
基于半监督学习和规则相结合的中医古籍命名实体识别研究
2022-08-02 03:56包振山宋秉彦张文博
中文信息学报 2022年6期
包振山,宋秉彦,张文博,孙 超
(1. 北京工业大学 计算机学院,北京 100124;2. 首都医科大学 中医药学院,北京 100069)
0 引言
中医古籍上起战国,下至明清,历时两千余年,详细记载了古今众多医者的辨证论治经验和临床诊疗规律,是传统医学珍贵的知识财富。这些古籍中存在着的大量症状名、病机、治法、方药等实体,它们之间的内在联系能够在一定程度上反映中医对疾病的诊疗机理。系统研究这些诊疗机理,进而从中获取可理解、可应用的经验知识来辅助医生临床决策,是一项具有实际应用价值的研究任务。而对中医古籍中的症状名等实体进行识别可有效帮助挖掘中医古籍文本,寻找其中蕴含的关联规则,为上述研究任务打下基础。
面向中医古籍文本进行实体识别,属于自然语言处理中的命名实体识别任务。该任务具有很强的领域性,在本文所涉的中医古籍领域完成该任务存在以下难点:
首先,目前中医古籍数字化程度低[1],获取可用的大量语料较为困难,而易获取的中文通用语料如中文维基百科、人民日报,古文语料如唐诗宋词、史书等,其用词断句均与中医古籍相差甚远;且中医古籍标注语料更是稀少,实验可用数据极为有限。
其次,中医古籍大多年代久远,语言多为古汉语,与现代汉语存在较大差异,导致通用的汉语分词工具Jieba[2]等对其处理效果较差,致使很难获取较准确的词向量。
最后,不同年代、不同地域的不同医家个体,其用词习惯、行文结构均有较大区别,同时中医古籍中的医学术语也在不断发展变化,导致无法按照统一标准进行识别。
故而目前对中医古籍领域的实体识别研究工作较少,且往往仅针对一本书籍。如孟洪宇等[3]利用条件随机场模型对《伤寒论》中术语进行自动识别,该文利用了词性和词边界作为特征,但未充分利用词典信息以及大量无标注的语料信息。叶辉等[4]利用条件随机场对《金匮要略》进行症状药物信息抽取,添加了中医诊断键值对[5]这一特征,此方法在一定程度上加入了中医先验知识,但同时也大大增加了人工标注的复杂度以及时间成本。李明浩等[6]基于LSTM-CRF对《全国名医验案类方》进行症状术语识别,由于语料和分词工具的限制,该文仅从医案语料入手,利用单字特征进行识别。
针对以上分析,本文借鉴了Turian等[7]将词向量作为无监督语义特征融入经典线性模型中的思想,提出了基于半监督学习和规则相结合的识别框架。在构建了中医古籍语料库的基础上,以条件随机场模型为基本框架,在引入词、词性、词典等有监督特征的同时,也引入了通过中医古籍预训练词向量获得的无监督语义特征,并结合中医古籍语言学特点添加基于规则的后处理,F值达到83.18%,有效提升了识别效果。
本文主要贡献包括以下4个方面:
(1) 本文整理并校对了376本中医古籍,构建了一个针对中医古籍领域的大规模未标记语料库,弥补了中医古籍语料不足的缺陷。
