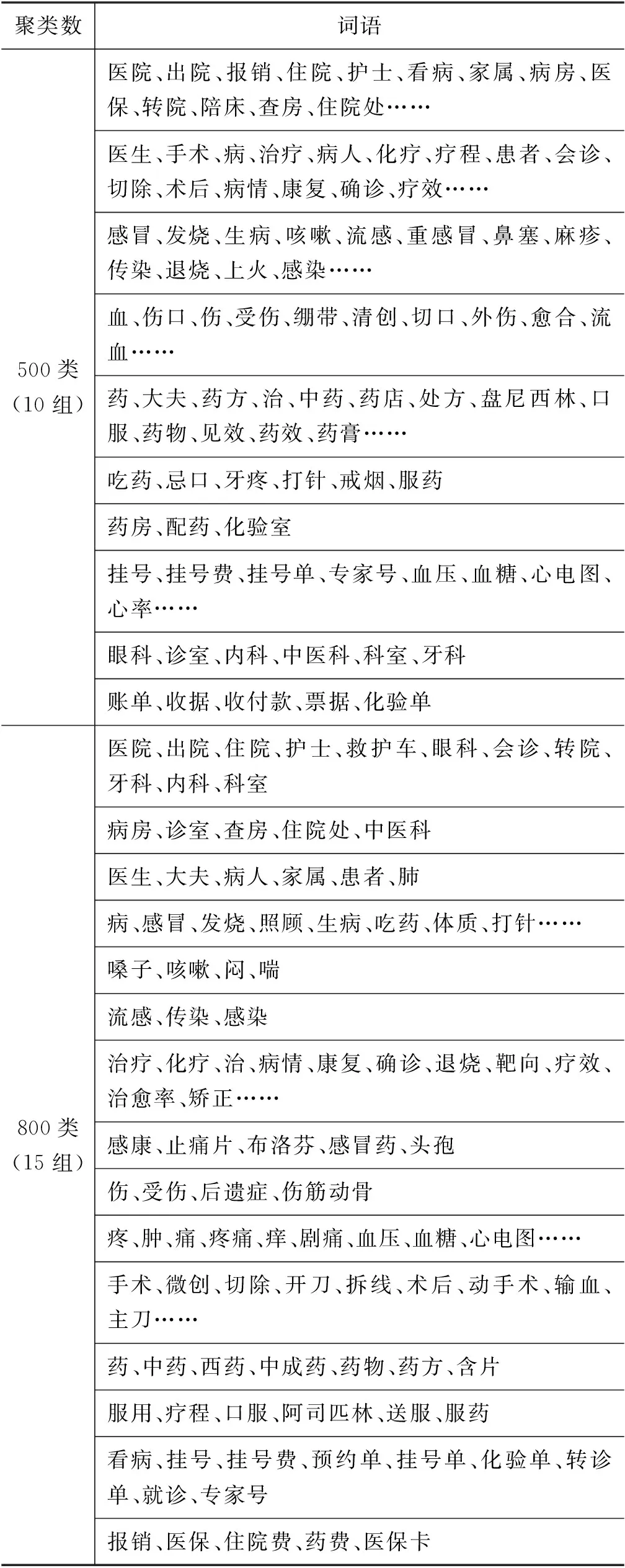
表1 500类、800类、1 000类词语聚类情况

续表
3 话题-场景库的构建
3.1 话题的确定
基于词语聚类结果,在对12本常用口语教材、《国际汉语教学通用教程大纲》[5]、吕荣兰[2]、刘华[10]等话题库以及英语教材的话题进行总结的基础上,本文总结出生活类一级话题15个,分别为个人信息、日常交际、居家生活、运动健身、生病就医、交通出行、购物、饮食就餐、天气、日期时间、资金管理、生活服务、休闲娱乐、意外与事故和住宿。每个一级话题下又有若干个二级话题,根据语料的场景标注,每个二级话题都有其对应的场景。以“生病就医”话题为例,其二级话题、场景如表2所示。
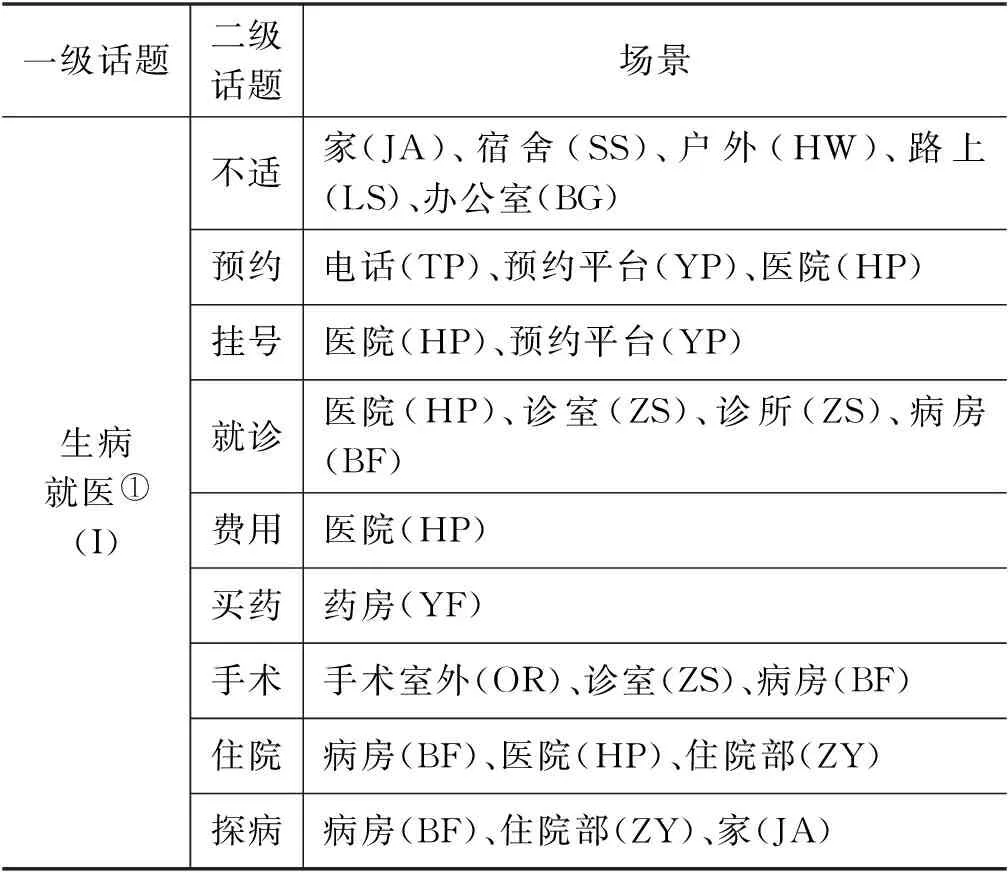
表2 “生病就医”二级话题、场景
参考词语聚类结果,我们总结出上表在一级话题“生病”中有二级话题9个,二级话题排列顺序基本遵循去医院看病流程。总体来看,关于“生病就医”话题的对话场景较为固定,几乎所有的二级话题中涉及到的场景都有“医院”。
