
辨证论治思想指导下的中医主题词自动标引模型构建
2022-08-02 03:32张异卓周璐孙燕郑丰杰徐凤芹李宇航
中国中医药信息杂志 2022年8期
张异卓,周璐,孙燕,郑丰杰,徐凤芹,李宇航
1.北京中医药大学中医学院,北京 100029;2.中国中医科学院西苑医院,北京 100091
主题词标引运用计算机技术对解析的文献进行管理,将解析的数据内容冠以恰当标识。通过对电子病历进行主题词标引,将病历中的词语与主题词表中具有相同内涵的词汇相对应,达成统一的文字表述,从而为系统挖掘中医辨证论治规律及智能化处理奠定数据基础。由于中医词语中包含大量“理法方药”信息,因此,中医电子病历需要在辨证论治思想指导下完成主题词标引。
随着中医电子病历的普及,实践工作对自动标引技术提出了一定需求。本研究团队在以往研究的基础上,采用基于双向编码表示(bidirectional encoder representation from transformers,BERT)的语言处理模型与Sigmoid输出函数结合,在辨证论治思想指导下构建中医主题词自动标引模型,以期帮助研究人员更加高效、精准地完成中医主题词标引任务,并为相关研究提供数据与方法学参考。
1 资料与方法
1.1 数据来源
建模数据来源于中国中医科学院“名医名家传承”项目管理平台。该平台的名老中医药专家经验信息数据库收录了60余位名老中医的临床医案、经验方、学术思想及临床经验,且采用结构化模式进行数据采集,保证了数据的规范性。本研究收集其中22位名老中医的电子病历,共计3 252份。
1.2 病历筛选标准
纳入标准:①参照《人力资源社会保障部、国家卫生计生委、国家中医药局关于评选国医大师、全国名中医的通知》评定为国医大师或全国名中医的病历;②属于中医内科疾病范畴的病历;③病历收集时间为2019年12月—2020年12月;④疾病、症状、证候、治法、处方等中医“理法方药”信息记录完整。
排除标准:①中医“理法方药”信息记录不明确者;②病历数据重复者。
1.3 数据标引
1.3.1 标引原则
本研究所用主题词表参照《医学主题词表》(Medical Subject Headings,MeSH)的结构建立,并在以往研究基础上,以《伤寒论》“观其脉证,知犯何逆,随证治之”的辨证论治思想为指导,经专家论证确定中医主题词标引三原则。①含义趋同原则:即原始词与标引的中医主题词含义趋同。本原则以“观其脉证”为指导,根据望、闻、问、切四诊合参方法审查描述中医临床词语的文字组成,分析其中医含义,标引为含义趋同的中医主题词,以保障标引的主题词与原始词传递相同的信息。