
多模块联合的阅读理解候选句抽取
2022-08-02 03:56王笑月郭少茹
中文信息学报 2022年6期
吉 宇,王笑月,李 茹,2,郭少茹,关 勇
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
随着自然语言处理技术的发展,国内外对于机器阅读理解的研究不断深入。本文重点关注机器阅读理解中的多项选择题任务[1-2],即: 给定文章、问题和选项,要求根据文章回答问题,从多个选项中选择最佳选项。对于该任务,研究者通常将整篇文章、问题及选项作为输入[3-4]并在三者之间两两交互,进行信息整合继而选出最佳选项。与片段抽取式阅读理解不同,多项选择的答案难以直接从给定的文章中提取[3](如在RACE[2]中87%的问题不能直接从文章中找到答案),且并非全文都与当前选项有关。若将全文信息编码将引入噪声从而影响模型预测。特别对于文章较长的数据集(如高考语文阅读理解多项选择题,其平均长度为1 134.15字/篇),输入全文将导致模型很难提取出与问题及选项相关的“重要信息”,且答题缺乏可解释性。因此,为提取问题所需的“重要信息”并提升模型性能,本文针对多项选择阅读理解任务中的候选句抽取问题进行研究。针对以上问题,Zhang等提出DCMN+[5],在对文章编码前加入候选句筛选工作,利用余弦相似度评估文章与选项间的关联程度,以此缩小文章范围。但多项选择题的候选句通常为多句[3],存在某些候选句与选项之间重叠度较低的情况,如图1所示,结合问题可得出S24包含判断选项A正误的关键信息,但从表面看S24与选项A关联度较低。若通过余弦相似度、模式匹配的方式查找,该类候选句很难被抽出且会对后续答题造成影响。鉴于此,Trivedi等[6]将候选句判断视为文本蕴含任务[7], 文章中句子视为前提、选项视为假设,判断两者之间是否存在蕴含关系。
由于缺少标注数据,采用SNLI[8]对模型进行微调之后进行预测。但该方法未考虑候选句之间信息冗余的情况,如图1所示,通过语义相似度计算,可在文中抽取出与选项A的关联句S1与S15,但这两句所含的信息相同,对答案预测并无提升作用且增加了计算量。对此,Yadav等提出ROCC[9],从候选句集对选项及问题的信息覆盖度、候选句与选项及问题之间的语义相关性以及候选句之间冗余性三方面计算ROCC得分,进一步筛选抽取结果。 在一定程度上缓解冗余现象,有效提高了候选句抽取的精确性。
