
12306在线咨询服务智能应答研究
2022-08-02 01:40杨立鹏廉文彬季续国陈华龙
计算机技术与发展 2022年7期
杨立鹏,廉文彬,季续国,李 雯,陈华龙
(1.中国铁道科学研究院集团有限公司,北京 100081; 2.中国国家铁路集团有限公司,北京 100844; 3.中科知程科技有限公司,北京 100044)
0 引 言
自2011年上线以来,12306互联网售票系统功能不断丰富,为旅客提供车票预订、候补、改签、退票等票务服务,推出接续换乘、动车选座、常旅客会员、候补购票和电子客票等客运提质服务;进一步优化架构,提高系统安全性和稳定性,日售票能力提升至2 000万张;围绕旅客出行的全行程,为旅客提供餐饮、酒店、旅游、定制服务等线上线下一体化、个性化、多元化的旅行服务产品。多元化的产品和服务,叠加海量的、不确定的用户需求,为提升面向用户的在线咨询、售后服务等带来了巨大挑战。客服系统作为铁路系统的重要组成部分,在出行高峰期面临服务需求突增,客服人员与服务需求严重失衡、重复性回答大量常见性问题、客服回答内容检索效率较低等问题。因此,12306在微信公众号平台开通了智能客服咨询功能,为旅客出行提供智能、高效的服务。智能客服可为旅客提供7×24小时的余票、正晚点、时刻表、预售期和起售时间等信息查询内容,解答旅客出行中的常见问题,增加了旅客服务的承载量,辅助客服人员快速准确地处理应答,减轻了人工客服的压力,为旅客提供更优质、更完善的体验和个性化服务。但分析大量咨询数据,发现智能客服系统还存在响应耗时较长、针对常见问题的回答准确度还有待提高等问题,影响了用户的咨询体验。因此,有必要对12306智能客服的在线咨询服务进行优化,提高系统响应能力和问答准确度。