②方向一致原则:即原始词与标引的主题词提示相同的辨证论治方向。本原则以“知犯何逆”为指导,把握病机、治法、治则等主题词的辨证论治方向,从而确保主题词标引后,主题词传递的辨证论治方向不发生偏离。③可替换原则:即原始词与标引的主题词之间相互替换不会影响辨证论治的思维过程。本原则以“随证治之”为指导,确立诊断、治法、方药,突显辨证论治各环节环环相扣,以体现理-法-方-药的链式关系。
1.3.2 标引方法
依据《中医学主题词表》(北京中医药大学中医信息学研究中心提供),对收集的症状和证候进行主题词标引,如“肚子胀”标引为“腹胀”,“大便稀不成形”标引为“便溏”,如原始词对应多个主题词则以逗号为分隔符分开标注。由2名具有执业医师资格的科研人员对病历进行逐条标注,由2名熟练掌握《中医学主题词表》的中医专家对标引结果进行双盲复核,不一致处提请第三位中医专家复核,并经讨论达成一致。
1.4 数据集划分

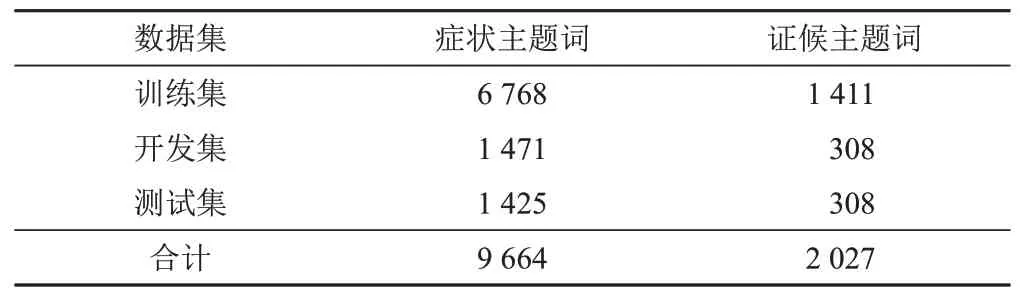
表1 各数据集标引的主题词数量
1.5 模型设计
BERT模型是一种被用于文本分类、文本信息提取、文本翻译等多种语言处理任务的人工智能模型,在多项处理任务中取得突破性进展,展现出优于既往模型的优势。该模型可以通过对给定文本的学习,将文本中的词语以数学向量即词向量的形式表示。以向量表示词语的方式,使词语具有方向性和位置性。通过余弦(Cosine)距离公式对词向量之间的距离进行计算,2个词语之间的词向量距离越近,表示二者关联越紧密。
病、症、证、方、药之间形成相关联的知识结构,使用BERT模型对具有“理法方药”结构的辨证论治知识进行学习,可使相关内容形成紧密的联系,词语具有特定的指向性,从而使所得模型在进行中医主题词标引时具有更好的效果。BERT模型对中医“理法方药”的学习示例见图1A,输入数据为疾病、症状、中医辨证诊断、治法、处方数据,训练模型对词语的编码能力。在此基础上,进一步学习中医主题词标引,将每个主题词中的词语作为标签,对原始词与主题词之间的映射关系进行学习。该学习过程示例见图1B,输入数据病历中的原始词,输出标引词。
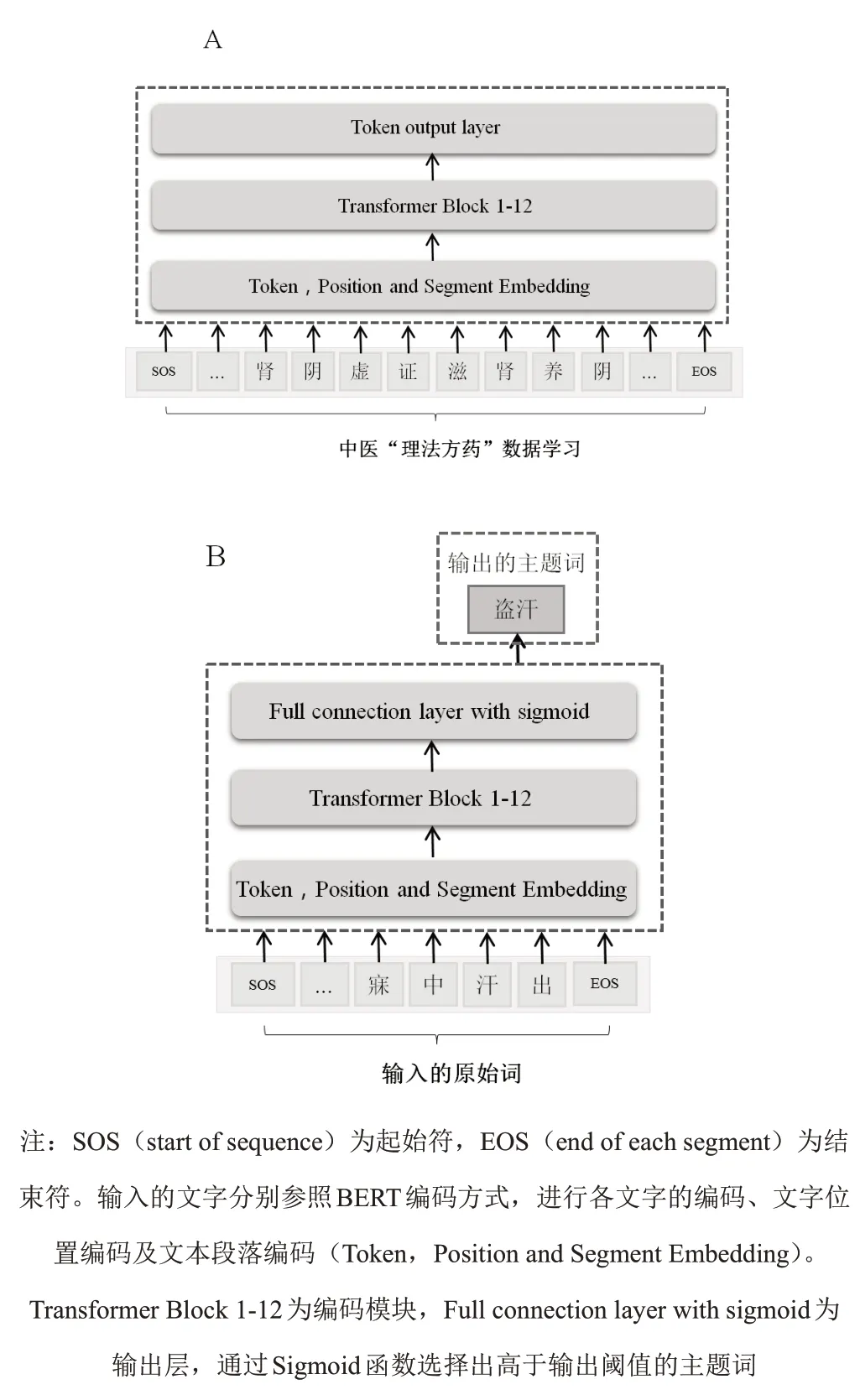
图1 BERT模型进行“理法方药”与主题词标引学习过程示例
1.6 模型构建
