
基于特征知识库的动漫视频暴力场景检测方法
2022-08-02 11:00张春磊熊丽婷
计算机测量与控制 2022年7期
张春磊,熊丽婷
(1.成都理工大学 工程技术学院, 四川 乐山 614000;2.华东交通大学 理工学院, 南昌 330100)
0 引言
动画电影和卡通片是重要的娱乐来源,特别对儿童更是如此。此类视频在设计时会考虑到儿童的心智水平,但卡通片中的某些内容也可能对儿童造成负面影响[1]。由于卡通片中的角色没有能力限制,这可能会使其产生暴力和激进的行为。一些研究表明,卡通片中的暴力内容会造成儿童观众对疼痛的不敏感。这些儿童观众习惯了暴力内容,在现实生活中将暴力当成了正面元素,并从中得到享受。此外,一些研究认为卡通片中的暴力会增加儿童的攻击性[2]。
目前暴力场景检测技术在视频监控领域得到了广泛关注,并被用于电影的场景过滤中。过去提出了很多视频中暴力内容的自动检测方法,但大部分方法针对常规视频开发,使用不同的低级和高级特征进行暴力检测[3],或者基于视频图像进行一些异常行为的检测[4]。目前已有方法大部分基于声音和视觉特征,以及这两种特征的结合进行视频中的内容感知和暴力检测。文献[5]提出一种结合多种模态特征的暴力检测技术,首先采用一种新的网络模型分别对音频和视频进行暴力检测,然后进行视觉和听觉双模态融合的暴力检测,最后采用注意力机制和双向网络进行优化。实验结果证明,该方法具有较高的准确率。文献[6]提出了中等暴力程度的聚类技术,以进行视频中的暴力检测。其中使用了声音-视觉特征和机器学习技术。使用多核学习对声音和视觉模态进行测试。该系统在来自2013 Affect Task的数据集上进行训练和测试,并通过MAP@100进行了评估。文献[7]提出一种基于局部约束的稀疏分类模型和运动韦伯特征相结合的暴力检测方法。利用高斯滤波对输入视频去除一些噪声,提取出运动韦伯特征;利用改进的稀疏分类模型用于特定类字典的学习;利用相应的分类机制用于对视频中的暴力行为进行分类。结果表明,提出的特征具有较强的判别性,且提出的基于局部约束的稀疏分类模型非常有效。文献[8]利用ImageNet和MIT场景数据集中的数据,对每个视频帧中的成分属性进行检测以进行对象识别。通过将该属性与来自视觉和声音模态的其他低级特征相结合,构建支持向量机(Supported Vector Machine, SVM)分类器[9]。
一部卡通中的场景对于某个儿童来说是暴力的,但其他儿童则可能认为其并非暴力场景。这种情况下的阈值等级是高度主观的,且在不同观众、不同情况和不同文化背景下存在显著差异[11]。本文提出了能够对卡通视频中的暴力内容进行自动检测的框架。首先,基于低级特征将卡通视频分割为不同片段;然后,并识别出不同对象,以找出令人高度反感的元素;最后,基于个体感知对卡通视频进行映射。仿真实验表明,本文方法在对象识别中具有较高准确率。
1 本文方法
1.1 系统架构
