
基于积分损失的对抗样本生成算法
2022-08-02 01:43章进,李琦
计算机技术与发展 2022年7期
章 进,李 琦
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
目前,深度学习在许多领域取得了迅猛的发展。例如:机器视觉[1-2]、语音识别[3]、自然语言处理[4]、恶意软件检测[5]等,甚至一度超过了人类的水平。但是神经网络与其他系统一样存在安全性和鲁棒性的问题。通过添加一些精心设计的噪声到图片上,可以使得深度神经网络给出置信度非常高的错误的预测,然而这些噪声对于人类来说是不可见的。添加了这些噪声的图片就称之为对抗样本[6],对应的攻击称之为对抗攻击。在实际生活中,深度学习的部署需要较高的安全性,例如人脸识别[7]、自动驾驶[8-9]等,因此研究强有力的对抗攻击算法,对于理解深度网络内在的脆弱性,进一步提升模型的鲁棒性和安全性就变得非常有意义。
在探索深度学习可解释性的过程中,Christian Szegedy等人[6]提出了对抗样本(adversarial examples)的概念,即在数据集中通过添加细微的扰动所形成的输入样本,将导致模型以高置信度给出一个错误的输出。他们发现许多深度学习模型,包括卷积神经网络(convolutional neural network,CNN)对于对抗样本都具有极高的脆弱性。同时,对抗样本具有迁移性,很多情况下,在训练集的不同子集上训练得到的网络架构不同的模型都会对同一个对抗样本做出错误的分类。根据目标模型的架构和参数是否已知可以将对抗攻击分为:白盒攻击和黑盒攻击。最近几年,有许多的攻击算法相继提出,其中主要的是基于梯度的攻击算法。这些算法可以被进一步地划分为单步的和多步的。Goodfellow等人[10]指出神经网络对对抗样本表现脆弱性的原因是神经网络的线性性,与早期所认为的非线性和过拟合有所不同,并提出了一种快速生成对抗样本的方法(fast gradient sign method,FGSM),这个算法是单步的并且具有较高的迁移性。Kurakin等人[11]将FGSM进一步改进,提出了多步的迭代版本的FGSM(iterative fast gradient sign method,I-FGSM),这个算法进一步提升了白盒攻击的成功率,但是对于目标模型产生了过拟合,迁移性较差。