
基于文本语义的热点事件网络暴力分析方法
2022-08-02 01:41刘玉文翟菊叶朱文婕
计算机技术与发展 2022年7期
刘玉文,翟菊叶,朱文婕,2,谢 静
(1.蚌埠医学院,安徽 蚌埠 233030; 2.中国科学技术大学 计算机科学与技术学院,安徽 合肥 230027)
0 引 言
随着计算机与通讯技术的快速发展,网络朝着终端移动化、平台多元化、带宽高速化的方向发展[1]。中国互联网络信息中心(CNNIC)发布的第47次《中国互联网络发展状况统计报告》显示:截止2020年12月,中国网民数量为9.89亿,已占全球网民总数的五分之一。网络打破了时间限制,在给人们带来便利的同时,也给网络暴力提供了滋生环境。当前,社会热点事件是诱发网络暴力的主要因素之一,是因为社会热点事件具有突发性和聚焦性,能在短时间内吸引网民聚集,其所产生的网络暴力威力大,不仅会对当事人的心理造成极大的影响,也会极大地破坏网络生态环境,给社会和谐发展带来严峻挑战。所以,热点事件中网络暴力分析对掌握网络暴力内部规律,寻找合适的网络暴力治理策略具有十分重要的意义。
自社交网络诞生之日起,网络暴力就如影随形。为了应对网络暴力带来的威胁与挑战,众多学者从社交网络入手开展了大量的网络舆情治理相关研究,提出了多种网络舆情处理框架,确立了网络话题识别[2]、网络社区检测[3]、意见领袖发现[4]、用户肖像刻画[5]、情感计算[6]等相关核心技术,取得了一系列研究成果。如Chang等[7]提出了一种基于智能语义框架的网络话题识别方法,该方法通过知识框架生成机制从文档中提取规则模式,再通过句法结构和语义关联来有效检测文档主题。Xing等[8]对新媒体环境下负面网络舆情检测指标体系进行研究,提出了基于信息熵的网络舆情检测模型,实现了舆情等级的自动分类。Yang等[9]对情绪因素影响下的突发事件网络舆情演化机理进行研究,把包含情绪函数的RDEU理论引入突发事件网络舆情演化博弈中,构建以网民和政府为代表的动态博弈模型,最后通过假设收益数值实现情绪影响下的演化仿真。
近些年,又有学者依托知识图谱提出了舆情危机治理新思路,实现了舆情感知智能化。如Shen等[10]提出了基于网络新闻语料的公共危机事件知识图谱构建方法,该方法从新闻语料中抽取实体,构建公共危机事件知识图谱模型。实现了实体关系抽取、知识融合、知识加工和知识推理等多项技术的整合。Bao等[11]提出了非结构化语料知识图谱构建方法,该方法运用词法分析和语义技术构建评论文本中实体与实体、实体与属性关系,把非结构化数据映射成知识图谱,实现了文本内容的逻辑表示,解决了网络舆情回溯和推理问题。梁野等[12]提出了一种面向舆情分析与预警领域的跨语言知识图谱架构,完成了涵盖多来源的面向舆情分析与预警领域的跨语言知识图谱构建平台CLOpin,高效地实现了多源数据整合,解决了夸语言舆情分析与预警问题。