(2) 为了提取无监督语义特征以及为后续的中医古籍数字化研究工作打下基础,本文结合开源工具Jiayan(1)https://github.com/jiaeyan/Jiayan完成对古籍语料的分词,解决了汉语通用分词工具对中医古籍基本无效的问题;并利用Gensim的Word2Vec开源工具(2)https://radimrehurek.com/gensim/models/word2vec.html训练该分词语料得到了针对中医古籍的预训练词向量。本文所做语料库与预训练词向量均已开源(3)https://github.com/Sporot/TCM_word2vec,可供中医古籍领域研究者使用。
(3) 本文所提出的基于半监督学习和规则相结合的识别框架,除了引入词性、词典等有监督特征,还引入了基于相似度的无监督语义特征,以及针对不同中医古籍所特有的规则特点,可以在减少人工选取特征及标注成本的同时,对不同时代、不同医家的中医古籍利用规则引入古籍先验知识,有针对性地提升识别效果。
(4) 在标注的《伤寒论》和《金匮要略》数据集上,本文首先从不同特征模板、特征组合角度进行实验得到最优半监督模型,再将其与各类现有模型进行对比分析,最后添加了基于规则的后处理,从而验证了本文所提半监督学习和规则相结合的识别框架的有效性。
1 相关工作
目前已有的主流实体识别方法可大致分为以下4类: ①基于规则学习。规则可以根据特定领域的句法结构或词典进行构造。如Alfred等[8]从马来语的语法结构出发提出了基于规则的马来语实体识别;Hanisch等[9]利用预处理过的同义词词典,识别生物医药文本中的蛋白质和基因名称。此方法虽简单、有效、速度快,但极度依赖于领域知识库的构建,且人工编写规则费时、费力。 ②基于特征的有监督学习。此方法针对标注的数据集设计具有代表性的特征,再利用机器学习中的各类模型,如隐马尔可夫模型[10]、决策树[11]、支持向量机[12]等完成识别任务。王世昆等[13]在明清时期的半文言古医案语料上,对比了条件随机场模型与最大熵模型[14]、支持向量机的识别性能,指出了条件随机场模型在该任务上的优越性。与基于规则的方法相比,此方法对知识库依赖小,自动化程度高,但依赖于标注语料库中的各类有监督特征,在耗费大量人工选取标注特征的同时,也无法利用未标注语料中的无监督语义和结构特征[15]。③基于无监督学习。聚类是无监督学习中最典型的方法,其通过衡量实体之间的语境相似性将实体划入与其相似度最高的一类。如李广一等[16]通过两轮聚类将命名实体与知识库实体定义链接,进而识别知识库中未出现的实体。④基于深度学习的方法。相比于前几种方法,深度学习模型可有效地从原始数据中自动学习有用的表示形式和潜在特征[17]。目前,BiLSTM-CRF仍是解决实体识别问题最常用的模型框架[18]。如Ma等[19]提出了融合BiLSTM、CNN和CRF的端到端序列标注模型,在英文公共数据集CoNLL2003上取得了出色的识别效果。而Zhang等[20]通过编码一系列字符以及所有与词典匹配的潜在词语提出了针对中文识别非常有效的Lattice LSTM模型。但目前多数识别性能较好的深度学习方法往往依赖于大量的高质量标注数据[21],针对标注数据极为有限的情况,开展该研究还有一定局限性。
