
基于神经网络的舆情情感分析研究热点与趋势
——基于CiteSpace 的可视化分析
2022-07-29 06:54:12谭坤彦杨孔雨
智能计算机与应用 2022年8期
谭坤彦,杨孔雨
(北京信息科技大学 信息管理学院,北京 100192)
0 引言
随着人工智能技术的迅速发展和各类社交平台的出现,互联网用户可以随时随地在网络平台上传播信息。大量的信息往往蕴含着用户的情感倾向,获取这些信息中的情感倾向或观点就是情感分析。对于决策制定者来说,可以理解民意,掌握舆论,判断其走向。早期的情感分析主要基于情感词典和传统机器学习,随着机器学习技术的飞速进步,深度学习方法已经成为情感分析的主流。在Mikolov等人(2013)首先提出了Word2Vec 工具中的模型后,文本可以表示为词向量矩阵,为引入各种神经网络模型打下了基础。基于神经网络的舆情情感分析研究具有重要的意义与价值,本文利用知识图谱软件CiteSpace,运用文献计量法,通过将结果可视化的方式,从发文量趋势、作者、机构、关键词的多元角度进行研究,分析国内外结合神经网络技术进行舆情情感分析的文献发展动态、研究热点、演变过程、前沿研究方向等,期寄能够给相关领域的研究者带来一定帮助。
1 分析方法与数据来源
CiteSpace 是基于Java 开发的一款信息可视化软件,由美国Drexel University 计算机与情报学教授陈超美研发,基于共引(co-citation)分析理论和寻径(PathFinder)网络算法等,对特定领域文献计量,以探寻出学科领域演化的关键路径及其知识转折点,并在相关领域中,查究到具有开创性、标志性、关键性和相互关联的文献,同时研究该领域的演变。
本文以CiteSpace 软件为主,Excel 等工具为辅,国内中文文献来源于中国知网(CNKI),经过人工进行剔除和筛选后,得到2011~2021 年的877 篇样本相关文献。国外英文文献来源于Web of Science(WOS)的核心合集数据库,人工剔除图书阅读笔记、广告等不相关内容后,导入CiteSpace 进行文献去重,最终得到423 篇样本相关英文文献。
2 基于CiteSpace 的文献可视化分析
2.1 文献计量分析
年度发文量变化趋势图能够反映研究领域的总体情况,在时间维度上反映每年的不同发文量和活跃度。根据检索获得的中英文相关文献绘制发文量趋势图,各年份不同变化如图1 所示。国内舆情情感分析结合神经网络技术开始于2011 年,此后发文量逐渐增加,于2020 年达到最高峰,2011~2015 年诞生阶段结束、进入发展阶段,2017~2020 年发文量迅速增长,虽然2021 年发表中文文献161 篇,数值有所回落,但仍持续受到关注。结合研究背景来看,情感分析的概念由Nasukawa 等人在2003 年最先提出,同年Bengio 等人提出了神经网络语言模型,国外相关文献最早发表于2006 年,初期发展趋势和国内基本一致,2018 年结束快速上升期、进入平缓发展阶段,同样也于2021 年发表Web of Science 核心合集81 篇,较上年发文量最高峰有所回落,相关理论研究也将更加完善。
