
基于多层次非负稀疏编码和SVM的窃电检测方法
2022-07-28 06:19张爱枫
重庆大学学报 2022年7期
黄 刚,颜 伟,王 浩,文 旭,,张爱枫,夏 春
(1.重庆大学 输配电装备及系统安全与新技术国家重点实验室,重庆 400044;2.深圳供电局有限公司,广东 深圳 440310;3.国家电网公司西南分部,成都 610041;4.重庆电力交易中心有限公司,重庆 400013)
电力用户的窃电行为将会给电网公司造成巨大经济损失[1],传统的物理窃电方式正发展为以数字存储和网络通信技术为手段的新型窃电方式,通过攻击智能电表注入虚假用电数据实施窃电[2],因此对新型窃电方式检测方法的研究具有重要工程价值。
针对虚假用电数据注入的窃电方式,现有检测方法一般遵循“特征设计 检测判别”的范式[3]。然而多数方法的研究侧重检测判别阶段,重点研究检测判别算法的选择或改进,提出了多种窃电检测模型,包括基于分类的支持向量机[4]、随机森林[5]、极限学习机[6],基于聚类的最优路径森林[7]、密度聚类[8],以及基于回归的自回归模型[9]等。而针对检测特征设计的研究较少,已有研究主要通过特征提取算法对用电曲线进行抽象凝练;文献[10]首先通过小波分解提取负荷曲线的时域和频域特征,然后通过多个分类器的分类结果交叉验证检测窃电用户;文献[11]首先通过主成分分析算法提取用户用电曲线中的用电特征,然后通过密度聚类算法对异常用电曲线进行检测;文献[3]以堆叠去相关自编码器提取周负荷曲线的用电特征,然后用定制惩罚项的支持向量机检测窃电用户。可见,现有窃电检测方法更多依赖通用特征提取算法对用电数据数值特征的提取能力,缺乏对正常用电或窃电情景的分析,导致特征设计过程与检测对象的物理背景耦合度低,使得所提取特征可解释性差,难以依据其物理意义调整改进,同时一些较为明显的窃电数据特征没能纳入检测特征,使得检测特征的针对性不强。
据此,文中提出了一种基于多层次非负稀疏编码和支持向量机的窃电检测方法。该方法以用户月度用电曲线为检测对象,首先,将月度用电曲线切分为周、日两个层次并基于非负稀疏编码算法提取多层次用电曲线用电模式特征;然后,基于正常用户和窃电用户用电情景对比分析,手工提取周、日两层次用电曲线的数值统计特征;最后,以用电模式特征和数值统计特征的融合检测特征为输入,通过SVM算法对用电曲线进行窃电检测。该方法主要创新点在于:1)周、日两层次用电特征提取呼应用电行为具有周周期性和日周期性的实际,用电特征刻画更精细;2)综合用电模式特征和数值统计特征构建曲线的融合检测特征,可解释性好、针对性强。
1 基于多层次非负稀疏编码和SVM的窃电检测方法整体设计
