
系统动力学方法在区域需水量预测中的应用综述
2022-07-31 11:05秦欢欢
人民珠江 2022年7期
秦欢欢
(1.东华理工大学核资源与环境国家重点实验室,江西 南昌 330013;2.东华理工大学水资源与环境工程学院,江西 南昌 330013)
区域需水量预测是指对区域用水历史数据进行分析,获得该区域用水的规律,然后通过一定的数学方法来研究、模拟该区域未来的用水量[1-2],是区域水资源可持续利用与管理的重要依据[3-4],其过程涉及诸多复杂的因素,如经济、水文、气象、社会、工程、技术、产业结构、工农业发展等[5-8]。在进行水资源规划时必须对研究区未来的需水量进行有依据的科学预测,以此来确保研究区供需水系统的统筹管理与优化处置。根据区域历史用水量数据、社会经济结构以及发展规划,科学、合理、准确地预测区域未来的需水量,对于该区域水资源的可持续利用与管理有十分重要的意义[2,9-13]。
目前,区域需水量预测中常用的方法有很多,如定额法[14]、指标法[2]、时间序列法[15-17]、灰色预测模型法[18-21]、神经网络法[22-25]、多元线性回归法[26-29]、主成分分析法[30-33]和系统动力学法等[3,5,34-44]。由于需水量预测中涉及的影响因素较多,大多数传统的预测方法无法刻画这些复杂因素及其相互之间的反馈关系和动态过程,也无法定量衡量这些因素对需水量预测过程的影响与作用程度,也就无法捕获区域需水量的系统行为[45-46]。系统动力学法较好地解决了这些问题,被广泛地应用于区域需水量预测[3-5,34-44,47-52]。
作为一种系统仿真的研究方法,系统动力学(System Dynamics,SD)于1956年被提出[53-57],它是一门集合了诸多自然学科和社会学科的交叉学科,目的在于从定量的角度去识别和解决复杂的、具有多个反馈回路的系统性问题,有着较为显著的处理问题的优势,已被广泛应用于生态环境、工农业等方面[34,45,58-63]。SD可以对需水量预测过程中涉及的多因素耦合的复杂巨系统进行定量分析与模拟,能够较准确地捕获影响需水量大小的诸多因素之间相互反馈的动态关系,可以为区域水资源可持续利用与管理提供科学的依据和建议,有利于实现区域资源环境与社会经济的可持续发展[64-67]。
1 SD方法概述
SD是由美国的Forrester教授创立的仿真方法,其最初的目的是为了解决企业的库存及生产管理相关问题。之后SD方法得到了巨大的发展,其应用逐步扩大至社会生活的大部分领域,进而形成了系统动力学这一新兴的自然与社会相结合的交叉学科[53-57]。SD方法的发展过程离不开系统论、控制论和信息论的支撑,也是一种结构、功能和历史的方法的有机统一体。对于需要解决的问题,SD方法基于该问题对应的系统的行为及其背后蕴藏的物理机制之间相互依赖的关系,采用数学建模的方式来构建导致该系统出现动态变化的因果关系,从而对系统现状及未来的行为进行定量的模拟与分析。一般来说,SD模型的主要变量包括流位变量、流率变量、辅助变量等。
SD方法处理的问题有如下基本概念。
a)反馈。系统中某一单元的输入输出之间的关系即为反馈关系,也是信息的传输关系,包括正反馈与负反馈两种。前者指的是能加强原有发展趋势的反馈关系,后者指的是能减弱原有发展趋势的反馈关系。
b)系统结构。指的是系统中某一单元的秩序,即构成该系统的各个单元本身以及各个单元之间相互关系与作用,这些单元及其关系构成了系统的固有特征。