通过对全部一级话题对话及词语聚类的考察,本文总结出15个一级话题下共102个二级话题,每个话题下有其对应的交际场景;根据对话内容,总结出每个话题和场景下的口语常用句。
3.2 各级话题的词汇特点及常用词分析
不同话题下词汇具有不同的特点,教材自动推送资源需要提供各个话题、场景下常用度高、代表性强的词汇。为提高话题词汇相关性,突出各话题词汇特点,本文对各级话题词汇特点及常用词的研究去除总词频中频次最高的前15个词,分别是“我、的、你、了(语气词)、是、好、吗、不、吧、您、这、有、就、我们、在”,且去除一些无意义的虚词,分别是助词、介词、连词和语气词。我们对每个一级话题下的词汇特点进行了分析(以“生病就医”为例),如表3所示。
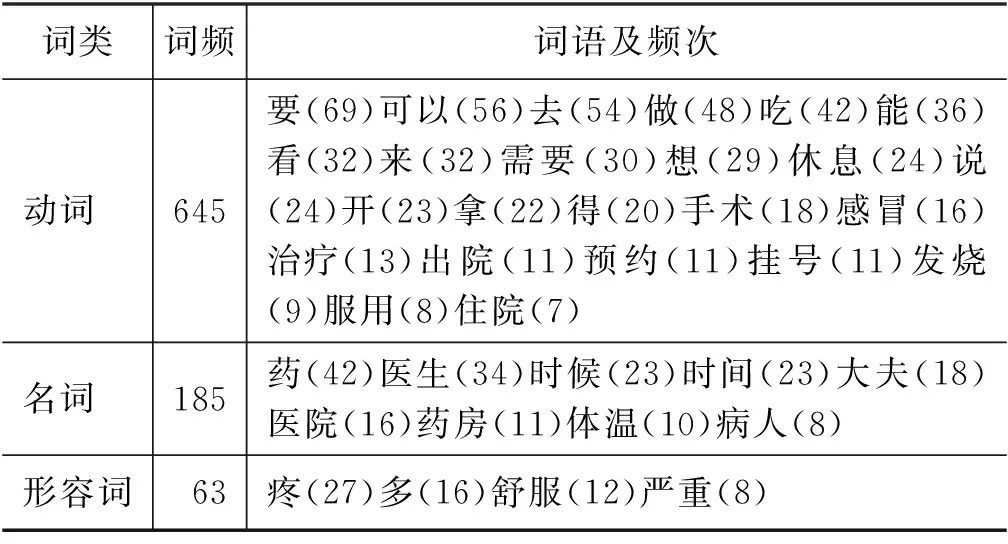
表3 “生病就医”话题高频词统计
通过统计发现在“生病就医”话题中高频动词数量很多,其中“休息、开、手术、感冒”等话题相关性较强,名词中“药、医生、大夫”话题相关性较强,形容词中“疼、舒服、严重”具有话题代表性,可作为“生病就医”一级话题下的常用词参考。