本文提出了用于卡通视频的暴力检测方法。首先,检测并识别出场景中的物体和动画角色,用于估计暴力概率。与现实视频不同的是,大部分卡通角色具备独有的特征,可用于预测场景的性质。同样的,在存在暴力元素的情况下,场景中的动画角色和不同物品也可用于估计场景的暴力性质[11]。例如,若视频中存在暴力角色和刀剑、献血等对象,则意味着该场景为暴力场景的概率较高。而非暴力角色例如桌椅、鲜花、乐器等普通物品则意味着该场景具有非暴力性质。本文使用贝叶斯概率模型来估计场景中的暴力概率。图1给出了所提系统概览。
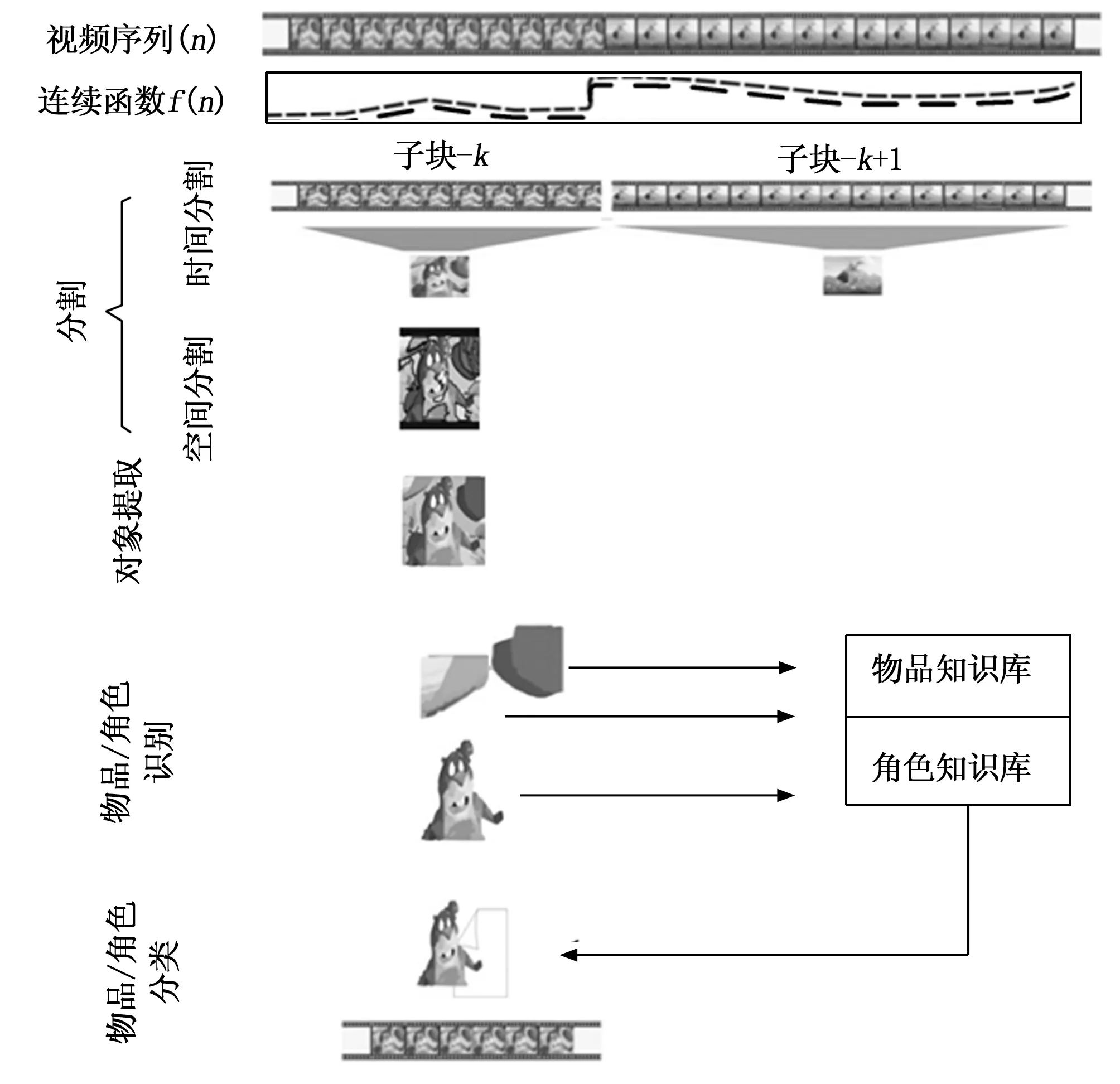
图1 暴力检测系统
算法1给出了本文所提的暴力估计模型的处理流程。
算法1:卡通视频暴力检测算法。
输入:M= 视频(片段)
1 forn= 1 toNdo //长度为N的视频,包含视频帧1...n。
2Fn= Extract-Frame_RGB(M,n) //将视频帧转换为RGB格式
3Fgray= RGB-to-Gray(Fn) //灰度转换
4Fr= Extract-Red-Channel(Fn) //RGB分离
5Fg= Extract-Green-Channel(Fn)
6Fb= Extract-Blue-Channel(Fn)
7FHSV= RGB-TO-HSV(Fn) //HSV分离
8Fh= Extract_Hue-channel(FHSV)
9Fs= Extract_saturation-channel(FHSV)
10Fv=Extract_Value_channel(FHSV)
11k= 1
12 for 每个Gray、RED、GREEN、BLUE、HUE、Value、Saturation通道 do
13 将特征加入特征向量FVn
14 ifn≠1 then
15M=TSS(Fn+1,Fn, mbSize,p)//利用TSS计算运动向量,mbSize= 20,p=5
16Δfn=|FVn+1-FVn|
17 ifΔfn>ththen
18k=k+1
19 将视频帧n标记为镜头边界k
20 SBF = 提取从第k-1帧到第k帧的镜头特征
21 Obj = 提取从第k-1帧到第k帧的关键帧中的对象
22 for 每个对象Obj do
23 OVF = Extract-Object-Visual-Feature//提取对象的视觉特征
24 if OVF在CKB中 then //将OVF与角色知识库相比较
25 Violencefactor(Obj) = extract-average-offensive-factor(Obj)
26 else if OVF在OKB中 then //将OVF与物品知识库相比较
27 Violencefactor(Obj)= extract-average-offensive-factor(Obj)
28 else
29 忽略对象Obj
30 Append_merge(Scene-Violence-factor, Violencefactor(Obj))//合并对象的暴力因子数值