结合以上研究及现有条件,本文融合了无监督学习与有监督学习,提出了以条件随机场为框架的半监督学习模型,并在之后加入针对特定古籍的规则处理,提高了实体识别的准确率。
2 整体框架
本文所提基于半监督学习和规则相结合的识别框架,借助词性、词典等有监督特征的同时,融入了无监督语义特征和规则进行识别。本文研究的整体框架流程如图1所示。
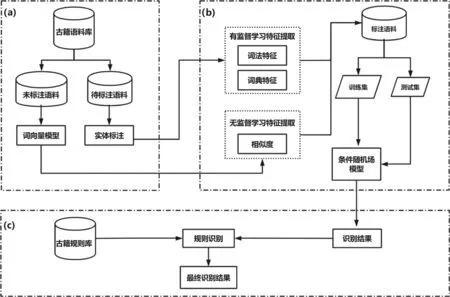
图1 基于半监督和规则相结合的识别框架流程
本文研究框架主要分为三个部分:
(1)中医古籍语料库及预训练词向量的构建。首先整理并校对了376本中医古籍作为该领域可用的大规模语料库,并基于Jiayan分词结果利用Word2Vec开源工具训练获得中医古籍预训练向量。
(2)半监督学习模型的构建。在条件随机场的框架下,首先引入词典、词性等有监督特征;其次根据预训练词向量获取无监督语义特征,得到半监督学习模型。
(3)规则库的构建。对于不同中医古籍间语言风格、用词习惯等差异,以及专业术语等特点,构建具有针对性的古籍规则库,利用规则进一步修正提升半监督学习模型的识别结果。
3 语料库及预训练词向量
3.1 构建中医古籍语料库
目前,中医古籍领域尚未有开源的大规模语料库,而语料库在计算机挖掘中医古籍知识的过程中不可或缺。
故而,本文首先整理并校对了376本中医古籍:从汉代至清朝,包含了孟凡红等[22]总结的中医古籍总目一级类目中基础理论、伤寒金匮、诊法、本草、临证各科等12类医书,构建了相对完善的中医古籍语料库。具体书籍目录可参见开源地址。
3.2 生成预训练词向量
从无标签数据中学习词向量表示形式,可有助于优化多种NLP学习任务,使其拥有更好的性能[23]。词向量是通过训练神经网络语言模型得到的一种分布式表示特征[24],可将词表示为一个连续的实数向量,该向量每个维度都可能代表着该词的一些潜在特征。与将每个词表示为仅有一位为1,其他位均为0的稀疏向量的独热编码(one-hot)方式相比,词向量方式保留了词语丰富的语言规律性[25]。
3.2.1 分词处理
训练词向量时分词的准确性至关重要,而中医古籍用词句法与现代汉语有较大差异,在对其进行分词处理时,Jieba等常用分词工具效果不好,所以本文结合Jiayan完成针对古籍的分词。
为了验证分词的有效性,本文选取《金匮要略》方论卷上中下537句进行人工分词,然后对各分词工具效果进行了评估,评估指标与本文6.2节中计算方法类似,结果如表1所示。

表1 分词效果对比
根据评估结果可得,对于中医古籍,Jiayan分词效果远好于其他通用分词工具。
3.2.2 词向量训练
在上述分词的基础上,本文使用了Word2Vec获取词向量。选用了Mikolov等[26]提出的利用大规模数据计算词语连续向量表示的CBOW模型架构进行训练。CBOW模型架构如图2所示。
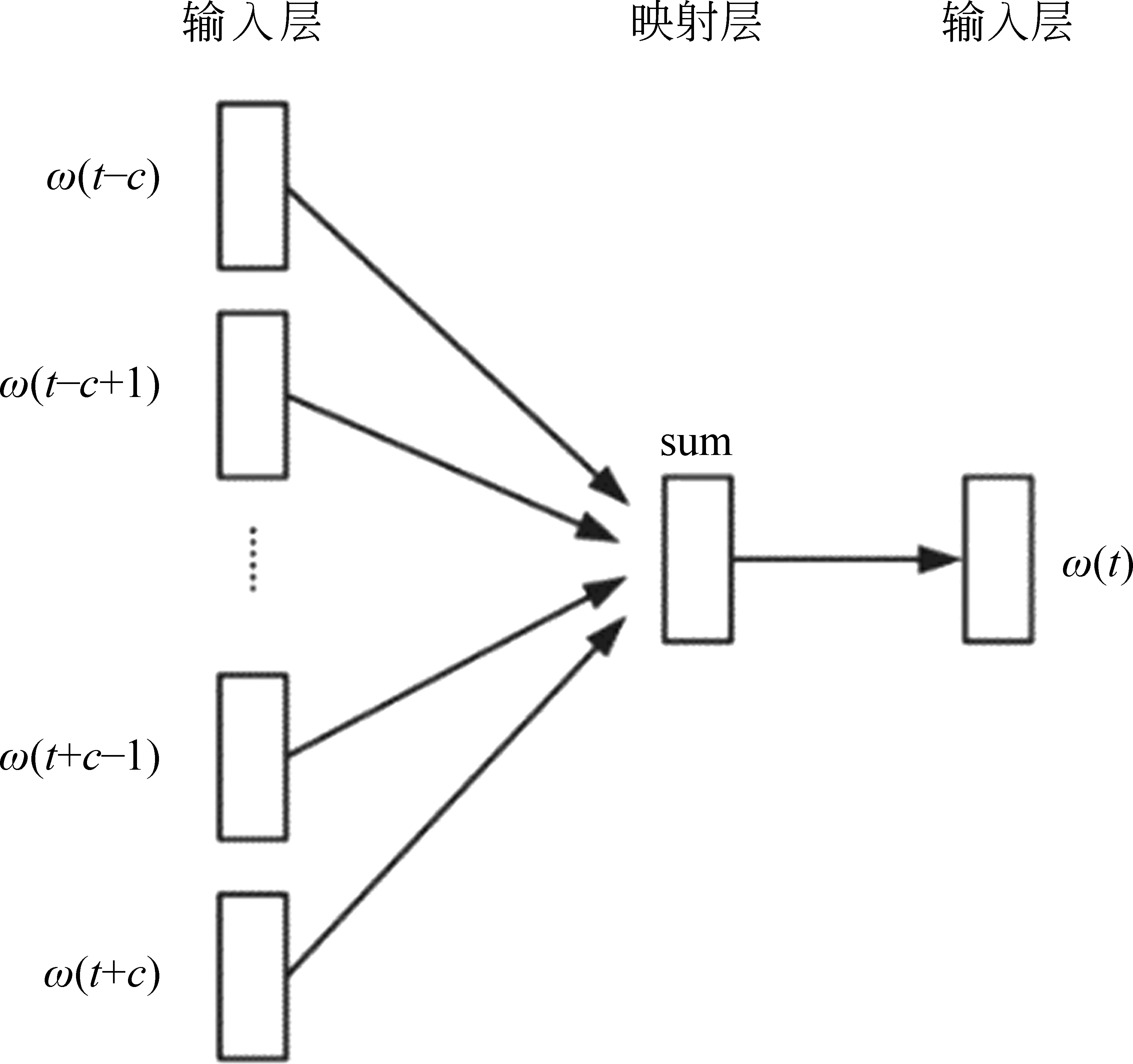
图2 CBOW模型架框
对于一个给定长度为T的文本序列,时间步t对应的词为ω(t),当时间窗口大小为c时,CBOW模型通过最大化给定上下文背景词生成任一中心词的概率,得到词ω(t)对应的m维词向量(v1,v2,…,vm)。