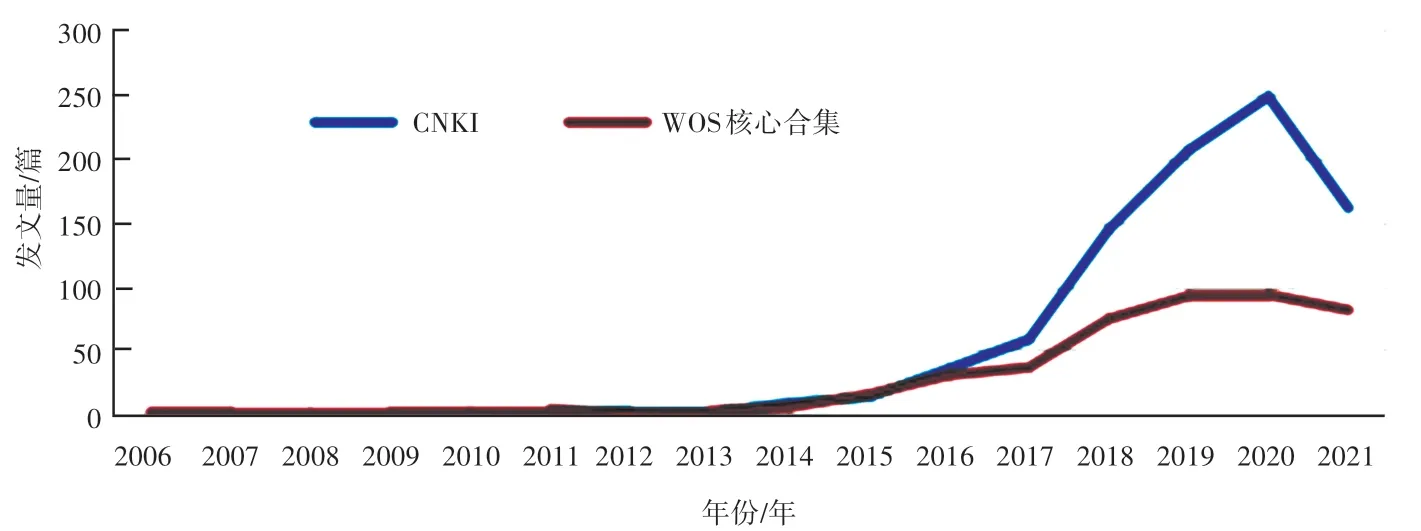
图1 发文量随年份变化趋势图Fig.1 Variation trend of documents volume with years
2.2 作者共现分析
通过作者合作共现图谱可以分析该领域各个作者的重要性、中心性和合作关系。对CNKI 中文文献作者进行分析处理后,得到国内作者共现图谱如图2所示。图2 中,作者节点数为214,连线数为30,密度为0.001 3,连线代表有合作关系,线条粗细代表合作关系的密切程度。由此可见,各个作者之间的联系和合作关系极为分散,多处于个人独立研究状态,未能形成明显的合作网络图谱,发文量最多的作者为张英、黄道英、范涛、王昊,发表文献数均为3 篇。

图2 国内作者共现图谱(节选)Fig.2 Co-occurrence graph of domestic authors(excerpt)
对WOS 核心合集进行可视化共现图谱分析,时间为2006~2021 年,作者节点数为247,连线数为162,密度为0.005 3,部分作者形成了小规模的合作网络,其中发文量最多的作者是Erik Cambria(10篇),汇聚成以其为核心的网状合作图谱。国外作者共现图谱如图3 所示。由图3 可见,国外作者的节点和连线数都比国内多,可知国外发文作者间的联系与团队合作比国内更加密切,说明国内应该加强作者间的共同合作关系。

图3 国外作者共现图谱(节选)Fig.3 Co-occurrence graph of foreign authors(excerpt)
2.3 机构共现分析
为分析该研究领域中的研究力量分布,对CNKI中文文献机构进行处理分析,得到国内合作机构共现图谱如图4 所示。网络裁剪方法同作者分析,发文量前三的机构分别为国家统计局8 篇、南京理工大学7 篇、南京大学信息管理学院6 篇,机构与机构间联系较为分散,尚未建立明显合作体系。

图4 国内机构分布共现图谱Fig.4 Co-occurrence graph of domestic institutions
对国外发文机构可视化分析发现,发文量前五的机构分别是新加坡南洋理工大学(Nanyang Technological University)13 篇、中国科学院(Chinese Acad Sci)10 篇、北京航空航天大学(Beihang University)5 篇、哈尔滨工业大学(Harbin Institute of Technology)5 篇、清华大学(Tsinghua University)5篇,国外合作机构共现图谱如图5 所示。

图5 国外机构分布共现图谱Fig.5 Co-occurrence graph of foreign institutions
