
基于深度强化学习的分布式能源系统运行优化
2022-07-28 06:57阮应君侯泽群钱凡悦孟华
科学技术与工程 2022年17期
阮应君, 侯泽群, 钱凡悦, 孟华
(同济大学机械与能源工程学院, 上海 201804)
分布式能源系统是一种直接面向用户并且能够满足多种能源需求的中小型能源转换利用系统,其中冷热电联供(combined cooling heating and power, CCHP)系统是最常见的分布式能源系统之一。CCHP系统以天然气作为动力源,通过原动机、吸收式制冷机、燃气锅炉等设备可以输出电、冷、热,同时满足用户侧的负荷需求,实现了能源的梯级利用,提高了能源利用率,同时该系统可以接入可再生能源,有利于改善环境污染。目前,中国建设的分布式能源系统也在逐年增加,然而目前有很多分布式能源系统无法发挥很好的经济效益,主要原因是分布式能源系统运行的调度策略不能够实现良好的经济效益。因此,分布式能源系统的调度优化问题逐渐成为研究热点。
目前,已经有很多关于电力能源系统调度优化的研究,并且有很多用于调度优化问题的传统、经典算法。例如文献[1]基于线性规划方法实现对能源系统的蓄热、电池的管理,降低了运行成本。文献[2]建立电-气-热综合能源动态网络潮流模型,引入氢储能设备,应用混合整数线性规划方法对能源系统的运行优化模型进行求解,有效地提高了该综合能源系统的能量利用效率和环境收益。文献[3-4]通过满足综合效益最优原则来建立随机规划调度模型,用粒子群算法对模型进行优化,实现微电网运行成本最低。然而对于上述的这些传统方法,往往依赖于精确的数学模型和参数,而对于一个综合能源系统,想要建立一个精确的数学模型几乎是不可能的。
同时,综合能源系统具有高度不确定性,例如用户侧负荷需求的不确定性、太阳能供应的不确定性、电价的不确定性等。对于传统的方法,通常是建立一个不确定性的数学模型来表征综合能源系统中的不确定性。文献[5]应用线性化随机规划框架,对能源价格和负荷需求的不确定性进行建模,实现住宅系统的能源管理优化,降低了投资和运行成本。文献[6]考虑太阳辐射强度服从Beta分布,建立概率分布函数来描述风光发电的不确定性。文献[7]应用梯形模糊数来表示风电出力。因此,能源系统运行优化的结果很大程度上取决于不确定性模型的精度,当模型精度较差时,最终的优化结果也会受到很大影响。
对于能源系统的运行优化,往往分为日前调度、日内滚动优化和实时调整3种时间尺度的优化。文献[8]预测得到风光发电的值,通过混合整数线性规划算法对能源系统进行日前调度优化。考虑到能源系统的不确定性,预测的结果往往存在偏差。日内滚动优化是指在某个时间窗口内,以日前预测优化的结果作为基础,并根据实际情况不断地对数学模型进行滚动更新[9],而实时调度则可以在更小的时间尺度内实时地对优化模型进行更新,从而具有更好的性能。在使用传统方法时,每一个调度区间运行优化完毕后,都需要重新开始训练模型,从而使其适用于下一个调度区间,这无疑不满足实时调度的实时性的特征。