为了验证领域语料的必要性,本文利用易获取的中文维基百科训练词向量进行对比,最终训练结果如表2所示。
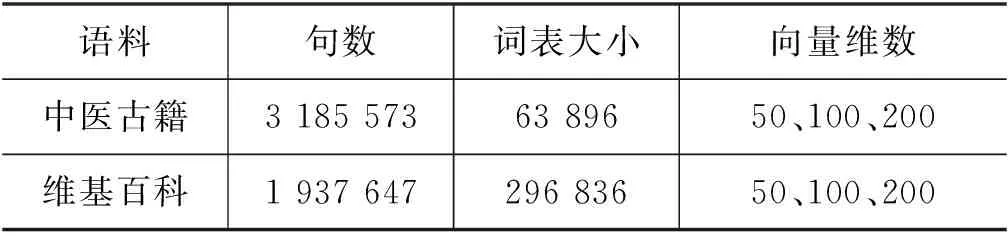
表2 词向量训练结果
评价词向量主要有两种方法[27]:
第一种为语义相关性,通过比较词向量间相似度大致评估其表示语义的准确性。
本文选取了不同语料词表中均包含的两个样例词语,一个为中医古籍常见症状“恶寒”,一个为现代汉语常见症状“呕吐”;利用词向量计算与样例词语空间上最相似的五个词,从而对不同语料和不同维度下的词向量进行评价,计算结果如表3所示。
分析表3的结果可得,中医古籍语料词向量所得相似词在语义上更加接近,其效果明显优于维基百科。且如“厥逆”等中医古籍特有的词语,在通用语料中往往查无此词。由此验证了使用领域语料的必要性。此外, 不同维度词向量间语义表达性能也有区别,从此评价方法来看,100维向量表达语义能力最佳。
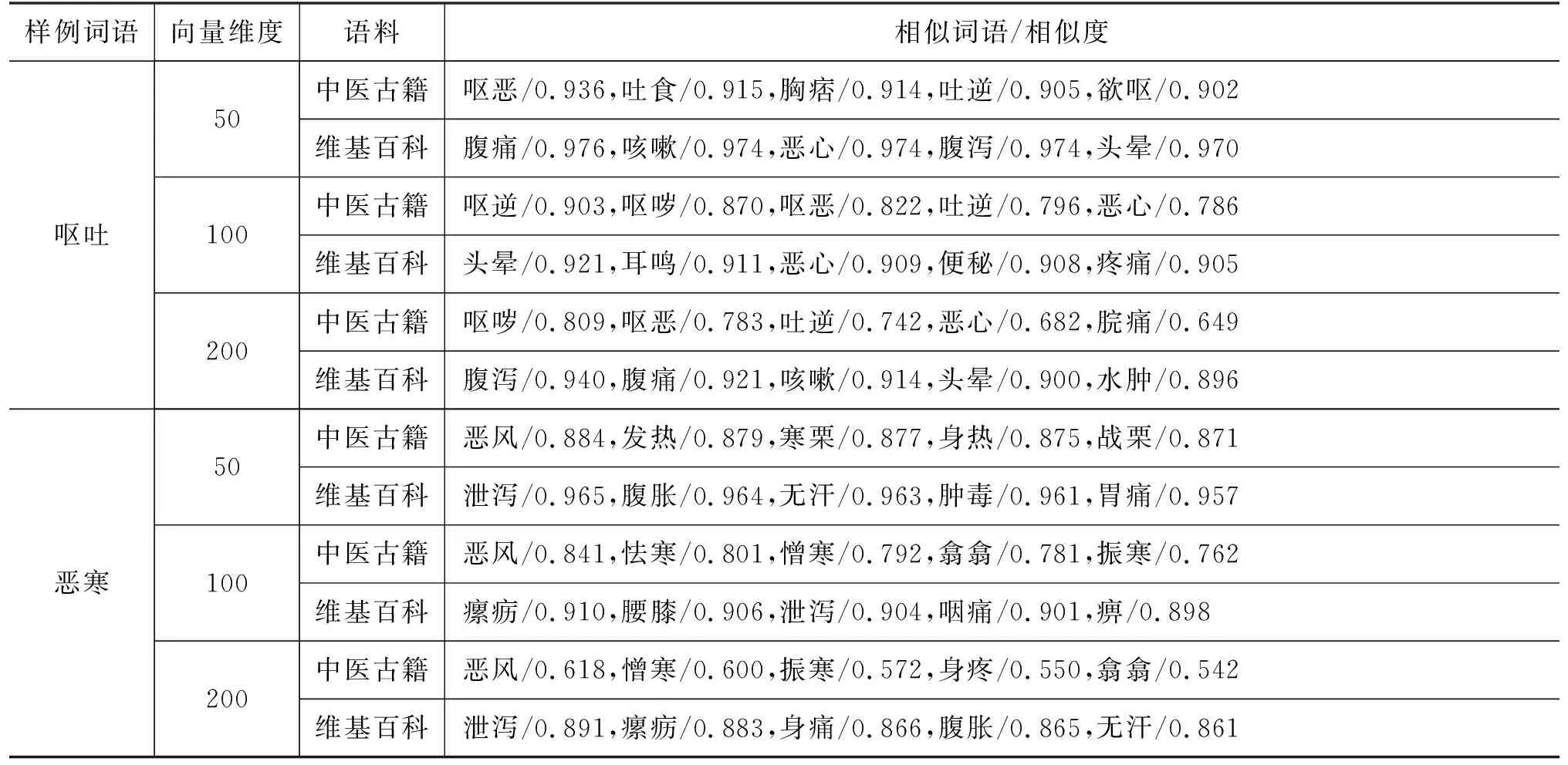
表3 词向量语义评价
第二种评价方法是通过衡量词向量对自然语言处理任务的提升效果,将在6.3.2节中进行描述。
4 半监督学习模型
4.1 条件随机场
本文所提半监督学习模型基于条件随机场(Conditional Random Field, CRF),其由Lafferty等人[28]于2001年提出,是一种以给定输入序列为条件,预测输出序列的概率的无向图模型。思想主要来源于最大熵模型,结合了隐马尔可夫模型、最大熵模型特点,克服了隐马尔可夫模型假设条件的限制及最大熵模型标记偏执的缺陷,可有效解决序列标注和文本切分问题,故而适用于命名实体识别研究。
对于中医古籍命名实体识别,给定观测序列X=(X1,X2,…,Xn)即古籍中的字,及对应的标记序列Y=(Y1,Y2,…,Yn)即实体类别标签,Y的条件概率分布P(Y|X)构成条件随机场,如式(1)所示。
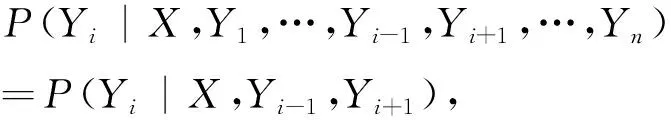
(1)
其中,i=1,…,n,对于线性链条件随机场,随机变量Y取值为y的条件概率如式(2)所示。
其中,
fk(t,Yi,Yi-1,X)表示当给定输入序列中的位置i和输入X,当前位置的标记Yi和前一个位置的标记Yi-1时的第k个特征值;wk为特征权重;Z(X|为归一化因子,在所有可能的输出序列上进行求和。条件随机场模型利用前后向算法进行不同序列位置的条件概率和特征期望,使用拟牛顿法等极大化似然估计求解模型参数,利用Viterbi算法进行动态规划解码测试序列结果,得到相应的实体类别标签。
4.2 特征定义
基于条件随机场的实体识别,选取合适的特征是关键。通过对中医古籍文本及实体词特点分析,本文从以下三个方面选取特征。
4.2.1 词性特征
词性作为语言独立特征,可能有助于提升识别效果。中医古籍中的古汉语最大特点是有词类活用和兼类词的现象。词类活用是指临时改变其基本语法功能去充当其他词类的一种特殊使用现象。兼类词是指有些词不止具有一种词性,经常具有两种或两种以上词性。例如,“夫阳盛阴虚,汗之则愈,下之则死”当中的“汗”字后面出现了宾语“之”,所以此处的“汗”字的词性应为名词活用为动词,解释为“发汗”。据此,本文在参考了信息处理用现代汉语词类标记规范的同时,兼顾古汉语的词性特点,设立如表4所示的词性标记集。
