
基于互联网旅游数据的游客量预测模型研究现状与展望
2022-08-01 08:41时萍萍胡姚刚孟继东
资源开发与市场 2022年8期
时萍萍,胡姚刚,孟继东
(1.重庆理工大学a.管理学院;b.电气与电子工程学院,重庆 400054;2.重庆大学 重庆旅游人才发展研究院,重庆 400044;3.重庆银行 博士后科研工作站,重庆 400024)
0 引言
2021年6 月,国家文化和旅游部在介绍《“十四五”文化和旅游发展规划》关于“完善现代旅游业体系”时指出,旅游业是幸福产业,是人民生活水平提高的重要标志,旅游业已发展成为传承弘扬中华文化的重要载体,对稳增长、稳投资、稳就业、促消费、调结构等方面的综合带动作用日益凸出。然而,在旅游业快速发展同时也伴随着问题出现,特别是因游客量的急剧增长和休假制度导致的节假日旅游需求集中,极易造成区域交通拥堵或景区超载、游客安全事故等现象,严重影响游客旅行体验,不利于旅游消费和旅游业的可持续发展,给旅游管理和调控带来了巨大挑战。因此,深入研究精准有效的游客量预测模型,及早掌握区域或景区游客量预测数据,对提升游客旅游体验,科学配置旅游资源和推动旅游业高质量发展有重要意义。
国家文化和旅游部在2020 年发布的《关于深化“互联网+旅游”推动旅游业高质量发展的意见》指出,坚定不移建设网络强国、数字强国,持续深化“互联网+旅游”,推动旅游业高质量发展。在旅游活动过程中,通过搜索引擎、博客、微博、社交网络、移动APP等互联网在线平台,游客可获取包括景点、交通、天气、旅游体验等信息,预定行程或购买旅游产品并反馈旅游体验评论信息。旅游出行前的搜索、交易、评论等数据被互联网记录、储存和积累,形成反映游客行为的互联网旅游数据[1,2]。互联网旅游数据是对传统统计数据在深度与广度上的重要补充和扩展,通过对互联网旅游数据提取、整理、分析、建模和可视化,掌握游客行为特征和偏好,及早获得游客量预测结果[3,4],为旅游管理部门配置旅游服务资源和提供高质量的旅游服务提供重要技术支撑。
互联网旅游数据具有多元异构、高频、海量、价值密度低的大数据特征,如何从旅游大数据中挖掘关键特征信息和构建有效的游客量预测模型,已经成为近年来国内外相关科研机构研究共识和热点[1]。目前,已有学者对旅游预测模型或互联网旅游数据研究现状进行了评述。如:Song 等[5]总结了1968—2018 年旅游预测模型发展,但利用互联网旅游数据开展游客量预测的现状和演变仍然不清楚;Li等[2]对不同类型的互联网数据旅游预测研究进行了整理,但却过于注重数据类型的分类,忽略了预测模型的演进趋势。因此,本文拟通过检索和梳理国内外重要核心期刊的相关研究,对互联网旅游数据特征、处理方法和游客量预测模型研究现状进行评述,并从关键词智能提取、非结构化数据转化、多源旅游数据融合、高维非线性混频数据处理4 个方面展望未来的研究要点及趋势。
1 互联网旅游数据
互联网旅游数据是虚拟网络中游客搜索、交易、评论、照片等被互联网记录、储存和积累的数据,可反映游客的注意力、兴趣和行为,具有数据量大、时效性高等特点[1,2]。但同时存在数据非平衡问题,获取的数据通常多而杂,只有极少部分具有预测使用价值,提取大量有较高价值的预测数据困难。目前,游客量预测建模一般需要的互联网旅游数据主要包括搜索引擎数据、社交媒体数据两类[6](表1)。

表1 互联网旅游数据特征Table 1 Characteristics of Internet tourism data
1.1 搜索引擎数据