在问答研究领域,秦兵[1]介绍了问答系统的构建流程,提出可通过完善建立候选集和优化相似度的计算方法提高智能回答问题的准确性。对单词和句子采用合理的表示方法是提高相似度准确性计算的关键,基于HowNet相似度[2]的计算和基于word2vec的方法是目前应用较多的相似度计算方法。因此,Tomas等人[3-4]针对文本的向量表示方法进行了研究。文献[5-6]研究了文本的相似度计算方法,其中Wang R H提出使用多信息进行文本的相似度计算。此外,由于不需要大量的特征工程工作、可显著减少数据预处理的工作量,深度学习[7]中的循环神经网络[8-9]被越来越多地应用在文本挖掘中。
综上所述,该文研究了候选集的建立和相似度计算的优化方法,综合利用倒排索引技术[10]和LSTM孪生网络[11-12]优化文本的相似度计算流程,从而提高问题的检索效率和准确率,进一步提升智能客服解答问题的能力。
1 在线咨询效果评估
从2019年问答的数据中选取8 741 633条记录,分别针对咨询的响应时间和准确度进行分析。
1.1 咨询响应时间
作为智能客服系统,咨询响应时间是重要的服务指标,其含义为用户发出咨询请求到获得咨询结果所需的总时间。铁路客户总是希望能够得到最快的咨询响应。对不同输入类型的响应时间给出了统计分析,在具体分析时,把响应时间分为三个区间,0~10毫秒、10~120毫秒和大于120毫秒。从统计结果可知,快速回复占比高,耗时较短,应推荐快速回复方法,提高相关文的推荐质量。
1.2 咨询准确度
评价智能客服效果的另一个重要指标是准确率,系统能否准确理解用户的咨询内容,并给出准确的回答。
图1中,会话长度为1且AT=0的含义为,用户在看到系统不能理解自己问题后立刻结束了会话。显然,此时用户的问题没有得到解答;会话长度大于1但以AT=0结尾则代表用户与系统进行了耐心的交流,但最终系统还是未能理解用户问题。未能解答(AT=0)的会话占比平均为20%左右,因此系统需要进一步降低系统未解答的比例。
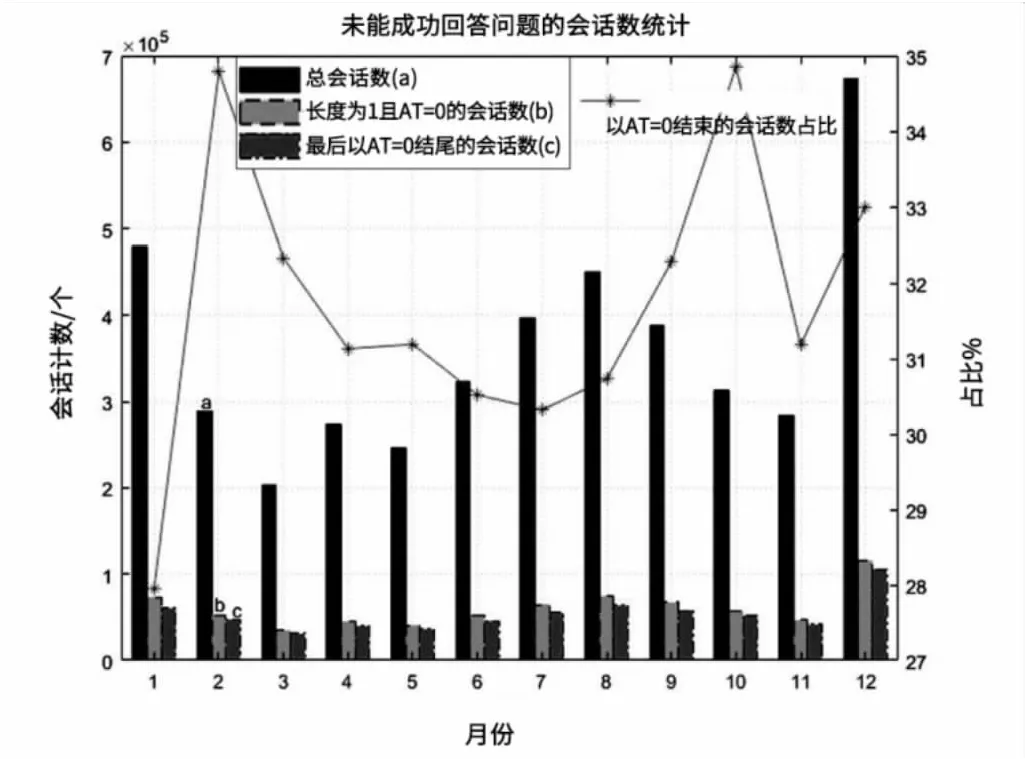
图1 不能回答用户疑问的会话占比统计
2 智能客服咨询服务检索方法