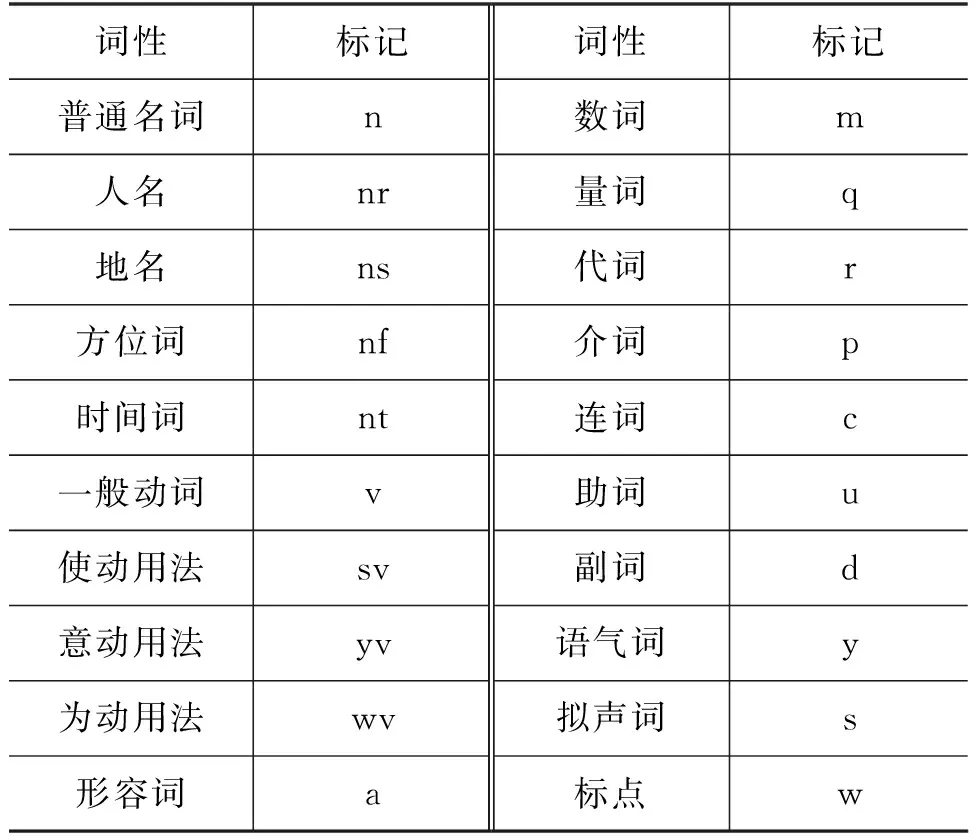
表4 古籍词性标注集
4.2.2 词典特征
中医古籍中的命名实体本质为名词,而这些名词出现的周围常伴随一些提示词语,如“其气上冲”“其人恶风”“身灼热者”中,“其”“其人”“者”均为提示词语,提示词语前后可能会出现相应的古籍实体词,故而整理并标注提示词作为词典特征,对提升实体识别效果可能有重要作用。通过对中医古籍语言特点的分析,可构建提示词词表。标注时,判断当前词是否在提示词词表中, 若在, 则标为“Y”, 不在则标为“N”。
4.2.3 无监督语义特征
由于在语义上相似的词语,其向量表示也是相近的。而中医古籍中的同一类实体名之间,如症状名“恶寒”与“怯寒”,其语义本身具有很强的相关性。故而,本文考虑将通过实体词典中词与待识别词语间的词向量相似度作为无监督语义特征引入条件随机场,弥补统计模型无法表达语义的局限。
根据3.2节在获得了词对应的词向量后,可以计算词向量间余弦相似度,获取词之间的相似性,从而得到相似度特征作为无监督语义特征。例如,词语w1的向量表示为A=(A1,A2,…,An),词语w2的向量表示为B=(B1,B2,…,Bn),则w1和w2的余弦相似度计算如式(4)所示。
其中,CosSim∈[-1,1],CosSim值越大,则两词关联度越高,即CoSim值越接近1,两词语义越相似,当CoSim值为1时,两词相同。
4.3 特征模板定义
条件随机场模型可以综合上下文信息以及外部特征,而如何有效融合不同特征,达到最优识别效果,特征模板的定义至关重要。本文采用CRF++开源工具(4)http://crfpp.sourceforge.net/构建中医古籍实体识别模型,利用定义的特征模板获取特征并学习。本文的特征模板定义如表5所示。

表5 特征模板定义
表5中,w表示标注语料中的第一列,也就是词本身。窗口表示词语间的跨度,如对于“五苓散主之”这句话,若是在按字分词的情况下,将当前词设为”散“字且窗口大小t设为2时,上下文t个窗口的词则分别是”五“、”苓“和”主“、”之“。F表示除词语本身之外的其他特征,也就是语料中除第一列之外的其他列,其中,Fij表示与当前词相差i个窗口的第j个特征对应的值。
5 基于规则的后处理
正如前文所分析的,不同中医古籍间随着年代的发展,地域的不同,存在用词习惯、行文风格、专业术语变迁等差异。为了有针对性地解决这些差异造成的识别错误,本文提出了基于规则的后处理。建立资源库和规则库,从中医古籍语言学与中医专业角度修正识别结果,提升识别性能。
5.1 建立资源库
本文所用资源库主要分为三个部分,每个部分的表示符号及具体内容如下:
(1)实体名词典(word_D):待识别的各类实体名词典。
(2)实体用字库(word_L):统计上述实体名词典中出现汉字作为实体名首字、中间字和尾字的频率,若频率达到指定的阈值,则将该字加入知识库,知识库分为如下三类:①实体名首字库(word_F);②实体名中间字库(word_M);③实体名尾字库(word_L);