随着人工智能技术的发展,出现了一些新的人工智能算法,例如强化学习和深度学习。它们的出现为电力系统的控制优化和能源系统的运行优化带来了新的思路。与传统算法相比,强化学习方法是基于数据驱动的方法,智能体可以对已有的大数据进行学习,通过不断地试错,最终学习到最优的运行策略,这样的学习方式同时可以学习到隐藏在历史数据中的能源系统中的不确定性。此外,经典的强化学习方法Q-learning方法是一种无模型的方法,它不需要系统的模型和先验知识,因此可以很好地避免传统方法中由于建立的数学模型的不精确而导致优化结果较差。
深度学习和强化学习的结合,借助神经网络强大的表征能力极大地提升了强化学习的学习能力,通过对历史数据的学习,最终可以获得一个由训练得到的黑箱模型,该模型可以直接用于对能源系统的实时调度优化,将任意时刻获得的实际负荷需求输入该黑箱模型,即可实时输出该时刻各个设备的出力情况[10],并且随着能源系统的运行,新的运行数据也可以对模型进行训练调整。因此,应用深度强化学习来解决能源系统的调度优化问题已成为一个研究热点。文献[11]采用了经典的深度强化学习算法深度Q网络(deep Q network, DQN)算法对预测负荷、风光发电出力和分时电价等信息进行学习,实现对微能源网的能量管理,但是只是对具体的某一天进行优化训练,最终得到的模型不具有泛化能力,并且DQN只能解决离散动作空间的问题,而实际的能源系统各个设备的出力情况是一个连续的变量。文献[12]采用可以对连续状态进行控制的深度强化学习算法实现对风光发电的自适应不确定性的调度,但是研究对象仅考虑了电能,而没有涉及冷热电多能量之间的耦合问题。文献[13-14]采用强化学习方法对储能装置进行调度控制。文献[15]采用了双层的强化学习结构对综合能源系统进行实时调度,将强化学习方法和传统方法相结合,简化了奖励函数的设置,大大提高了算法的运行速度和收敛速度,但是能源系统仅考虑了电热的能力耦合,没有冷能,并且采用的强化学习方法为DQN,不能够很好地控制实际能源系统的各个设备。
现以CCHP系统为对象,提出利用一种可以实现对连续状态进行控制的深度强化学习算法分布式近端策略优化(distributed proximal policy optimization, DPPO)算法对CCHP系统进行运行调度优化。DPPO算法弥补了DQN算法只适用于离散变量的不足,并且在PPO算法的基础之上实现对多个场景同时学习,提高训练效果。引入神经网络解决传统强化学习存在的维数灾难问题,避免对能源系统不确定性的建模,采用数个月的历史数据对模型进行训练,最终得到一个泛化能力良好的优化模型,实现对CCHP系统的在线运行调度优化。
1 分布式能源系统建模
选取的CCHP系统主要设备包含内燃机、吸收式制冷机、电制冷机、燃气锅炉。分布式能源系统的结构图如图1所示,用户侧电力负荷供给主要由内燃机、光伏发电提供,不足的电力可以从电网购得,多余的电力不考虑上网出售。冷负荷供给由吸收式制冷机和电制冷机提供。热负荷供给由内燃机发电产生的余热和燃气锅炉提供。

