
基于关键字的数据元语义描述方法
2022-07-29 03:31胡青宁董金平李婷玉苏宏伟
东北石油大学学报 2022年3期
胡青宁, 董金平, 李婷玉, 田 源, 苏宏伟
( 1. 中国石油冀东油田分公司 勘察设计与信息化研究院,河北 唐山 063004; 2. 中国石油冀东油田分公司 科技信息处,河北 唐山 063004 )
0 引言
中国石油开展石油数据湖建设,统一管理上游业务油气勘探开发领域的数据资产。石油数据湖由主湖和区域湖构成,主湖负责统一管控和公共数据管理,区域湖负责区域性数据存储及服务[1]。区域数据湖不仅要管理主湖范围的业务数据,还要管理大量油田自建数据库系统。油田区域数据湖中的数据库具有多源性、多层级、多维度的特点,没有定义统一的行业领域数据标准,因此不同数据库、不同层级的管理、不同角度的应用采用的数据相关术语、数据项标识有较大差异,存在大量同名异义、异名同义的数据项名称,导致出现数据错误引用、数据查找难、数据理解难等问题,给数据的管理和使用带来困扰。
为解决数据标准化,ISO发布系列标准ISO/IEC 11179-1~6,对数据元的框架、分类、模型、定义、命名、注册等进行规定[2],并持续性改进,国家标准GB/T 18391系列等同样采用该系列标准[3]。石油行业标准和中石油企业标准也发布数据元设计原则[4]和数据元设计指南[5]。目前数据元相关的标准主要从数据的规范化命名表达数据元的语义,在中文数据项名称的规范作用上有限[6]。
数据元语义描述方法可用数据元的概念继承关系和关联关系表达概念的语义。文献[7]利用语义泛化层级表达数据元语义,根据中医临床症状术语描述特点,研究中医临床症状数据元提取的方法、路径和原则,并给出符合实际应用的三层提取模型,从概念层、通用数据元层、应用数据元层提取数据元。文献[8]利用数据元构建通用领域知识图谱,提出一种综合相似度计算与知识图谱融合的语义查询扩展算法。文献[9]提出一种基于数据元的数据集成方法,通过对概念的内涵进行形式化的语义描述,可以实现不同模型之间模型级与实例级的语义映射。概念表达语义受上下文语境影响,随概念外延的扩展,容易产生歧义。为了更加规范、准确地描述数据元的内涵语义,文献[10-11]提出数据元语义树,将领域本体概念及概念之间的关系作为语义树节点和边,表达数据元特性词、对象词、限定词及之间的关系,并定义基于语义树结构的语义计算方法。基于数据元语义描述方法,文献[12]进一步扩展到数据模型的语义描述,将数据模型中实体的语义环境表达为语义树,与实体的各属性语义树共同表达实体的语义。基于语义树的数据元语义描述方法需要构建语法严格的树形结构,同时依赖预先建立的领域本体,增加语义描述的复杂度和构建成本。
关键字研究多集中在搜索引擎、自然语言处理、图像处理等领域。如基于结构化数据和非结构化数据包含大量语义信息,LOU Y等[13]通过计算语义信息的信息熵确定关键词的语义相关性,利用关键词与语义的相关度,构建基于信息熵的语义模型,从而提高搜索结果的准确性。文献[14]提出一种利用语义信息改进关键字检测的自动抽取摘要方法,通过对句子进行聚类识别源文档中的主要主题增加覆盖率,通过检测聚类中的关键字提高精度。