从当前研究成果中可以发现,网络舆情治理主要集中在负面舆论分析、舆情知识表示、舆论等级划分、舆情预警等方面,缺少对网络暴力内部数据特征的研究,无法深入了解网络暴力的内容组织关系。针对以上问题,在文本语义和情感词典技术的基础上,该文提出了一种基于文本语义的网络暴力分析方法(TSCA)。该方法从网络暴力数据特征入手,首先根据语境创建网络暴力领域情感词典,实现文本实体情感词汇的识别;然后根据文本分词的位置关系,运用语义规则生成负面情感词组集,并用卡方检验对暴力特征进行筛选;最后通过语义相似度对暴力特征进行计算,从暴力词和用户两个维度实现对网络暴力的多尺度分析。
1 相关技术
1.1 卡方检验
从文本内容的组成结构角度,语义分析包括词语级语义分析、句子级语义分析和文档级语义分析。但不管从哪个层级进行语义分析,首要任务都是解决文本特征的识别问题。文本特征识别是自然语言处理的核心技术,特征识别方法包括文档频率法(document frequency,DF)、信息增益法(information gain,IG)及卡方检验法等。其中,卡方检验法是最常用的文本特征选择方法。
卡方检验[13]主要功能是统计样本的实际观测值与理论推断值之间的相关程度,卡方值越大,则两者相关的可能性就越大,χ2统计量的计算公式如式(1)所示。
χ2(Featurei,Cj)=
(1)
其中,Featurei表示特征,Cj表示特征所属类别;M表示训练集中文本总数,A表示属于Cj类且包含Featurei的文本频数,B表示不属于Cj类但包含Featurei的文本频数,C表示属于Cj类但是不包含Featurei的文本频数,D表示既不属于Cj类也不包含Featurei的文本频数。
1.2 文本情感分析
1997年,MIT媒体实验室Picard教授首次提出情感计算(affective computing,AC)概念[6],目的是通过外部表露出的信息来研究人的内在心理活动。经过20多年的发展,情感分析延伸出了面部情感分析、姿态情感分析、自然语言情感分析、多模态情感计算等多个研究分支,该文研究的文本情感分析属于自然语言情感分析范畴。
当前,网络成为了民众信息交互和观点表达的主要平台,网络上存储了大量的文本数据,隐含着很多有价值信息,对文本进行情感分析能够感知网络舆情态势,了解民众需求,对促进社会管理水平的提高具有十分重要的意义。文本作为自然语言的一种存储形式,最小的语义单位是词,词语级情感分析是最基础的文本语义分析技术,同时也为句子级和文档级情感分析提供了知识支撑。词语级情感分析技术运用情感词典来衡量测试词汇的情感值,并依据语义规则进行情感计算,具体分析流程如图1所示。