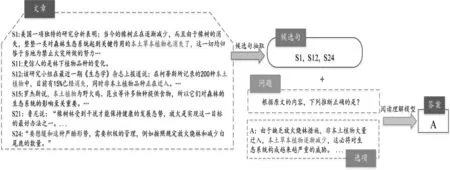
图1 候选句抽取示例
上述方法的提出虽使模型性能获得巨大提升,但仍存在以下挑战: ①直接将选项与问题拼接,忽视其拼接结果是否为一个完整的陈述句或存在语法错误,会对模型句意理解造成影响(图1);②通常数据集中候选句在全文所占比例较小,而无关信息占比较大,存在正负样本不均衡的情况;③对于需要多步推理的问题(即A推B、B推C),判断选项正误与否的候选句与选项之间并不存在直接关联,需寻找选项候选句的候选句。
面对上述挑战,本文在RACE和高考语文数据集(见5.2节)上进行实验。通过对数据集研究发现,文章候选句与选项之间的关联度较低。若仅用句对间关联较为明显的SNLI等数据集训练或采用无监督方式,都无法较准确、完整地将候选句抽出。故本文人工标注部分候选句对。考虑到选项信息不完整对候选句抽取的影响,本文将所有问题与选项拼接后改写,确保其不含语法错误; 之后,使用构造的数据集对BERT[10]进行微调;针对正负样本不均衡现象,采用FocalLoss[11]作为损失函数,在训练时推动模型更加关注于困难样本,降低简单负例的学习度,从而在整体上提高候选句抽取的F1值,基于此得到初步候选句集;对于多步推理问题导致候选句难以直接抽取的现象,本文提出基于TF-IDF的递归式抽取方法,进一步提升模型召回率;为保证候选句抽取结果的准确性,减少候选句之间的冗余,采用ROCC[9]过滤重复信息,提升准确率。
为进一步评估候选句抽取质量及所提方法对后续答题的帮助,本文将抽取出的候选句集拼接,采用BERT与Co-matching模型分别在RACE、高考语文阅读理解选择题数据集上进行实验,实验结果表明,采用候选句集作为输入相比全文在高考及RACE数据集上F1值分别提升了3.68%及3.6%。在候选句抽取上,本文所提方案相比于基线F1值进一步提升了3.44%及3.95%。
1 相关工作