通过在线咨询效果的评估可知在线客服咨询的服务能力还需要提升,因此需要建立一个高效的智能客服咨询服务计算流程。计算流程主要从三个方面进行优化:文本的预处理,FAQ候选集的建立和相似度计算,计算流程如图2所示。

图2 问答系统的工作流程
(1)当语义引擎接收到用户使用咨询的问题后,首先需要对用户提问的问句进行预处理操作,包括分词、词性标注、过滤停用词,从FAQ知识库中把相关度较高的问答对全部选出来作为精准匹配的候选集,利用word2vec训练词向量;
(2)利用孪生网络进行特征提取并生成句子特征向量;
(3)利用句子间的语义相似度计算出用户问句和FAQ候选集合中各个问句的语义相似度,系统设定相似度的最小阈值和最大阈值,如果计算出来的语义相似度存在大于预先设定的最大阈值的问句,将挑选出相似度分值最高的FAQ,并将该FAQ中的答案作为正确答案推送到用户端,并将其余高于阈值的FAQ作为该问题的相关问题汇总后推送给用户。
如果FAQ候选集合中每个问句通过相似度计算出的分值均不超过设定的最大阈值,将判定是否有落在最小阈值和最大阈值之间的FAQ,如果有,则将这部分FAQ作为建议推送给用户,以此引导用户寻找正确的问题答案。如果以上都不满足则推送给用户默认回复的话术,引导用户换一种表述方式咨询问题。
2.1 文本预处理
中文的词语之间是连续的,首先需要去掉标点符号、介词、语气词等虚词以及区分意义不大的高频词和低频词,然后对文本内容进行分词。由于12306智能客服系统关心的不是出现在问句中的每个词是否都能被准确切分,而是那些对检索有意义的相关词语能否被快速准确切分,因此为提高系统效率,根据系统特点设计了业务词库和通用词库两类。业务词库主要涉及业务直接相关的内容,包含铁路客运相关的概念、术语、符号等,该词库对中文分词具有关键性的作用。通用词库主要包含常见的名词、动词和一些形容词、副词等。