为了进一步提升攻击成功率和迁移性,Dong等人[12]将动量引入到I-FGSM,提出了(momentum iterative fast gradient sign method,MI-FGSM)算法。该算法可以有效避免震荡,稳定对抗样本更新方向,加速逼近最优值。之后,Jiadong Lin等人[13]认为MI-FGSM算法使得梯度不断累积,无限制加速,可能会错过最优值,将Nesterov集成到了MI-FGSM,提出了(Nesterov-momentum iterative fast gradient sign method,NI-FGSM)算法。该算法在每次对抗样本更新的时候粗略地估算下一次的位置,达到及时减速的目的,来避免梯度更新的太快。
由于之前的对抗样本生成算法可能会陷入局部最优值的情况,需要一种方法来有效地评估样本的梯度。Sundararajan等人[14]认为对于非线性深度网络,输入对于输出的梯度很容易饱和,导致一个重要的输入可能会有一个很小的梯度,并提出积分梯度(integrated gradients)这一算法。该算法通过在数据点周围间隔小范围的均匀采样,并对这些采样的数据进行梯度计算,最后将这些梯度进行累加,用来表示当前样本的梯度。用这个集成的梯度更好地捕获了输入对于输出的重要性。受到这种方法的启发,该文将间隔小范围的均匀采样变为按照间隔指数增长范围进行采样,从而避免采样次数过多所带来的计算消耗和大量无用的相似样本采样。同时,将采样的样本用于损失函数的计算,这样做不仅考虑了原始样本的损失同样考虑了当前样本线性比例上的损失,可以看作是在当前样本上的损失的一个集成,将其称之为积分损失(integrated loss)。在此基础上提出了积分损失快速梯度符号法(integrated loss fast gradient sign method,IL-FGSM)。该算法利用积分损失作为优化的目标函数,一定程度上避免了梯度饱和的情况,从而更好地达到全局最优值。实验结果表明,IL-FGSM效果较好,相比于基线方法提升了10%~20%的攻击成功率。
1 相关知识
1.1 符号说明