候选句抽取工作,依据训练方式可划分为四种类型:①使用无监督方法为候选句抽取提供指导,同时减少人工标注的消耗[12]。②有监督方法通过标注数据训练模型,从而实现下游任务中自动抽取候选句的目的。Trived等[6]使用文本蕴含语料[8,13]为训练候选句抽取模型。对于不提供候选句标注的数据集,研究者从结构化知识库[14]中选取相关线索知识,训练模型[15-16]。③使用信息检索进行候选句抽取工作,通过强化学习[17]或pagerank[18]学习如何在缺少明确训练数据的前提下进行候选句抽取;或是使用注意力机制在文本与选项及问题之间交互,使文章中与选项和问题相关部分的注意力权重更大[4,19]。④通过人工定义规则,抽取出含有噪声信息的候选句,使用弱监督方式训练模型[20]。上述工作, 各有其贡献之处与意义,推动了模型在相应下游任务上的性能表现。本文所提工作着重在对上述工作疏漏之处进行强化,综合使用有监督与无监督方式,使抽取结果可评价并且提高抽取结果的准确性,也减少了数据标注工作量。同时,对上述模型中未能考虑到的选项信息缺失问题以及正负样本不均衡问题也进行了相应处理。此外,本文针对多步推理问题提出了一种多步信息抽取方式,进一步提升了模型抽取效果,并在下游任务中验证了模型的有效性。
2 候选句抽取模型
本文提出一种新的候选句抽取模型,模型整体架构如图2所示。其主要包含四部分: ①选项改写模块: 融合选项与问题所涵盖的信息,确保其结果无语法错误;②候选句抽取模块: 从文章中初步筛选出与判断选项正误有关的句子集合;③TF-IDF递归抽取模块: 在前一步的基础上,使用TF-IDF作为引导,抽取多步推理问题候选句,避免关键信息遗漏;④筛选模块: 在所得句子集合上进一步筛选,提高候选句抽取精确率,降低信息冗余。
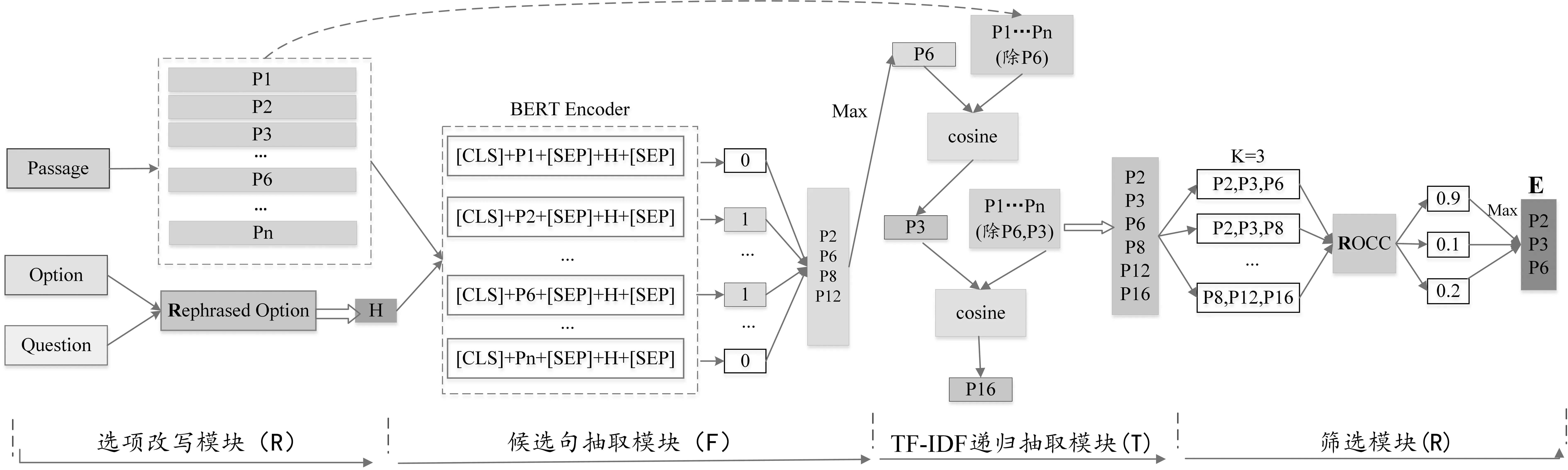
图2 候选句抽取模型整体架构
2.1 选项改写模块
通过对高考阅读理解及RACE数据集分析后发现,如图3所示,当问题为“下列说法符合 (不符合)文意的一项是?(或其同义表述),该类问题所蕴含的信息量较少,选项信息完整,无须对选项改写;而当问题为“下列对‘国外媒体关注点’的理解,不正确(正确)的一项是?”,选项内容为“科技竞争力”,若仅使用选项内容,其涵盖信息量过少,抽取对应候选句会较为困难;而若将问题与选项直接拼接,所得结果不符合语法规则。故提取问题的关键信息,并将其与选项信息融合,形成一条完整的句子。