电力用户窃电检测的难点在于现实中台区电网接线复杂,网络拓扑参数信息未知,难以通过潮流等精确物理约束检测窃电用户;此外,用户的用电负荷低、随机性高,简单的统计分析也难以捕捉用户的用电规律,检测准确率低。得益于智能电表在终端用户数据采集中的应用,海量高分辨率的用户用电数据为数据驱动的窃电检测方法提供了条件,用户窃电检测的研究逐渐转向数据驱动方法,形成了一种“特征设计 检测判别”的范式,设计待检测用电曲线样本的检测特征,并采取各种机器学习检测算法对样本进行检测。参考现有数据驱动窃电检测方法的通用范式,文中提出一种基于多层次非负稀疏编码和SVM的窃电检测方法,其整体框架设计如图1所示。
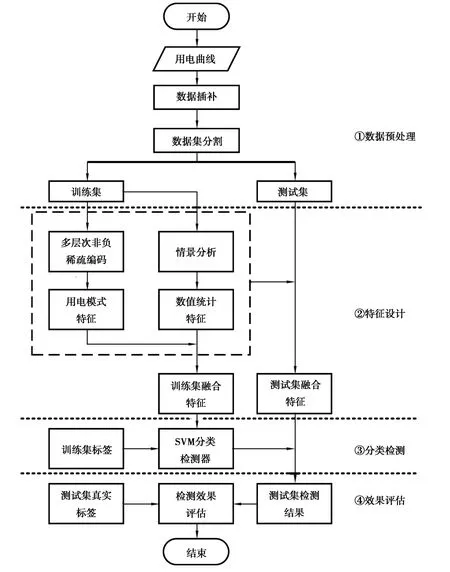
图1 基于多层次非负稀疏编码和SVM的窃电检测方法整体框架Fig.1 Framework of electricity theft detection method based on multi-level non-negative sparse coding and SVM
由图1可见,该整体框架分为4个阶段。
阶段1:数据预处理阶段。该阶段对用电曲线的缺失数据进行插补,并将数据集分割为训练集和测试集;
阶段2:特征设计阶段。基于多层次非负稀疏编码提取月度用电曲线的周、日多层次用电模式特征,以及正常用电和窃电情景分析提取用电曲线的数值统计特征,综合用电模式特征和数值统计特征形成曲线的融合检测特征;
阶段3:分类检测阶段。利用阶段2中训练集的融合检测特征及其对应标签训练SVM分类器,将测试集的融合检测特征输入SVM分类器,得到测试集用电曲线的分类检测结果;
阶段4:效果评估阶段。将测试集分类检测结果与真实标签对比,通过精确率、召回率、F1值等指标评价窃电样本的检测效果。
上述4个阶段中,数据预处理阶段主要借鉴现有文献采取线性插值法对缺失数据进行填充,文中重点研究特征设计阶段、分类检测阶段和效果评估阶段等3个阶段。
2 基于多层次非负稀疏编码和情景分析的月度曲线检测特征设计
用电曲线的特征主要分为形状和数量特征2类,若要充分提取用电曲线的用电特征,需同时对用电曲线的形状特征和数量特征进行刻画。采取多层次非负稀疏编码算法将月度用电曲线切分为周层次曲线和日层次曲线,并对其分别进行非负稀疏编码,获取用电曲线的周周期和日周期用电模式,借此提取用电曲线的形状特征;而后基于正常用电和窃电情景的对比分析,手动提取用电曲线的数值统计特征,作为曲线的数量特征。
2.1 基于多层次非负稀疏编码的月度曲线用电模式特征构建
2.1.1 非负稀疏编码原理及算法
稀疏编码是一种信息压缩算法,广泛应用于数据压缩领域,其原理是寻找一组过完备基向量对样本变量进行线性组合表示。基向量组由于过完备性将是非正交且冗余的,用少于样本变量维度数目的基向量即可实现对样本的线性表示,基向量的线性组合系数具备稀疏性,非负稀疏编码则在稀疏编码的基础上对基向量元素和线性组合系数增加了非负性约束。
电力用户的用电曲线可以看作是若干种用电模式下用电曲线的加权线性组合,这与非负稀疏编码的思想非常契合,因此可以将非负稀疏编码引入用电曲线的用电模式特征提取过程。非负稀疏编码中的每个基向量代表一种用电模式,而每个基向量对应的稀疏编码值则代表该种用电模式的线性组合系数,通过非负稀疏编码过程可将原始用电曲线解构为少数几种用电模式的线性叠加,即可实现用电曲线的用电模式特征提取。用电曲线的非负稀疏编码解构与重构如图2所示。