在对每个一级话题进行词频统计的基础上,我们提取出二级话题中的话题高频词,并参考高频词的词语聚类结果,总结各二级话题下的常用词,如表4所示。
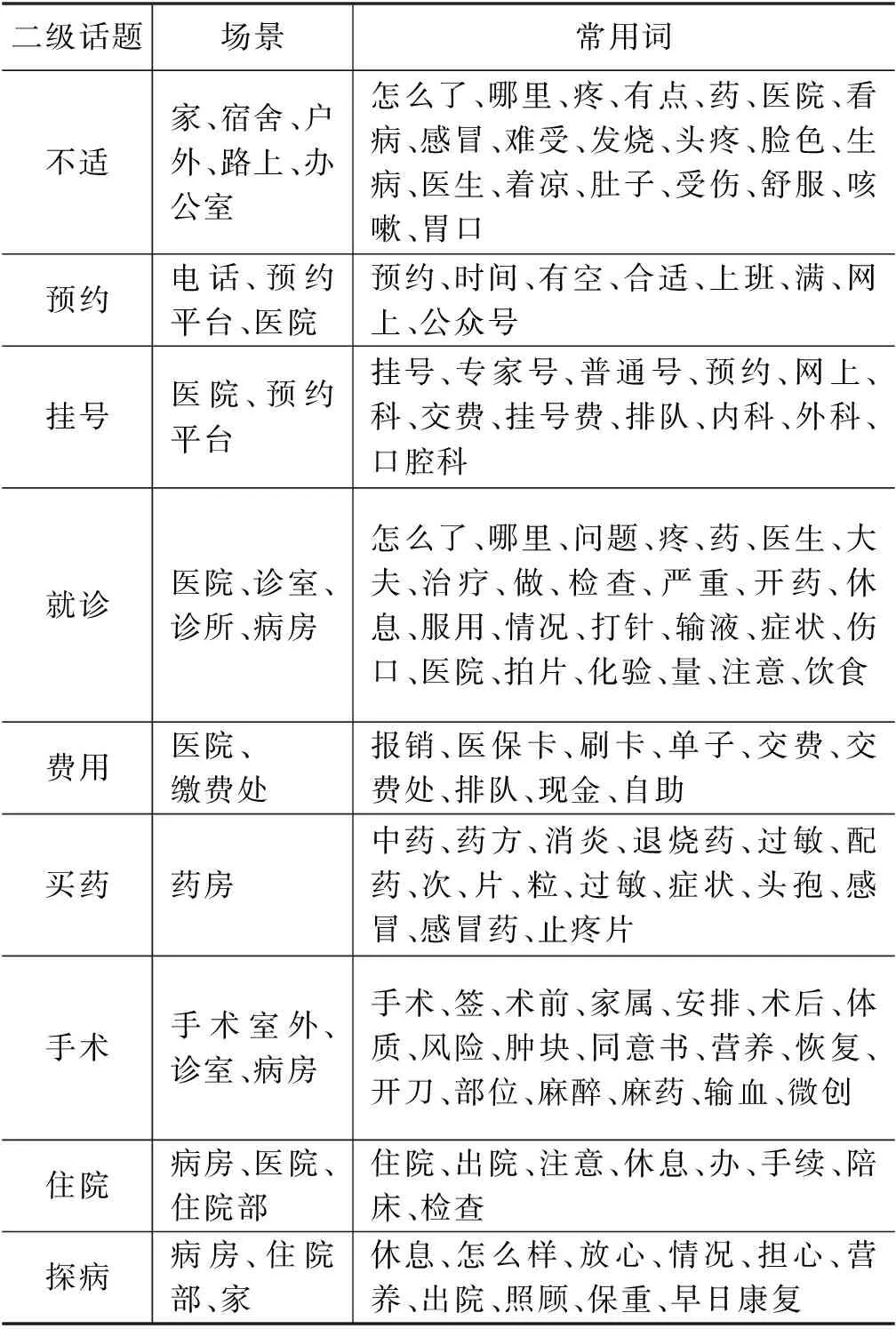
表4 “生病就医”二级话题常用词
3.3 生活类场景统计分析
通过对语料场景的标注以及对话题的考察,我们统计出81个生活类场景,相比较《对外汉语教学初级阶段情景大纲》,涵盖的生活范围进一步增加,场景是口语交际发生的场所,培养学习者根据场景进行交际是培养口语交际能力的关键。口语素材库需要尽可能多的交际场景来满足学习者的交际需求。具体生活类场景如表5所示。
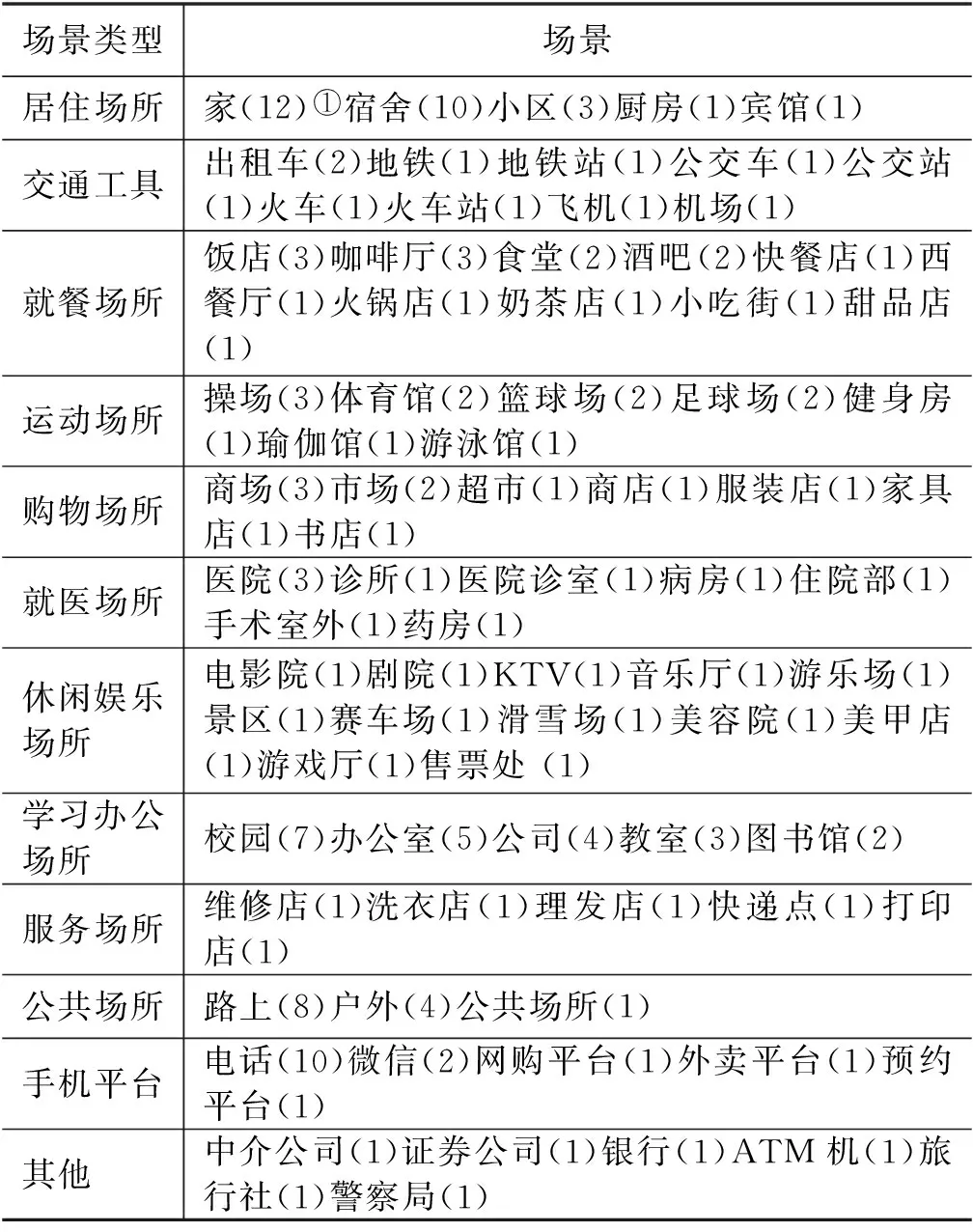
表5 生活类场景表
以上是根据话题所总结出的场景,共81个生活类场景。