由于业务关键词对问题查询的贡献往往大于普通词语,所以对2个词库的关键词分别赋予不同的权重。随着12306互联网售票系统功能的不断完善,业务词库和通用词库也需要持续完善。目前中文分词的技术已十分成熟,多数分词工具如中国科学院的ICTCLAS,哈尔滨工业大学的LITP、jieba(结巴)等,准确率都达到了95%以上。该文使用jieba分词器,并加入业务词库和通用词库,使得领域词汇如“候车室”“二等座”等可以被正确切分。
2.2 FAQ候选集的建立
在问答系统中,为了提高相应回复的检索效率,首先使用倒排索引技术实现问答对的第一层过滤,即首先构造一个倒排索引表,表中的每一项内容包括一个属性值和具有该属性值的所有记录的地址;然后在小范围内计算语义相似度,返回相似度最高的答案给用户;选出FAQ中的问句作为候选问题集。
假设用户输入的目标问题中一共存在n个词{W1,W2,…,Wn},12306的FAQ知识库中共有x个标准的问答对,第k(1≤k≤x)个标准问题中含有m个词{Q1k,Q2k,…,Qmk},目标问题和第k个标准问题之间重叠的词个数记ck,即ck={W1,W2,…,Wn}∩{Q1k,Q2k,…,Qmk},则取ck>0的FAQ中的问答对组成候选问题集。如果将FAQ库中的每个标准问题一一读取后,再和目标问题进行计算重叠的词个数,效率是比较低的。对于目标问句中的某个词,为了能够快速地统计FAQ库中究竟有多少问句含有这个词,本系统使用信息检索技术中的倒排索引快速获取候选问题集。
表1是12306的FAQ库的实例说明,12306的FAQ库存储了所有的12306问答对,其中第一列记录了FAQ库中每个问句在库文件中的位置。表2是构建的倒排索引表,表中第二列记录了FAQ库中的标准问题中所包含的关键词,第三列记录了每个关键词出现在FAQ中的位置编号集合。在FAQ库中出现过的所有关键词及其对应的倒排列表组成了倒排索引,通过关键词索引中的值很容易找到哪些FAQ库中的标准问题包含该关键词。对目标问句中的每一个词都进行这样的处理后,就可以进一步计算出ck的值。最后,找出ck>0的FAQ库中的标准问题位置编号,根据表1中的FAQ集合找到相应的FAQ,计算目标问题中的所有关键词,就可以将相关的FAQ全部找出并建立候选问题集。针对用户问题和候选问题集的相似度计算结果直接影响给用户反馈的结果,所以为了优化短文本相似度的计算,提出了问题匹配的相似度计算模型。