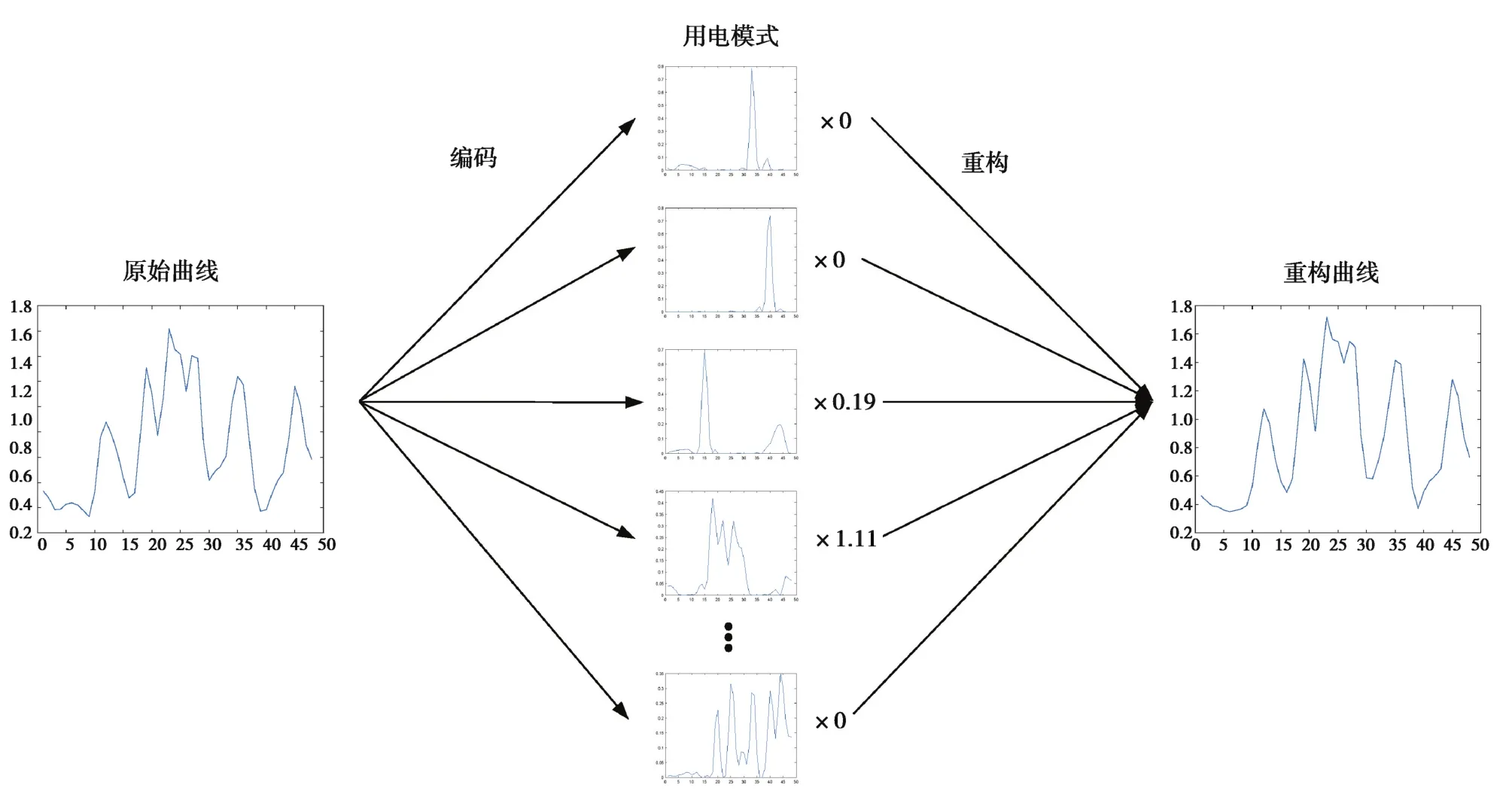
图2 用电曲线的非负稀疏编码解构与重构Fig.2 Deconstruction and reconstruction of electricity consumption curve by non-negative sparse coding
样本矩阵X的非负稀疏编码求解模型为
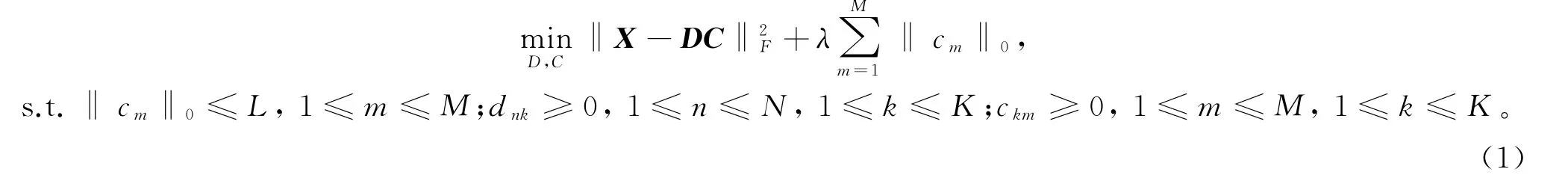
式中:X是N×M维样本矩阵,含有M个N维样本变量;D为过完备基向量组,包含K个N维基向量,且K>N以保证基向量的过完备性。通常称D为编码字典,D中的基向量为字典原子;C为样本的稀疏编码矩阵,是样本变量解构为字典原子线性组合时的权重系数,为一稀疏矩阵;‖‖F(F-范数)表示矩阵元素平方和的平方根;‖‖0(0范数)表示向量非零元素个数;λ为稀疏度约束惩罚系数。
由于模型中字典D和稀疏编码C都是变量,难以同时优化,故通常将优化模型分解为稀疏编码和字典更新两阶段,采取分阶段交替优化迭代的策略求解。文献[12-13]提出了一种适用于非负稀疏编码的字典学习算法,该算法采取基追踪(BP,basis pursuit)算法求解样本的稀疏编码阶段,而采取迭代奇异值分解(K-SVD,K-singular value decomposition)算法更新编码字典。
稀疏编码阶段,固定字典D为常量,将目标函数中稀疏度约束的0范数转化成1范数。同时基于稀疏编码的非负性,可将目标函数式(1)转化为
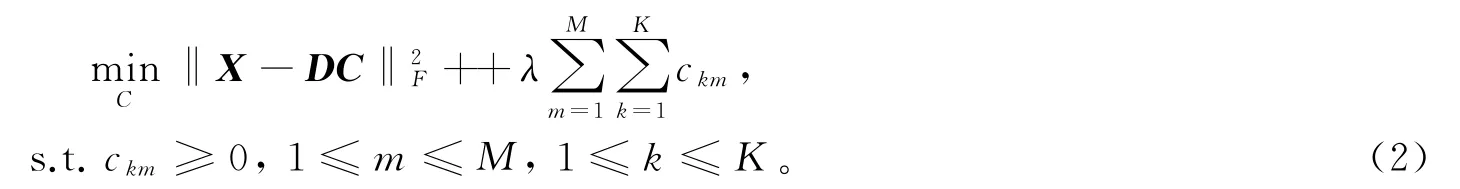
根据文献[13]的推导,可得到稀疏编码矩阵C的迭代求解为
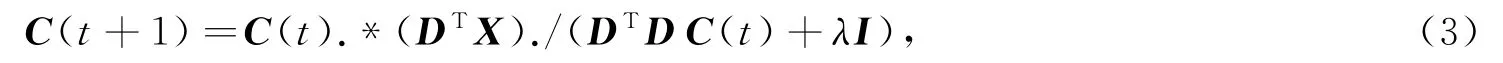
式中,稀疏编码矩阵的初值C(0)初始化为零矩阵。为确保稀疏编码向量c有指定数值的稀疏度约束L,需将样本变量x用其对应编码向量c中编码最大的L个字典原子进行线性表示。

字典更新阶段,固定稀疏编码C为常量,目标函数转化为
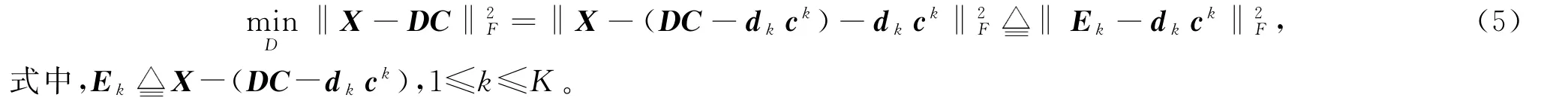
遍历更新所有字典原子dk及其对应编码行向量ck,使重构误差逐步降低,同时实现对字典原子的更新

最大奇异值对应的左奇异向量u1,初值更新为最大奇异值与其对应右奇异向量转置的乘积
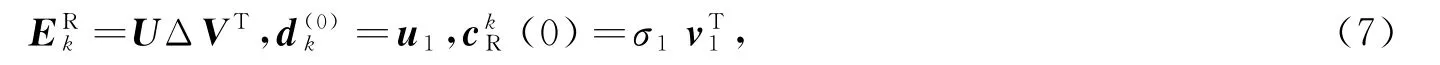
同时,为保证字典原子和编码的非负性,通过下述迭代处理将dk和ck中的负值截断为零:
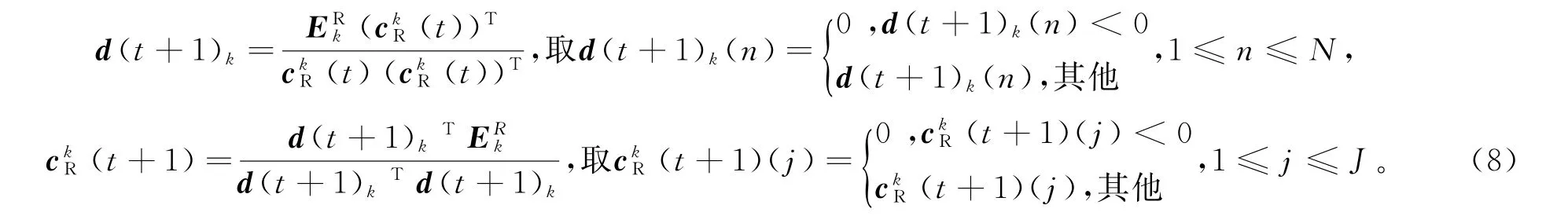
非负稀疏编码算法的流程如图3所示。
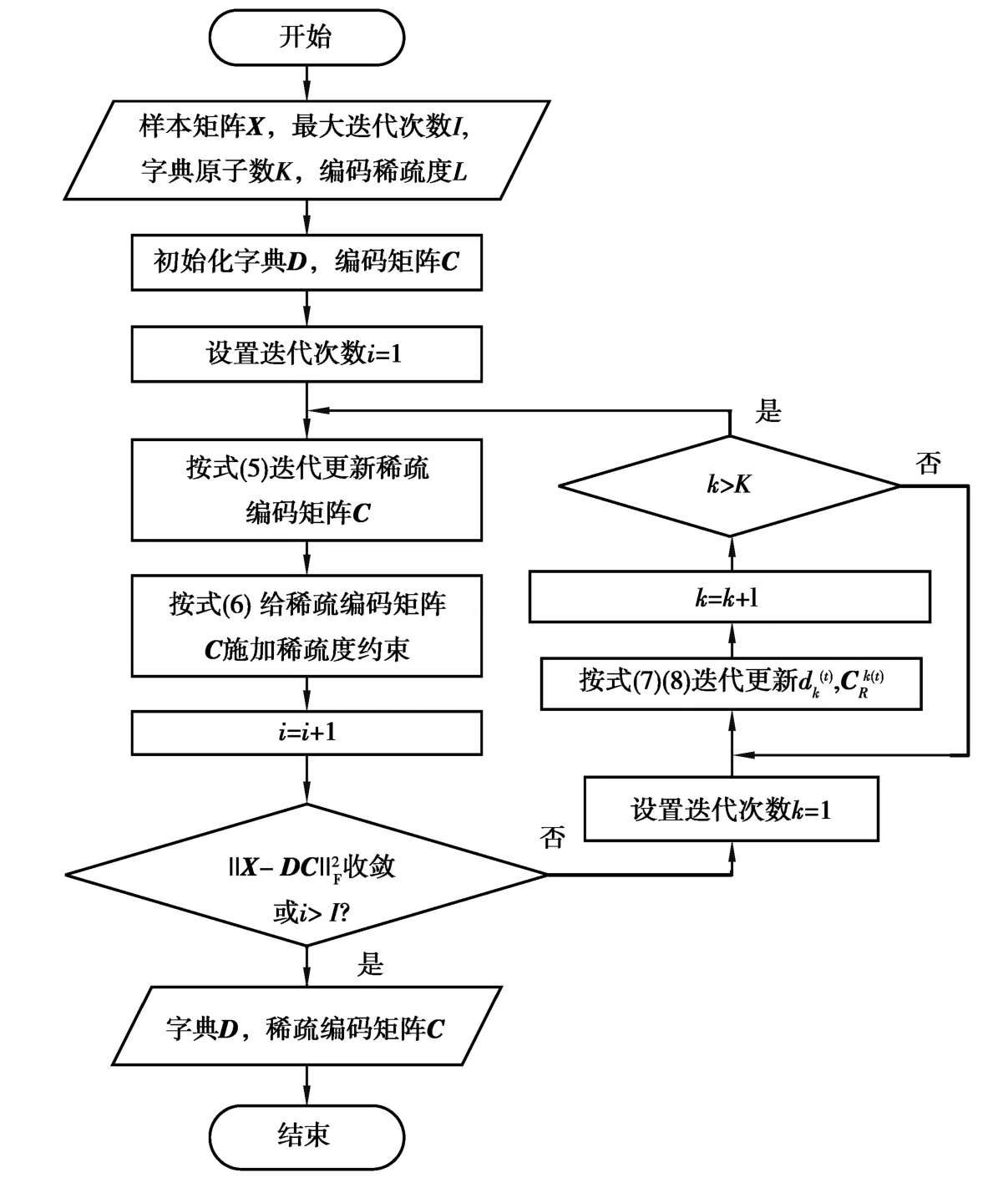