从国内外研究机构分析发现,发文量最多的都是各地高校及学院、科研机构,对神经网络和网络舆情情感分析做出了主要贡献,但是相互之间的合作仍然亟待加强。
3 关键词可视化分析
3.1 关键词聚类分析
关键词是一篇文献的核心和主题,CiteSpace 在使用关键词共现分析的基础上,使用对数似然比(Log-Likelihood Ratio,LLR)算法进行聚类,中文文献共生成14 个聚类,分别对每个类的主题进行归纳总结,前8 类见表1;英文文献共生成9 个聚类,总结主题,选取7 类见表2。国内外共同研究热点有数据挖掘、深度学习、文本分类、情绪分析等,国外主要关注情绪倾向分析及预测,国内更关注于舆情文本分析。同时,聚类不仅可以集中于验证研究热点,还能够指出其在各种领域上的具体应用,如表2 中聚类0 是电影预测领域的应用,聚类6 是电动汽车评论领域的应用,在研究计算机相关应用热点的时候,也要重视聚类关键词在非计算机类领域的应用。

表1 中文文献聚类表Tab.1 Chinese literatures clustering table
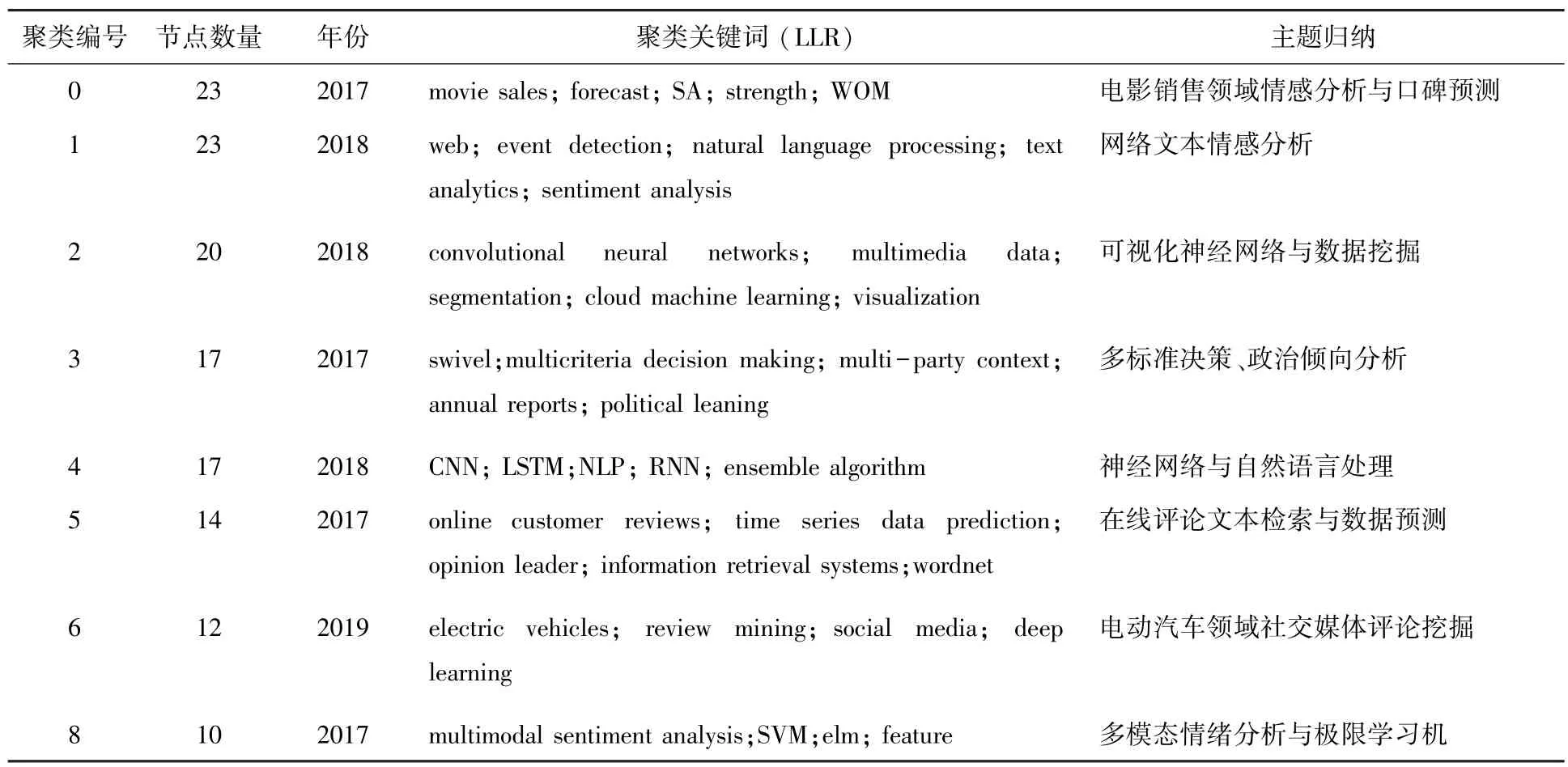
表2 英文文献聚类表Tab.2 English literatures clustering table
表1 中聚类#3 深度学习、#4 长短期记忆网络LSTM(Long Short-Term Memory)、#5 机器学习主要围绕情感分析的技术展开。
早期的情感分析主要基于情感词典(#6 号聚类),其关键是情感权重及情感计算规则。情感词典最早由Whissell 于1998 年提出,王科等人(2016)将情感词典自动构建方法归纳为三大类:基于知识库的方法、基于语料库的方法和基于知识库和语料库相结合的方法。目前最常用的3 个中文开源情感词典有HowNet、台湾大学的NTUSD 和大连理工大学的词汇本体库,在此基础上,阳爱民等人(2013)选用若干个情感种子词,通过改进的PMI(Pointwise Mutual Information)算法计算情感词的情感权值,从而构建出一种分类性能更加稳定的情感词典。陈国兰(2016)通过与具体社交网络(#7号聚类)结合,针对微博(#2 号聚类)文本的特点,构建了一个包括微博网络新词和表情符号的情感词典,与传统方法相比,判断正、负面情感的准确率更高。
随着人工智能技术的发展,情感分析逐渐与机器学习(#5 号聚类)相结合。传统机器学习大多是有监督学习,分类器主要有朴素贝叶斯(Naive Bayes,NB)和支持向量机(Support Vector Machine,SVM)等。