谷歌、百度等大型搜索引擎实时记录用户的搜索内容、搜索频率及位置等信息,生成谷歌趋势或百度指数结构化数据,用户在搜索引擎输入的关键词数量、内容、次数等信息,间接呈现了用户对旅游需求、兴趣和旅游目的地的关注程度。当前,在旅游预测研究中,谷歌趋势和百度指数数据应用较多,如Li等[1]对谷歌趋势和百度指数数据的特征进行了总结,结果如表2 所示。目前,谷歌搜索在全球占主导地位,而百度在中国拥有广大的用户规模,百度指数更适用于中国旅游预测[7]。基于搜索引擎数据的旅游预测过程(图1)主要包括搜索数据获取、搜索数据处理和构建预测模型3 部分。
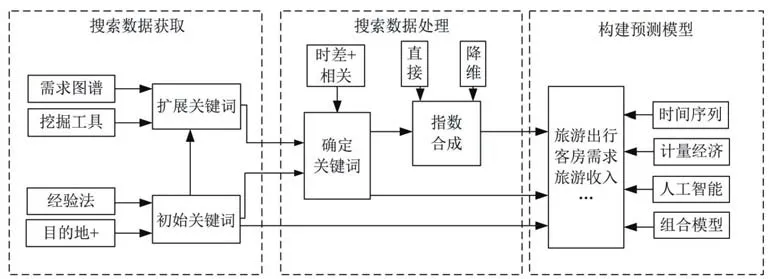
图1 基于搜索引擎数据的游客量预测过程Figure 1 Tourist volume prediction process based on search engine data

表2 谷歌趋势与百度指数特征比较Table 2 Comparison of Google trend and Baidu index
搜索数据获取主要包括初始关键词选取和扩展关键词两个方面。①初始关键词选取。经验选择法是常用的初始关键词选取方法,该方法依据研究人员的知识和经验确定关键词。例如,Li 等[3]在开展四姑娘山游客量预测时,直接采用了四姑娘山攻略、四姑娘山天气、四姑娘山海拔、四姑娘山在哪里、四姑娘山景区、四姑娘山门票、四姑娘山旅游、四姑娘山住宿8 个关键词的搜索指数作为预测变量。经验选择法虽然简单易行,但是与研究人员的知识、能力等因素相关,主观性较强,不具有推广意义。且该方法极易忽略重要关键词,也有可能选择不正确的关键词,无法准确预测游客量。②扩展关键词。旅游是一种非常复杂的活动行为,决策过程中涉及诸多阶段。少数关键字无法涵盖游客决策整个过程,导致具有预测功能的重要关键词遗漏。一些关键词挖掘工具,如站长工具、爱站网、需求图谱功能、搜索推荐,可对相关关键词进行扩展。李晓炫等[8]在对九寨沟游客量进行预测时,以九寨沟、九寨沟天气、九寨沟酒店、九寨沟机场为核心关键词,利用百度搜索推荐相关关键词的功能,共扩展出146 个关键词。相比经验选择法,关键词扩展法能捕捉到更多与出行有关的关键词,但部分关键词与预测因素相关性较弱甚至出现不相关现象,易产生数据噪音,难以提高预测精度。
搜索数据处理包括关键词确定和指数合成两个方面。①关键词确定。鉴于搜索引擎数据量庞大且包含丰富的信息,研究人员通过选择和减少关键词的方法提取有效信息进行准确预测。常用的时差相关法兼具领先性和相关性特点,通过计算每个关键词提前几期的搜索量与预测指标之间的皮尔森相关系数,再确定关键词的选择阈值,选择出具有预测能力的关键词。如,李晓炫等[8]选取至少提前1 期的关键词搜索量与景区游客量的皮尔逊相关系数大于0.8 的关键词作为最终关键词;Yang 等[7]采用了同样的方法确定预测关键词,但Google 趋势关键词选取条件为皮尔逊相关系数大于0.76,而百度指数关键词选取条件为皮尔逊相关系数大于0.8。可见,相关系数阈值的选择多是根据研究者自身经验,阈值过低导致选择条件过于宽泛,较多的噪音降低搜索指数与预测量的相关性;而阈值过高导致关键词较苛刻,有可能遗漏影响预测的重要因素[8]。②指数合成。为有效反映游客对目的地的整体关注趋势,可将搜索关键词合成一个指数或几个搜索指数[1,7,8],常 用 搜 索 指 数 合 成 方 法 有 直 接 合 成 法 和 降维合成法。直接合成法是将所有搜索关键词搜索量直接相加,合成搜索指数。如李晓炫等[8]、Yang等[7]直接把通过时差相关法筛选出来的关键词搜索量进行相加,合成预测因子。直接合成法直接、简单、易操作,但难以明确各搜索关键词对景区游客量的不同贡献。降维合成法可分为聚类分析、主成分分析(Principal Component Analysis,PCA)和广义动态因子(Generalized Dynamic Factor Model,GDFM)3 类:第一类,聚类分析是对研究对象按照一定的规则进行类或簇的划分方法。