对于一些常见场景,我们进行了更深一层的细分,如“医院”是一个大的场景,主要是“生病就医”一级话题的交际场景,“生病就医”一级话题下又有多个二级话题,那么本文在“医院”这一大场景下又细分了“诊室、病房”这些常见的小场景。另外,本文增加了手机平台场景,如“购物”话题中的网店,“外卖”话题中涉及到的外卖平台。目前网络平台在我们日常生活中占据了很重要的位置,这些平台上的对话虽不是常规的口语,但是具备口语色彩。对留学生来说,有必要学习常用的网络平台的交际用语。
通过对话题下场景的分析,我们发现一些场景几乎包含了所有话题,如“家、宿舍”这些固定生活场所,而大部分场景下话题受限制较大,在我们收集到的语料中一般只包含一个话题,如“医院诊室、病房、手术室外”场景一般只涉及“生病就医”话题、“音乐厅、游乐场”等场景一般只涉及“休闲娱乐”话题。这些场景内人们的对话通常是针对某一话题展开,话题延展性不强。由此可知大多话题和场景的关联性较强。
4 口语素材库在教材自动定制中的应用分析
基于上文口语话题-场景素材库的研究,本文对素材库的实现进行了前期的测试,可根据场景类型进行场景的选择,如图4所示。
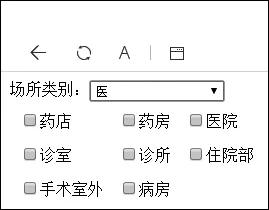