NGUYEN N V等[15]提出图像—关键字的双向转换关联模型,基于处理图像表示的最先进的词袋模型,表示语义概念和视觉特征之间的关联,使用交互式增量学习策略不断更新关键字视觉表示模型。在数据元语义表示上,使用关键字的研究相对较少,主要集中在数据元的语义计算方法上,如数据元语义相似性、相关性、数据映射等。文献[16]综合考虑语义相似度和语义关联度的概念语义相关度计算方法,提出一种基于数据元语义树的概念语义相关度计算方法。文献[17]利用语义相似度算法进行数据元间的相似性、一致性的检查,搜索数据元间的匹配关系,建立数据模型间的属性级的映射关系。文献[18]提出一种数据项与数据元匹配算法,计算数据项与数据元的相似度,实现数据项与结构化数据项的映射。
针对语义树描述数据元语义具有较高的复杂性和关键字描述数据元语义的研究缺乏,笔者提出一种简易的数据元语义描述方法。首先,分析基于语义树的数据元语义描述方法中语义树构建与应用的特点;然后,给出基于关键字的数据元语义描述方法与匹配算法;最后,构建油田区域数据湖的数据元字典及数据模型映射,验证该方法的有效性。
1 语义树方法
数据元是基本的、不可分割的数据单元,用一组属性描述其标识、定义、允许值和表示[2]。在数据元的相关规范中,数据元的语义通过三种方式进行定义或扩展。首先,通过规范的名称,明确表达数据元的语义;其次,以文字方式说明数据元的含义、使用方式等。此外,通过数据元的数据类型、管理模式等外部信息侧面表达数据元语义。数据元标准专门规定数据元的语义规则[6]:
(1)对象词是对现实世界事物的抽象描述。一个数据元只有一个对象词,如井、水管、设备、管柱。
(2)特性词是对象特性的描述。一个数据元只有一个特性词,如长度、深度、外径、内径、尺寸、压力、产量。
(3)限定词根据主题域需要添加,添加限定词后,其修饰的主词在指定上下文中唯一。一个对象词或特性词可以有多个限定词,限定词无顺序要求。此外,限定词可以拥有自己的限定词,如悬挂尾管、回接尾管、下入深度、年产量。
(4)表示词用来描述数据元素值呈现的方式。一个数据元只有一个表示词,如吨作产量的表示词时,用“吨”而不用“桶”。
数据元采用对象词、特性词、表示词、限定词等语义元素对名称规范命名是按照英文的语法结构定义的,不适合中文环境,因为中文语法结构不完全等同于英文,中文没有空格对各词进行分隔,且分词不同,造成语义也不相同[19]。时贵英、文必龙等提出利用语义树描述数据元语义[9-10]的方法,将数据元名称中的语义元素,按照元素之间的限定或修饰关系,使用语义树的方式表达为树形结构(见图1)。
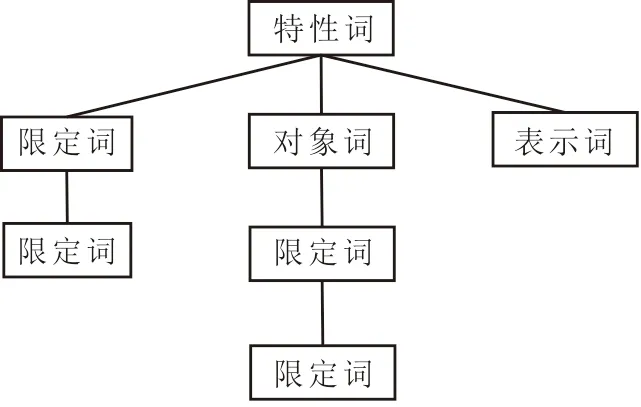
图1 数据元语义树结构Fig.1 Structure of data element semantic tree
构建数据元语义树包括两个基本元素:一是语义树中的节点,由对象词、特性词、表示词、限定词及约束条件构成;二是节点之间的连线,表示节点对应词汇之间的限定关系。在定义语义树的过程中,节点名称与节点关系的梳理复杂,文献[8]采取从领域本体获取相关内容,将一个数据元的语义树看作一个领域本体的子集,通过裁剪领域本体生成语义树。分析基于本体构建语义树的方法主要受三方面限制:
(1)语义树中的节点来自领域本体的概念;
(2)语义树中的节点之间的连接关系来自于领域本体中概念之间的关系;