(3)特征词集合(word_T):结合中医专业知识及古籍语言学特点,整理了识别实体相关的特征词集合,包括如下几类:①实体名前向指示词集合(word_B);②实体名后向指示词集合(word_A);③实体名中间词集合(word_I);④单字实体名集合(word_S);⑤表示并列关系的词与标点符号集合(word_P)。
5.2 建立规则库
本文通过整理根据中医专业者在进行人工标注时所遵循的部分可描述规律,结合构建的资源库总结并设计识别规则,建立相应的规则库。所有规则只适用于实体名识别后处理阶段,用以修正半监督学习模型的识别结果。具体构建实例如6.4节所示。
6 实验及结果
6.1 实验数据集及标注
本文选用了东汉张仲景所著《伤寒论》和《金匮要略》作为标注集,对该书中词性、症状名实体进行标注。
根据所选书中语言特点整理出包含38个提示词的提示词词典,进行词典标注。结合5.1节介绍符号表示,整理出如表6所示的提示词词表。
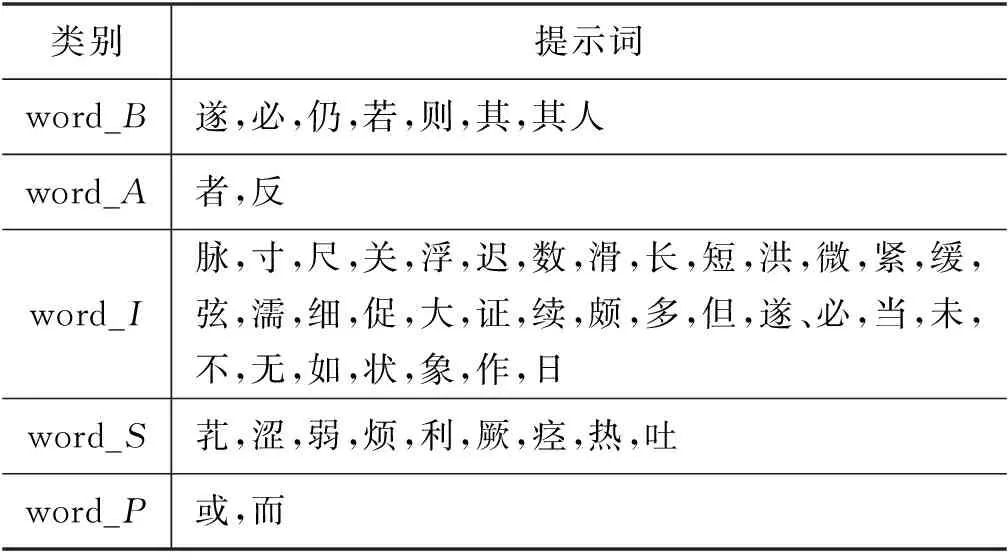
表6 提示词词表
将本文所用标注集获取无监督特征标注时,选用《中医临床常见症状术语规范》[29]整理出症状名词典,该词典包含症状名实体2 702个。计算待识别词与该词典中最大相似度作为该词的相似度值。由于CRF特征均为离散值,故而需将连续的相似值映射到[0,9]的离散空间内。而实验中,在分析了相似度结果后,为了更大限度地区分词之间的相似性,在映射过程中,设计映射规则如表7所示。

表7 相似度映射规则
最终,处理过后的标注数据共有17 081条,标注集示例如表8所示。将标注数据按照7∶3划分为训练集和测试集。用此标注集及整理词典验证上文所提基于半监督学习和规则相结合的方法对中医古籍实体的识别性能。
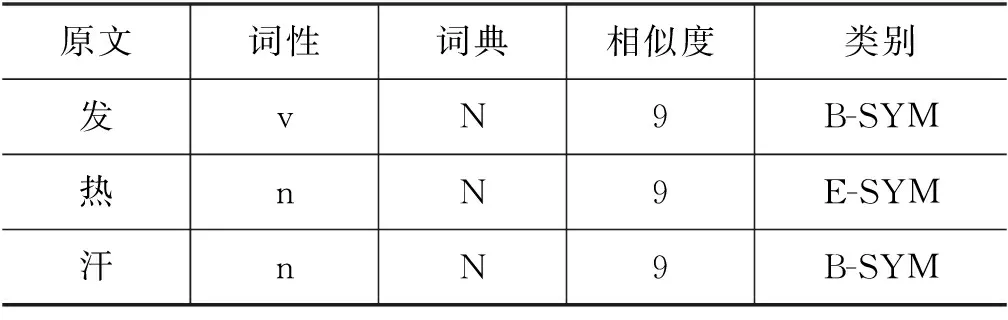
表8 标注集示例
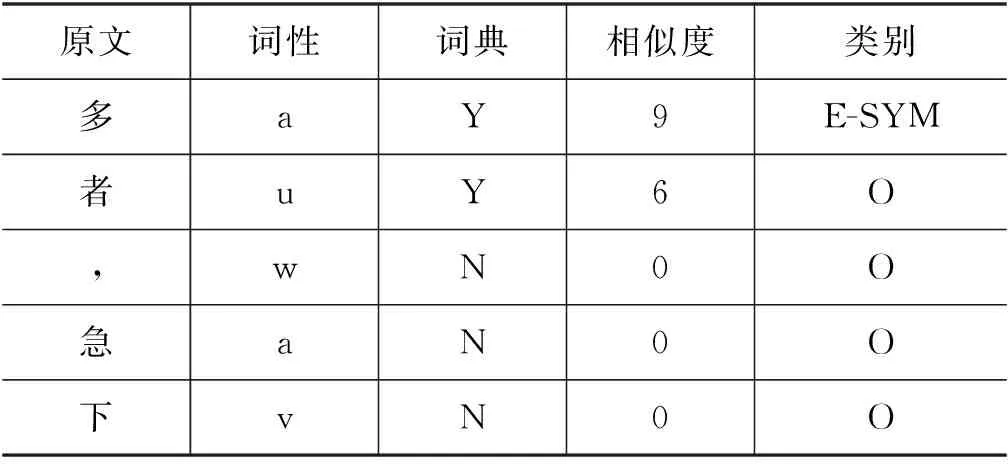
续表
6.2 评价指标
本文采用准确率(Precision,P)、召回率(Recall,R)和F1值三个指标来评估实验结果,其计算如式(5)~式(7)所示。

(5)

(6)

(7)
6.3 实验结果与分析
6.3.1 基准识别性能
首先仅选原文而不添加以上定义的任何特征,并对4.3节特征模板中的上下文窗口大小t取不同值,验证识别效果。结果如表9所示。故而选取t=3时的识别效果作为基准性能(Baseline)。
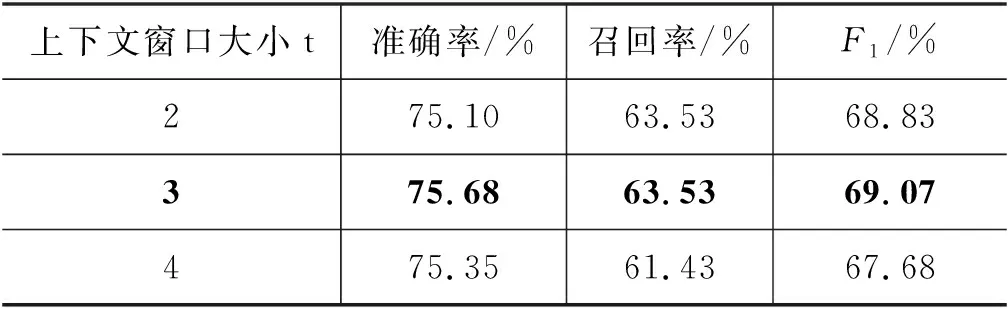
表9 基准性能
6.3.2 单一特征对识别性能的影响
在原文的基础上分别添加词性、词典及无监督语义特征进行实验。
在单独添加无监督语义特征时,由于不同维度词向量略有不同,故而在同一特征模板下,先对中医古籍不同维度词向量产生的不同相似度特征对识别性能影响进行实验。结果如图3所示,根据该图结果,可得在维度为100时,无监督语义提升识别性能效果最佳。

图3 词向量维度影响