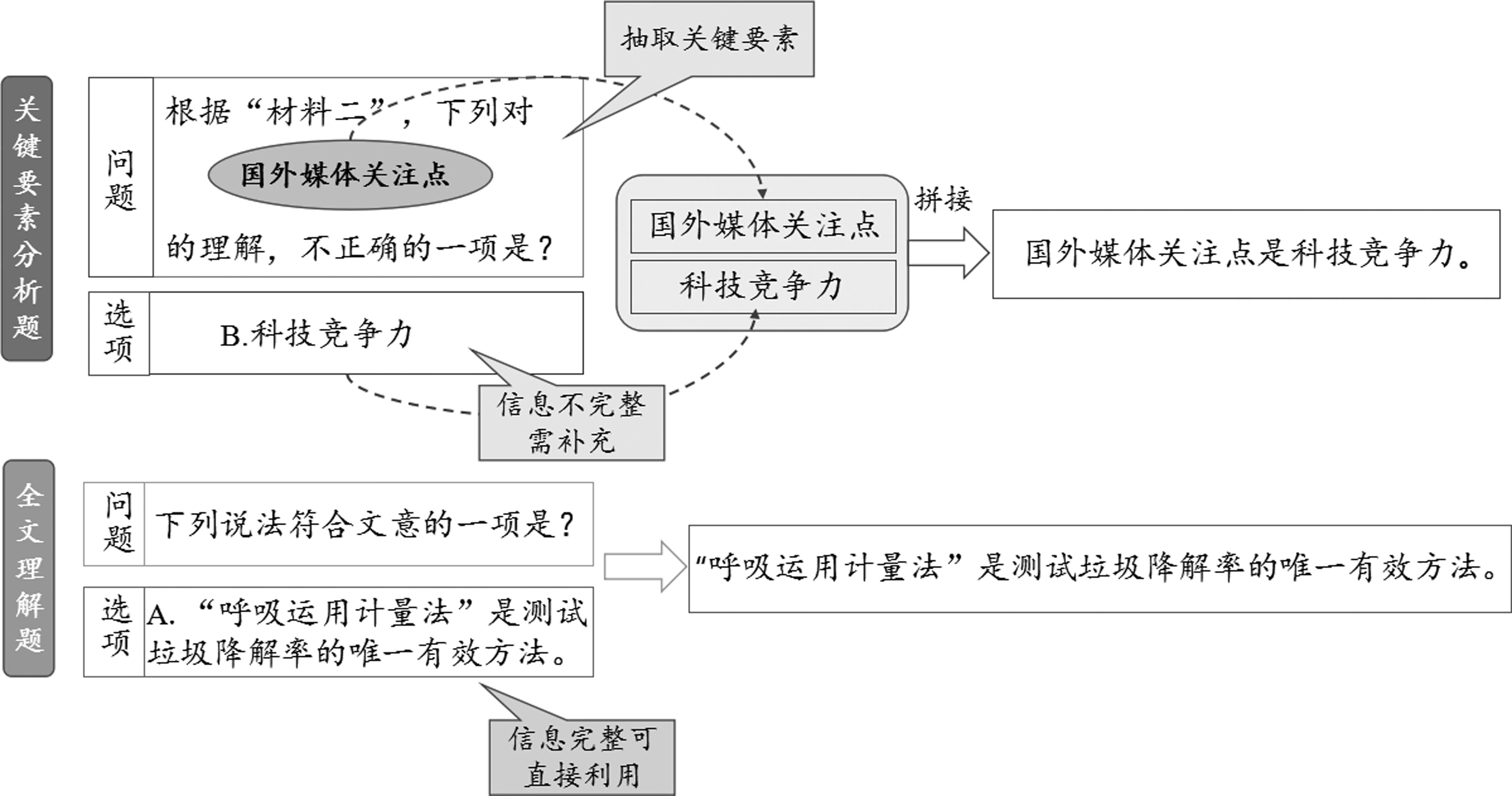
图3 选项改写示例
针对上述两种情况,首先采用正则表达式进行选项内容改写,使其形成完整陈述句H= {H1,H2,…,Hm},其中,m为选项改写句的长度;之后将文章切分为句子P= {P1,P2,…,Pn}其中,P为文章,n为文章中句子数量。
2.2 候选句抽取模块
该模块通过计算Pi与选项改写句H的关联度,初步抽取出候选句。本文在BERT基础上进行实验,首先将[CLS], 句子Pi、[SEP], 选项改写H、及[SEP]拼接后输入模型中,其中[SEP]为BERT中的片段分隔符,[CLS]为特殊字符(输入整体表示)。编码后,取[CLS]的编码结果Oi∈Rd进行分类,d为BERT隐藏层维度。
由于候选句数据集中存在正负样本不均衡现象(RACE候选句数据集中,正负样本比为1: 10)。本文采用FocalLoss作为损失函数,使模型聚焦于正样本的学习,缓解样本类别不均衡带来的风险。 输入的候选句对为(Pi,H),模型预测结果为P=[p0,p1],真值为Y=[y0,y1]。对于传统的交叉熵损失而言,其表示为:CE=-(y0log(p0)+y1log(p1)),显然,当负样本占比较大时,模型的训练会被负样本占据,使得模型难以从正样本中学习。
FocalLoss在原有的基础上加入权重系数γ及α,γ减少易分类样本的损失,使模型更关注于困难的、错分的样本;α用于平衡正负样本本身数量比例不均问题,由此缓解了正负样本不均衡的现象,如式(1)所示。
2.3 TF-IDF递归抽取模块
由于阅读理解多项选择题中存在多步推理问题,如图1所示,该情况难以直接使用文本蕴含的方式将选项对应候选句全部抽出。考虑到多步推理问题中存在链式关系,故基于上一步所得结果E= {E},首先选出与选项改写句关联度最高的句子作为第一跳候选句hop1。继而,计算其与文章句子(除本身之外)的相似度,取相似度高的作为第二跳候选句hop2。之后,计算文章句子中与hop2之间的关联度(hop1与hop2除外),并取关联度最高句子作为第三跳候选句,以此类推,重复K次(K值视具体情况设定),将所得的句子与候选句集合E合并。
2.4 筛选模块
2.4.1 冗余度
通过计算给定集合中句对间信息重合度,来确保候选句的多样性和信息互补性。得分越低的句子集合,信息冗余度越低,如式(2)所示。