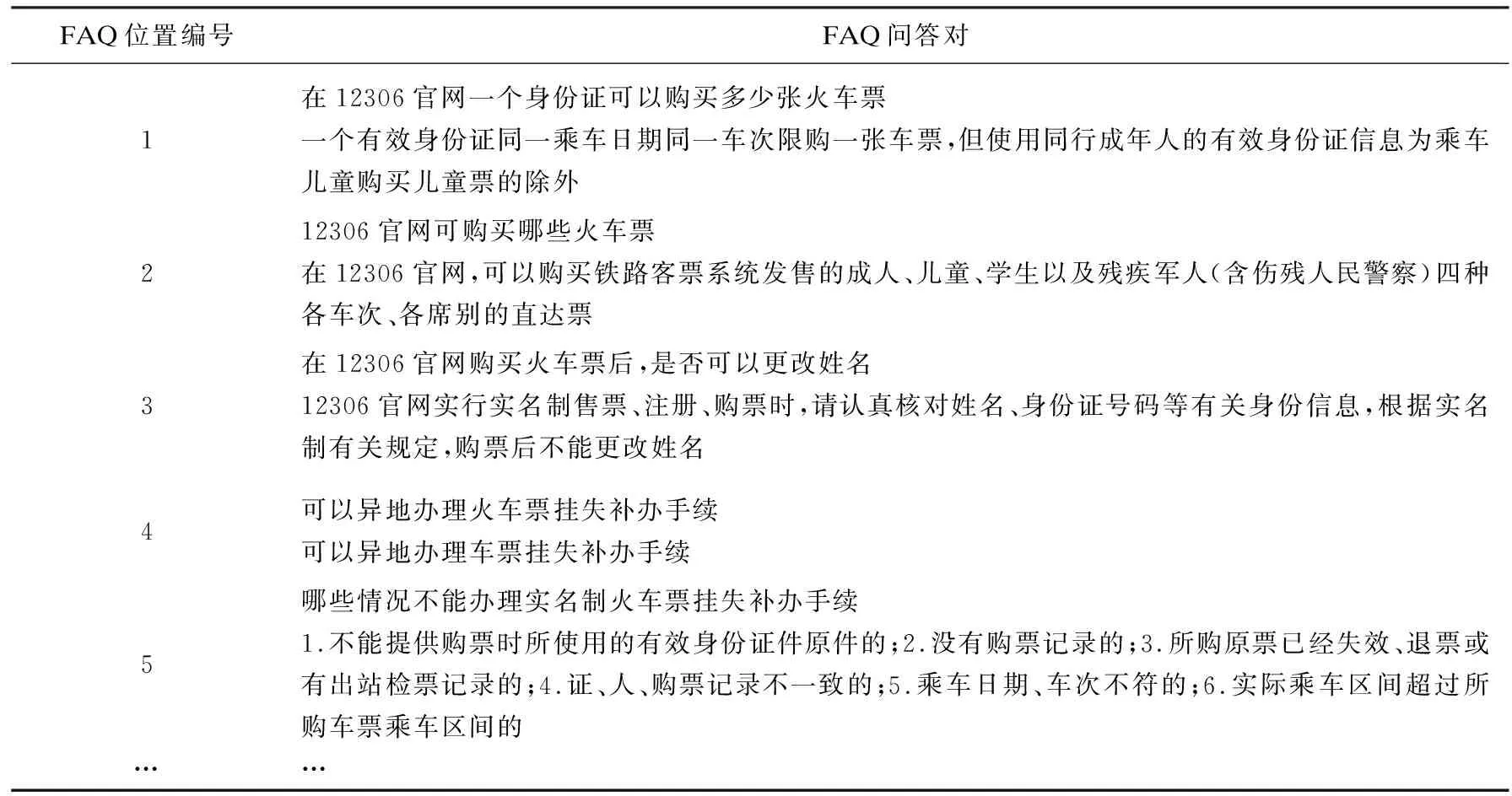
表1 12306FAQ集合
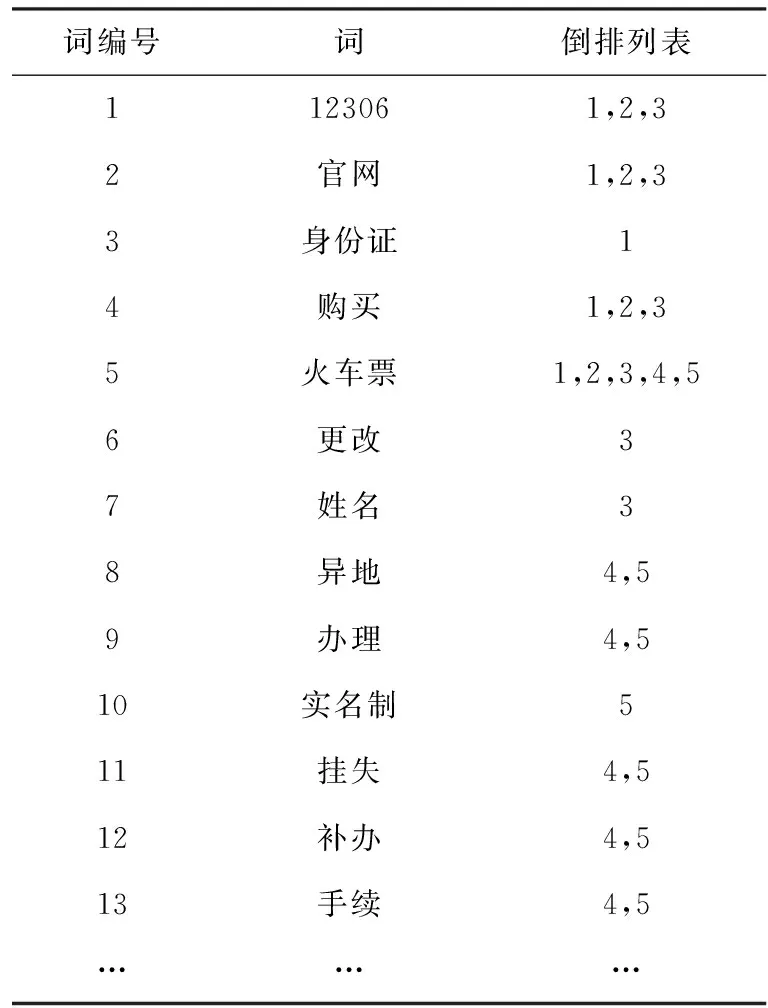
表2 倒排索引列表
2.3 问题匹配的相似度计算模型AT_LSTM
长短期记忆(long short-term memory,LSTM)[13]是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。由于LSTM的记忆单元对原RNN中的隐层节点进行替换,可以学习长期依赖信息,更好地获取整个句子的语义特征,而且已在许多自然语言处理任务如文本相似度计算、情感分析、机器翻译中成功应用,因此选用Siamase LSTM(孪生网络)来计算句子的相似度[14]。
假设12306的FAQ库中有N个问句,需要为输入的问句找出库里与其最相似的问句,即FAQ,显然使用一个LSTM或其他的神经网络需要O(N*N)的时间,这是非常耗时的操作,因此有必要找到一个有效的方法来减轻相似度的计算量。同时FAQ库中的每个FAQ相当于一个类别,根据输入匹配某个类别,属于一个多分类的应用[15]。在学习样本少且类别较多的情况下,适合使用孪生网络进行神经网络计算2个输入的相似性。算法流程如下:
(1)输入两个样本到两个同样的参数权重共享的LSTM神经网络;
(2)通过学习分别提取两个输入的特性向量;
(3)计算两个网络输出的距离,如果距离较近就认为是同一类,较远就认为是不同的类别。这里必须是同样的神经网络,因为如果使用两个不同的神经网络,即使输入相同,输出也可能认为两者不同。为了保证模型达到好的学习效果,通常使用对比损失函数(contrastive loss function)表示成对样本的匹配程度。对比损失函数可以有效地处理孪生神经网络中的paired data的关系,公式如式(1)所示:
(1)
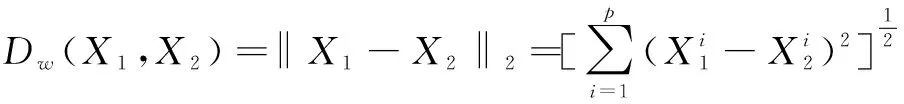
AT_LSTM(attention LSTM,基于注意力机制的LSTM模型)模型相似度计算的孪生神经网络结构主要由输入层、嵌入层、LSTM层、Attention层和匹配层5部分组成,如图3所示。
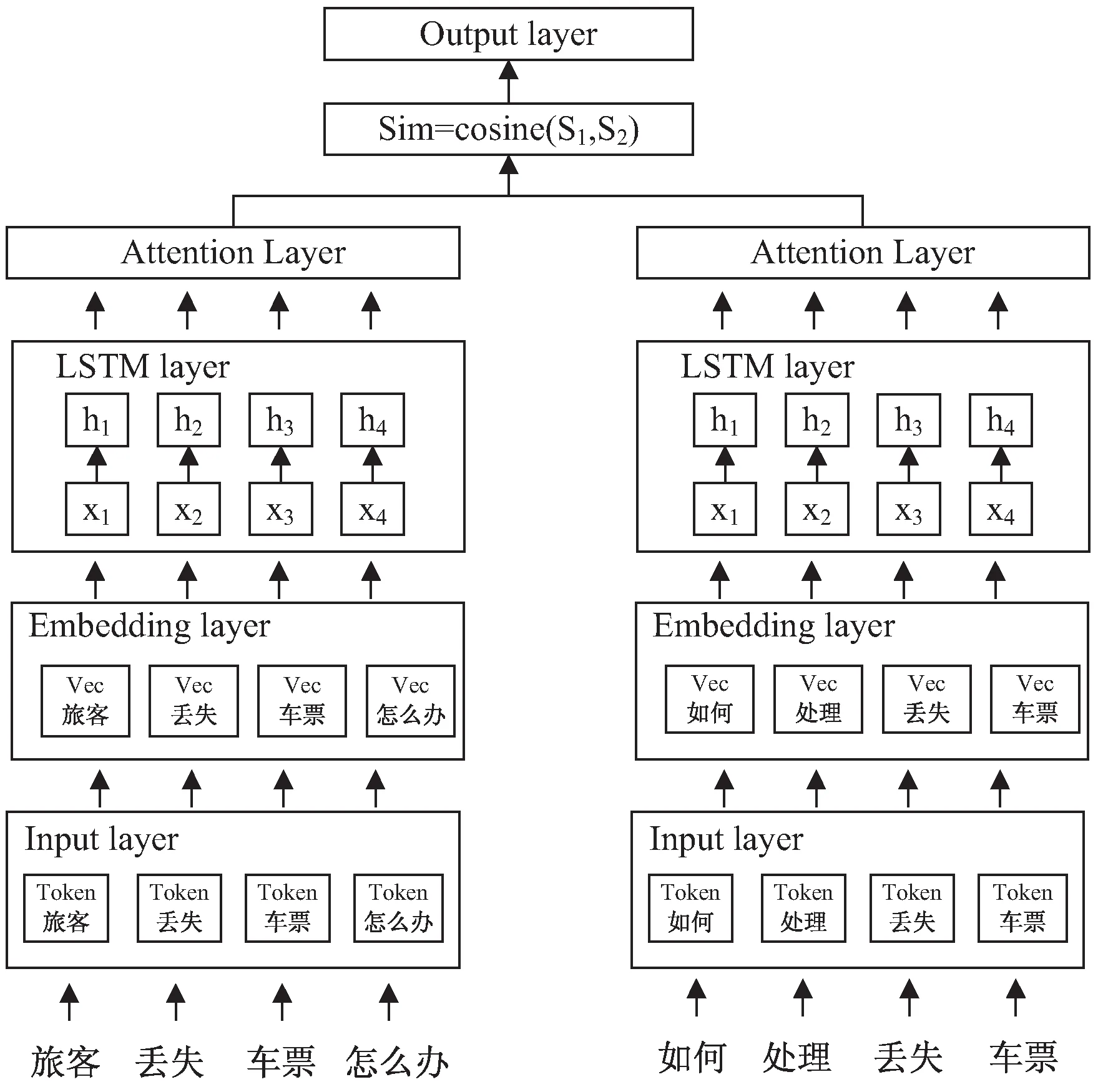
图3 句子相似度模型结构
输入层把每个词语用其在词典中的位置编号表示得到一个词语编号序列,并统一为同等长度,然后传递给嵌入层。嵌入层采用word2vec模型将词语映射为词向量序列后作为LSTM层的输入。在短文本的相似度计算过程中,由于领域相关的特征词对整个文本语义的贡献比较大,当理解一句话时,通常会将注意力放到几个重要的关键词或短语上,所以利用attention机制将领域词的特征对语义贡献的大小加权到句子级别的特征上,能够更深层次地表达文本的真实语义。LSTM网络结构的输出向量表示为[h1,h2,…,hn],使用公式(2)对LSTM输出的每个特征hi进行编码,利用tanh激活函数进行一次非线性变换得到ui,根据公式(3)利用softmax函数得到各个分量ui的attention权重向量W=(β1,β2,…,βn),最后通过公式(4)对LSTM结构输出的向量[h1,h2,…,hn]加权和,得到LSTM提取的句子特征向量表示S。
ui=tanh(Whhi+bh)
(2)
βi=softmax(Wβui)
(3)
(4)
最终在匹配层,得到两个句子的语义表示特征向量S1和S2后,在文本的语义空间中计算两个向量的相似度,从而判断两个问句是否语义相似。使用公式(5)对两个句子的特征向量计算分值。
(5)
3 实验结果及分析
3.1 准备数据集