神经网络是一个函数F(x)=y,接受一个输入x∈Rn,产生一个输出y∈Rm。模型F也隐式地包含一些模型参数θ。该文重点研究了用作m类分类器的神经网络。使用softmax函数计算网络的输出,该函数确保输出向量y满足0≤yi≤1,y1+…+ym=1。因此,输出向量y被视为概率分布,即yi被视为输入x具有类别i的概率。分类器将C(x)=argmaxF(x)i作为输入x的标签。设C*(x)为x的正确标签。softmax函数的输入称为logits。定义F为包含softmax函数的全连接神经网络,Z(x)=z为除了softmax之外的所有层的输出,所以z为softmax的输入,即logits,则:
F(x)=softmax(Z(x))=y
1.2 对抗样本
Szegedy等人[6]首先指出了对抗样本的存在:给定有效的输入x和目标t≠C*(x),通常可以找到类似的输入x',使得C(x')=t,但x,x'根据某种距离度量是接近的。样本x'具有这个属性被称为有目标的对抗样本。相反是无目标的对抗样本,只寻找输入x',满足C(x')≠C(x),并且x,x'很接近,而不是将x分类为给定的目标类别。因此,无目标攻击比起有目标攻击实施起来更加容易。
2 白盒攻击算法
研究者们提出了许多的方法来生成对抗样本,这里进行一个简要的介绍。
2.1 I-FGSM & PGD
由于FGSM是在梯度的符号方向上进行一次的单个步长ε的扰动,更新生成的对抗样本扰动强度较大,Kurakin等人[11]提出了基础迭代法I-FGSM。该算法采用多个较小的步长α更新优化扰动强度,同时将结果裁剪到约束范围ε,产生的对抗样本攻击能力更强。

Madry等人[15]提出了梯度投影下降方法(projected gradient descent,PGD),一个更强的FGSM方法的变种,主要思想是在更新对抗样本前,使用一个随机的起点作为对抗样本的初始值。
2.2 MI-FGSM & NI-FGSM
为了解决I-FGSM的迁移性较差的问题,Yong等人[12]提出了动量迭代快速梯度符号法(MI-FGSM)。该方法将动量项加入到攻击的过程中,来稳定的更新方向,避免了迭代过程中可能出现的梯度更新震荡和落入较差的局部最优值。更新步骤类似于I-FGSM,替换的公式如下:
其中,μ是动量项衰减因子,通常设置为1;g0=0,gn是第n次的搜集的梯度。
Lin等人[13]利用Nesterov来加速梯度下降并稳定梯度更新方向,在每次计算梯度前,提前使用下一次的对抗样本作为当前对抗样本,提出了NI-FGSM算法,公式如下:
2.3 DIM & TIM