从电子病历中提取疾病、症状、证候、治法、处方等“理法方药”数据,以BERT 的掩码语言模型(mask language model,MLM)学习法,对“理法方药”数据进行学习,在此基础上以Sigmoid作为输出函数,进行主题词标引的学习,通过学习症状、证候记录与中医主题词之间的映射,构建中医主题词自动标引模型,即TCM-BERT-Sigmoid模型。
本研究使用2种对照模型:①基于双向长短时记忆(bidirectional long short-term memory,Bi-LSTM)神经网络与Sigmoid函数的中医主题词自动标引模型,即Bi-LSTM-Sigmoid模型。②未对中医“理法方药”数据进行学习,仅基于BERT与Sigmoid函数的中医主题词自动标引模型,即BERT-Sigmoid模型。
设置 TCM-BERT-Sigmoid 和 BERT-Sigmoid 模型训练样本为每批次16个,优化器为Adam,学习率(learning rate,LR,神经网络训练过程中的超参数,用以控制参数更新速度)从0.000 2、0.000 3、0.000 5中选取,根据不同取值在开发集上的表现,选取表现最佳的数值。其余参数使用BERT默认设置。
设置Bi-LSTM-Sigmoid 模型训练样本为每批次256个,初始化权重为-0.05~0.05随机均匀分布,词向量维度为300,优化器为Adam。模型的LR从0.01、0.03、0.05 中选取,神经元失活比例(dropout rate,DR,神经网络每层中随机丢弃的神经元占整层神经元的比率。在每一轮训练中让一些神经元随机失活,从而让每一个神经元都有机会得到更高效的学习,以减轻神经网络的过拟合)从0.3、0.5中选取,LSTM的记忆单元数量(memory cell,MC)从128、256、512中选取。根据不同取值在开发集上的表现,选取表现最佳的数值。
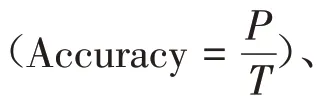

表2 对症状的不同中医主题词自动标引模型建模参数及开发集指标
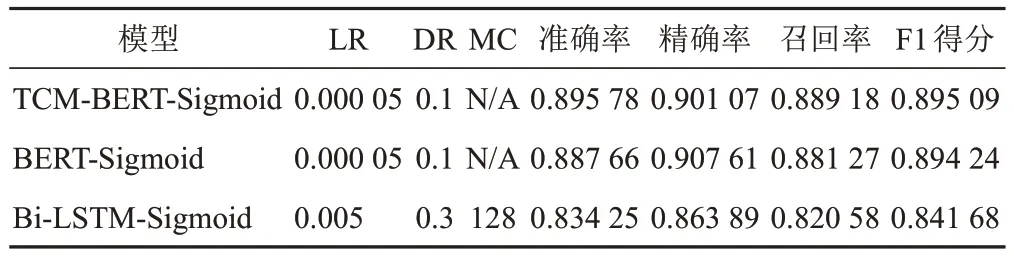
表3 对证候的不同中医主题词自动标引模型建模参数及开发集指标
2 结果
2.1 模型测试结果
根据划分的测试集进行模型测试,症状主题词标引时不同阈值的输出结果见图2,证候主题词标引时不同阈值的输出结果见图3。可见,当TCM-BERTSigmoid与BERT-Sigmoid中医主题词自动标引模型的输出阈值为0.2、Bi-LSTM-Sigmoid中医主题词自动标引模型的输出阈值为0.3时,各模型的精确率、召回率和F1得分更为均衡,测试结果见表4、表5。可见,在对症状和证候的主题词标引中,TCM-BERT-Sigmoid模型的结果均优于对照模型。