(3)语义树中的约束条件节点需要遵循相应的语法规则。
如果解除限制(1)(2),除节点名称及连接关系的规范性外,并不影响对数据元语义的定义和理解;对限制(3)将约束条件修改为对约束节点的限定词,不影响节点的语义。
1.1 数据元描述
通过对数据元语义树结构与构建特点分析,提出一种基于关键字的数据元语义描述方法。
定义对任一数据元e,e的语义可以表达为一个关键字集合K(e),称K(e)为e的语义关键字集,即
K(e)= {pty, obj, pre}∪Qobj∪Qpty∪C。
其中,pty为e的特性词;obj为e的对象词;pre为e的表示词;Qobj为obj的限定词集合;Qpty为pty的限定词集合;C为约束条件中的常数值集合。按照语义树定义,约束条件可以表达为逻辑条件表达式,如数据元“新井日产油量”中,约束条件可以用“井的计产类型=‘新井’”或用“井的投产日期>新井计算日期”表示。
将C中的常数值作为相应的限定词划分到Qobj与Qpty中,把pre划分到Qpty,得出进一步简化结果,即
K(e)={pty,obj}∪Qobj∪Qpty。
实际应用中较少有复杂的约束条件,并且约束条件表达式中通常有常量和属性,应用中大多忽略属性,如“新井日产油量”的新井,每年统计时条件相同,但在油田都知道新井的含义。因此,可以把约束条件中的表达式直接用其中的常数替代,不会影响数据元表达的语义。此外,为了将数据元的语义直观化,便于理解,将K(e)中关键字及关系表达为语义树(见图2)。
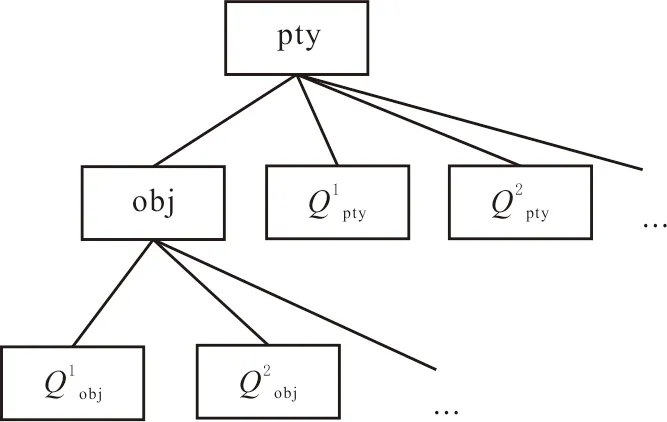
图2 基于关键字的数据元语义树Fig.2 Data element semantic tree based on keywords
基于关键字的数据元语义存储示例见表1。

表1 基于关键字的数据元存储示例
比较基于关键字的数据元语义树和基于本体的数据元语义树,结果见表2。在简洁性、理解性和灵活性上,采用关键字描述数据元的方法比基于本体的描述方法占有一定优势,适合工程化应用。

表2 数据元语义描述方法特性比较
1.2 数据模型
基于数据元描述数据模型的语义,是为数据模型中实体的属性指定一个数据元,确认采用指定数据元的定义,包括语义、数据类型等[12]。
定义实体r(a1,a2,…,an)的语义用关键字表示为
K(r)=Qr∪K(a1)∪K(a2)…∪K(an)。
其中,ai为r的属性;Qr为r的应用场景的关键字集;K(ai)为属性ai的语义关键字集。
定义实体r(a1,a2,…,an) 的任一属性ai的语义用关键字集表示为
K(ai)={pty,obj}∪Qobj∪Qpty。
其中,pty、obj、Qobj、Qpty与数据元中定义相同。
在企业应用环境中,数据元通常采用数据元标准化字典进行定义,具有企业领域范围内的通用性。数据模型是对企业的具体应用场景定义,具有一定的特殊性。在许多场合下,并不能为数据模型中的所有实体属性找到对应的数据元。在无法为实体属性找到对应的数据元时,需要利用数据元概念的泛化层级性,通过数据元关键字扩展描述实体属性的语义。数据元按概念的泛化层级分为数据元概念、通用数据元、应用数据元。