31 Prob_of_SVF = Estimate-SVF(Scene-Violence-Factor)//估计卡通视频场景的暴力概率
CKB:角色知识库
OKB:物品知识库
1.2 分镜检测和视频帧提取
一般卡通视频的低层次特征提取主要采用两大类视觉信息:亮度和色度。亮度信息是最明亮的信息,它包含了视频内容的大部分数据。在卡通漫画中,这些信息在理解场景的内容中扮演着重要的角色。大部分视频都是YPbPr格式,亮度信息由Y通道呈现。在本文研究中,视频以RGB格式提取。在这里,亮度信息以灰度级的形式提取。
本文利用低级特征(RBG颜色、亮度、色调)开发连续函数,并用于识别场景中的镜头边界。利用这些镜头边界信息,确认子镜头。从每个子镜头中选出有代表性的视频帧作为关键帧,并通过从子镜头中提取出的特征,利用关键帧进行对象提取。
1.3 运动估计
本文利用运动信息,计算视频帧中的运动。进行运动估计时,首先,将视频帧分割为108个子块,排列为9×12的阵列。在视频序列的当前帧和上一个已处理帧之间执行块匹配运动估计。将当前帧分割为非重叠的方形块,像素大小为N×N,每个块在上一帧中均有一个大小为(2W+N+1)×(2W+N+1)的对应搜索区域,其中,W为沿水平和垂直方向的最大像素位移。则对于每个当前块,寻找搜索区域中与当前块实现最优匹配的块。将平均绝对差(MAD)作为匹配准则:
MAD(x,y)=
(1)
式中,Fc(·,·)和Fp(·,·)分别为当前帧和上一帧中的像素强度,(k,l)为当前块的左上角像素坐标,(x,y)为与当前块位置相关的像素位移。检查搜索区域中的每个位置后,将运动向量定为具有MAD最小值(即最小误差)的(x,y)。
然后,利用图像块匹配运动估计方法的搜索(TSS)算法[12],计算出二维运动向量。虽然TSS最初针对搜索窗口相对较小的低速率视频应用而提出,即限制在W= 7,但可对TSS程序进行扩展,并用于W> 7的情况,其步数也将超过3步。
一般来说,给定W,则需要的步数计算为:
L=[log2(W+1)]
(2)
式中,[x]表示大于或等于x的最小整数。由此,第n步的步长(每步搜索中像素间距)计算为:
ss(n)=2L-n
(3)
从中可发现,TSS在每步中使用均匀分布的搜索模式,由此表现出简单性和规则性。具体来说,第一步的检查点数量为9,后续步的检查点数量为8(排查上一步已检查过的位置)。W= 7的情况下,TSS的总检查点数量为25个。由此,与FS的225个检查点相比,TSS的速度提升了8倍。
最后,将以笛卡尔坐标表示的运动,利用以下公式转换为极坐标:
(4)
(5)
利用上述公式得到运动的幅度和角度,并用于理解场景的性质,如图2所示。本文方法中,将该运动信息的复合效应作为特征。利用图像块数量、运动信息及图像块类型组成特征向量。

图2 运动估计示例