从图1中可以看出,计算规则是情感计算的核心,它的主要任务是依据情感词典对新词情感进行量化,量化方式包括互信息计算、相似度对比。
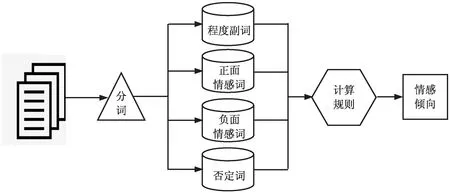
图1 文本情感分析框架
2 基于文本语义的网络暴力分析方法(TSCA)
从本质上说,文本暴力分析是情感分析的一个典型应用。由于热点事件的突发性和聚焦性,网民评论紧紧围绕着热点事件展开,语言相似性大,领域特性强,用经典的情感词典进行语义对比,情感计算结果准确度不高。另外,网络暴力是带有侮辱性的攻击语言,负面情感色彩强烈,但负面情感不一定都是网络暴力,如何从负面情感中筛选出暴力特征是网络暴力分析的关键。所以,在网络暴力分析流程中要解决两个核心问题:(1)暴力领域情感词典建立;(2)基于负面情感特征的网络暴力筛选。
2.1 文本暴力语义规则
情感词典是一种按照文本内词汇之间的逻辑关系搭建起来的知识库,它的建立需要遵循文本语义规则。文本由句子组成,句子又由词组成。词是文本的最小语义单位,但是词在表达语义的时候,由于缺少前缀修饰词,意义表达往往不明确。如果单纯的从词的角度去挖掘暴力信息,挖掘出的信息可能会不准确。比如:“人渣”是个暴力词,但如果语境是“他不是人渣”,在“人渣”的前面有个否定前缀,那整个语义就不具备暴力,所以,在文本暴力挖掘时,往往词组才是具备有效语义的基本单位。
从文学角度来说,词组可分成很多种类型,如:主谓词组(大家帮助);动宾词组(发现问题);介宾词组(把他打死);偏正词组(崇高的理想);否定词组(不喜欢)。从这些词组的语义环境来看,能显著对情感进行修饰或改变的只有偏正词组和否定词组。进一步研究发现,否定词和修饰词的位置在文本语义表示中非常重要,比如,“不很美丽”和“很不美丽”两者意义截然相反。另外,正情感词和负情感词前面加否定词时,语义翻转的程度也不同,如:正情感词“好人”加否定后得“不是好人”,语义翻转到了好人的对立面,即“坏人”;而负情感词“坏人”加否定前缀后的“不是坏人”,语义就不能翻转到“好人”,从语境理解,“不是坏人”只能表明“不坏”,但不能表明是“好”。因此,该文对具有否定的词组结构进行如下规定:
规则1:否定前缀+情感词。
如果正情感词前面有否定前缀,则否定权值为1;若负情感词前面有否定前缀,则否定权值为0.5。
规则2:否定前缀+修饰词。
当情感词前面同时含有否定词和修饰词时,若否定词在修饰词前,则否定权值为0.5;若在修饰词后,则取值为1。
2.2 领域情感词典建立