其中G表示给定句子集合,gi与gj分别表示集合中的某条句子,t(gi)表示gi所包含的词集合(去重后),|t|gi| ∩t|gj||表示gi与gj的共有词数量。
该模块用于衡量给定集合G对选项改写句H的词汇覆盖率,由H与集合G之间的共有词的IDF值加权平均得到。Coverage值越大,该集合包含选项改写句的信息越多,如式(3)、式(4)所示。
其中,Ct(H)表示选项改写句与集合之间的共有词。
2.4.3 相关性
使用BM25[21]计算给定集合G与选项改写句H的相关度。计算如式(5)所示。
从上述三个角度分别计算出给定集合得分后,综合得分计算集合的ROCC值。
R为集合与选项改写句的relevance得分,O为集合的overlap值,C(H)为集合对 选项改写句的coverage值,为避免计算中出现分子或分母为0的情况,添加ε作为平滑项,实验中设ε值为1。之后,选ROCC得分最大集合作为最终的候选句集合E2,如式(6)所示。
3 答题模型
得到候选句集合后,将其句子拼接为文章C。之后同问题Q,选项Oi一起作为答题模型的输入,如式(7)、式(8)所示。
式(7)中,f(·)表示模型编码过程,所得Ai∈Rd为文章、问题、选项的最终表示,其中d为模型维度。式(8)中,W∈Rd×4为参数矩阵,At为问题的正确选项。
4 数据集
4.1 候选句数据集
4.1.1 高考候选句数据集
以华中科技大学档案馆为例,档案馆联合学校数学与统计学院、社会学院通过课题立项的方式研究馆藏数据,经过数据提取、汇总、计算和列表作图的档案数据信息分析,直观地表达事物的量变过程,从微观着手,发现宏观规律。该课题以馆藏的数字统计学院近十年就业数据,分析研究本科毕业生就业状况为例,旨在探究十年来学生毕业取向,总结各类学生的成长规律,为以后做好学生职业发展规划打好基础。还依托大学校园网络服务大平台建设,抓住机遇积极与学校教务处加强合作沟通,在教务处信息化平台下,通过读取注册中心学生信息,掌握了第一手学生课程及成绩的档案信息,学校档案馆利用这些信息,开发网上出国成绩代办自助系统及综合档案业务利用系统。