数据元概念(Data Element Concept)是与数据元具体表现形式无关的数据元。在语义上,数据元概念不包含表示词[2]。如“日产油量”是数据元概念,因为产油量可以用“吨”表示,也可以用“桶”表示,没有指定表示方式,因此是数据元概念。通用数据元是适合不同应用场景的数据元,应用数据元是与具体应用场景相关的数据元。通用数据元与应用数据元是相对于一定的应用环境而言的,二者之间并没有本质的区别,只是应用场景大小的问题。应用数据元是通用数据元在应用场景下,进一步限定后生成的数据元,通用数据元可以看作被泛化的应用数据元。数据元、通用数据元和应用数据元之间的关系用数据元的语义关键字集表示为
K(e2)=K(e1)∪pre∪Q2,K(e3)=K(e2)∪Q3。
其中,一个数据元概念e1加上表示词,可以演化为通用数据元e2。通用数据元e2加上应用场景约束,可以演化为应用数据元;K(e1)、K(e2)分别为数据元e1、e2的关键字集合;pre为表示词;Q2为描述数据元e2的应用场景的关键字集,是一组限定词或约束条件;Q3为描述数据元e3的应用场景的关键字集合,是一组限定词或约束条件。通过Q3进一步特化e3的应用场景。
实体的属性与数据元是定义数据的基本单元。数据元的语义中已经包含应用场景的定义,不需要再单独指定应用场景,每一个数据元都具有完整的语义,如数据元“采油厂日产油量”的语义是完整的。实体的属性需要依赖所属实体的环境表达,如“采油厂日报数据”中的属性“产油量”表示“采油厂日产油量”,而在实体“采油厂月报数据”中,属性“产油量”表示的是“采油厂月产油量”。按数据元的层级性,实体的属性可以用通用数据元和应用数据元表示。
由于实体的应用场景可以转化为属性的应用场景,因此利用数据元e表达实体属性a的语义,有三种情况:
(1)当ptya=ptye,obja=obje,且a与e的应用场景一致时,直接用数据元表达属性的语义,即
K(a)=K(e)。
(2)当ptya=ptye,obja=obje,且a的应用场景比e的更小时,K(a)∈K(e) ,通过扩展数据元e的关键字表达属性的语义,即
K(a)=K(e)∪Qa。
其中,Qa为a相对e增加的语义约束,Qa=K(a)-K(e) 。由于增加更多约束,应用场景的范围变得更小。
(3)当ptya=ptye,obja=obje,且a的应用场景比e的更大时,不能用e表达a的语义。需要定义一个新数据元,通常将a转换为数据元加入数据元字典。
由于数据元在领域范围内可以作为标准进行定义,因此利用数据元表达数据模型的语义,可以简化数据模型的设计及语义描述。
2 数据元语义相似度
利用数据元描述数据模型的语义,关键是找到与实体属性匹配的数据元;同时,异构数据模型自动映射时,需要判断两个实体的属性是否具有一致的语义。前提需要进行数据元语义相似度计算。
在一定程序上,数据元名称反映数据元的语义[12]。在无法完全保证数据元语义描述完整、准确的情况下,数据元名称表达的语义对数据元的理解及应用具有指导意义。提出一种综合数据元名称及关键字集合的语义相似度计算方法。
定义任意两个数据元e1、e2,其语义相似度为
(1)