评论文本是用户发表意见的载体,文本包含用户的情感、态度、行为等特征,文本的情感计算可以转化为对语义词组的情感计算[14]。由于在不同的语境下词汇表达的含义可能会不一样,所以,首先需要依据语义环境创建情感词典,然后,用测试文本的分词与情感词典进行语义对比,得出测试分词的情感值。情感词典由3个数据表组成:情感词表Wc、程度副词表Wv和否定词表Wn。情感词表包含6个属性:前缀否定词ID、前缀副词ID、词项、性质(褒义或贬义)、情感值、位置;程度副词表包含3个属性:词项、强度值和位置;否定词表也包括3个属性:词项、否定值(否定一般设置为-1)和位置。
(1)情感词表创建。
根据当前语料的语义环境,人工筛选出N个核心情感种子词。种子词筛选原则是情感意义非常明确,具有代表性,情感极性最强。首先运用情感种子词建立原始情感词表,然后用循环的方法依次遍历文本分词,当i=1时,把文本di中的新词wi与情感词表中的所有词汇进行语义互信息计算,把互信息最高的词汇情感值作为新词wi的情感值,并填充进情感词表。依次循环,使得每个文本上的分词都会被遍历一次。以下介绍情感词表的扩充方法。
设wn是D中的新词,wi是情感词表Wc内的词项,wn的情感值可以通过与wi的点间互信息计算得到,计算公式如式(2)所示:
(2)
其中,P(wn,wi)表示wn和wi在D中共现的概率,P(wn)和P(wi)分别表示wn和wi单独出现的概率,PMI(wn,wi)的取值范围为[0,1]。如果PMI(wn,wi)>δ(δ表示wn和wi的相似性阈值),则判定wn和wi的语义相同。为了综合判断词汇wn的情感倾向,还需要在情感词表Wc上对wn进行综合考察,设情感词表Wc正面情感词集合为Wcp,负面情感词集合为Wcn,词汇wn的综合值计算公式如式(3)所示:
从公式(3)可以看出,S(wn)的取值范围也是[-1,1],绝对值越大,wn的极性越强。最后判断wn在Wc内是否为新词,如果是新词,则把wn直接加入到Wc中,否则对原有词的情感值进行覆盖。按照上述方法计算D中所有分词,完成对情感词表Wc的扩充。对任意情感词wn,若S(wn)>0,则wn具有正情感倾向;若S(wn)=0,则wn具有中性情感倾向;若S(wn)<0,则wn具有负情感倾向。
(2)程度副词表创建。
程度副词表扩充与情感词表扩充的过程相似,不同之处是程度副词的修饰程度取值范围为[0,1]。为了提高程度副词的扩充精度,根据6级划分理论,按梯度下降公式对每个级别赋予不同的权值,具体创建方式如下:
设wi是程度副词,Wv为程度副词表,为了度量wi的修饰程度,需要在Wv上对wi进行综合计算,如公式(4)所示:
(4)
其中,k表示wv的权值。根据公式(4)的计算结果,首先判断wi在Wv内是否为新词,如果是新词,则把wi直接加入到Wv中;如果不是新词,则对原有词的修饰强度进行覆盖。遍历分词预料库中所有副词完成副词表Wv的扩充。
(3)否定词表创建。