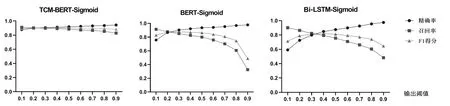
图2 对症状的不同中医主题词标引模型在不同输出阈值下的结果
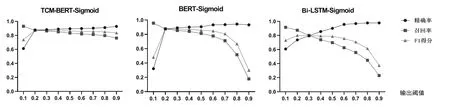
图3 对证候的不同中医主题词标引模型在不同输出阈值下的结果
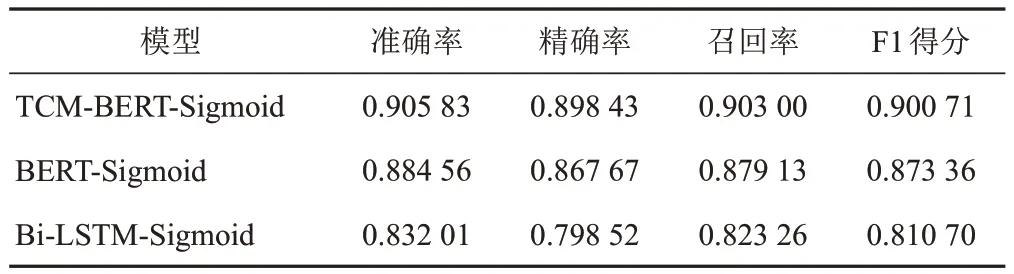
表4 不同中医主题词标引模型的症状主题词标引测试结果
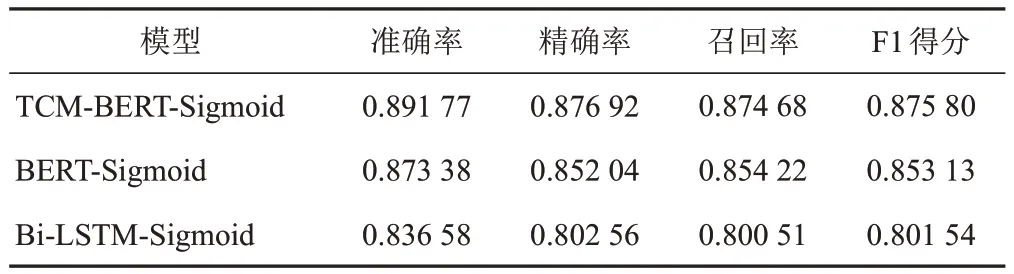
表5 不同中医主题词标引模型的证候主题词标引测试结果
2.2 对应1个主题词与对应多个主题词的测试结果
症状主题词标引时,分别对应1个主题词与对应多个主题词的测试结果见图4。可以看出,只对应1个主题词时的精确率低于召回率,表明模型在输出正确结果的同时,有时也会将错误结果一同输出,如症状为“小便发黄”,模型可能会标引为“尿黄”和“尿浊”,即在正确输出“尿黄”的同时错误输出了“尿浊”。对应多个主题词的测试结果显示,精确率高于召回率,表明在对应多个主题词的标引中,模型输出的结果正确但不全面,如症状为“苔白有齿痕”,模型可能仅标引为“齿痕舌”,而“白苔”未被标引。从F1得分来看,TCM-BERT-Sigmoid中医主题词自动标引模型的表现最优。

图4 不同中医主题词标引模型症状主题词标引结果
证候主题词标引时,分别对应1个主题词与对应多个主题词的测试结果见图5。可以看出,当证候只对应1个主题词时,召回率低,精确率高,表明模型在输出正确结果时容易发生遗漏现象,即如果模型认为没有把握输出正确结果时则选择不输出结果。当证候对应多个主题词时,召回率高,精确率低,表明模型在输出正确结果的同时,错误结果也会一并输出,如证候为“肺阴不足证”,模型在将其标引为“肺阴虚证”的同时,标引为“肾阴虚证”。但从F1得分来看,TCMBERT-Sigmoid 中医主题词自动标引模型的表现仍为最优。

图5 不同中医主题词标引模型证候主题词标引结果
3 讨论