基于情感词典和有监督学习的情感分析人力资源消耗过多,效率低下。为了提高文本分类的准确率,深度学习(#3 号聚类)通过构建神经网络模型对文本进行特征抽取和自动学习优化模型输出。#4 号聚类中包括“卷积神经网络(Convolutional Neural Networks,CNN)”关键词,利用卷积层,CNN可以学习局部特征。梁斌等人(2017)提出一种情感分类方法,通过结合3 种注意力机制来构造多注意力卷积神经网络模型,准确表示每一个词在句子中的重要性。#3 号聚类中包括关键词“循环神经网络(Recurrent Neural Networ,RNN)”,#4 号聚类还包含“LSTM”关键词,LSTM 是一种特殊的RNN。梁军等人(2015)提出了一种利用文本上下文信息、结构化信息和情感语义信息的模型,来解决情感极性转移问题。
国外的聚类还围绕具体应用领域展开研究,主要是#0 号聚类电影销售和#6 号聚类电动汽车,#0号聚类主要包括关键词预测、情感分析、口碑。口碑是由有经验的消费者创造的有用且可信的信息,也就是用户生成内容(User-Generated Content,UGC)。互联网技术的发展使人们能够在网络平台上与他人分享、交换意见,通过在线渠道实时传播评论信息等。电子口碑的早期研究倾向于只使用数量和评分,而不分析内容的语法,不足以解释在线交流的动态。在电子口碑中,情感应该作为一个重要参数,Liu(2006)分析了从雅虎电影的留言板上收集的40 部电影的评论,结果表明电影上映前的电子口碑对票房收入有显著影响。Duan 等人研究电影销售与在线评论和收视率之间关系,结果显示2 个领域之间存在影响,但高的评价不能确保高的销售额。Rui 等人(2013)分析电影的电子口碑,表明消费者观看电影的意愿受电子口碑影响很大。
#6 号聚类电动汽车包含关键词social media(社交媒体)、review mining(评论挖掘)和deep learning(深度学习)。公众对电动汽车的看法和使用电动汽车的普遍意愿对推广电动汽车起到了重要作用,XU 等人(2018)研究并确定了影响电动汽车接受和拒绝的因素。消费者对电动汽车技术特征的态度和对电动汽车效用的看法是影响是否选用电动汽车重要因素。消费者情绪和感受也会影响电动汽车的选择,了解消费者的情绪有助于改进客户关系管理(CRM),Jena(2020)通过情感分析,对电动汽车的情感进行分类。帮助用户获得对各种产品功能的高层次的看法概述,并大幅缩短用户阅读和提取有关产品、服务意见的文本长度。
#8 号聚类多模态情绪分析包含的关键词有:支持向量机、极限学习机、特征。情感分析中文本、声音和视觉模式的融合最近引起了越来越多的关注,多模态情感分析通过分析在线视频中的口语情态、听觉情态和视觉情态三种模式,扩展了传统的文本情感分析。Chaturvedi 等人(2017)提出了一种基于贝叶斯网络的ELM(Extreme Learning Machine),克服了传统ELM 不能推广到非线性数据集的缺点。