Xie等人[16]将输入多样性加入对抗样本的生成过程,进一步改善了对抗样本的迁移性,提出了DIM(diverse input method)算法。DIM的更新步骤和I-FGSM相似,具有如下的替换:
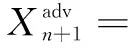
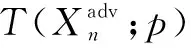
其中,p是概率值,表示有p的概率使用这个随机变换函数,p的概率保持原始的输入。这样做的目的是为了在不减少白盒攻击成功率的情况下,进一步提升黑盒攻击的成功率。通常设置p=0.5。
他们又将DIM和MI-FGSM整合到一起提出了M-DI2-FGSM,直觉上,动量和多样性输入是两个完全不同的方式来缓解过拟合的现象,通过将它们自然地结合到一起形成一个更强的攻击。总体上的更新过程和MI-FGSM相似,其中梯度的更新替换如下:
由于DIM是在单个样本上进行的优化扰动,Dong等人[17]在计算当前对抗样本时,对该样本进行一系列的图像变换操作,形成一个表示当前对抗样本的集合,用该集合来优化对抗扰动,由于计算效率的原因,他们进一步提出了TIM(translation-invariant method)。具体的,通过将没有变换的原始图片和一个内核矩阵(通常为高斯核)进行卷积操作,对梯度进行高斯模糊,以此来增加对抗样本的鲁棒性。DIM和TIM都是增加对抗样本迁移性的方法,通过将这两个方法结合到一起是目前有效的增加对抗样本迁移性的方法。
3 IL-FGSM & ENS-IL-FGSM
这里首先介绍积分梯度的概念,然后给出所提方法IL-FGSM的定义。
3.1 Integrated Gradients
为了有效评估模型输入对于输出的梯度,Sundararajan等人[14]提出了积分梯度(integrated gradients)这一算法。该算法初始时输入一个零排列的矩阵,随后让输入数据逐步向测试的目标数据转变,以此通过模型输出的变化反过来研究输入对于输出的影响,有效估计了模型输入对于输出的影响程度,一定程度上避免了输入对于输出的过饱和情况。具体的公式如下:
Xbaseline在他们的设置中,对于图片是纯黑的图片,对于文本数据是全为零的嵌入向量。s是估计X的积分梯度需要计算的采样总数。
3.2 IL-FGSM