其目标是将特征属性相似或信息相关的对象划分为一类,而类之间的对象特征属性是不相似或相关度较低的。如张玲玲等[9]采用K-均值聚类分析方法将海南、三亚、海南旅游等17个关键词分成3 类,并验证了第二类关键词指数变量对海南游客量具有预测能力。但当数据量较大时,K值较难确定,影响初始聚类中心的选择,分类效果不好。第二类,PCA在损失很少信息前提下,将少数几个集中了原始变量的大部分信息的综合变量(主成分)代替原始多个变量,各个主成分之间互不相关。如Li等[10]对北京旅游进行预测时,采用PCA将北京小吃、北京经典、北京特产、北京风景名胜区、北京饭店等15 个搜索关键词提取为6 个主成分。但当PCA主成分出现负值时,PCA 的含义解释较模糊,不如原始变量的含义明确。第三类,GDFM 以因子分析理论为基础,以高维经济变量为分析对象,引入更多的指标信息,采用基于频域分析的非参数估计方法,处理无限多的样本,更为全面反映指标信息,无需事先确定指标间的先行或滞后关系,直接用滞后算子多项式来刻画指标间的动态时序关系。Li等[11]采用GDFM 方法将搜索到与北京旅游相关的关键词整合成一个因子,与采用PCA 方法合成因子相比,GDFM合成的因子具有更好的预测能力。
1.2 社交媒体数据
旅游研究社交媒体数据主要来源于TripAdvisor、Expedia、Booking、携程、去哪儿、点评等网站[1,2],这些社交媒体通过论坛、博客、社交网络、照片和视频分享等方式为游客提供反馈旅游体验信息渠道。目前,社交媒体数据分为结构化数据和非结构化数据两类。①结构化数据主要包括用户转发数、用户回复数、评分数、旅游管理组织转发数等,可直接作为游客量的预测变量。②非结构化数据主要包括新闻、评论内容、照片、图像、视频等,需将非结构化数据转化为结构化数据后,再作为预测变量。与基于搜索引擎数据的游客量预测过程类似,基于社交媒体数据的旅游预测过程也包括搜索数据获取、数据处理和构建预测模型3 部分,但由于社交媒体数据多是非结构化数据,在获取与处理环节与搜索引擎数据有较大不同。
当前,社交媒体数据一般需要开发网络爬虫软件采集原始数据。通过网络爬虫技术从相关社交媒体网站收集在线文本数据(包括旅游相关评论和博客)[12,13]。利用网络爬虫在一个程序或一套程序方面实现迭代和自动下载网页,从超文本标记语言(HTML)提取统一的资源链接(URL)[14]。如,Xiang等[12]使用Python 和Java 编程语言中的网络爬虫获得酒店相关评论;Guo等[15]开发了一个网络爬虫,定期从TripAdvisor收集评论数据。
对于非结构化旅游数据,将非结构化社交媒体数据转化为结构化的时间序列数据是研究中的关键环节。社交媒体中的评论反映了消费者的情感倾向,通过机器学习、文本分析等方法,情感指数可将在线情感表示为一个时间序列,预测旅游需求。梅梅等[16]针对中文微博数据非结构化特点,从相关维、状态维、主题维、情绪维4 个维度提出了一套标准的微博情绪挖掘方法,通过K-近邻算法(KNN)、贝叶斯(NB)和支持向量机(SVM)进行倾向性分析,形成量化的情绪指标;Colladon 等[17]采用Condor 软件中的机器学习方法,将在TripAdvisor中收集的266万多篇帖子合成消费者情感指数,纳入国际机场抵达人数预测模型中,具有消费者情感指数的预测模型比基于Google趋势数据的预测模型表现出更好的性能;Starosta 等[6]采用人工神经网络方法,将媒体正面和负面新闻表示为时间序列的游客情绪指数,发现游客对旅游目的地的态度与游客量之间具有很强的相关性。
2 游客量预测模型研究现状