式中:dsim(e1,e2)为两个数据元名称的相似度;ksim(e1,e2)为两个数据元的关键字集合之间的项集相似度;WD、WK分别为两个相似度的权重,WD+WK=1。对数据元组成成分与结构分析可知:数据元词语由语素组成,语素越靠前,作用越小,为它分配的权值越小;语素越靠后,作用越大,为它分配的权值越大[20]。此外,由于油田领域数据元的关键字较为短小,具有表达随意、稀疏性和不平衡性等特性,编辑距离算法作为基于字面进行相似度度量的方法,对短文本的处理具有可行性高、效果好等优点[21]。因此,采用编辑距离计算数据元间语义的相似度。
以中石化数据元字典中1.4×104个数据元为实验数据,通过不同因数组合发现WD=0.3、WK=0.7[22]时,满足工程化应用需要。如数据元“油井所属区块单元名称”(设定为M)与数据元“油井所属区块单元代码”(设定为N)在不同因数组合下,计算的编辑距离相似度结果见表3。
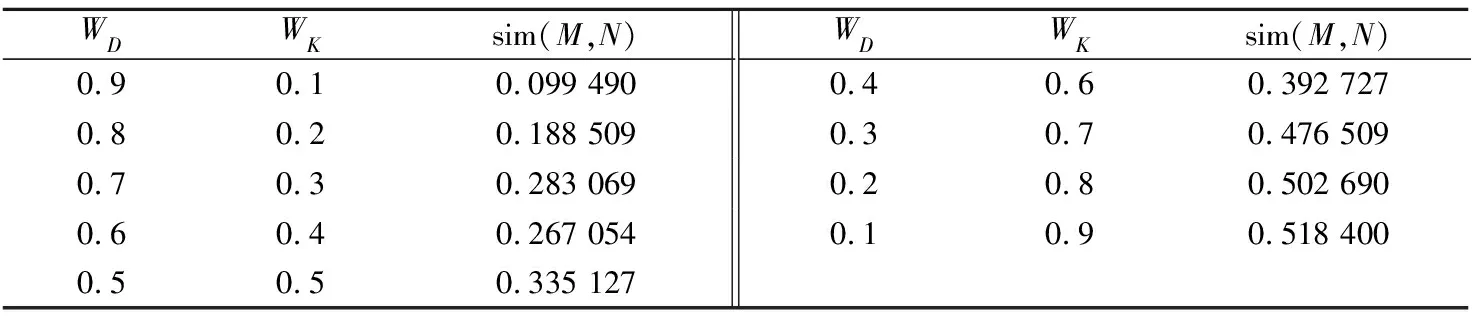
表3 不同因数组合的相似度计算结果
编辑距离算法[16,23]用dist(x,y)表示字符串x转变到y的最小成本,转换方式包括删除、插入和替换字符串。如将字符串x=“累积油产量”转换为字符串y=“累积地层油产量”的代价是dist(x,y)=2,需要执行的操作依次是在“累积”后面插入一个字符“地”,在“累积地”后面插入一个字符“层”。x和y的转换操作是对称的,将x转换为y的代价和y转换成x的代价是相同的。编辑距离越小,字符串x转变到y的成本越少,两个字符串越相似。编辑距离dist(x,y)可用公式转换为相似度度量函数DSIM(x,y),即
(2)
式中:length为字符串长度函数。两个数据元e1、e2的项集相似度公式计算为
(3)
两个集合A、B的项集相似度J(A,B)=AB的交集项个数/AB的并集项个数,即为杰卡德相似度系数(Jaccard Similarity Coefficient)[23]。杰卡德相似度系数是衡量两个集合相似度的一种指标,交集等于并集,意味着两个集合完全重合。
以数据元“尾管悬挂下入深度”为例,按照关键词分类,它的对象词是“尾管”,对象词的限定词是“悬挂”,特性词是“深度”,特性词的限定词是“下入”,在数据元字典中匹配到的前10个数据元及相似度计算结果见表4。

表4 数据元相似度计算结果示例
3 区域数据湖构建及应用
在油田区域数据湖建设中,利用数据资源目录描述油田勘探开发业务及应用系统的数据资源情况,其中数据资源目录利用数据元作为标准数据和中间桥梁,将业务模型[24]、应用数据模型、存储数据模型关联到一起(见图3)。业务模型与数据元关联后,可以从勘探开发业务角度掌握某一业务活动采用和产生的数据有哪些,数据由哪些应用系统产生,被哪些系统使用。数据元与存储数据模型和应用数据视图关联后,可实现以数据元为中介的数据模型之间的自动映射。完成应用的基础是构建数据元字典,并实现基于数据元的数据映射[25]。
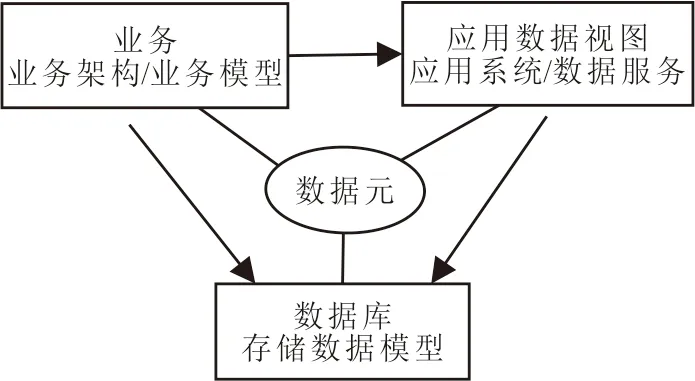
图3 油田区域数据湖中数据元与数据资源的关系Fig.3 The relationship between data element and data resources in oil field regional data lake
数据元字典的构建分四个步骤。