图1 分布式能源系统结构图Fig.1 Distributed energy system structure diagram
1.1 目标函数
目标函数为分布式能源系统的运行成本,且运行成本只考虑购买天然气和电力,设备的投资成本和维护成本忽略不计。目标函数表达式为
C=Ce+Cgas
(1)

(3)
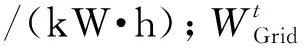
1.2 内燃机模型
内燃机在小型热电联供系统中被广泛应用。为保证内燃机运行安全,当功率负荷率低于20%时,内燃机将不会启动[20]。相关公式为
ηh=βηe
(4)
PICE=Mgas_iceqgasηe
(5)
HICE=Mgas_gbqgasηh
(6)
PICE≤PICE_max
(7)
式中:ηe、ηh和β分别为内燃机的电效率、热效率和热电比;qgas为天然气的低位热值,kJ/Nm3;PICE为内燃机的实际发电功率,kW;PICE_max为内燃机的最大发电功率,kW;HICE为内燃机热回收利功率,kW。
1.3 制冷机组模型
制冷设备包括电制冷机组和吸收式制冷机组,为保证设备运行安全,当功率负荷率小于20%时,吸收式制冷机组不会启动[20],制冷设备的数学模型可以表示为
EEC≤PECCOPEC
(8)
EABS≤HABSCOPABS
(9)
EEC≤EEC_max
(10)
EABS≤EABS_max
(11)
式中:EEC、EABS分别为电制冷机和吸收式制冷机的制冷功率,kW;PEC、HABS分别为电制冷机的耗电功率和吸收式制冷机消耗的热功率,kW;COPEC、COPABS分别为电制冷机和吸收式制冷机的制冷系数;EEC_max、EABS_max分别为电制冷机和吸收式制冷机的最大制冷功率,kW。
1.4 燃气锅炉模型
HGB=Mgas_gbqgasηh_boiler
(12)
HGB≤HGB_max
(13)
式中:HGB为燃气锅炉的实际热功率,kW;ηh_boiler为燃气锅炉的热效率;HGB_max为燃气锅炉的最大热功率,kW。
1.5 能量平衡约束

(16)
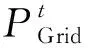
1.6 光伏发电系统模型
利用光伏电池将太阳能转换为直流电,光伏电池发电功率表达式为
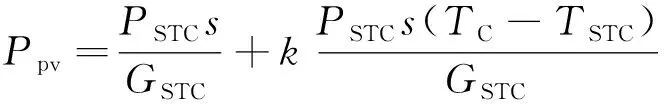
(17)
式(17)中:Ppv为光伏系统的发电功率,kW;PSTC为光伏系统的标称最大功率,kW;GSTC和s分别为标称太阳辐射强度和实际的太阳辐射强度,kW/m2;TC和TSTC分别为光伏电池的温度和标称环境温度,℃;k=-0.004 7 ℃-1,GSTC= 1 kW/m2,TSTC=25 ℃。
光伏电池的温度计算公式为
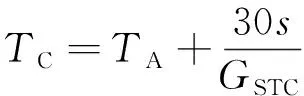
(18)
式(18)中:TA为周围环境的实际温度,℃。
2 基于深度强化学习框架的能源系统运行优化
2.1 深度强化学习框架
2.1.1 强化学习