图3 非负稀疏编码算法流程图Fig.3 Flow chart of non-negative sparse coding algorithm
2.1.2 月度用电曲线的多层次非负稀疏编码
考虑到用户月度负荷曲线在时序上具有周周期性和日周期性,用户用电曲线是否具有稳定且普遍的周周期性和日周期性是判断用户是否窃电的重要依据,因此可以将月度负荷曲线切分为周、日两个层次的曲线子序列,分别通过上述非负稀疏编码算法提取其用电模式特征,以考察其周周期性和日周期性。
设月度用电曲线跨度为T天,则将月度曲线按日切分,可得到T个日层次曲线子序列。另用长度为7天的滑窗对月度曲线进行切分,步长为1 d,可获得(T-6)个周层次曲线子序列。同时考虑到一周内各天(尤其是工作日与周末)之间用电特性的区别,将每个周曲线子序列内部各天都按照同一顺序排列,一条时长31 d、数据采集分辨率30 min一次的月度用电曲线的周、日两层次切分过程如图4所示。
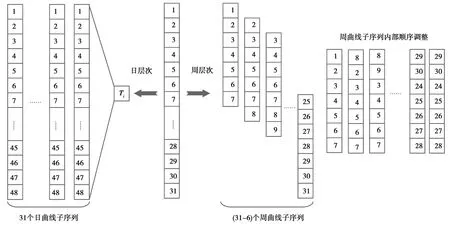
图4 月度曲线样本的周 日两层次切分Fig.4 Weekly-daily two-level segmentation of monthly curve samples
含有M个用户、采集时长跨度T天且数据采集日分辨率为t点/天的月度用电曲线样本集XN×M(其中N=Tt)做上述两层次切分,可得到周层次、日层次曲线子序列样本集分别为(其中Nw=7t,Nd=t,分别为周层次、日层次曲线子序列的分辨率;Mw=(T-6)×M,Md=T×M,分别为周层次、日层次曲线子序列样本数)。然后,分别在周层次和日层次上对子序列进行非负稀疏编码,得到编码字典分别为(其中Kw和Kd分别为周、日层次编码字典的字典原子数),对应非负稀疏编码矩阵为。
2.1.3 基于多层次非负稀疏编码的用电模式特征构建
通过上述多层次非负稀疏编码过程已获取了表征月度曲线周、日两层次用电模式特征的稀疏编码,然而由于字典原子的冗余性,稀疏编码特征具有高维度、高稀疏性的特点,价值密度低,不适合直接作为用电曲线的模式特征。同时,由于正常样本远多于窃电样本且正常用电模式相对窃电用电模式更少、更集中,非负稀疏编码对正常用电曲线和窃电曲线的重构误差存在结构性差别,也应作为用电模式特征的辅助特征。据此,在多层次非负稀疏编码的基础上对月度用电曲线的用电模式特征进行进一步构建,新构建的用电模式特征分两个部分:一是基于周、日两层次用电曲线的稀疏编码构建的用电模式正常度特征;二是周、日两层次用电曲线的非负稀疏编码重构相对平均误差。
用电模式正常度特征的构建过程如下:首先,忽略用电曲线的数量特征而仅考虑其形状特征,将样本曲线的稀疏编码转化成各编码系数的占编码系数总和比例的分数形式,用以表征原始曲线中各用电模式的占比为
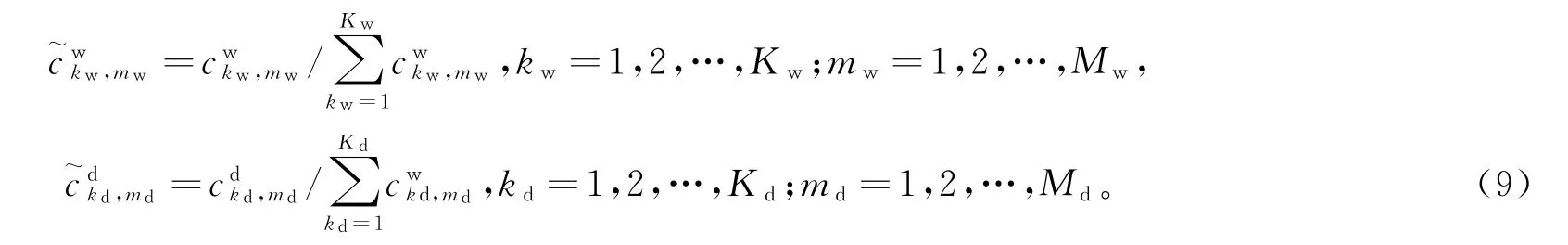
然后,根据各用电模式在全体样本中占比的总和确定各用电模式的正常度为:
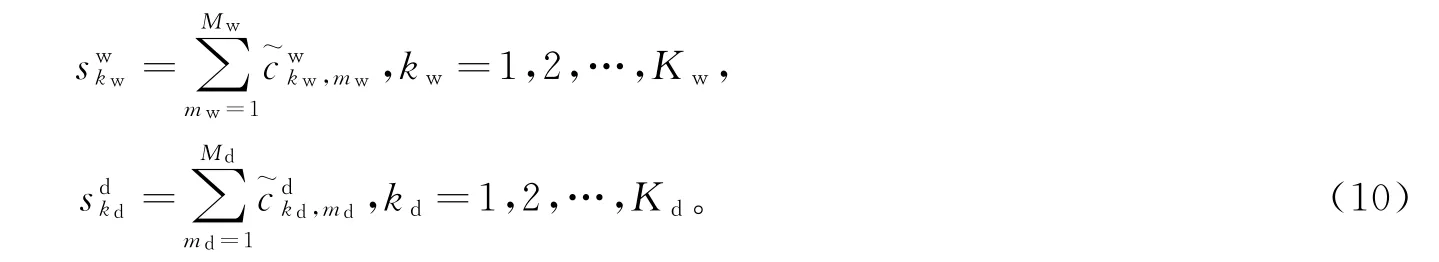
最后,将样本曲线中各用电模式的正常度加权求和即可得该样本的用电模式正常度为:
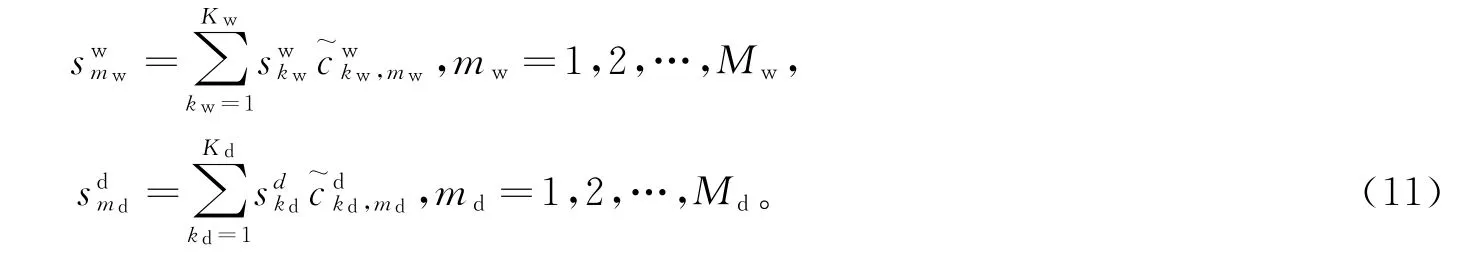
对于每个用户,将其周、日两层次用电曲线子序列样本的用电模式正常度整合,即可得到该用户用电模式正常度特征为
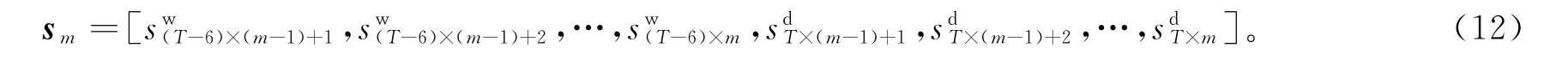
样本曲线的非负稀疏编码重构平均相对误差定义为重构曲线与原始曲线之间的相对误差,具体定义为:
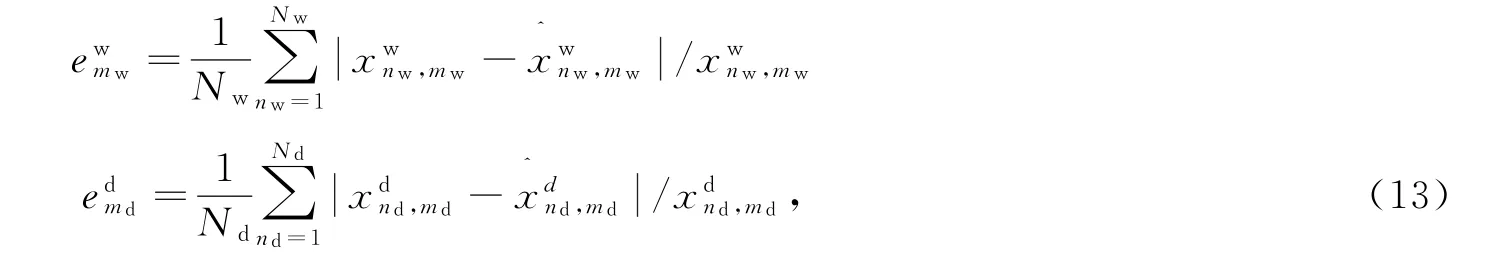
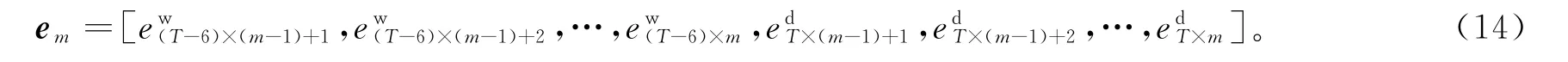
2.2 基于窃电情景分析的月度用电曲线数值统计特征构建
现实中窃电用户与正常用户电量数值存在一些系统性差异,通过捕捉这些差异构建用电曲线的数值统计特征,可提高窃电检测效率。一般而言,窃电行为在时间上有持续性且在数量上有较大幅度,窃电用户平均负荷水平相较正常用户将有一定幅度的差距;同时窃电用户电量通常会出现长时间为0或者某一较低数值的情况,且数值波动小。鉴于窃电行为的上述特征,可将电量平均值、方差和非重复数值个数等系统性差异变量作为月度用电曲线的数值统计特征,依旧分周、日两个层次,为:
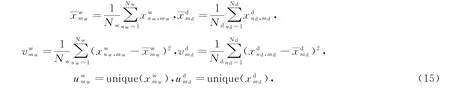
式中,unique(x)表示向量x中非重复数值的个数。整合上述周、日两层次用电曲线的数值统计特征可得用户月度用电曲线的数值统计特征为:
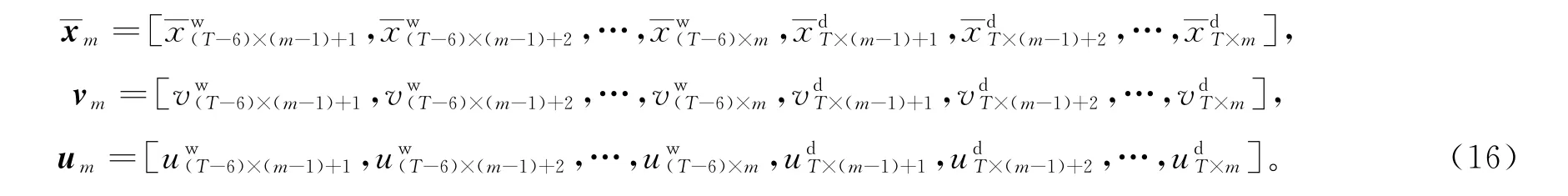
2.3 月度用电曲线用电模式特征和数值统计特征的融合
上述多层次非负稀疏编码算法在周、日两个层次上构建了月度用电曲线的用电模式特征和数值统计特征,综合二者设计用户的融合检测特征为
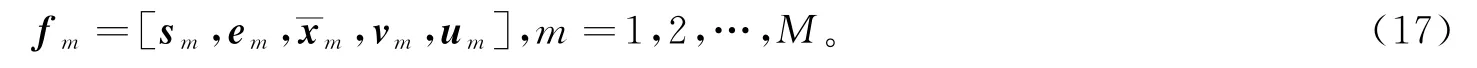
上述融合检测特征的组成结构如图5所示。
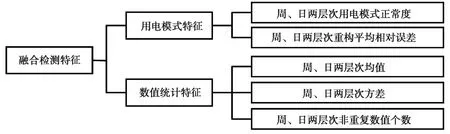
图5 融合检测特征的组成结构Fig.5 Composition structure of fusion detection features
由图5可知,融合检测特征兼顾了周、日两个层次下月度用电曲线形状和数量两方面特征,即用电模式特征和数值统计特征。其中,用电模式特征包括用电曲线的用电模式正常度和重构平均相对误差;数值统计特征包括用电曲线的均值、方差以及非重复数值个数。
3 基于SVM的窃电样本检测及检测效果评估