由于缺少中文阅读理解候选句语料,本文从数据集中随机抽取500道题,对每个选项人工标注其候选句。标注规则为: 对应每个选项,文章中与判断其正误有关句子标注为1,反之,标注为0。为确保数据标注质量,本文采取交叉验证的标注方式: 将数据二等分,由四个同学两两一组进行标注,各组内同学标注的数据相同。标注后两组同学交换进行两轮校验,针对标注结果中不一致数据,由仲裁者仲裁进行第三轮校验,剔除无法确定的数据,若无异议,经三轮验证后,将所得标注结果确定为最终候选句集合,包含45 311句对。其中训练集,验证集,测试集包含数据量分别为: 36 254,4 528,4 529。
4.1.2 RACE候选句数据集
本文采用Wang[3]标注的500道RACE mid-challenge部分候选句对,共34 736句对,其中训练集、验证集、测试集分别为27 790,3 473,3 473。由于初高中试题难度有所区别,在验证候选句抽取对答题的影响时,本文仅使用RACE数据集中的初中部分进行测试。
4.2 阅读理解多项选择题数据集
本文采用RACE数据集 mid-challenge部分进行实验 ,共收集18 364道题,按8∶1∶1方式将数据划分给训练集、验证集、和测试集。此外,本文同时收集了2005—2019年高考语文阅读理解选择题共7 886道,与RACE采用同样方式划分。
5 实验设计与结果分析
5.1 模型评价指标
候选句抽取评价指标: 实验采用F1值、P(准确率)、R(召回率)来评估候选句抽取效果, 计算如式(9)~式(11)所示。
答题模型评价指标: 对于答题部分,采用Accuracy作为模型性能评价指标。
5.2 参数设置
针对不同数据集的实验参数设置如表1所示。
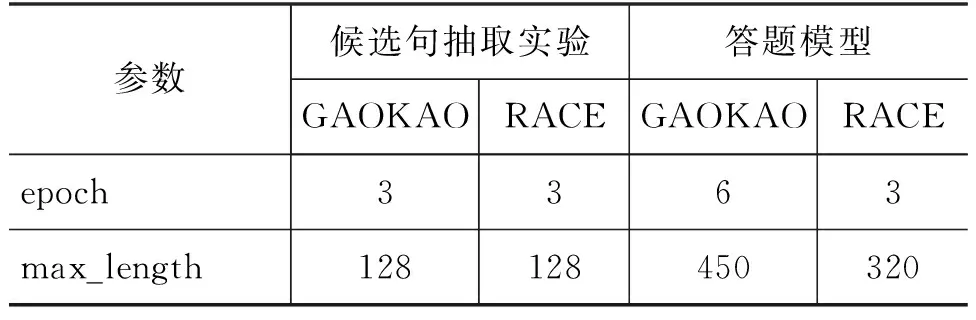
表1 模型参数设置
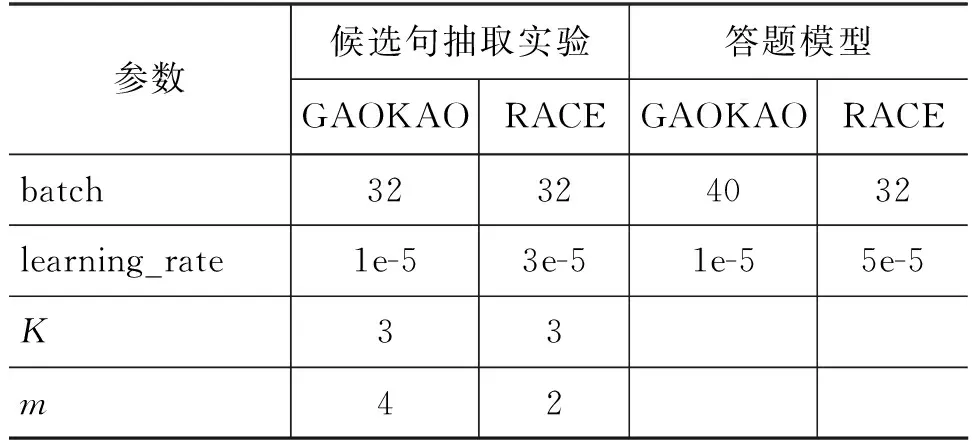
续表
5.3 实验结果与分析
5.3.1 基线模型性能比较
表2中展示各模型在高考及RACE候选句数据集上的效果。对于高考候选句数据集,从表中可看出BERT-wwm的P值,R值及F1值均高于BERT-base;ALBERT-base抽取候选句虽P值较高,但R值相比于BERT-wwm低17.71个百分点。故针对高考数据集,本文以BERT-wwm为基础进行改进,结果表明结合RFTR(本文方法)后,模型效果在P值上提升5.41个百分点,R值 提升1.99个百分点,F-1值提升3.44个百分点。对于RACE数据集,基线模型中BERT-wwm取得最优效果,故在此基础上结合RFTR后,效果提升了3.95个百分点。以上所述验证了所提方法的优越性。