12306FAQ问答集共600余条,从以往历史问答记录中针对每个FAQ选取意图相同不同问法进行语料标注,每个标准问题选取50条相似问法,50条不相似问法,最终形成64 700问题对。最后将问题对进行分词、打标签形成标准数据集。
3.2 模型训练
实验训练语料共64 700个问题对,其中54 700为训练集,5 000为验证集,5 000为测试集。此次训练使用随机梯度下降法对模型权重进行更新,LSTM网络参数设置如表4所示,其中最大句子长度,即句子中词的数量,根据以往用户访问记录进行统计分析,最大的句子长度是42个关键词,所以句子最大长度设为50。此次训练使用随机梯度下降法对模型权重进行更新,LSTM网络参数设置如表3所示。

表3 神经网络参数
AT_LSTM模型经过100次迭代训练,随着迭代次数不断增加,损失率不断降低,准确率不断上升,说明模型在训练的过程中不断的在优化,模型预测输出值越来越接近实际状况,在第80次迭代开始,损失率下降到约13%左右,准确率稳定在89%左右,模型趋近于平稳,基本已收敛到最佳状态。
3.3 实验结果与分析
为了验证提出模型的有效性,分别与基于HowNet和基于词向量余弦距离的相似度算法进行了实验对比。从表4可以看出,文中方法效果较好,HowNet效果最差,原因在于HowNet根据概念之间的上下文关系和同位关系实现词语相似度计算知识系统词语的语义相似度计算。由于对12306领域词汇收录较少,采用HowNet可能导致计算的相似度比较低;而采用基于词向量余弦距离的相似度算法得到的词语相似度较低,原因在于word2vec虽然解决了文本表示面临的数据稀疏和词语间语义关系建模困难的问题,但是却把词向量简单组合起来表示句子的向量,这并不能完全代表句子的真实语义,导致出现只要2个句子相同或相近的关键词越多则相似度越高的现象。AT_LSTM模型结合了孪生LSTM网络和注意力机制充分挖掘2个句子深度语义信息,然后利用余弦相似度算法计算句子特征向量之间的分值。