之后,通过调整特征模板定义,分别选取添加各类特征后的最优识别结果如表10所示。

表10 单一特征识别最优性能对比
分析表10结果可以看出,分别加入词典、相似度和词性特征,均对识别效果有所提升。其中,相似度特征F1值较词典特征高了0.4%,由此可以证明无监督语义特征可以在不需要人工进行整理提取并标注的情况下达到和部分有监督特征一样甚至更好的效果,由此证明其可降低人工选取特征的代价。而加入词性特征提升效果是最明显的,相比基线性能提升了5%,可见词性特征与模型识别性能关联度最高。
6.3.3 组合特征对识别性能的影响
基于添加单一特征的实验,继续对多个不同特征进行组合,验证不同组合特征对识别性能的影响。由于已证明在单独添加词性时识别性能最好,所以在以添加词性特征为基础的情况下添加其他特征。测试不同特征模板定义,得到各类组合特征最优识别性能,如表11所示。
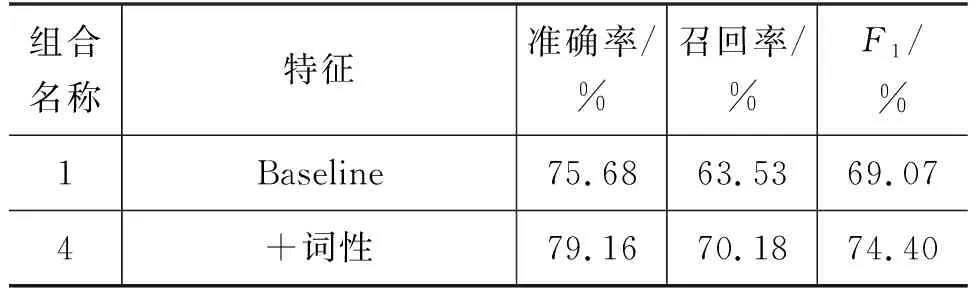
表11 组合特征识别性能对比
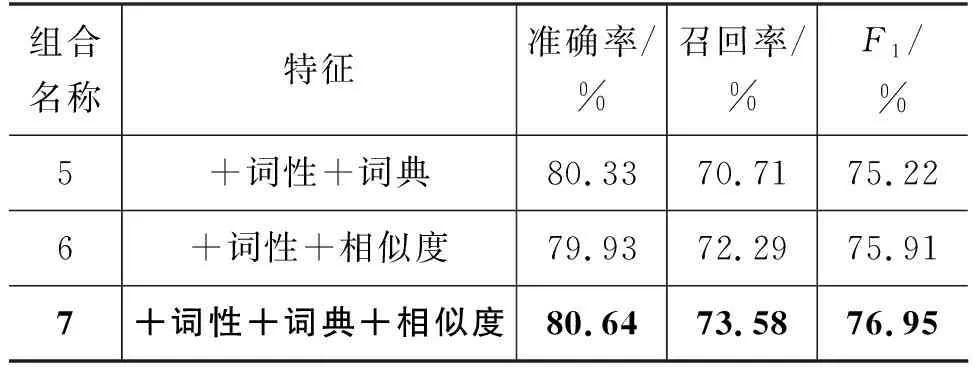
续表
通过分析表11的结果可知,组合特征的识别性能均好于仅添加词性特征的识别性能,而在词性特征基础上添加无监督语义特征的识别结果较添加词典特征识别结果高了0.7%,再次验证了无监督语义特征可以替代部分有监督特征,从而在减少人工标注量的同时更快、更好地达到更优的识别效果。
同时,表中结果也证明,在融合三类特征时,识别性能最佳,与Baseline相比F1提高了7.88%,证明了此半监督学习模型的有效性。
6.3.4 与其他模型识别性能的对比
在命名实体识别任务中,统计模型如条件随机场(CRF)、隐马尔可夫模型(HMM),深度学习模型如BiLSTM、BiLSTM-CRF往往能得到不错的结果。故而,在本文标注数据集上,将上述模型与本文所提半监督模型进行识别效果的对比, 从而验证本文模型的有效性。对比结果如表12中组合名称1,8,9,10所示。
此外,本文所提半监督学习模型从无监督语义的相似度角度引入了《中医临床常见症状术语规范》的症状名词典信息。为了更有效地对比模型,本文还选用了Ding等[30]提出的Multi-digraph模型对本文所标注数据进行识别,该模型结构如图4所示。
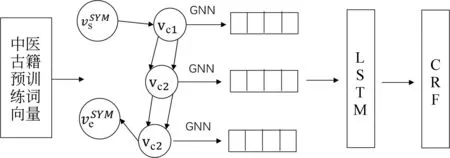
图4 Multi-digraph模型结构

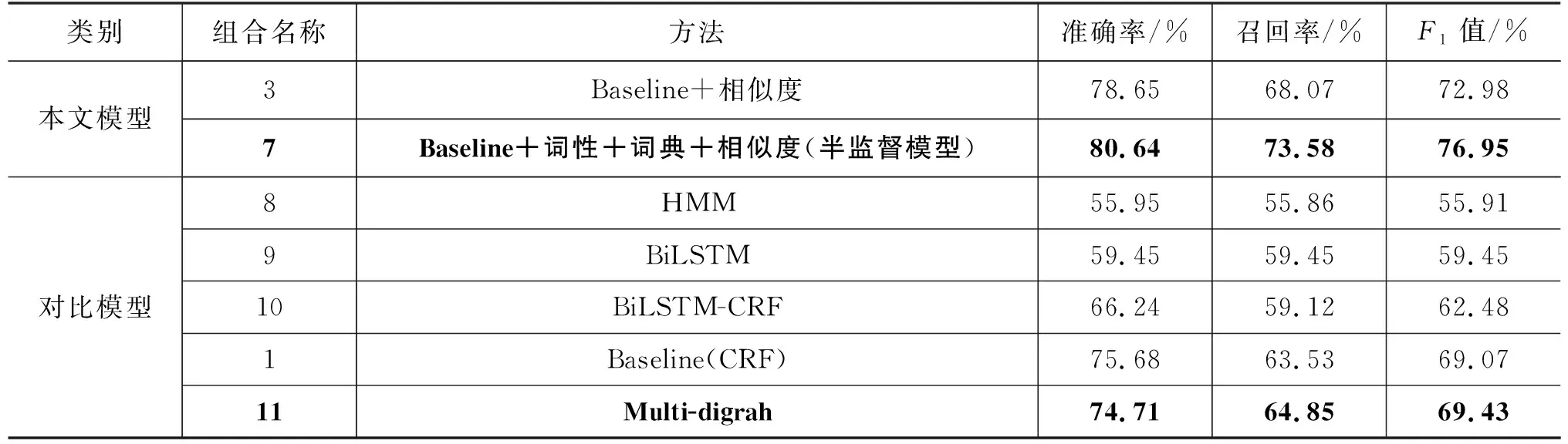
表12 与其他模型对比结果
从对比结果可以看出,在本文所标注的中医古籍数据集上,由于HMM无法捕获元素间长程相关性,该模型识别性能较差。而可能由于标注数据规模的限制,深度学习模型BiLSTM、BiLSTM-CRF也未能达到较好的识别效果,深度学习模型Multi-digraph的识别结果好于未添加外部特征的CRF模型,但与同样引入症状名词典信息的组合名称3模型相比,识别性能差一些;同时本文所得半监督学习模型即组合名称7的识别性能高于该深度模型7.52%。由此证明针对此中医古籍数据,本文所提半监督学习模型更加有效,且训练周期短,效率更高。