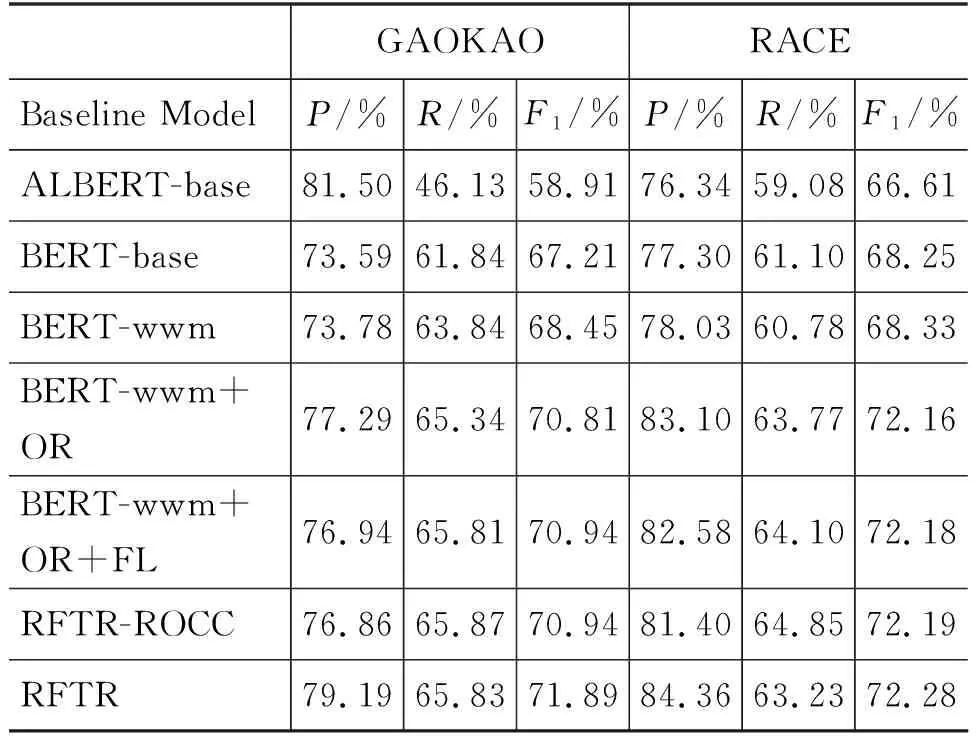
表2 基于高考语文和RACE的候选句抽取结果
5.3.2 候选句抽取消融实验
为进一步研究所提方案对实验结果的影响,在高考及RACE候选句数据集上分别进行了消融实验。如表2所示,改写选项后(即表中OR)在两数据集上模型F1值相比基线分别提升2.36及3.83个百分点,并且P值和R值也均有提升,表明改写选项使信息更完整,语义更通顺,这对模型的语义学习有很大帮助;之后针对数据集中正负样本不均衡现象,使用FocalLoss进一步使模型效果在F1值上分别提升0.13和0.02个百分点,其中对于高考R值提升0.47个百分点,表明更换损失函数后,模型对正样本学习的偏向性增强;使用TF-IDF相似度计算抽取多步推理问题的候选句使模型召回率分别提升了0.06和0.75,表明该方案可以有效缓解多步推理问题的信息损失;最后,使用ROCC从候选句集之间的冗余度,候选句集对选项信息覆盖率和候选句与选项相关性三方面考虑,进一步对结果进行筛选,在两数据集上P值分别提升2.33个百分点和2.96个百分点。
5.3.3 候选句抽取效果验证
本文在高考阅读理解选择题(高考语文)与RACE数据集上进行验证,将抽出的候选句拼接作为新文章输入模型,效果如表3所示,其中EV(RFTR)表示使用候选句作为文章的方法,该实验结果证明了候选句抽取的有效性。
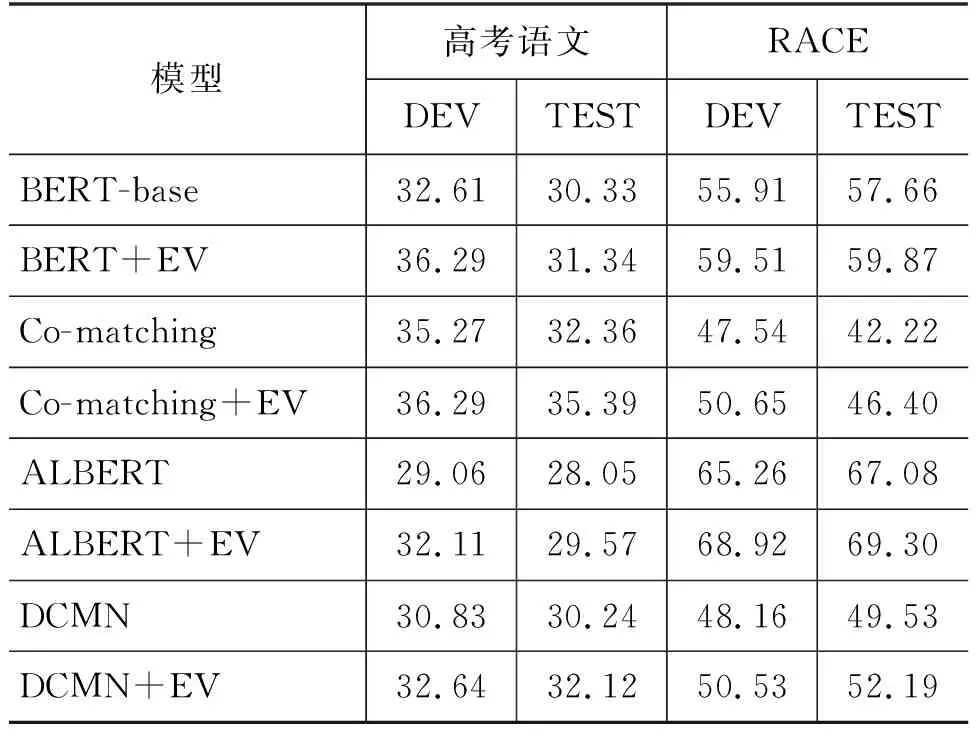
表3 高考语文与RACE数据集答题模型对比结果
5.3.4K,m对候选句抽取实验结果的影响
为比较实验中TF-IDF递归抽取模块(见3.3节)中K值及候选句筛选模块(见3.4节)全组合中m值对候选句抽取的影响,本文进行了参数对比实验。实验结果如图4、图5所示。由图4可知,在高考阅读理解选择题及RACE数据集中,随着跳数的增加,候选句的召回率逐渐提高,当K为3时召回率与F1值达到最优,表明当跳数为3时可有效缓解多步推理问题的信息损失;而当跳数为4时召回率下降,说明跳数过多也会引入一定的噪声。由图5可知,在高考阅读理解选择题及RACE数据集中m值分别为4和2时准确率达到最优,说明ROCC可有效筛选冗余信息,最大限度地整合相关信息,从而剔除部分无关句或冗余句。