通过对该领域研究热点的分析,得到关键词聚类图谱,节点与节点之间的连线颜色越浅代表出现得越晚。国内关键词聚类图谱如图6 所示。图6 中共有347 个节点,622 条连线,密度为0.010 4,值为0.631 5,值为0.874 4,国内关键词聚类图谱如图7 所示。图7 中共有173 个节点,454 条连线,密度为0.030 5,值为0.886 6,值为0.757 2。模块值(Modularity)用于评价聚类的有效性,平均轮廓值(Mean Silhouette)用于衡量聚类的同质性。当0.3 且0.5 时认为该聚类模块性显著、合理。

图6 国内关键词聚类图谱Fig.6 Domestic keywords clustering map

图7 国外关键词聚类图谱Fig.7 Foreign keywords clustering map
中文文献关键词聚类后按词频排序前13 位见表3,高频关键词代表了该领域研究的相关热点,关键词出现的频率越高,说明领域越热;关键词与其他关键词之间的联系越多,说明中心度越大。中文关键词聚类词频表见表3,通过分析可以看出,国内词频出现较高的关键词为“情感分析”、“深度学习”、“情感分类”、“词向量”、“神经网络”和“机器学习”。
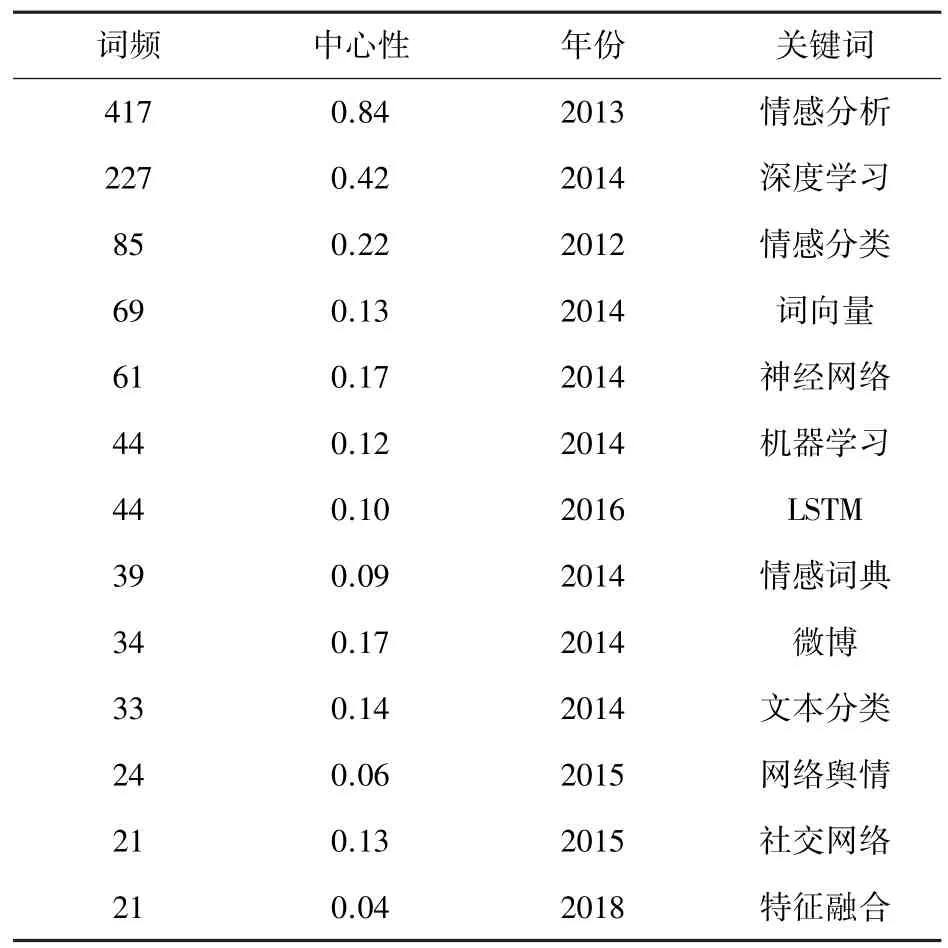
表3 中文关键词词频表Tab.3 Chinese keywords frequency table
英文高频关键词,见表4,国外词频出现较高的关键词为“classification(分类)”、“sentiment analysis(情感分析)”、“LSTM(长短期记忆网络)”、“neural network(神经网络)”、“CNN(卷积神经网络)”和“model(模型)”。国内的研究热点和国外也存在差异,国内更重视舆情中文文本的自然语言处理和中文文本分类方面,国外更重视神经网络模型的研究和具体领域的应用。

表4 英文关键词词频表Tab.4 English keywords frequency table
3.2 关键词时间线图谱分析
在CiteSpace 中对数据样本进行分析处理后,得到国内外时间线图谱如图8 和图9 所示,展现聚类关键词之间的关系,以及热点关键词随着时间变化的研究历程和前沿趋势。每个点对应的是关键词首次出现的年份,圆圈越大表示词频越大,连线表示2个关键词在同一篇文章中出现。连线数量多且密集,说明研究集中程度较好。
通过对图8 分析可得,国内基于神经网络的舆情情感分析研究热点从2011 年出现,2011~2012 年处于起始状态,研究热点为“语义理解文本倾向”、“观点挖掘”和“情感分类”。2013 年对情感分类进行进一步探讨,在情感分析的基础上,逐渐传承。2014 年开始结合机器学习和神经网络,研究热点为“词向量”、“情感词典”、“文本分类”、“深度学习”等。随着深度学习的研究不断发展完善,2015~2018 年,LSTM、门控循环单元(Gated Recurrent Unit,GRU)、CNN 等神经网络模型逐渐成为了热点研究对象,社交网络媒体逐渐成为研究舆情分析的平台。随着神经网络技术的发展,2019 年又出现了以“BERT”(Bidirectional Encoder Representation from Transformers)、“词嵌入”、“胶囊网络”为首的研究热点。