强化学习是机器学习的一个分支,与经典的有监督学习和无监督学习相比,其最大特点是交互式学习。强化学习基于马尔可夫决策过程(Markov decision process,MDP),即环境下一时刻的状态仅取决于当前的状态和当前所选取的动作。MDP一般包含4个元素:状态空间S、动作空间A、奖励函数R:SA→R以及状态转移函数P:SAS→[0,1],即MDP=〈S,A,P,R〉,一个简单的强化学习例子如图2所示。
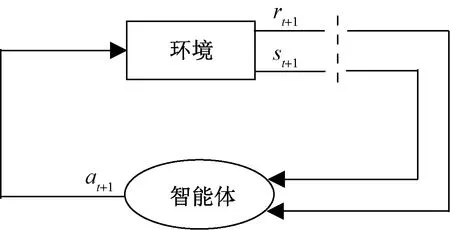
图2 强化学习基础框架Fig.2 Basic framework for reinforcement learning
图2中,在t时刻,智能体选取一个动作at作用于当前环境st,受到动作影响,当前状态将会根据当前的状态转移函数P转移到下一时刻的状态st+1,同时根据奖励函数可以计算得到一个奖励值rt+1,接着把得到的新的状态和奖励值输入到智能体中,智能体根据当前的动作选择策略输出一个新的动作。强化学习方法的目的是通过智能体和环境的不断交互,最终使得智能体学习到能够获得最大的长期奖励的动作选择策略[15]。长期奖励表达式为
Gt=rt+γrt+1+γ2rt+2+…+γn-trn
(19)
式(19)中:rn为终止状态时得到的奖励值;γ为折扣系数,一般来说γ∈[0,1]。
状态值函数Vπ(s)可以评估当前动作选取策略π的好坏,其表示在t时刻的状态s在未来可以获得的回报的期望值,即
Vπ(s)=Eπ[Gt|st=s]
(20)
将式(19)简化得
Gt=rt+γ[rt+1+γ(rt+2+…)]=rt+γGt+1
(21)
将式(21)代入式(20)得
Vπ(s)=Eπ[rt+γVπ(st+1)|st=s]
(22)
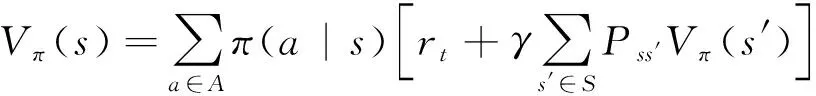
(23)
上述公式即为贝尔曼方程,该方程表示t时刻状态值与t+1时刻状态值的关系,其中Pss′表示状态转移函数;π(a|s)表示在状态s选择动作a的概率。
最后可以通过式(24)求得最优的策略π*,即

(24)
2.1.2 DPPO算法
虽然强化学习能够很好地解决控制问题,但该算法主要是基于表格的方法,因此只适用于解决离散的状态空间、动作空间的问题。然而,对于大多数实际任务来说,状态或者动作的数量是巨大的,而且有些任务是连续的状态空间和动作空间,很难使用表格来记录每个状态和动作。
目前,深度学习在计算机视觉、自然语言处理等诸多领域取得了突破,极大地推动了人工智能技术的发展[17]。充分利用深度学习的优势,特别是深度学习较强的表示能力可以极大提高强化学习智能体在实际任务中的性能[18-19]。
深度强化学习的智能体采用深度神经网络(deep neural network,DNN)代替价值函数。DNN的输入的变量是环境状态,输出是智能体选择的动作,而奖赏可以作为损失函数的参数之一,然后基于随机梯度算法推导出损失函数,通过网络模型的训练优化更新DNN的参数。