SVM是一种有监督分类算法,其基本原理是寻找一个最优超平面将特征空间中的样本点一分为二,并使得不同标签的两类样本点离超平面的间隔最大。对于线性不可分问题,通过核技巧将输入样本映射到高维空间,使得低维特征空间中线性不可分的样本在高维空间中线性可分。SVM由于其在高维特征分类问题上良好求解性[14],多次被用于窃电检测,故文中选用高斯核函数非线性SVM算法进行窃电样本的检测判别。通过带标签的训练集对高斯核函数非线性SVM分类器进行训练求解,以测试集测试分类器的检测效果,高斯核函数非线性SVM分类器的求解流程[15]如下:
1)将训练集样本的融合检测特征fi及其标签yi∈{-1,1}(i=1,2,…,N,y=1表示窃电)作为输入,线性SVM的模型为:
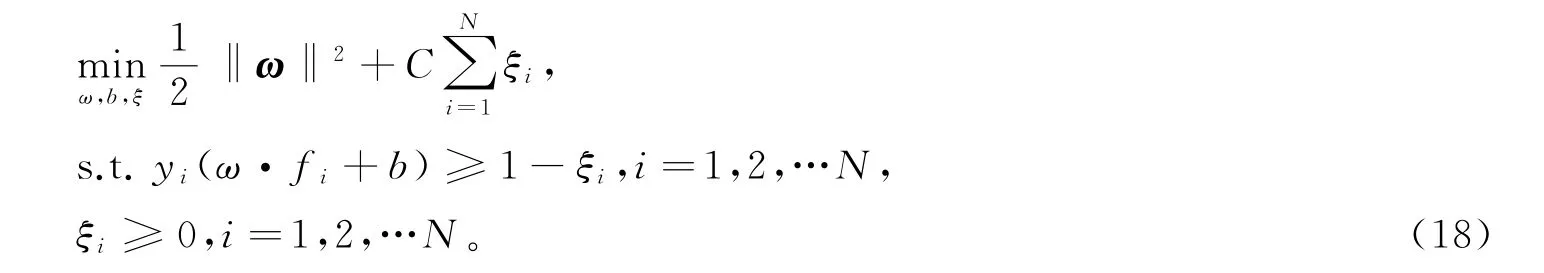
式中:ω为特征权重向量;ξi为函数间隔松弛变量;C为松弛变量的惩罚超参数。
2)将线性SVM转化为其对偶问题,同时引入高斯核函数可得到高斯核函数非线性SVM模型,为:
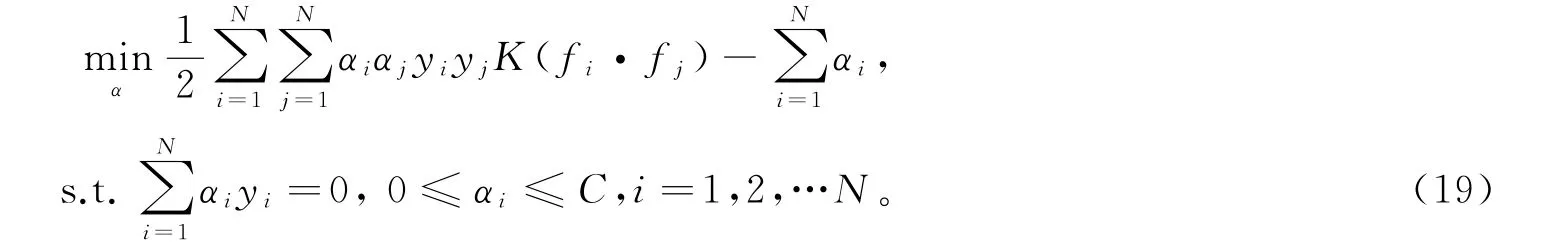
式中α=(α1,α2,…,αN)T为拉格朗日乘子向量;K(·)表示高斯核函数,为:
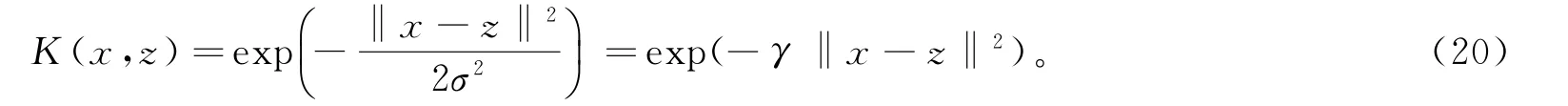
式中,γ为核函数待定超参数。
3)求解式(19)得最优解α*,然后计算

4)构造决策函数,预测样本的分类结果为

窃电样本检测效果评价指标选择基于混淆矩阵的精确率P、召回率R、F1值,具体表达式为式(23)。其中,精确率是指被判定为异常的样本中实际为异常的比例;回率是指实际异常样本被检测出来的比例,而F1值则是精确率与召回率的调和平均值,只有精确率与召回率都较高才能取得较高的F1值。
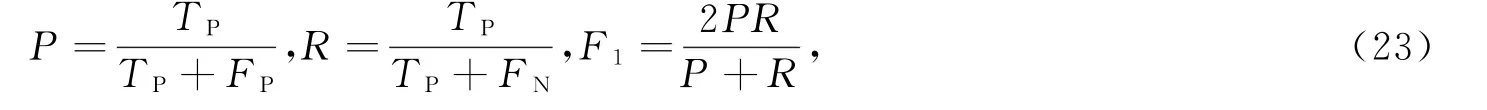
式中:TP表示真阳性(窃电)样本数;FP表示假阳性样本数;FN表示假阴性样本数。
4 算例分析
4.1 基础数据
以爱尔兰智能电表数据集[16]为基础构造本算例基础数据。该数据集包括了6 000多户低压台区用户近18个月的用电量数据,时间分辨率为30 min。以数据集中3 000个用户某月用电数据构造算例样本,随机选取20%的样本模拟窃电样本,按文献[17-19]中的数据篡改方式对选中窃电样本作表1所示6种处理,通过分层抽样方法将样本集按7∶3的比例随机分为训练集和测试集。

表1 窃电数据篡改方式及对应数学表达式Table 1 Data tampering methods for electricity theft and corresponding mathematical expressions
4.2 基于非负稀疏编码提取用电模式特征的合理性验证
非负稀疏编码能够有效提取用电曲线用电模式特征的关键在于编码字典和编码稀疏能够良好地重构原始用电曲线,因此需要考察非负稀疏编码对原始用电曲线的重构效果。非负稀疏编码算法中字典原子数目K和编码稀疏度L2个参数对用电曲线的重构平均相对误差平均值的影响如图6所示。
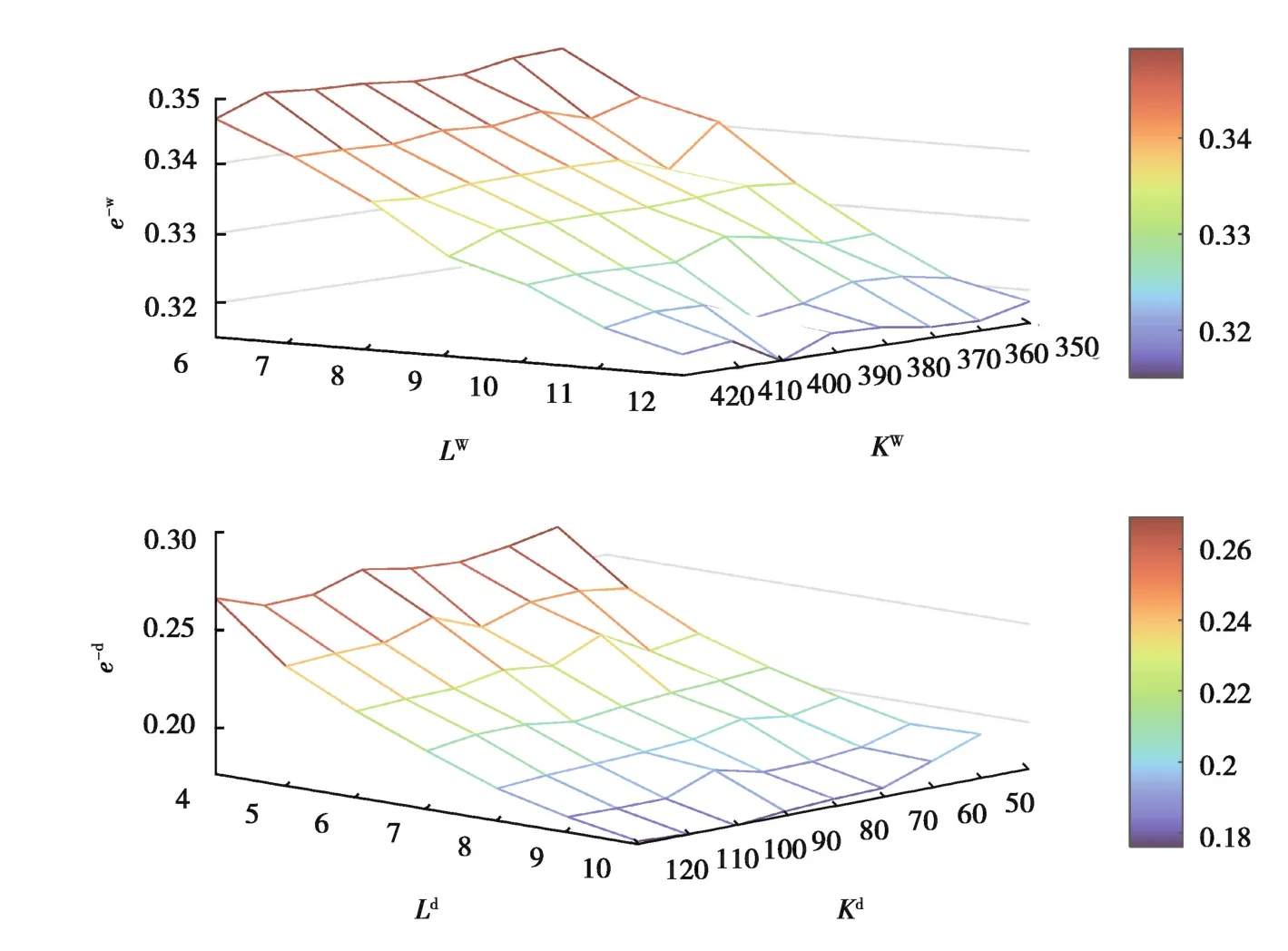