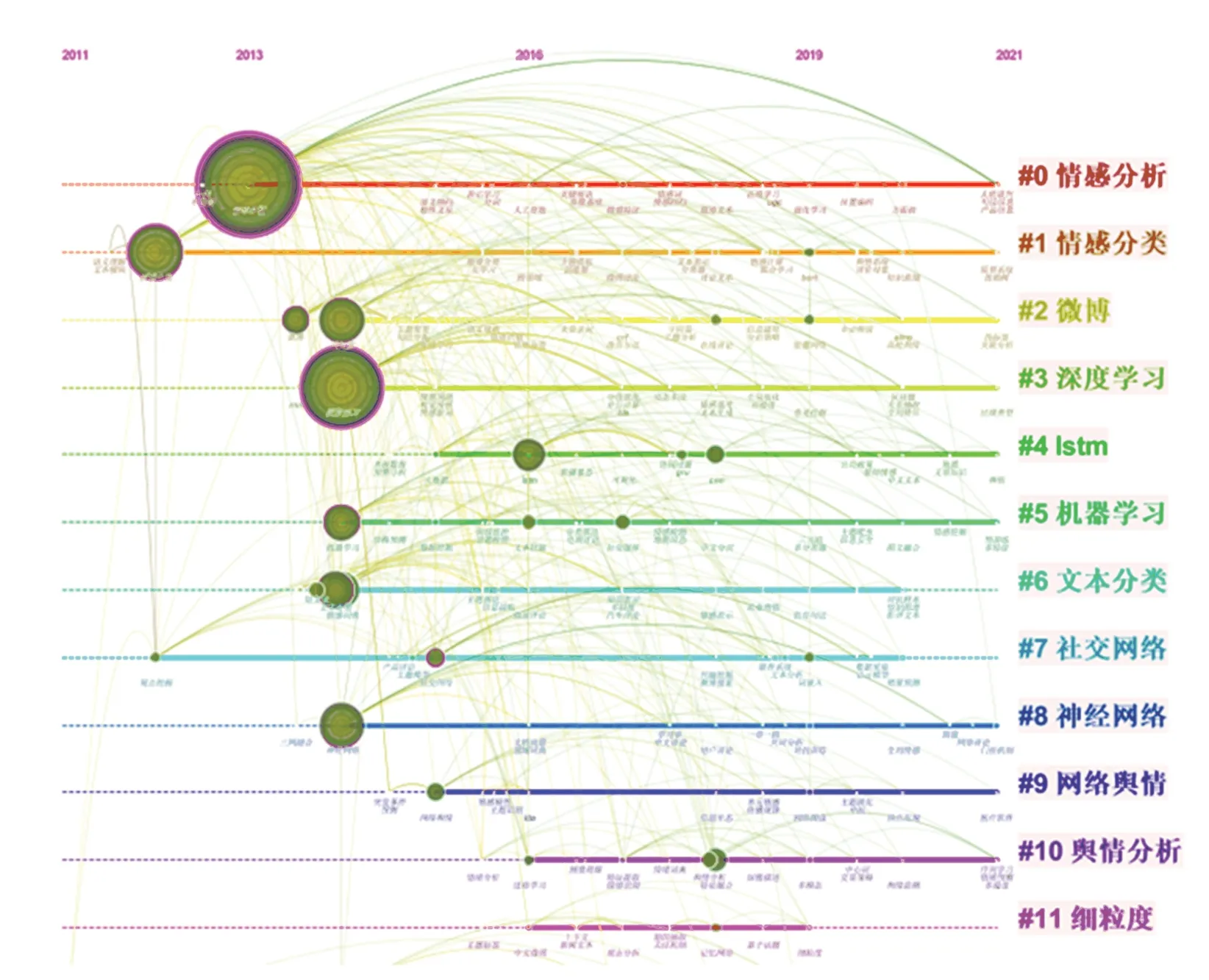
图8 国内关键词时间线图谱Fig.8 Domestic keywords timeline map
国外虽然节点数量少于国内,但连线比国内更加密集,联系更加密切,如图9 所示。研究热点从2010 年“RFM”(Recency,Frequency,Monetary)模型起步,2011 年的“神经网络”开始发展,2014~2015 年的研究热点为“模型”、“算法”、“词典”、“分类”。2016 年后在“情感分析”的基础上,出现了更加细化的多元分类,如“特征”、“LSTM”、“CNN”、“框架”。“BERT”热点稍晚于国内一年。
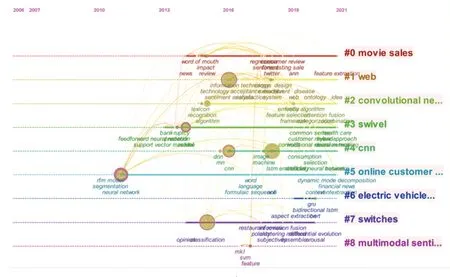
图9 国外关键词时间线图谱Fig.9 Foreign keywords timeline map
3.3 关键词突现分析
通过CiteSpace 的Burstness(突现)功能进行突现词分析,突现词代表了不同时期开始的研究热点,得到领域关键词的起始爆发时间、结束时间和强度等,选择前13 个关键词展示如图10、图11 所示。图10、图11 中,Year 代表原文发表年份,Begin 代表Burst 的开始年份,End 代表结束年份,Strength 代表突现强度,用来表示该领域在某些年份的文献中突现词的剧烈程度。由图10 可见,在国内,“机器学习”、“文本挖掘”和“中文微博”突现词出现在2016年,“深度学习”、“LSTM”、“记忆网络”、“细粒度”、“词嵌入”出现在2017~2019 年,“深度学习”和“LSTM”在这3 年中的强度值最大,机器学习的持续发展为舆情情感分析奠定了基础,情感分析进一步与神经网络技术结合。随着深度学习研究的日趋深入与发展,2020~2021 年出现的关键词“特征融合”、“BERT”、“舆情分析”、“销量预测”,可见研究人员已经将深度学习运用于舆情情感分析中,并且使用神经网络模型对销量进行预测。国内外既有联系,又有区别。由图11 可知,在国外,早期突现词主要由2013 开始突现的“支持向量机”、2016 开始突现的“卷积神经网络”和“情感分析”组成,随着人工智能的发展,在2018 年又出现了“主观性”、“社交媒体”和2019 年出现的“网络”、“模型集成”等新突现词,其中突现强度最高的是卷积神经网络。
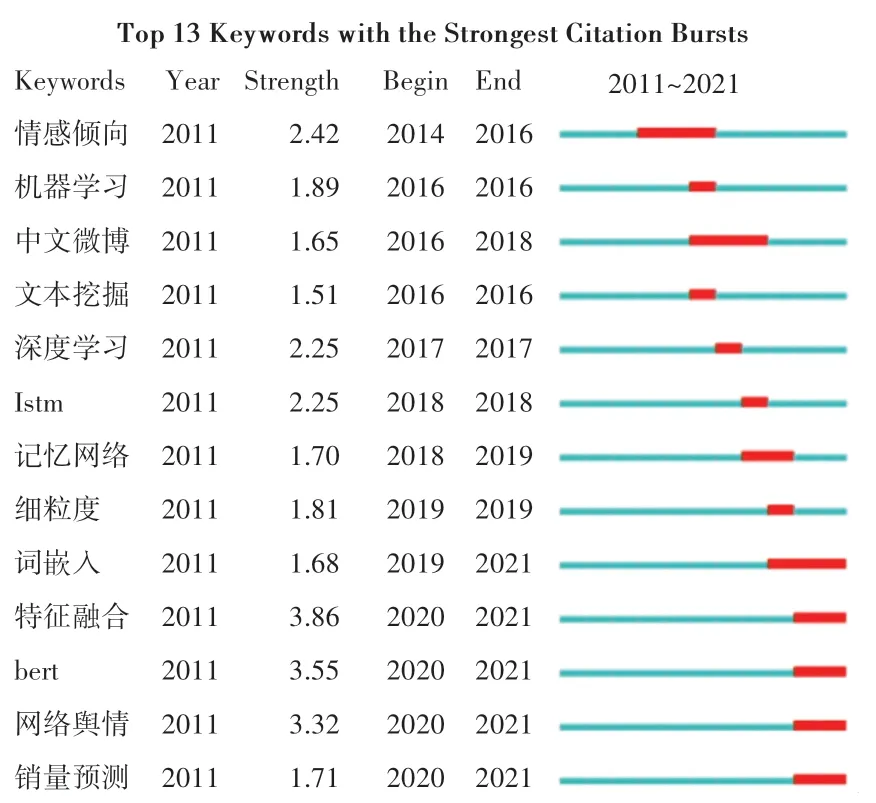
图10 国内突现强度前13 的突现词Fig.10 Domestic top 13 keywords with the Strongest Citation Bursts