基于互联网旅游数据的游客量预测模型主要包括时间序列模型、计量经济模型、机器学习模型、组合模型,与上述预测模型研究的相关研究现状分析结果如图2 所示。
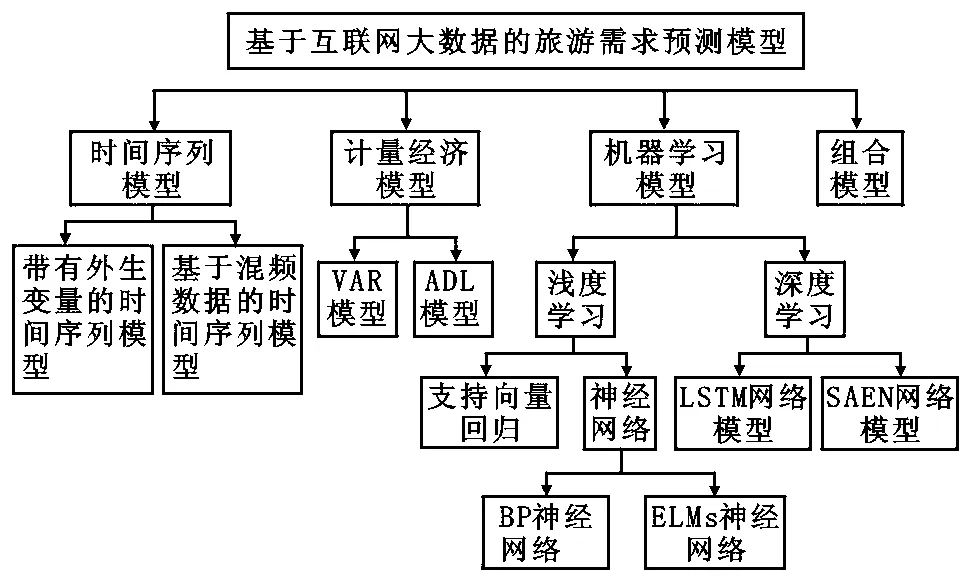
图2 基于互联网旅游数据的游客量预测模型分析框架Figure 2 Analysis framework of tourist volume prediction model based on Internet big data
2.1 时间序列模型
时间序列模型主要通过识别周期性历史数据(每天、每月、每季度或每年)的变化趋势确定模型,进而实现预测游客量[18]。互联网旅游数据为旅游预测模型引入了“互联网旅游数据”外生变量数据,早期的时间序列自回归(AR)模型、天真模型、自回归滑动平均(ARMA)模型、差分整合移动平均自回归(ARIMA)模型、季节性差分自回归移动平均(SARIMA)模型已成为互联网数据预测游客量的基础对比模型。目前,基于互联网旅游数据的时间序列模型可分为带有外生变量的一般时间序列模型和基于混频数据的时间序列模型两类。
带有外生变量的一般时间序列模型:考虑到互联网旅游数据的引入为游客量预测带来了新变量,带有外生变量的时间序列模型最早被应用于游客量预测中,以检验互联网旅游数据是否具有预测能力。如Choi等[19]采用ARX模型预测了美国、加拿大、英国、德国、法国、意大利、澳大利亚、日本和印度9 个国家到香港的游客量,发现关键词“香港”的Google搜索趋势与游客量正相关。考虑到互联网多源数据对游客量预测的重要价值,Li 等[3]采用ARMAX 模型对四姑娘山游客量预测时发现,与基于搜索引擎单一来源大数据的游客量预测相比,采用搜索引擎和多个在线评论平台的多源大数据对游客量预测具有更好的预测性能。在模型预测性能方面,Pan[20]发现ARMAX 模型不仅优于ARMA 模型,而且比一般的计量经济模型自回归分布滞后模型(ADL)、时变参数(TVP)模型和向量自回归(VAR)效果都好。由于互联网数据和游客量呈现非平稳的时间序列特征,建模之前通常采用差分运算对数据进行平稳化处理,通过消除趋势项和周期项来建立ARIMAX 模型。如Artola等[21]在预测英国、德国和法国到西班牙旅游游客量时发现,ARIMAX 模型精度明显提高。此外,考虑到游客量会因季节变动引起典型淡旺季周期性时间序列变化,须对Google 趋势或百度指数提供的互联网数据和游客量增加拟合时间序列周期性相关关系的差分处理,即构建SARIMAX 模型,SARIMAX模型不仅比一般的ARIMA、SARIMA、HW模型泛化能力强,且预测集的预测性能优于测试集的预测性能[22,23]。
基于混频数据的改进时间序列模型:宏观的旅游数据通常每月或每季度进行采集,而搜索数据或评论数据的生成频率是每天一次或更高频率。通常情况下,采用互联网数据开展的游客量预测研究面临多频率或混合频率问题。如果使用平均加权法将所有变量聚合到相同低频率上,将导致高频数据中可用信息丢失,从而导致无效或有偏差估计[24]。混频数据采样(MIDAS)可通过加权方案将高频过程投射到低频过程中,从而较大程度地保留高频数据信息;与基础时间序列模型结合,可提高预测精度。Bangwayo-Skeete等[25]采用周度Google 数据预测加勒比地区的月度游客量时,将MIDAS 与AR 的简化形式相结合组成“AR - MIDAS”预测方法,通过对比12 个月预测结果显示,多数情况下AR - MIDAS 模型优于SARIMA、AR模型。高频率搜索数据对景点和目的地规划至关重要,但混频模型的预测精度并不一直表现优越。Volchek 等[26]在预测伦敦5 家博物馆的参观人数时发现,复活节假期日期的变化导致了同期入境人数的显著波动,使得SARMX- MIDAS模型的RMSE比季节性天真模型差。