否定词能让情感词的极性发生翻转,如果情感词前有否定词,在情感计算时,根据否定词出现的次数e,用(-1)e乘以情感强度。由于否定词意义明确,其意义表达不依赖于语义环境,通常情况下以“不”、“没”、“未”等字组成,在HowNet词典中收录非常完善,所以,该文借鉴HowNet中的否定词表,以此填充到创建的领域词典内。
2.3 负面情感计算
负面情感词组检测。
网络暴力本质是极端恶劣的负面情感,所以文本暴力分析是情感计算技术的一种具体应用,目标是从负面情感特征中识别出暴力特征,并对暴力特征进行计算。文本是词汇的集合,文本的情感隐含在情感词中,文本情感通过计算文本词汇的综合情感值来实现。为了更清楚地表述词汇语义,特做如下定义:
定义1:语义词组。设五元组W=
语义词组W能够明确描述情感词的语义环境,其情感的计算过程如下:首先,依次遍历文本内情感词,根据文本中第n个分词wn所在的位置读取出前缀词,并与wn连接,组成语义词组W,W的情感值计算如公式(5)所示:
S(W)=N(wn)Adv(wn)S(wn)M(wn)Q(wn)
(5)
其中,N(wn)表示wn的否定词向量权重;Adv(wn)表示wn修饰词向量权重,两个分量可继续分解为公式(6)和公式(7):
N(wn)=(-1)e,e≥0
(6)
(7)
在公式(5)~(7)中,e表示否定词出现的次数,V表示程度副词出现的数量。M(wn)表示否定词的位置,初始值为1;Q(wn)表示情感翻转系数,初始值为1。根据该文定义的语义规则:①若否定词在修饰词前,则M(wn)取值为0.5;若在修饰词后,则取值为1;②当S(wn)>0时,若wn有否定前缀,则Q(wn)取值为1;若S(wn)<0时,则Q(wn)取值为0.5。由公式可以计算出词组W的情感值。如果S(w)的值小于0,则W为负情感词组。
2.4 网络暴力计算
(1)网络暴力词组筛选。
网络暴力作为一种攻击性语言,具有很强的负情感,但负情感特征词不一定都是暴力语言。暴力是负情感的充分条件,负情感是暴力的必要条件。所以网络暴力特征需要从负面情感特征中进一步筛选。χ2检验是常用的文本特征筛选方法,运用χ2检验的网络暴力筛选过程如下:
第①步:从负情感词组集中,用人工的方法标注出负面情感最强烈的20个暴力词组作为种子存放在词向量C中,并设定χ2检验阈值ξ=0.90;
第②步:利用卡方检验对负情感词组进行特征计算,按从大到小顺序,选择χ2(Wi,C)≥ξ的特征词组,添加到C中;
第③步:增加阈值ξ,使得ξ=ξ+0.01,返回到第②步,直到选不出暴力特征词组为止。
通过暴力特征词的筛选能把不具备暴力的负面情感词组过滤掉,大大提高了网络暴力识别精度。从情感计算角度看,网络暴力是负值,取值范围是[-1,0)。为了直观地对网络暴力进行描述,文本对包含网络暴力的负面情感进行翻转计算,把网络暴力取值范围映射到区间(0,1]内,转换后的暴力词组计算公式如式(8)所示:
Cyber(W)=-N(wn)Adv(wn)S(wn)M(wn)Q(wn)
(8)
定义2:暴力密度。设词组集WS={W1,W2,…,WK},暴力语义词组集WC={Wc1,Wc2,…,WcK},且WC⊆ WS,则WS的暴力密度计算公式如式(9)所示:
(9)
(2)文本暴力计算。
文本是单词的有序集合,即:di={w1,w2,…,wN}。但从词组的角度看,文本又可表示成多个语义词组的顺序排列,即:di={W1,W2,…,WK},且{W1∪W2∪…∪WK}={w1,w2,…,wN}。所以,基于词组的文本暴力计算公式如式(10)所示:
(10)
其中,C表示暴力词组向量。然后对所有文本的暴力值进行归一化处理,计算公式如式(11)所示:

(11)
其中,Cybermax(di)表示文本暴力的最大值,Cybermin(di)表示文本暴力的最小值。
(3)用户暴力计算。
用户暴力是用户所发表评论文本的暴力之和,所以,对于用户ui,其暴力计算公式如式(12)所示:
(12)
其中,|Di|表示用户ui发表的评论文本数量。对用户暴力进行归一化处理,计算公式如式(13)所示:
(13)
其中,Cybermax(ui)表示用户暴力的最大值,Cybermin(ui)表示用户暴力的最小值。
3 实验分析
3.1 数据来源及预处理
以“合肥母子三人跳楼事件”为例,使用八爪鱼数据采集器获取了腾讯新闻中该主题下的评论信息:用户节点1 052个,评论文本3 128条。首先抽取用户之间的“回复、点赞”关系,建立用户关系库U,然后使用ICTCLAS分词软件对评论文本进行分词,去除停用词、介词、语气词、转折词等无用词后,建立文本语料矩阵G。
U的大小为|U|×4,其中,第i行存放第i个用户ui的相关信息,存放顺序是:第1列存放ui的序号,第2列存放ui的ID,第3列存放ui回复的用户ID串,第4列存放ui点赞的用户ID串。G的大小为|G|×[2+N+3],其中,第i行存放第i条评论文本di的相关信息,存放顺序是:第1列存放di的序号;第2列存放发表di的用户ID,后N列存放di的分词结果。初始语料矩阵准备完毕之后,运用该文提出的方法对语料信息进行处理分析。
3.2 实验结果分析
(1)暴力词语义分析。
在语料矩阵G的基础上,按照文本暴力分析路线,首先创建领域情感词典S,生成负面情感词组集N,再通过卡方检验筛选出暴力词组集C。组成暴力词组集的高频基础情感词及情感值计算结果如表1所示。
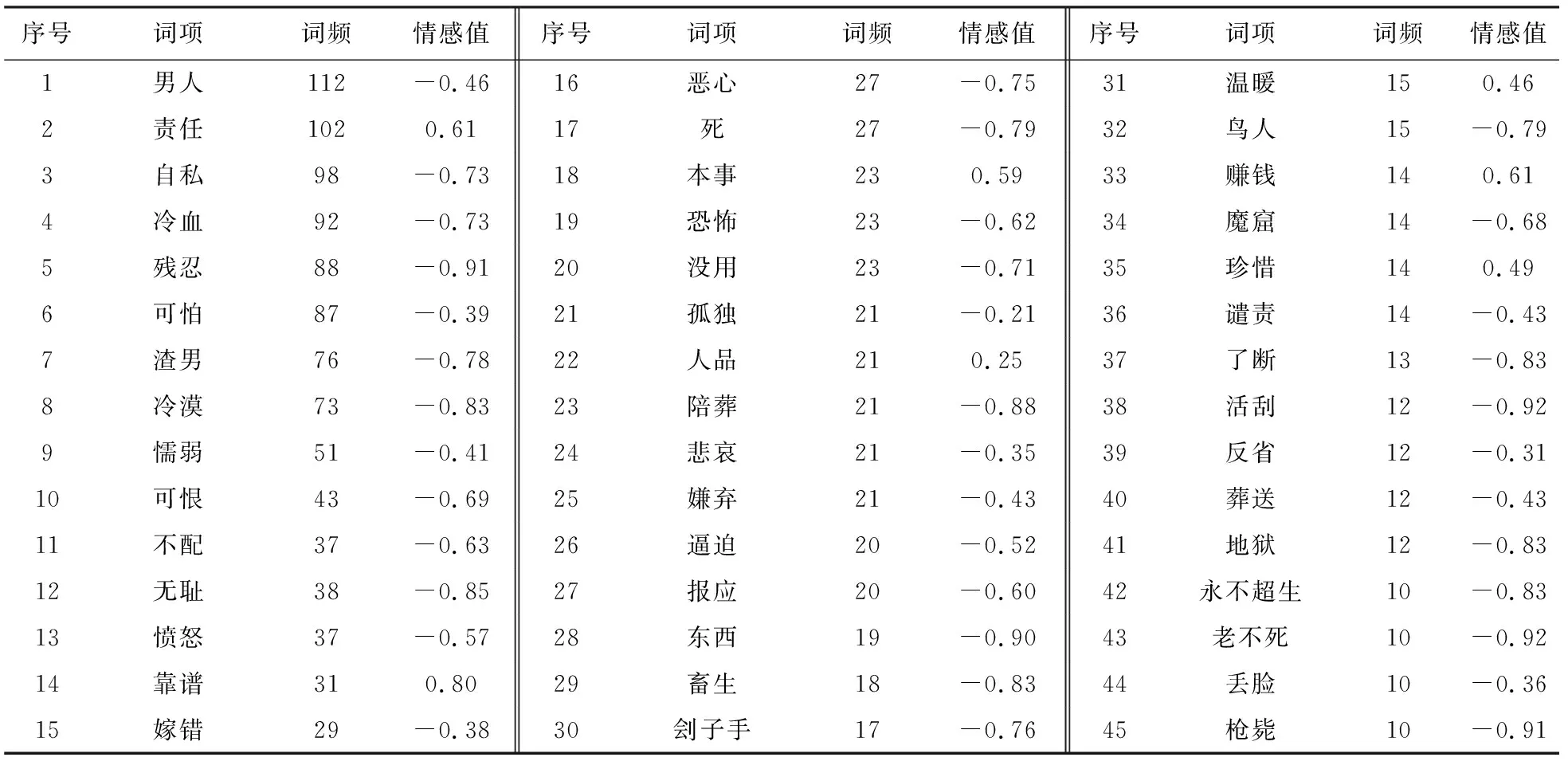
表1 事件评论网络暴力高频词列表(Top 45)
(2)暴力多尺度分析。