步骤1数据元原始资料收集。将业务模型中的数据项、应用数据视图中的数据项、存储数据模型中的数据项收集到数据元字典模板中,每一个数据项作为一个初始的数据元。数据元字典模板由基本信息、来源、语义组成,其中,基本信息包括数据元名称、代码、数据类型、长度、精度、计量单位、描述,来源由源模型、源表、源属性组成,语义由对象词、特性词、对象词的限定词、特性词的限定性组成。初始收集时,语义部分为空。收集完资料后,按数据元名称合并,合并时记录来源,同时统一数据类型相关信息。合并过程中,对于数据类型无法统一的,需要将数据元重新命名,表达为不同的数据元。
步骤2数据元语义描述。根据数据元来源信息,定义对象词、特性词、对象词的限定词、特性词的限定性,主要由人工填写。过程中,利用数据元名称的编辑距离相似度,将相似的数据元排列在一起,相互参照,可加速数据元语义定义,同时具有相互校正的作用。
步骤3数据元质量校正。根据数据元语义信息,计算数据元之间的关键字项集相似度。对每一个数据元,将与其相似的其他数据元按相似度从高到低排列,依次作为校正的参照数据元列表。校正过程分三种情况进行处理:
(1)同名异义的数据元。将数据元重命名并表达为两个不同的数据元,修改对应来源部分,依据数据元拆分为两组填写。
(2)异名同义的数据元。将两个语义相同的数据元合并成一个。
(3)语义需要修正的数据元。修改数据元的语义信息。
步骤4确认数据元,并适当修改源头模型的信息。对数据元名称、代码规范化,并按照数据元的规范定义,修改源头信息。
基于数据元的数据模型映射包括存储模型之间的映射、存储模型与应用数据视图之间的映射。以数据元为中介,通过数据元匹配,自动建立两个模型间的映射关系。对于不能完全匹配,但有较高相似度的,作为可能映射关系。
在数据湖的建设中,完成12个业务域梳理,采用基于关键字的数据元相似度融合方法,构建数据湖数据元字典,约有2.0×104个数据元,比中石化数据元字典增加超过6.0×103个,统计结果见表5。

表5 数据元统计结果
对钻井、测井、油气生产、采油工程四个业务域应用数据视图与存储数据模型自动映射,对比结果见表6。基于关键字的数据元语义自动数据映射,在匹配结果上删除干扰项,得到唯一对应的数据元,提高数据湖开发效率及应用的准确性和灵活性。
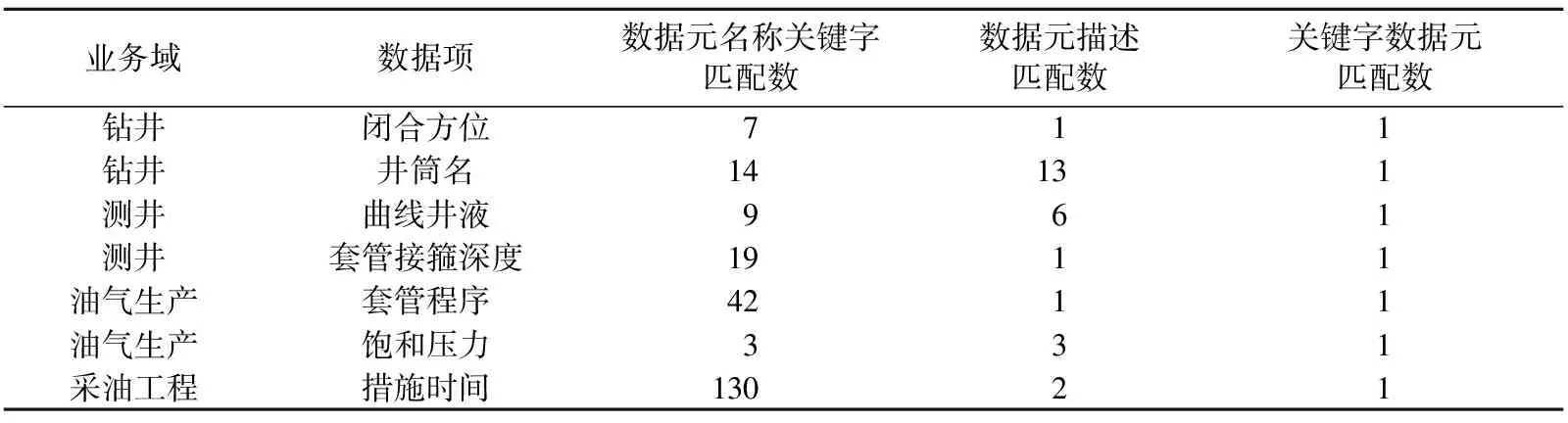
表6 基于数据元的数据模型映射对比结果
4 结论
(1)提出基于关键字表达数据元的语义表示方法,给出数据元语义的形式化定义及语义树定义。由于不需要领域本体作为约束,可用关键字自由表达,方法简单易用。
(2)结合编辑距离算法和杰卡德算法,给出数据元语义相似度计算方法。该方法综合考虑数据元名称及关键字集合对数据元语义理解的贡献,适合油田工程化应用,可提高数据模型映射的自动化程度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
华人时刊(2022年1期)2022-04-26
现代信息科技(2021年21期)2021-05-07
动漫界·幼教365(大班)(2019年10期)2019-10-28
现代盐化工(2019年6期)2019-09-10
电脑知识与技术(2016年10期)2016-06-16
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
环球时报(2009-11-25)2009-11-25