基于积分梯度算法,提出了积分损失快速梯度符号法IL-FGSM。该算法将积分损失(integrated loss)作为它的损失函数,替换了原本的对抗样本生成算法中的单一的损失,一定程度上避免由单一损失计算出来的梯度出现饱和的现象,更容易地估算出当前样本对于模型输出的梯度,从而更好地达到全局最优值。
具体的,在每次的迭代过程中,IL-FGSM依靠当前样本的积分损失来更新输入的图片:

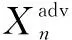
3.3 ENS-IL-FGSM
同时攻击多个模型,称为集成攻击。与攻击单个模型相比,同时攻击多个模型,可以显著提高对抗样本的迁移性。集成攻击的思想十分直观,如果一个对抗样本能同时攻击多个模型,那么它很可能对其他模型仍具有攻击性。
采用攻击多个模型的logits集成,由于logits捕捉概率预测之间的对数关系,因此由logits融合的模型集合汇集了所有模型的精细细节输出,这些模型的脆弱性很容易被发现。具体的,攻击K个模型:

L(X,y;θ)=-1y·log(softmax(Z(x)))
其中,-1y是标签y的one-hot编码的向量。将攻击多个模型的策略集成到提出的方法IL-FGSM,并命名为ENS-IL-FGSM(ensemble integrated loss fast gradient sign method)。相较于IL-FGSM,ENS-IL-FGSM具有如下的替换:

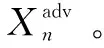
4 实 验
通过实验来证明所提IL-FGSM方法和ENS-IL-FGSM的优势。首先,提供了实验的相关设置,然后,比较了积分损失的采样策略,接着,分析了积分损失的采样次数问题。之后,将该方法和几个基线方法在常规训练和对抗训练的模型上进行了比较。最后,将增加对抗样本迁移性的方法与该方法结合起来,与基线方法进行了进一步的比较。
4.1 设 置
数据集:攻击一个不能将原始的图片正确分类的分类器是没有意义的,所以随机选择了ILSVRC2012验证集上的1 000张属于1 000个类别的图片,这些图片都可以被本实验的所有分类器正确分类。
网络:考虑了7个模型,其中4个是常规训练的模型:Inception-v3(Inc-v3)[19],Inception-v4(Inc-v4),Inception-Resnet-v2(IncRes-v2)[20]和Resnet-v2-101(Res-101)[21],3个是对抗训练的模型:Inc-v3-ens3,Inc-v3-ens4和IncRes-v3-ens[22]。