c)累积变量和速率变量。它们是组成某个系统的反馈回路中的2种性质迥异的变量,前者刻画的是系统变化过程中产生的累积效果,描述了该系统在某个时刻的状态,后者是累积变量变化快慢的定量化指标。
DYNAMO (DYNAmic MOdels)主要采用差分方程描述有反馈的社会系统的宏观动态行为,并通过对差分和代数方程的迭代求解进行计算机仿真、用于SD方法定量化模拟的专用计算机语言,该语言有多种不同的具体软件形式,包括VENSIM、POWERSIM、STELLA等。VENSIM Professional版本的软件是SD数值模拟过程中用得比较普遍的一款DYNAMO软件,它具有可视化建模过程、强大的结构分析、便利的数据集分析、详细的真实性与合理性判断、具有汉化版本等诸多优点,在SD方法的应用过程中得到了很好的推广与实施。
2 系统动力学在需水量预测中的应用
一般而言,根据主要用水部门的不同以及各用水部门的复杂性与变化性,需水量预测可分为生活、工业、农业和生态环境四大部分。需水量预测的周期分为短期预测和中长期预测,其中短期预测指的是以月、周或天为周期的预测,中期预测指的是以1~5年为周期的预测,而长期预测指的是以6年及以上为周期的预测。系统动力学方法可以进行不同周期的需水量预测,都具有较好的预测效果,但一般常见的应用是对区域进行中长期的需水量预测。
区域需水量预测的SD模型一般将研究区的人与自然耦合系统划分为需水模块与供水模块,前者包括生活、工业、农业和生态环境需水,后者包括地表水、地下水、污水回用和区域外引水(图1)。需水模块和供水模块共同决定了区域水资源的供需平衡状况,进而进一步影响区域水资源可持续利用情况。通常情况下,一个区域的供水量是相对稳定的,因此,需水量就成为区域水资源供需平衡的关键模块,需水量预测在区域水资源可持续利用过程中起着非常重要的作用。
2.1 生活需水量预测
生活用水量指城乡居民日常生活的用水,以及机关企事业单位、公共场所、商业办公楼栋、娱乐文化场所等建筑内的用水[2]。一般来说,生活需水量的大小与人口规模、经济发展、城镇化水平、气象因子(气温和降水)、水价大小以及区域节水机制等因素相关。在运用SD模型预测生活需水量的研究中,主要有考虑物理机制的生活需水量预测[43]、考虑宏观经济模型的生活需水量预测[4-5,68-69]、采用用水定额进行生活需水量预测[35,37,70]、耦合社会-水文多因素的生活需水量预测等[71-72]。陈颖杰等[43]以黄河流域为例,构建了考虑物理机制的需水量预测系统动力学模型,分析预测了多因子驱动及多要素胁迫作用下研究区2017—2030年的生活需水量。结果表明,黄河流域生活需水量随人口及用水需求的增加而不断增长,2030年不同情景下黄河流域生活需水量为48.06亿~50.98亿m3。秦欢欢等[4]通过建立考虑宏观经济模型的系统动力学模型,对北京市2019—2030年的需水量进行了预测。结果表明,不同情景下2030年北京市生活需水量为19.88亿~22.26亿m3。易彬等[71]采用社会-水文多重因素耦合的SD建模方法,建立了珠江上中游生活需水量预测SD模型,预测了未来需水量的变化情况。他们的研究结果指出,珠江上中游地区未来生活需水增量较小,总体趋势平稳;2050年广西、云南和贵州部分生活需水量分别为31.33亿、6.18亿、5.55亿m3。Qin等[72]采用社会-水文耦合的SD模型对华北平原2019—2028年的生活需水量进行预测,得到2028年华北平原的生活需水量为80.69亿~80.73亿m3。表1是不同研究区域生活需水量预测结果的比较,从中可以看出,SD法在生活需水量预测中的应用范围的尺度较宽泛,既可以是城市尺度,也可以是流域/区域尺度,而且采用不同的预测方法均可以构建SD模型进行生活需水量的预测,结果具有较好的适用性。