图11 国外突现强度前13 的突现词Fig.11 Foreign top 13 keywords with the Strongest Citation Bursts
对突现词进行研究分析,总结现阶段国内结合神经网络的舆情情感分析技术研究的前沿方向主要有:
(1)实现预训练模型的突破,如BERT、ALBERT(A Lite BERT)、XLNET、ELMo(Embeddings from Language Models)等模型。目前在舆情情感分析领域有许多经典的深度学习模型,Devlin 等人提出的BERT 模型,能够根据指定目标,捕捉到文本中相对应的情感信息,更加具有灵活性。BERT 模型可以动态获取各种语境下的词语表达向量,通过上下文信息充分解决词语多义性问题。由图6 看出BERT 的强度值位于所有年份中第二名,处于发展状态中。史振杰等人(2020)提出了一种结合卷积神经网络的BERT-CNN 模型,该网络模型在用BERT 表示词向量语义信息的基础上,使用CNN 提取文本特征,实现了对文本信息语义的深层理解。由于BERT 模型参数量较大、复杂度高等问题,Lan等人(2019)对BERT 模型进行改进,提出了ALBERT 模型。房京珂(2021)将ALBERT 模型与2 种双向递归神经网络结构结合,全面提取模型中的语义信息,使其更加适合舆情情感分析。梁淑蓉(2021)提出一种融合情感词典的XLNet 预训练模型和一种基于LSTM+Attention 网络层的XLNet预训练模型,前一种模型可以根据不同的上下文语言环境计算词向量,精准提高了情感倾向,解决情感词典构建数量和收录新词工作量的问题,后一种模型在一定程度上解决了中文文本的语义问题。李铮等人(2021)提出一种基于ELMo 和双向自注意力网络(Bidirectional Self-Attention Network,Bi-SAN)的中文文本情感分析模型,利用ELMo 模型抽取词向量,更好地表示了中文文本的一词多义性,提高了情感分类的准确性。未来,还能够通过增加计算机基础硬件算力,更广泛地使用其他模型,后续对最新模型的研究将会逐渐成为热点。
(2)特征融合表示方法的探索。多特征融合向量可以从短文本中充分学习词性特征信息和位置特征信息。韩普(2021)等人将词性特征向量和位置特征向量进行融合,一方面可以充分地学习特征间的语义关系,另一方面也可以有效地利用词性信息和位置信息,提升情感分析模型的效果。郭可心等人(2021)从多个不同角度挖掘图文之间的情感共现,增强了神经网络模型捕捉情感语义的能力。祁瑞华等人(2020)融合BERT 词向量和跨领域词向量生成跨领域统一特征空间,提高了情感分类的准确率。目前,在图文融合方面还存在许多问题,如数据集规模较小、情感数据集的建立困难、不同模型特征获取不一致、媒体数据类型单调、模型实验效果一般、准确率低、未考虑更多信息。在今后的研究中,进行情感分析的同时融入图文关系分析,是一个重要的研究方向。