深度强化学习主要分为两类方法:基于值的强化学习和基于策略的强化学习。基于值的强化学习实际上就是基于价值函数的强化学习,价值函数主要用于评估当前智能体基于某种状态的好坏程度,如深度Q网络(deep Q network, DQN)算法;基于策略的强化学习直接对策略π进行优化更新,以得到最优的策略π*,最终从最优策略π*中搜索当前状态对应的动作,如演员-评论家(actor-critic)算法。
策略梯度(policy gradients, PG)算法是基于策略的强化学习算法,智能体通过不断地与环境交互学习,对自身的策略不断改进。对于初始化的策略,在任意时刻的状态,每个动作被选中的概率都是随机的,通过智能体与环境交互得到奖励值的反馈,使得好的动作被选中的概率不断增大。演员-评论家算法在PG算法的基础之上增加了一套神经网络,即动作网络和评论家网络,前者接受到环境传入的状态输出一个对应的动作,后者根据动作作用于环境反馈得到的奖励进行更新,并且可以观测到现在所处状态的潜在奖励,用于指导动作网络。相比PG算法,演员-评论家算法可以实现每一步都对神经网络参数进行更新,而不必像PG算法一样等到回合结束的时候才对网络参数进行更新。近端策略优化(proximal policy optimization, PPO)算法同样采用了和演员-评论家一样的神经网络结构,PPO基于演员-评论家算法,利用更新之后的新的策略与旧的策略的比例进行更新,限制了策略更新的幅度,使得整个算法更具趋于平稳。所使用的DPPO方法是在PPO算法的基础之上,增加了多个线程,提升了学习速率。DPPO算法使用了优势函数,优势函数Aπ(s,a) 表示在状态s,选取动作a的优势有多大,和Q-learning的Q值有着类似的作用。不同的是,优势函数评估的是在某个状态采取各动作相对于平均回报的好坏,也就是采取这个动作的优势,而Q值评估的是某个状态采取各个动作的好坏。优势函数表达式为
Aπ(s,at)=Rπ(s,a)-Vπ(s)
(25)
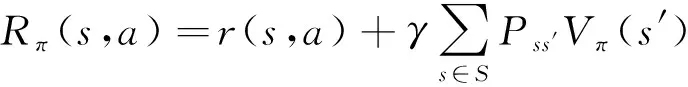
(26)
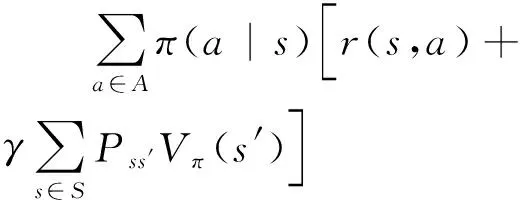
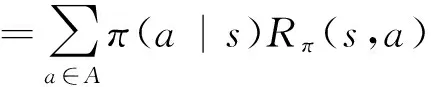
(27)

(29)
式(27)表示随着不断更新,新的策略相对旧策略的累计奖励汇报的期望值;式(28)表示目标值函数η(π)。在实际中,为了有更高的鲁棒性,选取剪辑代理目标(clipped surrogate objective)的方法来代替式(29)的更新方式,得
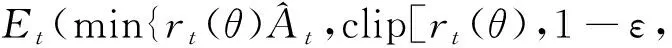
1+ε]At})
(30)
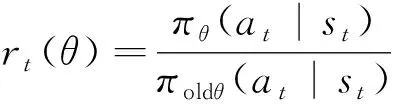
(31)
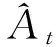
2.2 基于DPPO算法的分布式能源系统运行优化