为了进一步完善运动估计方法,本文算法使用公式(2)和(3)确定所需步数和使用的步长。其创新点在于,将每步分给为两个阶段:1)选择1个搜索象限;2)在选定象限中找到最小误差位置。以第n步为例。第一个阶段,计算图3(a)的A、B和C的MAD,其中,A为中心位置,B和C分别为水平方向和垂直方向上与A距离为ss(n)个像素的位置。要指出,从A至B和从A至C的方向与图3(b)中的方向1和方向7相对应。此外,令MAD(X)表示位置X的MAD,并标注4个象限I,II,III和IV,如图3(a)所示。确定搜索象限的规则描述如下:
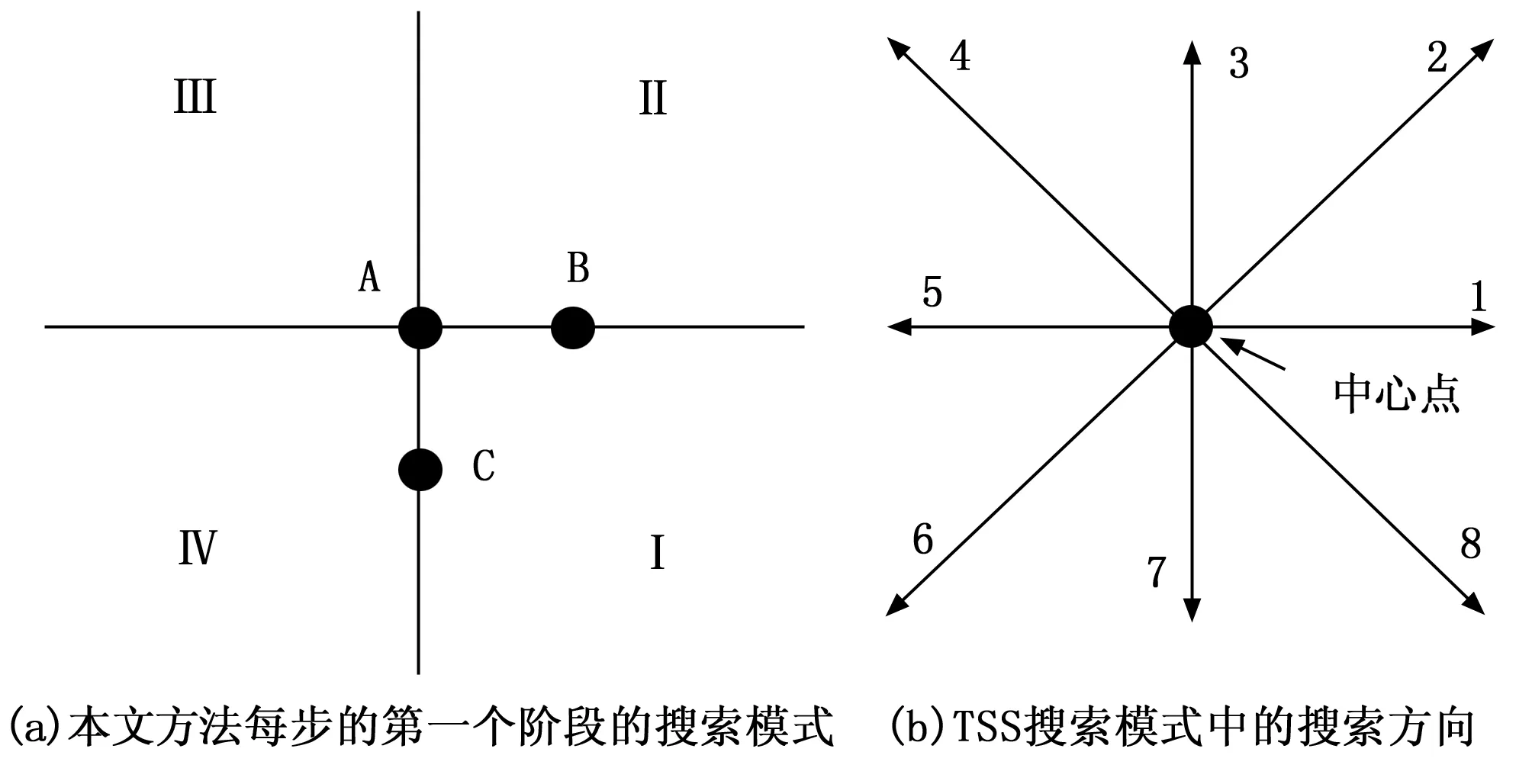
图3 不同的搜索模式
若MAD(A)≥MAD(B)且MAD(A)≥MAD(C),则选择I;
若MAD(A)≥MAD(B)且MAD(A) 若MAD(A) 若MAD(A) 实际上,本文方法在每步中采用相同程序,因此保留了TSS所包含的规则性。 表1给出了不同W值下,3个搜索算法的计算复杂度和加速比。从中可发现,所提本文方法比TSS的速度进一步加快了约1倍。这证明了所提方法的有效性和优越性。 表1 搜索算法计算复杂度比较 为理解图像或视频中的对象,需要基于分割处理进行对象提取。视觉特征和视频运动是图像分割中非常重要的估计。本文使用空间信息和运动信息进行分割。 1.4.1 空间分割 该步骤中对有代表性的视频帧进行分析,以进行空间分割。由于卡通视频中包含的阴影较少,所以卡通视频中的空间分割较为简单。本文利用水线分割(water segmentation)技术进行空间分割。 1.4.2 时间分割 合并从空间分割和时间分割得到的结果,以提取具有相似的视觉和运动信息的对象。大部分卡通对象中包含不同的颜色区域,将其识别为单独分割结果。运动特征中包含作为相同对象某一部分的最相似特征。图4给出了输入图像,从中计算出运动向量。对于该视频帧,利用之前的视频帧和宏块(36 * 48 = 1728)估计出运动向量。对于每个宏块,计算出运动向量。运动向量中,将所有图像块的运动均值作为阈值,并将运动幅度超过阈值的宏块选择为移动图像块。 图4 输入图像示例 图像分割后,需要从中提取物品和角色。利用水线分割技术在彩色特征上执行基本分割,其后基于运动信息,将分割结果合并为物品和角色。由于基于彩色的分割能够改善对象边界,本文所提模型中使用彩色特征和运动特征以提高对象提取性能。 在对象提取后,需要进行物品和角色的识别。在对象识别中,使用欧氏距离方法,利用最小值进行识别[13]。若得到多个结果,则将所有匹配的对象/角色均用于暴力估计。欧氏距离方法的计算过程如下: d(O,F)= (6) 式中,d(O,F)为物品O和知识库K中的元素之间的欧氏距离;Ofi为场景中物品O的第i个特征;Kfi为知识库中物品的第i个特征,i= 1, 2,...,n。在与知识库中的角色进行匹配后,得到3个不同的高级特征,即角色相关的暴力强度,视频中角色的暴力频率,以及角色的搞笑性质(用于确定场景中的幽默性)。