超参数:对于网络的超参数,与Dong等人[12]的设置相同,最大的扰动ε=16,迭代次数T=10,步长α=1.6。对于MI-FGSM,采用默认的衰减参数μ=1.0。对于DI-FGSM,变换概率p=0.5。对于TIM,采用高斯核,内核大小设置为7×7。
4.2 均匀采样OR指数采样
在计算Integrated Loss的过程中,对于同一个样本计算其IL损失,可以分为两种方式:均匀采样和指数采样。均匀采样指的是将样本在全为零的黑色的图片到该样本空间等比例的进行样本的损失计算然后集成。指数采样指的是将样本在全为零的黑色的图片到该样本空间进行间隔指数比例的样本损失计算然后集成。
将IL-FGSM分别在这两种采样策略下进行了比较。具体的,使用IL-FGSM在这两种策略下,设置采样次数都为5,攻击常规训练的模型,这些模型包括(Inc-v3,Inc-v4,IncRes-v2和Res-101)。如表 1所示,可以看出均匀采样和指数采样几乎具有相同的攻击用时,但是指数采样的攻击成功率平均要比均匀采样高出5%~10%。因为均匀采样,每次采样间隔的距离较近,导致了大量相似样本的计算,所以攻击成功率偏低。因此,综合攻击用时和攻击成功率,选择指数采样作为计算Integrated Loss的一种采样策略。
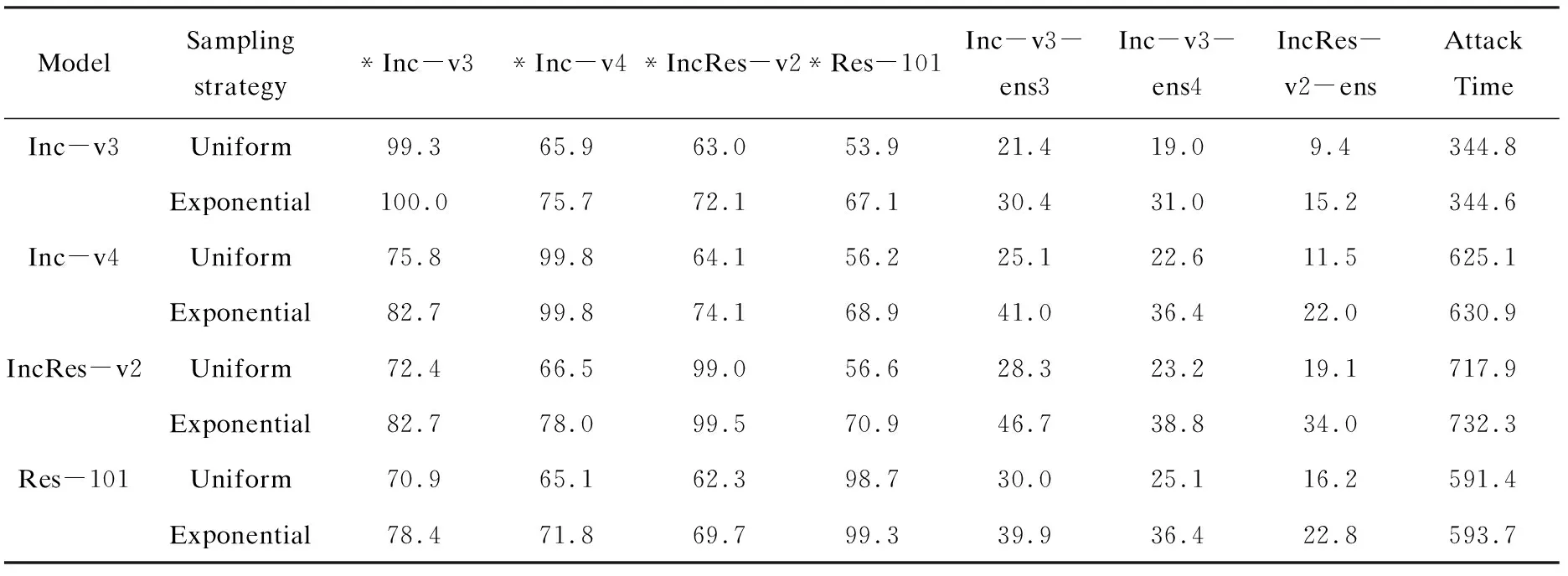
表1 单个模型设置下,使用均匀采样和指数采样攻击七个模型的攻击成功率(*表示白盒攻击) %
4.3 采样次数
合理的采样次数可以提供更好的梯度方向并且使计算变得更加高效。因此,研究了不同采样次数s的影响。使用Inc-v3生成对抗样本攻击Inc-v3,Inc-v4,IncRes-v2,Res-101,使用的采样次数从1到8。图 1显示了不同采样次数的攻击成功率,可以看出攻击成功率随着采样次数的增加而不断改善,在采样次数为5时,所有模型都获得了较高的成功率,5之后攻击成功率上升的相对平缓,所以综合计算消耗和攻击成功率的影响,选择采样次数为5。
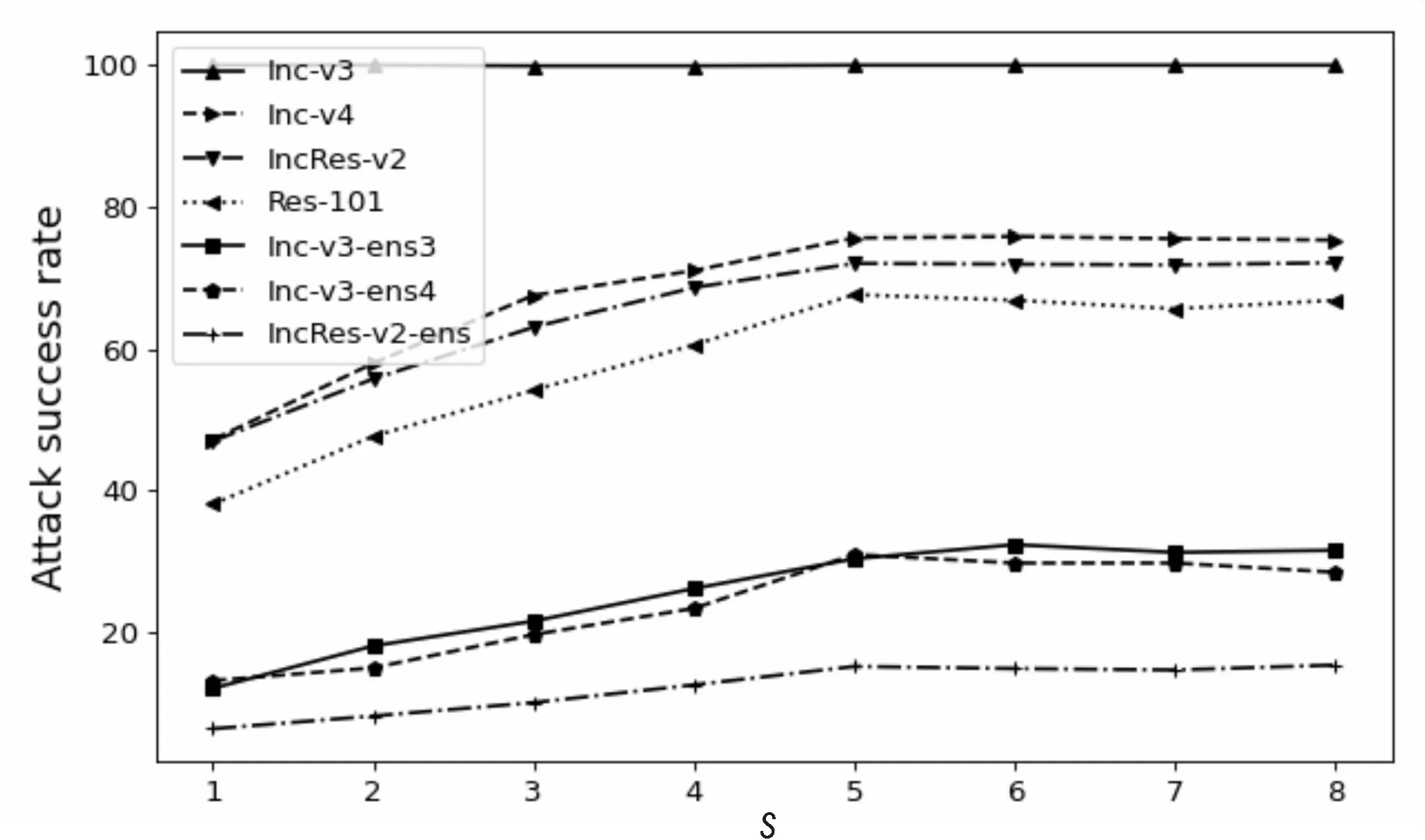
图1 不同采样次数的攻击成功率
4.4 攻击单个模型