为了反映暴力特征词之间意义分布形态,对45个暴力特征词进行多维尺度统计分析。根据暴力特征词两两之间共现频数,得到大小为45×45的暴力特征词共现矩阵。由于频次的范围变化大,数据分析不方便,为了消除词频计数对分析的影响,用Ochiia系数将共词矩阵转换为相关矩阵,并对共现频次进行归一化处理,再根据词与词之间的共现关系,建立两词之间的相异矩阵,计算公式如式(14)所示:
(14)
为了便于理解,用“1”与矩阵相减,得到表示两词建相异程度的相异矩阵,转换结果如表2所示。
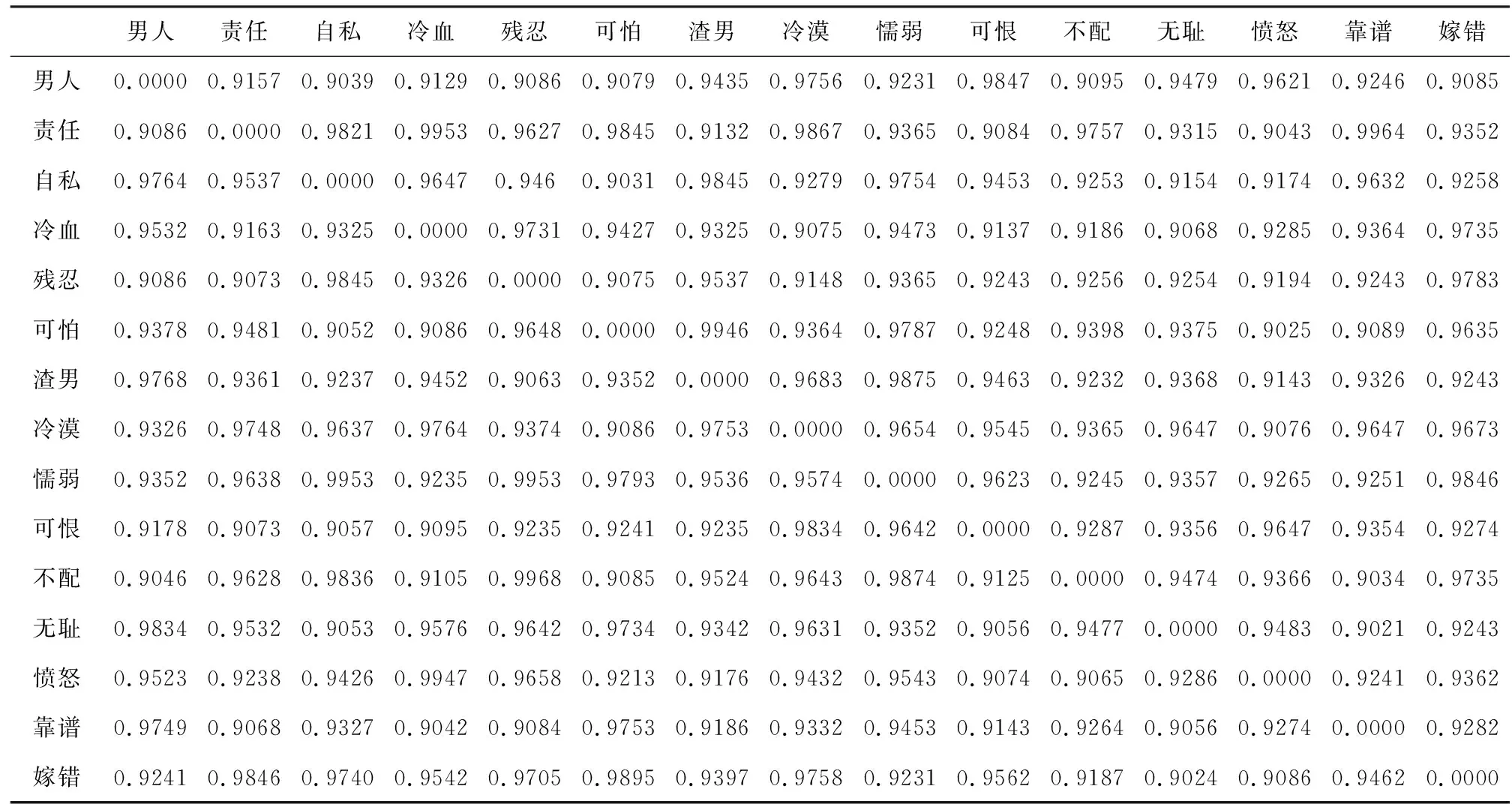
表2 Ochiia相异矩阵
把相异矩阵数据输入到SPSS软件中,选择二维分析组图输出方式,对其进行Euclidean距离分析,分析结果如图2所示。图中点与点之间的距离表示词汇所属内容主题的相关程度,距离越小表明主题语义相似度越大,主题内容越集中;反之,距离越远表明表达内容越独立。
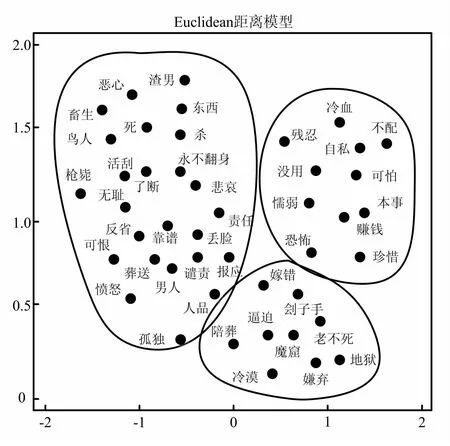
图2 暴力词汇多尺度分析结果
从图2显示的分析结果来看,词汇之间既有渗透交叉,又有群组分布的独立性,说明词汇语义反映出了明显的主题差异性。从词汇表达的内容角度出发,人工对词汇进行主题分组,根据划分边界大致可分成三个群组,每个群组代表一个被网络暴力攻击的实体对象,分别为:跳楼女子(以下简称“女方”)、女子丈夫(以下简称“男方”)、女子所处的家庭环境(以下简称“家庭”)。按照分组结果,对语料中每个群组词及群组内暴力词进行统计,结果如图3所示。
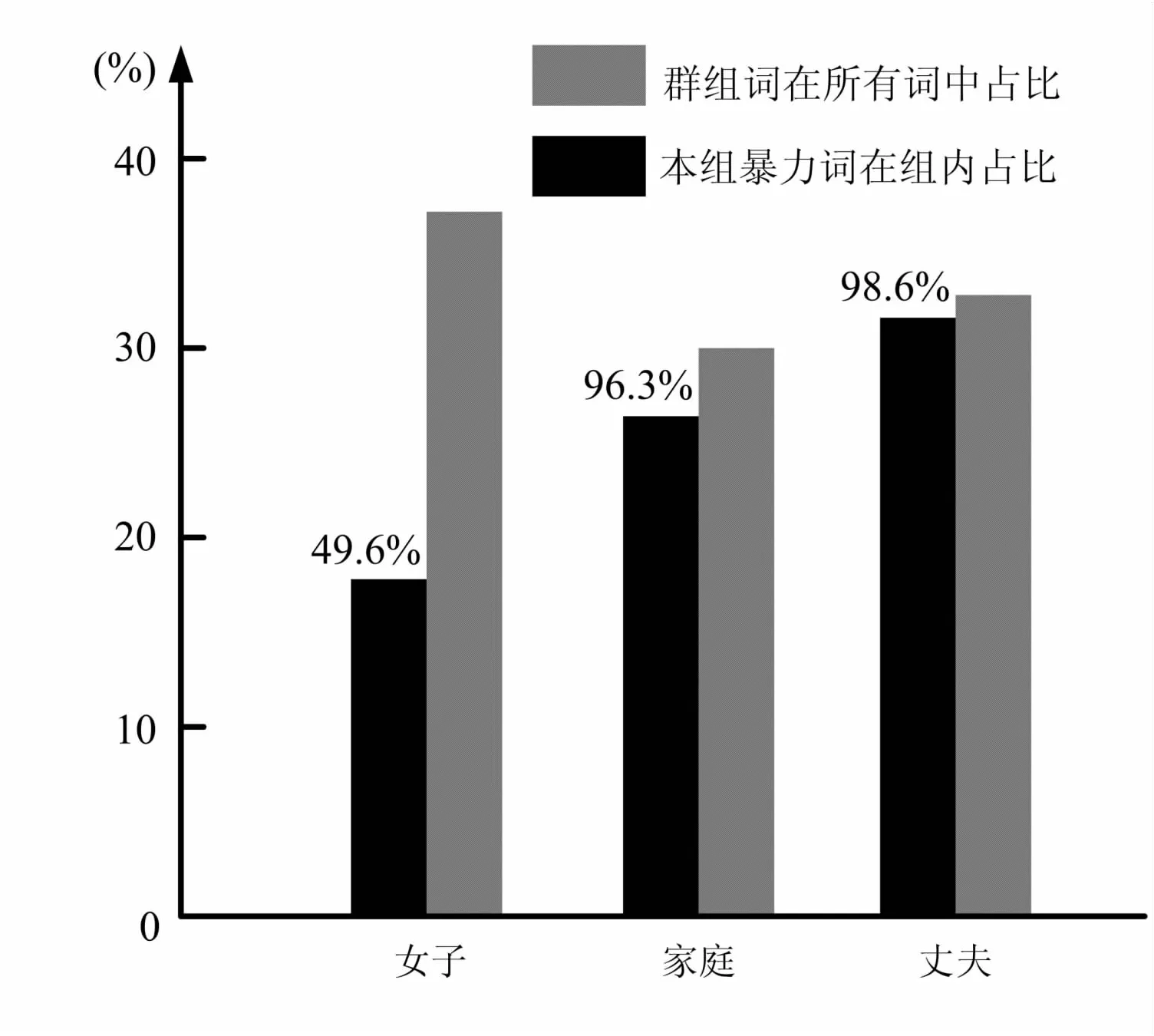
图3 各群组暴力词占比
从图3可以看出,在所有语料词组中,女方群组词数量的占比为38.2%,家庭群组词占比为29.7%,丈夫群组词占比为32.1%。网民针对女方发表的网络评论最多,也从侧面反映出了女方在事件中的主体地位。但从暴力词汇在群组内的占比来看,针对丈夫的暴力词占比最高,达到98.6%,其次针对家庭的暴力词占比为96.3%,说明网友的暴力攻击点主要集中在男方和家庭,而针对女子的暴力词占比也有49.6%,说明了虽然在整个事件中女方是受害者,但女方绑架子女生命的赴死方式也遭到了众多网友的鄙视。
为了度量不同群组遭受的暴力,运用公式(9)对每个群组的暴力密度进行计算,了解不同对象遭受暴力的强度,三个群组的暴力密度计算结果如图4所示。
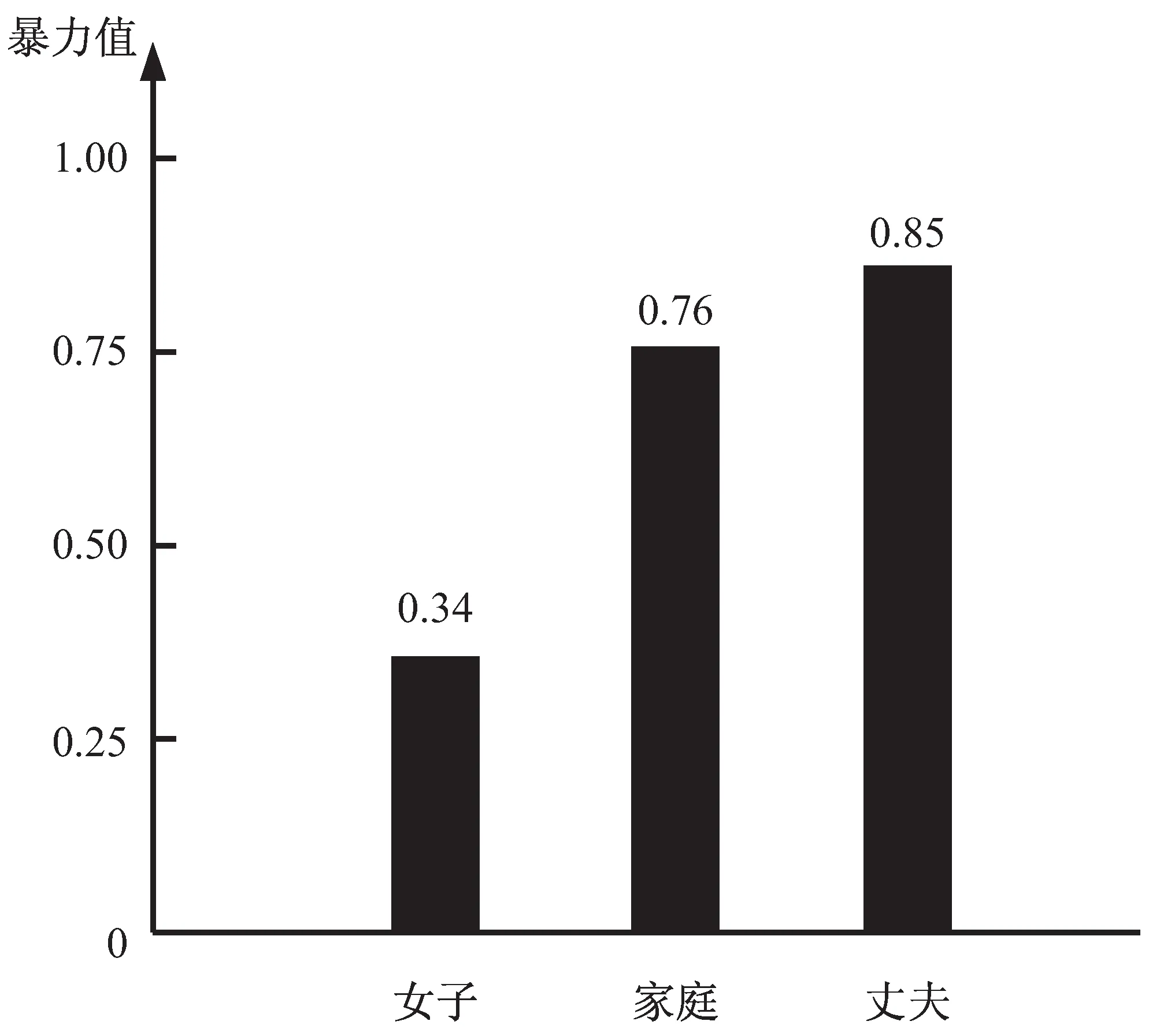
图4 三个群组网络暴力密度对比
通过群组词汇量整体占比、暴力词在群组内占比以及群组词汇的暴力密度等信息,可以对不同对象所遭受的网络暴力做如下分析。
①对男方的暴力攻击分析:通过图3和图4可知,攻击男方的暴力特征词占比最大, 暴力密度也最高。
说明事件中女子的丈夫是被网民攻击的主要对象。从评论文本中可以看出,网民一致认为他是促使妻子跳楼的最直接元凶,评论用词激烈极端,遭受的网络暴力最强。