采用深度强化学习用来解决CCHP系统的调度优化问题。首先,将能源系统调度优化问题转化成MDP;其次,选取可人为控制的能源设备作为控制对象,对应地对MDP中的状态空间和动作空间进行设计;最后,依据目标函数设计奖励函数用于指导智能体的学习。
2.2.1 状态空间
在强化学习中,状态空间需要能够充分描述环境的状态,合理地设计状态空间可以帮助算法更快地收敛。环境是CCHP能源系统,环境提供的信息包括在各时间步长的可再生能源出力、电价、电力负荷、供热负荷、冷负荷。因此,状态空间可定义为

表1 DPPO算法流程
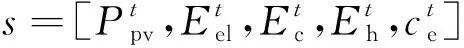
(32)
2.2.2 动作空间
当智能体接收到环境给出的状态,它将根据当前的策略从动作空间中选择一个动作作用于环境。动作是指各供能设备的出力,包括内燃机的发电功率、从电网流入的电功率、电制冷机组和吸收式制冷机组的制冷功率、燃气锅炉、内燃机的热功率。因此,动作空间可定义为

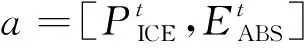
(34)
2.2.3 奖励
对于强化学习来说,奖励值的作用是指导智能体学习,最终学习到最优策略。奖励函数一般基于目标函数进行设计,选取运行费用及设备容量约束作为奖励函数,可得
r=-(Ce+Cgas+Pgb+Pec)
(35)
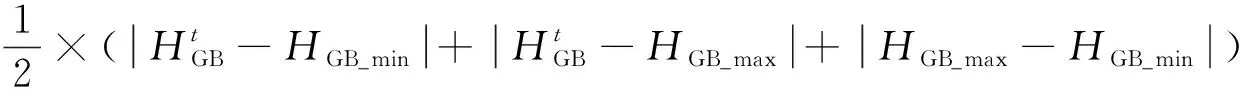
(36)
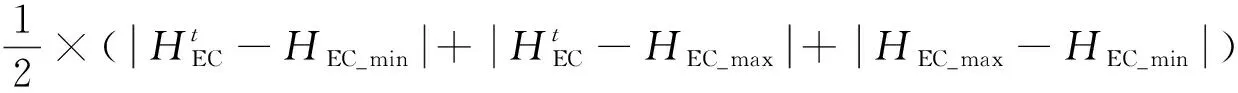
(37)
式中:Pgb和Pec分别为燃气锅炉和电制冷机出力不满足设备约束条件时的惩罚值。
3 案例仿真
3.1 算例数据及参数选取
分布式能源系统各个设备的参数如表2所示,深度强化学习智能体的超参数如表3所示。
选取历史全年负荷数据的6—7月,即60 d的数据作为训练数据。训练数据的电负荷、冷负荷、太阳能电功率如图3所示,采用上海的分时电价。

表2 设备参数

表3 智能体超参数
3.2 仿真结果及分析
3.2.1 调度结果
从全年历史数据里的测试数据集里取1 d夏季工况,用于实时调度优化测试,其负荷数据及光伏出力情况如图4所示。
图5(a)、图5(b)分别为将该测试日的负荷数据及太阳能出力输入到训练完毕的智能体后输出得到的电、冷调度策略。
由图5可以得到以下结论。
(1)在电负荷需求较低的时刻(1~8 h,23~24 h),并且此时电价较低,内燃机保持关闭状态,电负荷由电网购电满足。
(2)在电负荷需求较高时刻(10~22 h),光伏发电首先被利用,受该日天气因素影响,太阳能仅在8~14 h刻被利用;10~21 h购电成本较高,内燃机启动发电,且处于较高的负载率,剩余电负荷需求由电网购电提供。
(3)在没有冷负荷的时刻(1~9 h,23~24 h)各制冷设备保持关闭;在冷负荷需求较高的时刻(10~22 h),吸收式制冷机启动制冷,且处于较高负载率,可以充分利用内燃机发电产生的余热,不足的冷负荷由电制冷机满足其余的冷负荷。