图4 场景选择模式测试
在场景选择模式中,用户可根据场景关键词进行学习场景的选择,图4为场所类别选择为“医”,场景,即为“生病就医”相关场景,为“药店、医院”等。当用户选择场景为“医院”时,学习内容推送如图5所示。
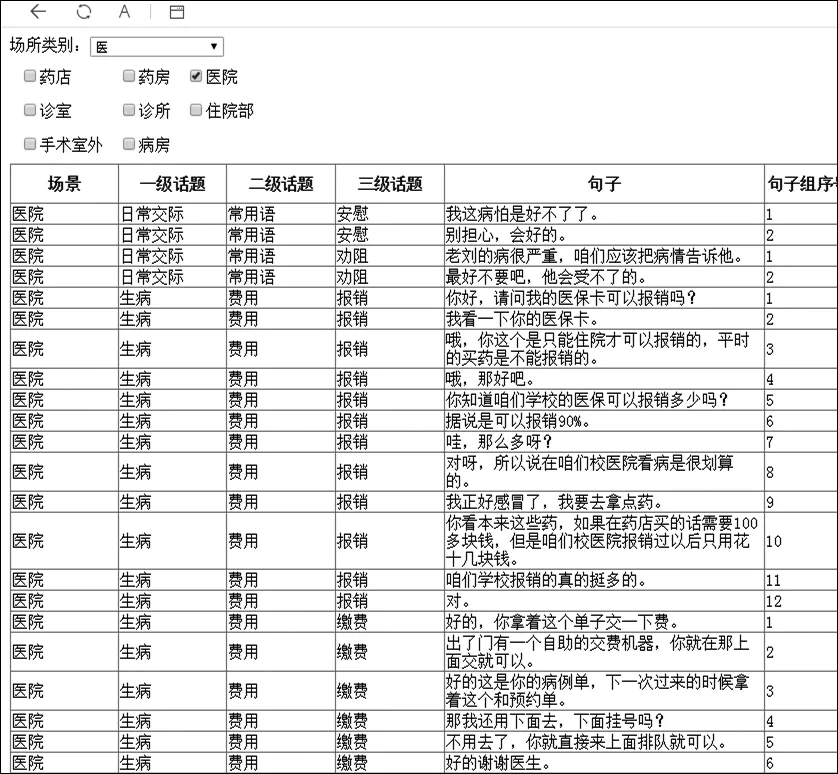
图5 场景为“医院”的学习内容推送
在场景“医院”下,涉及到一级话题“日常交际”“生病就医”及其下的二级、三级话题,图5中“句子组序”号表示该句为所在话轮的第几句。此测试可以根据学习者的场景特定需求为其推送学习素材。
另外我们对用户的学习界面进行了设计,以学习者的就医需求为例进行口语素材推送分析,学习内容包括话题常用词、会话及常用句(图6)。
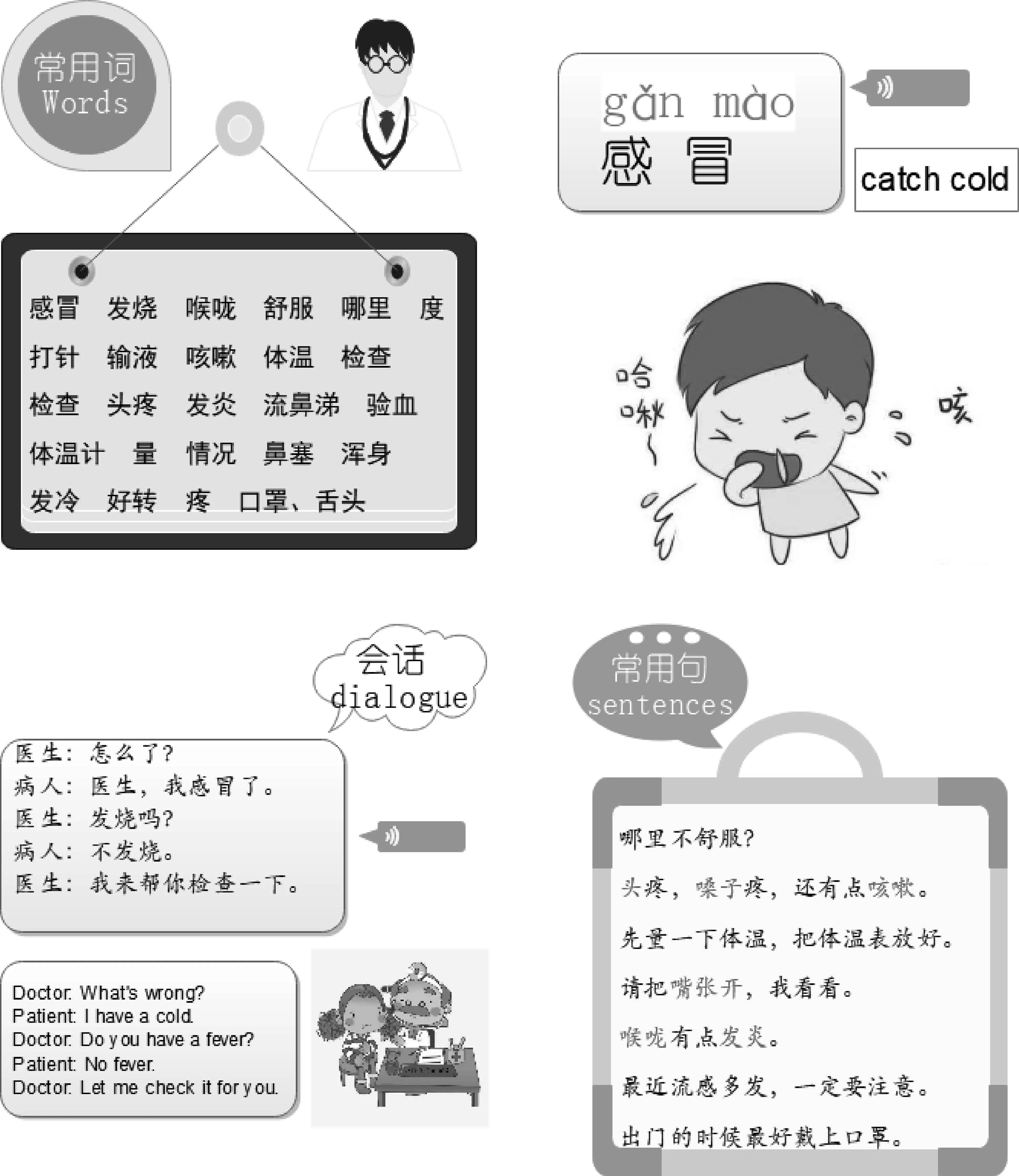
图6 学习模块页面设计