图6 参数K和L对非负稀疏编码重构平均相对误差的影响Fig.6 The influence of parameters K and L on the average relative error of non-negative sparse coding reconstruction
由图6可知,增大字典原子数目K和稀疏度L都可以降低周、日层次用电曲线非负稀疏编码重构的平均相对误差,且相对而言增加编码稀疏度L对于提升曲线重构精度的效果更加明显。平衡重构效果与计算负担,选取周层次非负稀疏编码参数Kw为400,Lw为12、日层次参数Kd为80,Ld为10,在上述参数设置下,周、日两个层次下典型正常、窃电曲线的直观重构效果如图7所示。周、日两个层次下正常、窃电曲线样本重构平均相对误差的平均值、中位数、最大值、最小值如表2所示。
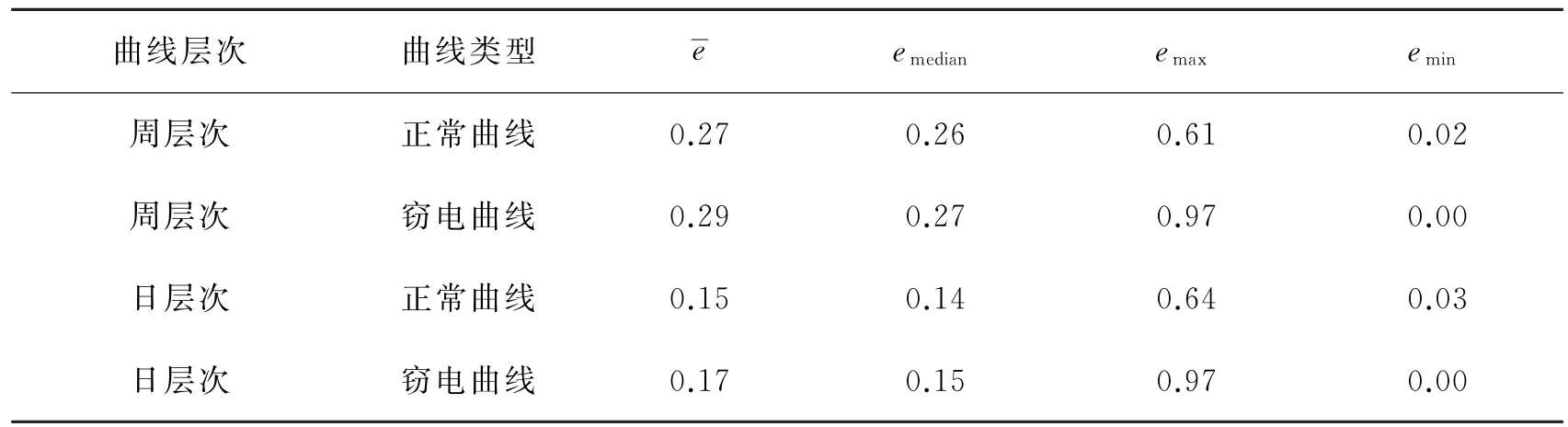
表2 周、日层次正常、窃电曲线的重构误差Table 2 Reconstruction error of normal and abnormal curve at weekly and daily levels
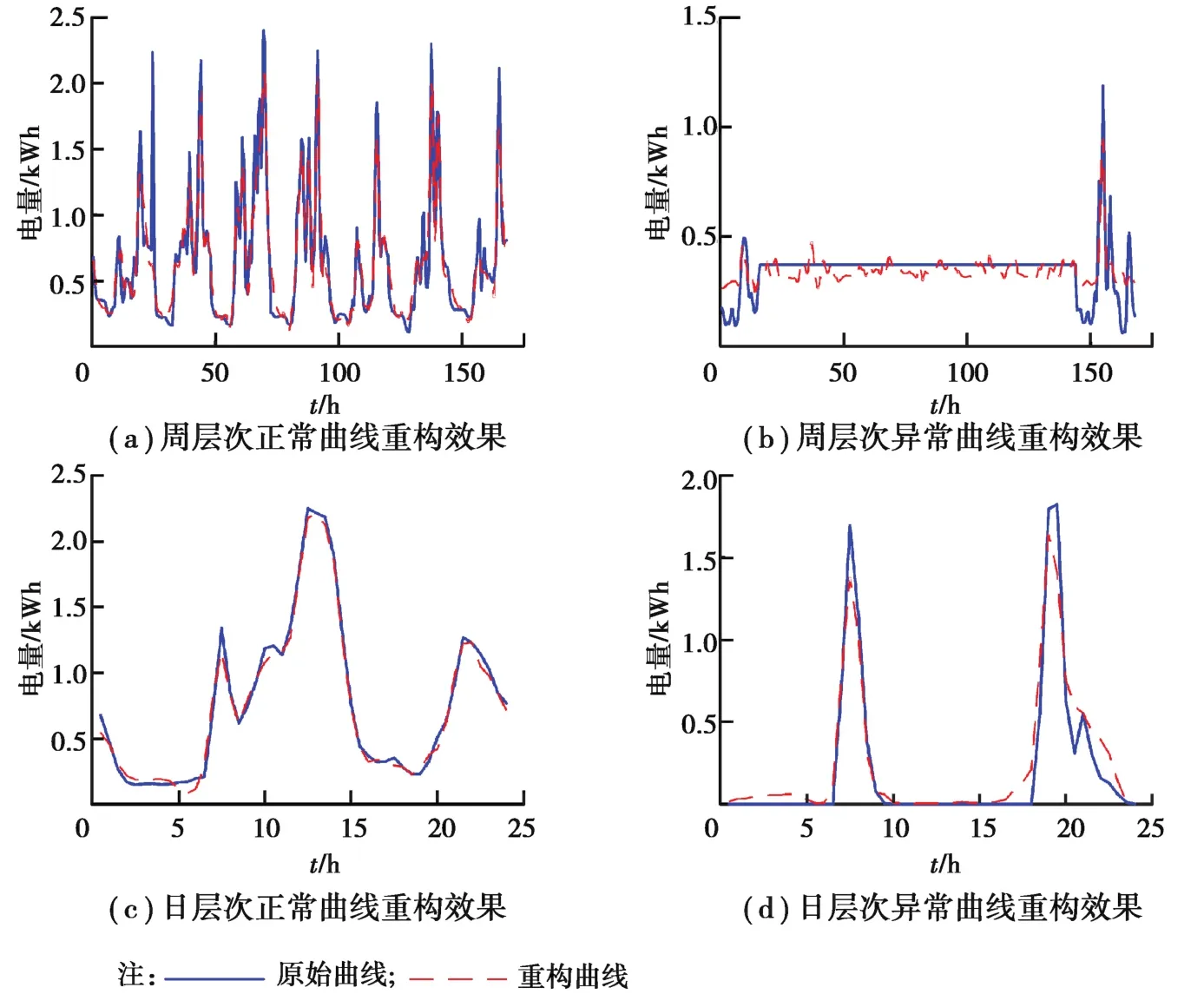
图7 周、日层次典型正常、窃电曲线的重构效果Fig.7 Reconstruction effect of typical normal and abnormal curve at weekly and daily levels
由表2可知,周、日两个层次下正常曲线和窃电曲线样本重构平均相对误差的平均值、中位数都处于较低水平,说明非负稀疏编码算法能够实现对用电曲线的良好重构,因此基于非负稀疏编码提取用电曲线的用电模式特征是合理的。
4.3 基于多层次非负稀疏编码和SVM的窃电检测方法的有效性验证
文中所提基于多层次非负稀疏编码和SVM的窃电检测方法核心在于改善窃电检测特征的设计方式,进而提高窃电检测的准确率,因此只需验证在同一检测判别算法下采取文中特征设计方式能够取得相较其他方式更高的检测准确率,即可验证文中方法有效性,据此设计5种特征方式如下:
1)直接以原始变量为特征,不做额外特征设计处理;
2)基于主成分分析(principal component analysis,PCA)构建检测特征;
3)基于独立成分分析(independent component analysis,ICA)构建检测特征;
4)基于日曲线单一层次非负稀疏编码和窃电情景分析构建检测特征;
5)基于周、日曲线多层次非负稀疏编码和窃电情景分析构建检测特征。
为叙述方便,将上述5种特征设计方式分别简记为ORIGIN、PCA、ICA、DSC和 WDSC。以高斯核函数非线性SVM为检测判别算法,各种特征设计方式下窃电样本的检测效果以及对应SVM超参数的取值如表3所示。
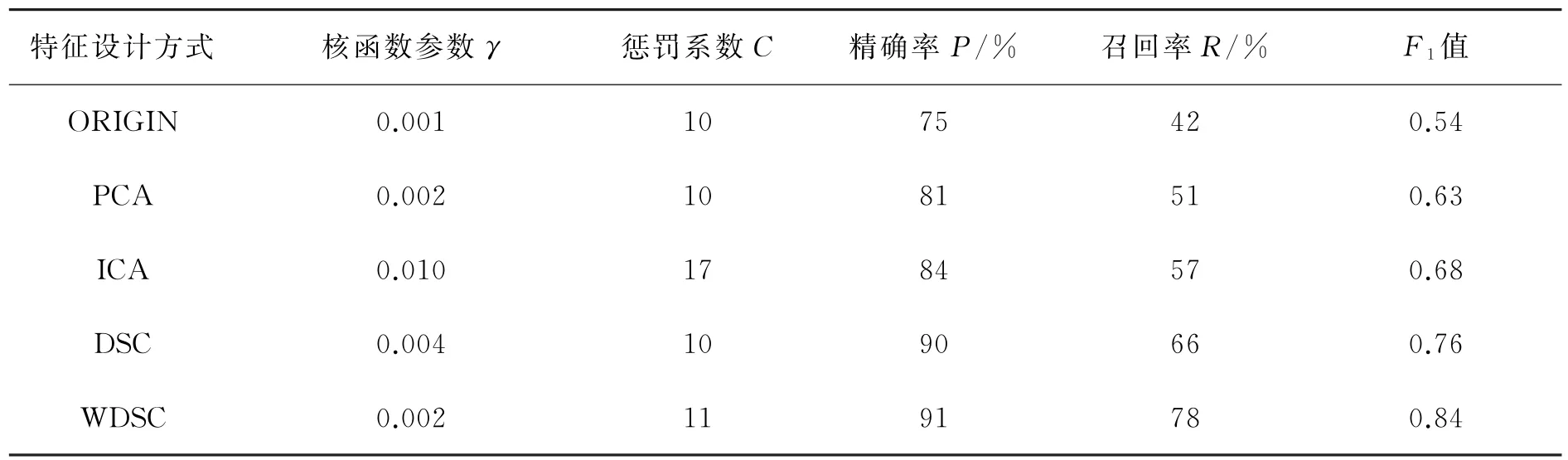