暴力强度指的是对某个卡通角色可以预期的暴力类型和程度。例如,猫和老鼠中存在许多暴力场景,但大部分场景的暴力程度不高。但在恶魔猎人动画片中则存在许多严重暴力场景[14]。 暴力频率特征用于确定暴力场景数量。从知识库中得到暴力频率信息,利用贝叶斯概率模型,计算出当前场景提取出的信息中包含暴力的概率[15]: (7) 式中,P(x)为当前场景存在暴力元素的概率;P(y)为当前场景中提取出的特征集合在知识库中的概率;P(y|x)为当前特征集合符合暴力场景的概率。 知识库是所提系统的核心部件,以半自动的方式创建,其中包含所有常见物品、卡通角色及其视觉特征和行为特征的数据信息。该知识库给出了物品和角色与暴力之间的关系。利用该信息,计算场景的暴力概率。将知识库分为两类,即角色数据库和物品数据库。 1.6.1 角色知识库 知识库的第一个部分是角色知识库,包含卡通角色的形态和行为。不断利用新的动画角色对该知识库进行更新。角色知识库包含角色数据集,其中保存了每个角色的不同图像。本文基于颜色(色调)直方图特征,提取出角色(对象)的不同视觉和几何特征。颜色直方图是图像中色彩分布的真实描述。所提方法中在提取色调直方图特征时,首先从图像中移除背景。将无背景的输入图像转换为色调通道并计算其直方图,用于特征提取分析。主要形式的图像输入如图5所示。RGB通道直方图是图像检索中最常用的视觉特征。该阶段中,将输入帧转换为灰度图像及其红、绿、蓝通道的直方图。此外,在物品和角色识别中还有许多重要的基础视觉特征,如纹理特征。由于使用过滤器提取问题特征,计算成本很高,所以本文使用快速傅立叶变换FFT进行问题特征的提取。 图5 输入图像处理 1.6.2 物品知识库 知识库的第二个部分包含常用物品信息,例如玫瑰、枪械、刀具和车辆。该数据库包含这些物品的视觉、形状和运动信息物品知识库包含物品数据集、特征提取、颜色直方图、RGB通道直方图、形状特征和暴力/分暴力物品特征。 另一方面,爆炸性材料(例如炸弹)则更多用在暴力场景中,普通场景中则不多见。为完成场景的暴力分类,识别出场景内的所有物品和角色及其特征,并估计其暴力倾向。场景的暴力概率计算为: (8) 式中,VN表示暴力物品数量;NVN表示非暴力物品数量。 为检验所提算法,本文使用3个不同数据集。第一个数据集包含来自20个不同类别的200个物品。第二个数据集包含513个不同图像帧中的23个不同卡通角色。第三个数据集为暴力和非暴力视频片段的集合,其中共包含200个视频片段,暴力视频和非暴力视频分别为100个。第三个数据集的数据分布如表2所示。 表2 暴力/非暴力视频片段分布 大部分暴力场景会在场景的镜头和对象中出现高光时刻[16]。此外,“献血”“爆炸”“火焰”等元素也会增加场景中的暴力概率。本文方法旨在将根据提取出的角色和物品的暴力概率,将场景分类为暴力场景和非暴力场景。使用最小二乘距离,通过提供知识库提取出的特征(色调、红绿蓝、纹理)和3个主要特征(暴力强度、暴力频率和搞笑程度)对角色的暴力水平进行评分,结果如图6所示。 