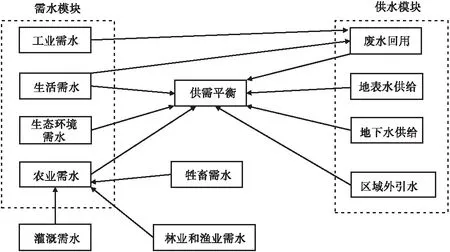
图1 区域水资源供需模块及影响因素示意
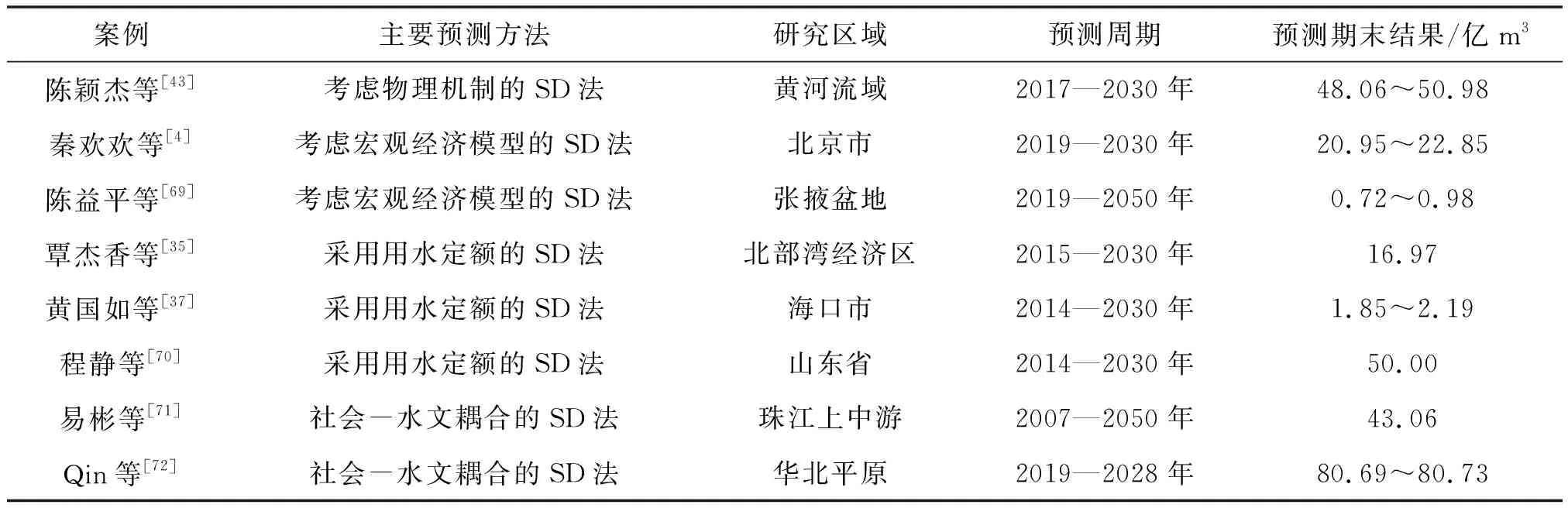
表1 不同研究区域生活需水量预测的比较
虽然生活需水量预测的SD模型有许多类型,但它们都从不同程度和角度考虑了影响生活需水量的自然、社会、经济和管理因素,用定量的方法对不同的研究区进行了生活需水量的预测。鉴于研究区域的差异性和数据的可获得性,这些不同的SD模型模拟结果都证明了它们在研究区的适用性。对于其他的研究者来说,这些SD模型和案例具有较好的借鉴性,但研究者需要根据具体的情况进行评判和选择。
2.2 工业需水量预测
工业用水量指工业产品的生产加工过程中直接或间接消耗的水量[2],其大小受到多种因素的影响,包括GDP、收入、用水及节水技术的进步、工业水价格、管理水平、政策因素等。在工业需水量预测的SD模型中,主要有考虑宏观经济模型的预测方法[4,68-69]、考虑物理机制的预测方法[43]、基于多种方法结合的预测方法[73-74]、系统动力学与分块预测相结合的预测方法[75]、耦合社会-水文多因素的工业需水量预测[72]等。吴泽宁等[73]采用定额法、回归分析法和系统动力学法相结合,预测郑州市2025年的工业需水量为7.086亿~7.163亿m3,2030年的工业需水量为8.619亿~8.876亿m3。刘二敏等[75]利用系统动力学方法和分块预测法对中国沿海某市的工业需水量进行预测,结果表明该市2030年的工业需水量为2.404亿m3。该方法适用于基础数据不足、用水量有突变等情况下的工业需水量预测。陈益平等[69]采用宏观经济模型和系统动力学相结合的方法对张掖盆地的需水量进行预测。2019—2050年平均来说,5种不同情景下张掖盆地的工业需水量分别为1.75亿、3.24亿、2.15亿、1.71亿和2.16亿m3,工业需水量在预测期内保持增长的趋势。Qin等[72]采用社会-水文耦合的SD模型对华北平原2019—2028年的工业需水量进行预测,得到2028年华北平原的工业需水量为25.09亿~25.27亿m3。表2是不同研究区域工业需水量预测结果的比较,与生活需水量预测类似,SD法在工业需水量预测中的应用范围的尺度也较宽泛,既可以是城市尺度,也可以是流域/区域尺度,而且采用不同的预测方法均可以构建SD模型进行工业需水量的预测,具有较好的适用性。

表2 不同研究区域工业需水量预测的比较
工业需水量的大小受到诸多因素的影响,其变化比较复杂,要想较准确对区域的工业需水量进行预测有一定的难度,不同的预测方法对工业需水量预测的精确度有较大影响[76]。运用系统动力学方法预测工业需水量,虽然有其特有的优势性,但一般也需要与其他方法相结合,采用多种方法进行预测,才能保证有较好的预测效果。
2.3 农业需水量预测
农业用水量指用于农业生产、林业灌溉和牲畜、家禽及鱼类饲养的用水量[2],可以分为灌溉需水量、牲畜需水量和林渔需水量三大部分。灌溉需水量通常采用灌溉定额法的预测[39,72,77-78]、基于作物的水文与农学特征的预测[4-5,68-69,79]以及考虑物理机制的预测[43]等。牲畜需水量和林渔需水量通常采用定额法进行计算[2,4]。