表3 各种特征设计方式下样本的检测效果Table 3 Detection results of the samples under various feature processing methods
由表3可见,ORIGIN取得了最低的F1值,说明额外的特征设计可以在一定程度上排除随机性等因素对样本曲线的干扰,聚焦于用户的主要用电特征,提高检测判别方法的精确率与召回率。
对比WDSC、DSC和ICA、PCA特征设计方式下的检测结果,WDSC和DSC取得了相较ICA和PCA更高的F1值,表明文中所提基于非负稀疏编码和情景分析的特征设计方法相比ICA、PCA特征设计方法更有效。这是由于WDSC、DSC将月度曲线的用电特征分为形状特征和数量特征分别构建,分别赋予各分量特征以物理意义,保证了特征的可解释性和针对性,易于修正改进;而ICA、PCA等通用特征提取算法没有依据窃电检测问题数据特征对方法作适应性调整,故对高度随机的用户用电曲线样本适应性差。
对比WDSC和DSC特征设计方式下的检测结果,两种特征提取方式在检测精确率上效果接近,但周、日多层次稀疏编码算法在召回率上明显高于日曲线单一层次稀疏编码算法,说明周、日两个层次的用电特征的确存在,多层次的特征提取能更加充分地刻画用户的用电特征。
综上,文中所提基于多层次非负稀疏编码和SVM窃电检测方法通过改善窃电检测特征的设计方法,能够有效提高窃电样本的检测精确率和召回率。
4 结 论
虚假数据注入的新型窃电方式下,现有窃电检测方法准确率不高。文中提出了一种基于多层次非负稀疏编码和SVM的窃电检测方法,主要研究结论如下:
1)相较于直接以原始用电曲线为特征,对原始用电曲线进行额外特征设计处理有助于排除随机性等因素对曲线用电特征的干扰,聚焦用户主要特征,进而可提高窃电样本检测的准确率。
2)正常曲线和窃电曲线的非负稀疏编码重构平均相对误差平均值、中位数都处于较低水平,说明非负稀疏编码算法能够实现对用电曲线的良好重构,基于非负稀疏编码提取用电曲线的用电模式特征是合理的。
3)基于多层次非负稀疏编码和情景分析的用电曲线融合特征设计方法能够有效提取用电曲线的用电特征,相较其他通用特征提取方法,文中方法在窃电检测的精确率和召回率上具有明显优势。
4)多层次非负稀疏编码由于同时考虑了月度用电曲线的日周期性和周周期性,相较单一层次非负稀疏编码特征提取方法更能全面刻画用户用电特征,能取得更高的窃电样本检出率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年7期)2022-04-22
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
天津诗人(2017年2期)2017-11-29
中学生数理化·中考版(2016年2期)2016-09-10
学苑创造·A版(2016年5期)2016-06-21
电影新作(2014年2期)2014-02-27
中国计算机报(2009年27期)2009-04-27