在这个部分,将IL-FGSM和其他的黑盒攻击方法(I-FGSM,MI-FGSM,NI-FGSM)进行比较,攻击单个模型。如表2所示,文中方法改善了所有的基线方法的攻击成功率。一般的,IL-FGSM和其他基线方法一样都具有几乎100%的白盒攻击成功率,在黑盒攻击上,文中方法超过了基线攻击10%~20%。表明这些高级的对抗训练的模型在黑盒攻击IL-FGSM攻击下只是提供了微弱的防护。同样的可以观看到,使用的白盒模型的结构越复杂,生成的对抗样本的迁移性越好。
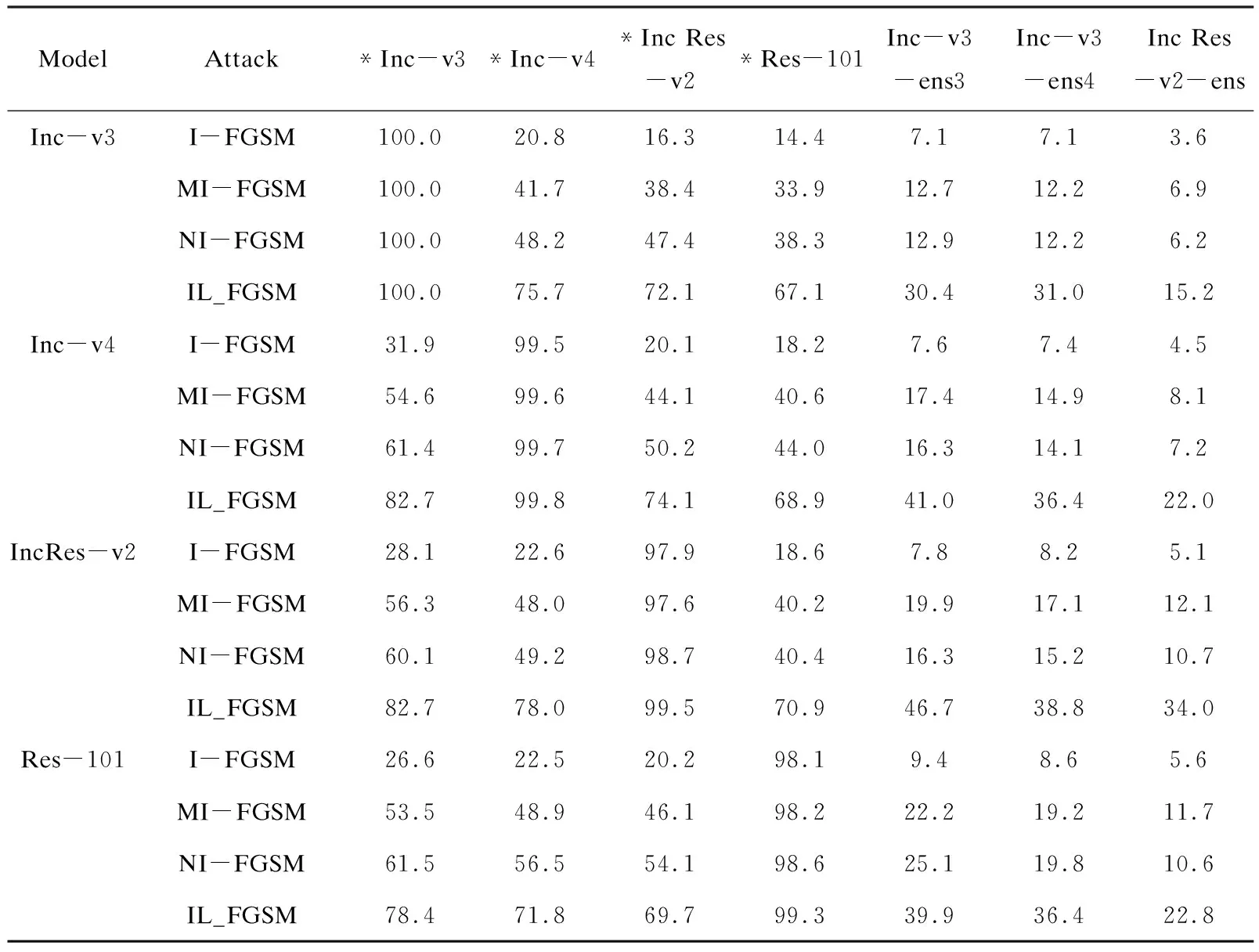
表2 单个模型设置下,攻击七个模型的攻击成功率(*表示白盒攻击) %
4.5 攻击集成模型
集成方法在研究中被广泛地采用来增加模型的表现和鲁棒性。集成的思想同样也可以用到对抗攻击上,因为如果一个对抗样本对于多个模型都是对抗的,那么它很有可能捕获到了内在的对抗方向,并且更容易在同一时间迁移到其他模型上,从而进一步提升黑盒的攻击成功率。目前,有三个常用的集成策略:logits集成、预测集成、损失集成,其中logits集成被认为是有效的集成策略。
考虑用IL-FGSM的集成模型算法ENS-IL-FGSM同时攻击多个模型在logits上的集成。具体的,使用(FGSM,MI-FGSM,NI-FGSM,ENS-IL-FGSM)攻击常规训练的模型集合,这些模型包括(Inc-v3,Inc-v4,IncRes-v2和Res-101),并将它们的权重设置为相等的。
如表3所示,与攻击单个模型相比,攻击集成的模型,在保持白盒攻击成功率的情况下,明显改善了黑盒攻击的成功率,并且文中方法在保持较高的白盒攻击的同时,在黑盒攻击上超过了基线攻击10%~20%。表明这些高级的对抗训练的模型在黑盒攻击ENS-IL-FGSM的攻击下只是提供了微弱的防护。
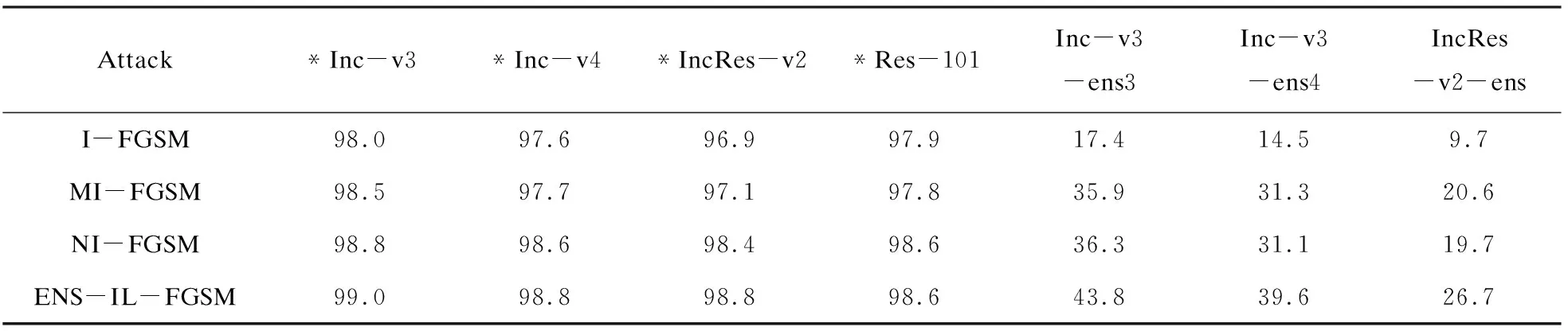
表3 集成模型设置下,攻击七个模型的攻击成功率(*表示白盒攻击) %
为了进一步提升IL-FGSM的黑盒攻击成功率,将改善样本迁移性的方法DIM和TIM集成到文中方法中。具体的,将它们与FGSM,MI-FGSM,NI-FGSM,IL-FGSM进行了集成,并进行了进一步的比较。如表4所示,IL-FGSM集成了DIM和TIM,在保持较高白盒攻击成功率的同时,在黑盒攻击上达到了70%~85%的攻击成功率,这个效果堪比白盒攻击。