2.2 计量经济模型
计量经济预测模型有助于探索经济因素与游客量之间的关系,其重点是建立长期因果关系,或确定各种解释变量对未来需求的影响程度。计量经济模型在游客量预测研究和实践中发挥重要作用,目前利用互联网旅游数据预测游客量的计量经济模型主要有VAR和ADL模型。
VAR模型是计量经济学中最常用的方法之一,一般不区分内、外生变量,把系统中每一个内生变量作为系统中所有内生变量的滞后值的函数来构造模型,通常用于多变量时间序列系统的预测和描述随机扰动对变量系统的动态影响[27]。其优点是易于估计,能够较好拟合数据,灵活性和实用性强,特别适合描述小变量集合的数据生成过程,已被用来分析不同语言搜索平台数据或多类型大数据对游客量的预测作用。如,Dergiades 等[28]对语言偏向和平台偏向进行定义,对多语言的源市场及不同的主流搜索引擎平台数据进行聚合,采用VAR 模型对塞浦路斯月度国际游客量进行预测发现,经过调整聚合后的数据表现出更好的预测效果;Liu 等[29]采用VAR模型检验天气、温度、周末和公共假日、网络搜索量多类型数据与游客量的关系时发现,网络搜索量与游客量之间存在长期关系。根据不同省市对天目湖的搜索指数值,Liu 等[30]采用VAR 中的脉冲相应函数检验了日游客量与搜索量指数之间的时空相关关系,发现日游客量、搜索指标与距离成反比关系,而旅游信息需求与距离成正比。但一般的VAR 模型受参数估计多,存在过度参数化问题。贝叶斯向量自回归模型(BVAR)是VAR 的一种扩展模型,其原则是当参数被断定在某一值时,使模型参数趋近于这一取向而不是锁定确定值,只要有充足的数据支持,就可以得到更为精确的估计,降低参数不确定性并显 著 增 强 预 测 性 能[31]。Gunter 等[32]使 用10 个 谷歌分析网站流量指标(平均会话持续时间、平均页面时间、跳出率、新会话、页面浏览量、返程访客、社交网络推荐、总会话、独特页面浏览量和用户),采用BVAR、因子增强向量自回归(FAVAR)和两者融合的贝叶斯因子增强向量自回归(BFAVAR)预测维也纳旅游人数,发现在短期1—2 个月内,单变量基准MA模型预测性能好,而对于较难的长期3、6、12 个月,BFAVAR预测性能比基准模型更优越。
ADL模型能解释游客量与各种影响因素之间的滞后跨期关系,除了评估影响因素的滞后影响外,还整合了滞后需求变量的影响,能够估计变量之间长期稳定关系。Huang 等[33]通过构建ADL 模型采用百度指数,对2007 年1 月1 日到2009 年12 月31 的北京故宫的参观人数进行预测,发现百度关键词指数与游客数据之间存在长期均衡关系和格兰杰因果关系,关键词“北京故宫”滞后2 期,“故宫”滞后1期,“故宫门票”当期,故宫实际游客量滞后1 期和2期均对故宫实际游客有正向影响,且融合百度指数的ADL 模型比ARIMA 模型的预测精度提高12.4%。但ADL模型并不总是能表现出较好的预测性能,Önder[34]在国家或城市的游客量预测时发现,ADL对城市(维也纳)预测效果好,但在对国家(奥地利)的游客量预测中HW模型反而效果更好。
2.3 机器学习预测模型
虽然时间序列模型与计量经济具有模型简单、计算复杂度低、处理速度快的优点,能够反映互联网旅游数据与游客量之间的长期线性关系,但是存在预测精度不高、性能不稳定等问题。互联网旅游数据与实际游客量数据均存在非线性、周期性和自相似性等特点,仅采用线性模型较难对其准确拟合。因此,非线性机器学习模型逐渐被用于互联网旅游数据的游客量预测中,根据机器学习模型结构的深度,分为浅层学习网络和深度学习网络两类(图2)。其中:浅层学习网络主要包括支持向量回归(SVR)模型和神经网络两类;深层学习网络主要包括长短期记忆网络(LSTM)和SAEN学习网络两类。