②对家庭的暴力攻击分析:从暴力词占比以及暴力密度对比结果来看,网民另一个攻击对象是女子所处的家庭环境。通过对原始语料分析可知,女子独自带孩子,孩子身体不好,丈夫不仅不给生活费,还遭受公婆嫌弃,引起了网民的极大愤恨和道德谴责。
③对女方的暴力攻击:虽然女方是受害方,本应该受到网民同情,但她以极端的方式剥夺了孩子的生命,从性质上来说,她也是杀人犯,展现出了她可怕、冷血的一面;另外也突出了她自私,懦弱的性格特征。网民在同情女子遭受不幸的过程中,同样也对她进行了指责。
(3)暴力用户分析。
用户是网络暴力的发起者,对用户暴力进行分析有助于掌握网络暴力实施的人群分布。具体分析过程是:首先遍历语料数据库G,以用户为单位检索出用户发表的评论文本分词,并与暴力词组集C对照匹配,找出用户的暴力词组;再根据公式(10)和(11)计算用户文本的暴力值,然后再用公式(12)和(13)计算出用户的暴力值;最后把用户暴力词组分别与三个群组暴力词组进行相似度对比,识别出用户暴力攻击的目标,计算结果如表3所示。
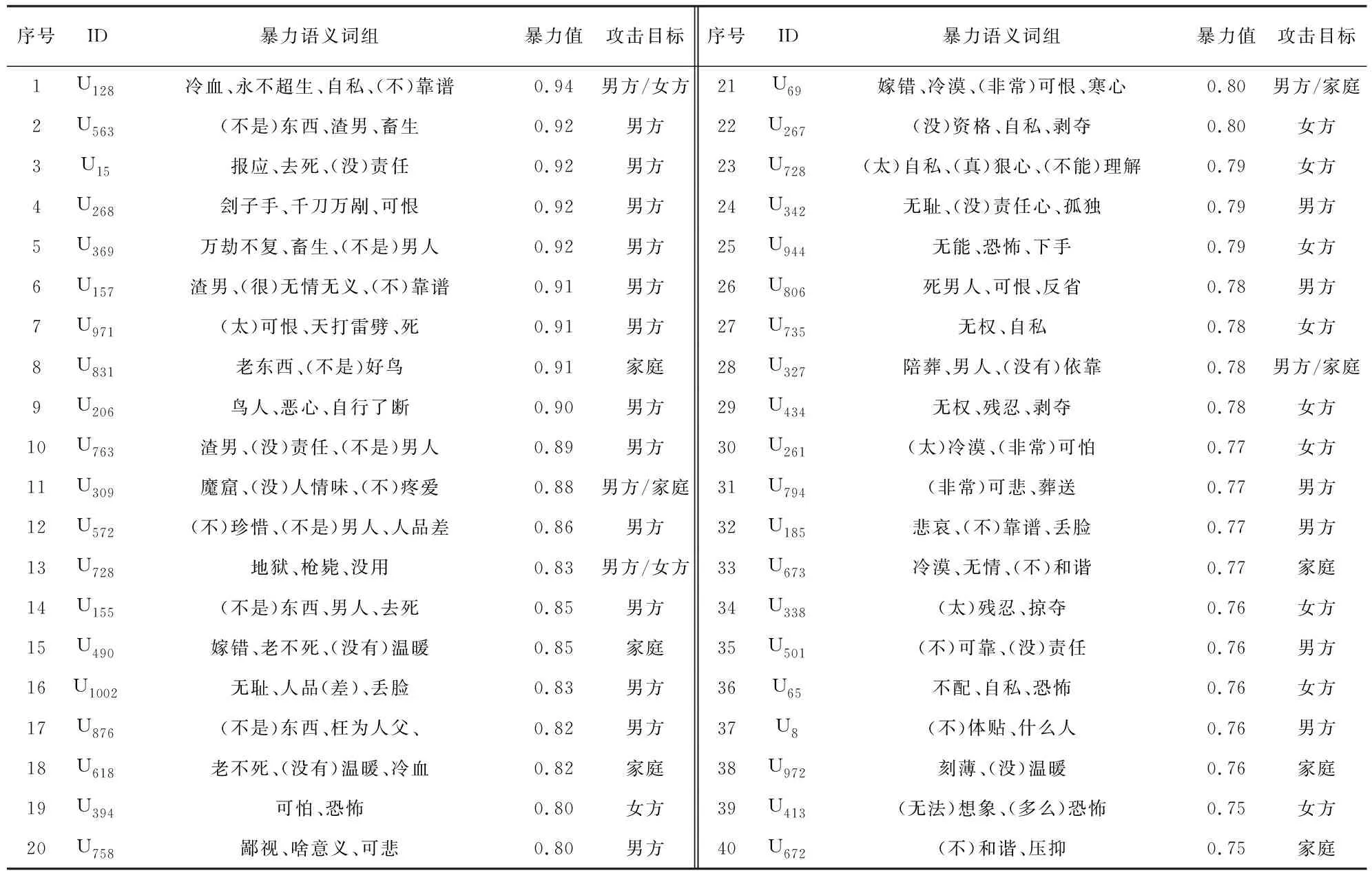
表3 暴力用户信息表(暴力值Top 40)
3.3 性能评价
暴力特征词组的筛选是该文的核心,为了验证该方法的暴力特征识别效果,对实验语料中的负面情感词组和暴力特征词组进行人工标注,并把原始语料库分成5个数据集,分别用TSCA和FWCC[15]方法对数据集的暴力特征进行提取。为了提高人工标注的可信度和准确性,采用三组标注法,以高分表决的方式标注语料中的暴力特征词组,两种方法的评价对比结果如表4所示。
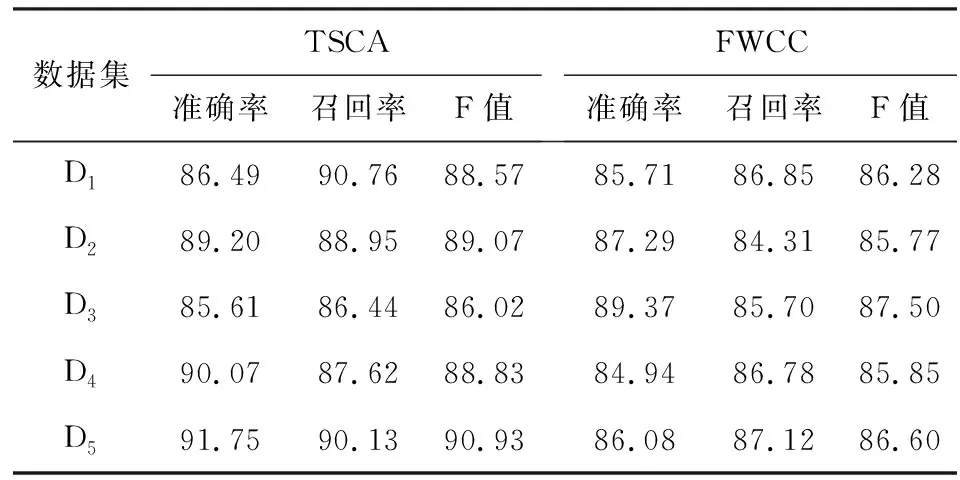
表4 暴力特征识别性能对比 %
从表4可以看出,在五组语料数据集上,TSCA方法的暴力特征词组识别性能(F值)高于FWCC方法,说明TSCA方法达到了良好的文本暴力特征识别效果。
4 结束语
运用信息熵理论建立了网络暴力领域情感词典,并以领域情感词典为基础,结合词法分析技术建立了基于文本语义的网络暴力分析方法。该方法能从暴力词和用户两个维度度量热点话题下的网络暴力信息,拓展了网络暴力识别与分析方法。经过实验,该方法在多维网络暴力分析方面达到了良好的效果。由于该方法中暴力阈值的设定是人工实现的,存在一定的局限性。如何实现阈值的自动划分是未来需要进一步研究的方向。
猜你喜欢
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
长江学术(2015年1期)2015-02-27
高中生学习·高三版(2014年3期)2014-04-29
教学与管理(理论版)(2009年9期)2009-11-04