在学习内容界面,常用词是口语素材库中归纳出的各低级话题的常用词,对常用词的学习配备相应的拼音、词语发音、词语朗读纠音以及图片展示。口语会话学习内容也保留了口语会话的特点,在会话范读中保留口语的语音语调,但语速不宜过快。最后,在常用句的学习中,浅色词语是可以被替换的内容,如第二句中,“头疼、嗓子疼”中的“头、嗓子”可以替换为“牙、肚子”等身体部位。常用句是对口语会话的总结,来源于上文口语素材研究中的资源。
5 结语
本文基于10 341条口语语料,对适合在线教材自动推送的汉语口语素材进行了分析。本文在分词与词频统计的基础上对汉语口语词汇特征进行了深入描写,总结各词类分布特点,同时根据腾讯AL LAB 公开的中文词向量数据,使用K-means算法对口语词汇进行词语聚类,将全部词语分别聚类为500类、800类和1 000类,通过对聚类结果的分析,发现聚类总数越多,同一话题内词汇的聚类数也越多,分类越细致,每类之间的区分度越弱,因此本文参考500类的分类结果对大话题进行划分,参考800类和1 000类的结果对下级话题和场景进行归纳。其次,基于词语聚类,在对语料场景话题及现有话题库的考察下,本文构建了一个包含15个一级话题、102个二级话题以及81个交际场景的话题-场景框架体系,并对各级 话 题下的常用词及常 用 句进行了总结。本文最后对口语素材库在教材自动推送中的实现进行了前期测试,并且对用户的学习界面进行了设计,口语素材库可以实现根据学习者所处的场景为其推送学习素材。下一阶段的研究将针对素材库的推送进行更深层次的分析,制作具有实用价值的汉语教材自动推送产品,服务于汉语学习者与汉语教师。
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
新世纪智能(英语备考)(2019年10期)2019-12-16 09:07:54
广东蚕业(2019年3期)2019-05-14 05:37:40
新世纪智能(语文备考)(2019年3期)2019-01-12 09:08:10
海外华文教育(2016年1期)2017-01-20 08:21:58
现代语文(2016年21期)2016-05-25 13:13:29
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