SVR是基于统计学习理论和结构风险最小原理,能够在有限信息的基础上,对发展趋势和最优解进行推广,该模型适用于分析小样本和多维化数据[35]。基于SVR的旅游预测方法研究主要思路是:利用在互联网搜索引擎中获得的搜索数据和游客量数据训练支持向量模型,并确定模型参数,基于训练后的SVR 模型对游客量进行预测。直接采用SVR进行预测会遇到3 个障碍:不恰当的模型自由参数选择对预测结果产生不利影响;核函数必须满足Mercer条件;模型训练复杂,速度慢[36]。①为了解决参数设置问题,灰狼算法(GWO)、蝙蝠算法(BA)因具有收敛速度快、易于实现、结构简单、易获得局部最优解和鲁棒性能好等优点,被引入优化SVR 模型参数,形成BA- SVR、GWO- SVR 模型预测游客量。与基于粒子群算法的SVR、ANN 模型相比,其预测精度得到明显提高。BA - SVR 的预测流程如图3所示[37,38]。②为了克服SVR 模型核函数的局限性,Tipping 提出相关向量机(RVM)对SVR 进行改进,RVM能够获得概率输出,最大程度地减少核函数的计算量,所选核函数不必满足Mercer 条件,能较好拟合小样本非线性数据。张斌儒等[39]的研究表明,RVM和SVM在预测海南游客量时表现出优异的预测性能和良好的泛化能力,但RVM训练过程更为简单,在小样本数据集中表现出更强的预测能力。③为应对SVR训练速度慢、储存量大的难题,最小二乘支持向量回归(LSSVR)将求解二次规划问题转化为求解高维空间线性最小二乘问题,简化了计算过程,提高了训练速度。Xie 等[40]采用LSSVR 搜索数据与经济指标预测邮轮游客量,并引入引力搜索算法(GSA),通过种群的粒子位置移动来寻找最优解,发现与传统模型相比,LSSVR - GSA 具有较高的预测精度和泛化能力。

图3 BA- SVR流程Figure 3 Flow chart of BA- SVR
神经网络包括BP和极限学习机(ELMs)神经网络两类。①BP。由于BP 有非线性映射能力强、网络结构柔性大等特点,在解决复杂的非线性预测问题具有突出优势,目前已经被广泛应用到游客量预测中[41]。Hu等[42]基于人工神经网络(ANN)框架预测香港至澳门的短途旅行游客量,将168 个观测数据采用BP测试,实证结果表明,具有搜索引擎数据BP模型优于ARIMA、ADL基准模型。考虑到搜索引擎数据与旅游历史数据受随机因素的影响产生噪音,陆利军等[43]提出了基于网络搜索的EMD 去噪与BP 神经网络结合预测方法。具体为:先利用EMD对原序列进行分解,再使用对BP 神经网络对IMF分量进拟合,预测误差均显著低于BP 和Elman神经网络基准模型。由于在训练过程中,BP 神经网络会面临陷入局部最优、收敛速度慢等问题,通常采用优化算法对BP 神经网络进行改进,以提高旅游预测的精确性。针对BP 神经网络的预测结果易受初始连接权值和阈值的影响,Li 等[44]利用果蝇优化算法(FOA)改进BP 神经网络,实现BP 神经网络初始连接权值和阈值的自适应最优选择,并采用FOA-BP模型预测黄山每日游客量,发现FOA - BP 比“遗传算法+BP”和“粒子群算法+BP”表现出更高的预测性能。针对BP 神经网络的部分重要参数容易陷入局部最优问题,Li 等[10]引入自适应差分进化算法(ADE)对BP 神经网络权值和阈值进行全局优化。②ELMs是一种单隐含层前馈神经网络,有着学习速度快、泛化能力强等特点。ELMs仅有一个隐含层,隐含层内神经元直接决定了预测模型的性能。