上述阐明通过DDPO算法训练得到的智能体可以实现对CCHP系统的运行调度,满足各个时刻的负荷需求。现选取6个测试日对该智能体调度策略的经济性进行对比分析,并选择另外一种基于值的经典的深度强化学习方法DQN及基于LINGO的线性规划进行对比。其中DQN将设备出力连续的动作空间进行离散:a=[0,0.25,0.5,0.75,1],神经网络的结构及参数与DPPO算法相同。在使用LINGO 对能源系统运行优化时,首先需要得到负荷的预测值,LSTM方法可以处理非线性关系,预测精度较高,因此采用该方法对负荷进行预测。LSTM神经网络搭建于Tensorflow平台,含有3层隐藏层,分别有64、100和25个神经元。预测得到测试日的负荷数据如图6所示。
由于预测存在一定偏差,最终基于LINGO得到的设备出力可能无法完全满足用户负荷需求,因此不满足的电负荷将由电网购电补充,不满足的冷负荷将由电制冷机补充。测试日运行费用如图7所示,具体数值如表4所示。相比DQN算法,DPPO算法得到的调度策略总运行费用降低7.12%,相比LINGO得到的调度策略,总运行费用降低2.27%,因此本文提出的基于DPPO算法的调度方法可以实现对分布式能源系统的经济性调度。
3.2.2 策略对比分析
对3种不同的方法得到的分布式能源系统调度策略进行对比分析,6个测试日的内燃机、 吸收式制冷机及电制冷机运行情况如图8(a)、图8(b)、图8(c)所示。
在每个测试日的1~8 h,购电费用较低,直接从电网购电来满足电负荷需求更具有经济性,9~21 h,购电费用较高,此时启动内燃机发电更便宜,并且产生的余热可以用来驱动吸收式制冷机提供冷负荷,具有更高的经济性。由图8(a)可知,总体来说,采用DPPO和LINGO方法获得的内燃机的运行策略大致相同,DPPO算法的激活函数选取的是双曲正切函数,因此实际上算法输出的动作始终是介于-1~1的,从而对应设备的出力功率也是介于0和最大容量之间的,这也是当LINGO和DQN中设备出力功率达到最大容量时,DPPO设备的出力功率略小于DQN和LINGO。
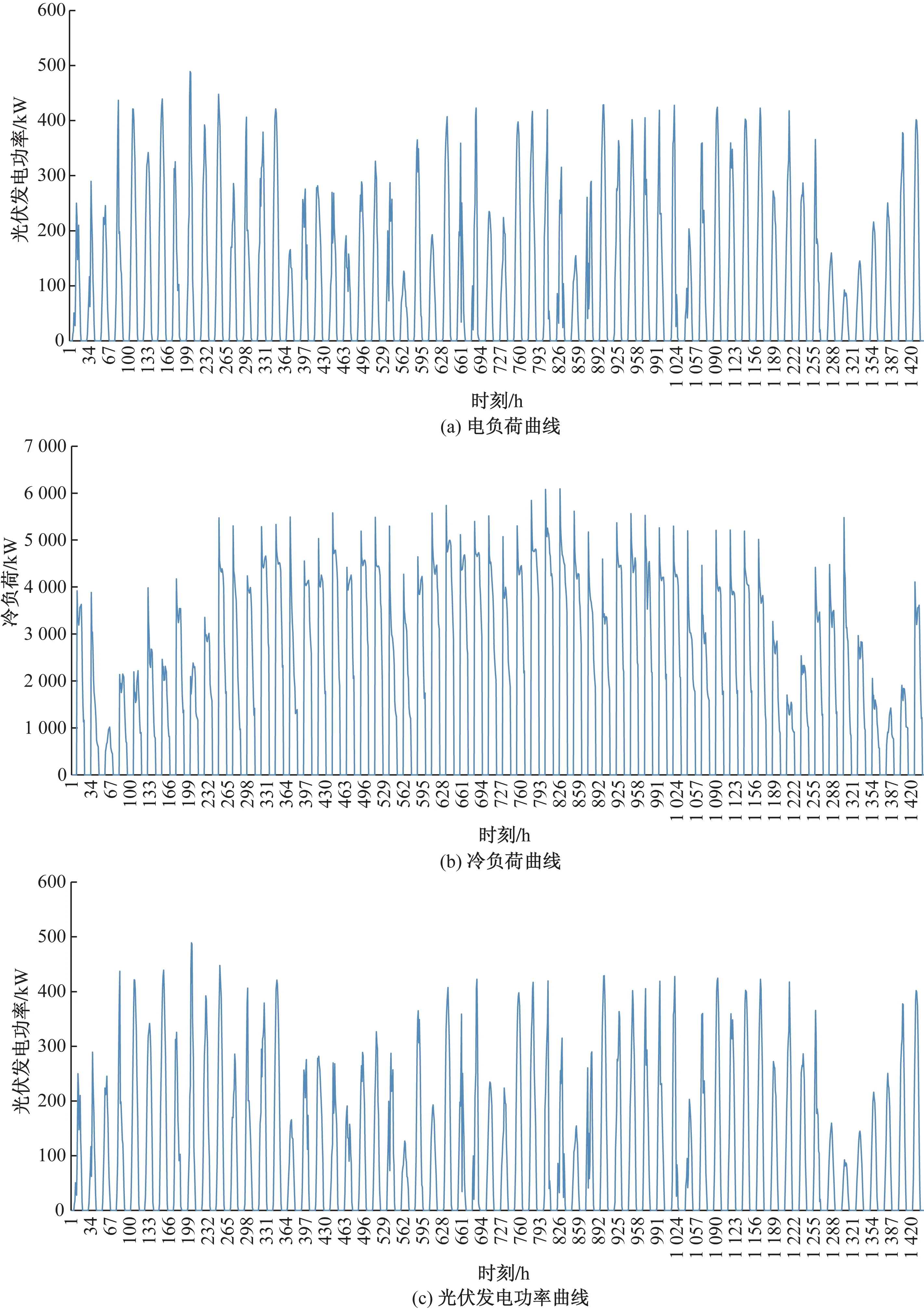
图3 训练数据电负荷、冷负荷和光伏发电功率曲线Fig.3 Power load, cooling load and PV power curves of training data
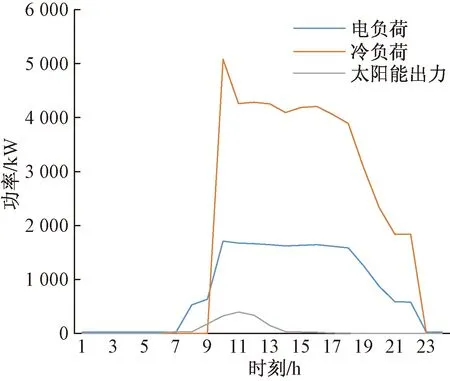
图4 测试日负荷及太阳能出力曲线Fig.4 Load and solar output curve of test day
此外,DQN算法得到的内燃机运行策略,不稳定,具有波动性,并且还存在频繁启停问题,由此可知DQN算法在训练的过程中,受状态空间、动作空间数量大的影响,始终在最优值附近保持震荡,无法收敛,因此无法充分发挥内燃机的经济性,导致运行费用增加。
由图8(b)可知,1、2、3、6测试日DPPO和 LINGO 的吸收式制冷机运行情况大致相同, DQN方法的吸收式制冷机运行情况同样存在波动、不稳定的问题,并且没有充分利用内燃机的余热,没有充分发挥吸收式制冷机的经济性。