对于考虑水文过程和农学特征的灌溉需水量预测方法,区域灌溉需水量可以采用以下公式进行计算[80-82]:
(1)
式中 cp、st——作物的种类、生长阶段指数;kc、A——农作物指数、面积;ET0——作物的参考蒸散发;LR——盐分浸出因素,通常为总灌溉水量的10%~15%;BE、ER、NIrWD——灌溉水利用系数、有效降水量和作物净灌溉需水量。
对于考虑物理机制的灌溉需水量预测方法,区域灌溉需水量的计算公式如下[43]:
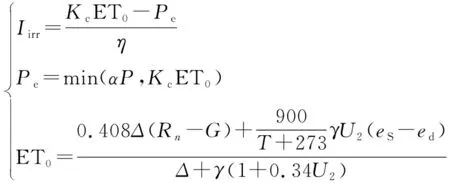
(2)
式中Iirr——灌溉需水定额;η——灌溉水利用系数;Kc——农作物系数;ET0——作物的参考蒸散发;Pe——有效降水;α——有效降水系数;Δ——饱和水汽压与温度曲线斜率;Rn——冠层表面净辐射;G——土壤热通量;T——平均温度;eS——饱和水汽压;ed——实际水汽压;γ——湿度计常数;U2——2 m高处风速。
来风兵等[77]采用定额法对新疆艾比湖流域的农业需水量进行了预测,预计农业需水量将由现状的29.76亿m3增长至33.39亿m3。陈颖杰等[43]考虑了基于物理机制的农业需水量预测方法,对黄河流域2017—2030年的农业需水量的变化趋势进行了预测,结果表明灌溉需水量呈下降的趋势。粟晓玲等[79]考虑了水文和农学特征的灌溉需水量预测,对石羊河流域进行了模拟,结果表明农业供水量和需水量受气候变化的影响程度不同,但2033年以后,农业供水量在不同气候变化情景下的变化趋势相同;不同行政区农业水资源系统对气候变化的响应存在明显差异。表3是不同研究区域农业需水量预测结果的比较,与其他两类需水量预测类似,SD法在农业需水量预测中的应用范围的尺度也较宽泛,既可以是省市尺度,也可以是流域/区域尺度,而且采用不同的预测方法均可以构建SD模型进行农业需水量的预测,具有较好的适用性。
2.4 生态环境需水量预测
生态环境需水量的预测涉及多学科、多因素,与其他需水量相比更加复杂,对其进行预测的难度也更大,目前中国在这方面还处于初步的研究阶段[2]。一般来说,在SD模型中,生态环境需水量通常作为模型的输入变量,在模型中不进行计算,通常由建模者根据研究区的实际情况和区域水资源利用与管理规划,基于现状的生态环境需水量进行适度增长的计算。

表3 不同研究区域农业需水量预测的比较
3 方法评价与研究展望
3.1 需水量预测SD方法评价
区域需水量预测的SD方法可以在一个综合模型中包含和分析水文、社会、经济和环境等因素以及气候与非气候情景下的管理措施,以了解复杂系统的动态行为及其对干预措施的反应[57,82-83]。SD方法在区域需水量预测中应用的共同之处是对不同尺度和形态的研究区域均能构建较完整、全面的社会-经济-水文-环境耦合模型,进而对不同研究区的需水量进行预测。这种跨尺度、跨经济发展区的应用说明了SD方法的广泛适用性,而且不同研究案例中模型校准和验证的结果也证明了SD方法在需水量预测中的合理性,表明SD方法可以运用于区域中长期的需水量预测,这对于合理制定水资源利用战略意义重大[64]。然而,SD方法在需水量预测中的应用还有一些局限与不足之处,具体包括。