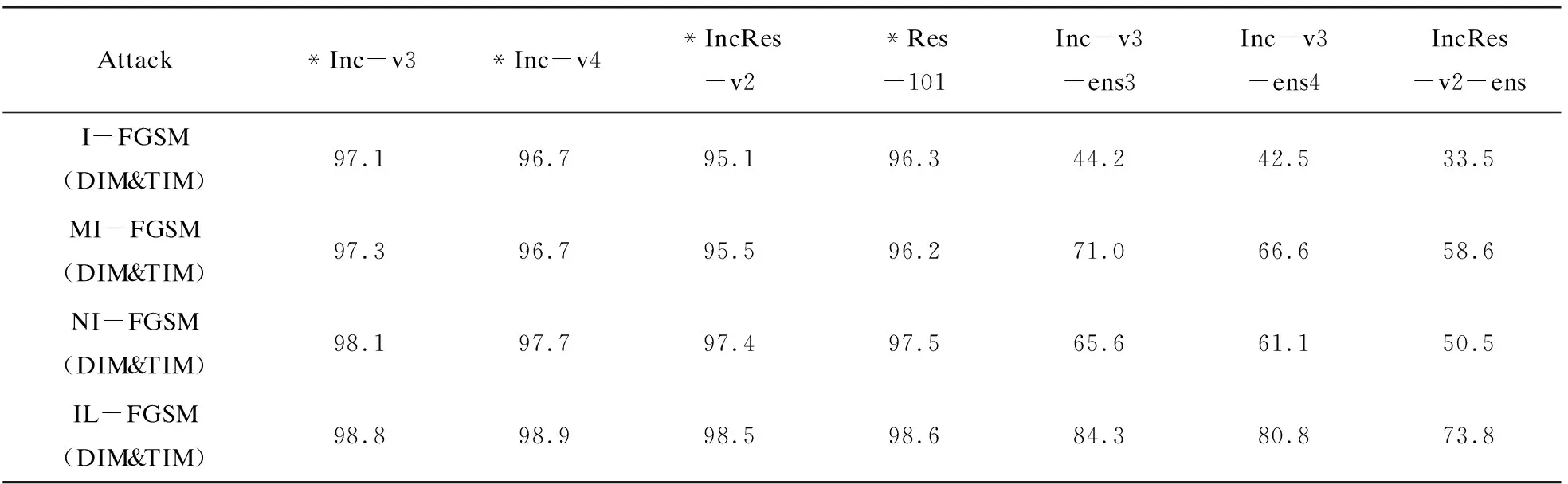
表4 集成模型设置下,集成DIM和TIM方法,攻击七个模型的攻击成功率(*表示白盒攻击) %
4.6 攻击用时分析
衡量一个对抗样本生成算法的好坏,不仅要考虑这个算法的攻击成功率,还要考虑这个算法的时间复杂度,也就是攻击所用时间。在这个部分,将IL-FGSM和其他的黑盒攻击方法(I-FGSM,MI-FGSM,NI-FGSM)在攻击用时方面进行比较。如表5所示,IL-FGSM在攻击用时方面比其他基线方法平均多出4倍的用时。因为IL-FGSM使用Integrated Loss作为它的损失函数,相比于其他基线方法,对于每一个样本只计算了一次损失,IL-FGSM计算了这个样本的线性比例损失的集成,所以相对的用时较多。
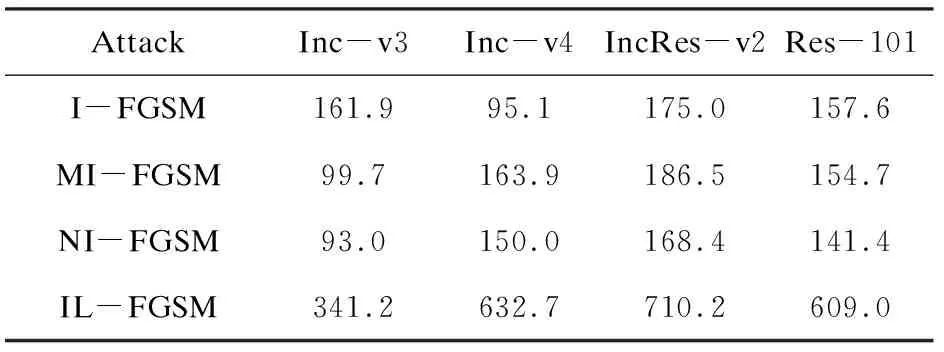
表5 单个模型设置下,四个方法的攻击用时 s
5 结束语
对抗样本的存在严重威胁到深度学习在众多安全领域的运用,因此对抗样本生成算法也成了当下研究的热点。该文提出了一种新的方法,积分损失快速梯度符号法IL-FGSM。该方法利用了输入的间隔指数范围采样的损失函数的集成来更新对抗样本,与单个损失函数的更新相比,使用了当前输入样本的积分损失来更新当前的对抗样本,这可以更好地避免梯度出现饱和的情况,引导梯度在全局最优的方向上更新。实验结果表明,IL-FGSM不仅提高了白盒攻击的成功率也提高了黑盒攻击的成功率。除此之外,将增加样本迁移性的方法DIM和TIM集成到了该方法,进一步提升了黑盒攻击的成功率。实验显示IL-FGSM提升了基线攻击10%~20%的攻击成功率。与基线方法相比,该方法生成了更强的对抗样本,但是计算消耗较大。未来,将做进一步的研究来加快积分损失的计算。
猜你喜欢
今日农业(2022年15期)2022-09-20
天天爱科学(2022年9期)2022-09-15
当代水产(2022年6期)2022-06-29
中国药学药品知识仓库(2022年10期)2022-05-29
中国典型病例大全(2022年9期)2022-04-19
小天使·二年级语数英综合(2019年10期)2019-11-08
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
中学生数理化·高三版(2016年9期)2016-05-14