由图8(c)可知,对于测试日1、2、3、6,DPPO算法和LINGO获得的电制冷机的运行策略比较接近,而在测试日4和5,由于LSTM负荷预测存在一定的误差,使得该两日的冷负荷预测值相较实际值偏大,如图6所示,因此LINGO得到的调度策略电制冷机承担了更多的冷负荷,产生了更多的运行费用。
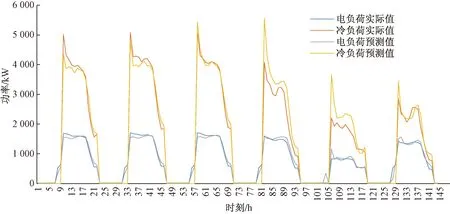
图6 测试日实际负荷和预测负荷曲线Fig.6 Actual load and forecast load curve of test days
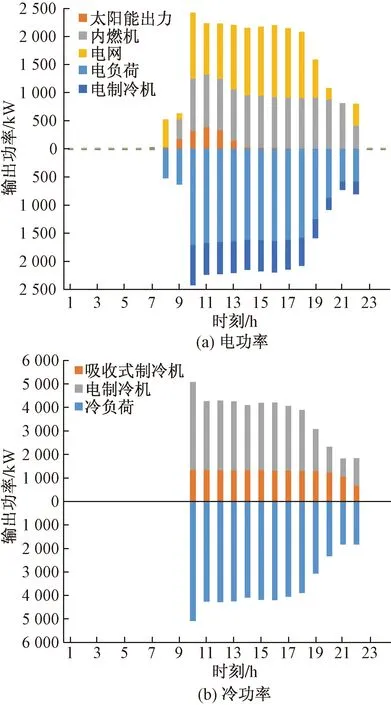
图5 测试日电功率和冷功率调度策略Fig.5 Power and cooling power scheduling policy of test day
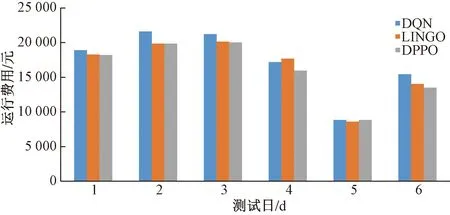
图7 测试日运行费用Fig.7 Operating cost of test days
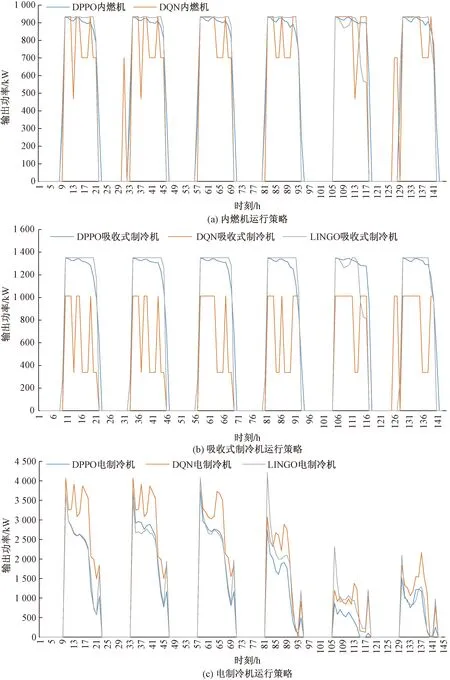
图8 测试日运行策略对比分析Fig.8 Comparison and analysis of operating strategy of test days
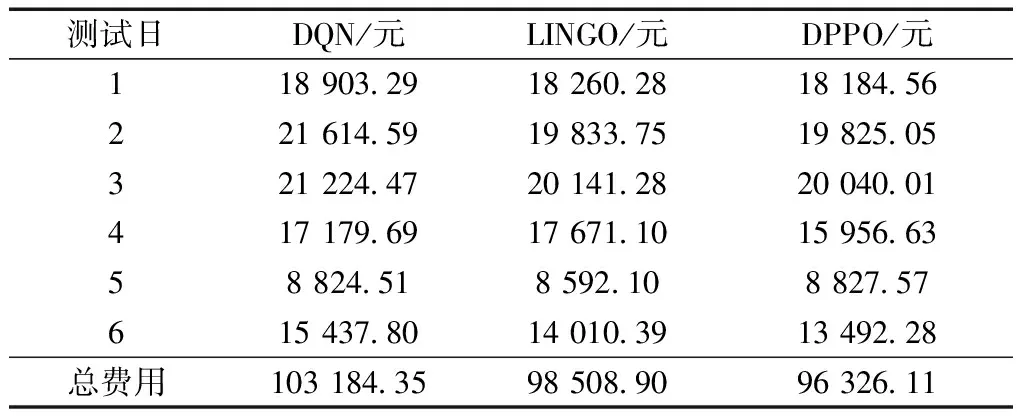
表4 测试日运行费用
对于DQN算法,由于其收敛效果不佳,导致其吸收式制冷机没有得到充分的利用,因此电制冷机承担了更多的冷负荷,增加了运行费用。
4 结论
提出了一种基于DPPO深度强化学习算法的分布式能源系统运行优化方法。该方法以能源系统运行的经济性为目标函数,实现了对分布式能源系统各个设备的经济性调度优化。与传统方法相比,本文方法不需要对能源系统的不确定性因素进行数学建模,并且利用历史数据对智能体进行训练,训练完毕后的智能体可以直接用来进行实时动态调度,不需要在每一次调度任务之前重复训练;与DQN算法相比,可以避免将动作空间离散化导致的维数较大算法不收敛的问题。通过比较DPPO方法、DQN方法及LINGO获得的调度策略,可以证明,本文方法可以实现对分布式能源系统的经济性运行优化。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
纺织标准与质量(2022年2期)2022-07-12
航天返回与遥感(2022年3期)2022-07-07
北京航空航天大学学报(2022年5期)2022-06-06
南方农业·下旬(2022年4期)2022-05-24
煤气与热力(2022年4期)2022-05-23
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年6期)2021-07-20
上海航天(2021年1期)2021-03-04
小资CHIC!ELEGANCE(2019年5期)2019-04-30