6.3.5 规则后处理对识别性能的影响
结合第5节中的分析,添加规则可以有效针对不同中医古籍特点提升识别性能。如《伤寒论》讲求以脉测证,当出现28脉中的脉象词往往是症状实体。同时,本文还对半监督模型的识别错误结果进行分析:如“既O/吐O/且O/利S”中,吐与利均为症状名,而半监督学习模型识别出“利”为症状,却未识别出“吐”为症状,根据5.1节资源库中的单字实体名和并列关系词可将其修正为“既O/吐S/且O/利S”。将如上类似情况进行结合总结,最终设定相应规则表达式如下:
设字串WqScWh,其中,Sc=C1C2…Ci…Cn表示候选症状名,Ci表示候选症状名中的字,Wq为候选症状名前一个词,Wh为候选症状名后一个词。
定义符号“∈”表示“属于”,“∉”表示“不属于”,“||”表示“或”,“&&”表示“和”,“//”表示并列关系。
定义函数IsSymptom(S),表示将S识别为症状名;IsDel(S),表示删除标记为症状名的S。
结合5.1节中规则资源库中表示符号,制定规则如下:
规则1(Wq∈wordB||Wh∈wordA)&&(SC∈wordS||SC∈wordD)→IsSymptom(Sc)
规则2(S)c//SZ)&&(SZ∈words||SZ∈wordD)→IsSymptom(Sc)
规则3(C1∈wordF&&Ci∈wordM&&Cn∈wordL)&&(Wq∈wordB||Wh∈wordA)→IsSymptom(Sc)
利用上述规则对识别结果进行修正,结果如表13所示。

表13 基于规则的后处理实验结果
由实验结果可知,添加规则修正后,相比半监督学习模型,识别效果F1提升了6.23%,相比最初的Baseline提升了14.11%,由此验证本文所提出的基于半监督学习和规则相结合的中医古籍实体识别方法的有效性。
7 结论
本文针对中医古籍实体名识别问题,首先构建了相关的大规模未标注数据集并训练了古籍词向量,从中获取了无监督语义特征。之后采用了条件随机场作为模型框架,选取词性、词典等标注特征与无监督语义特征一同进行组合实验,对比其识别性能,确定最优的半监督学习模型;并将此模型与深度学习模型进行了对比,证明了此半监督模型的有效性。
最后,在半监督学习模型结果上加入基于规则的后处理,结合了古籍先验知识有效提升了实体名的识别效果,并通过实验验证了本文所提出的基于半监督学习和规则相结合的方法对中医古籍此类自然语言处理程度较低的领域的有效性。
未来工作中,我们将优化词向量获取方式,进一步探索无监督算法对此领域的挖掘。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
通信技术(2021年12期)2022-01-25
汉字汉语研究(2021年3期)2021-11-24
布达拉(2020年3期)2020-04-13
计算机应用与软件(2018年9期)2018-09-26
金桥(2017年5期)2017-07-05
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
外语教学理论与实践(2014年2期)2014-06-21