为了避免隐含层神经元的数目选择问题,Sun 等[45]根据Mercer条件,选择用核函数代替隐藏层的激活函数,输出权重更稳定,构建核极限学习机(KELM)采用百度与Google数据预测中国热门旅游目的地游客量,与基准模型ARIMA、ANN、SVR、LSSVR 相比,KELM模型具有更高的预测精度和稳健性。与采用BP神经网络的旅游预测相比,KELMs 具有一定的优势:预测仅包含一个隐含层,能够实现快速游客量预测,减少了模型训练时间,避免了采用梯度下降、学习参数选择敏感和易陷入局部极值的问题。
LSTM学习网络是RNN在隐藏层加入长短期记忆单元后形成的一种新神经网络模型,包含遗忘门、输入门、输出门3 个控制门,LSTM 独特的门结构能够在最优条件下确定所通过信息特征[46]。考虑日流量预测数据有非线性,同时受多个解释变量和环境变化影响,解释变量与实际游客量的滞后性3 个特点,传统的计量经济模型不能完全挖掘解释变量与实际旅游量之间的复杂关系。Bi等[47]将LSTM模型(图4)应用于景点的日流量预测中,基于搜索引擎数据和天气数据对九寨沟和黄山两个不同景点的日游客量进行预测,预测效果明显优于传统的天真模型、ARIMAX、ANN和SVR模型。在对海南省游客量预测时,Zhang等[48]指出LSTM模型有3 方面的优点:①额外的存储单元和特殊的网络结构使LSTM能够在较大的样本下学习客流时间序列的复杂动态信息,能够有效学习游客量的特征信息,明显提高了模型的预测能力;②网络搜索指标的引入使得LSTM模型更好地拟合了旅游饭店的过夜客流动态,显著提高了LSTM网络的预测性能;③优化算法的不同和网络结构设计的特殊使得LSTM 的学习能力和预测能力明显高于BP 神经网络。虽然LSTM 能在一定程度上解决梯度消失和预先人工设定阈值问题,但是当序列超过一定限制后,梯度还是会出现消失现象。
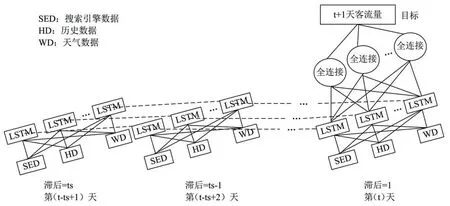
图4 日游客量预测的LSTM结构Figure 4 The LSTM architecture for daily tourist volume prediction
SAEN是一种组合堆叠自编码神经网络(SAE)和回声状态网络(ESN)的网络集成预测模型,利用SAE提取高维、非线性、动态变化的网络搜索指数特征,再结合ESN对网络搜索指数特征和游客量进行建模,提升预测模型效能。Lü 等[49]采用SAEN 模型预测了美国到加拿大的月度出境游客量、国外到北京旅游的月度入境游客量、国内到海南的月度游客量、国内到九寨沟的周游客量4 个案例,发现与传统统计方法和浅层机器学习方法相比,SAEN具有良好的时序拟合能力,预测准确度提升了40%。预测体系结构如图5 所示。与采用梯度下降算法的LSTM相比,SAEN采用最小二乘拟合法训练,具有计算速度快,节省计算成本的优势,但也会面临两个问题:初始参数的随机设置,可能导致SAEN 网络不稳定;SAEN运用最小二乘法一次性拟合训练数据,如果网络内部储备池不具备相当规模的神经元,可能会导致未知数据的过度拟合。

图5 SAEN游客量预测体系结构Figure 5 SAEN tourist volume prediction architecture
2.4 组合预测模型