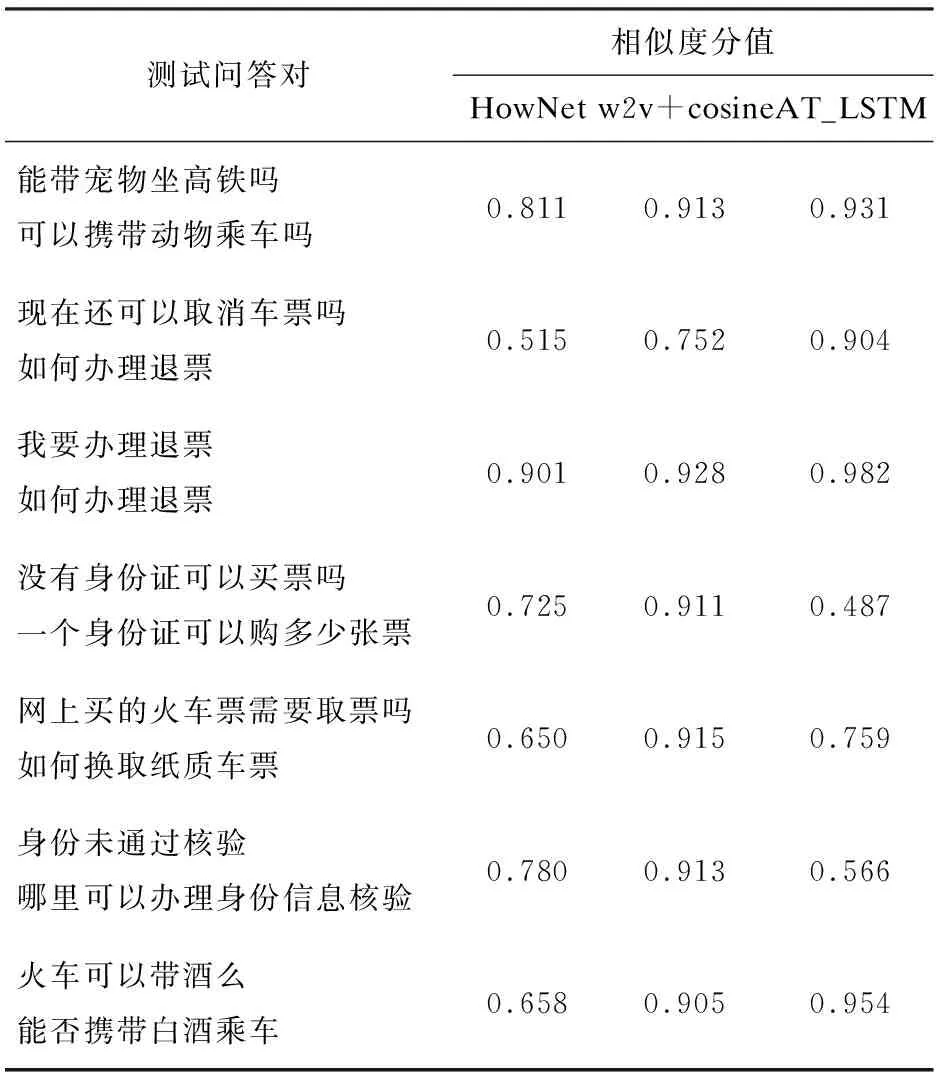
表4 部分实验结果
在测试集数据量相同的条件下,分别利用不同方法得到的准确率和耗时如表5所示。语义相似度值为[0,1]之间的小数,越接近于1表示相似性越高,反之则越低。一般短文本相似度通过人为设定阈值作为相似或者不相似的分界。该文设定阈值为0.9,当计算相似度值大于该阈值时认为2个句子相似,否则不相似。从表中可以看到,提出的AT_LSTM算法准确率最高、耗时也较低。

表5 不同算法实验结果对比
4 结束语
利用word2vec深度学习模型对问句中的关键词向量化,使得相近或相关的关键词其空间距离也更接近,能够较好地解决传统文本表示存在的语义不足和维度灾难问题;LSTM神经网络擅长处理时序数据;注意力机制可以更好地提取出句子的语义特征。充分结合word2vec、注意力机制孪生LSTM方法的优势,提出了可以准确、快速计算文本相似度的AT_LSTM模型,并对12306智能问答系统中的FAQ问答集进行了实验,实验结果验证了AT_LSTM模型的有效性。后续可根据12306相关系统的上线要求,对该算法进行进一步改造,并应用于12306智能问答系统。此外,由于知识图谱实体之间具有更丰富的语义关系,如果文本中出现多个特征词通过知识图谱证明它们之间的关系,将会对结果产生很大的影响。所以如何将知识图谱实体之间的关系融合到短文本相似度计算将是下一步工作研究的重点。
猜你喜欢
动漫界·幼教365(大班)(2020年7期)2020-06-26
读者·原创版(2020年2期)2020-02-20
电脑爱好者(2017年5期)2017-05-04
故事会(2016年21期)2016-11-10
爆笑show(2015年12期)2016-01-07
爆笑show(2015年1期)2015-03-26
长江学术(2015年1期)2015-02-27
山东青年(2014年10期)2014-11-24
网友世界(2009年12期)2009-03-05