(3)词嵌入层的设计。词嵌入已经成为各任务模型在预处理阶段的事实标准。目前,词嵌入方法是利用较长的上下文,通过神经网络模型来解决自然语言问题。韩旭丽等人(2019)提出了一种词嵌入辅助机制的注意力神经网络模型,该模型在原本词嵌入层的基础上加入辅助层,用来提取词向量的特征表示,降低了模型训练的复杂性和训练时间。赵亚欧等人(2020)提出一种基于语言模型的词嵌入的情感分析模型,将获取的词语向量作为网络输入,融合了词语本身的语义特征及其所在的上下文语义,可以很好地表示一词多义性。目前,基于大规模语料的预训练模型是最热门的研究方向,新型词嵌入越来越通用,语义功能越来越强大。
4 结束语
本文通过CiteSpace、Excel 等软件,以中国知网和WoS 核心合集文献为研究对象,采用文献计量和可视化知识图谱的方法,对神经网络的网络舆情情感分析进行了研究。通过发文量趋势分析、作者共现分析、研究机构共现分析、关键词聚类分析、关键词时间线图谱分析和关键词突现分析,研究了该领域的热点主题和前沿趋势。得出如下结论:
(1)从基于神经网络的舆情情感分析领域的发文量年度趋势来看,国内发表第一篇相关文献的起始时间比国外晚,虽然增长速度快,但却存在着一些问题,比如作者及机构间相互合作较少、学术交流不足,以及研究主题较集中,缺少领军人物等问题,国内研究成果主要由世界各地的大学和科研机构推广,应该加强作者或机构间的合作与沟通,共同发展。
(2)通过研究热点和研究前沿对比分析,国内外共同研究热点主题为“情感分类”、“LSTM”、“深度学习”、“神经网络”等,但国内外侧重点存在着差异,国内文献更重视文本的语义表达和文本情感分类方面,国外则更重视情感分析模型的应用及预测,更加具有实用性。
(3)国内研究前沿趋势主要为网络舆情情感分析的特征融合表示方法、预训练模型的探索和词嵌入层的设计。
本文分析对比了国内外神经网络和舆情情感分析研究的演变脉络,对进一步研究国内外概况,预测未来发展趋势具有现实意义。由于CiteSpace 软件的限制,并未收集所有英文期刊等文献,也未获取重要会议记录等数据,本文内容不能完整描述该领域的研究现状。CiteSpace 软件中具有更多功能可以分析WoS 核心合集中的文献,本文也并未全部运用,在后续的工作中拟做更进一步的研究完善。
猜你喜欢
少先队活动(2020年12期)2021-01-14 01:47:40
电子制作(2019年19期)2019-11-23 08:42:00
电子测试(2017年15期)2017-12-18 07:19:27
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
重型机械(2016年1期)2016-03-01 03:42:04
智能系统学报(2015年4期)2015-12-27 09:38:39
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
电子设计工程(2015年6期)2015-02-27 12:04:53