a)尽管SD模型已被证明是一系列子系统的有效建模工具,但将系统边界扩展到包括水文、社会、经济和环境子系统比单独考虑每个系统时引入的复杂性更大。这种复杂性通常由不同的时间和空间尺度以及不同子系统的因素之间的多重交互作用驱动。因此,建模者在开发概念模型、校准和验证复杂水资源系统方面面临困难——这是规模和复杂性之间差异的结果。
b)由于非线性、反馈和延迟,水资源管理系统具有高度的不确定性和动态复杂性,这给决策者带来了挑战。此外,水资源系统具有空间和时间特征,因此需要同时检查时间和空间模式,以了解整个系统的动态行为[84]。然而,SD模型在处理水资源系统中的不确定性和空间动态方面具有固有的局限性,特别是在气候变化影响的驱动因素下,因为SD不太适合包括导致这些不确定性的定性观点[85]。为了应对气候变化影响中的不确定性,一些建模者在不同的数值范围内开发了合理的情景,并进行了敏感性分析,以产生更广泛的合理建模结果,并揭示对结果影响最大的参数或模型组分[86-87]。
3.2 研究展望
区域需水量预测是有关部门规划、管理水资源的重要依据,也是区域供水系统优化管理的重要部分。在社会经济快速发展的当下,准确合理预测区域的需水量能够有效缓解区域供需水的矛盾,确保区域资源与环境的可持续发展。在SD方法在区域需水量预测中中国学者做了大量的工作,有力地促进了该研究领域的发展。未来,SD方法在区域需水量预测中应用的发展趋势和方向主要有以下两方面。
a)研究区域尺度的扩展。目前,大部分学者将SD方法应用于区域需水量的预测,其研究区域的尺度一般为城市、省和流域等中小尺度。未来,国家、全球等大尺度区域是需水量预测的发展趋势之一。一方面,水资源供需矛盾问题在世界范围内都是一个非常重要且突出的问题,从大尺度角度进行需水量的预测,可以为国家和全球的水资源可持续利用和发展提供科学、有效的指导。另一方面,一般来说,研究区域的尺度越大,其所具有的基础数据越丰富,用于SD模型的参数则会更可靠,SD模型的校准与模拟结果会更精确,需水量的预测结果也就更加具有实际指导意义。与此同时,在大尺度的区域进行SD模型建模,可以对某些因数据或其他原因而不便考虑和模拟的因素对模型的影响降低,甚至在一定程度上可以忽略这样的一些因素,这对于SD模型在需水量预测中的准确性和说服力都有很大的提升。因此,大尺度区域的需水量预测是未来SD方法应用的趋势之一。
b)加强与其他方法的结合与互补。如前所述,需水量预测的研究中,为了实现方法之间的优势互补,已有将SD方法与其它方法结合的案例。然而,这种方法间的结合还需进一步的加强。作为一种半定性半定量的方法,SD模型对于变量之间的定量关系的要求低于对于模型系统逻辑结构的要求。为了更精确预测区域的需水量,需要根据不同用水部门的用水结构和特点,在进行定量的模型模拟和预测时,可以将遗传算法、定额法、神经网络等方法与SD方法相结合,充分发挥它们各自的优势,使得定量化的需水量预测更加合理、准确。
猜你喜欢
水土保持通报(2022年3期)2022-10-15
建材发展导向(2022年12期)2022-08-19
农业机械学报(2022年7期)2022-08-08
江苏科技报·E教中国(2022年5期)2022-05-11
中国科技纵横(2021年10期)2021-11-29
马克思主义哲学研究(2020年1期)2020-11-26
科学与财富(2020年10期)2020-10-21
水能经济(2018年1期)2018-10-14
安徽农业科学(2017年18期)2017-07-10
太空探索(2016年5期)2016-07-12