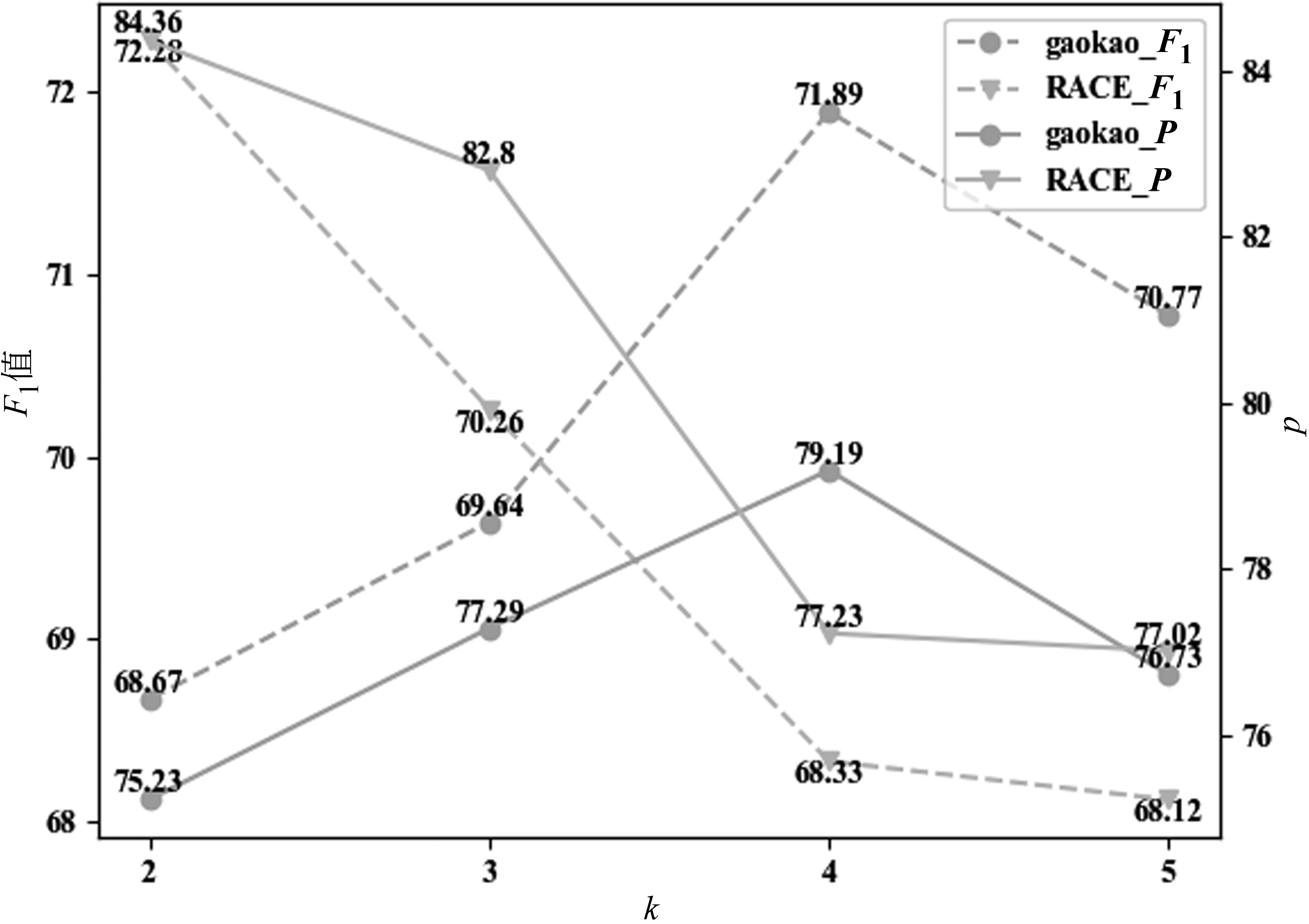
图4 递归抽取K值变化
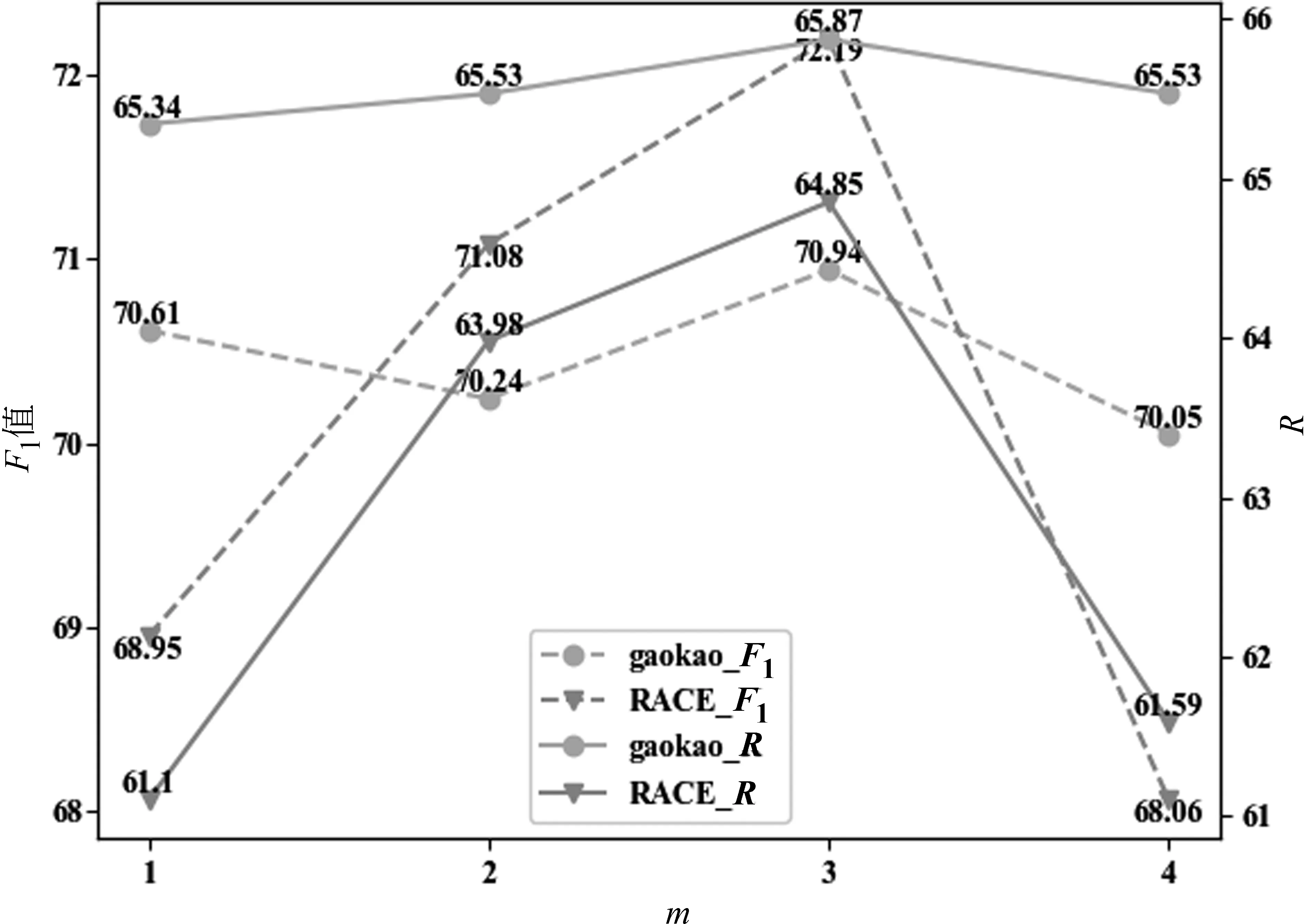
图5 筛选模块m值变化
5.3.5 错误抽取示例分析
本文选取了测试集中50条错误数据进行了分析,表4为列举的错误数据。

表4 错误示例

续表
由表可知,错误原因主要有以下三点: ①指代问题,需辨别表中的“它们”指代“蜉蝣”, 才可知“繁殖”与“生命延续”蕴含;②归纳概括问题: 如“我们都依然得和他一起,承受一个各人心底的诚与爱都尚有不足的时代。”尚有不足的言外之意是: “但那个时代的国民劣根性今天依然存在”,然其表述差异性较大,导致计算机无法“理解”;③涉及归纳与知识融合: 如需使模型知道“书版宋、报版宋、标题宋、仿宋等”均为“字形字体”。
6 总结与展望
本文针对多项选择阅读理解候选句抽取任务,以有监督方式抽取为基础,针对选项语义不完整、数据集正负样本不均衡及抽取结果信息冗余等方面进行改进。在高考阅读理解选择题及RACE数据集上进行实验,证实了该方法的有效性。同时,还验证了候选句抽取对多项选择题答案预测的帮助。此外,从表2可看出,候选句抽取仍存在较大提升空间。结合错误分析,下一步计划挖掘阅读理解中更深层次的线索(如句间指代关联),提升候选句抽取效果,进一步提高答案预测的准确率。
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
中学生数理化(高中版.高考数学)(2020年5期)2020-06-02
领导决策信息(2018年16期)2018-09-27
时代英语·高一(2017年5期)2017-11-14
时代英语·高三(2017年4期)2017-08-11
时代英语·高一(2017年4期)2017-08-09
数学学习与研究(2017年3期)2017-03-09
试题与研究·中考英语(2016年3期)2017-01-05