在游客量预测中,不同模型对游客量长短期预测精度是不同的[26,50,51],没有一种模型在任何情况下都优于其他模型。由于旅游数据具有线性和非线性特征,采用线性和非线性组合模型预测游客量,可兼顾各模型的优势,提高预测精度。目前,采用线性和非线性组合模型预测的研究主要有两类:①采用线性或非线性模型拟合原预测模型残差的组合模型。如Wen等[52]将ARIMAX 模型的残差和前一步预测结果作为非线性自回归与外生变量(NARX)模型的输入,预测我国31 个省份到香港特区游客量,与基础模型相比,具有较强鲁棒性与泛化能力。Yao等[53]在预测九寨沟游客量时,首先引入自适应粒子群算法(APSO)自动更新权值,克服了粒子群算法的振荡和早期收敛问题,对SVR 的参数进行优化,再采用ARIMA模型拟合SVR 模型预测的残差时间序列,构建的SVR-ARIMA 模型取得了较好的预测效果。②对不同频数据采用线性和非线性模型组合预测。如李晓炫等[8]、陆利军[54]考虑网络搜索数据与旅游历史数据易受随机因素的影响产生噪音,提出了基于网络搜索的EMD去噪与BP神经网络结合预测方法,具体为:先利用EMD 将高频噪声从原序列中分离,再对低频和高频数据分别采用计量回归和BP神经网络进行拟合,预测误差均显著低于基准模型。
3 展望
为了推进旅游产业稳定可持续化发展,旅游管理部门应更加重视科学优化配置旅游资源,推动互联网旅游数据在游客量预测的快速发展和应用。本文在对互联网旅游数据的游客量预测方法研究现状和存在不足进行综述的基础上,提出未来应重点关注以下4 个研究方向:①智能化提取预测能力搜索关键词的研究。准确预测游客量的前提是从海量的互联网旅游数据中尽可能多地提取有效信息。对复杂多变的互联网旅游数据而言,仅依靠手动提取出具有预测能力搜索关键词的方法,存在工作量大、噪声干扰等问题。深度学习能在一定程度上克服此类问题,如DBN 和CNN 均具有在多引擎数据中智能化提取预测关键词的能力,可降低搜索引擎数据的噪声和无关信息,但有关智能化提取关键词的研究仍较少,有待进一步深入研究。②非结构化社交媒体数据转化为结构化时间序列数据的方法研究。在进行旅游预测时,需将社交媒体数据中出现的文本、图像和视频等非结构化数据转换为结构化时间序列数据。现有采用自然语言处理、文本挖掘、深度学习和情感分析处理的方法已经在文本数据对目的地形象感知的研究得到广泛应用,后续研究中,经自然语言处理、文本挖掘等方法处理后的非结构化文本数据是否具有预测游客量的能力,以及图像和视频数据的结构化转换方法研究也应得到重点关注。③融合互联网多源大数据预测游客量研究。搜索引擎数据蕴含有反映预测游客量的重要信息,在基于互联网数据的游客量预测研究领域有一定的普适性,但无法得到游客的情绪指标因素,难以应用于旅游目的地资源配置实践中;社交媒体数据可采用文本分析的相关方法构建游客情绪指标,但社交媒体数据获取较复杂,且预测精度受所选非结构化数据处理方法影响较大。虽然已有文献[3]综合搜索引擎数据与社交媒体结构化数据开展了游客量预测研究,但是由于没有充分分析社交媒体中非结构化数据的影响,难以全面反映游客偏好。在后续研究中,需要考虑将互联网多源大数据纳入游客量预测模型中,研究多类型、多特征数据的组合预测模型,以获取更准确的预测结果。④高维非线性混频数据的处理方法研究。互联网旅游数据呈现出高频性、高维化、非线性三大主要特征,在对游客量预测过程中,既要充分保留高频数据信息,又要从高维变量中剔除噪音数据、识别重要预测数据,同时对变量间的潜在非线性关系进行识别与探究。虽然基于高维非线性混频数据游客量预测研究方法还较少见,但是在经济金融领域已经开展了研究。综合混频数据分析方法、高维变量选择方法和机器学习方法开展游客量预测更加符合实际,有待进一步深入研究。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
北方经贸(2017年4期)2017-06-30
今古传奇·故事版(2016年24期)2017-02-07
人间(2016年27期)2016-11-11
海外英语(2013年8期)2013-11-22
人生与伴侣·共同关注(2009年18期)2009-08-31