运用计算机技术对中医电子病历进行符合“理法方药”标引,是进行中医数字资源信息挖掘及智能化处理的前提,对开展中医辨证论治规律研究具有基础性意义。近年来,人工智能在医疗领域逐步得到广泛应用,自然语言处理(NLP)是人工智能重要领域之一,汇聚了众多文本处理技术,已被广泛用于临床记录的语言翻译及医疗信息提取等工作。以往研究中,研究人员提出了一些基于NLP的生物医学领域的归类模型:如从相似性匹配角度,提出Word2Vec、DNorm、 Jaccard's similar和 BERT-based ranking;从命名实体识别(NER)角度,提出transition-based model和 Bi-LSTM-CNNs-CRF。此外,在建模概念方面,许多从序列生成和文本分类角度构建的模型在NLP任务中也表现出良好的性能和适用性。但上述模型仅适用于一对一的归类情况,而不适合于一对多的归类情况。
基于以往研究,本研究通过不同技术的组合,提出了中医主题词自动标引模型。其中,得益于BERT模型使用的双向自编码技术,使模型具有更为出色的学习能力,基于BERT建立的TCM-BERT-Sigmoid中医主题词自动标引模型表现最佳,其精确率、召回率和F1得分均优于基于Bi-LSTM建立的对照模型。
为解决原始词对应多个主题词的问题,我们使用BERT 与Sigmoid 函数结合,通过限定输出阈值的方法,将高于限定阈值的主题词输出,高于限定阈值的主题词恰能与原始词对应,从而克服了难以处理1个原始词对应多个主题词的问题,使模型可以兼顾“一对一”与“一对多”标引情况,因此在中医主题词标引任务中具有更广的适用性,可为中医数据挖掘及中医辨证论治规律研究提供有力的工具支持。
本研究为单次实验,考虑到神经网络初始化权重的随机性会导致实验结果有一定浮动,今后研究应增加实验次数。此外,本研究构建的中医主题词自动标引模型仅针对症状和证候主题词进行研究,虽然取得了良好的实验结果,但此模型能否适用于其他中医主题词如疾病、治法、处方等的自动标引任务,仍需进一步探索。本研究构建的中医主题词自动标引模型未与其他仅适用于原始词与主题词“一对一”模型进行对比,有待进一步研究。
猜你喜欢
基层中医药(2020年1期)2020-07-27
资源信息与工程(2019年2期)2019-05-09
基层中医药(2018年9期)2018-11-09
温州医科大学学报(2018年8期)2018-03-03
温州医科大学学报(2016年2期)2016-03-16
云南中医学院学报(2015年3期)2015-07-31
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
沈阳医学院学报(2014年4期)2014-12-27
疑难病杂志(2014年12期)2014-04-16