图6 角色的暴力和非暴力分类 卡通视频中,物品的暴力/非暴力分类比角色分类的难度要大得多。这是因为物品有着各种不同的形状类型。为此,实验首先将视觉特征与最小二乘距离相匹配;然后,将暴力元素与形状和物品相关联,即某个物品与特定类型的暴力相关。如刀或锯条都属于高暴力程度的物品,但也可用于各种非暴力场景中,如图7所示。但当卡通图像中附带一些文字信息或其他确定性信息时,暴力/非暴力性的检测会发生一些转变。一些卡通示例如图8所示,其中,左边写有“氢弹之父”字样的漫画,虽然有氢弹爆炸的元素,但可定义为积极且有意义的。右边的潜艇406表示我国核潜艇的特殊舷号,具有国防教育意义。因此,卡通视频中的一些确定性信息可以对检测分类具有直接定性作用。 图7 物品的暴力和非暴力分类 图8 一些具有确定性信息的漫画检测分类 实验通过构建混淆矩阵(列联表)及马修斯相关系数(MCC)评估所提算法性能,实验结果如表3所示。 表3 本文方法对3个数据集中物品/角色识别结果 从表3可知,在数据集1和数据集2的物品识别中,根据混淆矩阵,准确率超过97%,取得了较好结果;使用高级测量MCC,结果为75.3%,性能较好。在数据集3的角色识别中,准确度为96%,MCC结果则为58.6%。该指标性能较低的原因是数据集中角色的背景影响。若从中移除背景,能够显著提高MCC性能。在第三个数据集中,本文方法的分类准确度为77%,该结果对于基于内容的视频检索系统是较为理想的。本文方法中,若概率超过阈值,则可将物品或角色识别为暴力元素,该阈值可根据观众的需求而设定。 由于动画片中暴力类型的多样性,卡通视频中的暴力检测任务难度很大。在卡通视频和现实视频中,对象的颜色和视觉特征存在显著差异,所以现实视频中有用的低级特征不适用于卡通视频。但卡通视频中,大部分情况下动画角色有着特有的性格和情绪。且为展示一些特效,会使用一些公共特性,例如在战斗场景中会使用乌云。本文方法利用了这一理念,通过识别出场景中的角色,以用于估计是否存在暴力。本文方法利用不同的角色和对象对暴力概率进行预测,在对象识别中取得了较高准确率,角色识别的准确率相对较低。这是原因是样本数据集中的背景影响到的识别性能。
1.4 分割

1.5 物品/角色提取和识别
1.6 知识库

2 实验结果与分析





3 结束语
猜你喜欢
小天使·二年级语数英综合(2017年3期)2017-04-01第二课堂(小学版)(2016年12期)2016-12-21Coco薇(2015年12期)2015-12-10小天使·一年级语数英综合(2015年8期)2015-07-06读者·校园版(2015年13期)2015-07-01小火炬·阅读作文(2014年4期)2015-04-07
——基于与QuestionPoint的对比新世纪图书馆(2014年11期)2014-02-23科学导报·学术论坛(2013年5期)2013-06-26读写算·高年级(2009年3期)2009-11-16
